
Привет, Хабр! Меня зовут Руслан Сафин и я расскажу про микросервисы и как определить необходимую гранулярность. Статья написана по следам моего доклада на TechLeadConf 2022: видео, тезисы и презентация.
Я работаю техническим директором в Byndyusoft. Развиваю техническую культуру и участвую в проектах в роли IT-архитектора, а ещё преподаю авторский курс по IT-архитектуре в университете. В коммерческой разработке 15 лет. Из необычного — проектировал защиту от накруток в интернет-голосовании конкурса Мисс Россия и автоматическое определение предвзятости судей в танцевальном спорте.
Byndyusoft занимается заказной разработкой с продуктовым подходом. Так как наша компания работает с крупными заказчиками, мы постоянно учимся новому, перенимаем и сами делимся практиками, наблюдаем и используем разные подходы и приёмы проектирования. Этим практическим опытом я и поделюсь в статье.

Как спроектировать микросервисы с нуля
Представим, что нам нужно спроектировать систему полностью с нуля. Уже есть предварительные требования, проведен системный и бизнес анализ. Что делать дальше? Как определить, сколько сервисов нужно и какими они должны быть.
Теория идеального микросервиса
Тема микросервисов уже достаточно старая, ей больше 10 лет точно. За это время появилось много статей и книг по теории.
Я попробовал обобщить всю теорию, и у меня получилось выделить 4 принципа идеального микросервиса:
-
Единственность ответственности. Это принцип из SOLID для проектирования классов. Он означает, что у одного микросервиса должна быть одна ответственность, а также что за одну ответственность отвечает ровно один микросервис.

-
Ограниченный контекст. Этот термин из Domain-Driven Design Эванса и его последователей. С его перекладыванием на микросервисы уже возникают, на мой взгляд, некие сложности. Напомню, что ограниченный контекст — это набор ограниченного смысла или ограниченной модели, который отвечает за некую бизнес-логику.
Ловушка в том, что при переходе на микросервисы и их проектировании есть соблазн выделить ограниченные контексты и сказать, что один контекст — это один сервис. На мой взгляд, это не так, по крайней мере, не всегда.
К примеру, гайдлайн от Microsoft по проектированию микросервисной архитектуры утверждает, что вторым шагом мы должны определить bounded contexts, и спроектировать наполнение каждого из них. То есть внутри ограниченной модели определить сущности, агрегаты и микросервисы. Несмотря на то, что смысловой периметр логики и данных ограничен, нам нужно в процессе работы контекста, к примеру, сформировать сущность, её сохранить, обсчитать и на что-то ещё и смаппить. Как правило, это делает не один сервис, а целая пачка микросервисов с отдельными ответственностями.
-
Связанность и связность. Рассмотрим два варианта взаимодействия контекстов:
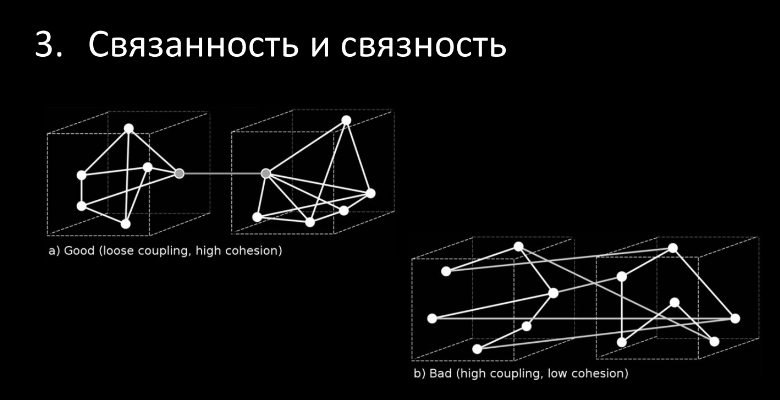
Сверху слева мы видим низкий coupling (низкую связанность) и высокий cohesion (высокую связность или прочность). В такой архитектуре мы получаем прочные контексты, слабо связанные с друг с другом.
