
Всем привет! Я работаю в MaritimeAI, и вместе с Yandex Cloud мы строим систему, которая позволяет учёным в НИИ биологии Иркутского государственного университета мониторить экологию озера Байкал.
Ещё недавно подсчёт и определение разнообразных видов планктона сотрудники выполняли вручную: с помощью микроскопа, глаз и бланка, в котором отмечали наличие того или иного организма. Мы решили это автоматизировать — а заодно поделиться датасетом с сообществом на Гитхабе. В конце поста поясню, кому может быть полезен датасет, как он будет обновляться и что ещё появится в репозитории. Но давайте обо всём по порядку.
Чем вообще занимается MaritimeAI? Мы применяем разнообразные методы машинного обучения в морских, экологических исследованиях и не только. Мы решаем задачи распознавания разных типов морского льда по спутниковым снимкам, умеем обрабатывать данные с сонаров, детектировать нефтяные пятна, улучшаем видео подводной съемки. При поддержке Yandex Cloud мы создаём для НИИ биологии Иркутского государственного университета систему, которая позволит поддерживать уникальный в своем роде эксперимент по мониторингу состояния экологии озера Байкал.
Уже 77 лет НИИ биологии ИГУ проводит наблюдения за состоянием воды Байкала. Это самое продолжительное подобное исследование в мире, методика которого не изменялась всё это время. Воду берут в определённой точке озера с глубин от 9 до 250 метров, регистрируют гидрофизические (прозрачность, температура на разных глубинах) и гидробиологические (численность и видовой состав фито- и зоопланктона) показатели. Раньше для такой работы было необходимо, глядя в микроскоп, просмотреть всю пробу и для каждого организма определить его вид. При этом в воде Байкала встречаются как завсегдатаи — виды планктона, которые мы ожидаем увидеть, так и редкие, неизвестные и инвазивные виды. После подсчёта для каждой пробы воды заполняют сводную карточку. Когда-то карточка была картонной — сейчас это, конечно, электронная форма.
Нашей задачей было автоматизировать оценку гидробиологических показателей так, чтобы облегчить труд специалистов НИИ биологии и при этом оставить им возможность самостоятельно изучать новые организмы.

Одинокая Cyclotella
Наш подход
Задача выглядела бы как типовой — object detection, для которого уже существует множество решений, если бы небольшое «но»: у нас нет фиксированного списка классов объектов. Вообще, конечно, есть список видов, которые обитают в водах Байкала, но он не является полным и окончательным. У некоторых видов различают стадии развития, этих стадий может быть достаточно много, и иногда они не очень различимы между собой — например, из-за не очень удачного положения организма под микроскопом, или же в пробу может попасть только часть организма. Новые объекты могут быть любыми — семена растений, объекты искусственного происхождения, инвазивные виды — всё это многообразие необходимо распознавать как нечто новое и показывать специалистам. Так что нужна система, которая возьмёт на себя заботу о рутине и «обычных» обитателях озера, а сложные, необычные и интересные объекты покажет знающим людям.
Epischura baikalensis
Итоговая формулировка задачи выглядит как нечто явно большее, чем стандартное описание задач машинного обучения, встречающееся во множестве курсов по ML. Тут мы имеем дело с расширяемым множеством объектов и заранее не знаем, насколько это множество может в принципе расшириться. Подобные проблемы есть не только в биологии, но и вообще в любой области, где данные часто и разнообразно меняются.
Ещё одно отличие от самых базовых формулировок задач ML — это определение качества работы системы. Мы с самого начала задались вопросом — а когда мы поймём, что наши алгоритмы работают хорошо? Конечно, можно привязаться прямо к долям распознанных объектов, к F1 и ROC-AUC, а при детектировании объектов использовать IoU.
Представим себе, что алгоритм уверенно распознаёт все встречающиеся зимой виды планктона и метрики нас устраивают. Но тут появляется инвазивный вид, который алгоритм не распознаёт и организмов этого вида становится столько же, сколько всех остальных видов вместе взятых. Тогда все метрики, конечно, стремительно просядут: известных видов становится меньше, а неизвестных — больше. Впрочем, это не должно быть серьёзной проблемой, ведь достаточно запомнить, как выглядит новый вид, и тогда стандартные метрики вернутся к прежним «хорошим» значениям. В общем, показатели типа accuracy могут и не быть признаками того, что алгоритмы работают хорошо или плохо.
