
Попытаюсь дать несколько советов начинающим изучать программирование и освоить профессию разработчика программного обеспечения. Возможно, некоторые из них вам покажутся спорными, у вас другой план на обучение или опыт когда удалось "войти в айти". Все рассказаное дальше субъективно, основано на моем опыте как интервьювера на Java вакансии, инженеров по данным. Надеюсь, что эти советы помогут вам стать востребованным и хорошо оплачиваемым специалистом!
Определить свою мотивацию, нишу и специализацию;
Нужно ли профильное высшее образование;
Будьте готовы, что учеба и работа захватят все ваше время и мысли;
Пишите резюме до того как еще станете тем кем планируете;
Постоянный мониторинг рынка;
Настроиться на самостоятельное изучение;
Учитесь читать технические публикации и комментарии на английском;
Учиться работе с базами данных, начните с PostgreSQL;
Быть готовым копаться в исходниках, в том числе в отладчике;
Помощь open source проектам, как портфолио и опыт;
Думайте как тестировать то что вы напишете;
Думайте как устанавливать программу которую пишете;
Начните проходить интервью дистанционно, следующий шаг - лично;
Будьте доброжелательны и просите обратную связь;
Готовьтесь что все к чему стремились окажется совсем не таким, как казалось до.
Определить свою мотивацию, нишу и специализацию
Разработка ПО это не та область где вы будете купаться в деньгах и славе. В нашем мире есть много других специальностей, где вы будете богаче, успешнее и счастливее. На заре появления персональных компьютеров шансов стать богатым было значительно больше, чем после схлопывания пузыря доткомов. На смену старателям времен "золотой лихорадки" приходят процессы из промышленности и сито акселераторов. Никто не даст вам чемодан с наличностью за туманные обещание новой "революционной шины данных" или "уникального Big Data фреймворка". Наша индустрия пытается сделать разработчиков информационных технологий легко заменяемыми шестеренками, как делала промышленная революция из ремесленников и кузнецов. Есть конечно разница в базисе, но подходы в этом стремлении те же. Что бы вам не рассказывали барышни из HR лучшую компанию в мире, про посещение курсов/участие в конференциях/плейстейшн и печеньки, воспринимайте рассказы критически. Никто выбирать выгодное направление развития и учиться кроме вас самого не будет.
Поэтому честно ответьте себе зачем вам становиться разработчиком программного обеспечения. Если ответ в том что программирование доставляет вам удовольствие, то продолжаем.
Внутри нашей профессии сотни, может даже тысячи ниш. Фронтэнд, бэкэнд, интеграционные проекты, платформы данных и т.п. Множество языков программирования, операционных систем, аппаратного обеспечения. Когда мне говорят "ты хороший специалист, нам не важно на каком языке программирования будешь разрабатывать в нашей блокчейн платформе" оказывается что требуется фулстэк разработчик, который будет писать на JavaScript, Python, Java, Go. IMHO размытие специализации понижает рыночную зарплату и увеличивает количество головной боли. Для бизнеса это выгодно, а для разработчика не очень. Так что старайтесь погружаться в популярное направление глубоко. Я не агитирую не изучать другие языки программирования вообще, скорее про то, что не стоит размывать свою экспертизу и фокус в изучении. При неверном выборе можно впустую инвестировать свое время и потом все повторится по кругу(с понижением вашего дохода).
Технический менеджмент и менеджерская стезя в ИТ компаниях совсем не простая. Вы можете пойти и по этому пути, но это совершенно другой набор навыков и софтскилов/ментальных установок. К тому же в успешных компаниях на 99.9%(исключаем из рассмотрения назначение в результате бюрократической игры или блата) вы не сможете управлять процессами и помогать людям в разработке, не обладая технической грамотностью.
Я начинал изучение с школе Basic на ZXSpectrum, в старших классах на персоналке уже погружался в C, в университете основными были Pascal и C++, дипломная работа на Java (приправленна XSLT трансформациями). На компьютерном кружке в школе изучал FoxPro, в университете перешел на MySQL, с первой работы после универа не могу расстаться с PostgreSQL, хотя в проектах часто были и Oracle и MSSQL.
Каждый кулик хвалит свое болото, одна из причин почему я за Java и PostgreSQL. Хотя, наверное, это больше чем язык программирования и база данных: оба средства свободные, кросплатформенные и в них инвестировано такое количество человеко часов, с которым вряд ли сравнятся еще какие-либо open source проекты. Здесь развитая экосистема, доступная документация, профильные конференции и экспертиза сообщества.
Нужно ли высшее профильное образование
Скорее нет, чем да. В университете дают некоторые фундаментальные знания, много вещей вширь. Большая часть из того чему нас учили мне не пригодилась. Главное научили учиться и обрабатывать большой поток информации.
С благодарностью вспоминаю что вник и сделал лабораторную по "ЭВМ, системы и сети". Там было распреленное Pascal приложени, которое брало данные и сохраняло результат по канувшем в лету NetBIOS под DOS. Так вот с помощью тех же принципов, когда-то давно спасал поврежденные данные в результате сетевых ошибок и то как после них восстанавливался HDFS в Hadoop на заре своего появления. Приложение было написано за 4 часа днем в субботу, запущенно копировать что возможно. Получил тогда за чудесное спасение данных около 400$ премии.
Вы станете хорошим программистом и без 5/6 лет университета, если вам интересно программировать и самообучаться. Но могут возникнуть сложности при приеме на работу или получении рабочей визы - почти всегда требуется подтвердить свою "айтишность" в случае релокации. Для кого важна стабильность, то без диплома будет почти невозможно попасть в корпорации и стать государственным служащим.