Второй вариант хуже — контексты рыхлые, у них низкая прочность внутри, и они лапшеобразно связаны друг с другом, то есть высокая связанность снаружи. Более предпочтителен первый вариант. Принципы проектирования пакетов/сборок. Одновременно с принципами SOLID Роберт Мартин сформулировал ещё и 6 принципов проектирования сборок, про которые часто незаслуженно забывают:
Reuse/Release Equivalence Principle
Common Reuse Principle
Common Closure Principle
Acyclic Dependencies Principle
Stable Dependencies Principle
Stable Abstractions Principle
Помимо описания в книге, принципы много раз перепечатаны и легко гуглятся

Как раз эти 6 принципов, на мой взгляд, идеально ложатся на проектирование микросервисов, в отличие от 5 принципов SOLID, которые все-таки больше про классы в ООП. Часть из них мы затронем в статье.
Мы рассмотрели 4 группы, в которых я обобщил всё многообразие принципов. Именно этот набор мы в компании и используем на своих проектах при проектировании микросервисной архитектуры.
Казалось бы, есть принципы и много теории: прочитай книги и иди проектируй. Но на практике, как правило, всё оказывается сложнее. Примерно то же самое происходит, когда мы проектируем монолит, пользуясь паттернами и принципами ООП — в итоге рано или поздно все равно всплывает техдолг.
Противоречия и сложности на практике:
Баланс соблюдения принципов. Мы пытаемся соблюсти один принцип, нарушается другой. Нам нужно ловить баланс, а он достаточно непростой.
Процессные и технические ограничения. Все мы живем в реальном, неидеальном мире. Всегда есть процессные ограничения, будь то бюджет или срок проекта, команда, технические ограничения. К техническим ограничениям я отношу инфраструктуру, готовность переходить на микросервисы и их поддерживать, разворачивать.
Рефакторинг и развитие архитектуры. Архитектура — это не что-то статичное, не так, что мы что-то запроектировали, отрисовали и ушли на 2-3 года в разработку, а она не меняется. Как код и любые другие процессы, архитектура тоже должна меняться. Ведь постоянно появляются новые требования на рефакторинг и внесение большей гибкости.
Мы рассмотрели теорию. Теперь приведу несколько упрощенные, но реальные примеры из практики — чтобы и в рамки статьи вместиться, и не скатиться в совсем простые и оторванные от жизни учебные примеры.
Примеры гранулярности из жизни
Разберем два примера — систему, которая спроектирована с более крупными микросервисами (чем было бы целесообразно), и систему с более мелкой (чем того требовала задача) нарезкой микросервисов. Разберём плюсы и минусы каждого примера и сформулируем сигналы, на которые можно обращать внимание, чтобы отрефакторить нашу архитектуру.
Крупно нарезанная система
Представим, что мы делаем систему доставки для интернет-магазина, в котором есть три типа доставки:
Курьерская доставка, когда курьер приходит к вам домой до двери;
Доставка в пункт выдачи заказов (ПВЗ);
Самовывоз из магазина.

Наверное, самое первое и логичное, что приходит в голову — разделить систему на 3 сервиса, каждый из которых будет отвечать за свой тип доставки. Если вы так сделали и у вас всё работает, ничего не трогайте!
Но с развитием проекта, могут появляться тревожные сигналы, что что-то идёт не так:
-
Повторы или циклы в трассировках. Рассмотрим частый сценарий, когда мы хотим на витрине показать все наши пункты выдачи заказов на карте, и туда же добавить магазины, чтобы на одной карте, на одном экране видеть все варианты пунктов выдачи. Как правило, интернет-магазины показывают и пункт выдачи, и дату доставки для каждого.
Например, чтобы посчитать время доставки, каждый из наших сервисов (типов доставки) должен знать время комплектации — когда товар соберут, когда его можно забрать со склада и когда его доставят в пункт. Может оказаться, что расчет времени комплектации при обращении к сервису расчета комплектации произойдет два раза, то есть мы просто два раза произведем один и тот же расчет, что не очень хорошо.
