
Исходные данные и описание проблемы
Сохранение входящих JSON документов в архивную БД
Немного контекста о том, как возникло это исследование...
В один из тех летних дней, когда на улице стояла ясная, солнечная, жаркая погода, когда стрижи быстро пролетали за окном, распространяя веселые звуки, мы закончили очередную задачу по проекту (в нашем проекте используется Python). Задача заключалась в получении различными способами (очередь, сервисы, файловая система и т.д.) входящих документов (JSON формат), обработке этих документов и сохранении обработанных документов обратно в JSON формате в архивную базу данных. Завершив кодирование и юнит тесты, мы выкатили решение на одно из тестовых окружений и стали ждать результатов. По функциональности решение работало отменно, но, оценив скорость работы решения, я задался вопросом, а можно ли его ускорить?

Если не вдаваться в детали, решение выполняло следующие простые действия:
- Получение данных из А (это может быть база данных вроде Oracle, MySQL, Postgres, MongoDB, или очередь, или специальный сервис)
- Дополнительная фильтрация и обогащение данных
- Запись в базу данных B в формате JSON
Первое, что пришло в голову — это добавить большее количество параллельных процессов. С увеличением числа процессов решение существенно ускорилось (примерно в N раз по количеству процессов, но не более чем в 32 раза для 32 процессов, т.к. с дальнейшим увеличением скорость начинала падать). Следующая диаграмма наглядно демонстрирует зависимость скорости обработки данных (фиксированное значение) от количества процессов. Я предполагаю, что такое поведение вызвано возрастающими накладными расходами для координации данных между процессами (мы использовали MultiprocessingPool) и возросшей нагрузкой на сеть и БД. После определенного значения (в моем случае это было 85 процессов) решение совсем переставало работать по причине нехватки памяти на рабочем компьютере.
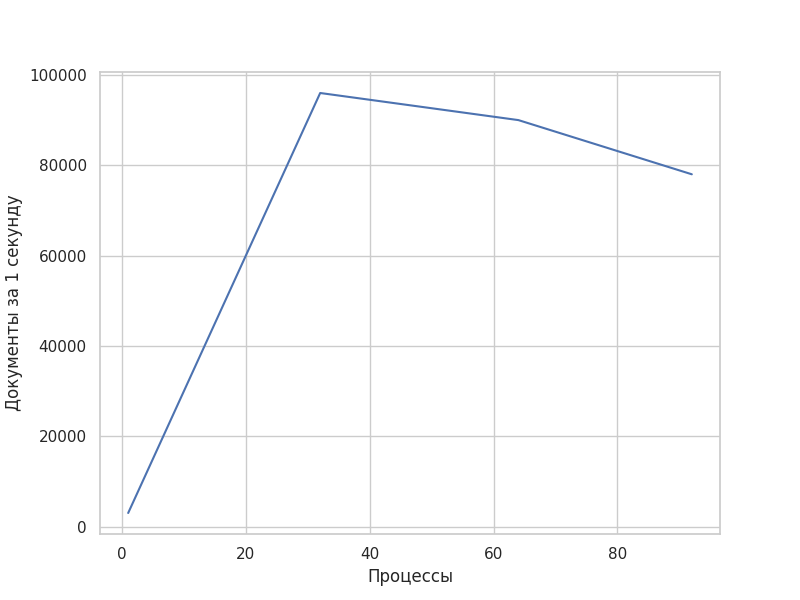
Интуиция шептала мне, что это ещё не всё, и можно копнуть глубже и попробовать оптимизировать решение для одного процесса.
В рамках данной статьи я не рассматриваю варианты с распределенными решениями на Python, такие как ray или dask. Хотя было бы интересно оценить и их возможности для подобной задачи, но это оставим для будущих статей.