В итоге, как это часто бывает в реальных задачах, мы оцениваем главное — сколько в среднем времени специалист тратит на обработку одной пробы. Такая высокоуровневая метрика, конечно, не связана напрямую с метриками обученных нейросетей, но служит отражением пользы всей создаваемой системы — тем, ради чего мы, собственно, и работаем над этим проектом. Перед началом разработки мы сделали замеры времени, которое сотрудники НИИ тратят на одну пробу. В среднем это около получаса, однако для сглаживания ошибок пробу могут обработать несколько раз и усреднить результаты каждого подсчёта. Мы делаем процесс таким, чтобы для съёмки пробы не требовалось участие специалиста именно по зоопланктону. Хотя процесс обучения алгоритмов ещё только идёт, они уже периодически берут на себя разметку, а начиная с января 2023-го мы будем автоматически обрабатывать большую часть самых распространённых видов зоопланктона.
Итого, у нас есть входящий поток изображений с более-менее постоянным фоном, на котором появляются разные объекты. Нам их нужно выделять и потом, по возможности, распознавать. Все эти шаги мы совместили с ручной обработкой изображений, как показано на схеме.
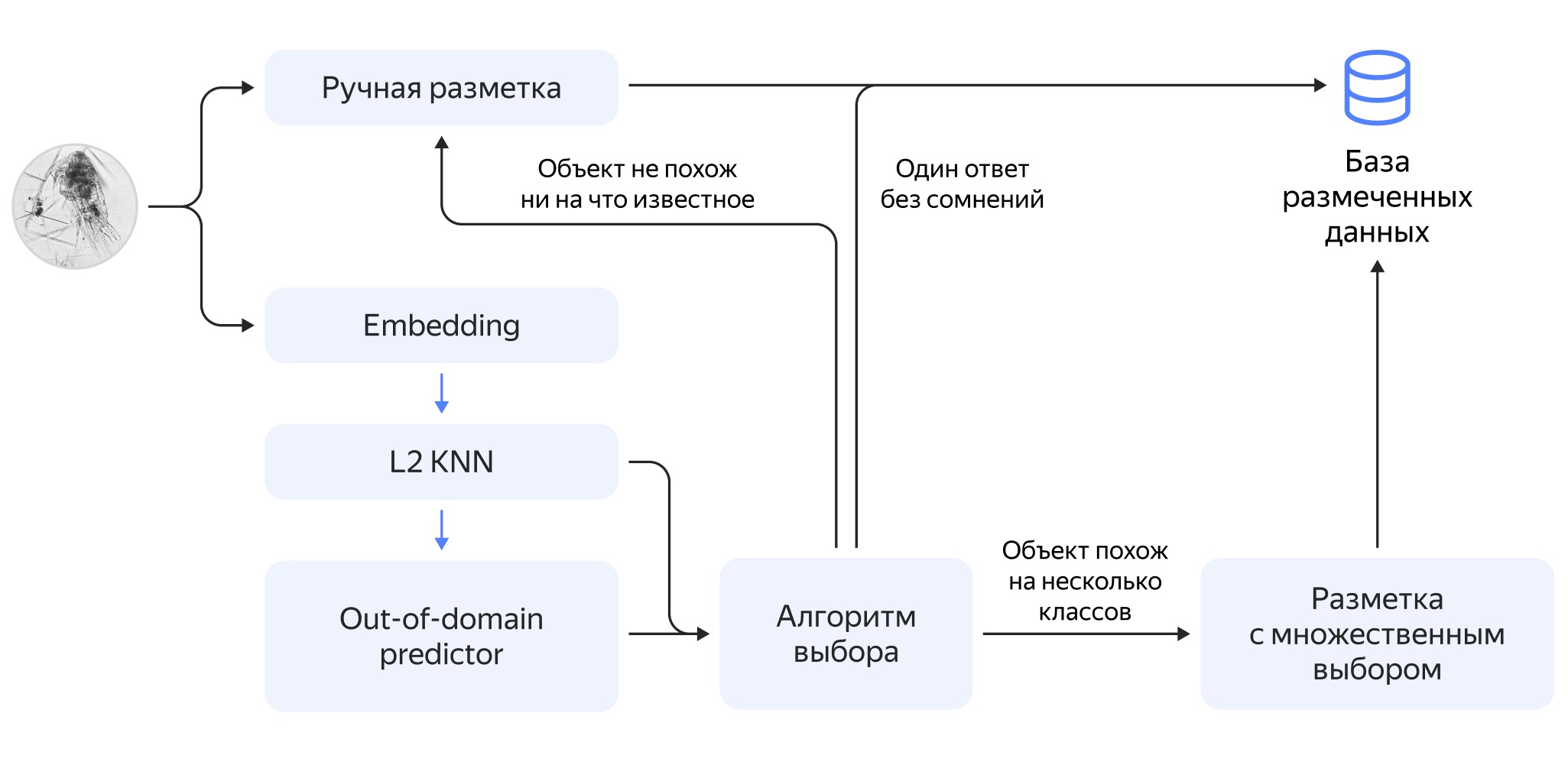
В процессе разработки у нас не было чёткого понимания всех нюансов работы специалистов НИИ биологии. Поэтому сначала мы оцифровали процесс «как есть». То есть мы, конечно, пронаблюдали, как сотрудники работают с пробами вручную, но, как и в любой реальной задаче, есть тысячи нюансов, которые мы можем не видеть. Вместо отсмотра пробы через микроскоп специалист теперь проводит фотосъёмку, сохраняя отдельные кадры с камеры микроскопа в специально созданной нами среде каталогизации проб. Затем можно просматривать пробу уже на компьютере, выделять объекты (обводить отдельные объекты полигонами) и присваивать им классы, а сводная карточка будет собираться автоматически.
Первый этап оцифровки прошёл успешно, и мы перешли ко второму — начали замещать части процесса разметки алгоритмами. Сама разметка у нас разделена на две большие части — детекция объектов и классификация.
Детекция пока является самым интересным и больным нашим местом. Идеально было бы безошибочно детектировать вообще всё, что мы видим. И тут начинаются сложности:
- Нам может попасться объект, которого мы никогда раньше не видели.
- Объекты достаточно часто накладываются друг на друга.
Поэтому нам нужно нечто более устойчивое, чем обычные детекторы и классификаторы. Пока что лучшее решение — выделять не объекты, которые мы видим, а фон этих объектов — он обычно выглядит более-менее одинаково. Фон представляет из себя стекло специальной ёмкости с подсветкой янтарного цвета. На дне ёмкости достаточно царапин и бугорков, которые нужно отличать от объектов, поэтому простая сегментация по цвету, увы, не сработает. Через выделение фона мы можем сделать маску фона, маску объектов и разделить отдельные объекты с помощью стандартного в OpenCV алгоритма Watershed. Сейчас фон мы выделяем классическим алгоритмом сегментации UNet, но не оставляем эксперименты с другими подходами.
Так мы получаем объекты или, если не очень повезёт, сгустки объектов. Впрочем, когда объектов много и они перекрывают друг друга, можно просто добавить в ёмкость с пробой ещё немного воды.
Для классификации мы решили воспользоваться подходом Metric Learning. У нас много классов для изображений, и есть большой количественный дисбаланс между примерами объектов отдельных видов — к примеру, до конца года мы не ожидаем увидеть байкальскую дафнию.
В дополнение для каждого класса объектов достаточно просто использовать алгоритм определения новизны объекта. Сейчас классификатор представляет из себя модель из трёх взаимосвязанных частей. Первая часть — классическая нейронная сеть, в основном на базе ResNet (здесь мы постоянно экспериментируем), которую мы через различные вариации Triplet Loss обучаем извлекать из изображений эмбеддинги отдельных объектов. Вторая часть — это, по сути, метод ближайших соседей, который работает на основе движка Faiss. С его помощью кластеризуем данные и определяем, насколько новое изображение похоже на полученные раньше — или на каком расстоянии от них оно находится.
На основе эмбеддингов/расстояний между ними работает и третья часть модели. Это out-of-domain-классификаторы, которые определяют «новизну» встреченного изображения — один предиктор на класс. Классификатор может путать между собой некоторые классы (я тоже путаю, если честно), поэтому мы даём людям возможность оценить найденный объект и указать, действительно ли он новый или алгоритм сделал ошибку.

После успешной классификации — неважно, ручной или автоматической — новые объекты попадают во внутреннюю базу данных MongoDB. На её основе мы формируем отчётность, которая в итоге и выступает результатом одного наблюдения. В отличие от лампового аналогового процесса мы можем вернуться к пробе после её обработки. А ещё мы из этой БД формируем наборы данных для обновления детектора и классификатора, что позволяет знакомить алгоритм с новыми видами и улучшать метрики распознавания для уже известных.
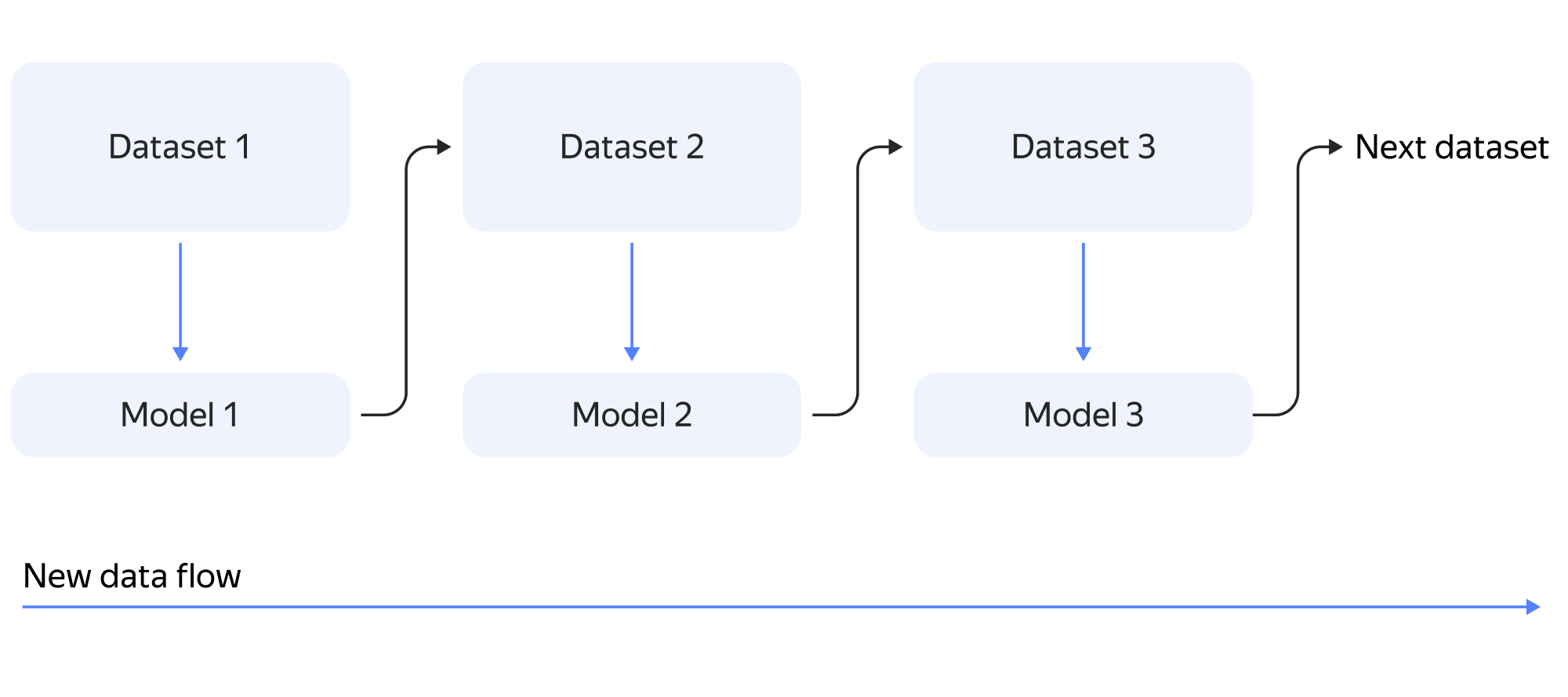
Так мы постепенно запоминаем все основные виды организмов в воде Байкала. Конечно, это происходит постепенно, и особую байкальскую дафнию мы будем ждать еще несколько лет. Но чем больше объектов мы видим, тем лучше распознаём новые объекты.
Во время работы мы столкнулись со множеством нюансов и неожиданностей. Вот несколько примеров:
- В нашем процессе мы можем измерить погрешность работы алгоритмов. А вот метрики качества работы людей мы пока не можем измерить. Раньше биологи пересчитывали каждую пробу по два раза и усредняли результаты подсчёта, чтобы сгладить возможные ошибки.