Такие повторы легко увидеть в трассировке запросов (например, в Jaeger) — мы просто смотрим трассу и видим, что повторяется один и тот же сервис, один и тот же endpoint. Сложнее отследить повторы и дубли в данных: некритично если это небольшой JSON, но если у нас мегабайтные JSON передаются по цепочке трассировки из 5-го сервиса в 4-й, из 4-го во 2-й, из 2-го в 1-й, а на самом деле они нужны только в одном месте — это явно проблема.
Кстати, в трассировках могут быть даже циклы — мы пошли в первый сервис, второй, в третий, потом снова в первый. Это уже совсем тревожный звоночек, что пора всё рефакторить. -
Нарушение инкапсуляции и избыточность. Представим другой сценарий, что один из потребителей нашего API хочет показывать минимальный срок доставки — например, “доставка от 2 дней”. Он должен знать про все три типа доставки, сходить во все три сервиса и вычислить минимальное из времени доставки, которое там есть.
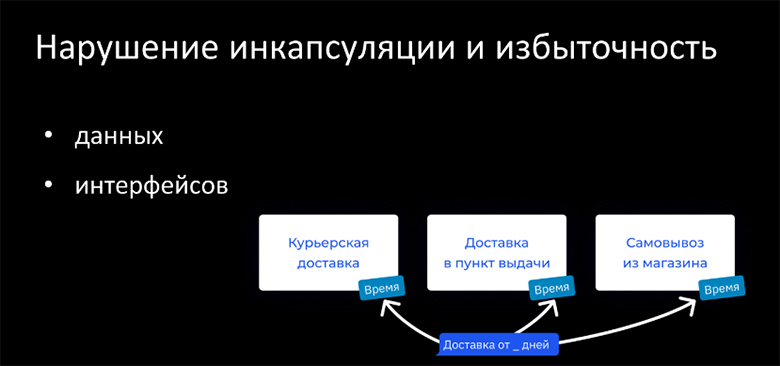
То есть небольшому микрофронтенду (отвечающему только за одну цифру минимального срока доставки) придется знать про огромные сервисы и про богатое API, которые они предоставляют, включая API по стоимости, списку ПВЗ и т.д., а ведь ему нужен совсем маленький кусочек — минимальное время доставки. Таким образом, у нас появляется избыточность интерфейсов, а в худшем случае — избыточность данных. К примеру, мы посчитали всё время доставки, отдали 10-мегабайтный JSON на тысячу пунктов выдачи, а нашему консьюмеру нужна была только одна цифра, потому что минимальное время — это 2 дня. Такая избыточность приводит не только к накладным расходам на сеть и процессорное время, но и в целом делает систему более хрупкой, т.к. позволяет использовать данные и контракты не по прямому назначению.
-
Дублирование. С ростом нашего проекта в сервисах, скорее всего, дублироваться начнут ответственности. В каждом из наших сервисов, к примеру, появится расчет стоимости и расчет времени, про который мы уже говорили. Соответственно, нашим сервисам потребуется дублировать и интерфейсы (контракты API), которые отвечают за стоимость и время.

Может появиться даже дублирование кода. От него, конечно, легко избавиться при помощи выноса логики в общий пакет или сборку, но с точки зрения архитектуры — это все равно дублирование, т.к. мы один и тот же функционал используем в разных сервисах.
Мы обсудили три звоночка о слишком крупном проектировании сервисов, которые наиболее часто встречаются и которые можно отследить. Теперь рассмотрим плюсы и минусы варианта архитектуры с более крупными сервисами.
К преимуществам крупно нарезанной системы в первую очередь можно отнести простоту и более низкие требования к инфраструктуре, разработке и тестированию. Эти преимущества вытекают из того, что подход более классический, похожий на монолит. Например, систему с небольшим количеством сервисов можно локально развернуть на компьютере разработчика или QA, инфраструктура не требует полной автоматизации (какие-то ручные действия можно и повторить, если это не десятки сервисов) и т.д.
