
 Хорошего дня, Хаброжители!
Хорошего дня, Хаброжители! Методы управления данными и их интеграции быстро развиваются, хранение данных в одном месте становится все сложнее и сложнее масштабировать. Пора разобраться с тем, как перевести сложный и тесно переплетенный ландшафт данных вашего предприятия на более гибкую архитектуру, готовую к современным задачам.
Архитекторы и аналитики данных, специалисты по соблюдению требований и управлению узнают, как работать с масштабируемой архитектурой и внедрять ее без больших предварительных затрат. Питхейн Стренгхольт поделится с вами идеями, принципами, наблюдениями, передовым опытом и шаблонами.
Для кого эта книга
Книга ориентирована на крупные предприятия, хотя может пригодиться и в небольших организациях. Ею могут особенно заинтересоваться:
● руководители и архитекторы: директора по обработке и анализу данных, технические директора, архитекторы предприятия и ведущие архитекторы данных;
● группы контроля и управления: руководители службы информационной безопасности, специалисты по защите данных, аналитики информационной безопасности, руководители по соблюдению нормативных требований, операторы баз данных и бизнес-аналитики;
● аналитические группы: специалисты по теории и методам анализа данных, аналитики и руководители аналитических отделов;
● команды разработчиков: дата-инженеры, бизнес-аналитики, разработчики и проектировщики моделей данных, а также другие специалисты по данным.
● руководители и архитекторы: директора по обработке и анализу данных, технические директора, архитекторы предприятия и ведущие архитекторы данных;
● группы контроля и управления: руководители службы информационной безопасности, специалисты по защите данных, аналитики информационной безопасности, руководители по соблюдению нормативных требований, операторы баз данных и бизнес-аналитики;
● аналитические группы: специалисты по теории и методам анализа данных, аналитики и руководители аналитических отделов;
● команды разработчиков: дата-инженеры, бизнес-аналитики, разработчики и проектировщики моделей данных, а также другие специалисты по данным.
Качество данных
Состояние и качество данных — еще один важный аспект проектирования. Когда наборы данных загружаются в RDS, они проверяются на соответствие определенным метрикам с использованием правил оценки качества данных. В первую очередь должна оцениваться целостность данных и возможность их технической проверки на соответствие опубликованным схемам. Затем выполняется проверка данных на соответствие таким функциональным показателям качества, как полнота, точность, согласованность, достоверность и т. д.
Преимущество использования общей инфраструктуры для RDS заключается в возможности использовать всю мощь больших данных для оценки качества. Например, Apache Spark (https://spark.apache.org/) может проверить и обработать сотни миллионов строк данных в течение нескольких минут. Существуют также фреймворки, которые можно использовать для проверки качества данных. В Amazon Web Services (AWS), например, был разработан Deequ (https://github/awslabs/deequ.com), — инструмент с открытым исходным кодом для расчета показателей качества данных. Другой пример — инструмент Delta Lake (https://delta.io), разработанный в DataBricks (https://databricks.com), — его можно использовать как для проверки схемы, так и для проверки данных. Эти инструменты позволяют глубже понять качество данных, что важно для всех сторон (рис. 3.7).
Если мониторинг качества данных реализован как надо, он не только обнаруживает и отслеживает проблемы с качеством данных, но и становится частью общей структуры управления, которая добавляет новые данные к уже существующим. Если по какой-то причине качество упадет ниже указанного порогового значения, структура может зарегистрировать данные и попросить владельцев рассмотреть и принять данные с текущим качеством или отклонить их и выполнить повторную доставку.
Качество данных можно контролировать в двух местах: в источнике или в RDS. Преимущество управления качеством данных в RDS с использованием нескольких источников данных на одной платформе заключается в возможности проверки ссылочной целостности. Системы-источники часто ссылаются на данные из других приложений или систем. Путем перекрестной проверки ссылочной целостности, а также сравнения и сопоставления всех наборов данных из всех RDS можно найти ошибки и корреляции, о существовании которых и не подозревали.
