
Всем читающим эту статью здрасте. Сегодня я хотел бы поделиться с вами своей реализацией поиска в ширину (BFS) на C#.
Негативные комментарии, касающиеся моего говнокода и реализации поддерживаются. Настоятельно рекомендую вам высказаться по поводу всего. Я начинающий, поэтому думаю, что это даже к лучшему.
Для начала я хотел бы кратко ознакомить вас с принципом работы моего кода
Что к чему?
Итак, изначально я создал класс под названием BFS:
class BFS{
}Далее я начал создавать такие поля и свойства, как:
Начальное значение (StartValue)
Конечное значение (GoalValue)
Словарь с вершинами (Graph)
Очередь (Queue)
И проверенные значения (UsedValues)
class BFS
{
private string _startValue;
public string StartValue {
get { return _startValue; }
set { _startValue = value; }
}
private string _goalValue;
public string GoalValue
{
get { return _goalValue; }
set { _goalValue = value; }
}
private Dictionary<string, string[]> _graph = new Dictionary<string, string[]>();
public Dictionary<string, string[]> Graph
{
get { return _graph; }
set { _graph = value; }
}
private Queue<string> _queue = new Queue<string>();
public Queue<string> Queue
{
get { return _queue; }
set { _queue = value; }
}
private List<string> _usedValues = new List<string>();
public List<string> UsedValues
{
get { return _usedValues; }
set { _usedValues = value; }
}
}Объявил конструктор класса:
public BFS(string startValue, string goalValue, Dictionary<string, string[]> graph)
{
StartValue = startValue;
GoalValue = goalValue;
Graph = graph;
}Создал метод поиска кратчайшего пути:
public void Search()
{
Queue.Enqueue(StartValue);
while (Queue.Count != 0)
{
string node = Queue.Dequeue();
string[] vertites = Graph[node];
if (node == GoalValue)
{
return;
}
foreach (string vertite in vertites)
{
if (!UsedValues.Contains(vertite))
{
if (vertite == GoalValue)
{
if (Queue.Count > 0)
{
Queue.Dequeue();
}
Queue.Enqueue(node);
Queue.Enqueue(GoalValue);
return;
}
Queue.Enqueue(vertite);
}
}
UsedValues.Add(node);
}
}И, наконец, метод вывода кратчайшего пути:
public void ShortestWay()
{
Search();
Console.Write($"{StartValue} ");
foreach (string value in Queue)
{
Console.Write($"--> {value} ");
}
}Работа программы
За основу возьмем вот такой вот граф:

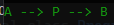
Кратчайший путь от A до B равен А -> P -> B
Запускаем программу, и получаем такой же вывод
Заключение
На этом в принципе можно и заканчивать. Кто дочитал до конца, тому я сильно благодарен. Поддерживаю критику в сторону моего кода, приму все во внимание
Кто хочет скачать код, держите ссылку на GitHub.
Комментарии (15)

alexdesyatnik
02.07.2022 15:14+11Современный C# поддерживает краткую форму записи свойств на тот случай, когда в геттерах и сеттерах нет никакой логики (как у вас), пользуйтесь этим, чтобы уменьшить количество boilerplate кода.
Не надо делать свойства публичными, если это не является необходимым. Публичные свойства и методы образуют интерфейс класса (не в языковом смысле, а в смысле модели использования клиентским кодом), зачем наружу будет торчать то, что не должно модифицироваться снаружи? В вашем случае вообще все свойства стоит сделать приватными.
Если английский не очень хороший, имеет смысл включить спеллчекер в настройках среды разработки. Что означает слово "vertite" в принципе понятно из контекста, но вообще вершина это "vertex" / "vertices". Это может казаться мелочью, но в большом объёме кода подобные мелочи снижают читаемость кода.
Нужно ли разносить инициализацию и запуск поиска? Подумайте, как ваш класс может быть использован в клиентском коде.
Точно не нужно смешивать возврат результата работы алгоритма и вывод. Я понимаю, что это исключительно учебный код, но это очень плохая привычка. Код для BFS должен принимать на вход граф и необходимые параметры поиска, и возвращать результат. Вывод результата на экран - не его задача.