Изначальная реализация работала медленно, профайлинг показал узкое место и большую трату времени на сериализацию JSON
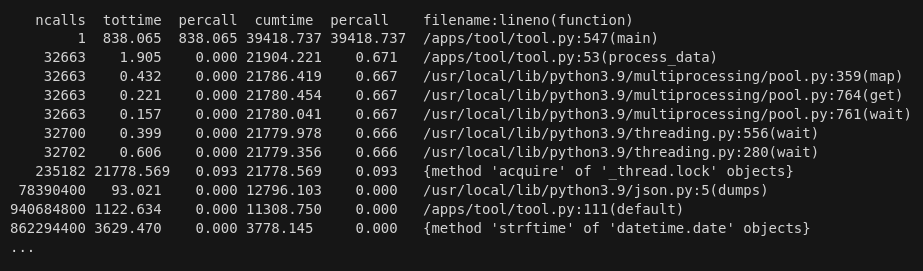
Вооружившись инструментами для профайлинга: cprofile и py-spy, я проанализировал, какие части кода чаще всего вызываются и занимают больше времени. В лидерах в негативном плане были вызовы из модуля threading и конвертация (или сериализация) JSON документа в Python словарь и обратно (для этого в первоначальной версии использовался стандартный модуль json).
То, что вызовы из модуля threading оказались лидерами, я объяснял тем, что под капотом multiprocessing.Pool использует threading модуль для обмена данными между главным процессом и процессами в пуле. С ростом количества процессов накладные расходы растут, и такое взаимодействие становится все более и более заметным. Тут вряд ли можно что-то сделать, разве только использовать альтернативную реализацию мультипроцессного пула (например, вроде mpire, но мои быстрые проверки с этим пакетом очевидных приемуществ в рамках данной задачи не показали).
А вот с конвертацией JSON документов в Python словарь и обратно можно было попробовать поработать, чем я и занялся.
Результаты профайлинга (cprofile):
Подборка альтернативных JSON сериализаторов на Python и их сравнение
Популярными решениями (но не всегда простыми) по ускорению того или иного медленного кода на Python являются реализации на более низкоуровневых языках (C, C++, Rust), использование Cython или использование pypy (далеко не всегда срабатывает и обычно имеет отставание от cpython в плане функционала).
К счастью, для работы с JSON существуют проекты, которые предоставляют альтернативы стандартному модулю json и имеют более высокую производительность.
Вот некоторые из них:
ujson — неплохая альтернатива, написанная на C/C++. Из недостатков можно отметить то, что не все функциональные возможности (на момент написания статьи), имеющиеся в json, реализованы в ujson;
orjson — хорошая альтернатива, созданная на Rust. API почти аналогичен модулю json (за небольшим недостатком);
rapidjson — еще одна хорошая альтернатива, реализованная на C++.
В документации и в описании вышеуказанных пакетов есть ссылки на бенчмарки. Бывает так, что автор хвалит и демонстрирует преимущества своего решения, что приводит к публикации таких бенчмарков, которые оказываются невоспроизводимыми в обычных ситуациях. Следуя принципу «доверяй, но проверяй», я решил удостовериться в объективности оценок и повторить измерения самостоятельно.
Быстрый бенчмарк для вызовов dump и load вышеупомянутых модулей приведен ниже на диаграммах. В качестве данных использовались случайно сгенерированные JSON документы пользовательского профайла следующего формата (пример в виде Python словаря):
{
"_id": "801512f3ff9658d50e47fe90",
"about": "I’m currently a Senior Data Science Manager at Indeed.com, where I help our Job Search Front End, Search Matching/Ranking, and Taxonomy teams.",
"address": "087 Simmons Greens Apt. 948\nGinastad, LA 61807",
"age": 32,
"balance": "$5,583.41",
"birthday": datetime.datetime(1990, 5, 4, 0, 0, 0, 0),
"company": "Indeed.com",
"email": "lisahenson@indeed.com",
"eyeColor": "#e2b21f",
"favorite": "whole",
"friends": [{"id": 63, "name": "Derek Greene"},
{"id": 68, "name": "Renee Doyle"},
{"id": 36, "name": "James Livingston"},
{"id": 43, "name": "Tyler Murphy"}],
"gender": "female",
"greeting": "Howdy!",
"guid": "749a6412-63a0-47f8-bdd8-268bd5c2162b",
"index": 2566,
"isActive": False,
"latitude": 36.215487,
"longitude": 71.038439,
"name": "Lisa Henson",
"phone": "791.126.7836x392",
"picture": "https://somehost.io/37x29",
"registered": datetime.datetime(2019, 11, 16, 19, 18, 24, 256),
"tags": ["data science",
"internet",
"california",
"bike",
"lakers",
"food",
"travelling",
"hiking"]
}")
")

Данные были получены после десяти прогонов с предварительным разогревом и взята медиана для каждого из пакетов для сериализации и десериализации JSON соответственно 1, 10.000, 1.000.000 документов. Это стандартная практика для того, чтобы избежать возможных флуктуаций, возникающих под влиянием других запущенных процессов. Указанное время — это время работы только вызова: package.loads(json_str) и package.dumps(python_obj). Также перед каждым измерением производился небольшой прогрев (1-5 предварительных вызовов целевой функции).