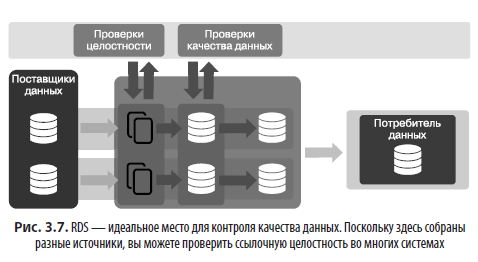
Оценка качества данных означает наличие в системе управления ими замкнутой цепочки обратной связи, которая постоянно исправляет и предотвращает повторное появление проблем с качеством. Благодаря этому качество данных постоянно контролируется и изменения его уровня должны немедленно устраняться. Проблемы качества данных должны решаться в системах-источниках, а не в RDS. Если данные исправлены в источнике, то проблемы с качеством больше не будут появляться в других местах.
Мой опыт показывает, что нельзя недооценивать влияние плохого качества данных. Если качество данных не обеспечивается должным образом, все потребители данных будут вынуждены снова и снова проводить работы по их очистке и исправлению.
Уровни RDS
У потребителей могут быть самые разные нужды — от простого исследования данных до принятия решений в режиме реального времени. Чтобы облегчить использование различных схем потребления, я рекомендую разбить RDS на разные уровни: входящий уровень и уровень доступа.
Входящие уровни, как показано слева на рис. 3.8, обычно основаны на недорогом (объектном) хранилище и используются для проверки качества входящих наборов данных, обработки для получения метаданных, а также архивирования и создания наборов исторических данных (вскоре мы обсудим каждую из этих прикладных функций). Естественно, что во входящих уровнях со временем накопятся большие объемы данных; обычно в виде набора файлов CSV или JSON. Наконец, данные могут передаваться на входящий уровень различными способами: пакетной передачей, загрузкой по событиям, загрузкой через API, захватом изменений и т. д.
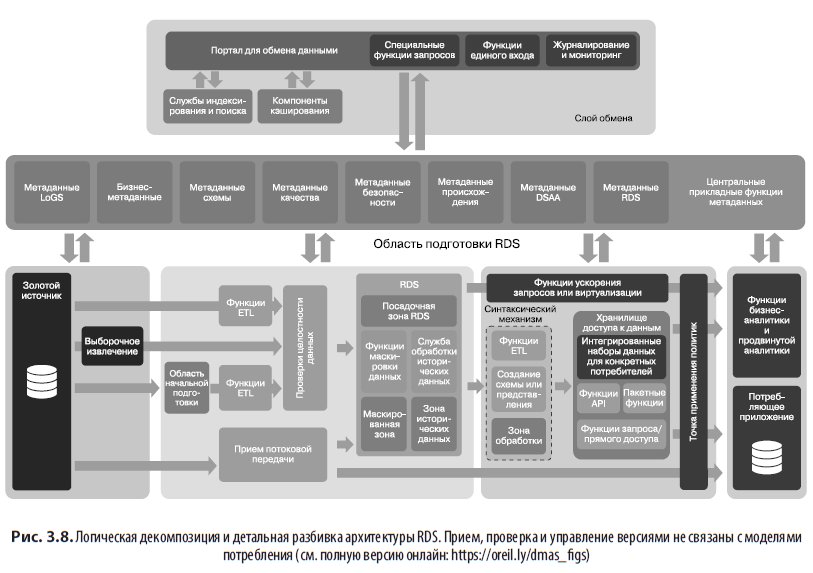
RDS используют разделение, предполагающее размещение данных от разных поставщиков в разных сегментах, папках или логических экземплярах базы данных. Разделение обеспечивает управляемость и изоляцию.
Уровни доступа к данным, как показано справа на рис. 3.8, оптимизированы для удобства чтения и могут предлагать несколько возможностей обработки запросов для улучшения взаимодействия с пользователем или повышения производительности. Хотя данные все еще находятся в контексте предметной области, они лучше подходят для решения бизнес-вопросов. Очевидно, что этот уровень дороже и часто приходится использовать несколько таких уровней для поддержки различных вариантов использования с разными моделями потребления. Например, для быстрых операций наборы данных могут находиться в хранилищах типа «ключ — значение» или в базах данных в памяти, а текстовые запросы могут располагаться в хранилищах, оптимизированных для поиска. Это также означает, что данные можно преобразовать в форму, которая лучше всего подходит для анализа. Их можно объединять, фильтровать или обрабатывать с использованием исторических данных или только подмножества данных входящего уровня.
Наконец, уровни доступа к данным предоставляют дополнительные возможности. Они могут предлагать самообслуживание и улучшенные средства управления безопасностью, а также инструменты бизнес-аналитики и аналитики для быстрого доступа к данным, и могут использовать метаданные для управления перемещением данных и их синхронизации.