Будьте готовы, что учеба и работа захватят все ваше время и мысли
Нет, серьезно! Я рад за тех, кто тратит только рабочее время на работу, но разработка ПО захватывает все ваше свободное время, особенно если вы хотите приблизиться к совершенству своих знаний и умений. Вы можете не соглашаться, писать про противоположное в комментариях и как кому-то повезло попивать смузи, разъезжая на красном Ferrari.
Постоянно появляются новые фреймворки и технологии. Этот процесс не для того чтобы вы суетились, как хомяк в колесе бесцельно и активно. Прогресс не стоит на месте, чтобы решать задачи быстрее и дешевле. Поэтому вам прийдется пропускать через свой мозг мегабайты технических текстов, чтобы извлечь зерна ценного.
Мнение, высказанное в комментарии к моей прошлой публикации на Хабре, имеет место быть и у вас должна быть сильная мотивация чтобы не отступить на язык Basic и учиться только в рабочее время, и только когда вас обучают. Я все же процитирую это здесь, даже поставил плюс на этот коментарий:
Так и зачем же нужна эта Arrow?
Если кто-то хочет прочитать 200 гб данных и извлечь из них последовательно расположенную информацию - самых примитивных средств вполне достаточно. Грубо пара гб в минуту дают нам 100 минут на весь объём. Это час сорок. Программу написать - ну ещё час сорок с отладкой и экспериментами. Итого - три двадцать на всё.
Считаем про эту Arrow. Надо лезть на их сайт и чего-то читать. Потом качать и чего-то пробовать. И да, если поверит автору, то нужно сходить ещё в несколько мест, куда он ссылки развесил, и там почитать, чего-то скачать, попробовать. И ради чего? А просто - модная технология. Пару дней на изучение всего с ней связанного. А может и больше.
Итак, три часа против 2-3 дня возни непонятно с чем, о чём автор даже не захотел рассказать подробно.
Вопрос - зачем? Сколько ещё детей не наелось этого хайпа? Сколько гигабайт ненужного хлама дети теперь потянут в свои проекты из-за такой бессмысленной рекламы? Нет, не бессмысленной, а вредной! Вместо часов предлагается тратить дни! Просто так, потому что кому-то захотелось заняться рекламой Arrow.
Как разработчик вы обязаны уметь отличать просто хайп от стоящих технологий, а для этого надо тратить свободное время на изучение! Нет единого верного пути, как пытались раньше убедить крупные корпорации принимающих решение ИТ менеджеров, предлагая свои продукты. У каждой технологии есть сильные стороны, область применимости и свои ограничения.
На "своей шкуре" испытал что учиться приходиться постоянно. Бывают периоды передышки, но на длинной дистанции это мой марафон а не спринт! Больше всего сил на изучение я потратил в университете и в первые годы работы. И не потому что было сложно, а потому что постоянно "набивал шишки" на банальных вещах - какие зависимости нужны например для Hibernate ORM или почему spring первой версии не управляет транзакциями как я ожидал при их декларативном объявлении, почему в проекте несколькими десятками модулей с сотней зависимостей возникают java.lang.NoSuchMethodException при запуске и т.п. Сейчас людям гораздо проще найти ответ на конкретный вопрос на stackoverflow, но без понимания что под капотом вы не сможете найти ответ на нестандартный вопрос, именно в вашем окружении из конкретных версий на конкретной платформе и задаче. Многие технологии(и почти нет исключений) в мотивационных статьях и обзорах не раскрывают какие баги и демоны у них под капотом, какие ограничения. И будет очень печально, когда что-то из этого помешает вам в последний момент перед сдачей проекта. Мне часто приходилось и приходится фиксить баги в используемых технологиях будь то Oracle Coherence или Dremio.
Понятно, что все время вы не сможете учиться и "поедете кукухой". Но поверьте, после отдыха, отпусков вам все равно придется уделять много сил самообучению. Будьте готовы жить новой работой, либо войдя в область, где-то свернуть по менеджерскому пути и бесить своих бывших коллег неосведомленностью и диктатом. Правда сработает это не во всех компаниях и не для всех людей такой переход возможен.
Ну и как последний аргумент, что люди, ненавидящие свою работу чаще тратят деньги на консультации психологов и винят родителя(ей) в своей судьбе. Вы будете чувствовать себя счастливым только если вам нравится то, чем вы занимаетесь и получаете от этого не только финансовую отдачу!
Пишите резюме до того как еще станете тем кем планируете
Серьезно, подавите в себе синдром самозванца и рассмотрите этот как маркетинг. Вы не пройдете фильтр HR персонала с плохим резюме, вашу кандидатуру отметут интервьюверы если у них есть выбор из десятка резюме. Мой совет - работаейте над личным брендом до его реального появления! Вспомите о фокусе и узкой специализации, постарайтесь уместить всю информацию в 1-2 страницы. Укажите то, куда стремитесь и улучшайте резюме - это итеративный процесс, основанный на обратной связи от интервьюверов и кадровых специалистов. Если откладывать составление резюме до времен, когда вы станенте экспертом в своей области, то значит не составлять его вообще.
Я составил резюме на 3 курсе универа, когда еще не знал о чем в нем пишу. Я нашел то что требуется и куда мне интересно развиваться по вакансиям на сайте monster com
Это замкнутый круг: чтобы получить опыт нужно много работать над проектами которые вам помогут развиваться, но чтобы работать нужен опыт. Разорвите эту циклическую зависимость составлением резюме ваших желаемых навыков и пусть оно будет вашей roadmap, которую будете "рихтовать" в процессе погружения и "пинков" после собеседований.
Постоянный мониторинг рынка
Опять же итеративный подход никто не отменял. Может так оказаться, что вы изучаете и стремитесь "в закат". Есть конечно аргумент что разработчики на Кобол будут нужны всегда. Но все же, постоянно следите за текущими трендами, попытайтесь смотреть где еще надо "подкачать ваши мышцы".
