
")
Предлагаем вашему вниманию разбор конференции KDD 2022 от ML команды Одноклассников. Такие разборы стали традицией, и в этот раз нам опять помогали коллеги из ВК, за что им большое спасибо. Мы подготовили краткое изложение восьми статей из области рекомендательных систем. Как нам кажется, эти статьи отражают текущие тенденции в науке о рекомендациях. Все меньше предлагается новых архитектур, и больше внимания уделяется корректной постановке задачи: как учесть долгосрочные эффекты рекомендера, скорректировать смещения и надежно завести это все в продакшен. Наши изложения не претендуют на полноту, но, прочитав их, вы поймете, о чем идет речь в статьях, и при желании изучите их подробнее. Надеемся, что вам понравится!
В этом выпуске:
Настраиваем рекомендательную систему на долгосрочную цель >>
Трансформерные рекомендеры в продакшене >>
Чиним positional bias рекомендера >>
На лету выбираем лучший источник рекомендаций >>
Чиним popularity bias рекомендера >>
Чиним duration bias рекомендера видео >>
Настраиваем рекомендательную систему с помощью reinforcement learning >>
Добавляем разнообразия в рекомендации видео >>
Surrogate for Long-Term User Experience in Recommender Systems
Автор разбора @anokhinn
Авторы решают задачу настройки рекомендательной системы на долгосрочную цель. Основная идея – приблизить долгосрочную метрику с помощью краткосрочных метрик и встроить полученное приближение в существующий рекомендательный сервис. Детали рекомендательного алгоритма играют второстепенную роль: предложенный подход работает для любого рекомендера.
Детали
Исторически рекомендательные системы настраиваются на краткосрочные метрики, например клики или лайки. Несмотря на удобство краткосрочных метрик – их легко считать и оптимизировать – у них есть важный недостаток: они плохо отражают “счастье” пользователя. Долгосрочные метрики, такие как доля возвратов на платформу, наоборот позволяют измерить качество пользовательского опыта в целом. Но долгосрочные метрики сложно оптимизировать:
Долго ждать, пока накопятся данные для подсчета долгосрочной метрики (если мы хотим измерить возвраты пользователей в течение года, то данные нужно ждать целый год).
Изменение долгосрочной метрики невозможно ассоциировать с конкретной рекомендацией (как понять, в какой момент мы показали настолько неудачную рекомендацию, что пользователь решил уйти с платформы).
Чтобы справиться с этими проблемами, авторы используют понятный подход: найдем краткосрочные метрики, которые хорошо приближают долгосрочные и настроим на них рекомендер. Улучшение таких краткосрочных метрик приведет к улучшению долгосрочных.
Выбор краткосрочных метрик
Долгосрочная метрика построена на частоте заходов пользователей в видео-сервис. Поведение пользователей бывает двух типов: низкочастотное (L: заходит редко) и высокочастотное (H: заходит часто). Задача рекомендера – побудить низкочастотных пользователей стать высокочастотными на горизонте 20 недель. Нужно выбрать краткосрочные метрики, оптимизируя которые, рекомендер успешно справится со своей задачей.
Авторы сравнивают пользователей, которые начинали низкочастотными, но постепенно стали высокочастотными (L-H) с пользователями, кто начинал и остался низкочастотными (L-L). Утверждается, что краткосрочные метрики, по которым можно различить эти типы пользователей, будут хорошим приближением для долгосрочной цели рекомендера. В качестве краткосрочных метрик предлагаются метрики разнообразия, повторные просмотры видео, долгие просмотры видео, частотные тематики видео и интервалы времени между заходами на разные страницы сервиса. Отбор делается с помощью random forest, который предсказывает тип пользователя (L-L vs L-H) по краткосрочным метрикам, рассчитанным за первый месяц. Победили две метрики:
Dentropy – энтропия распределения по тематикам видео, которые посмотрел пользователь.
Trevisit – среднее время между заходами на главную страницу сервиса.
Следующий шаг – учесть эти метрики при обучении рекомендера и измерить, улучшит ли это долгосрочную частоту заходов пользователя.
Использование в рекомендере
В статье задача рекомендаций поставлена в терминах reinforcement learning. Рекомендер обучается с помощью алгоритма REINFORCE. Чтобы учесть выбранные метрики при обучении модели, нужно встроить их в reward.
