
Команда Kubernetes Platform в Quadcode внедряет, поддерживает и сопровождает Kubernetes и все процессы вокруг него. Пять с половиной лет наши кластеры и подходы менялись и эволюционировали. В статье расскажем, с чего мы начинали, к чему пришли, и как получилось сделать сопровождение bare metal кластеров комфортным.

Наши кластеры и команда
Сейчас в нашей команде 5 человек. Но за всё время существования Kubernetes в компании с ним работали около 17 инженеров.
У нас есть три кластера в трёх окружениях:
Prod — самый большой кластер.
Preprod — вместе с prod’ом используется для большинства stateless-приложений компании.
Infra — используется в основном для короткоживущих приложений, например, GitLab, Jenkins Runner, браузерных тестов и тому подобного.
Prod |
Preprod |
Infra |
|
Количество нод |
97 |
53 |
22 |
Каждая нода |
40 CPU/256 GB |
40 CPU/256 GB |
40 CPU/256 GB |
Общая ёмкость |
3880 CPU; 24,25 TB |
2120 CPU; 13,25 TB |
880 CPU; 5,5 TB |
Предпосылки. До 2017 года
Главная предпосылка появления Kubernetes была такой же, как и у многих других компаний: распил монолита на микросервисы.
Микросервисы жили на LXC-контейнерах, нарезанных Ansible’ом. Сервера при этом выдавались по следующему процессу:
Команда запрашивает сервер через внутреннюю форму: накликивает конфигурацию и нажимает «Отправить заявку».
Генерируется письмо, которое уходит в дата-центр.
Дата-центр отдаёт сервер в промежуточную команду Infra Support, которая производит первоначальную настройку. Первоначальная настройка должна быть одинаковой на всех серверах компании.
Сервер передаётся в команду, которая его запросила.
Происходит донастройка сервера под нужды команды.

Создаётся тестовая платформа, которая позволяет поднять запакованные в Docker микросервисы на временной машинке в DigitalOcean. Вместе с микросервисом поднимаются все его зависимости, и от кого он зависим. IP отдаётся разработчику, разработчик идёт во временную сборку и тестирует свой микросервис.
Нам очень нравится, как Docker показывает себя с точки зрения одинаковых единиц поставок. И мы хотим, чтобы Docker стал единым рантаймом для всех наших микросервисов: кажется, что это удобно.
Но перевести всё в Docker и запустить голые Docker-контейнеры на железе или в облаке — путь в бездну ручной работы. Кроме рестартов нужно ещё решать вопрос отказоустойчивости виртуалок, на которых запущен Docker, и нужно управлять контейнерами. Поэтому мы начинаем подбирать инструмент оркестрации, и выбор падает на Kubernetes.
Выбор инструмента оркестрации. Q2 2017
Выбрав Kubernetes как инструмент оркестрации, задумались, где его развернуть: в облаке или на железе. Только вот экспертизы-то в нём нет, совсем. Начинаем думы думать да оценивать, что для нас было бы лучше.
Self-hosted Kubernetes был бы для нас понятен с той точки зрения, что его можно потрогать. Мы знаем сервера, на которых будем его крутить, знаем, как они выдаются, как настраиваются, и что у них внутри. Плюс, эти сервера будут поставлены сразу в наш дата-центр, что удовлетворяет пожелания бизнеса и безопасности: всё должно быть во внутреннем сетевом периметре и обладать низким latency, который нам важен потому, что мы финтех-компания.
Облако же потрогать нельзя. С одной стороны, непонятно, что там за железо. С другой стороны, понятно, что не нужно будет носиться с красными глазами, когда кто-то выдернет питание из стойки. По крайней мере, носиться точно будешь не ты.
Также ходят маркетинговые слухи, что управлять облаком проще. Реального опыта на нагруженных проектах у сообщества мало, поэтому сложно оценить, насколько эти слухи правдивы. Требования бизнеса и безопасности при этом никуда не деваются. Чтобы обеспечить внутренний сетевой периметр и низкий latency, нужно идти к NOC’ам, ставить им задачу и работать вместе с ними. Не сказать, что они у нас злые, даже наоборот, но задача стоит оркестратор сделать, а не гибридную инфраструктуру. Плюс на этот момент у нас в облаках ещё нет никакой прод инфраструктуры и глубокой экспертизы.
По стоимости даже если оценить сейчас:
Self-hosted Kubernetes |
Облако |
Мастера и рефлекторы поменьше 8 CPU/64 GB — €190 в месяц × 6. |
Amazon EKS — €75 в месяц. |
Ноды побольше 40 CPU/256 GB — стандарт поставки дата-центра €585 в месяц × 5 для начала. |
Amazon EC2 — €6603 в месяц. |
€55 800 в год |
€78 132 в год |
Сюрприз (нет), арендовать железо — дешевле. Плюс, в случае с облаком, помимо вычислительных ресурсов, нужны будут:
VPC;
TGW;
Direct connect;
ALB, ELB, NLB, NLP;
VPC peering;
и так далее.
И люди с контекстом не только в K8S, но и во всех этих сокращениях. В итоге получается, что вопросы стоят следующие:
В чью экспертизу мы готовы вкладываться? Во внутреннюю в Kubernetes, или в экспертизу в условный AWS?
Когда что-то пойдёт не так после того, как приложение заедет в K8S, а что-то обязательно пойдёт не так, к кому будет адресован вопрос о том, в чём именно проблема? К людям внутри компании или к техподдержке условного Amazon?
Вне зависимости от того, будет у нас bare metal или облачный кластер, нужно будет разрабатывать процессы по деплою, вводу приложений, сопровождению приложений, авторизаций, разграничению доступа. Опять же, нужно будет платить людям, которые будут этим заниматься, вне зависимости от того, какой у нас кластер.
Рассмотрев все причины, мы принимаем решение, что нам интереснее пинать своих инвестировать во внутреннюю команду и внутреннюю экспертность. И поднимаем свой bare metal кластер.