Этот совет отностится не только к новичкам! Вполне может быть так, что зарплаты на рынке выросли уже почти вдвое, а вы разбиваете лоб об стену и нанимаете людей дороже вас, участвуя в бессмысленных для вас корпоративных играх по стахановскому перевыполнению KPI и следованию HR процессам.
Как я это делаю. Хожу по собеседованиям, даже если меня все устраивает в данный момент. Как минимум я поддерживаю свой тонус, так как интервью это практический навык. Знакомлюсь с новыми людьми и трендами на рынке, понимаю как другие специалисты решают похожие на ваши рабочие задачи. Да, предвижу критику, что это нечестно. Но с другой стороны, при резком изменении ситуации, реорганизации или банкротстве фирмы у меня всегда актуальны навыки, нужные для поиска работы. Если все идет хорошо, то опять же вы расширили свои знания о том как лучше или по другому решать те же ваши рабочие задачи и организационные проблемы. Всегда знаешь сколько готовы предложить на рынке с вашими навыками. Много новой и полезной инфомации.
В этом подходе есть риски что вас запишут в нелояльные сотрудники, будут вам искать замену или не продвигать дальше по карьерной лестнице. Думайте сами, решайте сами как вам лучше мониторить рынок не во вред себе.
Настроиться на самостоятельное изучение
Да, курсы вам могут помочь двигаться в нужном направлении. Но камон, это не начальная и средняя школа, где вас в любом случае научат и выпустят во взрослую жизнь! Кроме вас никто не будет учиться. И умение учиться и самосовершенствоваться важнее десятка корочек о повышении квалификации или курсов от учебных центров.
Мы живем в мире, где доступны терабайты отличных учебных курсов для самостоятельного обучения. Но к сожалению в совершенстве владеющими эсперанто и русским, большая часть профильной литературы на английском языке. К этому мы вернемся в следующем разделе.
Книги с обзорным материалом могут и должны быть точкой входа и направлением. Но чтобы разобраться во всех тонкостях и закрепить навык вам прийдется свой писать код, а потом "проваливаться" в код фреймворков из отладчика, читать коментарии в чужом коде, искать статьи других разработчиков и авторов технологии которую вы изучаете.
Я начинал с брошюр по Basic напечатанной на матричном принтере, потом читал "Язык программирования Си" Кернигана и Ритчи, в университете были лекции и книги из библиотеки. Но самое ценное, что я качал по dial-up соединению модемом конкретные статьи интересующим меня вещам из C++, XSLT трансформации с zvon org. Это все была затравка, чтобы сесть вечером за компьютер и писать код. Помню как мой мозг трещал когда я начал подключаться по COM/OLE к фотошопу из C++ программы. Тогда я потратил не одну неделю тогда чтобы автоматизировать рутину своей работы в фотолаборатории, чем я подрабатывал на жизнь в то время. Позже структурировать информацию о всем том что я узнал из самообучения и практики мне помогла книга "The Pragmatic Programmer".
Из последнего что спасло мне и моим бывшим коллегам ученым по данным море времени по автоматизации рутины в документировании проект тоже было результатом моего обучения и экспериметов в свободное время с open source schemaspy. Документация структур данных это тоже артефакт и часть проекта, сильно упростило введение в дело новых людей с других отделов, кто искал нужные данные в почти трех сотнях таблиц AWS Redshift/Spectrum. И для первоначального наполнения этой документации я написал парсер, который из метаданных и C++ кода проекта другого отдела извлекал информацию по клиническим мерам и алгоритмам их расчета. Потому уже коллеги вычищали и расширяли это в ручном режиме.
Нет, я совсем не против толковых курсов!

Если вы ожидает что вас научат в рабочее и учебное время, то вы глубоко заблуждаетесь. Этот пункт как и ваша мотивация - воспринимайте как аксиому!
Учитесь читать технические публикации, комментарии на английском
Для кого-то это кажется непреодолимым барьером, но это факт. Чтение публикаций на английском вам необходимо, только если вы не программист на платформе 1С!
Мне помогло чтение документации со словарем, опыт перевода статей в университете. Заговорить хоть как-то я смог только в туристических поездках за границу, потом были командировки в Лондон больше десяти лет назад, где я работал больше месяца - тут без вариантов, языковой барьер пришлось сломать. Не могу назвать свое знание идеальным, но мне хватало моего рунглиша для выступлений с докладами на конференциях, чтения документации, участия в митингах и архитектурных комитетах на работе с коллегами из разных стран. Еще ковид заставил расширить словарный запас связанный с океаном и общаться с нейтив спикерами и новыми друзьями по хобби на едином для нас всех английском языке( я не говорю на немецком, испанском, тайском, дивехи, индонезийском).
Мой совет - просто говорите и читайте, не пытайтесь выучить идеально до этого. Это исключительно практический навык, иначе никак. Я не знаю таких людей кто знает английский идеально, но знаю нескольких рускоговорящих людей, которые пытались придраться к моему уровню. Иностранцы вряд ли будут насмехаться над вами!
Учиться работе с базами данных, начните с PostgreSQL
Данные в компьютере обычно живут дольше приложений, которые создали, чтобы их собирать и обрабатывать. Поэтому схему данных в крупных проектах нужно документировать лучше кода и уметь визуализировать. С каждым годом хранилища данных благодаря прогрессу дешевеют и уменьшаются в размерах на единицу хранимой информации. Если в 70х годах прошлого века хранилище на сотню мегабайт было размером с огромный шкаф, то сейчас в этот же объем уже уместятся петабайты данных. К тому же, благодаря твердотельным накопителям с интерфейсом NVMe время доступа сократилось на порядок по сравнению с жесткими дисками. Все больше и больше данных хранится теперь все дольше и дольше. Сбор и обработка всех возможных данных и их хранение в "озерах данных" теперь тренд, а не только удел интернет поисковиков. Для работы с данными важна какие структуры используются и как эти данные обрабатываются. Это не значит что вам срочно надо перечитать все что написал Дональд Кнут и срочно разработать свою программу, за вас это уже сделали разработчики баз данных. И если погружаться в устройство баз, то только число методов сортировок данных в разных контекстах/случаях удивит вас. Обычно разработчикам не нужно писать новую СУБД, а нужно уметь использовать то богатство выбора готовых рашений, что у нас есть, и понимать их ограничения.