Стоит отметить, что на измерения могут влиять (как в худшую, так и в лучшую сторону) типы данных, используемые в JSON документе. Для более точных результатов имеет смысл производить измерения на шаблоне, близком к тому, что будет использоваться на практике.
Для моего бенчмарка победителем оказался orjson. В этот раз результаты оказались сравнительно похожими на те, что опубликованы в документациях рассмотренных пакетов.
Изучив документацию orjson, я решил попробовать этот пакет для сериализации/ десериализации JSON документов. После подмены пакета с json на orjson я был удивлен тем, что скорость обработки одним процессом увеличилась почти в 2 раза.
Сериализация даты с модулем json
На этом можно было бы и закончить, но тут возникли некоторые проблемы. В данных, с которыми я работал, использовались даты, которые при конвертации в Python словарь становились объектами типа datetime.datetime. А json модуль не умеет (без дополнительных действий) сериализовать объекты типа datetime, да и любые другие объекты, которые не поддерживаются модулем. В случае сериализации неподдерживаемого типа json.dumps() бросает исключение вида: TypeError: Object of type datetime is not JSON serializable. Кроме того, в моем случае даты должны были сериализовываться с определенным кастомизированным форматом.
Забегая вперед, скажу, что orjson предоставляет возможность сериализовать даты в формате по умолчанию, но этот формат мне не подходил.
Выход из этой ситуации с json состоит в том, чтобы в вызове json.dumps() использовать дополнительный аргумент default: json.dumps(python_obj, default=custom_encoder). Этот аргумент принимает callable и использует этот callable для тех случаев, когда json.dumps() не может провести сериализацию. В теории, использование default должно приводить к накладным расходам и, следовательно, к более медленной работе. Посмотрим, как использование этой части влияет на скорость сериализации на практике. Вариант без default использует дату просто в виде строки.
Ниже приведены некоторые примеры использования default для работы с датами (и не только) в Mongo или в Django (в случае Django может использоваться альтернативный способ).
# Mongo
from bson import json_util
import json
json.dumps(py_obj_with_date, default=json_util.default)
# Django
from django.core.serializers.json import DjangoJSONEncoder
json.dumps(py_obj_with_date, cls=DjangoJSONEncoder)
# Общий вариант
import datetime
import json
def default(obj):
if isinstance(obj, (datetime.date, datetime.datetime)):
return obj.isoformat()
json.dumps(py_obj_with_date, default=default)

Как и предполагалось, дополнительно вызываемый код добавляет возможности, но также затрачивает какое-то время на сериализацию, что для этого примера, на мой взгляд, не сильно криминально.
Так как используемый в default callable сам по себе будет оказывать влияние на скорость работы, то его эффективность должна быть оптимальной.
Нюансы использования orjson и поиск возможных решений
orjson имеет близкий API с модулем json для сериализации. Если вам подходит формат даты ISO 8601, то вариант с orjson.dumps(pyobj) отлично подойдет. Но если необходим кастомизированный формат даты (как получилось в моем случае), то orjson.dumps() также имеет параметр default, который имеет такое же назначение, как и в json.dumps(). Дополнительно необходимо передать параметр option=orjson.OPT_PASSTHROUGH_DATETIME, который является маркером того, что объект типа datetime будет конвертироваться callable указанным в параметре default: orjson.dumps(pyobj, default=default, option=orjson.OPT_PASSTHROUGH_DATETIME)
Интересно, насколько быстро с данной задачей справится orjson с моим кастомным сериализатором даты на Python в сравнении с json?
Для этого сравнения будем использовать следующую функцию, написанную на Python, в качестве параметра для default:
def default(obj):
if isinstance(obj, (datetime.date, datetime.datetime)):
return obj.isoformat()
Как обычно, измерения делаем 10 раз и в этот раз для 1 миллиона JSON документов, каждый из которых содержит дату типа datetime, в качестве результата берем медиану. В дополнение добавим в сравнение сериализацию с использованием orjson с обработкой дат по умолчанию: orjson.dumps(obj).