Энтропия встраивается так:
Интуитивно, reward увеличивается, если просмотренное на шаге t видео увеличило разнообразие по тематикам в истории просмотров пользователя. И наоборот: если разнообразие уменьшилось, то на reward накладывается уменьшающий множитель. Если видео на шаге t не просмотрено, то reward нулевой, так как R0(st, at)=0.
Среднее время между заходами учитывается похожим образом:
Если на шаге t среднее время между заходами меньше заданного порога, reward увеличивается на c.
Обе модификации reward показали долгосрочный рост метрик рекомендера в A/B экспериментах.
Анализ
Идея, изложенная в статье, не новая: приближение долгосрочных метрик краткосрочными для обучения моделей известно давно. Интересно, что авторы довели эту идею до реализации на боевом рекомендере и показали долгосрочный рост. Несмотря на то, что метод можно повторить почти для любого рекомендера, не совсем понятно, будет ли он эффективен для классической постановки, или применение reinforcement learning имеет ключевое значение для успеха.
NxtPost: User To Post Recommendations In Facebook Groups
Автор разбора @boloz
В статье представлена архитектура системы рекомендаций групповых постов в фейсбуке. Эта архитектура работает на базе трансформеров и решает следующие проблемы: огромное количество постов, актуальность постов и различные виды фидбека с разных устройств. В качестве результатов авторы статьи говорят о 49% росте оффлайн метрики Batch Hits@K и о 0.6% росте количества групп, с которыми взаимодействуют пользователи.
Детали
NxtPost – это two-tower трансформер, который использует XLM-R энкодер для получения эмбеддингов из текста, предобученные модели для извлечения эмбеддингов из картинок и видео. При этом эмбеддинги картинок комбинируются при помощи Deep Sets Fusion. К полученным эмбеддингам добавляются добавляется метаданные, например, страна пользователя, публикующего пост и язык поста. Также модель учитывает кратковременные и долговременные интересы пользователя.
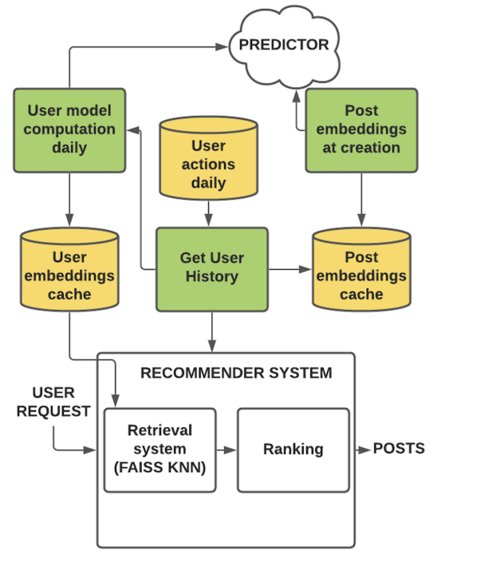
Авторы приводят примерную архитектуру их рекомендательной системы. Кратко можно сказать следующее:
Создание (изменение) поста запускает асинхронный расчёт (перерасчёт) его эмбеддинга. Эмбеддинг поста хранится в распределенной файловой системе и кэше.
Эмбеддинги пользователей пересчитываются ежедневно, для пользователей у которых есть новые взаимодействия с постами. Хранятся эмбеддинги пользователей в key-value distributed memory lookup store.
Анализ
Статья сосредоточена на применении трансформерной архитектуры в рекомендациях. Как утверждают авторы, с помощью предложенной архитектуры им удалось побить предыдущий бейзлайн Wide & Deep Learning for Recommender Systems. Помимо оффлайн метрик авторы приводят результаты A/B экспериментов, в которых они зафиксировали прирост вовлеченности пользователей на 0.6%.
Scalar is not Enough: Vectorization-based unbiased Learning to Rank
Автор разбора @Anvar5710
Авторы решают проблему несмещенного обучения ранжированию рекомендательной системы. Расширяется понятие examination hypothesis (EH гипотезы) и на основе нее строится несмещенная модель.
Детали
EH гипотеза – разложение вероятности клика на две скалярные функции: функция ранжирования (релевантность айтема r) и функция смещения (вероятность, что пользователь увидит айтем). Авторы предлагают рассмотреть векторный вариант этой гипотезы, так как на практике взаимодействия между функциями ранжирования и факторами смещения сложны, и скалярные функции не могут описать все возможные взаимодействия.
