
Всем привет! Меня зовут Олег Негрозов, я бэкенд-разработчик в hh.ru из команды Talantix. В дивном мире GraphQL есть один минус, который одновременно является и плюсом — пользователь ограничен лишь описанной схемой. Он может попросить у сервера все данные, доступные ему, или написать такой сложный запрос, который будет выполняться целую вечность. О том, как защититься от этого и ограничить свои API, я расскажу в сегодняшней статье.

Немного про доменную область
Расскажу немного про Talantix, чтобы было понимание, о чем дальше пойдет речь. Talantix — это система для рекрутеров, в которой они работают с кандидатами.

В коде кандидатов мы называем персонами или persons, так уж исторически сложилось. Персон рекрутер ведет по вакансиям — они называются vacancies. Все вакансии имеют свои этапы — workflowStatuses, и на каждом таком этапе имеются отклики – responses. Response — это объект, который ссылается на персону и имеет некоторые дополнительные полезные свойства, например, сопроводительное письмо.
Разбираемся со сложностью запросов
Вы, как пользователь своего же API, пишете те запросы, которые нужны именно вам, и строите систему, способную их выполнить. Но GraphQL позволяет ходить по графу сущностей вдоль и поперек, как душе угодно. И любой другой клиент API сможет запросить все данные системы, доступные ему, или же написать очень сложный запрос. Но какой запрос является сложным, а какой простым?
Разумеется, все зависит от конкретной ситуации. Например, мы можем обозначить сложным такой запрос, который выполняется дольше условных 5 секунд. Но даже если он выполняется достаточно быстро, он может требовать много оперативной памяти, создавать много тредов или использовать одновременно много соединений к базе данных.
Если такие технические критерии достаточно легко составить, зная свои возможности по железу и требования к быстроте отклика системы, то кажется вполне уместным использовать их для этих самых ограничений. Но тут возникает проблема: чтобы ограничить все запросы дольше пяти секунд, нам необходимо начать их выполнять и замерять время выполнения. К тому моменту, как станет понятно, что запрос сложный, мы уже потратим пять секунд процессорного времени. Все это касается и других технических ограничений: память, треды или базы данных. Нам не очень хочется впустую тратить ресурсы, а следовательно хочется понимать что запрос является сложным еще до его выполнения.
Нам нужен такой механизм разметки запросов, чтобы уже на этапе их парсинга или валидации становилось понятно, какого типа перед нами запрос. Тут вспоминаем, что наша схема является графом, а в запросе мы начинаем от некоторого входного узла, затем идем по ребрам и перечисляем сущности, которые хотим получить. По сути, запрос — это множество путей в графе: от персоны к ее вакансиям, от вакансий к их статусам и так далее. Кроме того, графы бывают взвешенными: когда ребра имеют некоторый вес и можно вычислить длину путей. Похожая идея применима и тут, но вместо ребер мы будем назначать вес узлу, а затем трактовать его как сложность вычисления этого самого узла. Если у запроса вычислить суммарную сложность по некоторым правилам, то ее можно ограничить пределом.
Для ясности рассмотрим пример: есть достаточно объемный на вид запрос, в корне которого находятся кандидаты со своими полями.
{
persons {
items {
id
firstName
lastName
responses {
items {
... on ResponseItem {
unread
workflowStatus {
... on WorkflowStatusItem {
name
vacancy {
... on VacancyItem {
id
title
}
}
}
}
}
}
}
}
}
}От кандидатов мы переходим к их откликам, а отклик, в свою очередь, ссылается на этап некоторой вакансии. Также в этом запросе присутствует синтаксис фрагмента, так как тип этих сущностей — union. В своем видео про ограничение доступа в GraphQL я рассказываю, что такое union и как мы его используем в нашем GraphQL API. А еще есть статья на Хабре. Но сейчас для нас важно то, что эти юнионы присутствуют в нашем запросе и система анализа сложности должна их учитывать.
Сложный ли это запрос? Все зависит от структуры базы данных и от того, какие методы для получения сущностей уже реализованы. Наверняка можно построить такую систему, в которой данный запрос будет простым. Но допустим, что откликами занимается уже разработанный отдельный микросервис, и выдавать отклики в один запрос к нему он эффективно может только для одного кандидата. Так как в корне запроса кандидаты присутствуют во множественном числе, резолверу ничего не остается, как для каждого кандидата отдельным запросом получить его отклики.