dopusteam
02.07.2022 15:46+2Добавлю ещё, что оба метода (search и shortestWay) публичные, но ничего не возвращают и при этом меняют внутреннее состояние. Можно их дёргать бесконечно и надеяться, что результат будет адекватным или хотя бы одинаковым

lair
02.07.2022 17:58+3В вашем случае вообще все свойства стоит сделать приватными.
Нужно ли разносить инициализацию и запуск поиска?
Точно не нужно смешивать возврат результата работы алгоритма и вывод.Прямо скажем, там вообще класс низачем не нужен. Один статический метод для поиска, который возвращает маршрут. Все эти свойства все равно нигде не используются.

mayorovp
02.07.2022 18:37+9Ваш способ хранения графа никуда не годится. Для начала, строки. Вы вообще понимаете, что строка — "медленный" тип данных? То же сравнение двух строк работает за ϴ(L), где L — длина строки. Причём эта самая длина строки равна Ω(log V), где V — количество вершин! Задумайтесь: вы заполучили множитель log V в вашу асимптотику только из-за того что выбрали хранение вершин как строк!
Ну, справедливости ради, в теории множитель log V будет при любом способе хранения, однако на практике именно в случае строк его невозможно игнорировать при малых V.
А ведь это далеко не единственная проблема строк, та же поддержка Юникода ещё и даёт приличных константный множитель при использовании компаратора по умолчанию...
Наконец, при использовании одних только строк ваш алгоритм является неуниверсальным. Если множество применений алгоритмов на графах — и некоторые из них требуют обозвать вершиной графа, к примеру, кортеж из нескольких элементов. Как вы будете их в строку кодировать — через запятую? Ну, это сработает, но это костыль. Медленный костыль, в силу медленных операциях над строками.
Самое простое что можно сделать для представления графа — это закодировать все вершины 32х-битными числами:
class Graph { // Здесь я для упрощения пишу public, но потом к этому будет отдельная придирка public Dictionary<int, List<int>> Edges { get; } = new(); }Почему 32 бита, а не 64? Потому что стандартные массивы в C# не могут содержать больше 231-1 элементов, и если вам когда-нибудь вдруг понадобится обрабатывать графы содержащие больше вершин — вам понадобится другой язык программирования.
Что же делать если нужно обрабатывать вершины, которые заданы не числами (а теми же строками)? Для начала, можно перекодировать их в числа:
class Graph<Vertex> { private Dictionary<Vertex, int> VertexIndices { get; } = new(); private List<Vertex> Vertices = new(); public List<List<int>> Edges { get; } = new(); public int GetVertexIndex(Vertex v) { if (VertexIndices.TryGetValue(v, out int index)) return index; int index = Vertices.Count; VertexIndices.Add(v, index); Vertices.Add(v); Edges.Add(new()); return index; } public Vertex GetVertex(int index) => Vertices[index]; }Наконец, третий способ — аксиоматический. Просто объявляем свои ожидания от графа в виде интерфейса, и пусть тот, кто использует наш алгоритм, его реализует:
interface IGraph<Vertex> { IEnumerable<Vertex> GetConnectedVertices(Vertex v); }Достоинство такого способа — в возможности работы с графом без его материализации в памяти. Иногда это важно, к примеру при работе с такими штуками как прямое произведение графов (которое тоже является графом) это поможет хранить всего 2V вершин и 2E дуг вместо V2 и E2 соответственно.
То самое прямое произведение для тех кому интересноclass GraphTensorProduct<V1, V2> : IGraph<(V1 v1, V2 v2)> { private readonly IGraph<V1> graph1; private readonly IGraph<V2> graph2; // конструктор как-нибудь сами public IEnumerable<(V1 v1, V2 v2)> GetConnectedVertices((V1 v1, V2 v2) v) => from u1 in graph1.GetConnectedVertices(v.v1) from u2 in graph2.GetConnectedVertices(v.v2) select (u1, u2); }Способы 2 и 3 можно комбинировать, требуя определённого интерфейса и предоставляя реализацию по умолчанию:
