

Недавно у меня появилась задача по снижению аллокации в очень горячем месте кода. Там происходит тривиальное: запускаются Task'и в которых заранее известным набором handler'ов обрабатываются объекты. Вооружившись профайлером, я с удивлением обнаружил, что много памяти (и много времени GC) затрачивается на удаление объектов-замыканий.
Что такое замыкание в C#?
Замыкания (closure) это очень крутая штука, которая помогает писать более лаконичный код на C#. Под капотом, замыкание это более-менее обычный класс, который "захватывает" ссылки на переменные, которые участвуют в замыкании.
Думаю вы видели, как многие IDE честно подсказывают, что в месте использования замыкания возникает захват переменных:

Что же происходит "под капотом"? В этом же классе создаётся класс, который представляет из себя то самое замыкание. Класс специально называется хитрым образом (в моём случае он называется DisplayClass4_0) и помечается атрибутом CompilerGenerated.
В специальном классе создаётся набор полей по количеству переменных, захватываемых замыканием. Также, создаётся метод, ссылка на который передаётся в метод Task.Run.
В декомпилированном коде (я использую dotPeek) это выглядит примерно вот так:

Почему происходит именно так? Потому что "замыкание" это не механизм платформы .NET, а языка C#. Если угодно, это синтаксический сахар, который делает язык красивым и выразительным. Однако, на более низком уровне, любой синтаксический сахар требует низкоуровневой реализации - и это она и есть. Подробнее о замыканиях написал Сергей Тепляков и никому не известный Стефан Тауб. У их написано много, объясняется сравнительно легко, в том числе затрагиваются особенности работы с замыканиями.
Аллокация при замыкании
Можно заметить, что при каждом замыкании "под капотом" создаётся инстанс класса замыкания, в его поля помещаются захватываемые значения, а в нужный нам метод передаётся ссылка на метод closure-класса, где и происходит выполнение логики, указанной в замыкании. Напомню, что инстанс класса размещается в куче, откуда его потом удалит GC.
Кажется, что это совсем не страшно, так как речь в подавляющем большинстве случаев идёт о помещении инстанса в Gen0, откуда он будет быстро удалён. Более того, сам класс замыкания предельно лёгкий и не занимает много места.
Однако, если место использования замыкания горячее (часто вызывается), то GC может не успеть удалить инстансы closure-класса. При самых печальных сценариях, это может привести к "выживанию" классов вплоть до Gen2, с последующим stop the world для проведения вдумчивой очистки кучи.
Более того, не надо забывать, что не все имплементации платформы работают одинаково. Например, игровой движок Unity имеет особенный GC с одним поколением. Это требует от разработчиков очень внимательно относиться к тому, кто и что аллоцирует и в каких количествах.
Имплементация собственного замыкания
Чтобы снизить нагрузку на GC, в некоторых сценариях можно попытаться написать собственную имплементацию замыкания. Кажется, что это просто, так как мы знаем как работает closure.
private sealed class Closure<T> {
private readonly Action<T> _action;
private readonly Action _closure;
private T _value;
public Closure(Action<T> action) {
_action = action;
_closure = Execute;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void Clear() => _value = default;
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public Action Prepare(T value) {
_value = value;
return _closure;
}
private void Execute() => _action(_value);
}Если мы знаем количество вызовов этого класса, то мы можем запросто преаллоцировать все замыкания. При использовании мы просто записываем значение аргумента в поле класса (точно также, как сделали бы за нас "под капотом "), а в качестве метода используем заранее созданную ссылку на метод этого же класса.
for (var i = 0; i < _objects.Length; i++) {
_tasks[i] = Task.Run(_closures[i].Prepare(in _objects[i]))
}
Task.WaitAll(_tasks);
foreach (var closure in _closures) {
closure.Clear();
}При использовании собственного класса-замыкания при декомпиляции кода мы можем наблюдать более понятную картину без "магии под капотом". Бонусом, мы избавились от создания new Action при передачи ссылки на метод замыкания в нужный нам метод.