А таких кандидатов может быть немало. В нашем случае, например, мы ограничиваем списки размером 50. Соответственно, данный запрос для нас будет сложным, и сложность здесь привносят те самые отклики, а значит они и имеют некоторый вес. Но также стоит понимать, что отклики одного кандидата мы с легкостью можем получить, а значит этот вес начинает играть большую роль только в списках. Это нужно учесть при разработке механизма.
Требования к механизму разметки
Чтобы перейти от идей весов к реализации, обозначим четкие требования. Первым делом нам важно, чтобы все запросы по умолчанию были простыми. Это означает, что количество сущностей и их полей в запросе никак не влияет на его сложность, если специально не указано иного. Такое требование выполнится автоматически, если сложность всех полей по умолчанию будет равна нулю.
Также нам необходимо, чтобы расширение API любыми полями и новыми сущностями не ломало запрос, который работал до этого. Данное требование само по себе важно, потому что наша система, как и наше API, развиваются и обрастают новой функциональностью. Мы не хотим, чтобы на фронте или в приложениях рабочий запрос упал только потому, что мы добавили кандидату поле со знаком зодиака.
Следующее требование заключается в том, что мы хотим помечать узлы, которые имеют существенный вес. Это должно быть не просто перечисление сложных запросов, а независимые друг от друга пометки узлов, которые в совокупности давали бы суммарную сложность запроса. А те самые правила сложения представлялись бы в виде некоторой функции сложности.
Четвертое требование достаточно простое — анализ сложности таких запросов должен происходить до их выполнения, например, на стадии валидации. И пятое требование — немного расплывчатое. Нам хочется, чтобы суммарную сложность запроса можно было прикинуть без метода проб и ошибок, а возможно даже вычислить в уме. Важно не слепо подбирать веса и пределы, чтобы проверять все это на каких-либо тестах, а назначать их осмысленно и получать предсказуемый результат.
Готовые реализации
Разумеется, идея вводить веса и вычислять сложность запросов не нова. И в Java-библиотеках для GraphQL уже имеются некоторые готовые решения. В статье мы рассмотрим всего два. Увы, ни одно из них не удовлетворяло всем нашим требованиям и нуждалось в допиливании. Также сразу хочу отметить, что они используют механизм instrumentations. Это такой интерфейс, который позволяет встроиться в некоторый этап выполнения запросов. Естественно, оба этих решения встраивались в этап парсинга и валидации запроса до его непосредственного выполнения.
Первое решение — это MaxQueryComplexityInstrumentation из базовой библиотеки graphql-java. Одним из плюсов данного инструментария является то, что он находится в базовой библиотеке, а значит, если вы настроили его под себя и неожиданно решили переехать со SPQR на библиотеку от Netflix, все ваши наработки и разметки весов останутся вместе с вами. Так же он очень прост - легко допилить его под какой-нибудь сложный корнеркейс и вашу логику подсчета сложности.
Но из его простоты вытекают и его минусы: инструмент предоставляет только обход узлов графа, а логику обработки этих узлов и вычисление сложности запроса вам придется писать самому. Здесь нет готового механизма разметки весов, поэтому и тут придется разработать что-то свое: например, аннотации на поля или нечто иное. Бонусом — специальные поля, вроде мета-информации, фрагментов и юнионов, вам придется разбирать самостоятельно. В целом, MaxQueryComplexityInstrumentation предоставляет минимальную функциональность, которую можно было бы допилить под наши требования, но мы решили посмотреть и на другие решения.
Так как мы используем библиотеку SPQR в своем проекте, было бы странно не посмотреть, есть ли у нее что-то готовое, и таким инструментом оказался ComplexityAnalysisInstrumentation. В этом инструментарии имеется уже готовая система разметки весов, аннотация @GraphQLComplexity, которой можно помечать как поля классов, так и резолверы. Данный instrumentation умеет учитывать фрагменты, интерфейсы и мета-поля, а также обладает готовой функцией сложности из коробки.