interface IGraph<Vertex> { IEnumerable<Vertex> GetConnectedVertices(Vertex v); } class Graph<Vertex> : IGraph<int> { private Dictionary<Vertex, int> VertexIndices { get; } = new(); private List<Vertex> Vertices = new(); private List<List<int>> Edges { get; } = new(); public int GetVertexIndex(Vertex v) { if (VertexIndices.TryGetValue(v, out int index)) return index; int index = Vertices.Count; VertexIndices.Add(v, index); Vertices.Add(v); Edges.Add(new()); return index; } public Vertex GetVertex(int index) => Vertices[index]; public void AddEdge(Vertex v, Vertex u) => Edges[GetVertexIndex(v)].Add(GetVertexIndex(u)); IEnumerable<int> IGraph<int>.GetConnectedVertices(int v) => Edges[v]; }
mayorovp
02.07.2022 19:08+8Теперь по поводу хранения остальных данных. Так вот: ваша ошибка в том, что вы в принципе начали их хранить!
Зачем вам в принципе класс BFS, хранящий внутреннее состояние алгоритма, когда локальные переменные работают куда лучше?
static partial class GraphExtensions { public static Vertex[] BFS<Vertex>(this IGraph<Vertex> graph, Vertex start, Vertex goal) { var queue = new Queue<Vertex>(); // или Queue<int>() для второго способа хранения var usedVertices = new HashSet<Vertex>(); // или bool[] для второго способа хранения // … return …; } }Ну куда же красивее получилось! И главное, нет такого количества нарушающих инкапсуляцию публичных свойств.
Наконец, самая важная придирка. У вас алгоритм неверный ответ выдаёт! Вы рассчитываете увидеть кратчайший путь в очереди, но в алгоритме поиска в ширину там никогда этого самого кратчайшего пути хранить не предполагалось!
Кажется, вы уже заметили что-то не так, из-за чего и добавили вот этот загадочный фрагмент кода:
if (vertite == GoalValue) { if (Queue.Count > 0) { Queue.Dequeue(); } Queue.Enqueue(node); Queue.Enqueue(GoalValue); return; }Однако, это всего лишь костыль, работающий лишь на некоторых входных данных.
На самом деле, если вы хотите получить кратчайший путь — вам надо для каждой посещённой вершины хранить не просто признак посещения, а откуда вы в неё пришли:
var queue = new Queue<Vertex>(); var usedVertices = new Dictionary<Vertex, Vertex>(); // или int[] для второго способа хранения // … var result = new List<Vertex>(); for (Vertex v = goal; v != start; v = usedVertices[v]) result.Add(v); result.Add(start); result.Reverse(); return result;Кстати, если выполнять обход графа не от start к goal, а от goal к start — при нахождении кратчайшего пути не понадобится делать Reverse.



Viceroyalty
03.07.2022 05:04+4Я понимаю что поиск в ширину это не уровень Хабра и реализован он криво, но самого-то автора зачем заминусовали?
Всё-таки это не маркетинговая шелуха, непроверенные слухи или перепост новости ещё и с кривым переводом, тут человек двигается в правильном направлении.
Поставил автору плюсик, хотя статье - минус.

playermet
03.07.2022 11:53+1Складывается впечатление, что статья получена методом генерации документации на основе бесполезных комментариев в коде. Основная тема статьи - алгоритм обхода графа. Вместо демонстрации бойлерплейта и описания порядка его добавления в код лучше было бы написать детальное объяснение самого алгоритма.

s_f1
04.07.2022 09:45Алгоритмы на графах – Sedgewick, Robert. Algorithms, Part 5: Graph Algorithms.
Хорошая книга.
lair
Так кратчайшего пути или поиска в ширину? Это два разных алгоритма.
… так какая у вас алгоритмическая сложность получилась?
mayorovp
Если у дуг/рёбер нет весов либо веса одинаковые — то поиск в ширину находит кратчайшие пути.
lair
Да я знаю, в общем-то. Но подменять одно другим без объяснений нехорошо.