

В модном и молодежном учебнике электроники от Харрисов есть пример простого конечного автомата - "улыбащейся улитки". Я решил наглядно показать, как можно в домашних условиях реализовать улитку на трех технологиях:
Микросхемы малой степени интеграции CMOS 4000. Первая массовая КМОП-серия, выпущенная в 1968 году. 20 микрон то бишь 20 тысяч нанометров. На таких микросхемах учились электронике бумеры, то бишь люди, родившиеся во время бэби-бума 1950-х годов и вошедшие в технологию в начале 1970-х. В том числе Стив Джобс и Стив Возняк.
Микросхемы программируемой логики Altera Cyclone IV, ныне Intel FPGA Cyclone IV. 2009 год, 60 нанометров. Интеловская микросхема, в которой вообще нет никакого процессора, только набор логических ячеек, между которыми можно программировать соединения. Удобна как тренажер для будущих проектировщиков микропроцессоров, так как для построения схемы внутри FPGA не нужно делать заказ на фабрике.
ASIC-технологии фабрики Skywater - лидера американского импортозамещения. 2019 год, 130 нанометров. На своем вебсайте компания пишет что они единственная в США контрактная фабрика микросхем, у которой нет инвесторов-иностранцев: "SkyWater is the only US-investor owned pure-play semiconductor and technology foundry". Поэтому в них инвестировал 10 миллиардов рублей Пентагон.
На работе у меня есть доступ и к технологии 3 нанометра, но показать ее вам на Хабре не могу, поэтому прошу вас поверить мне на слово, что и на 3 нанометра "улыбающаяся улитка" работает. Кстати, все это будет на семинаре в Бишкеке на следущей неделе. Итак:
Сначала условие задачи в Харрис & Харрис:

Диаграммы переходов между состояниями двух вариантов конечного автомата:
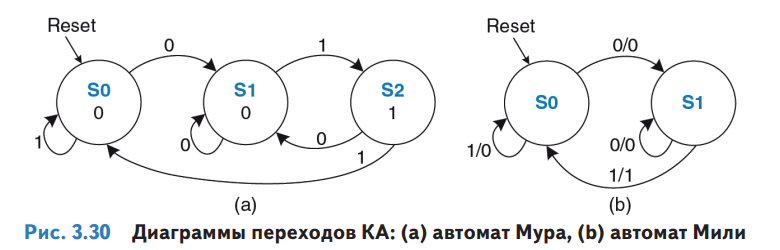
Если порисовать ручкой на бумаге карты Карно, из диаграмм выше можно построить схемы с логическими элементами И и НЕ и сохранением состояния в D-триггерах. Для схемы слева нужно два D-триггера (два бита состояния для трех состояний - 00, 01, 02), для схемы справа достаточно одного бита состояния:
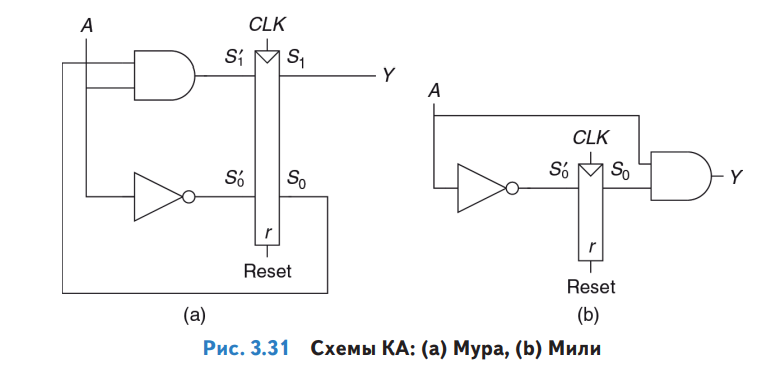
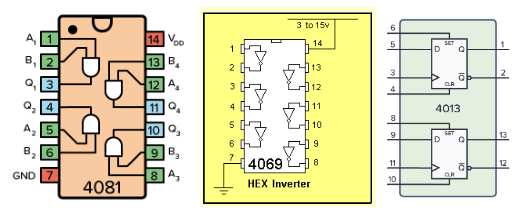
Теперь берем микросхемы CMOS 4081 (4 элемента И), 4069 (6 элементов НЕ) и 4013 (два D-триггера), втыкаем их в макетную плату снизу, соединяем ножки проводами - и конечный автомат готов. Для наглядности добавляем лампочек и кнопочек, к которым приклепляем дюжину резисторов чтобы ничего не перегорело и не подвисало (это не сложнее чем вязать шарфики крючком).

Вот как микросхемы 4081, 4069 и 4013 выглядят внутри:
Макетная плата сверху - это не часть конечного автомата. Слева на ней находится генератор тактовой частоты, справа - сдвиговый регистр, чисто для наглядности, чтобы видеть, какие мы скармливаем конечному автомату последовательности нулей и единиц. Все это работает вот как:
Теперь переносимся в 21 век и скачиваем с вебсайта Интела программное обеспечение Quartus Prime Lite Edition 21-1-1 (причем важно скачать именно Lite, а не Pro, если вы не собираетесь подарить Интелу 5 тысяч долларов). Для Windows или для Linux. Когда вы запускаете Quartus в первый раз, также важно сказать "Run" здесь, то бишь запустить бесплатную версию. Иначе может быть возня с переключением ее с лицензируемой на бесплатную:

Теперь вы можете скачать с гитхаба пакет с упражениями для семинара в Бишкеке, раззиповать его в любой директории, найти файл проекта day_3/lab_8_snail_fsm/top.qpf, и открыть его в квартусе с помощью меню "File | Open Project", который все время путают с "File | Open". Дальше нужно дважды кликнуть на Compile Design и через пару минут вы увидите следующее:
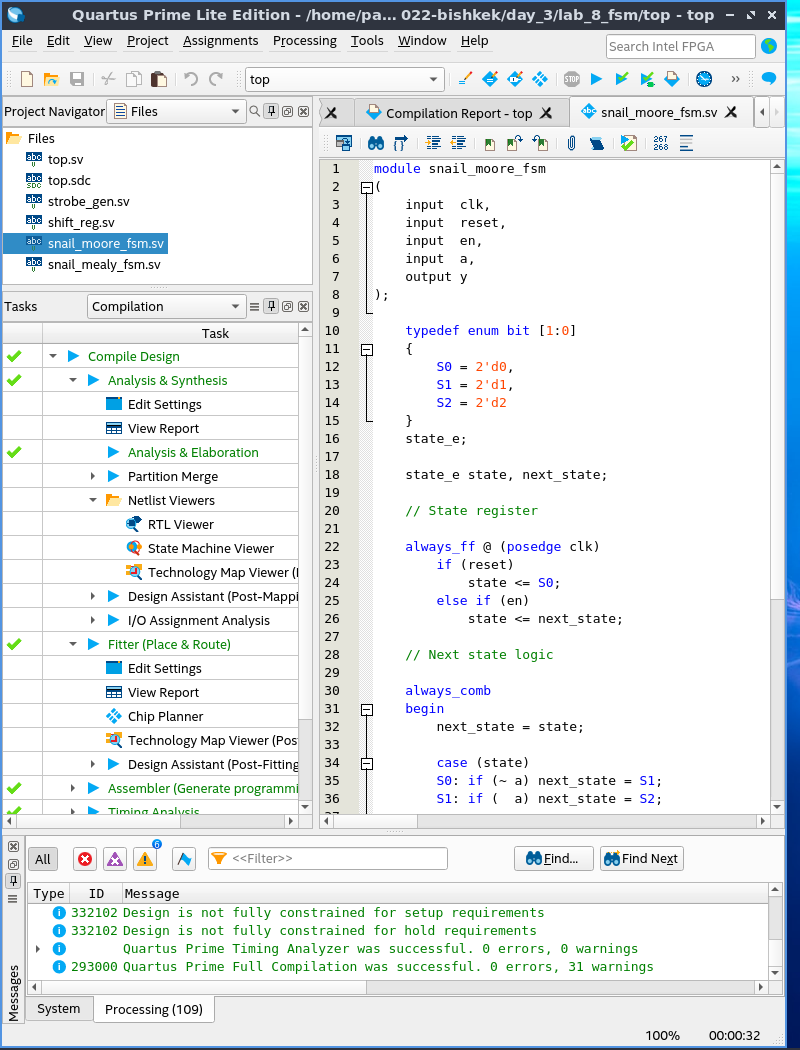
Если кликнуть в разные меню, вы увидите, как код на языке описания аппаратуры Verilog превратился в схему и как Quartus распознал состояния конечного автомата (он правда добавил в диаграмму сброс, но это нюансы):
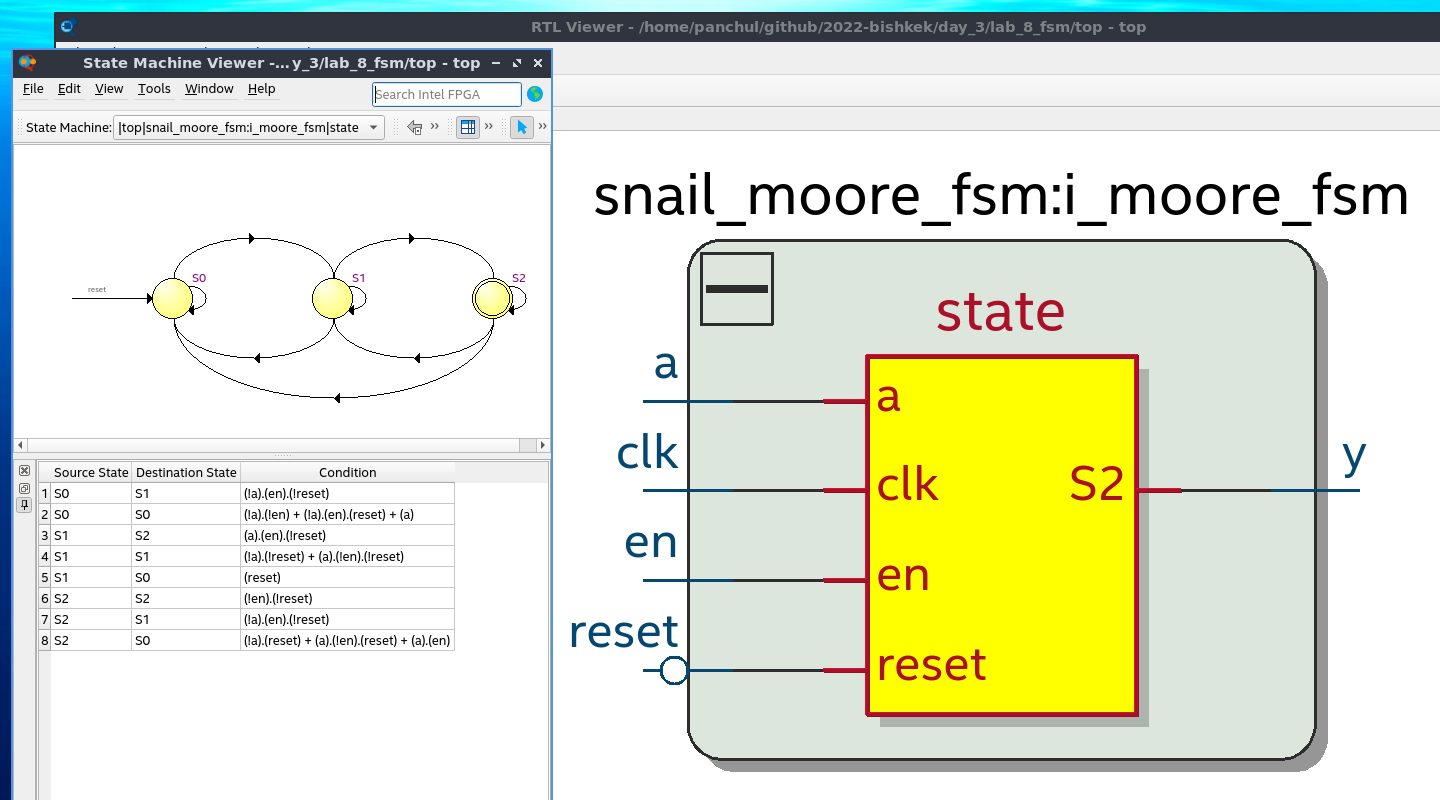
В другом меню вы можете увидеть как схема отобразилась на ячейки ПЛИС-а / FPGA. Она все еще представлена в виде графа:.

