
Доброго дня, хабровчане!
Как и обещал, в продолжение своего пет-проекта по созданию грид-компонента опишу здесь создание backend части на таком фреймворке как NestJS, попутно ознакомив читателя с дополнительными инструментами для backend разработки. Код проекта найдете здесь. Статья в основном для новичков, поэтому не пытайтесь найти здесь что-то сверхъестественное.
Сразу сделаю оговорку, что я не являюсь крутым специалистом по данному фреймворку, скорее – большим его любителем. Но почему все-таки NestJS, а не какой-нибудь FastApi (Python), Spring Boot (Java) или еще какой-нибудь модный backend фреймворк, которым также пользуется прогрессивная общественность? Все просто — котики!
Обзор котиков от NestJS






P.S. можете еще поискать, возможно их там больше.
Найдете - кидайте в комменты.
Шучу конечно, хотя коты в документации очень забавные.
Первая причина заключается в том, что на основной работе приходится периодически работать с данным фреймворком, копаться в чужом говно коде, дебажить микросервисы и т.п. Ну и во-вторых — фреймворк обрел уже достаточно большую популярность, имеет хорошую документацию (кому-то было не лень перевести ее на русский) и для многих является де-факто стандартом качества разработки RESTfull веб-сервисов. Неплохая обзорная статья по фреймворку находится здесь.
Ну а теперь к делу!
Писать будем также под Linux (Ubuntu). Необходимо иметь установленным NodeJS, npm (откуда и как установить описал в первой статье) ну и как обычно — желание творить!
Содержание
Установка NestJS и создание проекта
Для тех, кто ни разу не работал с фреймворком — опишу как его установить. Так же как и для VueJS, для NestJS существует своя CLI, которая сильно упрощает и ускоряет процесс разработки. Согласно инструкций в официальной документации выполним ее установку:
Установка Nest CLI
Откроем терминал и выполним командуnpm i -g @nestjs/cli

на момент написания статьи у меня была версия 9.0.0. Вывод в терминале у Вас наверняка будет отличаться, т.к. у меня уже был установлен nest и данной командой я его просто обновил.
Перейдем в директорию, в которой будем создавать проект и выполним команду по созданию нового проекта nest new grid-component-backend:
Создание проекта и запуск приложения
Среда nest cli запросит выбрать пакетный менеджер. Я выберу npm (и Вам тоже советую) и жмем Enter:

ждем окончания процесса создания проекта:

После успешного создания проекта в терминале можно увидеть команды для запуска приложения:
")
P.S. можете задонатить и порадовать разработчиков, но я, пожалуй, пропущу этот момент =)
Давайте проверим — все ли хорошо. Перейдем в папку с проектомcd grid-component-backend и стартанем наше приложение — npm run start:

Зелененькие логи говорят о том, что все прошло успешно и по адресу http://127.0.0.1:3000 будет доступно наше приложение:

Можно останавливать запущенный сервер (Ctrl+C) и закрывать терминал. Далее будем работать с проектом в VS Code.
В качестве СУБД для нашего небольшого приложения будем использовать легковесную sqlite.
Настройка Hot Reload
Nest также предоставляет возможность каждый раз не перезапускать/билдить проект при внесении изменений. Если Вы как и я используете Nest CLI, то для настройки этой возможности достаточно выполнить следующие действия:
Установить необходимые пакеты с помощью команды
npm i --save-dev webpack-node-externals run-script-webpack-plugin webpackВ корне проекта создать файл webpack-hmr.config.js и наполнить его следующим содержимым
В файл src/main.ts добавить вот такие данные
В файле package.json подкорректировать команду для запуска проекта
Сохраняем все изменения, останавливаем проект. В дальнейшем для запуска проекта будем использовать команду npm run start:dev .
В целом...эта штука работает, но почему-то иногда выскакивают вот такие ошибки:
Вывод в консоли при запуске в режиме Hot Reload