Но последнее можно считать и минусом, поскольку готовая функция из коробки использует движок JavaScript для парсинга целых выражений внутри аннотации @GraphQLComplexity. Авторы SPQR пошли по пути универсальности, но нам это показалось оверхедом. Более того, данная функция считает сложность всех полей по умолчанию равной единице, что уже противоречит нашим требованиям. Также к минусам можно отнести довольно критичные баги, например, обход графа пропускает узлы с типом юнион, а мы его активно используем. Имеется также баг, из-за которого не учитываются фрагменты в корне запроса. Можно было бы завести issue на разработчика библиотеки SPQR, но на момент внедрения анализатора SPQR не поддерживался уже больше года. Однако недавно появился апдейт, автор сообщил, что будет продолжать работу над библиотекой, поэтому есть надежда, что инструмент все же будет развиваться.
Что в итоге?
Несмотря на все свои минусы, ComplexityAnalysisInstrumentation уже близок к тому, что мы хотим, поэтому мы поступили следующим образом: честно скопипастили данный анализатор, пофиксили два критичных бага и написали свою функцию сложности, которая не использует движок JavaScript. Давайте разберемся, как она работает:
public int complexityFunction(ResolvedField node, int childScore) {
Resolver resolver = node.getResolver();
if (resolver != null && Utils.isNotEmpty(resolver.getComplexityExpression())) {
int resolverComplexity = Integer.parseInt(resolver.getComplexityExpression());
if (Collection.class.isAssignableFrom(resolver.getRawReturnType())) {
return resolverComplexity * (childScore != 0 ? childScore : 1);
} else {
return resolverComplexity + childScore;
}
} else {
return childScore;
}
}Если узел не имеет веса, то мы возвращаем вес его детей. Тут стоит напомнить, что сложность всех узлов по умолчанию равна нулю, а следовательно, двигаясь снизу вверх по запросу, функция сложности всегда будет возвращать ноль, пока мы не встретим помеченный узел. Если же узел имеет вес, нас интересуют две ситуации: если узел является коллекцией, то его вес умножается на вес детей, а если вес детей равен нулю, мы заменим его на единицу. Если же узел не является коллекцией, то его вес прибавляется к весу детей и такая функция, рекурсивно, начиная с листов, вызывается для каждого узла запроса.
Стоит пояснить идею умножения веса узла в случае коллекции. Данное условие является по сути договоренностью, вес коллекции мы трактуем как предельный размер этой самой коллекции. Таким образом здесь работает кратное увеличение сложности его помеченных детей, как это было в примере с откликами и кандидатами.
Рассмотрим пример такой разметки в нашем коде. Выше мы упоминали, что аннотацией можно помечать поля класса, поэтому давайте пометим поле items, как у персон, так и у их откликов.
public class Persons {
private PageInfo pageInfo;
private Counters counters;
@GraphQLComplexity(value = 50)
private List<PersonItem> items;
...
}
public class PersonResponses {
private PageInfo pageInfo;
@GraphQLComplexity(value = 50)
private List<Response> items;
...
}Вес 50 выбран исходя из лимита пагинации этих самых объектов. Аналогично аннотацией можно пометить и резолверы. В данном случае — резолвер объекта откликов, который уже не является коллекцией. Вес, в качестве примера, выберем аналогичный — 50.
@GraphQLComplexity(value = 50)
public CompletableFuture<PersonResponses> getPersonResponses(
@GraphQLContext PersonItem personItem,
@GraphQLEnvironment ResolutionEnvironment env) {
...
}Посмотрим еще раз на сам запрос и разберем как будет вычисляться суммарная сложность для него.
{
persons {
items { # вес 50, коллекция
id
firstName
lastName
responses { # вес 50
items { # вес 50, коллекция
... on ResponseItem {
unread
workflowStatus {
... on WorkflowStatusItem {
name
vacancy {
... on VacancyItem {
id
title
}
}
}
}
}
}
}
}
}
}Здесь три поля имеют сложность 50. Двигаясь снизу вверх по дереву запроса получаем сложность 50 для поля items, так как вес его детей равен нулю. Далее, к его сложности прибавляем сложность поля responses, поскольку responses не является коллекцией. А затем суммарную сложность 100 мы умножаем на вес поля items в узле персон, так как поле items имеет тип List.
В итоге суммарная сложность запроса составит 5000. Но встает еще один вопрос: как нам назначать предел? В нашем случае предел назначается эмпирически: так, чтобы простые и легкие запросы в него укладывались, а сложные — нет. Это не совсем то чего хотелось, но пока что при небольшом количестве сущностей это и так работает. При сильном усложнении системы тут возможны различные доработки, например - указание кастомных лимитов для отдельных "корневых" узлов в запросах.