- Специалист своим тренированным глазом может различить давно знакомый вид даже на сильно размазанном изображении. Во время скроллинга микроскопом по пробе учёный даже не задерживается для того, чтобы сфокусироваться на какой-нибудь Epischura baikalensis. Мы пробуем прикрутить обработку видео — то есть непрерывно снимать картинку с камеры микроскопа, сделать своего рода сканер, чтобы увеличить скорость обработки проб. Но пока что сталкиваемся с ограничениями камер и скорости «прокрутки».
- Некоторые стадии развития одного из видов отличаются количеством, а они могут просто не попасть в кадр. С такими примерами сложно даже людям, которые работают в этой сфере десятки лет.
- Когда в изображениях что-то сильно систематически меняется, мы переключаемся на полностью ручной режим. Например, наступило лето и в воде появилось много дополнительных объектов. Мы их не очень-то и учитываем, но они есть. Обычно специалист НИИ биологии, зная, что именно он видит перед собой, просто пропускает мелкие нюансы, а для сетей наступает пора дообучения.

Keratella Quadrata
Реализация в облаке
Мы делаем абсолютно всё в среде Yandex Cloud, используя сервисы платформы.
Для сотрудников НИИ биологии мы собрали портал с альбомами изображений проб — веб-сайт на Python + FastAPI, который работает в Compute Cloud, данные складывает в Managed MongoDB, а изображения — в объектное хранилище.
Для обучения новых моделей используем ноутбуки в сервисе DataSphere. Вообще это несколько нетипичное для нас решение, так как обучать модели мы привыкли через скрипты — их удобно оставлять на большое время «подумать», легко версионировать. Плюс DataSphere в том, что там добавлено сохранение состояний памяти в ноутбуках, то есть можно сделать чек-поинт, сохранить промежуточное состояние, прервать ноутбук, потом загрузить состояние и продолжить как ни в чём не бывало. Эта же особенность позволяет менять «на лету» железо, на котором исполняется ноутбук. Недавно стало возможным эксплуатировать ячейку ноутбука с обученной моделью как микросервис. В итоге мы собрали типовой ноутбук, в котором можно подкручивать те или иные параметры по обстоятельствам, менять модель или алгоритм обучения. После завершения обучения ноутбук выкладывает много статистики, глядя на которую, мы принимаем решение об обновлении моделей распознавания. Если нам всё нравится — выкладываем сериализованные модели в отдельное хранилище.
Алгоритмы распознавания работают у нас не в реалтайм-режиме, то есть можно запускать распознавание на не очень мощной виртуальной машине, пока все спят.
Для распознавания мы собрали компактный сервис, которому передаём сообщения через механизм Message Queue. Внутри себя сервис использует всё тот же Faiss и ONNX для нейронных сетей.
Ручная разметка
В какой-то момент мы решили быть ленивыми и не умножать сущности. Поэтому вместо того, чтобы встраивать открытые инструменты разметки в собственный интерфейс или даже писать свои, мы решили использовать уже готовую Толоку. С точки зрения разметки мы экспериментируем с различными типами заданий и предусматриваем, что через ручной интерфейс пользователи будут не только размечать новые изображения, но и контролировать друг друга и работу алгоритмов.

Поздняя весна
Лето
Открытые данные
Сотрудники НИИ биологии с помощью собираемой статистики решают множество научных задач, но это, как мы подозреваем, лишь малая часть того, что можно сделать при помощи таких данных.
В ближайшие несколько месяцев мы предоставим доступ к регулярно пополняемому набору данных, а также откроем исходный код. Но базовый датасет, фактически то, с чем мы когда-то стартовали сами, можем открыть уже сейчас.
Итак, на Гитхабе опубликован датасет, который содержит изображения из-под микроскопа с разметкой. В json-файле находятся объекты, каждый из них соответствует одному объекту в воде — рачку или водоросли.
Для каждого объекта мы даём:
- ссылку на содержащее его изображение,
- полигон или прямоугольник, в котором находится объект,
- лейбл класса объекта.
Датасет отлично подойдёт для тестирования гипотез по детекции, сегментации и классификации объектов в необычной области данных, для проверки устойчивости к дрейфу данных.
Планы по датасету: хотим разделить его на обучающую и проверочную части на манер временных рядов и установить некоторый бейзлайн, от которого можно будет отталкиваться.
Что мы будем делать дальше?