видимо не все работает гладко, поэтому webpack иногда просит перезапустить приложение.
Для автоматического перезапуска приложения можно установить свойство autoRestart в значение true в файле webpack-hmr.config.js:

Если кто сталкивался с такой проблемой и знает с чем это связано и как это вылечить — пишите в комментариях.
Настраиваем проект для работы с sqlite
Добавим необходимые зависимости для работы с sqlite. Как сказано в документации — Nest из коробки предоставляет пакет @nestjs/typeorm для использования TypeORM в качестве работы с базами данных. Установим этот пакет, а также зависимости для работы с СУБД sqlite c помощью команды npm install --save @nestjs/typeorm typeorm sqlite3 . В файле package.json можно увидеть эти изменения.
В файл главного модуля добавим настройки подключения к нашей БД. В случае sqlite их будет не очень много:
app.module.ts
В итоге файл корневого модуля будет выглядеть следующим образом:
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { TypeOrmModule } from '@nestjs/typeorm';
import { DocumentsModule } from './documents/documents.module';
@Module({
imports: [
TypeOrmModule.forRoot({
type: 'sqlite',
database: './test_db.sqlite',
synchronize: true,
autoLoadEntities: true,
}),
DocumentsModule // А это уже импорт нашего модуля для работы с доками,
// о нем говорится в следующем разделе
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule { }
В раздел импортов мы добавили модуль (класс) TypeOrmModule, вызвав его метод forRoot() с необходимыми параметрами. Судя по типу возвращаемого значения (см. скриншот):
")
этот метод возвращает некий динамический модуль, который поможет нам подключиться к БД.
В сам же метод forRoot() мы передали тип используемой СУБД (sqlite) и путь к файлу test_db.sqlite (этот файл БД будет создан автоматически во время очередной сборки приложения), а также свойства synchronize и autoLoadEntities. Подробнее об этих свойствах можно почитать здесь.
Создание модуля для работы с документами
Приложения на NestJS имеют модульную архитектуру. Подробней можно почитать в уже приведенной мной статье (она небольшая, советую Вам ознакомиться с ней).
Каждый новый модуль по-хорошему должен храниться в отдельной папке с одноименным названием и должен быть зарегистрирован в корневом модуле приложения (файл app.module.ts). Можно все это сделать вручную, но мы воспользуемся Nest CLI, которая сделает все это за нас. Перейдем в папку с проектом и выполним команду nest g module documents:

Как видно из рисунка — эта команда сгенерировала папку documents в папке src, добавила туда файл documents.module.ts и зарегистрировала этот модуль в файле app.module.ts. Вот эти изменения.
Далее, создадим папку src/documents/entities для хранения сущностей модуля Document (хоть сущность у нас будет всего одна), а в этой папке — файл document.entity.ts со следующим содержимым:
import { Column, Entity, PrimaryGeneratedColumn } from 'typeorm';
@Entity()
export class Document {
@PrimaryGeneratedColumn()
id: Number;
@Column({ length: 100, unique: true })
cipher: String;
@Column()
createdOn: Date;
@Column()
inArchive: Boolean;
}
Не буду подробно описывать все декораторы, я думаю их названия говорят сами за себя. В любом случае Вам так или иначе придется курить доки по TypeORM для проектирования своих баз данных =).
Зарегистрируем эту сущность в модуле document:
import { Module } from '@nestjs/common';
import { TypeOrmModule } from '@nestjs/typeorm';
import { Document } from './entities/document.entity';
@Module({
imports: [TypeOrmModule.forFeature([Document])],
})
export class DocumentsModule {}Если hot reload работает нормально, то при сохранении и сборке проекта в корневом каталоге будет создан файл базы данных test_db.sqlite.
Убедимся, что в этой БД создана таблица document с необходимыми атрибутами
Подключаемся к БД
Для этого нам нужно установить утилиту sqlite3. Инструкцию по установке можно почитать здесь.
Перейдем в терминале в папку с проектом и выполним команду sqlite3 test_db.sqlite