Попробуем запустить наш сложный запрос в системе GraphQL и увидим ошибку в поле errors с указанием сложности запроса, максимального предела и текстовым описанием.
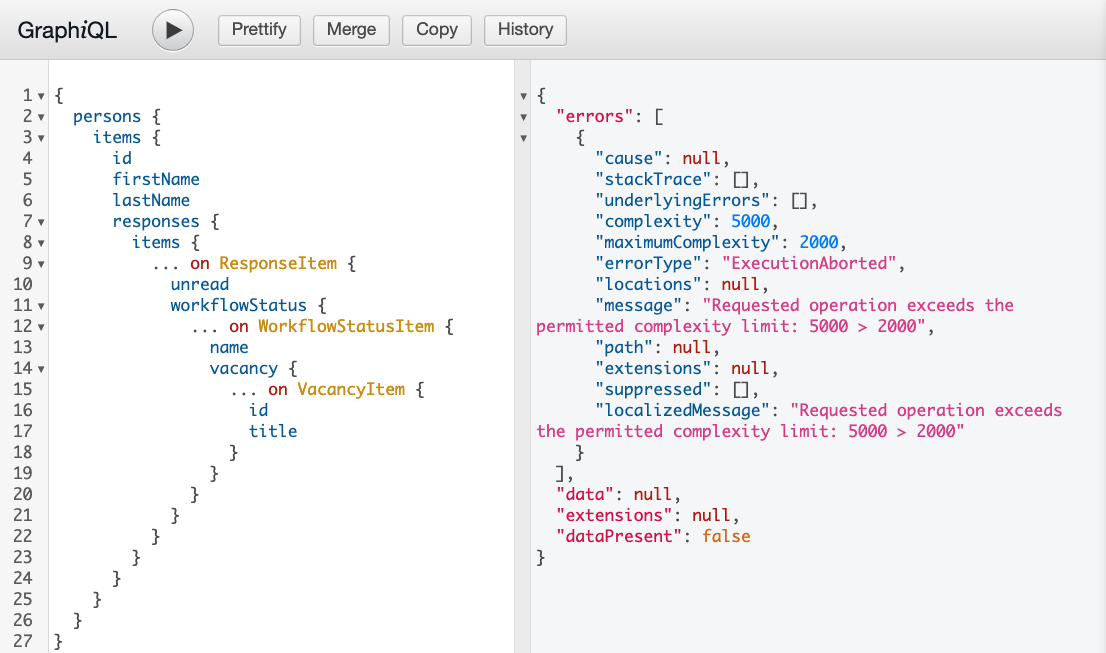
Как же запросить отклики кандидатов? Напомню, почему мы решили, что данный запрос является сложным: откликами занимается отдельный микросервис и так уж вышло, что эффективно отдавать их он умеет только для одного кандидата за раз. Попробуем запросить отклики для одной персоны:

Вуаля! Сервер отдал нам данные кандидата и список его откликов. Узел person мы никак не помечали и поэтому никакого умножения весов в вычислении сложности не было.
Важно еще раз отметить, что мы могли бы разработать систему, в которой запрос откликов и для N кандидатов был бы легким. Основная идея заключается в том, что при наличии уже реализованных методов и текущего устройства базы данных, запрос выполняется долго, а переделывать все, учитывая, что такой запрос лично нам (на фронте или в приложении) не нужен, мы не хотим.
У разработанного механизма имеются и минусы. Подбор весов и лимитов эмпирический, хоть и не требует подсчета количества полей в запросе, как это было бы, если бы их сложность по умолчанию равнялась единице. Также можно назвать минусом относительную сложность механизма — без документации или описания с первого раза сложно понять, где и как менять веса, и как они повлияют на итоговую сложность запроса.
Выводы
Если ваша GraphQL API уже достаточно сложная, с различными сущностями и связями между ними, вы наверняка захотите немного ограничить вашего пользователя, чтобы он не сломал вам систему.
Механизм instrumentation позволяет встроиться в этап валидации запросов и произвести анализ его сложности до его выполнения.
Тот анализатор, который получился у нас, удовлетворяет нашим минимальным требованиям и наверняка некоторое время не потребует доработок.
Видеоверсию этой статьи можно посмотреть на нашем канале по ссылке.
NeverIn
Вместо того, чтобы хорошо знать только sql приходится всякие псевдо технологии изучать типа JPA хибирнейт графQL