Однако векторная EH гипотеза на выходе дает вектор, что неудобно для ранжирования документов. Авторы вводят понятие базового вектора, на который проецируется результат разложения, чтобы получить скаляр. По этому скаляру сортируются документы в списке релевантности. Авторы берут базовый вектор как самый вероятный фактор смещения среди n текущих векторов.
Несмещенная модель ранжирования основывается на векторной EH гипотезе. Признаки делятся на два типа: признаки ранжирования x, от которых зависит релевантность r, и признаки предвзятости t, от которых зависит вектор смещения o. Итоговая вероятность клика зависит как от признаков ранжирования x (через релевантность), так и от признаков предвзятости t (через смещение).
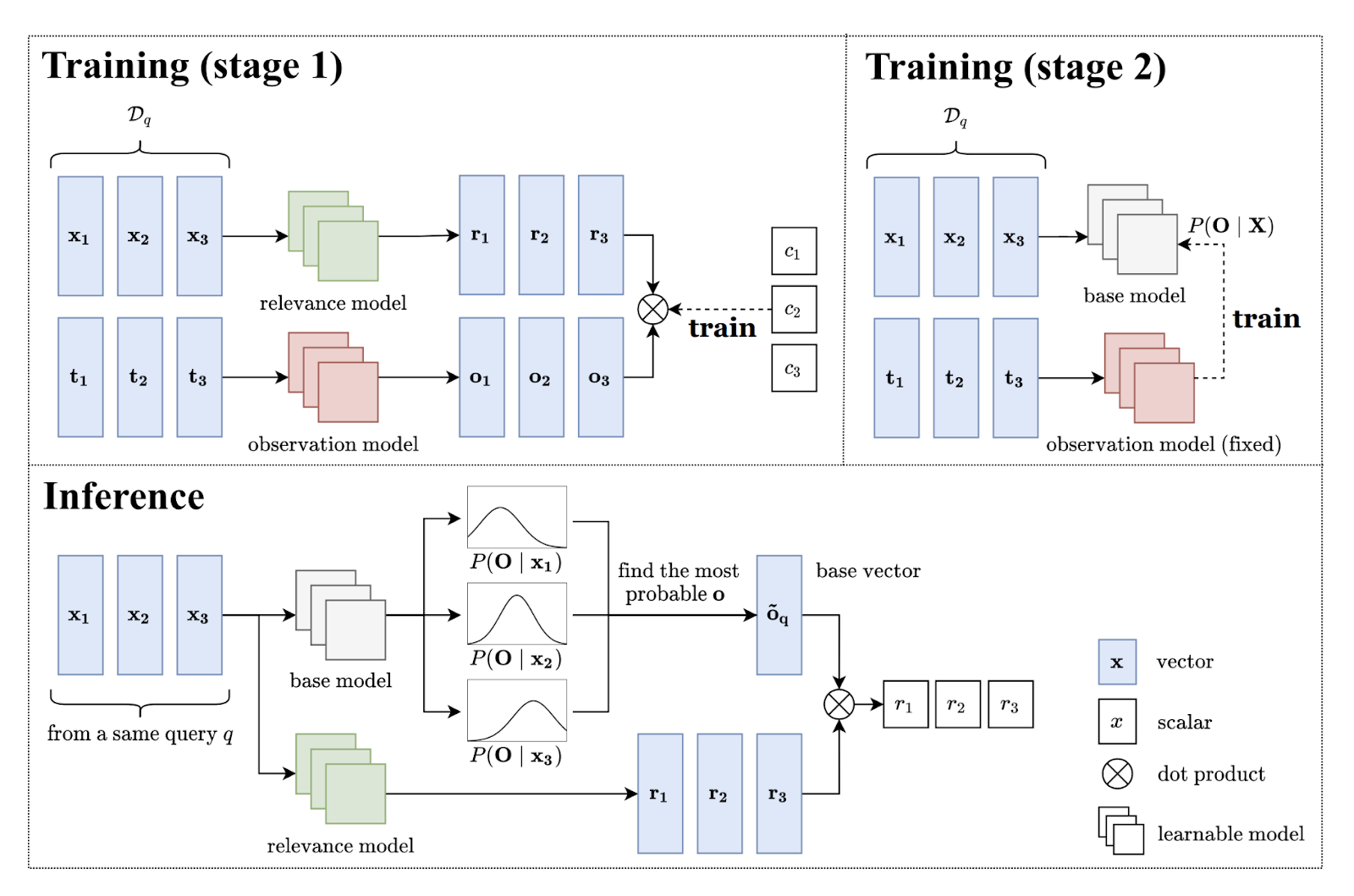
Обучение модели происходит в две стадии.