Выполним команду .database и убедимся что мы подключились к нашей БД:

Команда .fullschema выведет нам созданную таблицу (DDL) с ее свойствами:

Так что пока все идет по плану.
Добавим в таблицу запись и выведем содержимое:

Создание контроллера и сервиса
Еще одна важная составляющая любого RESTfull сервиса — это контроллеры. Если кратко, в NestJS контроллеры нужны для хранения эндпоинтов. Простыми словами, эндпоинт — это адрес (URI), по которому Вы будете обращаться в адресной строке браузера (либо другого web-клиента, например, Postman, о котором мы еще поговорим), чтобы получить доступ к данным приложения, — например, получить все документы из БД, добавить новый документ, обновить существующий, вывести документы по определенному фильтру, удалить один или несколько документов и т.д. Вместе с адресом иногда (я бы сказал чаще всего!) необходимо передавать дополнительные параметры: заголовки, тело запроса, параметры запроса, тип HTTP-запроса и др. Совокупность всех этих эндпоинтов, их грамотное описание, — что и для чего нужно вызывать с описанием всех параметров HTTP-запроса/ответа представляет собой т.н. API-интерфейс Вашего приложения.
Мне очень нравится определение из википедии:
Если программу (модуль, библиотеку) рассматривать как чёрный ящик, то API — это набор «ручек», которые доступны пользователю данного ящика и которые он может вертеть и дёргать.
Чтобы создать контроллер — выполним команду nest g controller documents:

Мы получили на выходе файлы documents.controller.ts (сам файл контроллера) и файл для тестирования documents.controller.spec.ts, который нам не понадобится. CLI также зарегистрировала контроллер в модуле для документов и поместила все в папку с соответствующим модулем. Вот коммит этих изменений.
Однако контроллеры необходимы лишь для хранения/описания эндпоинтов. Непосредственно для реализации всей логики нам нужен еще один важный элемент Nest приложения — провайдер (сервис).
Для создания сервиса выполним, как Вы могли уже догадаться nest g service documents. Результат будет абсолютно аналогичен предыдущему, ссылка на коммит.
Data Transfer Object (DTO)
Перед тем как приступить к реализации контроллера, — создадим в папке src/documents папку dto и добавим в нее два файла:
Файл create-document.dto.ts с таким содержимым:
export class CreateDocumentDto {
id: Number;
cipher: String;
createdOn: Date;
inArchive: Boolean;
}и paging-document.dto.ts с вот таким:
import { CreateDocumentDto } from './create-document.dto';
export class PagingDocumentDto extends CreateDocumentDto {
paging: {};
sorting: {};
filtering: {};
}Подробнее про DTO можно почитать тут. Простыми словами, DTO — это вспомогательные объекты (классы), с помощью которых мы будем взаимодействовать с нашими сущностями, которые мы создали ранее в папке entities, т.е. что-то вроде трансфера между сущностями в БД и телом HTTP - запросов (в оф. документации описание DTO как раз и лежит в разделе Request payloads). Также там говорится что лучше определять DTO-объекты как классы, что мы и сделали в вышеприведенных файлах.
В create-document.dto.ts у нас находится класс для работы с документами — как Вы заметили в нем абсолютно такие же свойства, как и в сущности "документ". Класс PagingDocumentDto в файле paging-document.dto.ts наследует CreateDocumentDto и добавляет еще три свойства для пагинации, сортировки и фильтрации. Зачем они нам нужны — узнаем уже совсем скоро.
Реализация API. Dependency injection
Добавим в контроллер вот такую строчку (импортировав при этом DocumentService):
constructor(private readonly documentService: DocumentService) {}Казалось бы...какой-то конструктор. Но данной строчкой мы внедрили в наш контроллер сервис, в котором будет находиться реализация всех методов для работы с документами и тем самым применили на практике такой подход как Dependency injection. Фреймворк NestJS (и не только он) целиком и полностью построен на этом паттерне. А чтобы мы могли использовать в нашем контроллере функционал DocumentService, — он (сервис), в свою очередь, должен быть снабжен декоратором @Injectable(), который говорит о том, что сервис можно внедрять. Это уже является реализацией такого принципа как IoS, об этом тоже упоминается в документации по Nest.
Ну все, хватит умных слов....поехали дальше!
Для начала создадим два метода (роута), — GET, на который мы будем "стучаться" чтобы получить все документы из БД:
@Get()
findAll() {
return this.documentService.findAllDocuments();
}и POST для создания документа:
@Post()
create(@Body() createDocumentDto: CreateDocumentDto) {
return this.documentService
.createDocument(createDocumentDto)
.then((response) => {
return response;
})
.catch((error) => {
throw new HttpException('Произошла какая-то ошибка при создании документа =(: ' + error, HttpStatus.INTERNAL_SERVER_ERROR);