Недостатки крупно нарезанной системы:
Повышенные риски техдолга для комплексных фич и интеграций. В нашем примере рассмотрим сценарий, когда нужно рассчитать оптимальное соотношение стоимости и времени доставки. Такой расчет придется или дублировать во всех сервисах каждого типа доставки, или создавать отдельные потребители соответствующего API каждого из сервисов. Как и комплексные фичи комплексные интеграции, скорее всего, также приведут к техдолгу: если у нас было два доставщика, и мы решили добавить ещё парочку, то нам придется опять обращаться ко всем сервисам и каким-то образом реализовать интеграцию в каждом.
Сложнее обеспечить гибкую отказоустойчивость, быстродействие и масштабирование. Пожалуй, это главный и часто упоминаемый минус монолитов, также свойственный и крупным микросервисам.
Мелко нарезанная система
Теперь рассмотрим тот же самый пример системы, но когда в архитектуре мы нарезали сервисы, наоборот, мельче чем нужно.
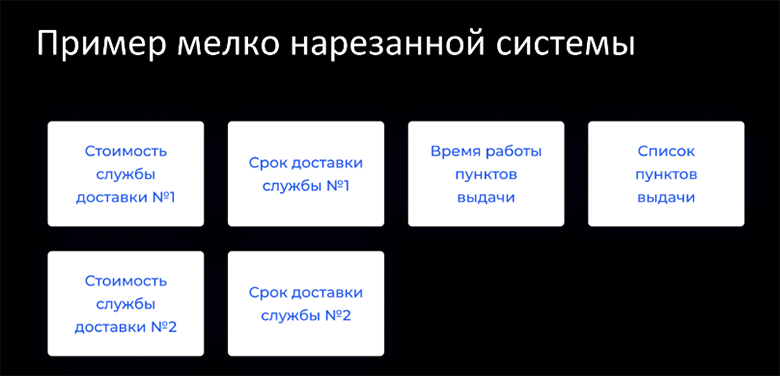
В этом варианте нарезки мы оттолкнемся не от типа доставки, а от разных ограниченных контекстов — например, контекстов стоимости доставки, срока доставки и контекста пунктов выдачи. В контекст стоимости добавим два микросервиса с разным расчетом стоимости доставки для первого и второго доставщиков. Точно также поступим с контекстом срока, т.к. алгоритмы расчёта срока тоже могут разниться между разными службами доставки. В контексте пунктов выдачи — выделим мастер-данные со списком ПВЗ, доступных в каждом городе, и (зачем-то) отдельно выделим время работы этих пунктов.
Посмотрим теперь в таком варианте, какие могут быть тревожные сигналы о слишком мелкой нарезке, и на что можно обратить внимание:
-
Максимальная сцепленность (cohesion). Максимальная сцепленность (или неотделимость) может быть по данным и по ответственностям. В нашем примере — мы понимаем, что отдельно время работы пунктов выдачи нам вообще ни в одном сценарии не требуется: всегда, когда мы загружаем список пунктов выдачи, должны сразу подтягивать туда и время их работы. Нет такого сценария, что мы отдельно берем список без времени либо, наоборот, берем время без списка. Это и есть максимальная сцепленность — настолько прочны эти атомы-микросервисы, что могут слиться в одну молекулу и нет смысла их дробить.

-
Нарушение инкапсуляции. Следующий сигнал — это опять нарушение инкапсуляции (как и в случае с крупными сервисами), но уже с другой точки зрения. Тут нарушается инкапсуляция контекста либо сервиса.
Напомню, в нашем примере есть контексты стоимости и срока доставки. Если мы хотим добавить третью-четвертую-пятую службу доставки, то нам придется в каждый из этих контекстов добавлять микросервисы. Проблема не в том, что функционал расширяется — это нормально. А проблема в том, что мы добавляем сервисы в нескольких контекстах. Т.е. одна причина — добавление службы доставки — требует изменения не в одном, а в нескольких контекстах. Таким образом нарушается инкапсуляция и единственность ответственности на уровне ограниченных контекстов сервисов.