Первая стадия: обучение relevance и observation model. Relevance model – модель ранжирования документов, учит предсказывать релевантность item-a, обучается на ранжирующих признаках x. Observation model – модель смещения, учится предсказывать вероятность, что пользователь увидит item. Она учится на признаках предвзятости t. Итого, первая стадия – это выполнение EH гипотезы.
Вторая стадия: векторная EH гипотеза дает вектор, а нам нужен скаляр на выходе для сортировки документов по релевантности. Для решения этой проблемы нужно обучить base model, которая будет выдавать базовый вектор. Обучение base model происходит на основе векторов из observation model o, так как базовый вектор берут как самый вероятный фактор смещения среди предложенных observation векторов.
Inference. Основная цель – отранжировать документы. У нас есть модель, которая дает вектора релеватности (relevance model). Однако это вектора, а нам нужны скаляры для сортировки, поэтому мы проецируем полученные вектора релевантности на базовый вектор, полученный из base model для данных векторов. В итоге, у нас скаляры ri, по которым мы сортируем документы и выдаем пользователю.
Анализ
Статья показалась интересной, хотя идея не новая – это развитие EH гипотезы. Реализовать такой подход вполне возможно. Однако предложенная модель не имеет такого большого прироста по метрикам, даже проигрывает некоторым рассмотренным в статье бейзлайнам.
Device-cloud Collaborative Recommendation via Meta Controller
Автор разбора @rds29
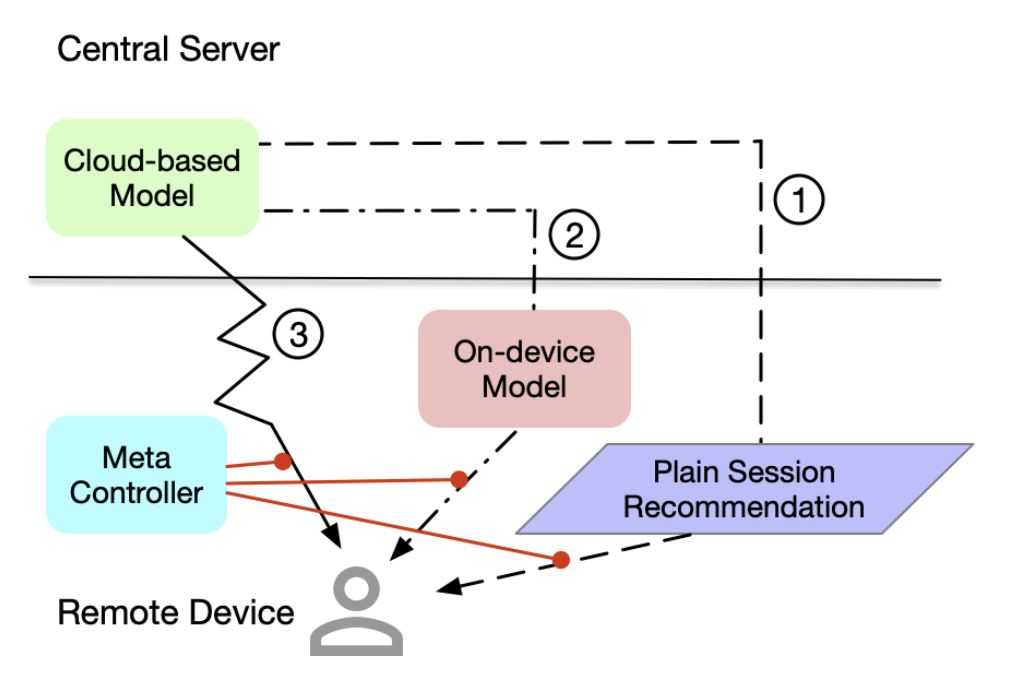
При взаимодействии с рекомендательной системой через мобильное приложение пользователь может получать рекомендации тремя основными способами:
заранее подготовленные оффлайн рекомендации,
рекомендации, которые были дополнительно переранжированы на мобильном устройстве с учетом последних действий пользователя,
рекомендации, которые постоянно переранжируются удаленным сервисом.