Дальше нужно выбрать, какой именно bare metal кластер. Мы находим четыре решения:
kOps;
Kubernetes The Hard Way;
Rancher;
Kubespray.
KOps отметаем сразу, так как на тот момент он поднимает кластер в облаке на EC2. Kubernetes The Hard Way — прекрасный мануал, по которому мы учимся: командочка за командочкой ты поднимаешь кластер, разбираешься, что для этого нужно и как оно работает. Но сопровождать кластер командочкой за командочкой — неудобно, и вообще мы уже все модные и хотим автоматизацию. А если нужно автоматизировать, то почему бы не взять уже готовый инструмент.
Остаются Rancher и Kubespray. Выигрывает Kubespray, который по большей части автоматизирует The Hard Way. Наши главные аргументы за Kubespray — следующие:
Он написан на Ansible. Мы долгое время работали на Ansible, нам удобно его читать, удобнее, чем исходный код Rancher.
Kubespray уже тогда позволяет довольно гибко достраивать солянку компонентов, из которых состоит Kubernetes.
С окружением Kubespray работает прозрачно, так же, как Ansible.
Kubespray разрабатывался Mirantis, одним из пионеров Kubernetes в то время. Мы доверяли их экспертности и опирались на неё.
Внедрение. Q3 2017
Мы раскатываем через Kubespray три своих кластера и деплоим первые микросервисы. Для нас наступает золотое время сопровождения кластеров, в которое входят все стандартные операции для Kubernetes и для bare metal:
Раскатка кластера.
Скейл кластера.
Разработка процесса для ввода приложений в K8S, авторизации, рекомендуемых пайплайнов деплоя, etc.
Апгрейд софта ноды: Docker, Kernel и т. д.
Апгрейд версии кластера.
Обновления сертификатов k8s, CNI и т. д.
Предпосылки рефакторинга. 2017-2019
Следующие два года мы живём-поживаем, ноды катаем, да факапов наживаем. Кластеры растут с 5 до ~20 нод. И начинаются первые проблемы.
Одна из проблем проявила себя при переезде в новый дата-центр. История следующая. К нам пришли инженеры из нашего дата-центра и сказали: «Старое помещение закрывается, будет новое». Казалось бы, сложностей у нас из-за этого возникнуть не должно: заскейлим ноды в новом помещении, в старом сдадим, заскейлим мастеры в новом помещении, в старом сдадим. В теории никакого даунтайма тоже не должно быть. На практике же с нодами всё сработало, а с мастерами — нет, потому что на тот момент Kubespray не поддерживал скейл мастеров.
Мы подумали, что сможем заскейлить мастеры сами. У нас за плечами уже был двухлетний опыт с Kubernetes, который должен помочь. На тестовом окружении всё получается, на Preprod мы допускаем даунтайм и понимаем, что c Prod идти на такой риск мы не готовы. Поэтому останавливаемся на идее, что самое простое решение физически перевезти все мастера из одного помещения в другое, будет в то же время самым надёжным.
Вытаскиваем сервера в одном помещении, грузим на машину и перевозим их в новое помещение. В итоге все девять мастеров были перевезены успешно, но остался осадочек, что в прогрессивное время приходится физически перемещать сервера из одной локации в другую.
Но это не единственная проблема, которая подняла голову. Операции по сопровождению Kubernetes стали сильно расти по времени. Вот несколько примеров:
Операция |
Время выполнения в 2017 году |
Время выполнения в 2019 году |
Раскатка кластера. |
0,5 часа. |
4 часа. |
Скейл кластера. |
0.5 часа. |
4 часа. |
Апдейт версии кластера. |
Не пробовали. |
Переезжали квартал и держали 2 кластера на каждое окружение. |
Скейл кластера стал занимать 4 часа. Это происходит за счёт того, что Kubespray позволяет поднять практически любую солянку из компонентов Kubernetes, и большое количество тасок просто скипается. Когда нод становится больше, плейбук долго скипает эти таски.
Апгрейд софта ноды занимал несколько дней, потому что это операция, которая иногда требует взаимодействия с дата-центром, с той самой промежуточной командой. Например, для обновления оси нужно передеплоивать сервер. Это долго, муторно и крайне неприятно.
Обновляться пришлось с версии 1.12 на 1.14 перекатом с одного кластера на другой. Это заняло целый квартал, потому что нужно было поставить всем командам задачи на редеплой, и дождаться, пока они его сделают.
Чтобы не быть голословными, посмотрим на время выполнения Kubespray в sample-конфигурации. Для замеров использовалась последняя на текущий момент версия Kubespray и прогон на разном количестве EC2-инстансов. Вот график времени выполнения в зависимости от количества нод:

В отличие от 2019 года, сейчас время выполнения уменьшилось с 4 часов до 2 часов, но рост всё равно есть, и этот рост — в десятки минут на каждые 3 ноды. Это много. Представьте, что будет, если у вас кластер на 50 нод, и нужно раскатить Kubespray. По 4 часа катать Ansible playbook на Kubespray — это неприятно. Плюс, Ansible может выдать ошибку, и нужно будет тратить ещё 4 часа.
На этом этапе мы сделали следующие выводы:
Kubespray долго скипает таски.
Большое количество дополнительных тасков Kubespray нам не нужны.
Kubespray поддерживает не все операции, которые нужны нам при эксплуатации. Пример — скейл мастеров.
Богатая вариативность конфигураций кластера нам скорее вредна, чем нужна. Нам нужен не любой, а наш, настроенный, понятный, работающий кластер с нашими переменными.
На тот момент мы уже разобрались в переменных Kubespray, как работает CNI и сам Kubernetes. Этих знаний должно хватить, чтобы самим написать операции, внедрить их и сопровождать. Поэтому мы решаем написать свой плейбук и убрать все лишние для нашей инфраструктуры таски, которые делает Kubespray. А если появится какой-то бинарь, который на себя возьмёт ещё какое-то дополнительное количество тасок, связанных с инициализацией кластера и join’ом нод, то вообще замечательно.
Выбор инструмента. Q3 2019
Здесь мы заходим на второй круг путешествия туда и обратно, и возвращаемся к выбору инструмента.