Минус подобного использования - инстанс класса замыкания нужно очищать от значения, которое в него было передано ранее. Сделать это необходимо, поскольку это место становится местом потенциальной утечки памяти, так как замыкание будет хранить ссылку на "захваченное" значение вечно.
Ещё один минус - многопоточность. При использовании собственной имплементации замыкания нужно следить за тем, чтобы переданные в замыкание значения были атомарны для каждого из потоков. Как это сделать красиво и без особых сложностей - совершенно другой вопрос.
Уменьшение аллокации при замыкании
Какие же конкретные числа мы можем получить при замене стандартного механизма замыкания на собственный велосипед? Были произведены замеры с использованием известного фреймворка для микробенчмаркинга BenchmarkDotNet. Код бенчмарка находится тут.
Method |
Runtime |
Mean |
Ratio |
Gen 0 |
Gen 1 |
Gen 2 |
Allocated |
|---|---|---|---|---|---|---|---|
AutoClosure |
.NET 6.0 |
6.131 ms |
1.00 |
203.1250 |
- |
- |
1,711 KB |
ParallelFor |
.NET 6.0 |
1.850 ms |
0.30 |
265.6250 |
- |
- |
2,158 KB |
ParallelForeach |
.NET 6.0 |
1.916 ms |
0.31 |
271.4844 |
- |
- |
2,221 KB |
SelfClosure |
.NET 6.0 |
5.883 ms |
0.96 |
93.7500 |
- |
- |
774 KB |
AutoClosure |
.NET Core 3.1 |
6.727 ms |
1.00 |
203.1250 |
- |
- |
1,713 KB |
ParallelFor |
.NET Core 3.1 |
1.925 ms |
0.29 |
257.8125 |
- |
- |
2,108 KB |
ParallelForeach |
.NET Core 3.1 |
2.015 ms |
0.30 |
265.6250 |
- |
- |
2,182 KB |
SelfClosure |
.NET Core 3.1 |
6.880 ms |
1.02 |
93.7500 |
- |
- |
773 KB |
AutoClosure |
.NET Framework 4.6.1 |
8.776 ms |
1.00 |
296.8750 |
46.8750 |
15.6250 |
1,890 KB |
ParallelFor |
.NET Framework 4.6.1 |
1.726 ms |
0.20 |
208.9844 |
9.7656 |
1.9531 |
1,290 KB |
ParallelForeach |
.NET Framework 4.6.1 |
1.861 ms |
0.21 |
216.7969 |
9.7656 |
1.9531 |
1,345 KB |
SelfClosure |
.NET Framework 4.6.1 |
8.380 ms |
0.95 |
140.6250 |
15.6250 |
- |
954 KB |
Приятно, что скорость осталась примерно прежней. Это говорит о том, что сделано более менее правильно.
Столбец "Allocated" бодро рапортует нам о том, что аллокация меньше почти в два раза. Но, собственно, почему же она есть? Если вы посмотрите код бенчмарка, то вы заметите, что я пытаюсь минимизировать аллокацию при запуске Task'ов. Это достаточно распространенный случай использования замыкания. Цифры, которые можно увидеть в столбце Allocated включают в себя затраты платформы на создание Task'ов.
Parallel.For и Parallel.ForEach
В бенчмарке, также, можно найти результаты для Parallel.For и Parallel.ForEach. Их использование значительно повышает скорость работы и, к сожалению, существенно увеличивают аллокацию. Дьявол кроется в деталях: Parallel.ForEach принимает в качестве аргумента IEnumerable<T>, который возвращает IEnumerator<T>. Это объект, который будет расположен в куче, а значит будет нагружать GC. Ну а Parallel.For принимает делегат, где снова создаётся объект-замыкания, что также влияет на аллокацию. Спасибо комментатору @Deosis.
