

Значимость темы машинного обучения (machine learning) сегодня очевидна. Это огромный домен знаний в Computer Science, которому в России, в частности, посвящают конференции уровня недавней AI Journey. Существует множество способов применения ML в различных областях, среди самых исследованных: распознавание изображений/видео/голоса, процессинг текста. Однако есть и более любопытные задачи, с которыми справляется ML. Например, обучение с подкреплением, что позволяет ИИ играть в игры типа Го, идентификация людей по фотографии, распознавание жестов, движений и поз человека.
Одной из не совсем обычных областей применения машинного обучения можно назвать работу с трехмерными телами. Такая технология активно исследуется за рубежом, а вариантов использования у нее может быть масса. Простой пример: дрон сканирует помещение, в котором находится множество тел. С помощью ML дрон может классифицировать объекты окружения, найти ошибки в пространственном размещении этих тел или же построить 3D-интерьер комнаты со ссылками на онлайн-магазин, где эти предметы можно купить.
Под катом — рассказ о том, как наш сотрудник задействовал машинное обучение для распознавания и классификации трехмерных тел. При этом весь информационный контекст был ограничен геометрией этих тел, то есть исключительно набором вершин и полигонов.
Привет, Хабр! Меня зовут Владимир Цышнатий, я ведущий разработчик C++ в МойОфис. Оригинальную версию этой статьи я написал четыре года назад, когда инструменты машинного обучения уже вызывали активный интерес крупных компаний. В 2022 году ML все чаще называют доминирующей отраслью технологий и, учитывая повышенное внимание к этой теме, я решил «оживить» свой материал: внес некоторые правки и рад представить его хабрасообществу. Надеюсь, этот труд пригодится моим коллегам и последователям :)
Тема статьи обусловлена моим прошлым профессиональным опытом: в 2018 году я работал в компании, которая создает трехмерные BIM/CAD системы проектирования. Однажды утром у нас с коллегами разгорелся спор о возможностях применения технологий машинного обучения в области распознавания трехмерных тел. В ходе дискуссии была сформулирована прикладная задача; ее суть я описываю ниже.