Получение данных
Давайте подробнее рассмотрим входящие уровни и то, как данные принимаются, собираются и накапливаются. Для перемещения данных приложений из золотых источников в RDS используются два основных метода.
Первый — событийно-ориентированная обработка, или загрузка данных по событиям. Предполагает передачу данных в виде потока небольших событий или наборов данных. Событийно-ориентированная обработка позволяет собирать и обрабатывать данные относительно быстро, поэтому ее часто называют обработкой «в реальном времени». По мере поступления данных могут применяться критерии и преобразования данных для обнаружения изменений в потоке событий (мы коснемся передачи состояния приложения в главе 5 и в частности в разделе «Потоковое взаимодействие» на с. 184). Прием потоковой передачи хорошо походит для случаев, когда объемы данных относительно малы, вычисления, выполняемые с данными, относительно просты и задержки должны быть относительно короткими, близкими к реальному времени. Многие сценарии использования допускают применение событийно-ориентированной обработки, но если полнота и объем данных являются серьезной проблемой, то предпочтительнее использовать традиционную пакетную обработку.
Второй метод — пакетная обработка — подразумевает процесс одновременной передачи большого объема данных, например всех транзакций из крупной платежной системы в конце дня. Пакет обычно выглядит как набор данных с миллионами записей, хранящихся в виде файла. Почему может понадобиться пакетная обработка? Потому что во многих случаях это единственный способ собрать данные. Наиболее важные RDBM имеют пакетные компоненты для поддержки пакетного перемещения данных. Согласование данных, процесс проверки данных во время перемещения, часто вызывает беспокойство1. Проверка наличия всех данных важна, особенно в финансовых процессах. Кроме того, многие системы сложны и содержат огромное количество таблиц, и применение языка структурированных запросов (Structured Query Language, SQL) — единственный надежный способ выбрать и извлечь все необходимые данные. Вот почему такие утверждения, как «пакеты не нужны» или «событийно-ориентированные данные — единственный вариант», слишком обобщены.
Хотя загрузка данных по событиям продолжает набирать популярность, этот метод никогда не сможет полностью заменить пакетную обработку во всех случаях использования. Я предполагаю, что на современном предприятии одновременно будут использоваться оба метода. Еще ожидается, что для предметных областей будет реализовано много дополнительных компонентов предоставления данных, учитывая большое разнообразие приложений и БД. Они будут различаться в зависимости от особенностей процессов ETL, захвата изменений в данных, средств планирования и т. д.
Метаданные схемы
При пакетной обработке старых систем одним из слабых мест обычно является управление метаданными схемы. Для обеспечения целостности и полноты данных в файлах TXT и CSV (значения, разделенные запятыми) также можно добавить вверху заголовок, описывающий схему и количество строк внизу в файле CSV. Другой метод описания файлов — разработать определение интерфейса с использованием метаданных схемы. Файл метаданных, который показан в примере 3.1, описывает не только схему данных, но и владение, контрольные суммы и версию. Контрольные суммы могут использоваться для проверки полноты после преобразования данных, а версия — для проверки эволюции и обратной совместимости.

Еще один подход к предоставлению метаданных с данными — разрешение областям регистрировать свои интерфейсы и выгружать свои метаданные на центральный портал регистрации. Этот реестр метаданных можно использовать и для хранения информации об интерфейсах, данных и связанных концепциях в одном месте. Мы обсудим это в главе 6.
Я уделяю так много внимания метаданным, потому что они важны как для совместимости, так и для поддержки передачи данных в хранилища RDS. В отсутствие метаданных вам придется вручную разрабатывать множество конвейеров. Метаданные помогут автоматизировать обработку и организовать создание дополнительных контрольных точек проверки, работающих согласованно, независимо от используемой базовой технологии.
В следующих двух разделах мы рассмотрим некоторые продукты и службы, требующие дополнительного внимания для правильного приема данных. Сюда входит сбор данных из готовых коммерческих решений и внешних сервисов.
Интеграция готовых коммерческих решений
Дополнительного внимания требуют интеграция и сбор данных из готовых коммерческих (commercial off-the-shelf, COTS) продуктов. Многие из них чрезвычайно трудно интерпретировать или использовать. Схемы БД часто бывают очень сложными, а ссылочная целостность обычно поддерживается программно, через приложение, а не базу данных. Часто данные защищены и могут извлекаться только с помощью стороннего решения.