Как же много я слышал про "убийц" объектно-реляционных баз данных. Приходилось работать с key/value, document oriented database, massive parallel processing, in memory database. Даже есть байки в практике про "успешные" замены хранилища данных на HBase, MongoDB. Как говориться, кто управляет программистами, тот их и танцует.
Но к счастью, PostgreSQL, сам собой сшивает красной нитью все мое портфолио. Не только потому что фанат, потому что архитектура и принципы положенные в основу этой СУБД опережали свое время. К тому же огромное сообщество и наши соотечественники Олег Бартунов, Фёдор Сигаев и сотоварищи, постоянно улучшают базу позволяя ей эволюционировать и работать в этом суровом мире с петабайтами данных. Хотя СУБД орентирована на работу с транзакционными данными(OLTP), это не мешает после "доработки напильником" быть распределенной колоночной СУБД, расчитаной на аналитические запросы(нишу OLAP). AWS Redshift - это форк постгреса 8.х версии 2005 года (я проработал с ним четыре года и могу сказать хорошее со стороны пользователя и администратора БД, но со стороны разработки это адище), форк Greenplum c большим трудом подняли до 9.х ветки постгреса, PG-Strom работает на 13 версии постгреса и запускает обработку на графических ускорителях Nvidia через CUDA, а Citus пытается их догнать на последних релизных 14.х версиях PostgreSQL за счет реализации только как расширения для этой БД. Трюк с декларативным партиционированием данных в PostgreSQL позволил мне использовать PostgreSQL в AWS RDS БД в несколько терабайт и не менять БД под решением из-за значительно возросшего объема данных в системе, без смены модели данных. В Redshift проекта хранится больше 25Тб данных и новые источники данные, не требующие высокого быстродействия и необходимые для сверки и обогащения данных моделей, были подключены через внешние таблицы Redshift Spectrum(на основе Hadoop) из объектного хранилища в S3, данные сериализованы как parquet файлы. И запросы все так же доступны по протоколу PostgreSQL из Redshift.
К текущим пока сложно решаемым проблемам PostgreSQL как платформы относится сложность векторизации кода для использования SIMD/GPGPU, а это ограничение текущей структуры данных на диске(это пытаются обойти в PG-Storm за счет того что запросы на Apache Arrow данных, доступных БД на CPU, также доступны и для загрузки в память GPU и обработки там минуя процессор через NVIDIA GPUDirect Storage). Отсутвие в ядре возможности для массивно параллельной распределенной обработки данных. Минусом для колоночных БД, которые стремяться использовать проект - отсутствие в проекте оптимизатора для колоночных данных и аналитических запросов, то что пытались решить в ORCA. Подключаемые движки хранения (pluggable storage)уже помогают постгресу на пути в его будущее. Ограничения отодвигаются от релиза к релизу!
Разработчики Apache Spark SQL признают что PostgreSQL одна из лучших SQL систем и пытаются использовать это в своих тестах. Так что не MPP единым. Даже сетевой протокол PostgreSQL настолько популярен и используется в таком количестве систем, что его эмулируют современная распределенная база данных CrateDB и база данных для работы с данными временных рядов QuestDB.
Для визуализаций существующих огромных схем почти любых баз данных с JDBC драйвером я использую условно-бесплатный DbVisualizer и польностью открытый SchemaSpy.
Если вам нужна работа с гео данными, то PostGIS - расширение к постгресу спешит на помощь, если нужен полнотекстовый поиск и встроенных средств в базу уже не хватает, то можно использовать расширение ZomboDB, которое автоматически поддерживает актуальность полнотекстового индекса в Elasticsearch и позволяет использовать эти индексы из запросов в PostgreSQL. Устанавливаемые расширения правят балом в этой СУБД!
Ну и вишенка на торте - отличная документация и море рускоязычных учебных материалов на хабре и бесплатных, доступных к скачиванию книг от Postgres Professional.
Быть готовым копаться в исходниках, в том числе в отладчике
Какой бы актуальной не была документация по технологии, которую вы решили использовать или реализации компилятора языка(и/или виртуальной машины) на котором вы пишете вам рано или поздно придется погрузиться в чтение исходников, возможно и в отладку. Это будут самые актуальные, но не самые легкие в получении, знания.
Я разбирался с многими особенностями Spring framework, CGLIB, AspectJ именно таким образом. На одной проекте я работал с коллегой, которому компания оплатила курсы по Spring от SpringSource за пару тысяч $, это было где-то 2008-10 году. И мне было крайне приятно получать от него похвалу, когда я помогал ему с его "затыками" со спрингом. Позже я даже побыл контрибьютором в устранении техдолга в Spring Boot/Spring Framework.
Этот навык лучше других научит вас читать чужой код, что крайне ценно в нашей работе. Понимать как и что изменять во фреймворке, если вы решили добавить нужную фичу и не дожидаться несколько лет, когда сообщество отреагирует на ваш запрос на новый функционал.