Дальше мы ищем бинарь, который заберёт на себя таски, связанные с init’ом и join’ом. И практически сразу находим Kubeadm. Он нам подходит, потому что:
Вышел из беты.
Наша команда получила контекст, и поняла, что мы можем делегировать некоторые процессы.
Kubeadm становится рекомендуемым способом оперирования K8S-кластером, в том числе и в официальной документации.
Внедрение. Q4 2019
Пишем свой плейбук, заменив большое количество тасков на exec’и Kubeadm. Внедряем и перекатываемся на версию 1.16 с Kubespray-кластера на Kubeadm, который написали сами.
Плейбук выглядел примерно так:
# Create audit policy files on each master (for apiserver and falco)
- hosts: kube-master
become: yes
roles:
- { role: kubernetes-audit-policy, tags: "kubernetes-audit-policy" }
tags: ["setup-cluster", "k8s-audit-policy"]
# Setup first master (kubeadm init). It is executed only on first play on firs master.
- hosts: kube-master[0]
become: yes
roles:
- { role: kubeadm-init, tags: "kubeadm-init" }
tags: ["setup-cluster", "kubeadm-init"]
# Generate join tokens and join new masters/nodes in cluster.
- hosts: kube-master[0]
become: yes
roles:
- { role: kubeadm-join, tags: "kubeadm-join"}
tags: ["setup-cluster", "kubeadm-join"]
# Setup calico using helm
- hosts: kube-master[0]
become: yes
roles:
- { role: kubernetes-networking, tags: "kubernetes-networking"}
tags: ["setup-cluster", "kubernetes-networking"]
# Add labels and anotations on nodes for manage taints using helm:
# app.kubernetes.io/managed-by: Helm
# meta.helm.sh/release-name: node-taints-labels
# meta.helm.sh/release-namespace: kube-system
- hosts: kube-master[0]
become: yes
roles:
- {role: kubernetes-annotations-labels, tags: "kubernetes-annotations-labels"}
tags: ["setup-cluster", "kubernetes-annotations-labels"]
################################### Install and configure rsyslog ##################################
# Install and configure rsyslog binary
- hosts: allЭксплуатация включает всё те же стандартные операции. При этом собственный плейбук позволил нам кардинально сократить время скейла кластера: с 4 часов до 9-10 минут на 15 нод:

В тот момент мы подумали: «Вау, победа! Когда будут следующие 4 часа, пока не очень понятно. За 2 года выросли на 15 нод и, наверное, текущего решения нам хватит на долгое время». И никогда раньше мы так не ошибались. Kubernetes получает репутацию очень стабильной платформы и доверие в компании. Поэтому от бизнеса приходит задача, что теперь практически все stateless-микросервисы по возможности нужно катить в Kubernetes.
Проходит ещё 2 года. Размер кластера растёт с 20 до ~100 нод. Вместе с этой сотней нод опять растёт время операций, и скейл кластера начинает занимать 1,5 часа. Если надо апгрейдить ядра или Docker, то времени требуется ещё больше: если раньше нужно было перезагрузить 20 нод или перезагрузить Docker, то теперь нужно сделать то же самое на сотне нод.
Операция |
Время выполнения в Q4 2019 года |
Время выполнения в 2021 году |
Раскатка кластера |
0,1 часа |
1,5 часа |
Скейл кластера |
0,1 часа |
1,5 часа |
Апгрейд версии кластера с 1.16 на Kubeadm не поддерживался. Мы переехали перекатом на версию 1.17, что заняло полгода, потому что количество микросервисов в кластере стало просто титаническим. С версией 1.17 уже написали свой плейбук по апгрейду, и с тех пор до версии 1.22 апгрейдились джобой в Jenkins, нажимая кнопочку и периодически посматривая за процессом.
Кажется, мы всё это проходили. Q3 2021
Внимательный читатель заметит, что про рост времени выполнения стандартных операций речь шла буквально раздел назад. Мы тоже прекрасно понимали, что вернулись туда, откуда начали.

