
«Собственно, б***ь, вот…», думал я, пока в телефонной трубке звучали длинные гудки. Я звонил своему боссу — не сомневаюсь, этим ясным пятничным утром он только и мечтал услышать, как его старший разработчик только что своими руками, не нарочно, удалил базу данных бэк-офиса.
Гудки напомнили мне писк больничной аппаратуры — когда монитор отмеряет последние пульсы умирающего больного. В данном случае, речь шла о моей карьере. Наконец, трубку на том конце кто-то снял. Мне оставалось уповать лишь на мудрость моего начальника. В глубине души я верил, что, выслушав меня, он произнесет какую-нибудь вдохновляющую речь, после которой я найду в себе силы всё исправить. Но он сказал: «Как это, мать твою, вообще случилось?!».
Что ж, сейчас я расскажу вам, как.

Немного контекста
Описанная история произошла несколько лет назад, я работал тогда в молодой e-commerce компании. В мои обязанности входило руководство двумя группами разработчиков, ответственных за поддержку нескольких важных инструментов для нужд бэк-офиса. Сам бэк-офис управлял потоками информации, доступной пользователям через фронтэнд приложения. Поддержку фронта при этом вели совершенно другие команды. К тому же, несмотря на свою молодость, компания уже могла похвастаться сотнями тысяч пользователей изо всех уголков мира.
Одна из моих команд занималась поддержкой основного каталога продуктов, от работы которого зависела большая часть потоков и служб, от управления информацией о продуктах до осуществления заказов. Можно сказать, это была критически важная платформа, поскольку все службы, процессы и приложения бэк-офиса так или иначе к нему обращались. Чтобы вам стало понятнее, вот упрощенная схема:
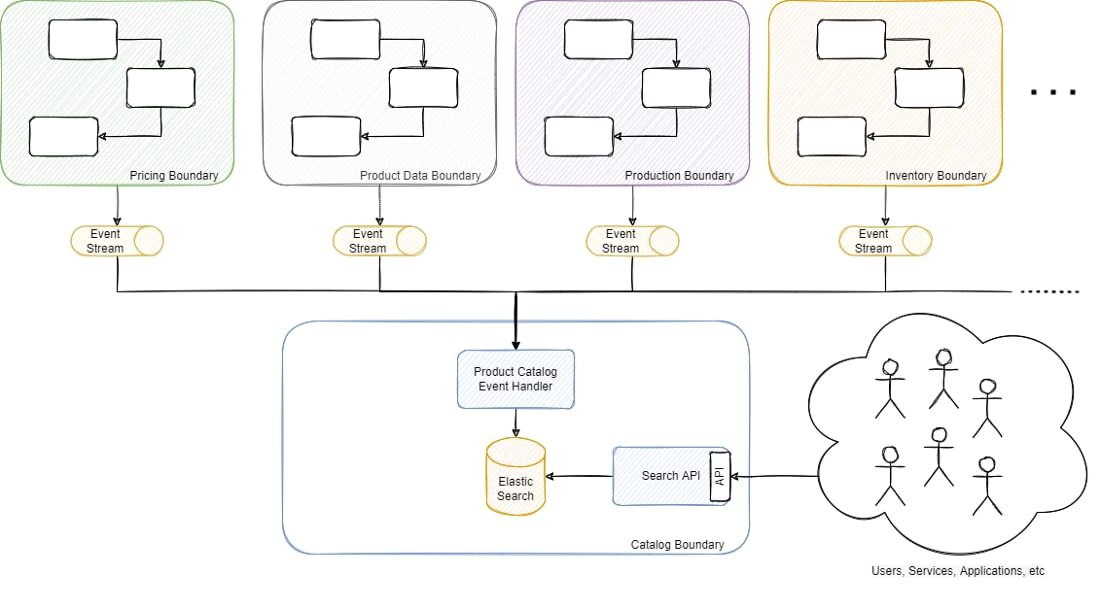
Платформа была построена на основе микросервисной архитектуры, каталог продуктов представлял собой модель для чтения с денормализованной информацией, полученной из потоков событий из нескольких разных доменов, управляемых другими микросервисами. Каталог продуктов поддерживался базой данных ElasticSearch, она хранила порядка 17 миллионов продуктов, включая метаданные, информацию о запасах, производстве, наличии, ценах и т.д., которые предоставлялись через REST API. Мы выбрали ElasticSearch в основном из-за большого разнообразия фильтров (более 50 штук, включая фильтры с поиском по тексту).
Очень краткий экскурс в ElasticSearch
Никто не имел прямого доступа на запись ни к одной базе данных, ни в одной технологии БД (мы использовали несколько технологий в зависимости от сценария использования, от SQL Server до MongoDB и Cassandra). Однако ElasticSearch был исключением, так как традиционно им управляли инженерные команды, а не Infra или DBA.
