
Начнем с экспозиции. В нашей компании продуктовая структура представляет из себя 9 продуктовых end-to-end команд общей численностью ~130 человек, работающих над развитием одного продукта.
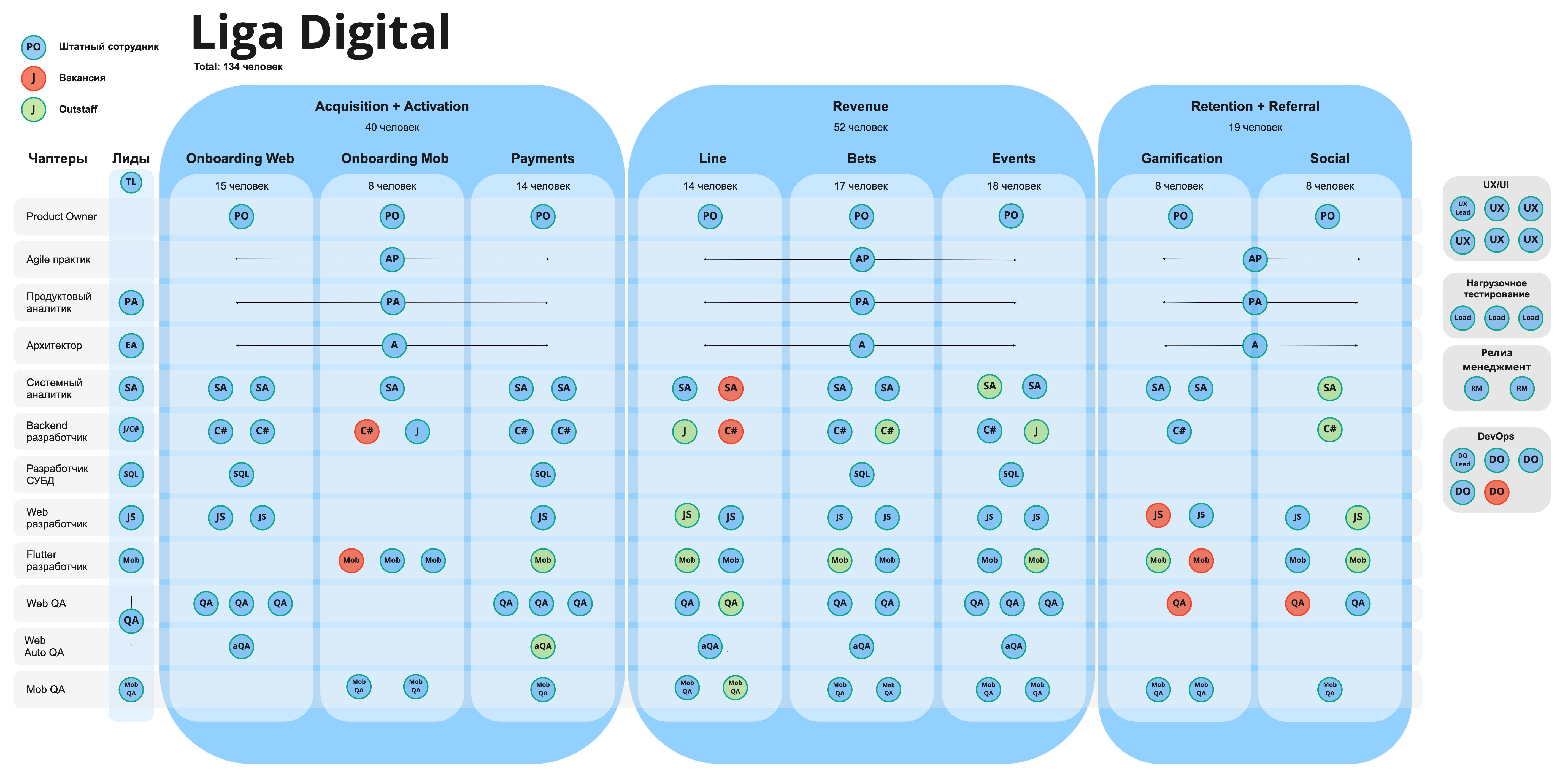
Каждая из команд укомплектована всеми необходимыми компетенциями. Все они живут в одном релизном процессе, делают задачи из одного бэклога (и проекта в Jira), и следят за одним набором метрик в Amplitude.
В условиях такого тесного взаимодействия естественным образом возникает вопрос: А как оценивать их эффективность? Об этом мы и поговорим.
Перед тем, как определить критерии оценки, давайте разберемся с тем, что же такое эффективная продуктовая команда. Все просто:
Эффективная продуктовая команда — та, которая выпускает классные (коммерчески успешные) продукты. Чтобы сделать классный продукт, нужно быстро поставлять качественные решения пользователям. То есть эффективность продуктовой структуры или команды можно оценить по двум факторам:
Как быстро бежит команда? (Time to market)
А туда ли она бежит? (Value)
Скорость команды