Конечно код коду рознь. И возможно, когда вы выйдете на проект, то останетесь один на один с кодом тех людей, которых в этой компании давно уже нет. Здесь у вас будет выбор бежать или сражаться! К сожалению адекватные и оплачиваемые Greenfield project это большая редкость и даже если вам удасться создать такой, а не будете ли вы потом стыдиться своего кода? Чтение кода популярных и качественно написанных open source проектов может привить вам чувство прекрасного и понимание возникающих при реализации компромисов.
Например, для тех кто считает слишком сложным пример работы с Apache Arrow/Parquet могу предложить более простое и лаконичное решение, но чтобы написать его, все равно надо перерыть кучу исходников, подебажить JDBC драйвер DuckDB(из-за ошибки в параметризации PreparedStatement) и написать на Java так чтобы обойти эту ошибку:
package com.github.igorsuhorukov.arrow.osm.example;
import java.sql.*;
public class CalculatePlaceOfWorshipBuilding {
public static void main(String[] args) throws Exception {
if(args.length!=1) throw new IllegalArgumentException("Specify source dataset path for parquet files");
String sql = "SELECT count(*) FROM parquet_scan('"+args[0]+"') where closed and " +
"(tags['building'][1] in ('church','cathedral','chapel','mosque','synagogue','temple','font')" +
" or (tags['building'][1] is not null and " +
"(tags['amenity'][1]='place_of_worship' or tags['religion'][1] is not null)))";
try (Connection connection = DriverManager.getConnection("jdbc:duckdb:");
Statement pragmaStatement = connection.createStatement();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
//preparedStatement.setObject(1, args[0]); issue with JDBC driver. Query return: Not implemented type: UNKNOWN
pragmaStatement.execute("PRAGMA enable_profiling");
try (ResultSet resultSet = preparedStatement.executeQuery()) {
if (resultSet.next()){
System.out.println(resultSet.getLong(1));
}
}
}
}
}
Для запуска добавим зависимость на встраиваемую в процесс базу данных DuckDB. Эта база данных несмотря на свой юный возраст уже умеет много и скоро сможет обогнать clickhouse-local по удобству и близости SQL диалекта к PostgreSQL.
Исходный код примера доступен здесь. Но чтобы мне не было скучно повторяться, теперь мы посчитаем сколько в мире, по данным OpenStreetMap зданий, помеченных как религиозные объекты. Исходные данные для примера - OpenStreetMap planet-220704.osm.pbf преобразованы в 188,2Гб сжатых zstd Parquet файлов. Для удобства чтения, выделил запрос:
SELECT count(*)
FROM parquet_scan('/ways_parquet/*/data.parquet')
where closed and
(tags['building'][1] in ('church','cathedral','chapel','mosque','synagogue','temple','font')
or (tags['building'][1] is not null and
(tags['amenity'][1]='place_of_worship' or tags['religion'][1] is not null)))Результат этого запроса и программы: 867023
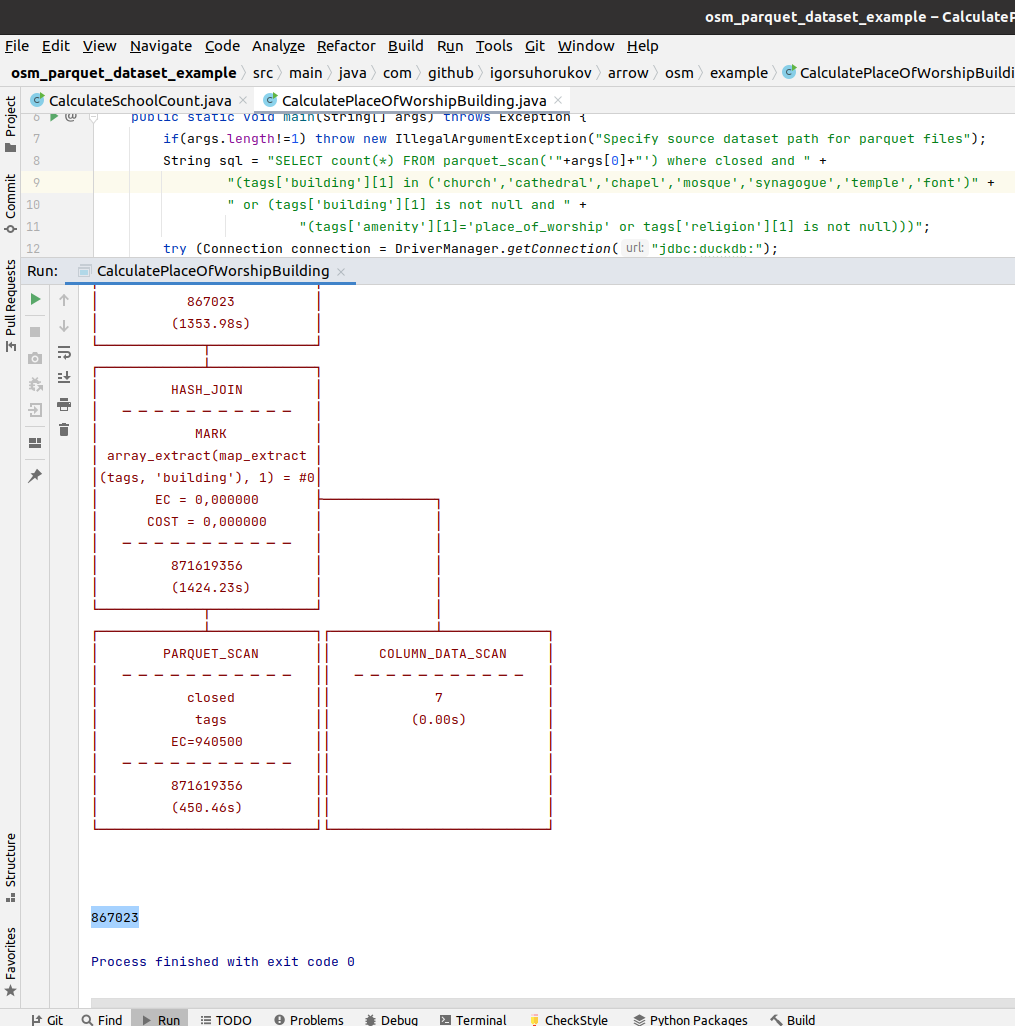
План выполненного запроса на ноутбуке с 16Гб ОЗУ и M.2 накопителем Samsung 970 EVO Plus
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Total Time: 407.14s ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌───────────────────────────┐
│ RESULT_COLLECTOR │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ 0 │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ UNGROUPED_AGGREGATE │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ count_star() │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ 1 │
│ (0.17s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ FILTER │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ (closed AND (IN (...) OR (│
│ (array_extract(map_extract│
│(tags, 'building'), 1)... │
│ NULL) AND ((array_extract│
│(map_extract(tags, 're... │
│ '), 1) IS NOT NULL) OR │
│ array_extract(map_ext... │
│ 'amenity'), 1) = │
│ 'place_of_worship')))) │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ 867023 │
│ (1353.98s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ MARK │
│ array_extract(map_extract │
│(tags, 'building'), 1) = #0│
│ EC = 0,000000 ├──────────────┐
│ COST = 0,000000 │ │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │ │
│ 871619356 │ │
│ (1424.23s) │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ PARQUET_SCAN ││ COLUMN_DATA_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ closed ││ 7 │
│ tags ││ (0.00s) │
│ EC=940500 ││ │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ││ │