})
}На данном этапе файл documents.controller.ts должен быть таким:
documents.controller.ts
import { DocumentsService } from './documents.service';
import { CreateDocumentDto } from './dto/create-document.dto';
import {
Body,
Controller,
Get,
HttpException,
HttpStatus,
Post
} from '@nestjs/common';
@Controller('documents')
export class DocumentsController {
constructor(private readonly documentService: DocumentsService) { }
@Get()
findAll() {
return this.documentService.findAllDocuments();
}
@Post()
create(@Body() createDocumentDto: CreateDocumentDto) {
return this.documentService
.createDocument(createDocumentDto)
.then((response) => {
return response;
})
.catch((error) => {
throw new HttpException('Произошла какая-то ошибка при создании документа =(: ' + error, HttpStatus.INTERNAL_SERVER_ERROR);
})
}
}
Декоратор@Bodyговорит о том, что параметр createDocumentDto будет передан через тело POST-запроса. В нашем случае тело запроса будет в формате JSON, ключи которого будут совпадать со свойствами класса CreateDocumentDto
Теперь нам осталось реализовать методы findAllDocuments() и createDocument() для получения и создания документов, соответственно.
Вот как будет выглядеть метод для получения документов:
async findAllDocuments(): Promise<Document[]> {
return await this.dataSource.getRepository(Document).find();
}А вот так для создания:
async createDocument(createDocumentDto: CreateDocumentDto): Promise<InsertResult> {
return await this.dataSource
.createQueryBuilder()
.insert()
.into(Document)
.values([
{
cipher: createDocumentDto.cipher,
createdOn: createDocumentDto.createdOn,
inArchive: createDocumentDto.inArchive,
},
])
.execute();
}В обоих случаях мы воспользовались преимуществом async/await синтаксиса. В последних версиях TypeORM для доступа к данным необходимо обращаться к объекту DataSource для взаимодействия с БД.
Ну что, пробуем "дергать" наше API...!
Чтобы выполнить GET-запрос для получения документов достаточно открыть любой браузер и в адресную строку вставить 127.0.0.1:3000/documents. Вот, примерно, что должно получиться:

Оказывается Mozilla умеет красиво выводить JSON ответы. Это означает, что все прошло успешно и мы получили ВСЕ документы из базы данных, который у нас всего один.
Ссылка на коммит вышеперечисленных изменений.
Postman. Тестируем API и заполняем БД
Выполнить GET-запрос из предыдущего раздела в браузере не составило особого труда, но как я уже говорил выше, существуют другие типы HTTP запросов, в которые нужно передавать дополнительные параметры — тело, различные заголовки, вложения и т.д.
Наверное, самой распространенной программкой для выполнения HTTP-запросов является Postman. О том как его установить — почитаете в официальной документации. А о его возможностях есть несколько статей на хабре, например тут и тут.
Давайте выполним POST-запрос и добавим новый документ в БД. Вот как это выглядит:

cURL запроса
curl --location --request POST '127.0.0.1:3000/documents'
--header 'Content-Type: application/json'
--data-raw '{
"cipher": "7e0535f9-666e-45c4-843d-6c366a4a9d80",
"createdOn": "2019-03-18T15:49:00.000Z",
"inArchive": false
}'
Имея подобный cURL — очень легко создать запрос, просто импортировав его в Postman. В нем уже содержатся все необходимые параметры для выполнения запроса. Делается это следующим образом:
-
Нажимаем "Import":