-
Линейный рост инфраструктурных работ. Если мы достаточно мелко нарезали систему, то сервисов к нас получилось много. И мы можем заметить, что с увеличением числа сервисов линейно растет инфраструктурная ручная работа и нагрузка на девопсов. И рано или поздно у нас остается только два варианта: либо нам необходимо повысить уровень инфраструктуры и автоматизации, либо — признать, что пока уровень инфраструктуры не тянет нашу архитектуру, и нужно отказываться от мелкой гранулярности и переходить на более крупную. Иначе мы не сможем вечно добавлять сервисы и просто упремся в наш DevOps.
Подробно о повышении уровня инфраструктуры я рассказываю в этом докладе: Как снизить накладные расходы на добавление +1 микросервиса / Руслан Сафин
К преимуществам мелконарезанной системы, помимо стандартных плюсов микросервисов в гибкости работы с отказоустойчивостью и масштабированием, я бы отнес гибкую работу с техдолгом на уровне архитектуры. Когда сам сервис совсем небольшой, буквально 10-20-50 строк кода, которые отвечают только за бизнес-логику, вряд ли мы накопим большой технический долг на уровне кода. Техдолг перетекает на уровень архитектуры, и уже там мы можем вынести новый сервис, переписать сервис заново, либо объединить три сервиса в один и т.д.. Такая работа с техдолгом более гибкая, простая и, как правило, команды проще за это берутся т.к. не нужно переписывать и рефакторить огромные куски кода — можно что-то небольшое просто отключить и заменить новым.
Недостатки мелконарезанной системы
Выше требования ко всем этапам разработки: проектированию, инфраструктуре и разработке, тестированию, деплою и поддержке
Выше риски избыточной работы. Достаточно высокий шанс, что мы где-то будем over-engineer’ить. Если достаточно мелко нарезать сервисы, то часть фич нам будет сложно реализовать — например, для выкатки небольшого нового функционала придется деплоить по 5 сервисов за раз.
Как достичь баланс
Мы рассмотрели два противоположных примера. Но вопрос остался открытым — как же всё-таки спроектировать “правильно”? Я постарался сформулировать 4 общих принципа, которые помогут приблизиться к балансу при нарезке микросервисов. В детали каждого из них можно погружаться долго и глубоко (например, под мастер-данными понимаю подход, описанный в статье Управление мастер-данными в микросервисной архитектуре), пока попробуем их назвать кратко.
Путь к золотой пуле — выделение корней агрегации согласно домену и контексту видимости
Выделение корней агрегации согласно домену и контексту видимости. Как правило, многие выделяют корни агрегации, но часто забывают про контекст видимости. Например, есть контекст, который рассчитывает клиентскую стоимость доставки, но нам ещё нужна себестоимость доставки для интернет-магазина. Скорее всего, у этих стоимости и себестоимости будут разные контексты видимости: стоимость нужна для показа клиенту на витрине; а себестоимость не интересует сервисы, которые отвечают за витрину. Себестоимость нужна для аналитических систем и внутренней кухни (например, проверки выставленного счета службой доставки), в которых, скорее всего, клиентская стоимость уже не так важна.
Если у корней агрегации разные контексты видимости, то советую разделять их на два агрегата.Отделение бизнес-логики от данных и состояния. Это принцип из классического программирования. Если сервис является мастер-системой, то он отвечает за хранение данных, их обновление и предоставление доступа к чтению. Не нужно в тот же сервис вмещать бизнес-логику, лучше её вынести в отдельный микросервис.