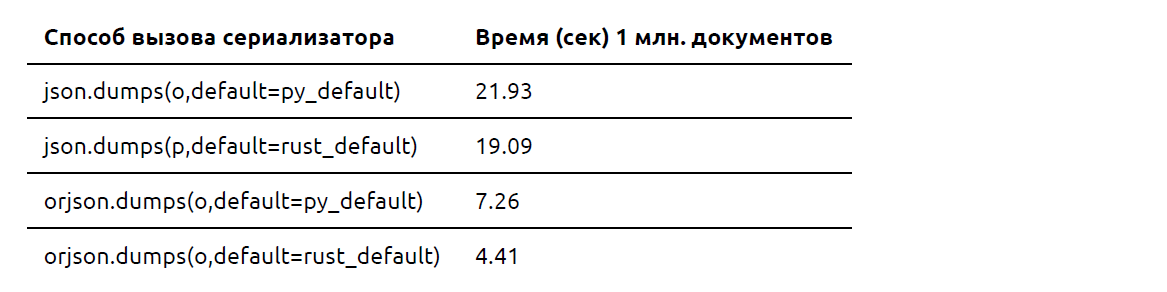
Как видно из измерений:
1. orjson.dumps(obj, default=default) отрабатывает почти в 4 раза быстрее, чем json(obj, default=default).
2. orjson.dumps(obj) отрабатывает почти в 2 раза быстрее, чем orjson.dumps(obj, default=default), где default - «кастомизированная» функция написанная на Python.
Использование кастомного datetime форматтера на Rust с orjson
Далее мне стало интересно, насколько можно приблизиться к измерениям, которые демонстрирует orjson.dumps(obj) с кастомизированным форматом даты? Отсюда появилась мысль переписать соответствующий код для default функции на Rust и использовать эту, потенциально более быструю, функцию.
Посмотрев, что предлагают существующие Rust байндинги для Python, я решил остановить свой выбор на самом популярном пакете: PyO3
Чтобы реализовать модуль для Python, написанный на Rust, мне пришлось по сути создать отдельный проект. Следуя гайдлайнам PyO3, я использовал в качестве финального сборщика и паблишера инструмент под названием Maturin и в результате получил желаемый wheel файл, который мог устанавливаться как зависимость в Python проект.
При финальной сборке необходимо не забывать использовать --release флаг, чтобы Rust компилятор использовал оптимизации, иначе полученный пакет может работать медленнее кода, написанного на Python.
Для иллюстрации будем использовать следующий вариант default (только для демонстративных целей, в моем случае код, конечно, был несколько другим):
fn serialize_date(date_obj: &PyDateTime) -> PyResult<HashMap<String, String>> {
let mut result: HashMap<_, _> = HashMap::new();
result.insert(
String::from("$date"),
format!("=={}-{:02}-{:02}T{:02}:{:02}:{:02}.{}==",
date_obj.get_year(),
date_obj.get_month(),
date_obj.get_day(),
date_obj.get_hour(),
date_obj.get_minute(),
date_obj.get_second(),
date_obj.get_microsecond())
);
Ok(result)
}
#[pyfunction]
fn rust_default(obj: &PyAny) -> PyResult<HashMap<String, String>> {
if obj.is_instance::<PyDateTime>()? {
return serialize_date(obj.downcast::<PyDateTime>()?);
} else {
return Err(PyTypeError::new_err("Type is not JSON serializable"));
}
}
// Функция, которая почти ничего не делает: нужна для "определения накладных расходов"
#[pyfunction]
fn do_nothing(_obj: &PyAny) -> PyResult<String> {
Ok(String::from("{}"))
}
#[pymodule]
fn custom(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(do_nothing, m)?)?;
m.add_function(wrap_pyfunction!(rust_default, m)?)?;
Ok(())
}Примерным аналогом функции serialize_date будет следующий код на Python:
def py_default(obj):
if isinstance(obj, (datetime.date, datetime.datetime)):
return {
"$date": (f'=={obj.year}-{obj.month:02}-{obj.day:02}T'
f'{obj.hour:02}:{obj.minute:02}:{obj.second:02}.{obj.microsecond}==')
}
Результаты измерений в случае использования функций py_default и rust_default и для json, и для orjson. Функция, написанная на Rust, работает быстрее на 13% для json модуля и на 40% быстрее в случае orjson. Код, написанный на Rust, опирается на макрос format!, который не является быстрым вариантом.