Во всех ситуациях я рекомендую реализовать дополнительные службы, которые позволят сначала выгрузить данные во вторичное хранилище (рис. 3.9), а затем настроить конвейер для переноса данных из этого хранилища в RDS. Преимущество такого подхода в том, что решение поставщика отделено от конвейера данных. Обычно схема данных продукта COTS напрямую не контролируется. Если поставщик выпустит обновление продукта и изменит структуры данных, то конвейер данных перестанет работать. Подход с промежуточным хранилищем обеспечивает гибкость, позволяющую поддерживать совместимость интерфейса.

Извлечение данных из внешних API и SaaS
Внешние API или SaaS, играющие роль поставщиков, тоже обычно требуют особого внимания. Бывают случаи, когда нужно получить полный набор данных, но API позволяет извлечь только относительно небольшую часть. Другие API могут применять регулирование, используя квоты или ограничения на количество запросов. Есть также API с дорогими тарифными планами для каждого вашего вызова.
Во всех этих ситуациях я рекомендую создавать небольшие службы или приложения, которые обращаются к API и хранят данные во вторичном хранилище, как показано на рис. 3.10.
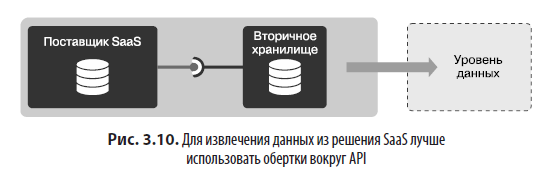
Создавая обертки, инкапсулирующие API поставщика SaaS, можно спроектировать интересный шаблон. Все вызовы сначала будут передаваться обертке, инкапсулирующей API. Если запрос был выполнен недавно или только что, то обертка немедленно вернет результаты из вторичной БД. В противном случае будет вызван API поставщика SaaS, а результаты переданы потребителю и одновременно сохранены во вторичном хранилище для любого последующего использования. С помощью этого шаблона можно в конечном итоге получить полный набор данных и заполнить хранилище данных только для чтения (RDS).
Служба исторических данных
Аспект, который я хочу обсудить более подробно, — это управление жизненным циклом данных путем сбора и хранения исторических данных. Удаление нерелевантных данных делает системы более быстрыми и экономичными.
Архитектура RDS берет на себя роль хранения и управления большими объемами исторических данных. Основное отличие от архитектуры корпоративного хранилища состоит в том, что RDS хранят данные в исходном контексте. Никакого преобразования в модель данных предприятия не ожидается, поэтому ценность не будет потеряна. Это серьезное преимущество: в оперативных сценариях использования, требующих сохранения большого количества исторических данных, не нужно преобразовывать данные обратно в исходный контекст.
Хотя RDS не зависит от технологии, вероятность того, что все входящие уровни RDS будут спроектированы с использованием дорогостоящих систем управления AWS, очень мала. Когда хранилище и вычислительные ресурсы разделены, ваши RDS, скорее всего, будут размещены в недорогих распределенных файловых системах, доступных только для добавления. Это означает, что любое изменение или обновление существующих таблиц повлечет за собой полное переписывание файлов или уровней доступа к данным. Поэтому для распределенных файловых систем, доступных только для добавления, я советую использовать один из описанных ниже подходов, так как существует компромисс между затратами в управление входящими данными и простотой их потребления. У каждого подхода есть свои плюсы и минусы.
Разбиение на разделы полноразмерных моментальных снимков файловых систем
Первый подход — сохранять все доставляемые данные путем логического разбиения на разделы и группировки. Разбиение на разделы — распространенный метод организации файлов или таблиц в отдельные группы (разделы) для повышения управляемости, производительности или доступности. Разбиение обычно выполняется по некоторым атрибутам данных, таким как географическое местоположение (город, страна), значения (уникальные идентификаторы, коды сегментов) или время (дата и время доставки). Пример разбиения на разделы показан на рис. 3.11, слева.