Здесь у команды возникает логичный вопрос: а нужно ли что-то менять? Kubernetes работает стабильно. Полтора часа выполнения операции — неприятно, но пока это всё же не четыре часа. Делать изменения ради изменений бессмысленно, и стоит найти хорошую мотивацию.
Мотивация пришла от бизнеса:
«Вы прекрасно поработали в последние четыре года. Большинство микросервисов в Docker, мы достигли цели по единому рантайму. Но есть проблема. В проде у нас Kubernetes, а на тестовой платформе — Docker Swarm с Docker-контейнерами. Это ведёт к тому, что люди деплоятся по-разному и поведение микросервисов на тестовой платформе и в проде разное. Хочется, чтобы всё стало одинаковым.»
Вариантов два: либо убрать Kubernetes из прода, либо добавить Kubernetes в тестовые сборки. Kuber убирать не хочется, ведь он отлично себя показывает. Решаем, что нужно катить Kuber-сборки, но уже на тестовую платформу, которая нашими силами обросла дополнительными облаками, в том числе Amazon. И решаем, что будем поднимать временные Kuber-кластера на EC2-инстансах в качестве прототипа. Но нужно ТЗ: за сколько эти кластера должны подниматься, в каком количестве, сколько нод.
Бизнес даёт ТЗ:
Время поднятия < 3 минут на EC2.
Количество нод — произвольное.
Количество кластеров — произвольное.
Число сборок на тестовой платформе — от 200 до 1000 в день. Здесь мы понимаем, что текущий флоу нам не подойдёт: для него понадобится 200-1000 раз создавать EC2-инстансы, заводить инвентарники, идти в Jenkins, нажимать кнопку плейбука и отдавать IP кластера разработчику. Можно сделать webhook с джобы Jenkins, автоматизировать инвентори в Ansible и добиться какой-то автоматизации. Но зачем автоматизировать прокату джобы и Ansible playbook, если нужно автоматизировать создание кластера?
EKS/GKE — отлетают сразу. Кто создавал знает, что 3 минутами там и не пахнет.
Интерес нашей команды в грядущих переменах — в двух вещах:
Можно обеспечить постоянную и ежедневную проверку конфигурации на работающих тест-окружениях.
Где-то здесь должен быть ответ на вопрос, как не катать железки по три часа, схватывая ошибку Ansible.

Декомпозиция процесса

Четыре года мы занимались тем, что пушили плейбук на наши железки, а теперь нужно было делать что-то другое. Чтобы разобраться, как делать другое, оставляем все накопленные знания и возвращаемся к истокам, а именно Kubernetes the Hard Way.
The Hard Way выделяет девять этапов на то, чтобы поднять K8S-кластер. У каждого этапа — своё количество Bash-команд, всего около сотни на каждый мастер или ноду:
Этапы по Hard Way |
Количество команд |
Провижн CA и создание сертификатов для control plane |
31 |
Генерация конфигов k8s для аутентификации |
21 |
Генерация конфига и ключа шифрования |
3 |
Бутстрап etcd |
13 на каждом члене etcd-кластера |
Бутстрап k8s control plane |
33 |
Бутстрап нод |
25 |
Конфигурация kubectl |
5 |
Установка CNI |
3 |
Установка DNS |
6 |
Можно автоматизировать всю эту сотню команд на каждую ноду каким-то скриптом, но хочется чего-то проще. И способ сделать проще есть в документации Kubernetes. Kuber для оперирования кластерами предлагает Kubeadm. И если посмотреть, что делает Kubeadm, то можно прийти к выводу, что для первого мастера пять этапов из Hard Way сворачиваются в команду Kubeadm init со сгенерённым заранее конфигом. Для дополнительных мастеров все операции сворачиваются в четыре команды:

Если кажется, что даже четыре команды — это много, есть лайфхак. Можно заранее сгенерить сертификаты для kubelet:
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pemДобавить их на ноду вместе с:
"clientCAFile": "/etc/kubernetes/pki/ca.crt"
/etc/kubernetes/kubelet/kubelet-config.jsonИ запустить kubelet с ключом -- register-node. Он поднимется, зарегистрируется в кластере как нода, и даже Kubeadm join в этом случае делать не придётся (правда придётся делать команды, чтоб сертификаты сгенерить и положить, но вдруг для кого-то это прозрачней).
Итак, у нас есть четыре команды, которые нужно выполнить правильно, в нужное время, с нужным конфигом. Чтобы правильно их выполнять, начинаем делать прототип.
Прототипирование
Шаг 1. В первую очередь идём в наш плейбук, делаем окружение Dev, и для переменных в group vars вместо статичных значений ставим плейсхолдеры. Раскатываем прокатку конфигов на EC2-инстанс без экзеков Kubeadm. Получаем такие конфиги:
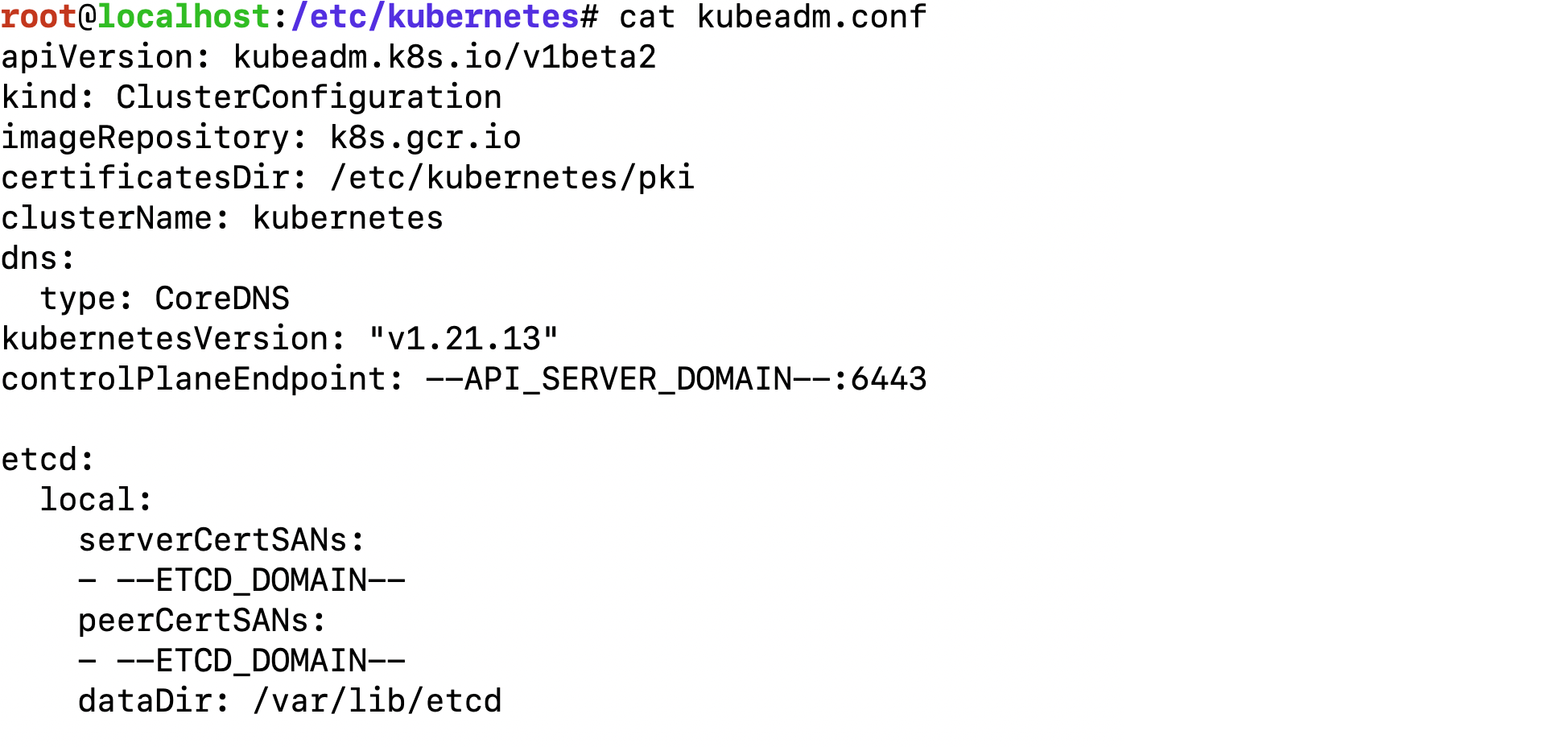
Шаг 2. Делаем снепшот с этого EC2-инстанса и через тестовую платформу поднимаем с этого снепшота новые машинки, для которых прописываем метаданные Amazon. Метаданные выглядят примерно так:
~ cat ud-decoded
{
"domainsEnv": "BASE_DOMAIN=* API_SERVER_DOMAIN=* ETCD_DOMAIN=*",
"masterAddr": "master01.build126.*",
"kubenodesAddr": "node01.build126.* node02.build126.* node03.build126.*",
"myDomain": "node03.build126.*",
"myRole": "node"
}