│ 871619356 ││ │
│ (450.46s) ││ │
└───────────────────────────┘└───────────────────────────┘
Ближайший аналог этой конструкции профилирования запросов DuckDB в PostgreSQL: EXPLAIN ANALYZE
Недостатки этого кода - это невозможность здесь использовать параметризированный запрос, что может привести к SQL injection. Но мы с вами все равно знаем и понимаем что такой код нельзя выставлять наружу, как сервис или часть приложения.
Помощь open source проектам, как портфолио и опыт
Мне этот пункт, честно, не сильно помогал при прохождении интервью в РФ. HR используют amazinghiring и похожие системы реагирующие на ваши пул реквесты, но на сам код обычно никто не смотрит, даже технические интервьюверы.
Когда я собеседовал на вакансии, то смотрел если были ссылки на Github/Bitbucket из резюме. И один раз этот фактор сыграл большим плюсом коллеге с минимальным опытом Java разработчика, но с pet проектом, как фактор заинтересованности программированием и стремлением к самообучению. Мы сделали ей предложение о работе и она продуктивно работала на проекте.
Лично я поучаствовал как контибьютор в Spring Boot/Spring framework, H2, Schemaspy, Elasticsearch, osm-parquetizer, instagram-java-scraper, Apache Arrow, QuestDB. Считаю грамотным вносить в upstream используемых библиотек улучшения, чтобы не плодить форки. Но в этом правиле тоже есть компромисы - насколько заинтересован проект в ваших изменениях, насколько оперативно и насколько честно он работает с сообществом.
Участие в разработке open source - как фильтр часто недооценивают нанимающие, так как изменения в популярные проекты( больше 1К звезд, например) принимают только при должном качестве реализации и покрытии тестами. То есть человек обладает навыками коллективной работы, проходит code review, пользуется современным инструментарием и следует принятым в проекте практикам кодирования. А эйчары воспринимают таких людей иногда как потенциальную жертву готовую перерабатывать на проекте без должной компенсации, этакого "доброго самаритянина". Но пожалуй стоит разделять проприетарные проекты со спринтовой соковыжималкой соков и светлое и перспективное для коллег по цеху. Вообще я против выжимки всех соков из работников. У программистов должно быть время на развитие и на свежий, не замыленный взгляд на работу. При загрузке в 150% это вряд ли возможно и специалист быстро выгорает, получая к проекту отвращение. Формально бизнес доволен, а реально при замене специалиста ухудшается производительность команды из-за временных ресурсов на онбординг нового человека, качества кода и принимаемых проектных решений. Об этом обычно менеджмент не думает. Тщетность формальных метрик по измерению пользы от программиста не работают, про одну такую историю рассказывал в "Как изменение двух строк кода может занять несколько дней".
Если хотите разорвать замкнутый круг: где найти опыт работы, а на работу вас не берут без опыта, то присмотритесь к open source проектам. Там часто есть задачи до которых не доходят руки у основной команды и наиболее активных контрибьюторов популярного проекта. Это может быть документирование кода, улучшение тестов и их покрытия, работа с тех. долгом.
Думайте как тестировать то что вы напишете
Сложно заставить писать себя юнит тесты, но еще сложнее протестировать в связке все готовое решение, написать end to end тесты которые включают UI или базу данных, с шиной сообщений и внешними по отношению в вашему проекту системами. Тут нет золотой пули, каждый раз приходится ломать голову как это можно покрыть автотестом. Особенно весело это когда вы используете облачный сервис, которого нет в open source и который выставляется уникальным решением облачного провайдера.
Мое хождение по граблям автоматизации "Эмуляция Amazon web services в JVM процессе". Я рекомендую использовать инверсию управления( IoC) при реализации, абстракции и фасады в приложении, где это возможно, чтобы упростить тестирование проекта. Пример как использовать webdriver когда-то рассказывал в "Что нам стоит сайт распарсить. Основы webdriver API".
Selenium WebDriver хорошо подходит до тех пор, пока не надо распознавать картинки со страницы, чтобы выполнить нужное действие. Поэтому надо думать о тестируемости интерфейса еще на этапе разработки, чтобы не пришлось обучать нейросети или адаптировать систему машинного зрения в тесты.