Авторы статьи предлагают реализацию “мета контроллера”, призванного автоматизировать переключение между этими 3 подходами с помощью машинного обучения для поиска компромисса между качеством рекомендаций и стоимостью их получения. Основная проблема, возникающая при решении данной задачи – это подготовка датасета для обучения. Авторы предлагают использовать методы причинно-следственного анализа (causal inference): создание counterfactual датасета. Такой метод генерации предполагает, что один из трех подходов, например, оффлайн генерация, берется за базовый, а для остальных двух при помощи CATE и T-Learners рассчитывается размер эффекта относительно базового подхода.
Предлагаемый алгоритм:
подготовить датасеты отдельно для каждого из трех подходов;
обучить модели на этих датасетах предсказывать вероятность того, что пользователю понравятся рекомендации;
рассчитать CATE для каждого сэмпла из всех трех датасетов;
на основании CATE выбрать для каждого сэмпла подход, дающий наибольший положительный эффект;
получаем объединенный датасет, в котором каждой записи соответствует подход, которым стоит воспользоваться для получения наилучшей рекомендации;
обучаем классификатор и дополнительно штрафуем модель за выбор третьего подхода, т.к. считаем его самым вычислительно дорогим;
получаем модель, которая выполняет роль мета контроллера.
Авторы проверили свой подход на трех датасетах: Amazon, MovieLens и Alipay. В каждом случае им удалось превзойти качество рекомендаций моделей без мета контроллера, но улучшение NDCG@5, AUC и HitRate@1 во всех случаях было всего около 1%.