Представим себе здание — многоквартирный дом, — в котором все квартиры полностью укомплектованы мебелью: есть стулья, столы, кровати и так далее. При этом все подобные предметы представлены 3D-моделями, импортированными в проект в виде вершин и треугольников — без какого-либо контекста вроде меток и любой другой заданной специфики. Нам необходимо создать спецификацию для этих тел, то есть посчитать, сколько стульев/столов/другой мебели нужно купить, чтобы обставить все квартиры.
Конечно же, можно просто попросить пользователя указать на этапе загрузки модели в проект, что именно он импортировал. Однако спор требовал пойти по пути технологий и автоматизации.
Что ж, вызов принят: нужно создать Proof Of Concept. Исследование уже имеющихся методов привело меня сюда.
Для пробной реализации был выбран метод DeepPano — за его оригинальный подход к проблеме, простоту реализации и приличные (на момент написания оригинальной статьи) результаты.
Собираем данные
В 2018 году подходящих для моей задачи датасетов было совсем мало. (Впрочем, и сейчас область обработки трехмерных тел с помощью алгоритмов машинного обучения значительно менее изучена, чем, к примеру, обработка изображений или текста.) Поэтому данные пришлось добывать с миру по нитке. Одним из лучших вариантов оказался ModelNet10, который представляет собой набор тел из 10 категорий. Всего в этом датасете около 5000 моделей, включая различные шкафы, телевизоры, стулья и прочие подобные предметы — то есть то, что нам нужно.
Оказалось, датасет очень несбалансирован.
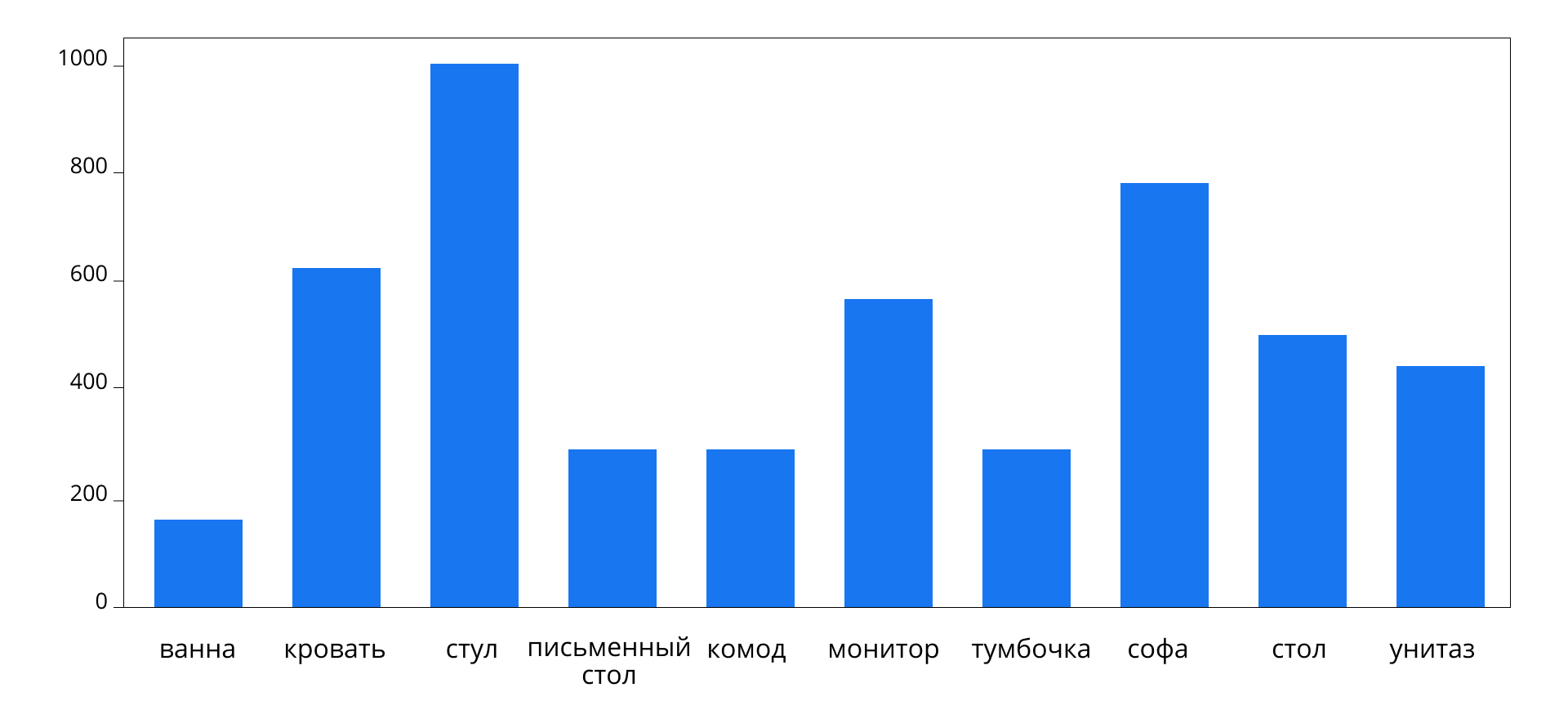
В нем обнаружилась масса дубликатов, число семплов после их удаления оставило около 3500. Очевидно, это слишком маленький набор данных, ведь мы, по большому счету, еще даже не начинали с ними работать. Я решил загрузить больше моделей нужных мне категорий с 3D Warehouse.
Проблема в том, что эти модели представлены в формате .skp — внутреннем формате SketchUp. Мне же нужны лишь треугольники, кроме того, в ModelNet10 все модели существуют в формате .off, который представляет из себя только сохраненную геометрию, без материалов и другого контекста. Очевидно, из .skp можно вытянуть геометрию и сохранить в .off. Проделать это можно с помощью SketchUp C API. Кроме того, для некоторых категорий дополнительные данные набрать не удалось и, поскольку моя работа — всего лишь Proof Of Concept, такие категории были удалены. Осталось 7 категорий объектов.
После всех этих манипуляций датасет получился таким:

Разбалансировка все еще есть, ее я решил компенсировать весом семплов или аугментацией. На этом этап сбора и первичного процессинга данных я посчитал завершенным.
Прежде чем делать дальнейший препроцессинг данных, давайте разберемся, в чем основная идея метода DeepPano и какой именно препроцессинг нам потребуется для его использования.
В чем плюсы DeepPano?
DeepPano не занимается распознаванием 3D-геометрии напрямую. Вместо этого метод сводит задачу к распознаванию grayscale-изображений. Получается это с помощью создания разновидности цилиндрической проекции.
На вход подается трехмерное тело (это именно визуализированное тело, его можно покрутить):

А результатом является картинка в градациях серого (именно картинка, покрутить нельзя):

Так как же работает цилиндрическая проекция?
Рассмотрим на примере кубика.
Представим, что есть кубик, расположенный нижней гранью на плоскости XoY, в то время как ось Z проходит через центр кубика.
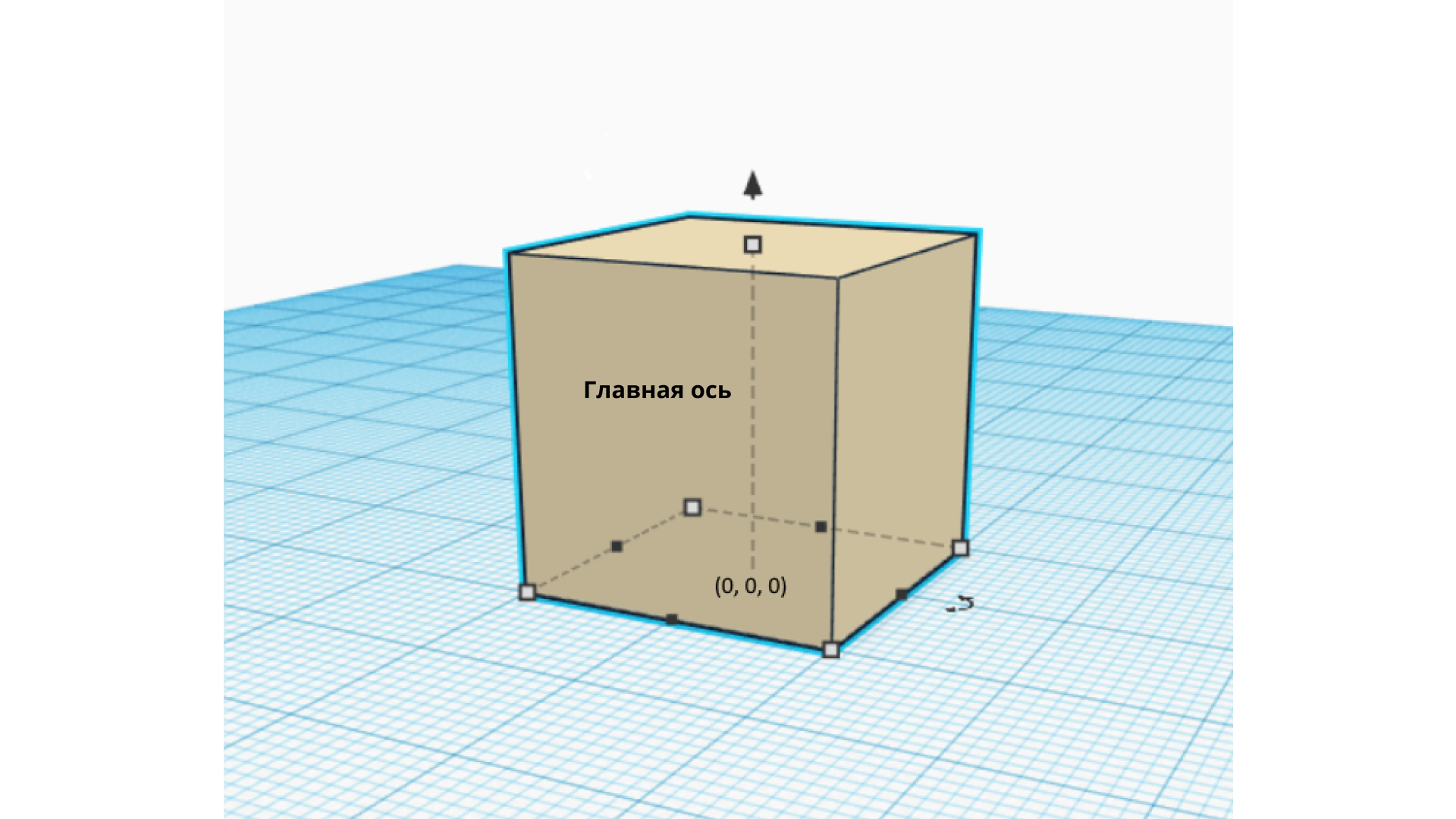
Ось Z назовем Главной осью (Principal Axis) Далее представим себе цилиндр, описанный вокруг этого кубика:

Теперь нанесем на боковую поверхность цилиндра сетку размером MxN.

Теперь спроецируем каждый узел сетки на Главную ось. Обозначим множество получившихся проекций как P (points), а множество отрезков, соединяющих узлы сетки с их проекциями — S (segments).

Для каждого отрезка из множества S пересекаем его с кубиком и запоминаем точку пересечения для каждого узла сетки.
В общем случае (для тела, которое не является кубиком) мы можем получить несколько пересечений или же, напротив, ни одного:

Если точек пересечения нет, запоминаем это в узле сетки, а если таких точек несколько, берем ближайшую к узлу сетки. То есть мы смотрим на внешнюю поверхность тела, игнорируя возможные полости в нем.
Теперь каждому из узлов сетки соответствует либо точка, в которой отрезок пересекается с внешней проекцией тела, либо отсутствие такого пересечения. Обозначим это множество как R.
Теперь мы можем сформировать результат преобразования тела в картинку с помощью следующего алгоритма:
Создать матрицу изображения размером MxN (такого же, как размер сетки на цилиндре)
-
Для каждого элемента из R (текущий элемент из R обозначим CR):
Если пересечения нет, то в матрицу-изображение вносим 0 — черный пиксель
-
Иначе
Берем проекцию CR на Главную ось, обозначим проекцию PR
Соединяем отрезком PR и CR, запоминаем длину отрезка, обозначаем DR
Берем длину отрезка от узла сетки до PR, обозначаем DO
Пишем в матрицу-изображение значение пиксела, равное DR / DO. Очевидно, что это будет число в интервале [0, 1]
Результат алгоритма записываем в файл для дальнейшего препроцессинга.
Каковы преимущества и недостатки этого алгоритма?
Плюсы:
Простота реализации, понятная математика.
Мы фокусируемся на видимой, внешней поверхности тела. Два одинаковых внешне шкафа с разной компоновкой ящиков будут для нас одним и тем же шкафом. Это упрощает задачу распознавания и является разумным предположением.
Алгоритм можно параллелить или включить в пайплайн обучения модели, тогда его можно будет заставить работать на GPU.
Результат будет посчитан для всех тел, даже для тех, у которых есть проблемы с геометрией (например, не хватает треугольников).
Минусы:
-
Требуется препроцессинг:
Тела нужно изначально ориентировать одинаково. В датасете, к примеру, могут быть шкафы, повернутые на 90 градусов. Сделано это было, исходя из предположения, что шкафы более высокие, чем широкие и длинные. Поэтому можно построить Minimal Bounding Box, с помощью которого и ориентировать тело.
Нужно понять, где будет проходить Главная ось для каждого тела. Если тело уже правильно ориентировано, то можно взять (0, 0, 0) в центре нижней грани BoundingBox, а ось построить вертикально вверх.
Если выйти за рамки Proof of Concept, стоит, конечно, учитывать внутренние особенности тел. Сделать это можно с помощью цилиндрических сечений. По сути, сейчас мы взяли только самое внешнее из них. Ничто не мешает прогонять этот же алгоритм для концентрических цилиндров уменьшающегося радиуса, но той же высоты, и получать набор картинок на выходе. Далее можно комбинировать эти картинки в одну, получая некий дескриптор тела, или представлять один семпл в обучении как набор картинок.
Здесь приведен код расчета цилиндрической проекции по описанному выше алгоритму с использованием trimesh для поиска пересечений с телом.
Вот примеры расчета для реальных тел:
Стул