Для начала нужно понять, а что, собственно, мы хотим измерить в скорости работы команды. Время от идеи до релиза? Время от "взяли в работу" до "выпустили"? Давайте разложим основные этапы разработки любой крупной задачи на временную шкалу:
Генерация идеи — кто-то придумал что нужно сделать классную фичу.
Создана задача — об этой классной фиче впервые появился цифровой след, ее завели в Jira, Kaiten или Trello.
Взята в работу — та самая точка взятия обязательств командой. До этого момента работа над классной фичей по сути не велась.
Разработка закончена (Ready for Release) — все работы сделаны, фича готова к выпуску.
Релиз — релиз.
Аналитика & Обратная связь - этап, о котором многие забывают или игнорируют. Мало просто выпустить классную фичу, нужно обязательно собрать аналитику/данные/метрики и ответить на вопрос "а что она нам дала?". Может, вы ее зря делали :)
Теперь пойдем от обратного и поговорим о метриках на основе этой шкалы:
Dev Time — самая базовая единица измерения в нашей шкале. Показывает, сколько времени уходит на разработку/тестирование и подготовку фичи к релизу. Это самая честная и понятная метрика для команды, т.к. она на 100% находится в зоне ее влияния.
Release Time — сколько времени занимает выпуск готового функционала. Метрика больше для корпораций и крупных компаний. В истории, когда у тебя десятки или сотни команд, время выпуска релизов может достигать недель, и за этим показателем есть смысл следить и как-то его улучшать. В небольших командах или компаниях с низкой бюрократией и/или низким техническим легаси этой метрики может вообще не быть, т.к. время на релиз несущественно.
Cycle Time — от "взяли в работу" до "выпустили в прод". Первая из перечисленных метрик, которую можно ставить в KPI команды и мониторить ее на дашбордах. По ней видно, как быстро работает каждая из ваших команд.
Начинаем усложнять. Допустим с метрикой Cycle Time вы разобрались и даже улучшили до нужных значений.
Lead Time — следующий уровень. Сколько времени проходит от того, как мы завели задачу в бэклог до ее фактического выпуска? По опыту, Lead Time обычно кратно больше Cycle Time. И причина этому — долгое время ожидания очереди в бэклоге.
Time to Market — та самая фраза, которую вы слышите на митапах и конференциях. Научиться ее измерять — дело уже высшего пилотажа, и мало кому действительно удается. Вся сложность кроется в измерении самого первого этапа — генерации идеи. Как оцифровать тот самый момент, когда вы на совещании или по пути на работу придумали классную фичу и решили ее делать? Сколько дней или недель прошло до того момента, как эта фича появилась в бэклоге в Jira?
Time to Learn — сколько времени проходит от момента, когда классную фичу кто-то придумал до момента, когда по ней появились цифры в амплитуде. Показатель в большей степени характеризует с какой скоростью работает ваш бизнес/продукт в целом. Как быстро вы выпускаете новые продукты или проводите эксперименты?. Как быстро вы обрабатываете результаты этих запусков и делаете из них выводы? Как быстро вы потом можете обновить свои приоритеты и поменять свой курс? Этот показатель комплексно отвечает на вопрос "как быстро работает ваша компания". И разумеется, тот, кто работает быстрее — тот обычно и побеждает.
Справедливости ради отмечу, когда мы начинаем внедрять оценку эффективности команд в организации, то первым делом определяем приоритетные метрики. В нашем случае это — Lead Time, Cycle Time и Release Frequency. Мы сразу и честно себе признаем, что все что больше этого (Time to Market, Time To Learn), мы нормально посчитать сейчас не сможем, да и вряд ли сможем на них в ближайшей перспективе повлиять. Поэтому сразу убираем их из фокуса.

Далее, как технически измерить эти показатели? Очень просто — timestamp в Jira. Для того, чтобы собрать статистику по всем нашим командам, нам достаточно настроить автоматическую выгрузку из Jira нескольких временных кодов:
Дата создания задачи. Автоматически создается Jira в любой задаче.
Дата перевода задачи в статус In Progress. Также автоматически создается самой Jira.
Дата выпуска задачи в релиз. Сильно зависит от вашего релизного процесса. В нашем случае — в каждую задачу проставляется fix version. По нему определяем дату релиза и проставляем ее в выгрузке.
Тип задачи. Важно не забывать разделять метрики по типам задач и следить за ними отдельно. Ведь Cycle Time по багу нельзя сравнивать с Cycle Time новой фичи.
Итого, если настроить автоматическую выгрузку по всем этим параметрам и положить в простенький дашборд в том же Powerbi, то получаем простой, но результативный инструмент по отслеживанию эффективности ваших команд:

Скорость сжигания бэклога
Если возиться с Jira и считать метрики не хочется или не можется — есть альтернативный вариант. Считаем скорость сжигания бэклога продуктовыми командами. Метод до жути простой, но рабочий. Как говорится — "keep it simple, stupid" (принцип дизайн проектирования, принятый ВМС США).
Что делаем:
Вводим в командах любую систему оценки задач. В сторипоинтах, в часах, в штуках — как вам нравится.
В конце каждого спринта/итерации/месяца собираем два показателя: сколько планировали единиц в работу, сколько по факту выполнили. Строим из этих данных несложную таблицу или дашборд.
Наглядно видим слабые места в системе, получаем массу фактуры для работы над улучшениями.