Сокрытие
костылейнюансов интеграции на периметре, так называемый anti corruption layer. Наверняка у многих были ситуации, когда мы интегрируемся с внешней системой, и нам приходится писать какие-то «if’чики»: если external ID = 108, то сделай это. Эту ID = 108 лучше не пропускать внутрь периметра нашей системы. Давайте ее обработаем где-то на входе в периметр и забудем. Т.е. если ID = 108, то мы идем по такому-то бизнес-процессу, и никакие сервисы внутри нашего периметра не знают про этот костыль с магической айдишкой.Разделение BFF согласно архитектуре фронтенда. Этот принцип также касается организации периметра нашей системы. Периметр — это или интеграция с внешними системами, или с пользователем (взаимодействие с нашим UI-интерфейсом). Если у нас микрофронтенды на UI, то хорошо сработает вариант, когда наши BFF-сервисы (Backend-for-Frontend) повторяют архитектуру на фронтенде. Т.е. под каждый микрофронт — свой BFF. Другой пример — это отдельные BFF для мобильных приложений, десктоп-приложений и так далее. В любом случае, советую делить BFF для крупных систем, чтобы не выставлять всё развесистое API в одном единственном BFF.
Если попробовать применить эти принципы к нашему примеру, то получится такой вариант:
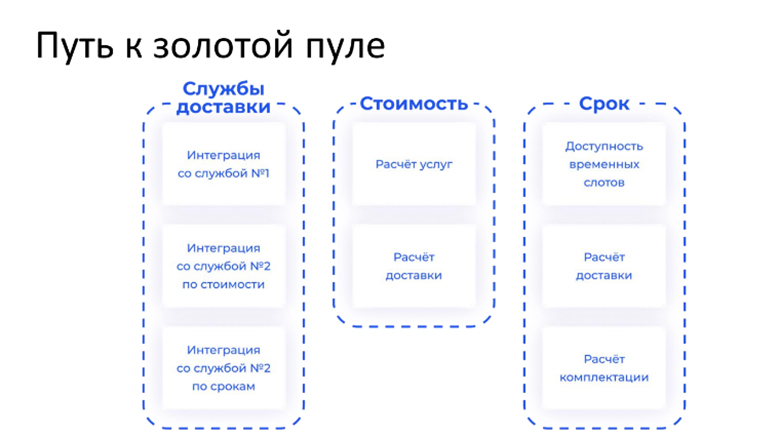
Выделяем три контекста:
Интеграция со службами доставки. В данный контекст мы можем добавлять сколько угодно сервисов для каждой службы доставки. Допустим в приведенном примере нам необходимо два разных сервиса для стоимости и сроков. Главное, что при добавлении одной службы доставки добавятся несколько новых микросервисов только в один этот контекст.
Расчет стоимости. В этом контексте есть общий расчет стоимости доставки (допустим, междугородней Москва-Самара), а уже в доставке по Самаре могут быть варианты: или мы рассчитываем стоимость доставки до пункта выдачи, или нужно дополнительно включить услуги подъема на этаж, сборку и т.д. То есть внутри контекста стоимости мы уже выделяем отдельно расчет общей доставки для разных типов и отдельно расчет услуг, допустим, для курьерской доставки.
Расчет сроков. Здесь ситуация аналогична расчету стоимости — есть общий расчет срока доставки и специфика для конкретного типа, например, расчет доступных временных слотов доставки для курьеров.
