
В данном цикле статей мы реализовываем систему автоматического поиска хайлайтов в матчах Dota 2. Для ее создания нам требуется размеченный датасет с тайм-кодами. На YouTube есть множество каналов, где люди выкладывают нарезки с интересными моментами из профессиональных матчей по Dota 2. Зачастую на видео есть маленькие часы из интерфейса игры. Время на них мы и будем распознавать.

В предыдущих частях:
В первой части мы распарсили реплей одного матча по Dota 2 и нашли хайлайты с помощью кластеризации.
Во второй части мы написали сервис для параллельного парсинга реплеев на Celery и Flask.
Под катом
Скачиваем видео с YouTube с помощью
yt-dlp.Семплируем кадры из ролика через
ffmpeg.Кропаем изображение с помощью
OpenCV.Краткий обзор
Tesseract,EasyOCRиTrOCR.Распознаем время.
Заключение.
Все ссылки на код и использованные материалы вы найдете в конце статьи.
Скачиваем видео с YouTube
Я использовал yt-dlp — прямого наследника youtube-dl, который умеет обходить проблему медленной загрузки.
Возьмем для примера канал DotA Digest и скачаем ссылки на все ролики.
yt-dlp \
--print-to-file "%(url)s" youtube/urls.txt \
--flat-playlist https://www.youtube.com/c/DotadigestDDОпция --download-sections позволяет скачать часть ролика.
yt-dlp \
--format mp4 \
--download-sections "*00:30-00:45" \
https://youtu.be/wUPhtY4sNP0Также с утилитой можно взаимодействовать напрямую из Python. Напишем функцию, которая скачивает метаданные и сохраняет в json, а затем скачивает само видео.
...
import yt_dlp
def youtube_download(url):
options = dict(
format='mp4',
outtmpl=f'{VIDEO_DIR}/%(id)s.%(ext)s',
)
with yt_dlp.YoutubeDL(options) as ydl:
info = ydl.extract_info(url, download=False)
video_id = info.get('id')
info_file = f'{video_id}.json'
video_info_path = VIDEO_DIR / info_file
video_file = f'{video_id}.mp4'
video_path = VIDEO_DIR / video_file
if video_path.exists():
logger.info(f'Video already exists: {video_path}')
return video_id
logger.info(f'Downloading: {url}')
with yt_dlp.YoutubeDL(options) as ydl:
ydl.download(url)
with open(video_info_path, 'w') as fout:
json.dump(info, fout, indent=4)
return video_idСемплируем кадры из ролика
Обычно в видео от 24 до 60 FPS (кадров в секунду), при этом время на часах в игре обновляется раз в секунду. Чтобы не обрабатывать лишние изображения, будем брать по 1 кадру из видео в секунду. Для этого можно воспользоваться утилитой ffmpeg
ffmpeg -i <video_path> -r 1/1 frames/$filename%03d.bmpЕсть wrapper на Python, но я предпочел закостылить свой вариант.
import subprocess
def sample_frames(video_id):
video_path = VIDEO_DIR / f'{video_id}.mp4'
output_prefix = FRAMES_DIR / video_id
for file in os.listdir(FRAMES_DIR):
if file.startswith(video_id):
logger.info(f'Frames already exists: {video_id}')
return
logger.info(f'Sampling Frames from: {video_id}')
cmd = f'''ffmpeg \
-i {str(video_path)} \
-r 1/1 \
{str(output_prefix)}__$filename%03d.bmp
'''
subprocess.run(cmd, shell=True)Кропаем изображение с помощью OpenCV
Зачастую в задачах оптического распознавания символов (OCR) приходится сначала детектировать участок изображения, где есть текст, а уже потом его распознавать. Нам повезло, часы в интерфейсе игры — статический объект. Положение может слегка меняться в зависимости от разрешения экрана, но этим фактом мы пренебрежем.
Для начала загрузим один кадр с помощью OpenCV:
import cv2
import matplotlib.pyplot as plt
image = cv2.imread(str(frame_path))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)И выведем результат на экран.
fig = plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.show()
Объект image является массивом numpy, что позволяет обрезать и масштабировать изображение буквально в три строчки.
bbox = (16, 23, 619, 653)
crop = image[bbox[0]:bbox[1], bbox[2]:bbox[3]]
crop = cv2.resize(crop, dsize=None, fx=16, fy=16, interpolation=cv2.INTER_CUBIC)
Координаты bounding box подбираются методом "тыка". Слева взят небольшой запас, потому что время в матче иногда переваливает за отметку в 100 минут, в таком случае на часах будет 100:00.
Краткий обзор Tesseract, EasyOCR и TrOCR
Читатель невооруженным глазом обнаружит на предыдущей картинке время 3:14. Вдобавок задача оптического распознавания символов достаточно популярная, встречается при работе с документами или, например, номерными знаками машин. Это наводит на мысль, что должна найтись open source модель, которая из коробки будет неплохо работать.
Tesseract
Первое, что выдал в поиске Google — свой же проект, согласно википедии, с достаточно увлекательной историей.
Tesseract — свободная компьютерная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х, а затем 10 лет «пролежавшая на полке». В августе 2006 г. Google купил её и открыл исходные тексты под лицензией Apache 2.0 для продолжения разработки.
Выполним команду.
tesseract \
<file_path> \
stdout \
--oem 1 \
--psm 7 \
-c tessedit_char_whitelist=0123456789
> 214В результате было распознано 214. Неплохо для первой попытки, но недостаточно. На некоторых аналогичных изображениях текст и вовсе не распознается. Простые преобразования силами OpenCV не помогли, а даже если бы и помогли, моя душа все равно не была бы спокойна. Проблема, скорее всего, обусловлена тем, что в качестве модели используется LSTM, обученная в далеком 2019 году.
EasyOCR
Следующее, что попалось под руку — EasyOCR, которая состоит из Detector и Recognizer. Первый отвечает за обнаружение текстов на картинке, второй за распознавание. Для начала без страха, без уважения, я попробовал скормить целиком весь кадр, ведь библиотека из коробки возвращает не только распознанные символы, но и bounding boxes.
import easyocr
image = cv2.imread('youtube/frames/ukbICbM4RR0__033.bmp')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
reader = easyocr.Reader(['en'])
result = reader.readtext(image)
for (bbox, text, prob) in result:
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)
plt.rcParams['figure.figsize'] = (16, 16)
plt.imshow(image)
И действительно, много строк было детектировано и распознано. Но модель пропустила интересующие нас часики. Более того, если посмотреть вниз картинки, можно заметить, что имя персонажа DAWNBREAKER выделено неполностью и распознано как AWNBRIAKER.
Я решил подать модели на вход обрезанное изображение, но с первого раза она ничего не распознала. Обойти проблему можно, оставив немного пространства вокруг текста.