И снова дьявол кроется в деталях. При увеличении количества заданий (изначально их было 10) начинает стремительно выигрывать имплементация на Parallel.For и Parallel.ForEach. Во-первых, она просто быстрая, а во-вторых, создание enumerator'a и аллокация замыкания - это фиксированная плата, никак не зависящая от количества. Бенчмарк это явно показывает. Спасибо @soalexmn. В его комментарии количество заданий увеличено до 400 и цифры там совсем драматичные.
Method |
Runtime |
Tasks |
Mean |
Ratio |
Gen 0 |
Gen 1 |
Gen 2 |
Allocated |
|---|---|---|---|---|---|---|---|---|
AutoClosure |
.NET 6.0 |
10 |
6.252 ms |
1.00 |
203.1250 |
- |
- |
1,709 KB |
ParallelFor |
.NET 6.0 |
10 |
1.891 ms |
0.30 |
263.6719 |
- |
- |
2,154 KB |
ParallelForeach |
.NET 6.0 |
10 |
1.909 ms |
0.31 |
269.5313 |
- |
- |
2,220 KB |
SelfClosure |
.NET 6.0 |
10 |
5.747 ms |
0.88 |
93.7500 |
- |
- |
773 KB |
AutoClosure |
.NET Core 3.1 |
10 |
6.706 ms |
1.00 |
203.1250 |
- |
- |
1,710 KB |
ParallelFor |
.NET Core 3.1 |
10 |
1.900 ms |
0.28 |
259.7656 |
- |
- |
2,115 KB |
ParallelForeach |
.NET Core 3.1 |
10 |
2.016 ms |
0.30 |
265.6250 |
- |
- |
2,190 KB |
SelfClosure |
.NET Core 3.1 |
10 |
6.740 ms |
1.01 |
93.7500 |
- |
- |
774 KB |
AutoClosure |
.NET Framework 4.6.1 |
10 |
8.514 ms |
1.00 |
296.8750 |
46.8750 |
15.6250 |
1,896 KB |
ParallelFor |
.NET Framework 4.6.1 |
10 |
1.667 ms |
0.20 |
208.9844 |
13.6719 |
1.9531 |
1,292 KB |
ParallelForeach |
.NET Framework 4.6.1 |
10 |
1.768 ms |
0.21 |
216.7969 |
9.7656 |
1.9531 |
1,344 KB |
SelfClosure |
.NET Framework 4.6.1 |
10 |
8.455 ms |
0.99 |
140.6250 |
15.6250 |
- |
950 KB |
AutoClosure |
.NET 6.0 |
100 |
65.939 ms |
1.00 |
2000.0000 |
- |
- |
16,368 KB |
ParallelFor |
.NET 6.0 |
100 |
3.455 ms |
0.05 |
347.6563 |
- |
- |
2,831 KB |
ParallelForeach |
.NET 6.0 |
100 |
4.040 ms |
0.06 |
367.1875 |
- |
- |
2,975 KB |
SelfClosure |
.NET 6.0 |
100 |
60.615 ms |
0.92 |
750.0000 |
- |
- |
6,982 KB |
AutoClosure |
.NET Core 3.1 |
100 |
68.076 ms |
1.00 |
2000.0000 |
- |
- |
16,370 KB |
ParallelFor |
.NET Core 3.1 |
100 |
3.467 ms |
0.05 |
335.9375 |
- |
- |
2,726 KB |
ParallelForeach |
.NET Core 3.1 |
100 |
3.796 ms |
0.06 |
351.5625 |
- |
- |
2,845 KB |
SelfClosure |
.NET Core 3.1 |
100 |
69.871 ms |
1.03 |
750.0000 |
- |
- |
6,980 KB |
AutoClosure |
.NET Framework 4.6.1 |
100 |
78.586 ms |
1.00 |
2857.1429 |
571.4286 |
142.8571 |
18,094 KB |
ParallelFor |
.NET Framework 4.6.1 |
100 |
3.343 ms |
0.04 |
289.0625 |
3.9063 |
- |
1,788 KB |
ParallelForeach |
.NET Framework 4.6.1 |
100 |
4.095 ms |
0.05 |
304.6875 |
7.8125 |
- |
1,912 KB |
SelfClosure |
.NET Framework 4.6.1 |
100 |
78.101 ms |
0.99 |
1285.7143 |
142.8571 |
- |
8,685 KB |
P.S.: Начал писать в телегу и, внезапно, Дзен. Заглядывайте, если интересно.
Комментарии (21)