Кровать

Унитаз

Процессинг получившихся данных
Убрать дубликаты или очень похожие картинки. Можно сделать попиксельное сравнение или сравнение с помощью кросс-корреляции.
Выбросить нетипичные тела. Например, те шкафы, которые являются более широкими, чем высокими, для них алгоритм нормализации ориентации не даст нужного результата.
Аугментировать данные: те же шкафы бывают несимметричными. Тогда простое отражение картинки даст нам новый «полезный» шкаф. А вот с унитазами так не выйдет, нужен или более хитрый способ аугментации, или же просто подправить вес семпла при обучении.
Ну когда уже нейросети??
А почему вообще нейросети? Это решение было принято, так как именно сети лучше всего справляются с распознаванием объектов с картинок. Та же устаревшая AlexNet победила в ImageNet, чем произвела революцию в image classification. Во многих соревнованиях сети справляются лучше других алгоритмов. А поскольку моя задача обозначена как «Proof Of Concept», я решил не мудрить и построить сверточную сеть простейшей архитектуры.

Архитектура сети VGG16.
Создадим модель
def create_model():
inp_1 = Input(shape=original_img_size)
conv_1 = Conv2D(96, kernel_size=(5, 5),
activation='relu',
input_shape=(image_rows, image_cols, 1),
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same',
name='conv_1')(inp_1)
batch_norm_1 = BatchNormalization()(conv_1)
max_pool_1 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool1')(batch_norm_1)
conv_2 = Conv2D(256, (5, 5), activation='relu',
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same', name='conv_2')(max_pool_1)
batch_norm_2 = BatchNormalization()(conv_2)
max_pool_2 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool2')(batch_norm_2)
conv_3 = Conv2D(384, (3, 3), activation='relu',
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same', name='conv_3')(max_pool_2)
batch_norm_3 = BatchNormalization()(conv_3)
max_pool_3 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool_3')(batch_norm_3)
rwmp = MaxPooling2D(pool_size=(1, 20), padding='same', name='rwmp')(max_pool_3)
flatten_1 = Flatten(name='flatten1')(rwmp)
dense_1 = Dense(64, activation='relu',
kernel_initializer='uniform',
bias_initializer='uniform',
name='dense_1')(flatten_1)
dropout_1 = Dropout(0.5, name='dropout_1')(dense_1)
dense_2 = Dense(64, activation='relu',
kernel_initializer='uniform',
bias_initializer='uniform',
name='dense_2')(dropout_1)
dropout_2 = Dropout(0.5, name='dropout_2')(dense_2)
softmax = Dense(num_classes, activation='softmax',
kernel_initializer='uniform',
bias_initializer='uniform',
name='output')(dropout_2)
return Model(inp_1, softmax)
model = create_model()
optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=optimizer,
metrics=[keras.metrics.categorical_accuracy, fmeasure, precision, recall])
'''
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64, 160, 1) 0
_________________________________________________________________
conv_1 (Conv2D) (None, 64, 160, 96) 2496
_________________________________________________________________
batch_normalization_1 (Batch (None, 64, 160, 96) 384
_________________________________________________________________
max_pool1 (MaxPooling2D) (None, 32, 80, 96) 0
_________________________________________________________________
conv_2 (Conv2D) (None, 32, 80, 256) 614656
_________________________________________________________________
batch_normalization_2 (Batch (None, 32, 80, 256) 1024
_________________________________________________________________
max_pool2 (MaxPooling2D) (None, 16, 40, 256) 0
_________________________________________________________________
conv_3 (Conv2D) (None, 16, 40, 384) 885120
_________________________________________________________________
batch_normalization_3 (Batch (None, 16, 40, 384) 1536