Нюанс в том, что двоеточие было распознано как 8, и в итоге модель выдала 3814. Снова промах. На других кадрах возникала проблема, что символы слева от двоеточия модель вовсе игнорировала.
В репозитории есть схема работы алгоритма.
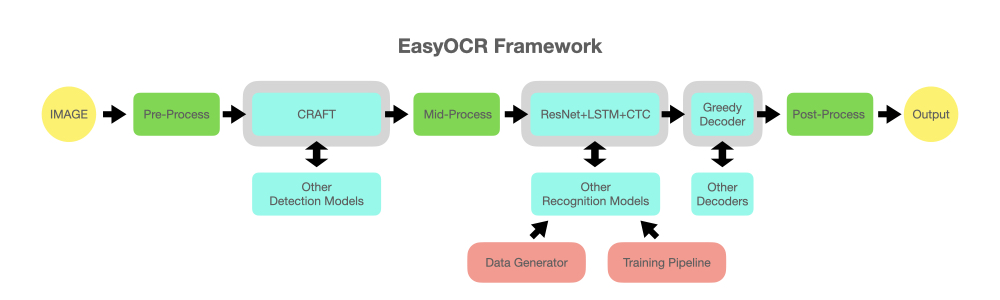
Ключевыми действующими лицами являются ResNet и LSTM — все те же архитектуры из "дотрансформерной" эпохи.
Также в репозитории есть скрипт для обучения модели, но я не шарю в CV мне было лень возиться.
TrOCR
Наконец я наткнулся на TrOCR. Данная библиотека не умеет детектировать текст на картинке, умеет только распознавать. Но нам этого хватит. Архитектура выглядит следующим образом:
Visual Transformer (ViT)в качестве энкодера для работы с изображением.RoBERTaв качестве декодера для работы с текстом.
Ниже представлена схема из статьи. Читать ее нужно с правого-нижнего угла.