В отличие от других технологий баз данных, доступ к ElasticSearch осуществляется через REST-интерфейс. Как правило, URL-адреса имеют следующий формат (в то время мы использовали ElasticSearch версии 5):
{cluster_endpoint}/{index_name}/{type}/{document_id}
(Например: elastic.com/productIndex/product/152474145)
*В более свежих версиях type был упразднен.
Все операции с БД выполнялись через HTTP-запросы: если другие СУБД требовали написать SQL-скрипт, то ElasticSearch достаточно было HTTP-запроса. Например, следуя принципам REST, если у вас есть индекс каталога продуктов (индекс в ElasticSearch является чем-то вроде аналога SQL-таблицы), и вы хотите получить конкретный продукт, вы должны выполнить GET elastic.com/productIndex/product/152474145. Тот же эндпоинт будет использоваться для обновления этого продукта с помощью PUT или PATCH, удаления с помощью DELETE или создания с помощью POST или PUT. То же самое применимо к остальным компонентам URL: GET-запрос к elastic.com/productIndex/product поможет получить информацию о типе product. То же касается и elastic.com/productIndex — можно получить информацию об индексе, обновить или удалить ее.
Мой подвиг
Это была самая обычная пятница — как и в другие дни, мы бегали с одного совещания на другое. В мимолетных перерывах между встречами я обычно занимаюсь ситуативными задачами, например, помогаю в решении сложных вопросов или проблем, с которыми команды не справляются самостоятельно. В тот раз поступил бизнес-запрос на экспорт данных с учетом фильтров, которые не были доступны через API. Это не самая простая операция, но, учитывая срочность и важность вопроса для бизнеса, мы решили помочь.
За пятнадцать минут, которые у меня были до следующего совещания, я скооперировался с одним из старших членов команды, чтобы быстро получить доступ к среде и выполнить запрос. Поскольку прямой доступ к ElasticSearch — это, по сути, обращение к REST API, для этих целей мы использовали Postman.
Мой коллега ассистировал мне через удаленный совместный доступ к экрану. Полезная практика, которая позволяет проверять код перед выполнением операции в режиме реального времени. Сначала я хотел протестировать подключение и убедиться, что у меня правильный URL, поэтому я скопировал эндпоинт и имя индекса (что-то похожее на то, что мы обсуждали выше cluster_endpoint/index_name) и отправил GET-запрос. Если вы знакомы с интерфейсом Postman, то, возможно, помните, что HTTP-действие выбирается из выпадающего списка:

К сожалению и моему великому ужасу, сразу после отправки запроса я увидел, что вместо GET было выбрано DELETE. И вместо того, чтобы извлечь информацию об индексе, я просто удалил его.
Запрос занял всего несколько секунд, сразу подтверждения выполнения я нажал отмену. Она успешно выполнилась. Во мне забрезжил огонек надежды, совсем слабый, похожий на последний лист умирающего дерева. Возможно, я отменил запрос как раз вовремя, наивно подумал я.

Однако этот чахлый листик тут же сдуло порывом ветра рационального мышления: я понял, что запрос всё ещё продолжает выполняться на стороне сервера (в ElasticSearch) несмотря на то, что он отменён на клиенте (Postman). Я выполнил стандартный поиск без фильтров по индексу, чтобы уточнить общее количество строк. Запрос, который обычно возвращает 17 миллионов результатов, на сей раз принес только несколько сотен (сервис обрабатывает около 70 событий в секунду, эти несколько сотен были продуктами, которые создавались/редактировались в это самое время).
И вот так просто основной каталог продуктов бэк-офиса, включающий денормализованное представление 17 миллионов продуктов с информацией от десятков микросервисов со всей платформы, навеки сгинул — и унес с собой мою самооценку.
В чем нам все-таки повезло
Я позвонил своему боссу, и мы быстро организовали военный штаб, так как с каждой площадки начали поступать сообщения о проблемах. Поскольку это была, по сути, модель для чтения, она не была источником истины для какой-либо конкретной информации, поэтому нам «всего лишь» пришлось сводить информацию со всех других служб.
У нас было несколько вариантов:
ElasticSearch не имеет возможности менять схему при возникновении деструктивных изменений. По сути, вся стратегия сводится к переиндексации всей информации в новый индекс. Для обработки таких ситуаций у нас был компонент, который создавал каждый продукт с нуля, получая данные от кучи разных микросервисов через синхронные REST API. Также это помогало решить любую проблему с целостностью из-за ошибки или любого инцидента в вышестоящих сервисах. Однако на сбор всех данных по всем 17 миллионам продуктов ушло 6 дней. Так или иначе, мы сразу же приступили к работе.
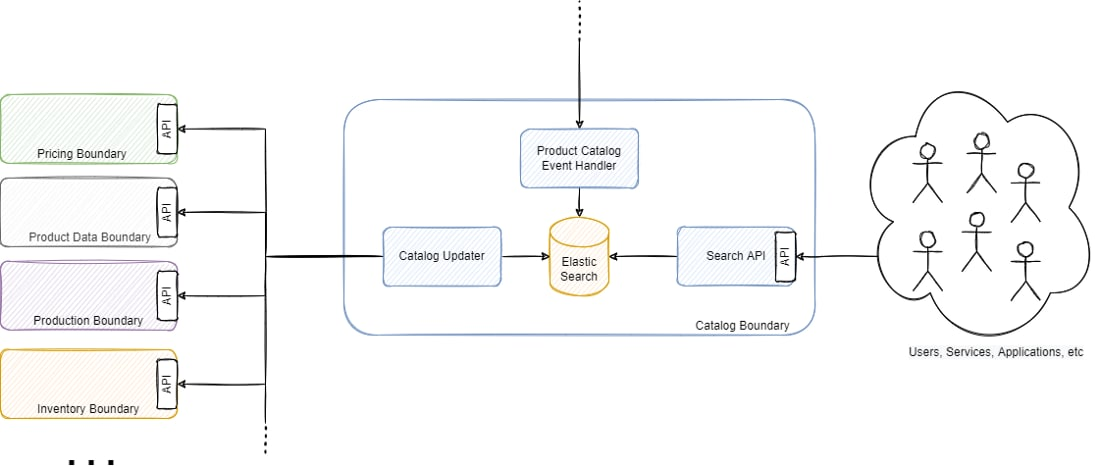
Вторым вариантом сгладить возникшую проблему было использование потоков событий. Большинство сервисов имеют функциональность для повторной публикации событий, если это необходимо, поэтому мы также попросили наиболее критичные площадки начать воспроизведение данных, которые бы применялись вместе с изменениями, сопутствующими обычному использованию.
Однако в чём нам действительно повезло, так это в том, что несколько дней назад нам пришлось сделать радикальное изменение схемы. Как я написал выше, нам потребовалось создать новую версию индекса и переиндексировать всю информацию. Длительный процесс, во время которого обе версии обновляются с учетом последних изменений. Мы дескопировали старый индекс, и новая функциональность, которой и требовалось пресловутое изменение, была не столь критична, поэтому мы просто откатились на старую версию. Данные устарели на несколько дней, но это было не так критично, как их полное отсутствие. Вкупе со всем вышеописанным, нам удалось успешно восстановить БД.
Чему мы научились
Резервные копии против скорости восстановления
Вечный спор по поводу необходимости резервного копирования разгорелся с новой силой. У нас были резервные копии большинства баз данных, кроме ElasticSearch. Кроме того, эта база данных была моделью для чтения и по определению не являлась источником истины. В теории, модели для чтения не должны иметь резервных копий, они должны оперативно перестраиваться, чтобы не вызывать проблем в случае крупного инцидента. Поскольку модели для чтения чаще всего хранят информацию, выведенную откуда-то еще, возникает вопрос, рационально ли их бэкапить с экономической точки зрения. Но на практике быстро восстановить модель и при этом не навредить бизнес-процессам весьма непросто. Если в модели хранится несколько сотен или тысяч записей, это не проблема. Однако модель с несколькими миллионами записей из десятков различных источников — совершенно другое дело.
В итоге у нас получилась некая смесь из этих двух вариантов. Мы переработали процесс восстановления до такой степени, что он сократился с 6 дней до всего нескольких часов. Однако из-за критичности компонента даже несколько часов даунтайма мы себе позволить не можем, особенно в сезоны продаж. Было несколько вариантов дальнейшего сокращения времени простоя, но по итогу мы отвергли их из-за чрезмерной сложности или дороговизны инфраструктуры. Мы приняли решение ограничиться включением резервного копирования только в самые критические периоды работы бизнеса.
Горизонтальная масштабируемость оказалась пустышкой
Одним из самых разрекламированных преимуществ наличия микросервисов является возможность горизонтального масштабирования. Часто незаметная деталь — полагаясь исключительно на синхронные API (как изображено на рисунке 4), горизонтальная масштабируемость быстро превращается в тыкву. Компонент, отвечающий за перестройку модели чтения, работал почти 6 дней, но теоретически мы могли бы кратно сократить это время, горизонтально масштабировав его. Дело в том, что для получения информации он полагался на синхронные REST API. Он запрашивал данные у каждого следующего микросервиса через REST-запросы, строил денормализованное представление и сохранял состояние. Его масштабирование вызвало бы большое количество запросов к другим сервисам, которые могли бы не справиться со значительной дополнительной нагрузкой и сами нуждались бы в масштабировании. Это вызвало бы цепную реакцию, которая в конечном итоге поставила бы под угрозу всю платформу. Добавим к этому тот факт, что большинство из них очень зависимы от баз данных, и их базы данных также нуждались бы в масштабировании.
Мы провели масштабирование, весьма скромное, однако даже тогда начались последствия в виде перегрузки других сервисов. Оглядываясь назад, можно сказать, что все это стало больше походить на монолит, чем на действительно распределенную архитектуру...
Доступ на основе ролей
Возможно, одним из самых очевидных шагов, которые мы предприняли, было внедрение ролевого управления доступом. Мы использовали старую версию ElasticSearch, которая обеспечивала лишь самую базовую аутентификацию пользователей, поэтому мы воспользовались тогда еще платной версией XPack. В более поздних версиях ElasticSearch XPack уже включен в бесплатную лицензию.
Мы всё-таки перешли на более новую версию ElasticSearch (седьмую) и реализовали разные роли для чтения и записи. В конечном итоге, только приложения должны иметь возможность регулярно писать напрямую в базу данных, пользователи могут иметь возможность (максимум) читать.
Виноваты процессы, а не люди
Я всегда повторяю своим командам, когда что-то идет не так, одну популярную пословицу. Ее смысл состоит в том, что виноваты процессы, а не люди. Мы должны понять, какая часть процесса дала сбой, и найти способы изменить ее, чтобы мы или кто-либо другой, новый сотрудник или опытный специалист, никогда больше не совершил ту же ошибку.
Это то, во что я искренне верю, и это заложено в мой стиль руководства и разбора инцидентов. Несмотря на то, что это не помешало мне ощутить себя полным идиотом, и сегодня, спустя годы после случившегося, мне до сих пор кажется, что я оправдываюсь, но в глубине души за этим стоит здравый смысл. Мы изменили способы доступа к живым данным, поскольку никто не должен был иметь прямой доступ на запись. Даже для доступа на чтение его стали избегать, так как несанкционированный запрос может оказать серьезное влияние на ресурсы, особенно в ElasticSearch, где сложные запросы (например, с высокой глубиной пагинации) могут привести к сбою кластера (например, закончится память на клиентских узлах). Это предназначено не для того, чтобы сузить автономию команд, а чтобы защитить людей от неправильных действий.
Специальные запросы передавались действующим инженерным командам, которые управляли такого рода запросами, в идеале без прямого доступа к базе данных. Ручные повторяющиеся задачи были интегрированы в функциональность соответствующих сервисов и должным образом валидированы через прикладной уровень, что предотвращало нежелательные удаления или перегруженные запросы. В целом, главный вывод — гарантировать, что у людей есть надежные и безопасные средства для выполнения своей работы и реагирования на запросы бизнеса.
Заключительное слово
Я много раз читал о подобных ситуациях, но всегда был уверен, что они никогда не произойдут со мной. «У меня есть выстроенный процесс» — наивно думал я, — «Я не отношусь к подобным действиям легкомысленно». Иногда достаточно лишь одного мгновения, доли секунды рассеянности, чтобы оставить после себя непоправимый ущерб. Я был навсегда смирен этим опытом, это поучительная история, которую я иногда рассказываю своим командам, чтобы показать, что иногда их босс тоже может совершить ужасную ошибку.
А процессы в конечном итоге существуют для того, чтобы защитить нас от нас самих и нашей неизбывной глупости.
Комментарии (76)

playermet
20.11.2022 22:32+10Вообще странно было иметь настолько легкий доступ к действию с настолько деструктивными последствиями. Все равно что красную кнопку на столе хранить, как в том меме с карандашом.

intet
21.11.2022 10:19Поддерживаю - все подобные ситуации решаются очень надо выдавать пользователя с правами по только на чтение. Это радикально снижает возможность ошибки
playermet
21.11.2022 10:44+4Даже если аккаунт админский. Для действия которое сносит целую базу хотелось бы иметь предохранитель. Например, гитхаб просит ввести имя репозитория, который пользователь хочет удалить. Необходимость не слишком частая, чтобы это сильно мешало, но зато теперь нечаянно это точно не сделаешь.



Politura
20.11.2022 22:32+14Кстати, а как правильно по-русски будет? Вроде раньше не переводили и всегда говорили что-нибудь типа "прод", или "продакшен", неужели теперь переводят как "продуктивная"?
playermet
20.11.2022 23:02+5Может не дословно, но по смыслу ближе всего "рабочий сервер". Еще иногда говорят "боевой". Для БД аналогично. Дословно будет "производственный", но я не слышал чтобы кто-то так говорил.

Areso
21.11.2022 10:45"промышленный".
промбаза - и так вполне говорят.

toxicdream
21.11.2022 11:12Промбаза вообще-то несколько другое :)
Areso
21.11.2022 11:48Продуктовая база тогда должна вообще выглядеть как склад с гниющими продуктами, нет?)
Кстати говоря - после эдцати лет эксплуатации, промышленная база как-то так и выглядит, кек.

Iv38
20.11.2022 23:22+9В моём окружении популярный вариант «продуктовая бд». Впрочем, он ничем не лучше, такая же корявая калька. Правильнее было бы «производственная», но по-русски это тоже звучит не очень. Есть ещё вариант «боевая бд».

AirLight
20.11.2022 23:53+11Продакшен база звучит лучше, чем продуктовая, особенно если в ней храняться не продукты питания.
Iv38
21.11.2022 00:45Согласен,«продуктовая» и «производственная» имеют неправильные оттенки смысла. Лучше и правда заимствовать в лоб, если не можешь подобрать адекватный перевод.
Areso
21.11.2022 10:45промышленная, промбаза, "на проме". почти не отличается от "на проде".
Iv38
21.11.2022 15:47Я знаю, что такую терминологию используют кое-где. Например, в Сбере. Но мне вообще такое не нравится. Основная причина, скорее всего, в том, что в моём окружении никто так не говорит. А другая в том, что я не могу подвести под это основания использовать такое слово. Что «промышленная», что «производственная» имеют особый оттенок, заводской такой, энтерпрайзный.

warhamster
21.11.2022 12:19-1Ни от какой кривой кальки так не корёжит, как от "боевая база", "на бою" и тому подобных. Что угодно, только не это



DoMoVoY
20.11.2022 23:00+2лучше уж SQL, где надо не мышкой, а умышленно нажать последовательность букв DELETE.
По итогу вы сделали восстановление из ранее использованных индексов. Повезло.
Iv38
20.11.2022 23:26+3Если бы он запрос руками писал, ему бы тоже понадобилось написать эти буковки. Но у него был удобный инструмент для совершения ошибки.
Iv38
21.11.2022 00:57+4Я, кстати, регулярно ошибаюсь с глаголами в Постмане. Очень легко представить ситуацию, когда в одной вкладке сначала выполняешь
DELETE /items/id
А потом хочешь посмотреть список, но ленишься открыть новую вкладку и исправляешь запрос, забыв поменять глагол на GET.DELETE /items/
К счастью, обычно такая операция не определена.
Поэтому я в Постмане стараюсь не лениться и не переиспользовать вкладки для разных операций. В таком случае тоже можно забыть поменять глагол, но по молчанию там GET, который в большинстве случаев безопасен.

Aquahawk
21.11.2022 08:20+8Не далее как в пятницу наблюдал запуск запроса UPDATE без секции WHERE. В этом случае бекап был отдельно слит прямо перед операцией, но тем не менее. Из тех серверников, что я знаю, так или иначе почти каждый делал это в продакшне. И рекомендация писать сначала SELECT и смотреть что выбралось, а потом переписывать начало запроса на UPDATE или DELETE не меняя секцию WHERE не спроста появилась.
DoMoVoY
21.11.2022 09:36+5На прод базе еще лучше пользоваться транзакциями.
begin/commit/rollback
Vitaly83vvp
21.11.2022 14:33Лучше через какой-нибудь "менеджер" миграций, где не нужно писать сам SQL или, как минимум, он протестирован локально.
Разумеется,
begin/commit/rollback, никто не отменял.

JuriM
21.11.2022 09:05+2Я думаю и остальные бэкапы тоже никто не проверяет, если нет периодических процедур disaster recovery

Xeldos
21.11.2022 13:34+1Когда-то давно я умышленно нажал последовтельность букв "DELETE FROM table_name<ENTER>". На самом деле я хотел написать ещё WHERE, но дрогнула рука. Хорошо, что в мускуле тогда уже была защита от безусловных удалений. Это была mysql-консоль, на проде, на боевой базе, под админским, разумеется, аккаунтом.


DmitryKoterov
20.11.2022 23:03-13Не ElasticSearch, а Elasticsearch. Брэнды надо уважать, иначе они кусаются.

ncix
21.11.2022 00:39+8Помню много лет назад презентацию ребрендинга флагманского продукта одной крупной софтверной компании, и основателю из зала задали вопрос "а как это правильно произносится", на что основатель ответил - "а как вам больше нравится? Можете произносить как вам нравится!"
Это было неожиданным, но очень "сильным" ответом. Не важно, как говорить: "хюндай", "хёндай" или "хёнде" - все варианты работают на бренд. Более того, многочисленные смешные и нелепые вариации, их обсуждения и даже споры пользователей только способствуют запоминаемости бренда.Iv38
21.11.2022 02:57+4Вот Хюндай как раз настойчиво боролся с неправильным произношением. Но, похоже, и они осознали бессмысленность этих действий и смирились. А вот Найк, например, заявлял на прессконференциях, что нравится вам Найк а не Найки, ну так тому и быть, значит в России будет Найк. Эдоуби тоже никогда не спорила с русским названием Адоб, и у них даже было такое российское юрлицо. Ещё один противоположный пример из айтишного мира — PostgreSQL. Их евангелисты неоднократно подчёркивали, что правильно Постгрэс-кью-эль, а не Постгрэ. Ну и сами виноваты, раз такое написание выбрали, вряд ли теперь удастся это исправить.

dwdraugr
21.11.2022 09:47Про юрлицо, насколько я знаю, есть какой-то закончик о транслитерации, который не даёт разгуляться в нейминге для зарубежных дочек.

cadmi
21.11.2022 16:02Потому что Postgres - это была другая база. В том, что подросли школьники, которые этого не помнят, те люди, которые "выбирали написание", уж точно не виноваты.
Выбирали, кстати, в том числе Вадим Михеев из Красноярска, который тогда работал в соседнем здании (поэтому я прекрасно этот процесс помню) и написал половину тогдашнего постгреса (из-за чего он во многом и стал sql) и Джулиан Ассанж (да, тот самый).Iv38
21.11.2022 16:09+2А сколько ещё подрастёт, это же не врождённое знание. Написано же PostgreSQL, прям регистром выделено, а это неправильно, оказывается.

Celahir
21.11.2022 19:54-1Как зануда-школьник, читающий в данный момент официальную докментацию PostgreSQL, приведу цитату из пункта 2.3 предисловия.
Many people continue to refer to PostgreSQL as “Postgres” (now rarely in all capital letters) because of tradition or because it is easier to pronounce. This usage is widely accepted as a nickname or alias.
Не знаю, кто там определяет правильность, но я буду называть так, как написано в доках.

FlashHaos
20.11.2022 23:54+7Удивительные приключения разработчиков на проде! «Как вы можете нас не пускать в продуктовую базу, вы нам не доверяете? Вы плохой сисадмин, был бы хороший девопс, он бы строил эджацл, а не запрещал доступы.»

eltardowut
21.11.2022 01:21Если надо было просто запросы и фильтры потыкать там, где жалко что-то потерять, то нахера это было делать не под R/O учёткой, напрашивается вопрос.
Iv38
21.11.2022 03:08В статье есть ответ почему так было
Мы использовали старую версию ElasticSearch, которая обеспечивала лишь самую базовую аутентификацию пользователей, поэтому мы воспользовались тогда еще платной версией XPack. В более поздних версиях ElasticSearch XPack уже включен в бесплатную лицензию.
Я так понимаю, что там не было разделения на роли. Мне это тоже кажется ужасно странным. Но я не знаком с администрированием ElasticSearch, может это и правда так, или я что-то понял неправильно.

ivanrt
21.11.2022 02:45+1"Мы приняли решение ограничиться включением резервного копирования только в самые критические периоды работы бизнеса." Делать что-то только в самые критичные моменты... что может пойти не так (с)?

Stas911
21.11.2022 04:38+2Только на прошлой неделе общался в крупным банком, все разработчики одного из DataLake которого работают сразу в проде - "но ведь нам для работы нужны prod данные". Ну да, ну да, а скопировать кусок в dev не позволяет религия, видимо...

ChidoriAmi
21.11.2022 18:55я не из этого банка, но представляю себе, как это - на проде 100500 мильонов ГБ и мощность серверов достаточная, а на тесте и места фиг да маленько, и запросы бегают в 2-3-5 раз дольше. А когда еще данные нужны не из 3 таблиц, а из 28, ууу, вообще больно становится.
Нужен жестко регламентированный, желательно автоматический и постоянный/регулярный процесс, сопоставимые по параметрам контуры и удобные способы репликации, иначе разработчики, как ток, пойдут по пути наименьшего сопротивления. А такой процесс, контуры и способы репликации - это вопрос способности менеджеров настоять на их необходимости и выбить ресурсы из экономного начальства =) Такие менеджеры на вес золота идут и редко встречаются))
Stas911
21.11.2022 19:57Да это понятно, но как только накапливается критическая масса народу, то обязательно что-то уронят или грохнут. Да и вообще - работать в проде не особо комфортно и ссыкотно.