Анализ
Авторы статьи решили интересную инженерную задачу, но улучшение полученных офлайн метрик выглядит совсем незначительным. Поэтому применимость данного подхода на практике остается под вопросом.
Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System
Автор разбора @AlexeyShik
Многие модели в целях минимизации loss’а отдают предпочтение популярным item’ам, а не тем, которые лучше всего подходят конкретному пользователю. Такой вид смещений в данных называется “Popularity bias”. Авторы статьи разработали фреймворк, позволяющий снизить частоту популярных item’ов за счет большего влияния user-item фичей на итоговый score.
Детали
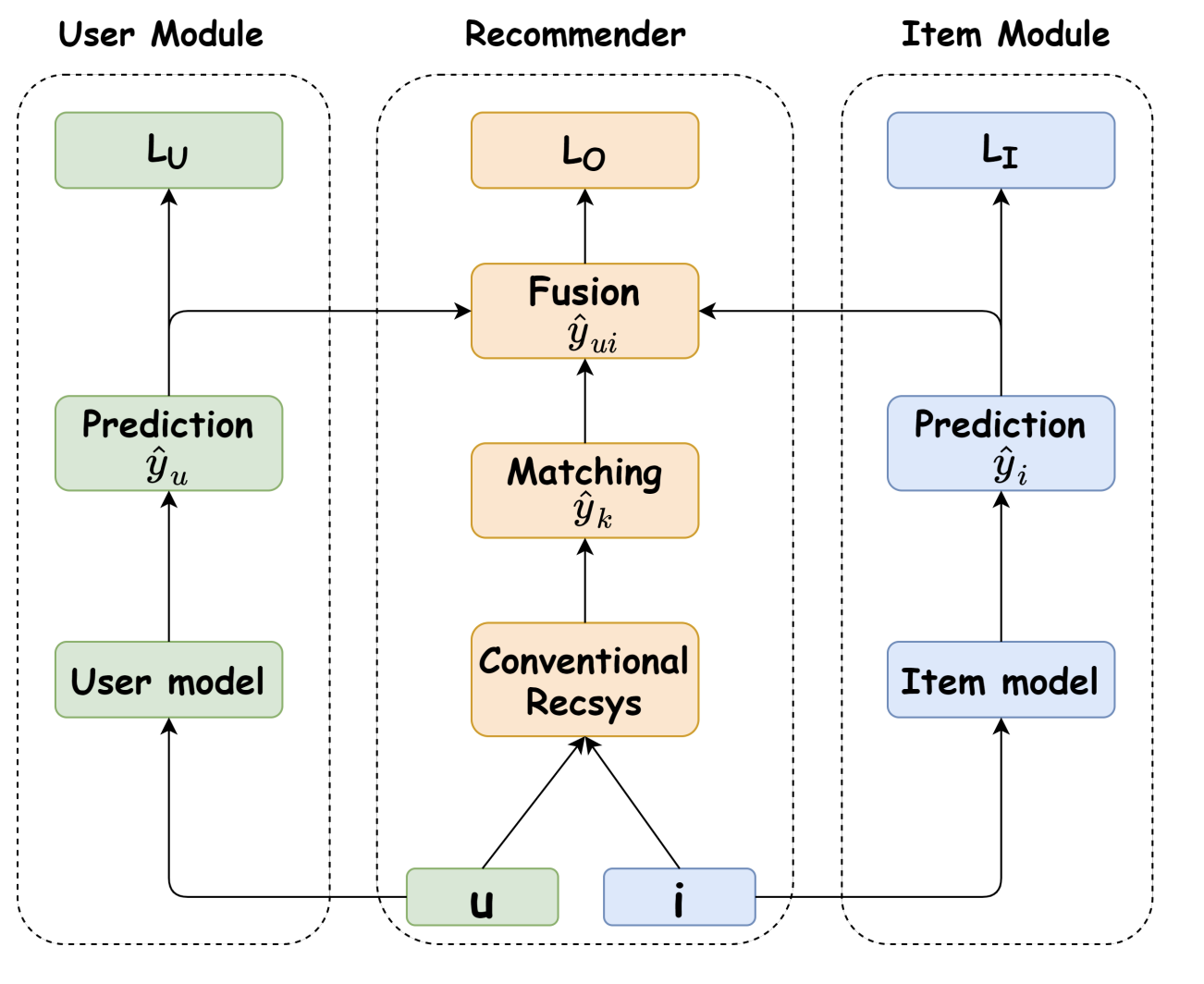
Авторы предлагают рассмотреть два мира. В мире (a) user-item признаки K зависят от признаков пользователя U и признаков item’а I, а итоговое предсказание Y зависит от всех трех категорий признаков. Таким образом учитывается и персонализация, и bias’ы пользователя и item’а.
В мире (b) связь между признаками пользователя U, признаками item’а I и user-item признаками K разрывается: на предсказание влияют только признаки пользователя U и item’а I. В этом мире нет персонализации, потому что для обучения user-item признаков вместо признаков пользователя и item-а используются их средние значения u* и i*.
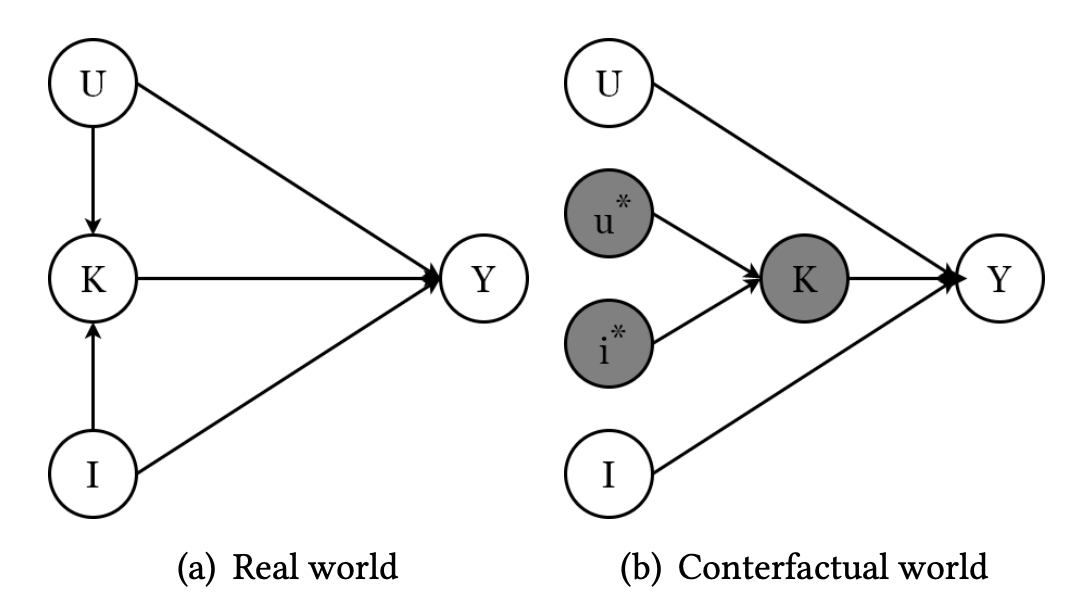
Используя соображения causal inference, авторы определяют итоговый score модели как разность предсказаний в мире (a) и в мире (b) с гипер-параметром ‘c’.