А вот граф размещен внутри микросхемы. Логические функции ячеек изменяются с помощью мультиплексоров, подсоединенных к битам программируемой пользователем памяти, отсюда сокращение ПЛИС - "Программируемые Логические Интегральные схемы", или ППВМ - "Программируемые Пользователем Вентильные Матрицы":
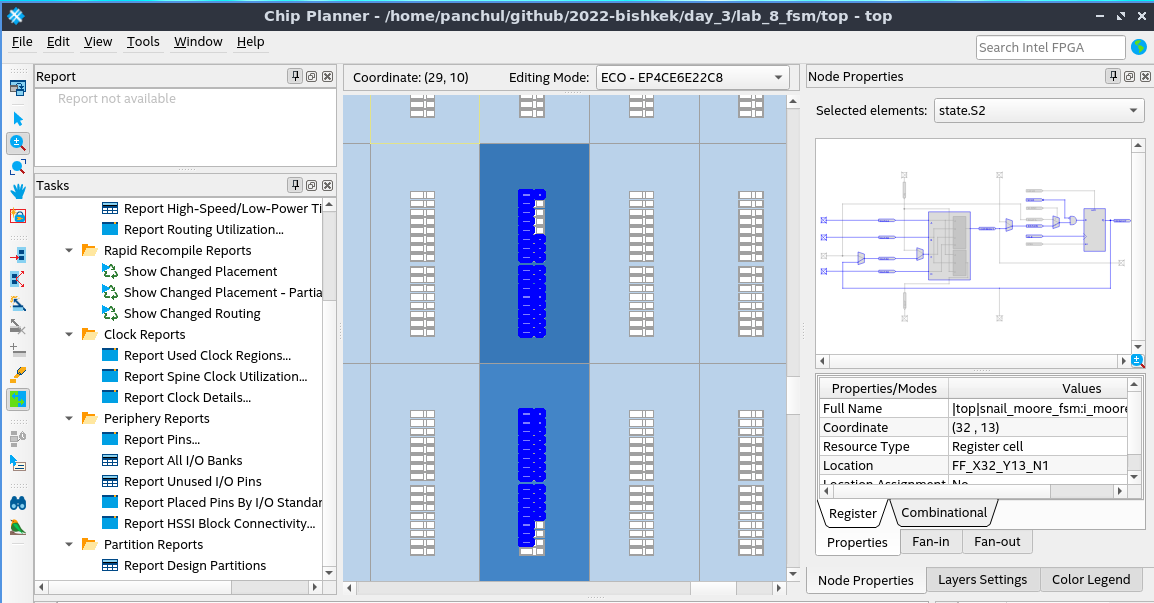
Заливаем это в микросхему на плате и вот как она работает вживую:
Теперь перейдем к фиксированным микросхемам, которые выпускаются на фабрике. Вот так выглядит фабрика Skywater:

Фабрика дает проектировщикам так называемую ASIC standard cell library - библиотеку ячеек, которые фабрика может произвести, построить рядами на силиконе и соединить дорожками из меди. Примитивы функционально похожи на то, что мы видели в CMOS 4000: логические элементы И, ИЛИ, НЕ, их простые комбинации, мультиплексоры, простейшие сумматоры сумматоры и разнообразные D-триггеры - с синхронным или асинхронным сбросом, разрешением итд.
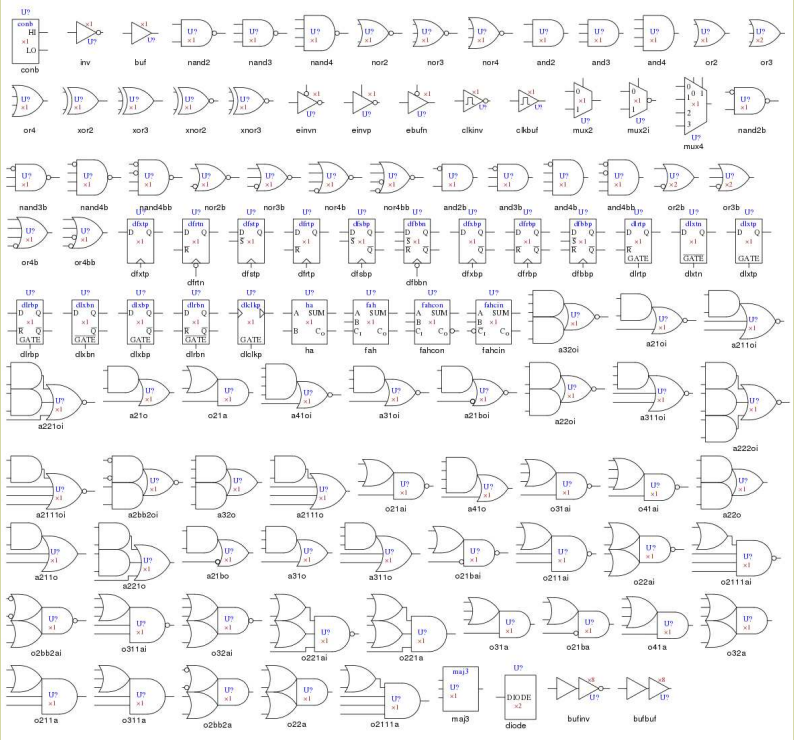
.