_________________________________________________________________
max_pool_3 (MaxPooling2D) (None, 8, 20, 384) 0
_________________________________________________________________
rwmp (MaxPooling2D) (None, 8, 1, 384) 0
_________________________________________________________________
flatten1 (Flatten) (None, 3072) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 196672
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 4160
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
output (Dense) (None, 7) 455
=================================================================
Total params: 1,706,503
Trainable params: 1,705,031
Non-trainable params: 1,472
'''Интерес представляет слой RWMP, который по сути является построчным Max Pooling. Если верить DeepPano, это нужно, чтобы сгладить эффекты от ошибок препроцессинга при нормализации ориентации тел. Конкретнее — для компенсации ошибок при повороте тел вокруг Главной оси.
Обучаем модель
Читаем картинки из файлов.
Перемешиваем как следует.
Для кросс-валидации делим в соотношении 70:15:15 train:validation:test.
-
Обнаруживаем, что пространства для аугментации самих тел не так много:
Color augmentation неприменим, так как картинки серые;
Horizontal flipping тоже, потому что его должен компенсировать RWMP;
Vertical flipping — не годится, т.к. предполагает шкаф «вверх ногами»;
ZCA whitening не годится, потому что у нас природа картинок синтетическая, соответственно, значения в каждом пикселе очень важны.
Прочитаем заранее сгенерированные картинки с удаленными дубликатами:
def read_data(directory):
from PIL import Image
def image_and_label(path):
def encode_pattern(string):
for i in range(len(classes)):
if classes[i] in string:
return i
raise ValueError('Unknown mesh category {}'.format(string))
img = img_to_array(load_img(path, grayscale=True))
label = encode_pattern(path)
return img, label
def images_and_labels(image_paths):
images = []
labels = []
for path in image_paths:
img, label = image_and_label(path)
images.append(img)
labels.append(label)
labels = keras.utils.to_categorical(labels, num_classes=len(classes))
return images, labels
wildcard = directory + os.sep + '**' + os.sep + '*.png'
image_paths = glob.glob(wildcard, recursive=True)
images, labels = images_and_labels(image_paths)
return np.array(images), labels
x_train, y_train = read_data(train_path)
x_val, y_val = read_data(val_path)
def unison_shuffled_copies(a, b):
assert len(a) == len(b)
p = np.random.permutation(len(a))
return a[p], b[p]
x_train, y_train = unison_shuffled_copies(x_train, y_train)
x_val, y_val = unison_shuffled_copies(x_val, y_val)
train_datagen = ImageDataGenerator(rescale=1.0/255.0)
val_datagen = ImageDataGenerator(rescale=1.0/255.0)
train_datagen.fit(x_train)
val_datagen.fit(x_val)
train_generator = train_datagen.flow(x_train, y_train, batch_size=batch_size)
val_generator = val_datagen.flow(x_val, y_val, batch_size=batch_size)Перейдем к обучению сети:
checkpointer = callbacks.ModelCheckpoint(model_name + '.h5',
monitor='val_categorical_accuracy',
save_best_only=True,
save_weights_only=False,
mode='max',
period=1)
reduce_lr = callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.5, patience=2,
verbose=1, mode='auto',
epsilon=0.0001,
cooldown=0, min_lr=0)
tensorboard = callbacks.TensorBoard(log_dir='logs', histogram_freq=0, write_graph=True)
%%time
history = model.fit_generator(
train_generator,
steps_per_epoch=train_batches_per_epoch,
epochs=num_epochs,
validation_data=val_generator,
validation_steps=val_batches_per_epoch,
callbacks=[checkpointer, reduce_lr, tensorboard],
workers=1,
use_multiprocessing=False,
shuffle=True)Результаты
Categorical accuracy для train:

Categorical accuracy для validation:
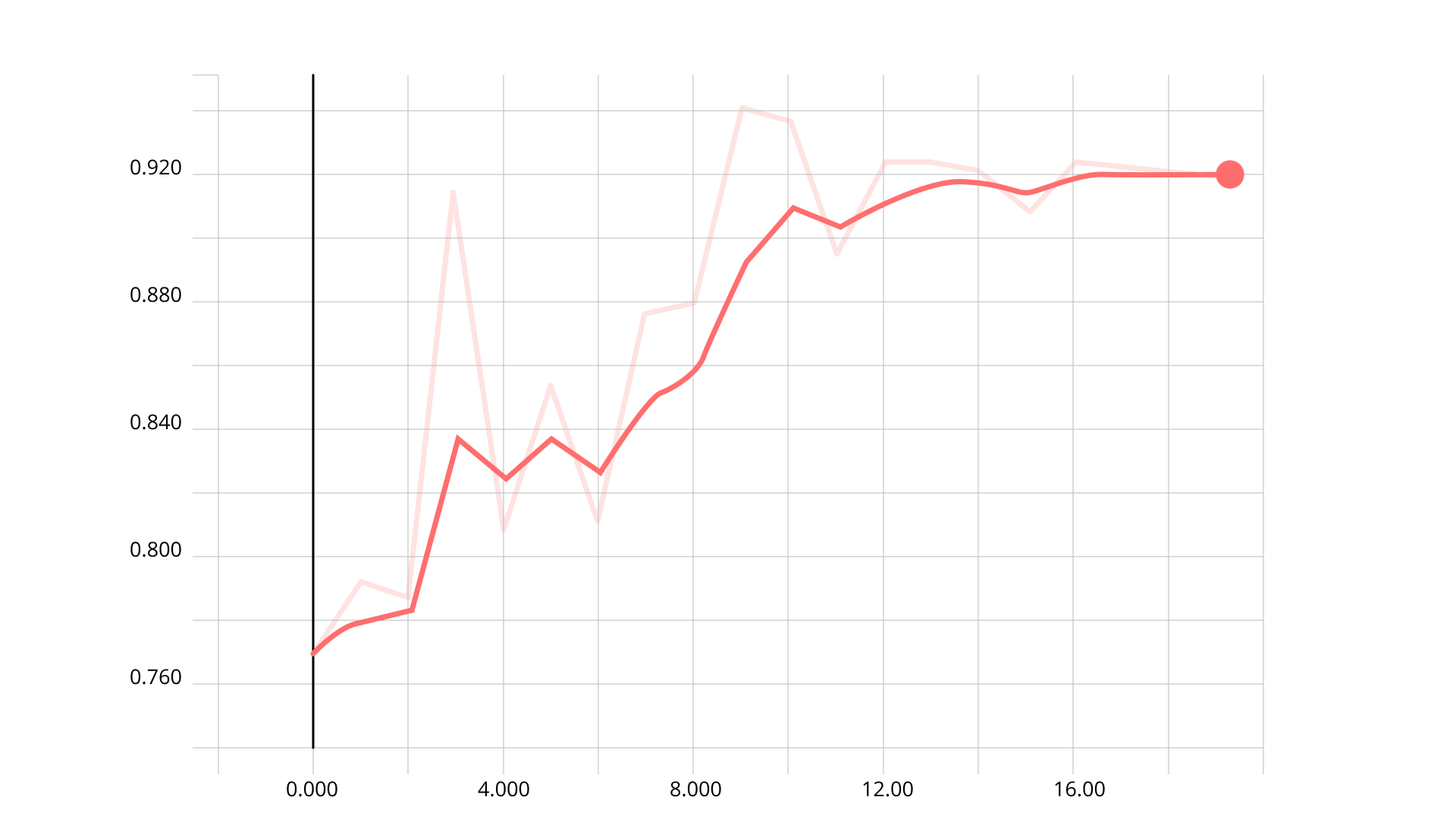
Так как categorical accuracy отличаются менее чем на 5%, заключаем, что нет overfitting.
На тестовом датасете categorical accuracy получилась 89.5%.
Classification report:
from sklearn import metrics
true_labels = np.argmax(test_true_labels, axis=1)
pred_labels = np.argmax(test_pred_labels, axis=1)
print(metrics.accuracy_score(true_labels, pred_labels))
def report(true_labels, pred_labels):
print(metrics.classification_report(true_labels, pred_labels, target_names=classes))
report(true_labels, pred_labels)
'''
0.8948948948948949
precision recall f1-score support
bed 0.92 0.96 0.94 112
chair 0.96 0.99 0.97 90
dresser 0.65 0.95 0.77 80
monitor 0.93 0.98 0.96 100
table 0.94 0.68 0.79 92
sofa 0.96 0.84 0.90 96
toilet 0.98 0.84 0.91 96
avg / total 0.91 0.89 0.90 666
'''Confusion matrix:

В целом результаты выглядят неплохо, за исключением того, что некоторые столы распознаются как комоды. Видимо, что-то с данными. Впрочем, это не отменяет Proof Of Concept.
Немного поиграем с моделью
from scipy import misc
import trimesh
def what_is_this(filepath):
img = img_to_array(load_img(filepath, grayscale=True))
img = img / 255
plt.imshow(img[:, :, 0], cmap='gray')
plt.show()
img = np.expand_dims(img, axis=0)
probabilities = model.predict(img, batch_size=1, verbose=2)
return classes[np.argmax(probabilities)], probabilities
what_is_this(test_path + os.sep + 'table' + os.sep + 'table_0224.png')
# Output
# ('table', array([[1.94e-13, 1.08e-10, 5.86e-12, 5.81e-15, 1.00e+00, 1.27e-31, 5.15e-21]], dtype=float32))Как видно, это стол, и модель уверена в этом:

Выводы
Машинное обучение вполне можно использовать для процессинга трехмерных тел. Это даже может быть не более ресурсоемко на этапе обучения, чем процессинг картинок, потому что этап получения картинки можно отделить от этапа обучения. А можно не отделять, если ресурсов много и хочется параллелизма.
Даже такой простой метод распознавания дает неплохие результаты, если уделить должное внимание процессингу данных.
Прикладная задача может быть решена сохранением полученной обученной модели в файл и использованием его на стороне C++ с помощью tensorflow C++ API. Поддерживать это у большого числа пользователей будет непросто, поэтому лучше поставить сервер-распознаватель, на котором обновлять модель по мере ее обновлений.
Что можно улучшить
Можно было бы добиться конечного решения прикладной задачи. Не пишу об этом здесь, так как к machine learning это уже не имеет прямого отношения.
Добавить больше категорий.
Изобрести аугментацию данных. Например, на GAN или VAE. Кое-что уже получилось.
Учесть контекст тел, например, материалы, размер тел, текстуру. Разумеется, это уже не будет просто sequential neural network.
Можно комбинировать разные подходы. Например, сделать модель, которая работает на вокселях и комбинировать с DeepPano.
Учесть внутреннюю структуру тел, например, полости.
***
Будем рады ответить в комментариях на ваши вопросы по поводу описанного эксперимента и узнать ваше мнение о нем. Также, пожалуйста, поделитесь, если у вас есть собственные сценарии применения сверточной модели нейросети для решения каких-либо прикладных задач. И конечно, подписывайтесь на наш хабр-блог, его мы регулярно наполняем интересным контентом: делимся экспертизой наших сотрудников и переводим статьи зарубежных авторов.
Комментарии (3)

HGordon
30.11.2022 20:05+1А зачем вы руками создавали VGG? Здесь есть образовательный смысл или чем-то реализация из pytorch не подходит?

Tsyshnatiy Автор
30.11.2022 21:32+5В моем случае я много экспериментировал с настройками сети и ее компоновкой, есть даже кастомный слой RWMP. Кроме того, с pytorch был не знаком, использовал keras
Enigmat
Не особо разбираюсь в 3D-моделинге и пр., но пару лет назад увлекался VGG16, прочел с интересом. Благодарю за доступное раскрытие темы