Пояснение из статьи по поводу декодера.
When loading the RoBERTa models to the decoders, the structures do not exactly match. For example, the encoder-decoder attention layers are absent in the RoBERTa models. To address this, we initialize the decoders with the RoBERTa models and the absent layers are randomly initialized.
Выполним код.
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
model_version = "microsoft/trocr-base-printed"
processor = TrOCRProcessor.from_pretrained(model_version)
model = VisionEncoderDecoderModel.from_pretrained(model_version)
pixel_values = processor(image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
> '3.14'Ура-ура! Модель распознала 3.14. Практика показала, что во всех кадрах в качестве разделителя распознается точка, а не двоеточие. В некоторых ситуациях разделитель вовсе не распознается. Но нам повезло, в Dota 2 на часах время всегда отображается в формате mm:ss, поэтому проблему можно решить конвертацией в timestamp.
def convert_to_timestamp(text):
sign = -1 if text.startswith('-') else 1
digits = ''.join([c for c in text if c.isdigit()])
seconds = digits[-2:]
seconds = int(seconds)
minutes = digits[:-2]
minutes = int(minutes)
timestamp = sign * (minutes * 60 + seconds)
return timestampВыводы
Мы научились скачивать видео с нарезками хайлайтов с YouTube, семплировать кадры и распознавать на них время. Также мы изучили несколько библиотек для распознавания символов на изображениях. Конкретно в нашем примере трансформеры правят баллом и работают из коробки без дополнительного обучения и сложных преобразований входного изображения.
В следующей части я планирую стрельнуть из пушки по воробьям и использовать BERT для матчинга названий видео с записями в БД, чтобы сопоставлять кадры и события из текстовых реплеев Dota 2.
Всех неравнодушных приглашаю в комментарии.
Ссылки
Комментарии (5)

Degot
29.07.2022 11:09попробуйте сначала сделать upscale с помощью waifu2x ( waifu2x-ncnn-vulkan.exe -n 0 -s 2 -x -i input.png -o output.png) , обрезать и уже потом EasyOCR... можно попробовать отфильтровать по HSL перед OCR... Ещё можно подсчитать количество "белых" пикселей в столбцах обрезанного изображения и отфильтровать всё что меньше threshold'а...
З.Ы. Я так EVE автоматизировал.
З.Ы.Ы. Перед отправкой в OCR, поиграйтесь с последовательностью "предобработки" изображения.. я использую Aforge.net IPLab



AigizK
30.07.2022 08:46Для тессеракта лучше инвертировать картинку, так как черный текст он лучше распознает. Плюс добавить паддинги. Результат должен улучшиться. Хотя такие размытые картинки не приходилось распознавать ????
Luchnik22
Спасибо, за статью, думаю вам будет интересно ещё поработать с Game State Server, у меня тоже есть идея распознавать сообщение о смерти Рошана и интегрировать с overlay, можем попробовать вместе - почитайте мою статью
arch1baald Автор
Да, мне доводилось работать с GSI — хорошая штука. Кстати, для Overlay можно использовать Overwolf, там из коробки поддерживается эта фича