Физически ячейка выглядит как несколько слоев кремния с примесями бора и фосфора. Про каждую ячейку известны ее физические параметры - задержки в пикосекундах при разных условиях, размер, параметры энергопотребления - все это учитывает софт, который превращает код на верилоге в GDSII файл, который отправляется на фабрику, чтобы по нему сделать набор фотошаблонов для печати микросхем.
Skywater скооперировалась не только с Пентагоном для его радиационно-устойчивых нужд, но и с компанией Гугл, которая спонсирует молодых гениев, решивших спроектировать свои микросхемы с помощью вышедшего года три назад набора открытых средств проектирования под названием OpenLane. Превращение кода на верилоге в фотошаблон с помощью OpenLane выглядит так:
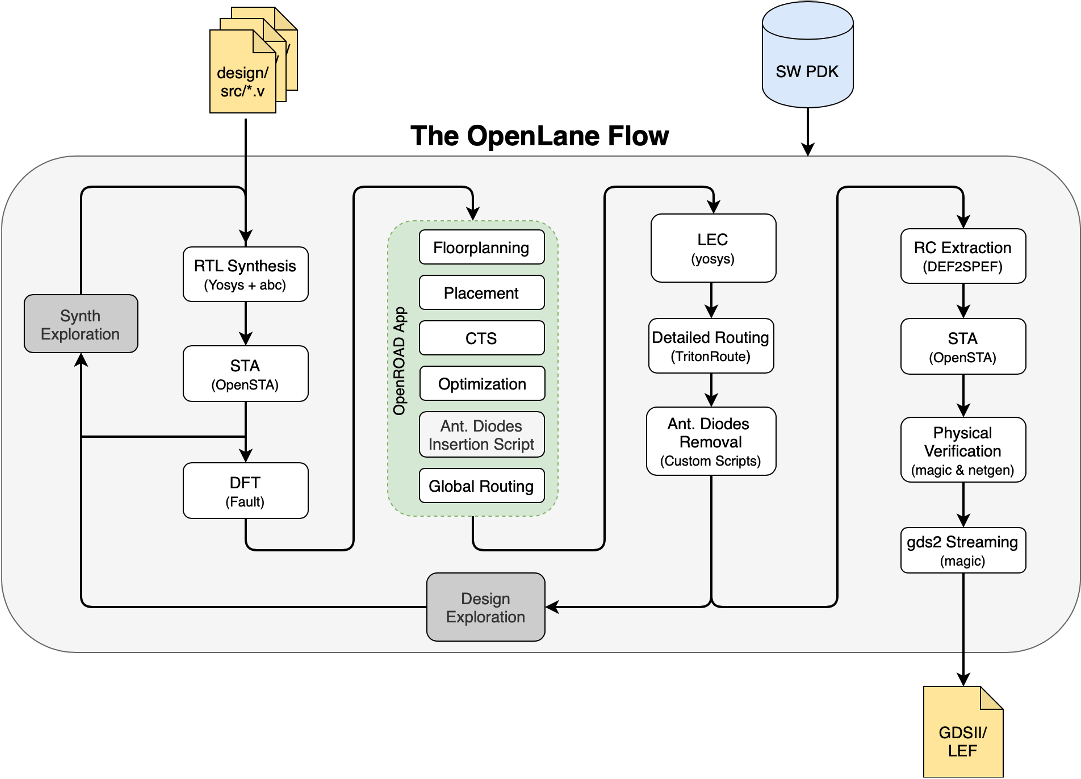
Я установил OpenLane на компьютере с Lubuntu 22.04 LTS по инструкции с гитхаба.
Сначала устанавливаются пререквизиты:
sudo apt install -y build-essential python3 python3-venv python3-pipПотом устанавливается Докер:
sudo apt-get remove docker docker-engine docker.io containerd runc
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg
| sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu
\
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
apt-cache madison docker-ce
sudo apt-get install docker-ce=5:20.10.17~3-0~ubuntu-jammy docker-ce-cli=5:20.10.17~3-0~ubuntu-jammy containerd.io docker-compose-plugin
sudo docker run hello-worldПотом надо добавить себя в группу, которая может запускать докер:
sudo usermod -aG docker $USER, после чего перелогиниться. Теперь можно клонировать репозиторию OpenLane:
mkdir -p ~/github
cd ~/github