Тестирование базы данных тоже не простой момент, но кроме логики работы приложения вам возможно придется еще тестировать и миграции схемы БД. Для каких-то тестов можно заменить реальную базу на H2, а вот где-то прийдется поднимать и настоящий постгрес в докер контейнере, в этом если вы пишете на Java поможет Testcontainers. Остается непростой выбор, как вам эмулировать внешние сервисы для вашего проекта.
Думайте как устанавливать программу которую пишете
Для работы вам прийдется еще разбираться с способами установки для облачного провайдера или инфраструктуры вашего работодателя. И этот пункт перекликается с end to end тестированим. На все что запускаете вне юнит тестов, вам надо развернуть автоматически в каком-то тестовом контуре и запустить сценарии. За это в крупных компаниях обычно отвечают DevOps/CloudOps специалисты, но не исключено что вы будете приходить к ним со своим прототипом, иначе вас могут просто развернуть туда откуда пришли. Даже наличие выделенного специалиста в команде не отменяет вашего глубокого погружения и активного участия в автоматизации. Готовых рецептов здесь нет. Стандартом де факто является Terraform из за его возможности работать в разных средах для развертывания решений. Но принятые и разрешенные к использованию средства для развертывания и управления инфраструктурой могут сильно вас сковать по рукам!
Я не силен в terraform, но активно читал и правил скрипты на нем, помогал CloudOps делать первоначальное решение, дебажил consul конфигуратор для spring boot. До этого настраивал на проекте сбор логов в Elasticsearch(ELK) и zipkin для трассировки между компонентами проекта. Лет 8 назад я активно использовал NanoCloud (и испралял некоторые ошибки) в нем для тестирования in-memory JVM data-grid на основе Coherence. Особое наслаждение было копаться с настройками Jumbo-кадров в linux, запускать тесты для UDP протокола и выводить команду сетевиков на чистую воду, играющих в пин понг с моей командой. Также было приятно узнать что мою сборку groovy-grape-aether используют в проде достаточно крупного проекта в организации в которой я не работал, чтобы "тащить" зависимости из репозитория. А точнее, есть хадуп, и на нем Oozie, и она запускает Spark. А у него куча разных настроек, которые определяются при старте, из разных источников. Поэтому груви играет роль продвинутого bash, доставая конфиги из HDFS, например. Поэтому Oozie запускает груви, а груви уже готовит почву для спарка, и стартует его.
Как бы вы не хотели, вам прийдется вникать в установку проекта и всех его компонент, тюнить параметры системы, JVM, сети, спускаться на физический уровень или на уровень инфраструктуры, когда надо выжать все возможное для производительности из доступного.
Если вы посмотрели на все это и даже не знаете еще как скачать и запустить IDE компиляторы и зависимости для своего первого Hello world проекта, то в этом случае все что я могу посоветовать - сделать первый шаг без установки/настройки и попробовать open source облачную IDE Eclipse Che
Начните проходить интервью дистанционно, следующий шаг - лично
Этот совет такой же как и с изучением английского. Как бы вы хорошо не знали свою работу и программирование, но хорошие вакансии и зарплаты - результаты навыка прохождения интерью.
Я предпочитю встретить лично на финальном интервью человека, с которым предстоит работать на проекте, но это было в доковидную эру найма. Сейчас это несколько сложнее.
Если есть возможность первое интервью лучше проходить удаленно. Вам это поможет не так волноваться, как при личном собеседовании. Интервьюверу же сильно сэкономит время - он может досрочно прекратить собеседование, если решит что в этом нет смысла. И это взаимно честно, так как вы к тому же экономите время и деньги на дорогу!
Будьте доброжелательны и просите обратную связь
Кто же захочет давать злыдню обратную связь. Хотя однажды я рассказывал даже такому кандидату почему ему не сделали оффер. Многие из тех кто не проходил интервью не ожидали что им ответят на их просьбу. Считаю фидбэк не тратой времени, а платой за наше общее время потраченное на интервью и возможность человеку улучшить свои знания(если он конструктивно воспримет свои недочеты). Эйчары не любят тратить свое время и время технических специалистов на такие вещи, хоть и пообещают вам до этого. Кадровые специалисты еще опасаются что фидбэк с причиной отказа можно использовать против работодателя им проще ответить шаблоном одним на всех кандидатов "будем рады рассмотреть вас в будущем". Опять же для рекомендуемых мной кандидатов в другие отделы, когда замалчивали, я ходил и собирал обратную связь face to face с теми кто принимал решение об отказе.
Готовьтесь что все к чему стремились окажется совсем не таким, как казалось до
И вот вы обучились чему планировали, вышли на работу и обнаружили что это не то что вам описывали на самом деле, что важные для комфортной работы вопросы остались не обговоренными или не заданными вами. Ну что ж, сочувствую, но так бывает. Терпи/вникай, договаривайся или беги. Опять же этот опыт и иначе его никак не получишь. Рынок нужных и толковых специалистов за предлагаемые деньги не безграничен, бывает обе стороны лукавят на интервью или что-то выясняется прямо на месте.
Пару раз я попадал в ситуации, когда даже не отдавал трудовую книжку. В том контексте до сих пор считаю что правильно сделал. Как "Fail fast fail safe" принцип не только в компьютерной системе, но и в своей жизни. Был другой случай, когда просил после интервью показать код проекта, в котором многое было готово уже в коде, со слов директора. Для этого пришлось подписал кипу соглашений о неразглашении, но мне исходники его так и не показали, а устроили презентацию и знакомство с коллегами. Когда в первый рабочий день я увидел "это", то засучил рукава, разгебая те Авгеевы конюшни, параллельно обучая коллег и внедряя практики разработки, и не пожалел после. Те люди с которыми работал оказались отличными коллегами и я научился кое чему новому для себя, не только и не столько в плане технологий. Тот проект стартовал не без трений. Сначала работы было очень много, но вспоминая этот опыт я не жалею что остался с ними, а с тем менеджментом до последнего в этом проекте. Так легаси и отсутсвие документации может стать началом нового проекта. Так что не воспринимайте в этом пункте "fail fast fail safe" как аксиому, бывают приятные исключения.