Попытка оптимизации кода на Rust
Ради интереса я решил испытать себя и попробовать написать более быстрый вариант на Rust (сразу хочу отметить, что не являюсь экспертом в Rust, поэтому было бы интересно получить советы и рекомендации по этому поводу в комментариях). Ниже код, к которому я пришел для «оптимальной» версии на Rust, которая примерно на ~15% быстрее первоначальной версии «в лоб»:
fn serialize_date(date_obj: &PyDateTime) -> PyResult<HashMap<String, String>> {
let mut array: [u8; 30] = [0; 30];
let mut result: HashMap<_, _> = HashMap::new();
array[0] = 61; // =
array[1] = 61; // =
// year
let mut year = date_obj.get_year();
let mut year_array: [u8; 4] = [0; 4];
for i in (0..=3).rev() {
year_array[i] = (year % 10) as u8;
year = year / 10;
}
array[2] = year_array[0] + 48;
array[3] = year_array[1] + 48;
array[4] = year_array[2] + 48;
array[5] = year_array[3] + 48;
array[6] = 45; // -
// month
let mut month = date_obj.get_month();
let mut month_array: [u8; 2] = [0; 2];
if month < 10 {
array[7] = 48;
array[8] = (month as u8) + 48;
} else {
array[8] = (month % 10) as u8 + 48;
month = month / 10;
array[7] = (month % 10) as u8 + 48;
}
array[9] = 45; // -
// day
let mut day = date_obj.get_day();
let mut day_array: [u8; 2] = [0; 2];
if day < 10 {
array[10] = 48;
array[11] = (day as u8) + 48;
} else {
array[11] = (day % 10) as u8 + 48;
day = day / 10;
array[10] = (day % 10) as u8 + 48;
}
array[12] = 84; // T
// hour
let mut hour = date_obj.get_hour();
let mut day_array: [u8; 2] = [0; 2];
if hour < 10 {
array[13] = 48;
array[14] = (hour as u8) + 48;
} else {
array[14] = (hour % 10) as u8 + 48;
hour = hour / 10;
array[13] = (hour % 10) as u8 + 48;
}
array[15] = 58; // :
// minute
let mut minute = date_obj.get_minute();
let mut minute_array: [u8; 2] = [0; 2];
if minute < 10 {
array[16] = 48;
array[17] = (minute as u8) + 48;
} else {
array[17] = (minute % 10) as u8 + 48;
minute = minute / 10;
array[16] = (minute % 10) as u8 + 48;
}
array[18] = 58; // :
// second
let mut second = date_obj.get_second();
let mut second_array: [u8; 2] = [0; 2];
if second < 10 {
array[19] = 48;
array[20] = (second as u8) + 48;
} else {
array[20] = (second % 10) as u8 + 48;
minute = second / 10;
array[19] = (second % 10) as u8 + 48;
}
array[21] = 46; // .
