
Привет, Хабр! Для машинного обучения в специфических областях очень остро стоит проблема нехватки данных для обучения. Давайте рассмотрим один из способов генерировать изображения.

Немного о задаче
В рамках проекта для УрНИИ фтизиопульмонологии по распознаванию микобактерий туберкулеза мне категорически не хватало данных, поэтому было принято решение нагенерировать датасет. Проблема в создании такого набора заключается в стоимости и временных затратах на создание одного снимка, а, следовательно, нормальный датасет вручную не создать. Для решения проблемы можно использовать модели GAN. Данная модель состоит из генератора и дискриминатора. Генератор – генерирует новые изображения, дискриминатор – определяет реальное изображение или нет. Таким образом модель обучается генерировать и классифицировать «фейки», с каждым разом генерируя изображение лучше и лучше.
Импорт необходимых библиотек:
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from tqdm import tqdm
from numpy.random import rand
import keras
from keras.optimizers import Adam
from keras.models import Model, Sequential
from keras.layers.core import Dense, Dropout
from keras import initializers
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Input
from numpy import expand_dims
from numpy import zeros
from numpy import ones
from numpy import vstack
from numpy.random import randn
from numpy.random import randint
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import BatchNormalization
from keras.layers import Reshape
from keras.layers import Flatten
from keras.layers import Conv2D
from keras.layers import Conv2DTranspose
from keras.layers import LeakyReLU
from keras.layers import Dropout
from matplotlib import pyplotНа входе имеются 64 изображения клеток легкого. На один снимок приходится 1 изображение клетки. Каждый снимок приведен к разрешению 128x128.
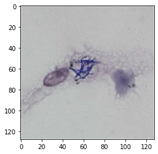
64 изображений не хватит для обучения модели. Поэтому применяю методы аугментации. К каждому изображению применялись методы поворота изображения. Помимо этого, к изображению применялся метод отражения. Поскольку каждое изображение клетки уникально, перечисленные операции не дадут негативного эффекта на качество набора данных. С каждой операцией получается новое изображение, которое нейронной сетью будет признано как уникальное распределение.
После аугментации текущий датасет составил 640 изображений. Далее изображение нормализуется, то есть запись пикселя из вида 0-255 приводится к виду -1 – 1.
По внутреннему устройству дискриминатор представляет из себя обычную сверточную сеть. В данном случае дискриминатор будет получать на вход изображения размером 128 на 128 с 3 каналами (где 128 – это высота и ширина изображения, а 3 – значения каналов RGB), т.е. (128,128,3). Далее по полученной матрице прохожу ядром свертки размером (4,4) до тех пор, пока не получу одно число – принадлежность к классу «реальные» или «фейковые» изображения.
Ниже приведен код модели дискриминатора.
def define_discriminator(in_shape=(128,128,3)):
model = Sequential()
model.add(Conv2D(128, (4,4), strides=(2,2), padding='same', input_shape=in_shape))
model.add(LeakyReLU(alpha=0.02))
# понижаем размерность 32х32
model.add(Conv2D(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.02))
# понижаем размерность 16х16
model.add(Conv2D(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.02))
# понижаем размерность 8х8
model.add(Conv2D(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.02))
# понижаем размерность 4х4
model.add(Conv2D(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.02))
# классификатор
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(1, activation='sigmoid'))
# компиляция модели
opt = Adam(learning_rate=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
return modelГенератор по своему устройству похож на дискриминатор, но работает в обратном направлении. Вместо понижения размерности матрицы и получения единственного значения на выходе, генератор преобразует входной вектор и повышает его размерность до тех пор, пока не будет достигнута необходимая размерность матрицы.
Обучение модели
На вход генератор получает случайную выборку из пространства скрытых переменных, напоминающих данные в обучающем наборе. В данном случае это случайный вектор размером 1024х4х4 на входе и матрицей 128х128х3 на выходе. Генератор включает в себя 5 скрытых слоев для преобразования входного вектора в матрицу 4х4 и дальнейшего повышения размерности матрицы и выходной слой с изображением (128,128,3).