git clone https://github.com/The-OpenROAD-Project/OpenLane.gitВсе, инсталляция закончена, но нужно создать свой проект. Копируем наш исходник улыбающейся улитки на верилоге в директорию $HOME/github/OpenLane/designs/snail_moore_fsm/src , потом добавляем в $HOME/github/OpenLane/designs/snail_moore_fsm два скрипта на TCL (один - общий для контроля OpenLane, второй - для контроля библиотек от SkyWater) - и можно запустить синтез.
Но сначала нужно запустить докер. Это делается так:
cd $HOME/github/OpenLane
make mountТеперь вы видите промпт типа "OpenLane Container (xxxxxxx):/openlane$ ", под которым можно запускать скрипт на TCL:
./flow.tcl -design snail_moore_fsmСкрипт выполнит все 39 шагов синтеза и произведет вот такой главный лог. Интересно, что из исходного верилога синтезируется тоже верилог, но только низкоуровневый, и на каждой стадии в него добавляются всякие физические детали. В самом начале процесса компонент OpenLane под названием Yosys превращает верилог на уровне регистровых передач в верилог, который представляет сосбой просто создание экземпляров ячеек библиотеки Skywater и соединение их проводами. Вот посмотрите на это синтезированный код. Он ничего вам не напоминает? Конечно что, это те самые И, НЕ и D-триггеры, которые мы видели на макетной плате с технологией 50-летней давности. Только это технология 2018-го года, а не 1968-го:
/* Generated by Yosys 0.12+45 (git sha1 UNKNOWN, gcc 8.3.1 -fPIC -Os) */
module snail_moore_fsm(clk, reset, en, a, y);
wire _00_; wire _01_; wire _02_; wire _03_; wire _04_;
input a;
input clk;
input en;
input reset;
wire \state[2] ;
output y;
sky130_fd_sc_hd__nor2_2 _05_ ( .A(reset), .B(en), .Y(_03_) );
sky130_fd_sc_hd__or3b_2 _06_ ( .A(reset), .B(a), .C_N(en), .X(_04_) );
sky130_fd_sc_hd__a21bo_2 _07_ ( .A1(\state[2] ), .A2(_03_), .B1_N(_04_), .X(_01_) );
sky130_fd_sc_hd__and4b_2 _08_ ( .A_N(reset), .B(en), .C(\state[2] ), .D(a), .X(_02_) );