В метаданных AWS находятся просто значения переменных для плейсхолдеров, и роль ноды — мастер это или нода.
Шаг 3. Пишем скрипт в cloud-init, который идёт на сервер метаданных Amazon, забирает метаданные и подставляет значение переменных в плейсхолдеры. В зависимости от роли ноды (основная мастер-нода/дополнительный мастер/workload-нода), скрипт запускает соответствующие операции и поднимает кластер на каждой ноде независимо от других нод:

Запускаем инстансы кластера из снепшота, куда положили конфиги и скрипт, с проставленными метаданными, в течение 180 секунд ждём init’a и join’a всех нод — PROFIT.
В итоге получаем следующие результаты прототипирования:
Время поднятия на EC2 правда < 3 минут. У нас стоит ожидание в 180 секунд. Если мастер не дождался всех нод, которые были переданы в метаданных, за 3 минуты, то скрипт сваливается с exit code 1.
Правда сколько угодно кластеров, пока есть инстансы в облаке.
Непонятно, как это все скейлить и обновлять на лету, но сейчас такой задачи не стоит, потому что такие сборки не живут дольше недели.
Думаем, что получилось у нас неплохо. И это странно, потому что когда с первого раза получается неплохо? И решаем посмотреть, как сделано у вендоров.
А как у вендоров?
Берём в одну руку SSH, в другую руку берём grep, и идём для начала на ноды EKS.
EKS. Грепаем по слову eks в cloud-init-output.log и находим говорящий скрипт /etc/eks/bootstrap.sh:

На скрине — main-функция скрипта, если убрать все if’ы. Если приглядеться, то можно увидеть, что:
Через AWS CLI забираются сертификаты и переменные из метаданных.
Sed’ом эти переменные подменяются в конфигах с плейсхолдерами.
Запускается сервис systemctl start kubelet.
В принципе, это автоматизация The Hard way.
DigitalOcean. В логах cloud-init DO нет ничего, но если посмотреть скрипты cloud-init, то можно найти скрипт 000-k8saas:


Внутри него можно увидеть следующее:
Curl’ом забираются метаданные и складываются в файл на файловой системе.
Оттуда метаданные экспортируются в env-переменные.
Если у ноды роль master, запускается скрипт bootstrap-master, если роль kubelet, то запускается bootstrap-kubelet.
Сами скрипты не посмотреть, но файлик 10-kubeadm.conf и бинарь Kubeadm на самой ноде намекают на то, как поднимается и control plane, и нода в частности.
Метаданные выглядят так. Мы сильно удивились, когда увидели похожую с нашей логику с ролями:

GKE. Итак, у двух вендоров мы увидели примерно одинаковую архитектуру. Пошли на GKE, и тут увидели, на первый взгляд, что-то другое. Грепнули по kube в cloud-init-output.log и увидели следующие сервисы:

Подумали, что за интересные сервисы? Пошли в systemctl, нашли kubernetes.target, у которого есть сервисы kube-node-configuration и kube-node-installation:

Здесь мы понадеялись на ноу-хау, но в итоге это oneshot-сервисы, которые ведут на скрипты:

Функции в обоих скриптах — примерно одинаковые. В качестве примера посмотрим на функцию download-kube-masters-certs:

Вот что в ней происходит:
Curl’ом забираются метаданные с сервера metadata.google.internal.
Однострочником на Python из yaml-формата метаданные, в этом случае сертификаты, экспортируются в env-переменную.
Если посмотреть дальше по скрипту, будут те же самые sed’ы и systemctl start Kubelet.
В общем, кирпичики для того, чтобы поднять кластер таким образом, везде плюс-минус одинаковые:
Есть какой-то сервер метаданных — в случае облаков это их внутренние сервера.
Есть какой-то бинарь, который заберёт эти метаданные. У кого-то это AWS CLI, у кого-то curl.
Есть какой-то бинарь, который подменит метаданные. В общем случае это sed.
Есть что-то, что поднимет кластер либо в виде Kubeadm, либо в стиле Hard Way.
Есть куча систем которые генерируют эти метаданные которые разбросаны по облаку, в связи с чем время поднятия control plane везде около получаса. Но в нашем случае все быстрее, потому что пока их не так много.
Внедрение (но уже другое)
Наши HW-кластеры с их проблемами всё так же на месте. Мы хотим, чтобы в будущем они оперировались примерно так же, как и облачные кластеры. Для этого нужны:
Для Hardware |
Для облака |
Система инвертаризации. |
Процесс скейлинга кластера. |
Сервер метаданных. |
Процесс апгрейда существующих кластеров. |
Пулл-система обработки метаданных. |
Написать всё это можно, но нужно решить, как и каким инструментарием пользоваться. Это как всегда самый сложный вопрос. Мы идём в эту сторону, и уже сейчас видно, что когда мы туда дойдём, то столкнёмся с новыми проблемами.
Первым напрашивается то, что это будет пулл-система со всеми её проблемами, где кто-то ошибся, а оно раскатилось без ведома, что-то сломалось, но непонятно, где и как. Относительно fail fast подхода A/B-тестирования конфигурации, мы надеемся, что у нас это будет из коробки, потому что bare metal кластеры в данном случае становятся частным случаем наших облачных кластеров, которые поднимаются на EC2-инстансах.
При этом сама система объективно станет сложнее. Раньше у нас было — добавил инвентори и пошёл смотреть в логе, что там делают Jenkins и Ansible playbook. Сейчас появляются какие-то provisioner инстансов, поставщики метаданных, поставщик снепшотов, если они нужны, скрипт, который идёт на сервер метаданных. Как это всё между собой взаимодействует — отдельный вопрос.
С одной стороны, это всё новые сервисы, с другой стороны, никто не мешает их строить по принципу микросервисов. Мы знаем, как с ними работать: обложи мониторингом, логированием, сделай observability, и из минусов это всё превратится в плюсы. На этом этапе микросервисы докатываются до сопровождения инфраструктуры. Наверное, это даже хорошо.
Задачи на будущее
Если уходить от теории и говорить о задачах, которые мы планируем решить, то нам очень хочется:
Обновление ядер для 100 нод за час.
Уверенности в disaster recovery.
Чтобы все окружения раскатывались одинаково.
Уйти от зависимости в размере или количестве кластеров.
Если говорить про порядок, которым мы дальше пойдём, то он примерно следующий:
Добавить скейл и апгрейд на EC2-кластера.
Описать все дополнительные системы, необходимые вокруг bare metal.
Согласовать инструментарий с другими командами и бизнесом.
Внедрить.
Перезагрузить ноды кластера.
Ретроспективные выводы
Оглядываясь на 5,5 лет назад, мы верим, что по большому счёту наш путь был верным. Решение вкладываться во внутреннюю экспертность команды позволило нам со временем сделать что-то, что похоже на решение вендоров, но на Bare Metal, совмещая и возможность самостоятельно контролировать конфигурацию K8s, и возможность не тратить большoе число времени на поддержку самого K8S.
Но как бы мы поступали, если бы внедряли сейчас кластеры с нуля? Бизнес, скорее всего, сказал бы: «Поехали на EKS, эксперты в сообществе есть, и вроде всё работает». Однако все вопросы, кому разбираться, когда что-то идёт не так, — техподдержке или внутренним людям — они остаются. И кажется, что в процессе проработки мы бы дошли до выбора собственного решения.
Скорее всего, это тоже была бы пуш-конфигурация. Если посмотреть с нуля на все эти системы, которые нужны для оперирования кластером за три минуты, может стать страшновато. Возможно, мы бы испугались, что нужны метаданные, скрипты, и нужно что-то писать вокруг кластера, когда хочется просто получить кластер. Но сама итерация между пуш-конфигурацией и пулл-конфигурацией сейчас прошла бы быстрее: уже есть опыт сообщества и есть люди, которые могут им поделиться.

Fitrager
Мне кажется самый правильный путь поднимать kubernetes в bare metal и разбираться как он работает под капотом с помощью самого сложного пути - сборка кластера kubernetes по частям. Сам в своё время проходил этот путь.