Импорт -
Переходим на вкладку "Raw text", вставляем cURL и нажимаем "Continue":

Добавляем cURL -
На следующей вкладке нажимаем "Import":

И еще раз Import -
Бьютифицируем наш JSON:

Делаем JSON красивый Наш запрос готов. Осталось нажать кнопку "Send".
-
А чтобы создать cURL из имеющегося запроса — нужно нажать в правом-верхнем углу кнопку со знаком "</>", выбрать в выпадалке cURL и копировать готовый текст:

Копируем запрос как cURL
После отправки запроса — в ответе должен прийти id созданной записи с 201-ым кодом ответа, который говорит о том, что все прошло успешно и запись была создана:

Но что, если нам нужно добавить сотню/тысячу записей. Причем желательно, чтобы данные не дублировались. Можно, конечно, написать небольшой скрипт на каком-либо языке программирования с использованием библиотеки для работы с REST, но, раз уж мы начали изучать Postman, сделаем это с его помощью.
Массовое добавление записей в Postman
Для начала сохраним наш POST-запрос в какой-нибудь папке:

затем изменим тело запроса следующим образом:

в двойных фигурных скобках мы используем т.н. переменные окружения.
Далее перейдем на вкладку "Pre-request Script" и добавим следующий JS код:

Данная вкладка предназначена для того, чтобы добавить JavaScript код, который будет выполнен ПЕРЕД выполнением самого запроса. Тем самым мы имеем возможность задавать переменные окружения в фигурных скобках, определенные нами выше в теле запроса.
Сначала мы определили функцию randomDate(start, end), которая возвращает рандомную дату в заданном интервале (самому было думать лень, поэтому взял код отсюда).
Чтобы назначить переменной значение, необходимо воспользоваться следующим синтаксисом, который нам предоставляет Postman:
pm.environment.set("variable_key", "variable_value");Задаем переменную createdOn, передав в функцию randomDate начало и конец интервала:
pm.environment.set("createdOn", randomDate(new Date(2012, 0, 1), new Date()));Генерировать рандомное булевое значение inArchive (а почему бы и нет!) можно вот так:
pm.environment.set("inArchive", Math.random() < 0.5);Получить уникальный GUID для поля cipher можно следующим образом:
pm.environment.set("cipher", "{{$guid}}");обязательно сохраняем все изменения:

кликаем правой кнопкой мыши по папке с запросом и выбираем пункт "Run collection":
В открывшемся окне у нас имеется единственный POST-запрос, который мы добавили в папку. Т.к. у нас в БД уже есть 2 записи, зададим 98 итераций и поставим галочку напротив "Save responces" чтобы сохранять ответы (мало ли, вдруг что-то пойдет не так):

Нажимаем "Run grid-component-backend"
Если все пройдет успешно, — Postman выполнит 98 запросов по созданию записей:

Проверить наличие записей в БД можно тремя способами: напрямую выполнить SQL-запрос в БД, выполнить GET-запрос в браузере как в предыдущем разделе, либо создать в постмэне GET-запрос, который должен вернуть нам JSON-массив с добавленными документами.
Получение cURL из браузера
Покажу как можно получить готовый cURL из вкладки Network браузера для последующего импорта в Postman.
-
Запустим наш браузер (у меня Mozilla, но то же самое прокатит и для Google Chrome) нажмем клавишу F12 чтобы открыть консоль. Введем как и ранее в адресную строку http://127.0.0.1:3000/documents для выполнения GET-запроса и нажмем Enter. На вкладке Network должен появиться наш запрос:

-
Если кликнуть по нему правой кнопкой — в контекстном меню можно найти замечательную опцию Copy as cURL, которая сгенерирует вам cURL и сразу добавит в буфер обмена для последующего импорта в Postman:

Данная опция очень полезна для отладки API в готовых проектах.
Пагинация, сортировка, фильтрация
Так как записей теперь у нас в БД достаточно (целых 100, а могло быть еще больше!) нужно выводить их небольшими порциями. Вообще, пагинация — это отдельная, очень обширная тема, на которую написано немало статей. Погуглив немного по этой теме Вы увидите, что для реализации пагинации применяются в основном два стиля (синтаксиса) — skip-take и limit-offset. Но! это всего лишь два названия одной и той же сущности. Помимо этого каждая СУБД предоставляет свои штатные инструменты для постраничного просмотра данных. Вот ссылка на неплохую статью про пагинацию в Postgres, а вот официальная дока по этой теме.
Первым делом нужно понять, как лучше всего осуществить пагинацию, используя имеющуюся ORM, в нашем случае TypeORM. Давайте же спросим это у гугла, который в первой же ссылке отведет нас на стэковерфлоу. Ну все...осталось только сделать.
Добавим в контроллер следующий метод (по умолчанию POST запрос в NestJS возвращает 201 код ответа, который говорит о создании некоторой записи/объекта, но в данном случае нам не нужно ничего создавать, — нужно просто вернуть записи, поэтому добавим декоратор @HttpCodeс соответствующим кодом ответа):
@Post('/findPaginated')
@HttpCode(HttpStatus.OK)
findPaginated(@Body() pagingDocumentDto: PagingDocumentDto) {
return this.documentService.findPaginated(pagingDocumentDto);
}а в сервис, соответственно, реализацию метода:
Реализация пагинации
async findPaginated(pagingDocumentDto: PagingDocumentDto) {
let options = {
skip: pagingDocumentDto.paging['skip'],
take: pagingDocumentDto.paging['take'],
order: pagingDocumentDto.sorting,
};
const filter = pagingDocumentDto.filtering;
let filters = {};
// Цикл для динамического формирования фильтров
for (var column in filter) {
if (Object.prototype.hasOwnProperty.call(filter, column)) {
const valueToFilter = filter[column]['valueToFilter'];
const comparisonOperator = filter[column]['comparisonOperator'];
const columnType = filter[column]['columnType'];
if (valueToFilter || valueToFilter === false) {
filters[column] = this.operatorMapping(
columnType,
comparisonOperator,
valueToFilter,
);
}
}
}
options['where'] = filters;
const [documents, count] = await this.dataSource.getRepository(Document).findAndCount(
options,
);
return {
documents,
count,
};
}
operatorMapping(
columnType: string,
comparisonOperator: string,
valueToFilter: any,
): FindOperator<any> {
switch (comparisonOperator) {
case 'likeOperator':
if (['number', 'datetime-local'].includes(columnType))
return Raw(
(alias) =>
`lower(cast(${alias} as text)) like '%${(
valueToFilter + ''
).toLowerCase()}%'`,
);
// if (['string'].includes(columnType))
return Raw(
(alias) =>
`lower(${alias}) like '%${(valueToFilter + '').toLowerCase()}%'`,
);
case 'notLikeOperator':
if (['number', 'datetime-local'].includes(columnType))
return Raw(
(alias) =>
`lower(cast(${alias} as text)) not like '%${(
valueToFilter + ''
).toLowerCase()}%'`,
);
// if (['string'].includes(columnType))
return Raw(
(alias) =>
`lower(${alias}) not like '%${(
valueToFilter + ''
).toLowerCase()}%'`,
);
case 'greaterThanOperator':
return MoreThan(valueToFilter);
case 'greaterThanOrEqualOperator':
return MoreThanOrEqual(valueToFilter);
case 'lessThanOperator':
return LessThan(valueToFilter);
case 'lessThanOrEqualOperator':
return LessThanOrEqual(valueToFilter);
case 'notEqualOperator':
return Not(valueToFilter);
default:
// equalOperator
return Equal(valueToFilter);
}
}Немного комментариев.
С фронта к нам будет приходить тело запроса, содержащее необходимые параметры. Вот пример такого тела:
{
"paging": {
"skip": 0,
"take": "5"
},
"sorting": {
"createdOn": "DESC"
},
"filtering": {
"createdOn": {
"columnType": "datetime-local",
"comparisonOperator": "greaterThanOrEqualOperator",
"valueToFilter": "2016-02-11T14:44"
},
"cipher": {
"columnType": "text",
"comparisonOperator": "likeOperator",
"valueToFilter": "14"
}
}
}В объект options сохраняем данные для пагинации (skip, take) и сортировки (order):
let options = {
skip: pagingDocumentDto.paging['skip'],
take: pagingDocumentDto.paging['take'],
order: pagingDocumentDto.sorting,
};в filter сэйвим данные для фильтрации:
const filter = pagingDocumentDto.filtering;В объект filters будем динамически добавлять параметры для поиска данных в зависимости от фильтруемых столбцов и операторов сравнения:
let filters = {};
// Цикл для динамического формирования фильтров
for (var column in filter) {
if (Object.prototype.hasOwnProperty.call(filter, column)) {
const valueToFilter = filter[column]['valueToFilter'];
const comparisonOperator = filter[column]['comparisonOperator'];
const columnType = filter[column]['columnType'];
if (valueToFilter || valueToFilter === false) {
filters[column] = this.operatorMapping(
columnType,
comparisonOperator,
valueToFilter,
);
}
}
}В данном цикле мы перебираем все свойства объекта filtering из тела запроса выше и передаем их в метод operatorMapping(), который формирует нам выражение для поиска.
Для like-поиска был использован метод Raw. Причем для поиска по столбцам с не текстовыми значениями пришлось кастануть их в текстовый тип, ну и привести к одному регистру:
return Raw(
(alias) =>
`lower(cast(${alias} as text)) like '%${(
valueToFilter + ''
).toLowerCase()}%'`,
);В конце передаем все параметры в метод findAndCount, который возвращает нам найденные записи и их количество:
const [documents, count] = await this.dataSource.getRepository(Document).findAndCount(
options,
);Запускаем фронт и бэк. Что-то пошло не так. CORS
Итак, все готово — вода, кипящее масло бэк и фронт. Давайте запустим все это вместе.
Как Вы уже успели заметить — линукс установлен у меня на виртуалке. Это, честно говоря, боль! Поэтому чтобы сильно не нагружать систему — я закрою VS Code и запущу фронт и бэк в терминале.
Переходим в папку с бэкендом и запускаем его:

а теперь фронт (в отдельном терминале):

Если фронт вы делали по инструкции из первой части, то после запуска должен запуститься браузер, который отобразит грид и попытается загрузить данные. Если успеть нажать F12 и открыть консоль, то можно увидеть вот такое сообщение:
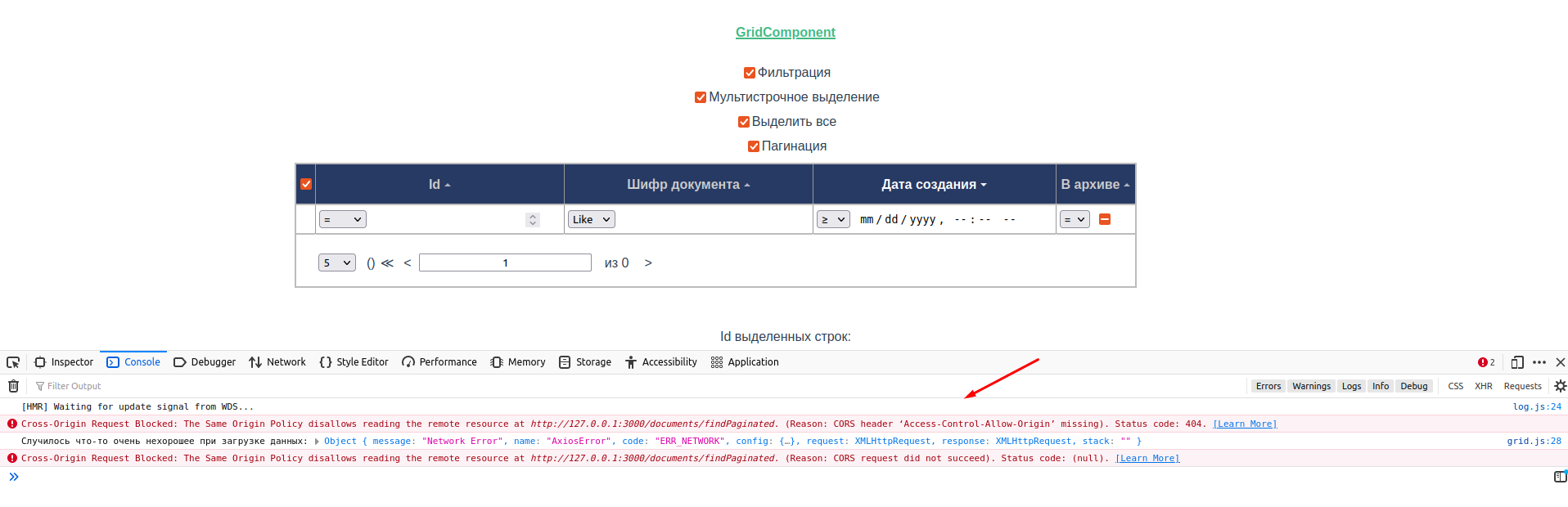
Cross-Origin Request Blocked: The Same Origin Policy disallows reading the remote resource at http://127.0.0.1:3000/documents/findPaginated. (Reason: CORS header ‘Access-Control-Allow-Origin’ missing). Status code: 404.
Попробую объяснить простым языком. Фронт крутится у нас по адресу 127.0.0.1:8080, а бэк на 127.0.0.1:3000. Т.е. используются разные источники (Origins), поэтому браузер пытается добраться до бэкенда через (cross) фронтенд:
")
но браузеры придерживаются политики одного источника — Same-origin policy (а у нас они разные, т.к. разные порты), поэтому, если не предпринять дополнительные меры, то браузер не позволит выполнить данный запрос на бэкенд.
В NestJS есть отдельная страница по CORS, на которой описано как можно доработать приложение, чтобы браузер не ругался. Есть несколько способов, — я воспользуюсь вот таким (в файл main.ts добавим следующую опцию):

Сделайте такую же доработку, запустите проект с помощью команды npm run start:dev и обновите страницу в браузере:

Отлично! Данные загружены, все работает!
P.S> Мозилла почему-то отображает элементы для пагинации слева (а по задумке должны быть справа) и галочки выровнены по центру, хотя предусматривалось, что они будут слева. Хром же отображает все как и я хотел (как в песочнице). Если есть мысли по данному поведению — оставляйте в комментариях.
Заключение
Ну вот, наконец-то...я это сделал! Однако, чтобы Вы понимали, — все что описано в этих двух статьях — это даже не надводная часть, а лишь снежная шапка, покрывающая вершину айсберга под названием Web-разработка. Наверное, где-то вот здесь:

Тем не менее, очень надеюсь, что материал этих двух статей был хоть сколько-нибудь полезным и послужит отправной точкой для изучения Web-технологий.