У нас много планов.
- Разнообразие организмов в пробах заметно варьируется от сезона к сезону: весна, зима, лето, осень. Поэтому работы по знакомству со всеми основными видами и дообучению алгоритмов у нас, как минимум, на год.
- Кажется, экспериментов у нас накопилось на неплохую научную статью о метрическом обучении.
- Байкал — не единственное место на планете, где ведётся мониторинг. Подобные наблюдения учёные проводят и в других точках земного шара, собирая образцы из самых разнообразных водоёмов, и там своя отдельная жизнь, которую тоже надо изучать.
- Есть планы по написанию научной статьи по биологии, созданию вики и открытой базы данных.
Эти исследования помогут выявлять проблемы в балансе микроорганизмов в озере на ранней стадии — и сохранить Байкал для будущих поколений.
Комментарии (10)

spiralis Автор
24.09.2022 12:28+3Это решение НИИ. Им к научным статьям нужно прикладывать данные, к тому же есть желание наладить взаимодействие с другими научными организациями, выполняющими похожие работы. Мы будем постепенно открывать всё больше данных, добавляя новые атрибуты к объектам и расширяя выборку за счет новых фотографий.
Съемку делает специалист НИИ. Хотя сейчас это уже может быть не только специалист по планктону, но и, к примеру, студент, который уже освоил использование микроскопа. Со своей стороны мы смотрим, как можно автоматизировать и эту часть процесса.

PereslavlFoto
24.09.2022 18:07-31. Спасибо. Из ваших слов я понял, что решение принимали в НИИ и вы не знаете подробностей об их мотивах. Собственно, причина моего вопроса в том, что на своём сайте НИИ не даёт никаких разрешений, не позволяет никому использовать свой контент. Вот отсюда и появляются подозрения.
2. Если это специалист НИИ, тогда разрешение CC0 должно быть опубликовано не от вашего имени, а от имени самого НИИ. Если же это делает студент, который не работает в НИИ и в обязанности которого нет этой работы, тогда разрешение CC0 должно быть опубликовано от имени конкретного студента.

krox
24.09.2022 15:57+1А изображений на текущий момент в гитхабе то нет....
spiralis Автор
25.09.2022 02:24Но в json-файле есть ссылки на скачивание этих изображений.
С учетом количества изображений нам никакого git lfs не хватит уже сейчас, не говоря уже о пополнении датасета, поэтому сами изображения мы храним вне гитхаба.

Akr0n
24.09.2022 17:25+1Можно ли сотрудникам других научных учреждений получить тестовый доступ системе распознавания? Например, для ознакомления студентов и аспирантов с новым технологиям в этой сфере.
Как думаете, можно ли применить систему к микробиму других озер региона? Если кто-то из научного сообщества вызовется добавить фото других озер?
spiralis Автор
25.09.2022 02:45Это прямо один из наших планов на будущее - попробовать подключить другие водоемы. Что касается доступа к технологиям - есть планы открыть исходный код и модели.
Akr0n
25.09.2022 03:08Для других водоемов нужны данные из других регионов, планируется ли для этого подключать научные организации из других субъектов РФ?
PereslavlFoto
25.09.2022 03:14Что же мешает их открыть? Почему только планы?
spiralis Автор
26.09.2022 01:55+1За время разработки и эксплуатации мы несколько раз встречали нюансы, из-за которых достаточно сильно меняли архитектуру решения и мы считаем, что если дойдем до зимнего сезона без дополнительных сюрпризов, то в принципе можно начинать делиться наработками.
Также у нас еще есть несколько подходов к валидации распознанных изображений, которые мы бы хотели сначала протестировать и только потом выложить наиболее подходящий.
Ну и самое главное - наш full-stack хочет сделать рефакторинг перед релизом :)
PereslavlFoto
1) Вы опубликовали датасет при помощи инструмента Creative Commons CC0, то есть объявили, что все права на этот датасет перестали существовать, датасет перешёл в общественное достояние.
Такой поступок очень редко встречается в российских НИИ, вузах и академических институтах. Что привело вас к такой щедрости, к такому благородству? Почему вы, в отличие от «Яндекса», не стали продавать права на фотографии?
2) Рассказывая про датасет, вы написали: «a specialist now takes photographs by saving frames from the microscope’s camera». Снимки делает специалист вашей компании? Или специалист из университета?
Спасибо.