navferty
19.07.2022 22:46+2Класс специально называется хитрым образом (в моём случае он называется
DisplayClass4_0)Надо заметить, что название класса
<>DisplayClass4_0, и эти две угловые скобки в начале имени дают гарантию, что в пользовательском коде на языке C# точно не будет коллизий с таким сгенерированным классом.
teoadal Автор
19.07.2022 22:56+2Да, вы правы.
Я объяснюсь. При написании статьи бывает чертовски сложно балансировать на определённом уровне знаний, которые, волей-неволей, предъявляются к читателю. Детальное разжевывание мелочей имплементации захламляет статью и отпугивает знатоков. Увы, это и не привлекает людей уровня junior, так как для них это просто не интересно. У них задача "сделать", а не "понятно как сделать, но нужно, чтобы работало быстрее".

Deosis
20.07.2022 07:24+1В данном случае стоит протестировать также метод Parallel.For, так как он специально сделан для параллельной обработки массивов.
teoadal Автор
20.07.2022 10:39Очень хороший вопрос, который я забыл осветить в статье!
Действительно, использование Parallel.For и Parallel.Foreach значительно повышает скорость работы. Однако, к сожалению, их использование существенно увеличивают аллокацию (почти в три раза выше на .NET 6):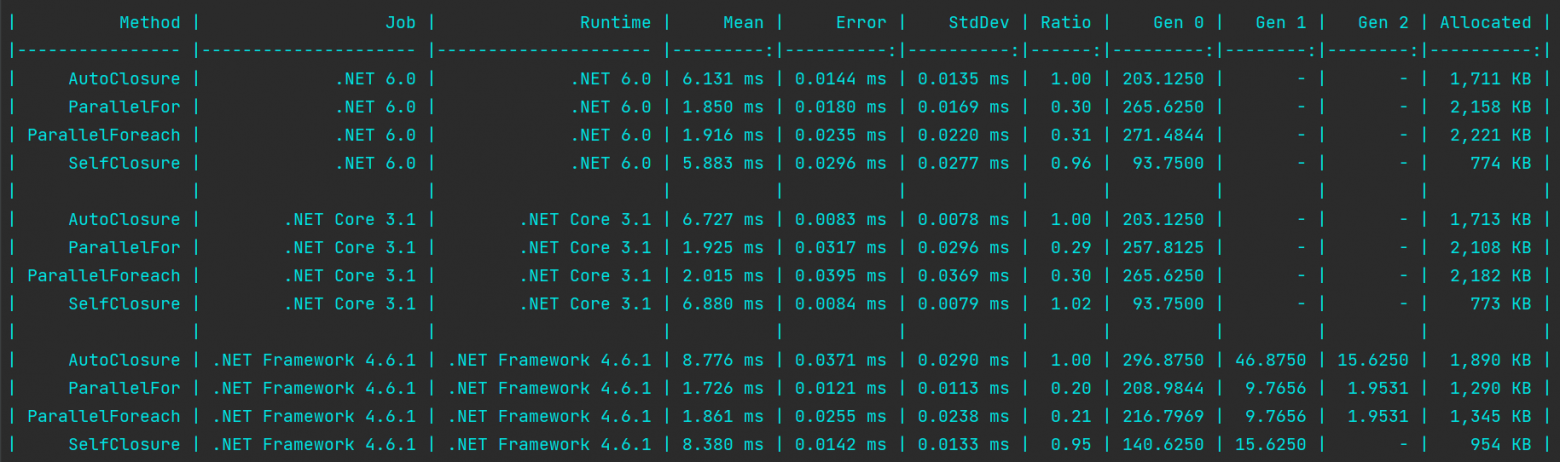
Дьявол, к сожалению, кроется в деталях. Parallel.Foreach принимает в качестве аргумента IEnumerable<T>, который возвращает IEnumerator<T>. Объект, который будет расположен в куче. Parallel.For снова создаёт то самое замыкание, что также влияет на аллокацию.
Deosis
20.07.2022 11:29У вас в тестах для SelfClosure память выделяется заранее до теста, так что сравнение неспортивное.
teoadal Автор
20.07.2022 11:55Во-первых, потому что я могу это сделать и это действительно будет работать именно так. В реальном приложении я, опуская детали, точно также беру заранее подготовленный набор замыканий через
Interlocked.Exchange. Если он null, я создаю новый массив с замыканиями. После использования, я кладу массив обратно. Короче говоря, в самом плохом сценарии получаю плюс-минус тот же результат, что и в AutoClosure.
Во-вторых, а зачем, собственно, мне создавать массив с замыканиями на каждый запрос? Зачем мне вообще создавать объект замыканий, если я могу их предсоздать и запулить. Если бы я назвал это Pool, было бы проще? Воспринимайте это как пул замыканий (а-ля вот так), сильно упрощённый для теста.
В-третьих, для Parallel.ForEach я тоже заранее создаю набор "замыканий". От этого ничего не меняется.