Для обучения модели используется следующая функция:
def train_new(g_model, d_model, gan_model, dataset, latent_dim, n_epochs=20000, n_batch=256):
bat_per_epo = int(dataset.shape[0] / n_batch)
half_batch = int(n_batch / 2)
# проходимя по эпохам
for i in range(n_epochs):
# проходимся батчами по датасету
for j in range(bat_per_epo):
# выбираем случайным образом реальные изображения
X_real, y_real = generate_real_samples(dataset, half_batch)
# обновляем веса дискриминатора
d_loss1, _ = d_model.train_on_batch(X_real, y_real)
# создаем «искусственные» изображения
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# обновляем веса генератора
d_loss2, _ = d_model.train_on_batch(X_fake, y_fake)
# подготавливаем вектор для входа генератора
X_gan = generate_latent_points(latent_dim, n_batch)
# говорим, что все «искусственные» изображения реальны
y_gan = ones((n_batch, 1))
# обновляем веса генератора при помощи ошибки дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# выводим результаты функции потерь
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %
(i+1, j+1, bat_per_epo, d_loss1, d_loss2, g_loss))В качестве аргументов функция для обучения будет принимать модель генератора, модель дискриминатора, модель GAN, набор изображений клеток, случайный вектор, количество эпох обучения и размер батча.
Эпохой называют прохождение всего датасета через нейронную сеть один раз. Так как одного прохода для обучения недостаточно, необходимо использовать несколько итераций. Весь датасет нельзя пропустить через нейронную сеть, так как он слишком велик для нее. Поэтому весь набор данных делится на части или батчи. Размер батча в данном случает составляет 256, а число батчей равно 2. Число батчей определяет, сколько будет итераций в одной эпохе.
Внутри функции реализован обучающий цикл, в котором модели обрабатывают входные изображения, с дальнейшим обновлением весов, с целью минимизации функции потерь.
Перед началом обучения необходимо настроить параметры, которые будут использоваться в процессе обучения. Создаем переменные, которые будут хранить в себе количество батчей на одну эпоху и размер половины батча. Значение половины батча необходимо, так как берется половина реальных данных и половина сгенерированных моделью. Данная процедура выполняется для одинакового количества классов в обучающей выборке.
Из набора данных случайным образом достается 128 изображений, половина батча. Считается ошибка дискриминатора на реальных данных.
Создаем с помощью генератора 128 изображений и передаем их в дискриминатор. Необходимо, чтобы все изображения на выходе из генератора определялись дискриминатором как реальные, поэтому вручную задаем для них класс 1, то есть «реальные», для подсчета значения функции потерь. Далее классифицируем сгенерированные изображения дискриминатором. Теперь можно сравнить классы, проставленные дискриминатором, и классы, которые были проставлены вручную. Все случаи, где классы будут различаться, и будет ошибкой. Далее происходит обновление весов моделей при помощи метода train_on_batch. При помощи оптимизатора и функции потерь по частной производной находится направление для изменения весов, с целью уменьшения функции потерь. Веса изменяются согласно значению, установленному в параметре learning_rate.
Данный цикл будет выполняться до тех пор, пока не достигнет установленного значения (20 000), либо не будет прерван пользователем.
Результат
Для отслеживания процесса обучения на каждой итерации в консольную строку выводятся значения функции потерь для текущей эпохи. Каждые 100 итераций происходит сохранение текущего результата в виде графика с n-ым количеством изображений, а также выводятся значения метрики accuracy.

На изображении примеры сгенерированных моделью данных после 5 000 эпох. Низкое качество обусловлено некорректным подходом к аугментации и недостаточным количеством эпох.
В заключении можно сказать, что подход к генерации синтетических данных с использованием GAN полностью заслуживает право на существование. Для улучшения результата для аугментации изображений стоит применять поворот не только на градус кратный 90, но и на другие случайные углы. В таком случае, распределения получатся более разнообразными.
Полный код работы можно найти по ссылке здесь.
Для воспроизведения результатов можно использовать датасет MNIST.
Комментарии (2)
Goupil
08.07.2022 13:33+1В статье так и не сказано, насколько сгенерированные изображения помогли при обучении на недостаточном количестве данных.
Я баловался с GANами по своей тематике. Сложилось впечатление что из малого набора тренировочных данных они не могут научиться синтезировать достаточно адекватные изображения, хотя что-то угадывается. Чудес не бывает.
datacompboy
И в итоге модель научится определять туберкулёз у роботов...