sky130_fd_sc_hd__a21o_2 _09_ ( .A1(y), .A2(_03_), .B1(_02_), .X(_00_) ); sky130_fd_sc_hd__dfxtp_2 _10_ ( .CLK(clk), .D(_00_), .Q(y) );
sky130_fd_sc_hd__dfxtp_2 _11_ ( .CLK(clk), .D(_01_), .Q(\state[2] ) );
endmoduleМы можем использовать современную инкарнацию древнего, из 1980-х, редактора Magic, чтобы посмотреть на результат на физическом уровне. Выглядит он так:a
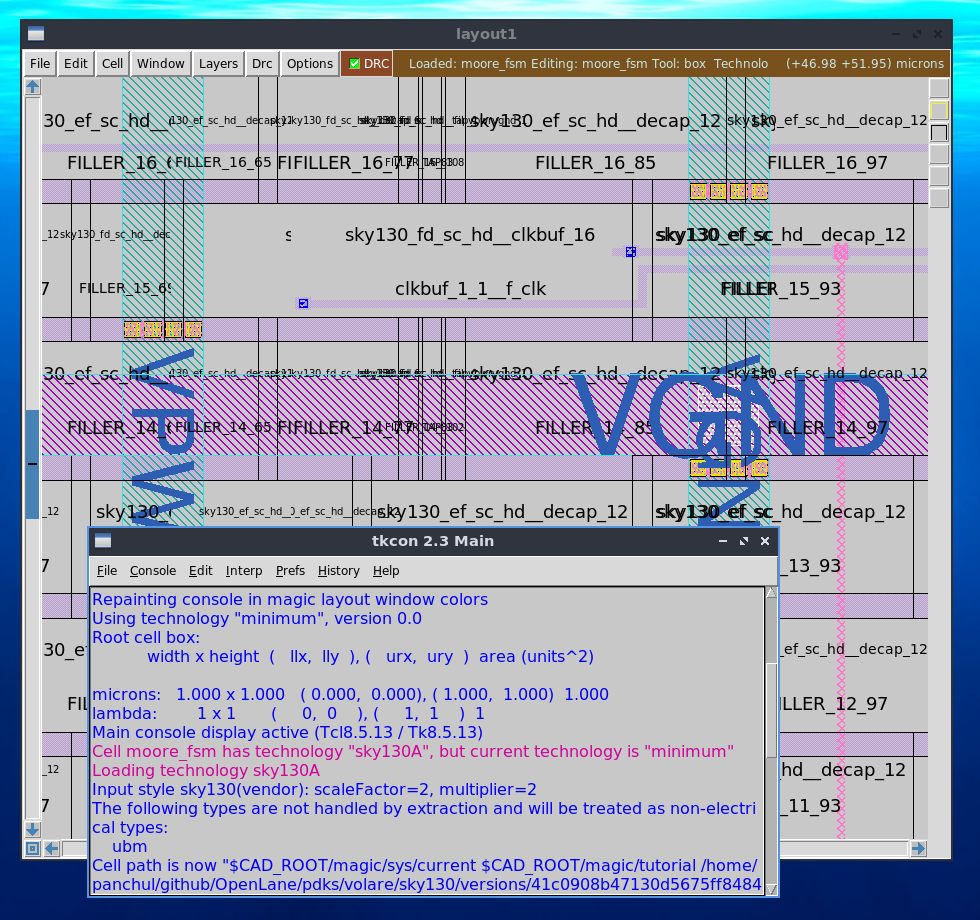
Magic запускается из докера просто как magic &. Затем вам нужно открыть файлы с расширением .mag, который вы можете найти в signoff внутри директории RUNS внутри вашего проекта. Также можно запустить редактор поновее, klayout, но он использует другой формат данных, файл с расширением .gds..
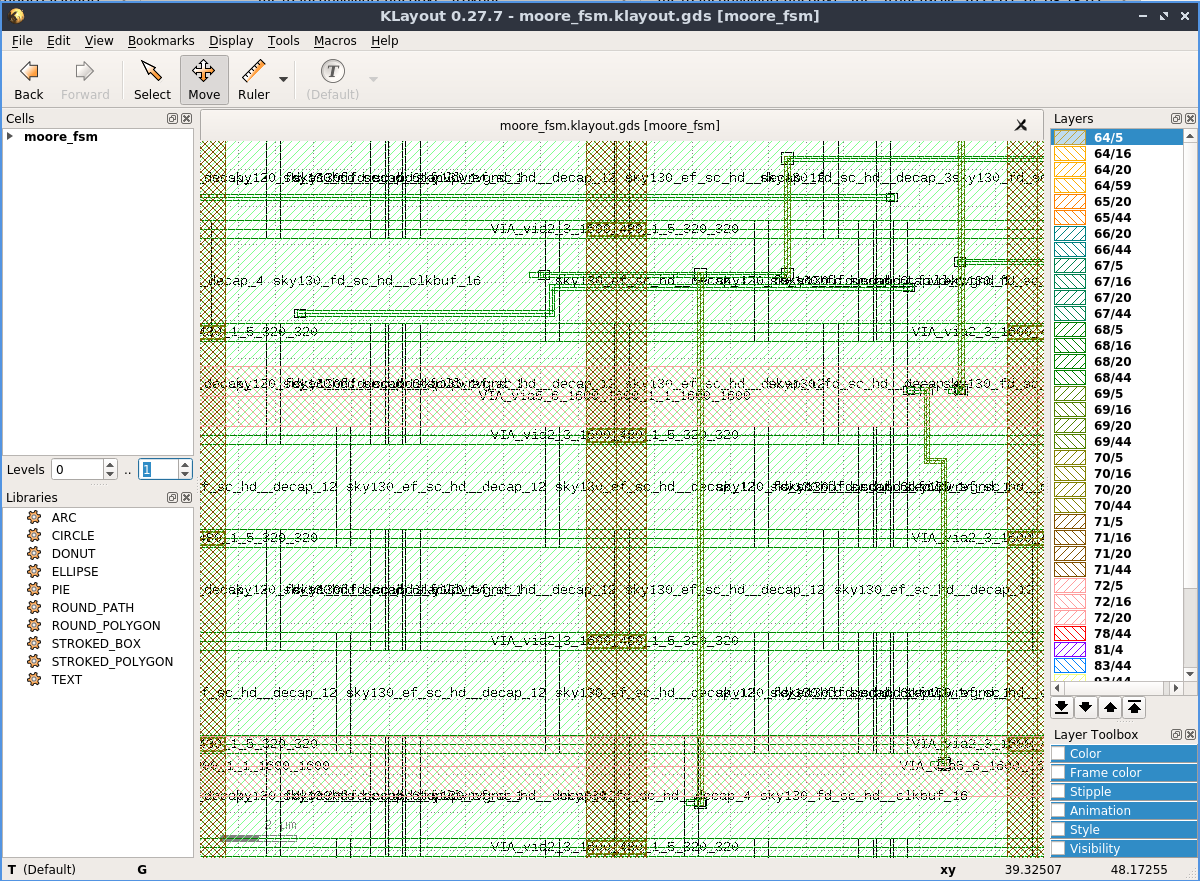
Также OpenLane производит стандартные для тулов такого рода отчеты о максимальной тактовой частоте, размерах, энергопортреблению итд - я собрал самые важные отчеты в репозитории файлов для семинара в Бишкеке.
Но перед тем, как улыбающуюся улитку синтезировать, ее нужно симулировать и отлаживать на временных диаграммах (это то, чем проектировщик микросхем на уровне регистровых передач занимается полдня, помимо митингов, писания кода и рисования микроархитектурных диаграмм). Вот так выглядят временные диаграммы "улыбающейся улитки" в бесплатной программе GTKWave после симуляции в бесплатном симуляторе Icarus Verilog:
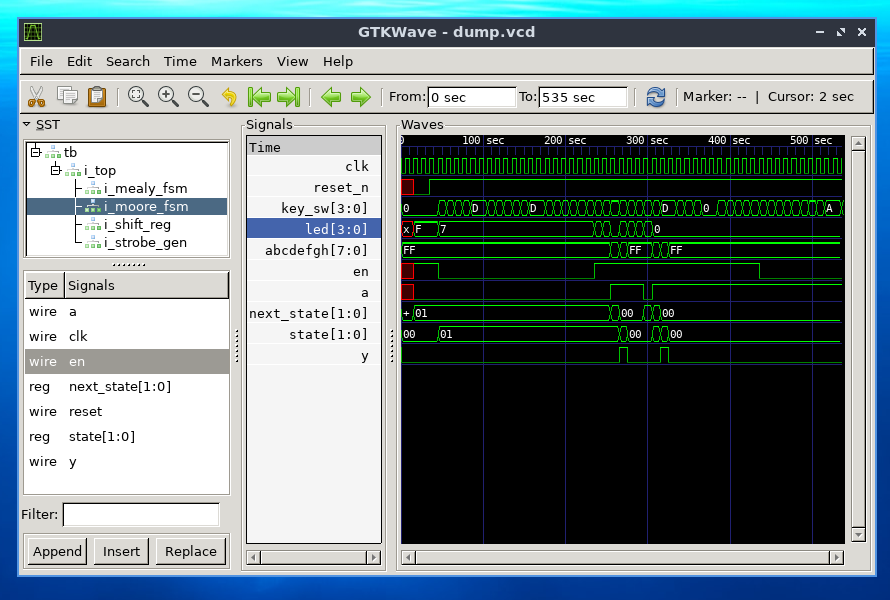
Однако Icarus медленный и не поддерживает всего языка SystemVerilog. А GTKWave очень тормозит когда у вас чуть больше сигналов, чем в игрушечном примере. К счастью, в Бишкеке будет компания Siemens EDA (в прошлом - Mentor Graphics), у которой есть симулятор Questa. У него лучше и поддержка языка, и скорость, и возможности отладки
.