soalexmn
20.07.2022 12:35+2Лучшее решение все-таки Parallel.For/Parallel.ForEach так как никаких замыканий практически не создается.
2-3КБ которые аллоцируются на Parallel - это внутренние таски/структуры, необходимые для метода. Например, в вашем тесте можно поменять количество хэндлеров-заданий с 10 на 400 и получить уже совсем другую картину:
| Method | Mean | Error | StdDev | Median | Ratio | RatioSD | Gen 0 | Gen 1 | Allocated | |---------------- |-----------:|----------:|-----------:|-----------:|------:|--------:|-----------:|---------:|----------:| | AutoClosure | 132.774 ms | 9.6346 ms | 28.4079 ms | 137.038 ms | 1.00 | 0.00 | 10500.0000 | 750.0000 | 64 MB | | ParallelFor | 7.057 ms | 0.1364 ms | 0.1912 ms | 7.142 ms | 0.07 | 0.01 | 421.8750 | - | 3 MB | | ParallelForeach | 7.415 ms | 0.0224 ms | 0.0209 ms | 7.418 ms | 0.08 | 0.01 | 453.1250 | - | 3 MB | | SelfClosure | 102.784 ms | 2.4890 ms | 7.2998 ms | 105.092 ms | 0.81 | 0.19 | 4500.0000 | 333.3333 | 27 MB |Кстати, перфоманс AutoClosure/SelfClosure такой низкий из-за слишком маленьких заданий - рантайм тратит больше времени на шедулинг чем на сами задания, где-то был доклад или статья по этому поводу.
teoadal Автор
20.07.2022 12:59О, спасибо большое! Я обязательно добавлю это в статью и доработаю бенчмарк. Но я всё ещё рад, что SelfClosure обходит AutoClosure по аллокации)
Вот за это я люблю Хабр! Комменты от профессионального сообщества всегда интереснее и полезнее, чем на всяких других площадках.


Aquahawk
20.07.2022 09:16+1Только не при каждом вызове, в при каждом создании замыкания. При выхове ничего не аллоцируется.

astec
20.07.2022 11:02Вот так не будет проще/быстрее?
var j = i;
_tasks[j] = Task.Run(() => _handlers[j].Handle(_objects[j]));



gdt
20.07.2022 12:06Может быть, в таком случае есть смысл сделать какую-то свою очередь/пул задач? Ну то есть, у вас под капотом условно крутится N тасок или потоков, которые из условного ConcurrentDictionary выгребают Action<T> action и T obj, и делают action(obj), а вы у себя в коде делаете что-то типа pool.FireAndForget(handler, obj), который их туда складывает? Всё равно ваш obj будет копироваться в замыкание, так что потерь точно быть не должно :)
Также, не пробовали ридонли структуры для своих замыканий? Если там не сотни тысяч одновременно, теоретически может помочь (как минимум, есть смысл замерить).
teoadal Автор
20.07.2022 12:28Может быть, в таком случае есть смысл сделать какую-то свою очередь/пул задач
Вы прям описали одну известную библиотеку для background-обработки задач. Для случаев "fire and forget" она подходит идеально и построена примерно так, как вы написали.
В моём случае понадобилось небольшое вкрапление (микрооптимизация) в горячем месте кода. Что-то вроде вот такого, что я писал для Mediator (использовать в продакшене не рекомендую!).Также, не пробовали ридонли структуры для своих замыканий?
В них же нужно запихивать значение. Либо пересоздавать всю структуру каждый раз, при каждом вызове. Если будет время, то попробую, спасибо.