Запроектированная архитектура и выбор целесообразного способа разделения на микросервисы, не должны быть статичны. Я на самом деле удивился, что даже в российских ГОСТах черным по белому написано, что архитектура изменяема во всем жизненном цикле проекта. Об этом же говорит Эрик Эванс в докладе. Там он представляет слайд, который, на мой взгляд, заслуживает внимания:
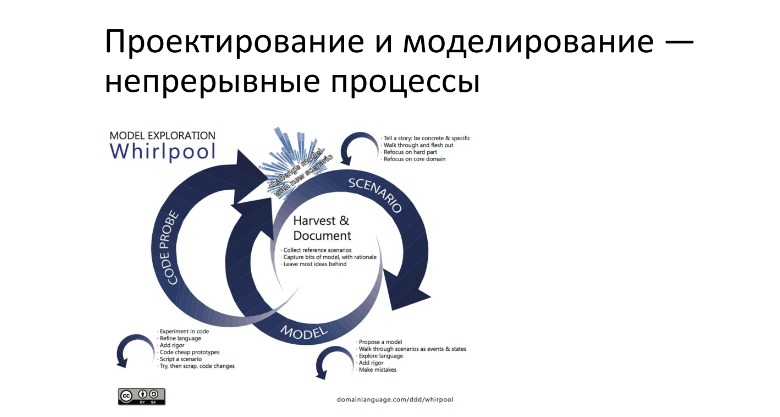
https://www.domainlanguage.com/ddd/whirlpool/
Если коротко изложить идею, то есть поток сценариев, который приносит аналитический отдел. Этот поток запускает вихри моделирования и проектирования — в том числе моделирование данных и проектирование архитектуры. В свою очередь этот процесс запускает третий вихрь — пробу кода. Мы пробуем это реализовать, и в определенный момент все эти вихри сходятся в одной точке. А дальше мы смотрим — подошли ли это моделирование, проектирование и проба реализации или нет.
Эрик Эванс говорит про этот подход в докладе и противопоставляет его водопаду.
С чего начать нарезку сервиса
Вернемся к нашей базовой проблеме — мы подошли к новому проекту и не знаем, с чего начать. Я предлагаю следующий список того, что нужно определить и прозрачно зафиксировать для старта проектирования:
Мастер-данные, то есть агрегаты.
Ответственности и намерения. Особенно важны намерения. Когда говорят про классы в ООП, про ответственности обычно помнят, а про намерения, на мой взгляд, незаслуженно забывают. Если в целом класс — это ответственность, то намерение — это, скорее, метод класса или функция. У сервисов точно также — есть базовая общая ответственность, за которую он отвечает, и есть REST API с набором методов-намерений. Например, намерение определенного endpoint’а — расчет минимальной стоимости доставки или расчет доставки Москва-Петербург.
Внешние влияющие факторы. Всегда есть внешние факторы, влияющие на разработку — сроки, бюджет, опыт команды, уровень инфраструктуры и т.д. Нужно честно себе в них признаться и не обманывать себя, иначе это повредит проекту. Лучше визуализировать и рассказать о них всей команде и бизнесу.
Вопросы практику
Для проверки того или иного вариантов разделения на микросервисы, я советую использовать следующий список контрольных вопросов, помогающий понять насколько крупно, мелко или нормально мы нарезали сервисы.
Что будет, если мы раздробим/попарно объединим мастер-данные? Мы произвели разбивку системы на несколько сервисов, отвечающих за те или иные мастер-данные, и теперь попробуем челленджить решение с помощью этого вопроса.
Что будет, если мы преобразуем ответственность (микросервис) к намерению (endpoint) более крупного сервиса и наоборот? Например, у нас есть сервис, рассчитывающий стоимость доставки с endpoint’ом, который считает минимальную стоимость доставки. Что будет, если этот endpoint вынести в отдельный микросервис расчета минимальной стоимости? Чтобы узнать это, мы визуализируем архитектуру и проверяем её нашими принципами (coupling, cohesion и др.) и бизнес-сценариями. И наоборот, если мы сразу выделили микросервис для расчета минимальной стоимости, то выясняем, что будет, если преобразовать этот микросервис к endpoint’у более крупного сервиса с более крупной ответственностью?
Насколько влияют на разработку внешние факторы? Например, каковы: наш уровень инфраструктуры, готовность нашего DevOps к большому или малому количеству сервисов, квалификация и опыт команд. Если команда всю жизнь писала монолиты, то сложно сразу перейти на систему, когда один человек разрабатывает 5-10 сервисов, лучше начать с небольшого числа сервисов на человека.
Выводы
Мы рассмотрели теорию «идеального» микросервиса, попробовали выделить ее основные моменты (объять необъятное ????).
Разобрали варианты проектирования системы для конкретной задачи: крупнее целесообразного, мельче целесообразного и целесообразный.