// microsecond
let mut us = date_obj.get_microsecond();
let mut us_array: [u8; 6] = [0; 6];
for i in (0..=5).rev() {
us_array[i] = (us % 10) as u8;
us = us / 10;
}
array[22] = us_array[0] + 48;
array[23] = us_array[1] + 48;
array[24] = us_array[2] + 48;
array[25] = us_array[3] + 48;
array[26] = us_array[4] + 48;
array[27] = us_array[5] + 48;
array[28] = 61; // =
array[29] = 61; // =
let ds = str::from_utf8(&array).unwrap();
result.insert(
String::from("$date"),
String::from(ds)
);
Ok(result)
}Финальные результаты в виде чарта и таблицы:
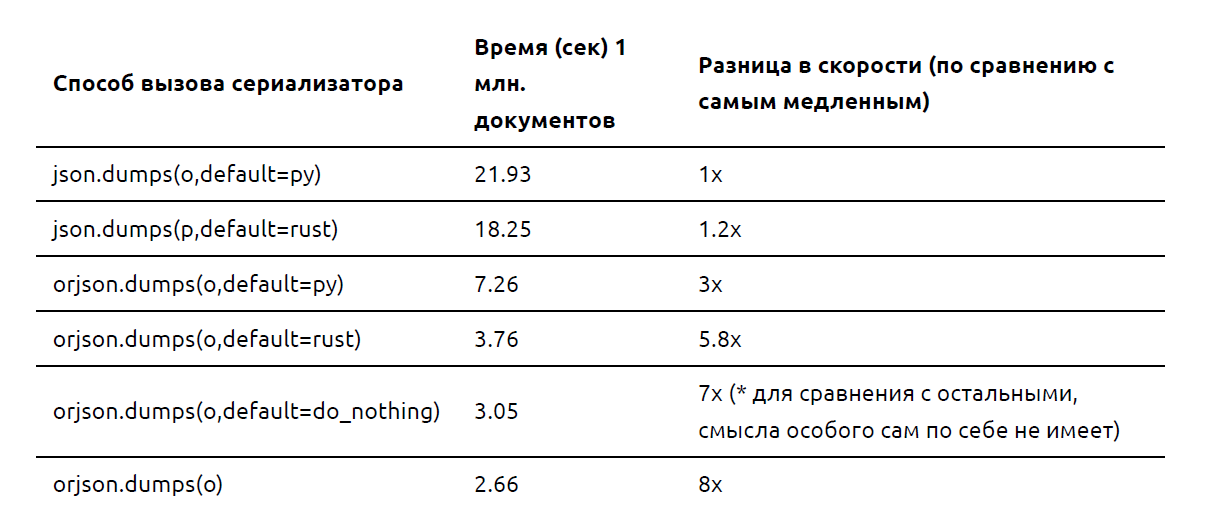

С этой «оптимизированной» функцией на Rust мне удалось увеличить производительность почти в 2 раза по сравнению с аналогичной на Python при использовании orjson.
В заключении этой части хотелось бы сказать несколько слов о нюансах эффективного использования PyO3 байндинга для Python:
PyO3 предоставляет возможность конвертировать объекты Python в структуры Rust (через trait FromPyObject). Для достижения оптимального результата в производительности в первую очередь следует конвертировать Python типы в родные для Rust типы. Работать с Python типами можно (например, со списками через &PyList), но оптимальной производительности достичь в этом случае сложно. Поэтому все «тяжелые» вычисления оптимальнее переложить на Rust. PyO3 предоставляет удобный набор основных типов из коробки, которые преобразуются из Python в Rust автоматически.
Простой и оптимизированный код на Python сложно ускорить через Rust байндинг. Попробуйте написать простую функцию sum(), аналогичную встроенной функции в Python, и вы обнаружите, что код на Python будет работать быстрее, чем на Rust. Почему? Вероятно потому, что для такого примера будет оверхэд в виде конвертации данных из &PyList в Vec<i64>.
Заключение
Вот такое небольшое приключение получилось у нас: начали с рабочей, но не очень скоростной версии решения и ускорили самую медленную часть благодаря альтернативному JSON сериализатору почти в 6 раз (и в 2 раза, если рассматривать решение целиком). Мимоходом произвели большое количество измерений и сравнений возможных вариантов сериализации.
Наше решение на практике стало работать быстрее, что можно было отметить даже невооруженным глазом. С другой стороны нам пришлось:
добавить дополнительные зависимости в проект (orjson и кастомизированный сериализатор даты)
создать отдельный проект на Rust для кастомизированной части для сериализации даты,
добавить юнит тесты (и для Python части и для Rust части)
поддерживать проект кастомизированного сериализатора даты: после внесения изменений пакет необходимо перестроить и опубликовать в локальный или публичный репозиторий,
обновить CI: добавить все необходимые действия в пайплайн для поддержки проекта.
Стоит оно того или нет? Каждый решает сам, исходя из необходимости и имеющихся в распоряжении времени и ресурсов...
P.S.: В завершении хотелось бы попросить читателей поделиться в комментариях своим опытом оптимизации и ускорения Python решений. Что работало и помогало, а что нет? Заранее спасибо.
Комментарии (20)

trak
09.06.2022 15:16Результаты профайлинга (cprofile):
прокомментируйте пожалуйста, где на этом выводе cProfile видны тормоза преобразования в Json ? (не сарказм, серьезно)

Bromles
09.06.2022 16:43Очень странная подсветка в блоках кода на Rust. Буквально 2-3 слова подсвечивает, остальное серое. Это у меня баг или автор выставил не Rust в качестве языка для них?