В формуле нижний индекс соответствует вершине графа, а домик означает, что score получается за счет обучения модели. Например, yk – это предсказание рекоммендера (на рисунке ниже, Conventional Recsys), отражающее, на сколько пользователю u подходит item i.
Реализация
Предложенный авторами подход использует многозадачное обучение. Обучаются три компонента:
В User module используется модель, обозначенная User model, для обучения score yu на основании только признаков пользователя. Оптимизируется лосс LU.
В Item module используется модель, обозначенная Item model, для обучения scorer yi на основании только признаков item’а. Оптимизируется лосс LI.
В Recommender части используется модель, обозначенная Conventional Recsys, для обучения score yk на основании признаков и пользователя, и item’a. Полученный yk в схеме называется Matching и обозначает user-item соответствие. После чего на основании score’ов yu, yi, yk по формуле выше определяется score yu,i (на схеме модели соответствующий компонент называется Fusion). Оптимизируется лосс LO.
Если проводить аналогию с мирами из прошлого абзаца, то в мире (a) обучаются yu, yi, yk, а в мире (b) обучаются только yu, yi. Затем по формуле вычисляется причинно-следственный эффект. Причем в левую часть формулы подставляются score из мира (a), а в правую часть - из мира (b).
В качестве лоссов LO, LI, LU используется binary cross-entropy loss. Итоговый лосс L определяется как
Эксперимент
Важная особенность проведенного авторами эксперимента заключается в том, что user-item взаимодействия в тестовой и валидационной выборке распределены равномерно по item’ам. Таким образом, в тестовой и валидационной выборках нет явно популярных item’ов и эксперимент проверяет именно устойчивость построенной модели к popularity bias.
В общем случае в качестве модели user-item признаков (Conventional Recsys на схеме) может быть использована произвольная user-item модель. В эксперименте авторы используют Matrix Factorization и LightGCN для сравнения данного метода избавления от popularity bias с аналогами. В обоих случаях данный подход оказался лучше предыдущих по представленным в статье метрикам, в частности, лучше текущего SOTA (DICE_MF, DICE_LightGCN).
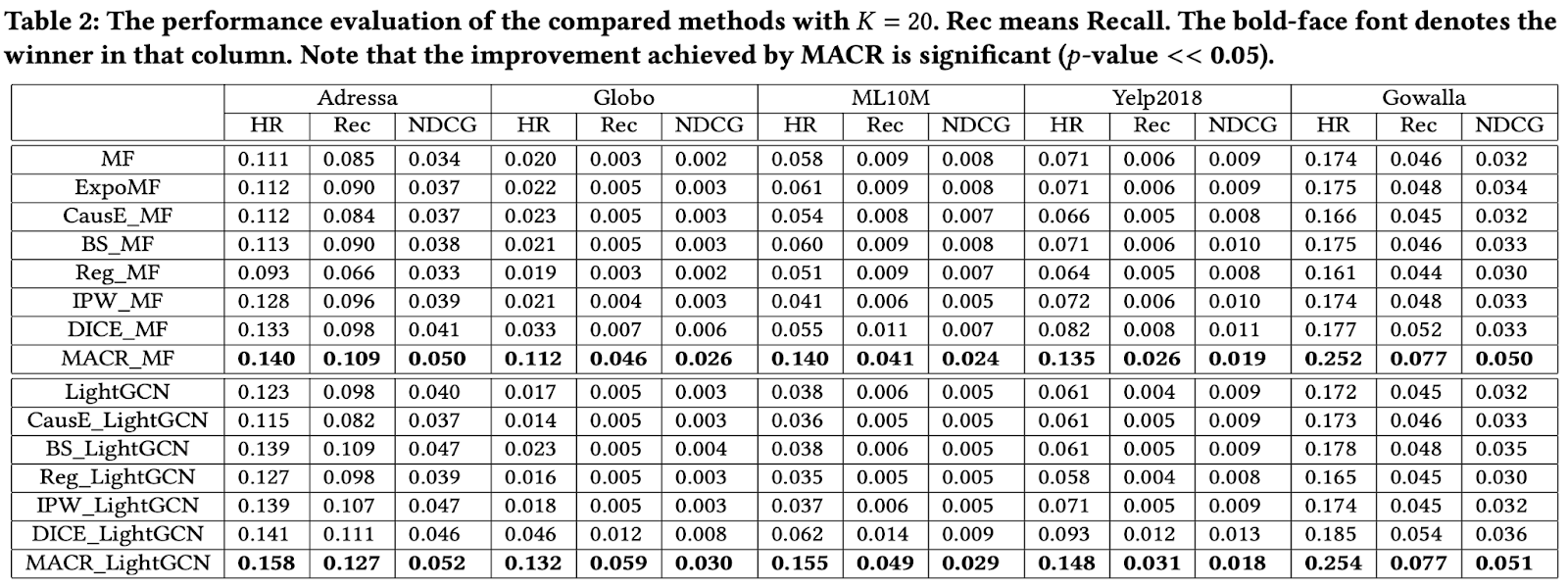
Отмечу, что в статье не приводится результатов эксперимента, если тренировочная и валидационная выборка не распределены равномерно по item’ам. Интересно, как изменятся результаты в таком случае.