Прислушивайтесь к своей интуиции. Не спрашивайте совета и не вините потом никого - вы хозяин своей судьбы, а не друзья или родители!
Мои советы не претендуют на абсолютность, полноту и возможно не помогут вам, по причинам о которых недавно рассказывал @nmivan в "Невыжившие в IT" . Они так же пронизаны отсылкам к моему опыту и не факт что сработают именно для вас. Но все же я верю, что есть много общего в нашем пути в разработке программ и систем!
Комментарии (14)

ZicZac
13.09.2022 09:57-1Главное научили учиться
Вот не помню чтобы кто-то кого-то "учил учиться". Выглядело это скорее так: "вот вам материал, как хотите, но чтоб сдали". И люди начинали что-то придумывать - кто-то пытался разобраться, кто-то списывал, кто-то покупал контрольные и курсовые, кто-то подмазывался к преподавателям, кто-то в наглую давал взятки, остальные отчислились. А вот чтобы кто-то кого-то учил каким-то методикам обучения - не было такого.

igor_suhorukov Автор
13.09.2022 10:01Ну по крайней мере вас поставили в условия, требующие приобретения этих новых навыков. Даже не знаю какие формальные методики, кроме ТРИЗ, учат творчески искать решения!
WalterWhite01
13.09.2022 10:11-1Скорее университетский "метод" заключается в том, чтобы бросить человека в воду, и чтоб он начал барахтаться. Если утонет - отчисление, если не утонет и будет плыть - значит, научился плавать.

beeptec
13.09.2022 19:12-1Дисциплинарное, дисциплинированное или хаотичное обкуривание знаниями не несет никакой пользы и удовольствия от процесса, пока Вы не поставите перед собой конечную задачу на уровне проекта. Не все программисты те, которые просто пишут код...

gudvinr
14.09.2022 12:36оба средства свободные
Java свободная только на бумаге, по факту балом правит Oracle, а псевдо-свободка оканчивается прикручиванием фронтендов к JVM и сборками JRE с костылями от разных компаний типа jetbrains.
igor_suhorukov Автор
14.09.2022 12:51Не совсем. Гугл конечно хотел бы Apache лицензию на OpenJDK и полную свободу на мобильном рынке Java. Лицензия проекта GPL-2.0 with the Classpath Exception и на мобильные JVM действуют патенты. Десяток дистрибьютивов от разных фирм Azul, Corretto, AdoptOpenJDK, Oracle, Liberica JDK и т.п. Неразбериху и волнение на рынке вызвали попытки оракла перевести поддержку на LTS сборки на платную основу. Паника позади, OpenJDK сборки есть
gudvinr
14.09.2022 13:13То есть вы просто подтвердили мои слова :)
Я не говорил про то, что "настоящая" свобода — это пермиссивные лицензии. Какая бы там ни была лицензия, по факту никакой свободы нет.
Да, полторы калеки могут что-то там распространять, патчи делать какие-то минимальные, сами поддерживать их. Но в реальности никто не пикнет без Oracle, глобальных решений никто кроме них в развитие Java не продавит и т.д.Какой толк от этой "свободы", если любые фишки в "свободной" сборке обречены на загнивание, т.к. они нигде больше поддержаны не будут? А поддержаны они нигде не будут, потому что сборка это просто сборка, и все сборщики тащат костяк из официальных реп Oracle.
Можно сколько угодно говорить про светлое и чистое, но реальность это не изменит.
igor_suhorukov Автор
14.09.2022 13:29Вы сильно недооцениваете платформу, ваше право. Но только операция по выманиванию исходников из Sun micro systems стоила больших денег. В сравнении с CLR от MS свободы и выбора значительно больше
gudvinr
14.09.2022 13:37То что там больше свободы, чем в другом несвободном продукте, тоже развиваемом корпорацией, не делает платформу свободной.
Вы сами упомянули патенты на JVM. И где "свобода" в этом?Можно придумывать оправдания сколько угодно, мол, интеллектуальная собственность, что ж поделаешь, и говорить они очень открытые подходы к разработке исповедуют, правда-правда, возможно даже пулл-реквесты принимают.
Но сути это не меняет, Oracle создаёт иллюзию свободы, когда формально лицензии соблюдаются, а на деле у них монополия на разработку и развитие "свободной" платформы.igor_suhorukov Автор
14.09.2022 13:48Маловероятно что вы сталкнетесь с ограничниями, кроме попытки создать свою JVM для embedded и мобильных устройств. А вот достаточно быстро использовать огромную экосистему для разработки приложений и распределенной обработки данных получится. Каждый делает сам этот выбор!
gudvinr
14.09.2022 14:51использовать огромную экосистему для разработки приложений и распределенной обработки данных
Это со свободой никак не связано. Тоже самое можно сказать о других языках/платформах, которые приверживаются диктатуры в плане подхода к разработке самой платформы.
igor_suhorukov Автор
14.09.2022 14:55Более не пытаюсь вас переубедить! Rust и С/C++ гораздо свободнее но и требуют большего погружения, гораздо большей экспертизы и кругозора разработчика!
igor_suhorukov Автор
14.09.2022 13:36Хоть в живую Azul я никода и не видел, но судя по инофрмации он кардинально отличающаяся от OpenJDK JVM. Глубже интегрирована в операционную систему, чтобы обеспечить Java программе низкие задержки при работе. Но она стоит денег и покупают в основном банки!
panteleymonov
Терпение