cepera_ang
09.06.2022 18:53+2simdjson не пробовали? Быстрее ничего нет :)

GamePad64
10.06.2022 01:14+4По поводу сериализации даты на Rust:
Массив лучше всего сразу заводить динамический: `vec![0; 30]`. Затем поглащать его через String::from_utf8_unchecked. Во-первых, не породим лишнюю копию данных, во-вторых, избежим ненужных проверок.
HashMap лучше сразу создать с HashMap::with_capacity(1);
Лишние переменные: month_array, day_array и другие.
Про деление уже выше сказали

DirectoriX
10.06.2022 04:23+2Почти всё ещё забавно наблюдать как разработчики сначала пишут проект на лайтовых скриптиках (Python, Node.js), а потом героически поднимают производительность ныряя в нормальные компилируемые языки (обычно сразу в C/C++/Rust).
Каждый раз интересно, что мешает сразу писать на чём-то более производительном, хотя бы на Java/.Net.
lebedec
10.06.2022 09:00+4А мне так же забавно наблюдать как разработчики сначала берут Java/.Net, тратят буквально недели на обсуждения очередного интерфейса или абстрактного класса, чтобы достичь необходимой гибкости архитектуры. И в конечном итоге всё равно из-за нехватки производительности изучают твики виртуальной машины, изобретают всякие костыли для ручного управления памятью и прочее.
Пренебрежительное отношение к скриптовым языкам может быть разве что от незнания бытовой мудрости — какой бы язык не выбрал, всё равно найдутся функциональные блоки, которые будет выгоднее переписать на другом языке.DirectoriX
10.06.2022 13:51+2Я ж не спорю, что, например, для прототипирования или для однократных задач скриптовые языки лучше. Но такое ощущение, что все команды думают: «Ну уж этот проект точно никогда не будет обрабатывать много данных, поэтому быстро напишем на том, на чём можем быстро написать». Только вот далеко не всегда такая быстрая разработка выливается в простую поддержку, оказывается, что иногда приходится переписывать на чём-то быстро работающем, то есть выполнять двойную разработку.
Тут виноваты скорее даже не сами разработчики, а аналитики, которые не смогли заранее, до начала разработки, предсказать нагрузку на продукт/модуль.

Insurgent2018
10.06.2022 09:05-1Сарказм? Прежде чем понять, что появились(возникли) проблемы в производительности в том или ином конкретном месте, проект должен уже работать хотя бы как внутренний MVP. Очевидно, что на C и так далее, вы более или менее сложный проект - будете только дописывать, когда "клиенты" уже будут пользоваться проектом, а автор только лишь тюнить узкие места.
amarao
В растовом коде я вижу деление одной и той же переменной в цикле. Это убивает производительность (для этой операции) примерно в 5 раз. Деление (или взятие остатка от деления) в конвейре занимает 2 тика, деление для зависимого значения (т.е. деление результата предыдущего деления) занимает 20+ тиков.
Возможно, все конвертации можно заменить на lookup-таблицы (т.е.
month_str = month_lookup[month])dopusteam
А можете поделиться ссылкой или подробностями, почему так?
amarao
Я это для себя обнаруживал, отлаживая tight loop в графическом коде (где надо быстро-быстро считать точки, хотя бы 60 кадров в секунду).
С ходу нашёл вот это: https://www.geeksforgeeks.org/computer-organization-and-architecture-pipelining-set-2-dependencies-and-data-hazard/
А сами цифры вот: https://www.agner.org/optimize/instruction_tables.pdf
Для IDIV там IDIV r64/m64 2 9-17 7-12 (2 тика в pipeline, 7-12 если сделать для data dependency)
cepera_ang
Потому что операция деления одна из самых затратных и если делить независимые значения процессор может параллельно (т.е. каждые n тактов начинать операцию деления, которая занимает 10*n тактов), то для деления одного значения несколько раз по очереди нужно каждый раз дождаться результатов предыдущей операции.
ofhellsfire Автор
Спасибо за идею и ссылки. Обязательно попробую!
domix32
Есть подозрение, что можно обойтись ссылками на слайсы конечного массива, а не аллоцировать отдельные массивы. Плюс +48 сделать в конце всего, дабы не захламлять код.