

Возможно, самая важная часть нашей работы — это осмысление данных, в первую очередь чисел. Как правило, мы смотрим на показатели, которые получаем благодаря инструментам нагрузочного тестирования, мониторингу серверов и приложений, логам или запросам к базе данных.
Цель состоит в том, чтобы понять поведение системы, но иногда получаемая информация вводит нас в заблуждение.
Сырые данные против сводных
Возьмем для примера простой нагрузочный тест. Скажем, мы запускаем короткий тест, который запрашивает одну веб-страницу 100 раз. Сырыми можно назвать данные, которые были записаны для каждого из этих 100 запросов (ключевым показателем является время ответа). Сырые данные можно нанести на точечный график, и мне кажется, что на это следует обращать внимание в первую очередь всякий раз при анализе каких-либо данных, связанных с производительностью.
Возьмем в качестве примера график, на котором показано время ответа для 100 запросов:
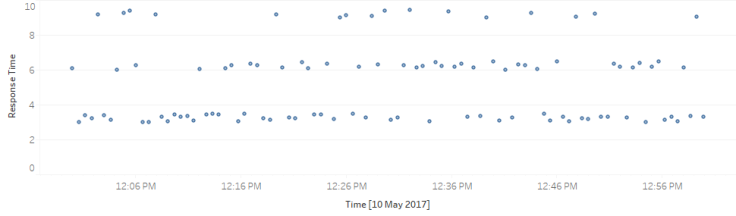
Ключевое наблюдение заключается в том, что есть три горизонтальные «полосы» времени отклика около 3, 6 и 9 секунд. Гипотетически это может быть вызвано таймаутом или переповторами.
Теперь давайте возьмем те же данные и построим график среднего времени отклика с периодом выборки в одну минуту:

Мы по-прежнему видим, что время отклика колеблется от 3 до 9 секунд, но мы потеряли видимость закономерности — теперь мы хуже понимаем поведение тестируемой системы. А что произойдет, если мы увеличим период выборки до пяти минут?
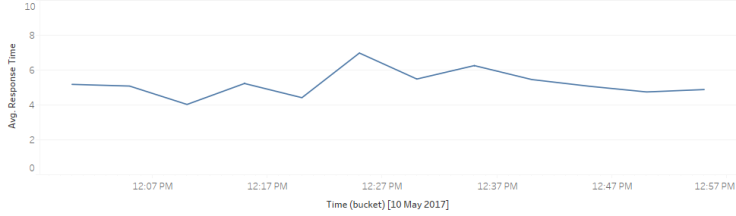
Теперь у нас создается ложное впечатление, что время отклика составляет около 5 секунд, хотя на самом деле во время нашего теста время отклика от 5 до 6 секунд вообще отсутствовало.
Это относится не только к средним значениям (которые вызывают много критики), но и к любым совокупным показателям, включая процентили и медианы.
Вот еще один распространенный пример. Скажем, у нас есть конкретный запрос, который занимает более минуты в 5% случаев, но в остальное время отвечает быстро. Если мы нанесем необработанное время отклика на график (график слева), то сразу станет ясно, что происходит, но просмотр среднего значения тех же данных (график справа) дает нам ложное впечатление, что время отклика равно около 4-5 секунд:
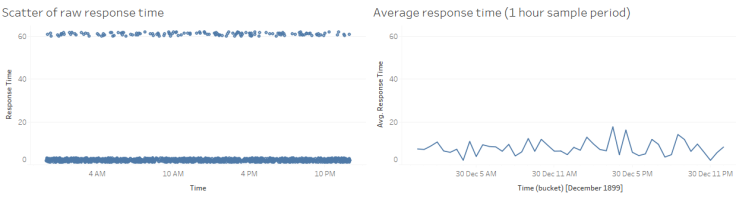
Период выборки
Период выборки — это то, как часто вы собираете замеры данных. Например, можно сделать снимок использования памяти за пятиминутные периоды.
Одна из наиболее распространенных ситуаций, когда периоды выборки влияют на мою работу, связана с интерпретацией показателей процента загрузки CPU (тема, достойная отдельного поста). Недавно я получил данные об использовании ресурсов продакшн-сервера, усредненные за период выборки в один час. За это время средняя загрузка процессора не превышала 40%:

Однако это вовсе не означает, что CPU не был загружен в течение марта. В течение любого заданного периода в один час может быть 10 минут, когда CPU постоянно достигает 100%, 50 минут, когда CPU находится на уровне 10%, а среднее значение будет составлять около 25% — что, опять-таки, не показывает истинного поведения системы.
Объем выборки
Если набор данных невелик, будьте осторожны со сводными показателями. Чем меньше объем выборки, тем меньше и уверенности в том, что мы наблюдаем. Если мы запускаем короткие тесты, которые выполняют только десятки или несколько сотен запросов, сводные показатели будут сильно колебаться между запусками теста.
Я часто сталкиваюсь с проблемой использования процентилей, когда объем выборки меньше сотни. «90-й процентиль» некоторых данных о времени отклика говорит нам, что «90% времени отклика заняло столько времени или меньше» (50-й процентиль — это медиана).
Если объем выборки всего из десяти записей, то «95-й процентиль» не является значимой метрикой. В этой ситуации 90-й, 95-й и 99-й процентили будут равны. Сводные показатели сообщают нам полезную информацию только тогда, когда объем выборки достаточно велик. Я все еще в поиске инструмента, который предупреждает или адаптируется к такого рода ситуациям.
Ограничение точечных графиков
Мы не можем с помощью точечных графиков узнать все. Во-первых, они не говорят о плотности данных. Взгляните на один экстремальный пример:
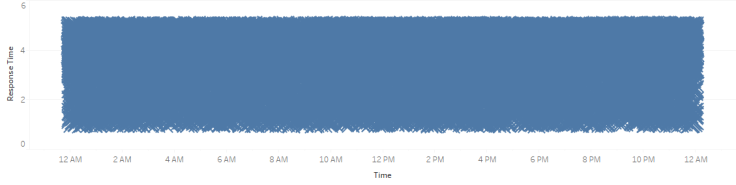
Здесь мы видим сплошной блок результатов времени отклика в диапазоне от 1 до 5 секунд. Однако мы не понимаем, что между 3 и 5 секундами в четыре раза больше записей, чем между 1 и 3. Даже если я скорректирую график, чтобы мы могли увидеть разницу:

… мы все еще не видим масштаба разницы между количеством 3-5 секунд и 1-3 секундами времени отклика.
Чтобы увидеть плотность, можно разбить данные на группы - так мы узнаем, сколько записей было сделано для каждой группы. Ниже я сгруппировал одни и те же данные о времени отклика в «сегменты» по 200 миллисекунд и отобразил количество запросов для каждого из них. Теперь масштаб разницы можно увидеть между двумя полосами времени отклика:

Таким образом, мы можем использовать сводные показатели, чтобы получить более полное представление о необработанных данных.
Чем еще хороши сводные показатели?
При помощи сводных показателей удобно отслеживать изменения с течением времени. Учитывая проблему плотности, может быть трудно понять, имеет ли место общая деградация с течением времени, просто глядя на необработанные данные.
Сводные показатели также могут дать нам общее представление о производительности в нужной ситуации. Например, если время отклика определенного ресурса постоянно занимает около 2 секунд без каких-либо выбросов или значительных отклонений, то в этом конкретном случае среднее значение является достаточно точным представлением пользовательского опыта.
Заключение
Цель этой статьи состоит не в том, чтобы отговорить вас от использования сводных данных. Важно понимать ограничения данных, которые мы предоставляем клиентам. Спросите себя:
О чем мне говорят эти данные?
О чем они не говорят?
Что (как кажется) показывают эти данные, хотя это может привести к неверным выводам?
Если вы будете продолжать задавать себе эти вопросы, вы повысите не только ценность, поставляемую клиентам, но и целостность индустрии тестирования производительности.
Всех желающих приглашаем на открытое занятие онлайн-курса «Нагрузочное тестирование», на котором ассмотрим инструменты shift left performance testing, и сравним два наиболее популярных из них: Gatling и k6. Регистрация открыта по ссылке.