Вот так выглядит "улыбающаяся улитка" в Квесте:
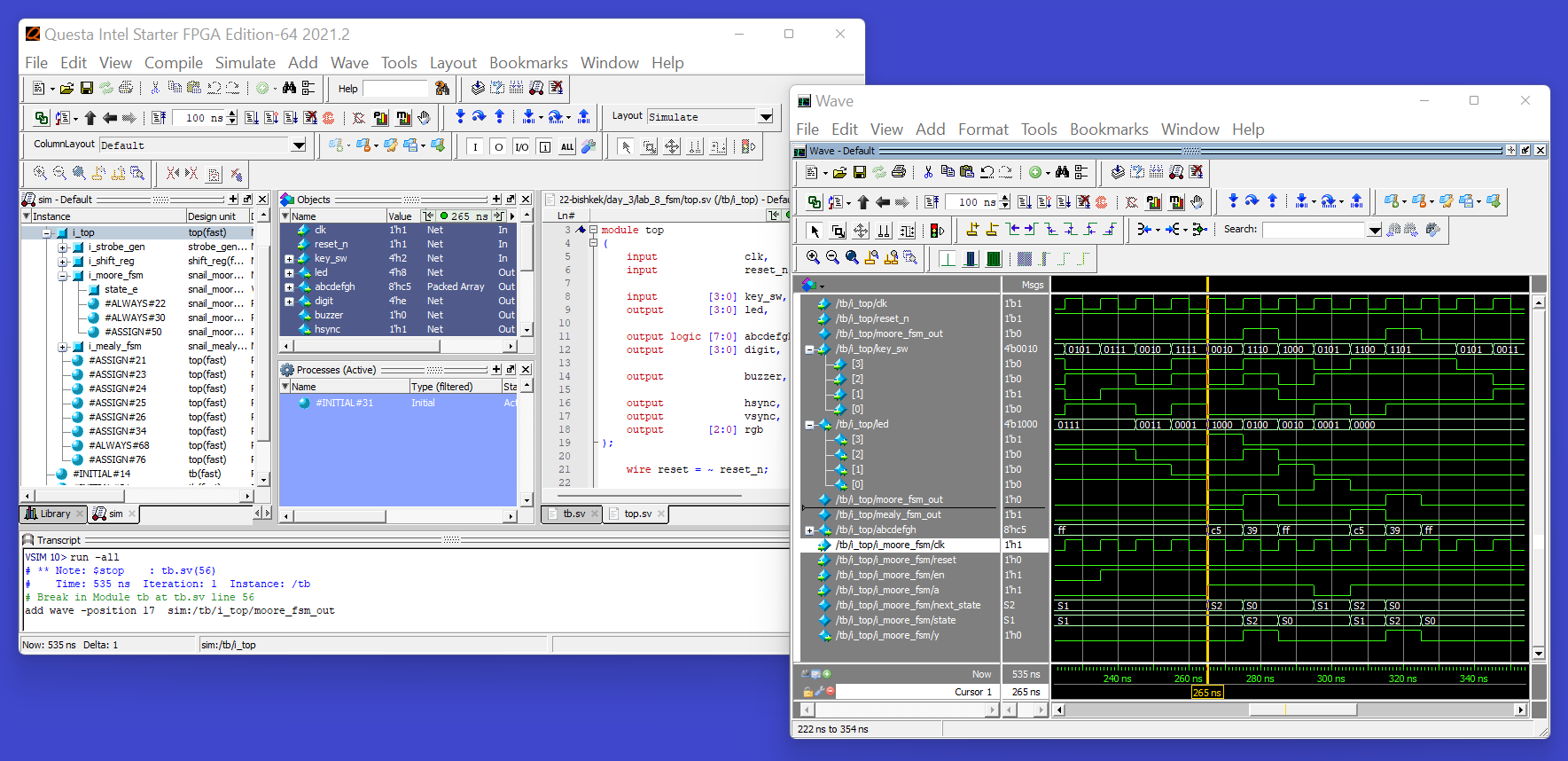
Про семинар в Бишкеке я уже писал, но ниже его детальное расписание. Еще не поздно сесть на самолет и туда прилететь. Заодно можете там со мной к исследованию среднеазиатской кухни:

.




До встречи!
Комментарии (14)

radiolok
27.07.2022 11:00+5Смех-смехом, а я с помощью yosys сейчас пытаюсь синтезировать схемотехнику вычислителя на элементах струйной логики, а также схему соединений будущего лампового компьютера - эмулятор на верилоге с помощью библиотеки элементов, которые я могу сделать на пневмонике/лампах превращается в схему соединений будущих модулей. Жаль синтезированную схему не получается пока засунуть в kiCAD виде нетлиста - приходится для струйного процессора вручную перерисовывать схему.
В теории даже openRoad можно будет прикрутить, где чипом будет шасси, а элементами - модули. И он мне схему соединений - жгут проводов между ними - засинтезирует.

YuriPanchul Автор
27.07.2022 11:07+3Надо же, я представлял такое теоретически, но чтобы кто-то реально стал делать гидравлический компьютер с синтезом из Верилога 8-)
radiolok
27.07.2022 11:16+9Не путайте пневматику и гидравлику - которые работают клапанах и давлении - с пневмоникой - на базе эффекта прилипания струй. Базисом в нем является элемент 2OR-2NOR, и сумматор на нем довольно легко синтезируется.

Вообще интересный проект выходит - синтез схемы в yosys, потом разработка платы соединительных каналов в kicad, проверка корректности работы струйного элемента с помощью симуляции в openFOAM. Прям openSource-процессор для пост-апокалипсиса. Даже электричества не надо для работы, только воздух - можно запитать от баяна, или органа.
Вот как раз со стадией переноса в KiCAD пока проблемы - простую схему можно и вручную быстро перерисовать. Но хотелось бы автоматизации, тогда можно будет в yosys скармливать библиотеку, например 155 и 555 логики, а на выходе получать синтезированную схему процессора на микросхемах малой степени интеграции


victor_1212
27.07.2022 14:49>Skywater скооперировалась не только с Пентагоном для его радиационно-устойчивых нужд, но и с компанией Гугл, которая спонсирует молодых гениев,
DARPA программа 3DSoC, статья супер интересная, вперед и вверх!

axe_chita
28.07.2022 04:16+1Спасибо за новую статью, было интересно.
П.С. С habrastorage какая та проблема, не отображаются картинки. Пришлось дочитывать через TOR

Khort
28.07.2022 23:00Юрий, вот вы интересно заголовок написали, про 3нм и 130нм. Да, понятно, что для цифрового дизайнера (RTL) разницы нет, под какой процесс писать код. Или, все таки, есть разница?
Начну издалека. Напомню, что частю работы по разработке эсика является верификация, в т.ч. симуляция пост-лейаут нетлиста. С задержками. Проверить те вещи, которые не видит STA. Далее, задержки (SDF) выписываются с помощью STA-тула. А в чем разница в STA на 3нм и 130нм? Разница - статистический STA на тонких процессах. В котором при расчете задержки пути, задержки складываются квадратически, а не линейно. Может так RTL симулятор считать задержки статистическими формулами? Нет, не может. Да и SDF не поддерживает статистические данные. Так как же быть, как симулируют нетлист с задержками на 3нм? Поделитесь опытом. Раз уже упомянули 3нм
YuriPanchul Автор
28.07.2022 23:13Разница есть - разный static timing analysis, особенно с учетом floorplan. Также разные библиотеки памяти и энергопотребление - скос в динамическое.
Мой заголовок о том, что если нет доступа к 3 нм, то это не означает, что нужно ждать у моря погоды, вздыхая "ах, отрезали санкциями, ох, какой смысл, зачем этот навоз мамонта ворошить". Суть в том, что учиться можно и на 130-нм, и в будущем применить это знание.
*** Так как же быть, как симулируют нетлист с задержками на 3нм? ***
Это не симулируют. Точнее где-то в конце может и симулируют, но вообще просто регулярно делают STA с учетом floorplan и после place & route. Вы это можете видеть на диаграмме - STA делается несколько раз - сначала после синтеза, потом после физического размещения. Причем на тонких техприцессах разница может быть 30% и выше. STA с учетом place & route идет долго, поэтому его делают нечасто. Деталей алгоритма я не знаю к сожалению.
Khort
28.07.2022 23:38Раньше симулировать надо было, ведь только так можно протестировать исключения (иначе - отловить баги) в констрейнтах, которые STA не видит. Но, это вы дизайном занимаетесь, не я. Раз сказали не симулируют, значит стали как то по другому проверки делать. Спасибо за ответ.
А что касается STA в P&R, то его гоняют на всех этапах: до и после плейса, после CTS, route, и конечно в конце, в специализированном signoff туле после сделанной полноценой экстракции паразитов из GDS. Это я уже как специалист говорю.
YuriPanchul Автор
28.07.2022 23:54Есть тулы для верификации констрейнов для случаев multicycle path и подобных которые работают независимо от STA. Я про них может напишу потом - я сейчас на самолет собираюсь
YuriPanchul Автор
30.07.2022 08:13Да, я вспомнил что в Juniper в конце проекта на 7 нанометров далали gate-level simulations, но эти занималась physical design team. Еще gate-level simulation нужен для оценки динамического энергопотребления на уровне блоков. Но вообще чем дальше к back-end, тем я более смутно все представляю - я все-таки front-end logic designer.
Daffodil
Странно, я как-то использовал GtkWave в большом проекте, и его внутренний формат дампов FST оказался эффективнее чем FSDB используемый в Synopsys. И на трассах в несколько гигабайт особенных тормозов не было. Да и сам разработчик GtkWave, который сейчас работает в AMD, утверждает что дебажит в нём симуляции CPU ядра Zen.
Возможно вы просто используете текстовые VCD дампы?
YuriPanchul Автор
Да. А Икарус умеет производить что-то другое чем текстовые VCD дампы? (сейчас погуглю)
YuriPanchul Автор
Я также со скепсисом отношусь к тому, что на GTKWave якобы можно эффективно дебажить большой процессор. Например он не умеет искать drivers и loads сигналов, как умеет это делать Cadence SimVision и Synopsys Verdi. Это одна из часто используемых ежедневных операций. Или я чего-то пропустил с GTKWave?
Daffodil
Driver/Load Tracing там действительно нет. И в принципе такую функцию невозможно реализовать на формате вроде VCD, т.к. он не содержит информации о нетлисте. Хорошая тема для будущих open-source разработчиков.