DriverEntry
20.07.2022 13:07+3Вообще без замыканий тоже достаточно удобно и лаконично.
void DoWork(object p) { }...Task.Factory.StartNew(DoWork, objects[i], CancellationToken.None, TaskCreationOptions.DenyChildAttach, TaskScheduler.Default);teoadal Автор
20.07.2022 14:35Да, всё верно. Можно и так.
Только, во-первых, надо использовать не DoWork, а сделать переменную и туда положить DoWork, иначе будет аллокация, о чём честно предупреждает Rider.
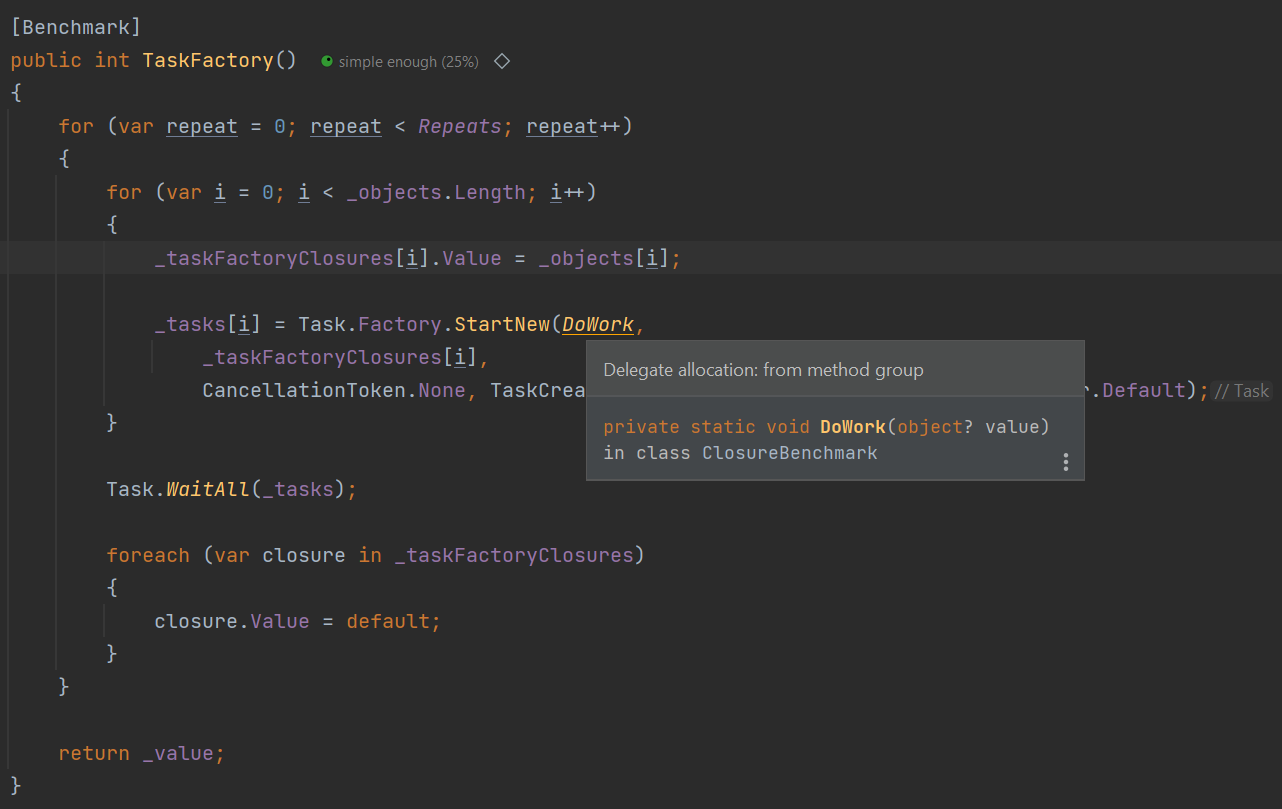
Во-вторых, необходимо всё-таки выполнить условия задачи, совместив объект данных с handler'ом. Для этого я обновил бенчмарк и сделал объект TaskFactoryClosure. Я понимаю, что из этого синтетического теста не очень понятно, что надо совместить данные + обработчик, но представим себе, что они у вас разные и формируются по разному под данные. Из теста это исключено, чтобы не замерять бизнес-логику и сконцентрироваться на аллокации. Статья-то про это)
Ну и вот результаты: плюс-минус аналогичные SelfClosure. Круто!

epeshk
20.07.2022 16:01Только, во-первых, надо использовать не DoWork, а сделать переменную и туда положить DoWork, иначе будет аллокация, о чём честно предупреждает Rider
В будущих версиях языка (начиная с C# 11) это будет не нужно
https://docs.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-11#improved-method-group-conversion-to-delegate


tbl
Здесь жесть конечно. Объект иммутабельный же (только параметризация вызова отличается). Здесь можно выполнить прямые инлайны и оптимизацию по месту при кодогенерации в JIT без всяких созданий управляемых объектов на куче, а просто на стеке. В java 11+ смогли такое для случаев, когда при кодогенерации в инлайне доступно тело лямбды. А с легковесными виртуальными потоками, которые приедут в Java 19, это будет доступно и для межпоточного взаимодействия.
teoadal Автор
Да, к сожалению, вот так. Я не знаю о чем думали создатели этого механизма и может быть есть более оптимальный способ (знатоки подскажут)... но я использовал наиболее простой и самый распространенный способ создания Task'a. Возможно, была надежда на то, что получится короткоживущий объект и он будет удалён из кучи почти сразу. Но это, к сожалению, не так и бенчмарк это подтверждает - "объекты замыкания" существуют в Gen2.
tbl
Ну, когда в java 8 вводили лямбды (один из видов замыканий), то планировали, что в будущем в JVM не будет лишних созданий объектов на уровне оптимизированной компиляции байткода там, где это возможно. И в следующем релизе JVM это подогнали (java 11). Странно, что в экосистеме .net языки следуют на 2-3 (а то и больше) поколений впереди VM. Такое ощущение, что виртуальная машина не развивается.
lair
В общем случае замыкание в C# не иммутабельно.
Типичный пример: