
Хорош ли ваш английский? Мой – нет. По крайней мере точно недостаточно, чтобы обходиться без переводчика в играх.
Недолгий поиск бесплатных программ в интернете мне не помог. Возможно, я просто плохо искал :) Но когда я поймал себя на мысли, что сейчас возьму в руки сотовый и буду переводить экран с помощью камеры, я понял, что пора спасаться. И путь к спасению - сделать переводчик самому.
Я нашел широко известную в узких кругах программу распознавания текста Tesseract OCR и свободное API для Google Translate. В результате получилась программа, которая может на лету переводить выделенную надпись на экране. Выглядит это примерно так: вы зажимаете горячую клавишу Win+Alt и прямоугольной областью выделяете часть изображения, где находится непонятный текст. Область выделяется, только пока зажата горячая клавиша. Вуаля – перед вами перевод во всплывающей подсказке! Выглядит это примерно вот так:

Можно распознать и с картинки в буфере обмена через меню иконки в трее:
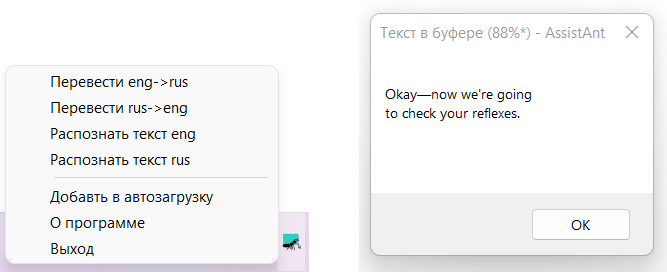
Ссылки:
Собственно проект AssistAnt https://github.com/AantCoder/AssistAnt/releases/latest
Компонент распознавания текста Tesseract OCR https://github.com/tesseract-ocr
Переводчик Google Translate Rest API (Free) с помощью GTranslatorAPI https://github.com/franck-gaspoz/GTranslatorAPI
Если совсем коротко, то это всё :) Некоторые нюансы и альтернативные способы использования есть в пункте приложения «О программе». Дальше опишу технические сложности, с которыми столкнулся в процессе разработки для заинтересовавшихся.
Горячие клавиши всё портят
Какую клавишу на клавиатуре ни возьми: или занята, или неудобна. Если кажется, что обнаружил свободную и удобную, то значит просто не нашел программу, которая уже её использует. Поэтому я не стал биндить горячую клавишу, а решил лишь отлавливать нажатие на Win+Alt. По моему разумению, ни одна программа не использует две эти клавиши отдельно от остальных. Разумеется, если вместе с Win+Alt нажать ещё что-то третье, то мой переводчик не отреагирует.
Такая комбинация хорошо выполняет свою цель: позволяет выделить область на экране, минимально влияя на активную программу. Правда, есть один минус, опишу его в следующем пункте.
Перевод из всплывающих подсказок
В попытке выделить текст двигаем мышкой – она покидает элемент интерфейса – всплывающая подсказка исчезает. Это заставило меня сделать стандартную систему, как при вырезании скриншотов. Если нажать Win+Alt и отпустить, не двигая мышкой, то создается скрин всего экрана, который открывается поверх всех окон. И уже в нем предлагается выделить область для перевода, как при стандартной комбинации Win+Shift+S (правда, реализовано это не столь красиво). Дальше всё как в первом способе: выдается всплывающая подсказка с переводом, за исключением того, что выделенное изображение помещается в буфер обмена (зачем? просто могу).
Плохой разбор мелкого текста
Оказалось, что Tesseract (может быть и все подобные?) плохо распознает текст с высотой строки меньше 20 пикселей. Особенно, когда он с тенью или размытием. Эффекты безусловно очень помогают прочесть надпись человеку, но нейронке не нравятся.
Помучавшись несколько вечеров, накидал сложную комбинацию простых фильтров изображений. После этого мелкий текст иногда стал читаться даже лучше, чем текст среднего размера. Из-за этого решил добавить повторное распознавание без фильтров, если качество распознания было меньше 90%. В конечном итоге вышло вот так:
Первый прогон (хорош для самого мелкого текста):
Увеличиваем картинку в 2 раза (красиво, с «высококачественной бикубической интерполяцией»),
Переводим в градации серого,
Увеличиваем изображение, добавляя пустую рамку в 7 пикселей и пустое пространство справа на 200 (так лучше распознаются короткие слова. Видимо, в вытянутом изображении ожидается меньшее количество строк),
Увеличиваем резкость,
Увеличиваем картинку ещё в 2 раза,
Ещё раз увеличиваем резкость (двойной подход немного уменьшает артефакты).
Второй прогон (обработка попроще, если качество распознания с первого прогона меньше 90%):
Увеличиваем картинку в 3 раза,
Переводим в градации серого,
Увеличиваем резкость
Третий прогон (вдруг при обесцвечивании текст стало не видно, или резкость ухудшает распознаваемость текста):
Увеличиваем картинку в 3 раза.
Медленно работает
В фильтрах многое требует доработки. Они как были сделаны на скорую руку, так и остались. Очевидно, что если выделить больше половины экрана, то программа начинает уходить в себя, пытаясь применить все эти фильтры (особенно хорошо подвешивает увеличение кол-ва пикселей в 16 раз).
Поэтому, а также из-за того, что как правило, в крупных выделенных областях экрана и шрифт также крупный, был добавлен выбор фильтров на основе размера изображения:
Если размер изображения больше миллиона пикселей (ширина*высота), то не обрабатываем его, а отправляем на распознавание как есть.
Если изображение больше 20000 пикселей, то увеличиваем только в 3 раза. В этом случае во всплывающей подсказке после % появляется *.
Если размер изображения меньше указанного в предыдущем пункте, то применяем все описанные выше фильтры. В этом случае во всплывающей подсказке после % появляется * с числом прогонов, которые понадобились, чтобы добиться качества распознавания выше 90%.
Утечка памяти
Иногда проще убить, чем прокормить. Так я и поступил, не желая возиться с утечкой памяти в чужих библиотеках (правда же в чужих?..) Теперь, спустя пять минут с момента последнего обращения к переводчику, программа автоматически перезапустится, и уж точно освободит всю память. Если же её будут интенсивно использовать на слабых компьютерах, то должен помочь перезапуск после 20 переводов: программа ждет 30 секунд после последней активации (чтобы дать прочитать текст) и перезапускается. Надеюсь, это будет достаточно незаметно для пользователя.
Переносы строк
Спасибо комментаторам @aborouhin, @danilasar и другим – открыли мне глаза на ухудшение качества перевода из-за переноса строк. Google Translate видя текст на разных строках воспринимает его как отдельные предложения. Первая мысль: отказаться от Google Translate удалить переносы строк. Но тогда переводчик может начать воспринимать, например, списки как единое предложение. А даже если и нет, то мы теряем форматирование текста.
Вдоволь помучив переводчик появилось такое решение: на место переноса вставить спец. разделитель, который переводчик не может игнорировать, но и предложение не разрывает.
Это решение дало хороший результат, но оно не идеальное, так как переводчик не может свободно менять слова в предложении.
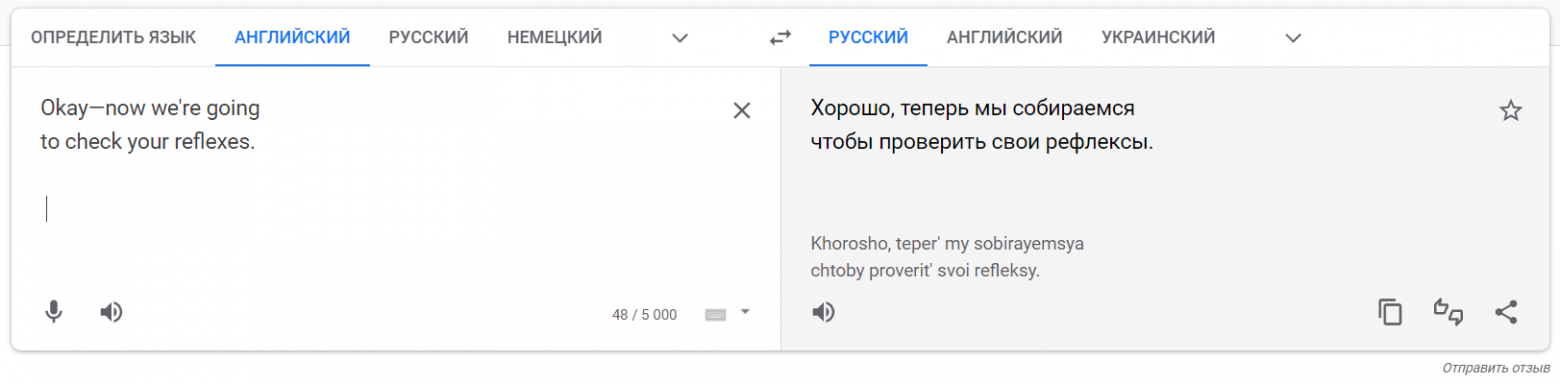
Вот пример старого варианта с двумя строками:Okay—now we're going
to check your reflexes.
Хорошо, теперь мы собираемся
чтобы проверить свои рефлексы.
Пример хорошего перевода:Okay—now we're going to check your reflexes.
Ладно, сейчас мы проверим твои рефлексы.
Пример с подстановкой (в переводе ## заменяется на перенос строки):Okay—now we're going ## to check your reflexes.
Ладно, теперь мы собираемся ## проверить твои рефлексы.
Вроде бы самое интересное описал. Сам проект можно посмотреть на гитхабе: https://github.com/AantCoder/AssistAnt
Скажу с лишним хвастовством – программа классная. Мне с моим ужасным знанием английского очень помогает.
P.S. Если есть какие-то комментарии, идеи, что можно улучшить или предложения по поводу производительности, то напишите мне здесь или в Issues на гитхаб.
UPD 27.11.2022: Добавил раздел Переносы строк, обновил картинку
Комментарии (30)

aborouhin
25.11.2022 20:40Любопытно, как в примере с картинок в посте Вы умудрились получить неправильный перевод (как минимум лишнее "чтобы"), если текст, судя по картинке с messagebox'ом, распознан корректно, и Google Translate, если ввести в него этот текст, переводит его тоже корректно. Это какой-то неправильный API...

danilasar
25.11.2022 20:44+2Очень похоже на то, что программа перевела эти две строчки по отдельности, не пытаясь их объединить в целое предложение.

Ant00 Автор
25.11.2022 20:52Нет, объединяю в единый текст. На перевод могут влиять переносы строк
danilasar
25.11.2022 20:54+3Тогда попробуйте перед отправкой в Google Translate API убирать лишние переносы строк. В переводах небольших фрагментов текста их отсутствие вряд ли испортит жизнь пользователю, а качество перевода повысится.
Ant00 Автор
25.11.2022 22:07+1Думаю действительно будет лучше, если убрать переносы строк...

funca
26.11.2022 01:32Форматирование текста перед отправкой нужно готовить самому - он ведь только переводчик, а не угадыватель грамматики и пунктуации. Куски разделенные переносами строк воспринимает как разные фрагменты.
У бесплатного Google Translate API было ограничение на количество запросов. До некоторой степени решалось с помощью пула проксей или тор. Сервис из этого не сделать, но для мелко-домашнего применения годилось.
Ant00 Автор
25.11.2022 20:50Всё как есть в самом гугл переводчике
Вот текст в виде текста:
Okay—now we're going
to check your reflexes.aborouhin
25.11.2022 21:04
Действительно, Гугл Транслейт не может понять, что разрыв строки тут не несёт смыслового значения. Удивлён - для перевода текста, скопированного из PDF или plain text с заданной максимальной шириной строки, это ж боль :(
Но обсуждаемой программе было бы полезно такие ситуации отрабатывать самой, чтобы улучшить качество перевода.
Ant00 Автор
25.11.2022 22:08Наверное действительно лучше будет убрать переносы строк.
Вот только думаю, не испортит ли это перевод, там где нет точек, а фразы разнесены графически. И не поломает ли форматирование текста, хоть это и наименее важноtruetunkin
25.11.2022 23:49В такой ситуации возможно самым простым решение будет просто переехать на нормальный переводчик, без танцев с бубном, переносами строк, тем более определением фраз. У яндекс переводчика есть неплохой api - https://yandex.ru/dev/translate/doc/dg/reference/translate.html
У bing переводчика вроде тоже.

AlexCzech01
26.11.2022 11:34Потому что для него разрыв строки несет смысловое значение - для него это начало нового предложения.
Видимо, авторы решили, что пользователи чаще вставляют абзацы без точки в конце, чем цельное предложение, разбитое на отдельные строки. Поскольку у них для принятия таких решений есть статистика, я бы им поверил
aborouhin
26.11.2022 14:57Ну от Гугла я ожидал интеллектуальной обработки подобных ситуаций с распознаванием, где это безграмотный конец предложения (без точки), а где - скопированный с принудительными разрывами строк текст или, скажем, стихи.



314159abc
25.11.2022 23:49Это интересно своей простотой. Но вот например ту тысячу слов, которую я знаю по-английски, я знаю из игр. Так что может есть смысл лишний раз открыть живой бумажный словарь. Хз.

janvarev
26.11.2022 00:40+1Крайне рекомендую Maverick OCR Helper с поддержкой: английского и японского, а также DeepL (что качественней).
Тыкаем на ~, рисуем прямоугольник, из которого будет распознаваться.
Можно сделать активные области на клавиши 1-0 + графическую обработку изображения - чтобы распознавалось Тессерактом лучше.Видюшка с объяснением, как работать.
Если нужно, я для него даже локальный HTTP API написал.
Ant00 Автор
26.11.2022 08:44+1Воот! Я знал, что плохо искал, спасибо! :)
Скачал, бегло посмотрел. Программа классная, особенно облегченная Ёлочка. Пожалуй, я бы свою не писал, если бы её видел: почти полные аналоги. Вот их различия, которые я увидел сразу:
Занять горячую клавишу Ё это слишком жестко. Хотя можно Alt+ или Ctrl+, но всё ещё не идеально (по моему скромному мнению)
Перевод более гладкий. Вероятно, из-за лишних переносов строк у меня. Нужно поправить :)
Чуть хуже, чем у меня, интеграция с программами: он делает скрин, для выделения области в нем, из-за чего программа с которой переводят, теряет фокус. Присутствуют нажатия не на хоткей: это и дольше, и мешает игровому процессу.
Красивое, настраиваемое окошко. Перевод можно выделить и скопировать. У меня это нужно сделать методом выделения области, а потом нажать в трее Перевести. Наверное, нужно поменять на копирование сразу перевода в буфер.
Я как-то не так сделал выделение по скрину :) Оно у меня немного тормозит
Для новелл очевидно более удобно: можно настроить область для перевода и не дергать мышкой.
Мелкий текст обе программы одинаково хорошо видят.
Нет функции перевода по тексту из компонента WinAPI (у меня это Win+Alt и после +Ctrl). Не то чтобы это минус, программа то по переводу изображений. Но в некоторых, преимущественно старых, программах, где это можно сделать, взять для перевода текст выглядит логичней.
У меня можно отдельно перевести и/или распознать текст и картинку по меню в трее

j_larkin
26.11.2022 11:33+2Сколько сил тратят люди только для того, чтобы не тратить сил на изучение языка )
314159abc
27.11.2022 22:50+1Мне кажется это не совсем так, на то, чтобы выучить английский на таком уровне, чтобы понимать больше 50% слов и логических конструкций, требуется год. Ну м. б. полгода, если ты гений – месяц. На то, чтобы по нажатию клавиши запихивать скриншот поочередно в ocr, а затем в гугл транслейт можно при лучшем раскладе потратить пару вечеров.

Arhammon
26.11.2022 11:33С точки зрения совершенствования английского - интереснее вариант не переводчика, а именно словаря.


in11w
28.11.2022 10:56+1Давно пользуюсь аналогом https://github.com/OneMoreGres/ScreenTranslator
Сейчас, похоже, сломался - перевод не отображает.
danilasar
Насколько я помню, Тессеракт может в значительно большее количество языков. При дальнейшем развитии программы, думаю, было бы неплохо добавить поддержку тех языков, которые доступны и в этой библиотеке, и в Google Translate API.
P. S. Что касается утечек памяти, суицид - тоже не выход) Если, опять же, программа будет развиваться, с этим нужно бороться прежде всего.
Ant00 Автор
Было желание сделать локализацию и выбор с какого в какой язык переводить. Но не понятно будет ли это реально востребовано, самому мне это не нужно. Ну и плюс размер данных для распознания в несколько метров для каждого языка раздует программу :)
Ant00 Автор
На счет перезапуска программы для освобождения памяти. Это конечно не здорово, но, я не знаю как решить эту проблему для сторонней библиотеки. Можно запускать её отдельным процессом или отдельным доменом попробовать и их перезапускать, но это примерно так же коряво будет, и в таком маленьком проекте только лишнее усложнение.
Может быть кто посоветует что ещё можно сделать? Подобная проблема вообще часто мне встречается.
funca
Обычно так и поступают - отправляют в отдельный процесс и периодически перезапускают.
Кстати в MacOS функция распознавания текста на картинках уже примерно год как встроена в стандартный просмоторщик. Аналогично работает в браузере и некоторых других приложениях. Выглядит так, что при выделении мышкой области на изображении она выделяется как обычный текст. Иногда на сайтах уже не понятно где текст текстом, а где картинкой.