-
Выделили три чек-листа:
Принципы разделения, на что нужно обращать внимание;
Факторы-пререквизиты, которые при этом нужно учитывать;
Контрольные вопросы для проверки, крупно мы нарезали, мелко или идеально.
На DevOpsConf 2023 будет трек полезный техлидам и много других актуальных кейсов. Пока не закрыт приём заявок. Ещё 3 дня, до 1 декабря включительно, можно подать свой доклад на выступление на конференции. Ждём ваши предложения и заявки на участие.
Комментарии (8)

sgjurano
29.11.2022 09:36+3При чтении статьи возникла мысль, что самое правильное разбиение приведенной функциональности на микросервисы — оставить её в покое, и не пытаться её пилить пока в этом не возникло необходимости.
Сложности с определением точек разделения, по опыту, говорят в первую очередь о недостатке информации, то есть о преждевременности распила.
Стоило бы дождаться пока потребности себя проявят, и пилить после этого по уже понятным лекалам.
Самая большая трудность при распиле будет заключаться в разделении данных, поэтому по возможности стоит избегать возникновения связей в подозрительных местах.

razon Автор
29.11.2022 10:39да, только дело в том, что в живых проектах потребности, как правило, постоянно растут и видоизменяются. Тут главное не пересидеть — пока будем ждать промежуточного или окончательного устаканивания потребностей (которого может и не произойти), техдолг будет всё расти и расти, увеличивая сложность и стоимость требуемого рефакторинга
sgjurano
29.11.2022 11:00Так и есть, однако не стоит сбрасывать со счетов, что выбор неверных точек разделения на начальной стадии проекта приводит к бо́льшим трудозатратам на протяжении всей жизни проекта, ну и при рефакторинге появится необходимость сливать части системы, а не только разделять их.
Я эмпирическим путём пришёл к тому, что для крупного рефакторинга нужно не менее 3 сценариев, не укладывающихся в исходную архитектуру, иначе очень велик риск неверного обобщения.
razon Автор
29.11.2022 11:40естественно, если всё работает — ничего не трогай ) работает в плане стабильного time-to-market и качества при внесении изменений. В данной статье как раз и постарался выделить сигналы и моменты, когда пора не только разделять, но и объединять сервисы.
Про более общую тему рефакторинга архитектуры микросервисов (а не только про объединение/разделение) я говорю в следующем докладе (пока в открытом доступе есть только описание и слайды), надеюсь в будущем так же его опубликовать на хабр

erlyvideo
30.11.2022 21:16+1мне всё таки кажется, что важный момент ещё кадровый. Сомнительная идея делать по 10 микросервисов на одного программиста (и я такое видел)
razon Автор
30.11.2022 22:17Опыт команды безусловно важен, я его и упоминаю во внешних факторах, которые необходимо учитывать. При этом вовсе необязательно, чтобы все разработчики были синьорами: при высоком уровне инфраструктуры добавление нового микросервиса сводится только к программированию бизнес-логики, и в случае мелкой гранулярности эти несколько строк кода легко можно поручить и менее опытному коллеге.
На мой взгляд, нельзя сказать что 10 сервисов на человека или 10 человек на сервис — плохо, опять же оптимальность соотношения будет зависеть от многих факторов. Главное избегать жесткой привязки: что конкретный микросервис знает и изменяет только конкретный разработчик, т.е. 20 микросервисов на двоих лучше, чем 10 на каждого. На некоторых проектах у нас примерно такое соотношение и получается (~40 микросервисов на 4 бэкенд разработчика)
Politura
Хм, а в чем сложность-то? Вроде горизонтальное масштабирование, и отказоустойчивость делается плюс-минус одинаково, что для мелких микросервисов, что для крупных, что для монолитов. Наоборот, если нарезать слишком мелко, то можно легко нарваться на необходимость в распределённых транзакциях и вот тут уже проседает быстродействие и появляется геморрой.
razon Автор
под отказоустойчивостью тут подразумеваю Fault tolerance. К примеру, при отказах более мелких сервисов у нас деградация по функциональности будет ниже, чем если ложаться крупные куски системы