В нашем примере мы собираем статистику по закрытым сторипоинтам в спринт каждой команды. "Сжигаются" сторипоинты в момент, когда задача доезжает до статуса Ready for Release, то есть она оттестирована и готова, осталось только выложить в прод.
Здесь важно сказать, что любую систему можно довольно таки легко обмануть. И история с оценкой метрик не является исключением. Рано или поздно ваши команды найдут способ читерить с оценками, это неизбежно. Но. Как правило, первыми способами обойти систему будут положительные под предлогами — "а давайте нарезать таски на более мелкие", "а давайте меньше брать в спринт", "а давайте оставлять временной резерв на непредвиденные задачи и вбросы". Это приводит к положительному эффекту процесса разработки. Ведь действительно, нужно лучше декомпозировать задачи, не брать в работу то, что "не лезет", и оставлять время на исправление багов.
Вывод
В первой части мы разобрались с вопросом «как быстро мы бежим?». А это - только вершина айсберга. Можно бежать очень быстро, но бежать не туда или вообще бежать в стену.
Во второй части расскажу как оценивать качество того, что создают продуктовые команды (и ответить на вопрос "а куда мы бежим?"), как правильно мотивировать их на достижение коммерчески успешных результатов в продукте.
Комментарии (4)

tt0uchq
18.08.2022 16:40Тут еще вопрос "производственного процесса", выбранного командами в Jira, который определяет этапы в процессе перевода фич/эпиков/задач из одного состояния в другой, вплоть до Ready for release. У вас единые требования здесь? Одна методология для всех? Ведь где-то могут вводить апрувы или код ревью в процесс, где-то нет, в зависимости от зрелости команды, ее квалификации. И такой момент, можно делать быстро, но не качественно, как-то оцениваете качество?

teplovden Автор
18.08.2022 17:15+1Команды живут в одном проекте в Jira, в котором запущены параллельные спринты (под каждую команду). Воркфлоу и DoD стандартизированы и едины на весь проект, то есть все команды живут в одном процессе. Но есть разделение воркфлоу под каждый тип задачи (эпики, стори, тех стори, баг, саб-таск). Впринципе любая из команд может инициировать изменения в рабочем процессе, но эти изменения должны быть приняты остальными командами.
Да, качество конечно же оцениваем. И пост-фактум по выпущенным фичам, и на этапе планирования оцениваем потенциальный эффект. На эту тему готовлю вторую часть статьи, там будет подробный разбор как мы это делаем.

funca
19.08.2022 08:52Как правило, первыми способами обойти систему будут положительные под предлогами — "а давайте нарезать таски на более мелкие", "а давайте меньше брать в спринт", "а давайте оставлять временной резерв на непредвиденные задачи и вбросы". Это приводит к положительному эффекту процесса разработки. Ведь действительно, нужно лучше декомпозировать задачи, не брать в работу то, что "не лезет", и оставлять время на исправление багов.
Выигрывая в управляемости, снижается общая производительность.
У задач есть ненулевые накладные расходы. Все это кратко растет с ростом их количества и количества контуров обратной связи.
Команды со временем учатся торговаться и попадать в оценки (ага, полезный скилл), а эффективные менеджеры - получать бонусы за удержание проекта в зелёной зоне. Цена - сдвиг time to market далеко вправо. Впрочем, вы предлагаете его игнорировать, что оставляет наблюдать кругом лишь положительные, с точки зрения данной методологии, эффекты.
DrinkFromTheCup
Эффективная продуктовая команда - та, которая справляется с поставленной перед ней задачей.
В общем случае задача - обеспечить прибыль компании.
Команда при этом может работать "в минус", может не поставлять вообще ничего, может поставлять некачественные (с точки зрения компании, не пользователя) решения раз в год от силы.
Если от этого у компании в целом прирастает прибыль - продуктовая команда справилась со своей частью задачи.
А вот и он, featurebloat driven development. Давно не виделись, здравствуй...
"Классный продукт" - это такой продукт, который за разумную цену делает свой факинг джоб.
"Быстрой поставке качественных решений" тут не место.
Например, потому, что "быстро" - это иллюзия и чистый вред. Для пользователя. А значит, продукт уже не будет "классным".
"Давно не виделись, здравствуй..." х2.
Т. е. оценки потенциальной прибыльности ЗАРАНЕЕ - НЕ ПРОИЗВОДИТСЯ.
При адекватном планировании этот этап идёт вторым пунктом, а не самым последним, когда претензии предъявлять уже не к кому.
Дальше читать не стал. Статья смердит чайкингом и скрипом уключин.