AnyKey80lvl
21.11.2022 06:38+2Все словоблудие можно уменьшить до фразы "У нас были резервные копии большинства баз данных, кроме ElasticSearch"
Iv38
21.11.2022 16:05+3Ну вообще-то нет. В статье побольше информации. Бэкапы конечно надо иметь, но у них не было бэкапа не из-за раздолбайства, а из-за того, что они считали, что этой базе бэкап не нужен по идеологическим соображениям. И какое-то время это было правильно, но они не учли проблем роста.
Вторым элементом катастрофы было отсутствие в эластике ролей. Третьим — особенность устройства API эластика в сочетании с особенностями Postman.
И мне кажется, это полезные знания. А не только то, что надо делать бэкапы. Которые они, кстати, так и не стали делать регулярно, даже проанализировав катастрофу.AnyKey80lvl
21.11.2022 16:28И без ролей бэкап бы помог. Благо в эластике он прекрасно реализован (правда, могут быть технические трудности с обеспечением эластика shared storage'ем).
И в целом для управления эластиком мне нравится больше кибана devtools. Там как раз буквы писать нужно + история запросов всегда под рукой - у меня их штук 30 для управления кластером. Встал на нужную строчку, Ctrl-Enter - профит. Очень удобно. Если эластик (и кибана) вдруг полегли, обычно хватает CURLa. В постмане же гораздо проще ошибиться, действительно.

kazimir17
21.11.2022 08:38+6У меня тоже есть пара историй которые учат тому, что некоторые действия не должны быть легкими и простыми, иначе велик шанс их случайного совершения.
Давным давно, когда компьютеры были не у в всех, мой знакомый приходил ко мне поработать за компьютером, он любил использовать total commander и совершать все файловые операции через комбинации клавиш (для скорости и пущей эффектности), и в итоге простой комбинацией клавиш отформатировал мне диск C вместо дискетки, о бекапах я тогда еще не знал)
Однажды я работал на проекте где использовалась MongoDB и по просьбе отдела QA я написал простой скрипт который при исполнении удалял часть коллекций в базе, скрипт этот я просто положил в репозиторий. В один прекрасный день, мне нужно было подключиться к прод базе консольным клиентом, я запустил клиент из каталога где и лежал этот скрипт. Как оказалось, волей гения разработчиков Mongo консольный клиент в момент запуска находит все js файлы в текущем каталоге и запускает их, очень удобно. Помню то ощущение как от удара кнутом, когда я понял что произошло, но к счастью база была маленькая и мы восстановили ее за полчаса. Скрипт я конечно переписал так, чтобы случайная загрузка не приводила к исполнению.

Daimos
21.11.2022 12:29+1Звонок в службу технической поддержки:
- У меня компьютер не работает!
- После чего это произошло?
- Я его включил - загрузился Нортон. Смотрю - у меня слева диск С: и справа диск С:. Я подумал - зачем мне два диска С:? И стер правый, чтобы освободить место.

4dinterface
21.11.2022 08:38+8Чему я научился после того как я случайно уничтожил продуктовую базу данных?
Проходить собеседования!
blind_oracle
21.11.2022 11:50+4- Опишите ваш самый большой факап
- Так, щас, у меня и статья есть...





Askalite
21.11.2022 11:49Этот пост не похож на посты про "Смотрите как у меня хорошо получается". Плюс.

vvbob
21.11.2022 11:55Я как-то когда работал "мальчиком при кампухтерах", так грохнул бухгалтерскую БД 1С. Времена тогда были.. сложные, и на фирме было две БД, одна для проверок, красивая, белая, вторая настоящая, и лежала она у главбуха на компе (паранойя, да, она самая), доступ к ней был только у директора, главбуха и ее помощницы. Но в один прекрасный момент, комп главбухши засбоил, винда перестала загружаться, а я по привычке, что-бы не париться долго решил просто залить на него образ винды, с предварительным форматированием - все компы были по сути тупыми клиентами, все данные лежали в расшаренных папках на сервере, 1С работала через терминал на этом-же сервере, поэтому проблемы с клиентскими компами так обычно мной и решались. О том что там лежит "секретная" БД, я вспомнил уже когда образ винды накатился и запустился. :)))
Ощущения были незабываемые. Повезло - отделался малой кровью - на сервере лежал бекап (который я делал тайком, скриптом по расписанию, на такой вот случай, он, конечно запароленный был, но я пароль, естественно знал), с него и восстановил базу, немного данных потерялось, но это бухгалтерия довольно быстро восстановила, там меньше чем за день потери были.