Разбиение полных моментальных снимков на разделы выполнить проще. По мере поступления данных каждый снимок добавляется как новый неизменяемый раздел. Таблица — это набор всех снимков, в которых каждый раздел сохраняет полный размер на определенный момент времени. Недостаток такого подхода — дублирование данных. Я не считаю это проблемой в наши дни, когда облачные хранилища стоят относительно дешево. Полные моментальные снимки также упрощают повторную доставку. Если исходная система обнаруживает, что были доставлены неверные данные, их можно отправить снова и раздел будет перезаписан. Основной недостаток этого подхода — усложнение анализа данных. Сравнение между конкретными периодами времени может быть затруднено из-за необходимости обрабатывать все данные при чтении. Это может стать проблемой, если потребители требуют, чтобы все исторические данные были обработаны и сохранены. Обработка исторических данных за три года может привести к последовательной обработке как минимум тысячи файлов и занять много времени, в зависимости от размера данных.
Обслуживание исторических данных
Второй подход — оптимизация всех наборов данных для использования исторических данных. Например, обработка всех наборов данных в SCD, которые показывают все изменения, имевшие место с течением времени. Обработка и создание исторических данных требуют дополнительного процесса ETL для обработки и объединения различных доставок данных (см. правую часть рис. 3.11).
Подход к созданию исторических данных позволяет организовать их хранение более эффективно, обрабатывая, удаляя дубликаты и объединяя данные. Как можно видеть на рис. 3.11, медленно меняющееся измерение занимает половину количества строк. Поэтому запросы, например, при использовании реляционной БД выглядят проще и выполняются быстрее. Очистка данных или удаление отдельных записей, что может потребоваться для соблюдения требований GDPR, также упростится, так как вам не придется обрабатывать все наборы данных. Еще одно преимущество — возможность выбора более простых и быстрых реляционных БД благодаря более эффективному хранению данных.
Однако есть и недостаток: создание SCD требует большего управления. Все данные нужно обработать. Изменения в исходных данных необходимо обнаруживать сразу после их появления и затем обрабатывать. Это требует дополнительного кода и вычислительной мощности. Еще хочу заметить, что потребители данных имеют разные требования. Поэтому, несмотря на наличие медленно меняющихся измерений, потребителям все равно необходимо обрабатывать данные. Например, данные могут поступать и обрабатываться каждый час, но, если потребитель ожидает, что данные будут сравниваться по дням, все равно потребуется дополнительная работа по преобразованию.
Один из недостатков создания исторических данных для общего потребления состоит в том, что потребителям все равно может понадобиться обрабатывать данные всякий раз, когда они пропускают столбцы в выборках. Например, если потребитель запрашивает более узкий набор данных, могут появиться повторяющиеся записи и придется снова выполнить обработку для удаления дубликатов.
Наконец, повторная доставка может быть трудновыполнимой, так как при этом могут быть обработаны и добавлены в измерения некорректные данные. Это можно исправить с помощью логики повторной обработки, дополнительных версий или сроков действия, но в любом случае потребуется дополнительное управление. Проблема здесь в том, что правильное управление данными может стать обязанностью центральной группы, поэтому такая масштабируемость нуждается в обширном интеллектуальном самообслуживающемся функционале.
Для масштабируемости и помощи потребителям вы также можете рассмотреть возможность смешивания двух подходов — сохранение всех полных моментальных снимков и создание «исторических данных как услуги». В этом сценарии всем предметным областям потребителей предлагается небольшая вычислительная инфраструктура, с помощью которой они смогут планировать создание исторических данных в зависимости от объема (ежедневно, еженедельно или ежемесячно), временного интервала, атрибутов и необходимых им наборов данных. Используя краткосрочные экземпляры обработки в общедоступном облаке, вы даже можете сделать такой подход рентабельным. Большим преимуществом этого решения является сохранение гибкости при повторной доставке при отсутствии необходимости привлекать команду инженеров для работы с данными. Еще одно преимущество — возможность адаптировать временные рамки, объемы и атрибуты к потребностям каждого клиента.
Об авторе
Питхейн Стренгхольт (Piethein Strengholt) — главный архитектор ABN AMRO — курирует стратегию обработки данных и изучает ее влияние на деятельность организации. Ранее он работал стратегическим консультантом, проектировал множество архитектур и участвовал в крупных программах управления данными, а также был внештатным разработчиком приложений. Живет в Нидерландах со своей семьей.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Покупка электронной книги вне РФ доступна на Google Play.
Для Хаброжителей скидка 25% по купону — Данные
eigrad
А этот текст точно не yalm-100b писало? RDS? SCD? Spark сотни миллионов строк в минуту? (а я думал он распределённый и масштабируется) Delta Lake инструмент для data quality? Как связаны снимки ФС и партиционирование? Понятно что гуглопереводчик, но не понятно как.