piratarusso
21.11.2022 12:16Ошибки к сожалению неизбежны. И подобный опыт, сын ошибок трудных, наверное есть у большинства. Но в результате возникли правильные вопросы по функционированию системы. И это автор может записать себе в актив.
Оглядываясь назад, можно сказать, что все это стало больше походить на монолит, чем на действительно распределенную архитектуру...
Т.н. распределённая архитектура имеет массу трудно решаемых проблем, её применение должно быть чем-то оправданно, если есть возможность её не использовать. то обычно получается вполне работоспособный вариант. IMHO

v1000
21.11.2022 12:27+1вместо GET было выбрано DELETE.
всегда удивляло, как в продуктах так легко можно использовать разные команды, которые могут иметь такие разные действия.
причем если запрос информации можно делать без лишних вопросов - почему удаление информации должно быть настолько-же просто, без дополнительных вопросов и параметров?
blind_oracle
21.11.2022 13:57Просто RBAC для хипстеров - это сложно и муторно, проще всем выдать админские права и не париться.

vassabi
21.11.2022 14:131) там все по Http REST стандарту. А уж у постмана вообще нет понимания - зачем вы делаете запросы. Вам надо сделать запрос - он тут же выполняет :)
2) все штуки, которые спрашивают "вы точно хотите?", к которым вы привыкли - увы, но это визуальные надстройки, а не "протокол запрашивает подтверждение и т.д"



BeLord
21.11.2022 14:21-1Чего, судя по всему, не было, так это специалиста отвечающего за безопасность. Потому, что случившееся это типовой случай диверсии, а уж умышленно она сделана или нет, с точки зрения безопасности не важно. Основной принцип - пользователь не должен иметь возможности совершить деструктивные действия.

AlexanderS
21.11.2022 21:14Ее смысл состоит в том, что виноваты процессы, а не люди.
Парадокс в том, что эти процессы выстраивают как раз люди. И именно они порой бывают виноваты. Если же вы доведёте процесс до идеала, не позволяющего никаких ошибок, то, боюсь, люди будут в нём уже не люди а некое приложение процесса не имеющего ни свободы выбора, ни свободы воли.

cross_join
21.11.2022 22:10+1Манипулировать рабочей БД через инструменты разработчика типа postman не очень хорошая идея. В инструментах администраторов обычно можно просто обозначить соединение как production, и тогда операции на запись или блокируются, или требуют дополнительных подтверждений.
aelaa
Вот в этот момент что-то пошло не так?
Если уж назвали ее базой - будте добры делать бэкап.
Бэкап делают не (только) вещей, которые являются источником истины, но и вещей, которые долго восстанавливать. Как собственно и произошло.
shark14
Проблема сидит глубже. Полагаю, тут дело в недооценке реальной (а не теоретической) трудозатратности восстановления индекса.
Если бы его реально можно было восстановить за пару часов — таких проблем бы не было. Судя по всему, когда-то так и было, на более ранних этапах жизни проекта и текущая стратегия была обоснованной. Затем в какой-то момент объем данных вырос и за тем, что восстановление индекса может стать проблемой, не уследили. Особенно с учетом того, что подобных инцидентов ранее не было.
В реальных сложных системах при быстром росте трудно бывает уследить абсолютно за всем, даже если масштабированием занимаются опытные инженеры. Простого решения тут нет, к сожалению.
aelaa
Проблема не в том что это сложно, а в том что это не запланировано. Да, нужен архитектор, который следит за процессами. Конечно, идеала нигде нет, и такие случаи - повод что-то исправить, но общие правила типа тренингов по восстановлению из бэкапа раз в N месяцев - вещи достаточно известные
shornikov
Тренинги - это хорошо. Интересно было бы послушать про тренировочное развертывание чего-то действительно большого, типа банка или магазина уровня Озона.
Мне почему-то кажется, что это малореально. Вот у автора - восстановление заняло 6 дней. Через сколько часов бы руководство сказало "все, заканчиваем фигней страдать, работать надо, авось пронесет..."
aelaa
Мне почему-то кажется, что руководство Озона хорошо понимает почему это необходимо
shornikov
Скорее всего. Но вот руководство wb - точно нет.
Но мне интересно, как это выглядит. Бывшая сотрудница IT банка мне тут подсказывает, что у них это было в виде "под новый год мы берем свежую кассету и разворачиваем за пару часов". А что происходит когда "дата-центр не отзывается в виду попадания метеорита?". Одно дело архив тестом проверить, другое - когда выясняется, что даже пользователей надо создавать с нуля на системе, которую тоже надо срочно где-то достать.
vitaly_il1
Насколько понимаю, регулярные симуляции восстановления системы (не только базы, разных сценариев) как раз и должны показать, насколько хорошо (надежно, быстро) работает план по восстановлению. И как его поправить.
Согласен, что в небольших фирмах это "забывают" делать.