Анализ
Подход очень простой, красивый, эффективный и не зависит от архитектуры user-item модели. Однако для его применения в продакшене придется аккуратно выбирать гиперпараметр c, чтобы и получить снижение popularity bias, и не просадить продуктовые метрики.
Deconfounding Duration Bias in Watch-time Prediction for Video
Автор разбора @submaps
Предсказание времени просмотра видео – ключевая задача для вовлечения пользователей в видеосервис. Однако предсказанное время просмотра не всегда зависит только от степени релевантности видео для пользователя. Иногда оно может быть ложно скоррелировано с длительностью видео. Такой эффект возникает, потому что часто рекомендательная система видеосервиса стремится увеличить как таргет проведенное пользователем время (time spend) и предлагает видео с большей длительностью, а не только большей релевантности пользователю. На рисунке показано чем больше длительность видео, тем больший разброс в значениях watch-time.
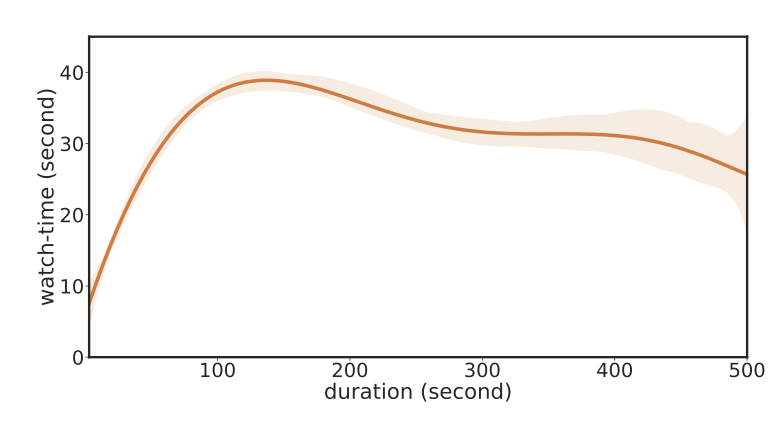
Из-за этой ложной корреляции модели ранжирования склонны отдавать предпочтения более длительным видео. Для решения этой проблемы авторы предлагают свой подход Duration-Deconfounded Quantile-based (D2Q). Идея – создать модель, и управлять её инференсом через causual графовую модель. Благодаря этому, в графе причинно-следственных связей явным образом убирается ложное влияние. Также в работе используется эмпирическая оценка квантиля, в который попадает видео по длительности.
Авторы перечисляют существующие методы борьбы со смещением модели:
Causal intervention.
Данная работа относится к третьей категории casual intervention. С помощью каузального вмешательства авторы устраняют нежелательное влияние продолжительности на видео, при этом сохраняя желаемое влияние продолжительности на время просмотра.
В статье предлагается представить зависимость параметров видео сервиса в виде causal графа и далее исключить влияние нежелательного смещения, убрав дугу между вершинами D и V. Это меняет формулу условной вероятности зависимости других узлов и соответственно убирает влияние на распределения таргета – времени просмотра. Такой подход называется backdoor adjustment.
 моделируется влияние продолжительности видео как на видео, так и на предсказание времени просмотра. На рис. (b) используется бэкдор-корректировка для устранения связи с длительностью и устранения ее влияния на видео.")
Причинно-следственный граф на рисунке показывает, что продолжительность является искажающим фактором, влияющим на время просмотра двумя путями: ???? → ???? и ???? → ???? → ????. Первый путь предполагает, что продолжительность имеет прямую причинно-следственную связь со временем просмотра. Модели времени просмотра выучивают эту связь, поскольку пользователи тратят больше времени на просмотр длинных видео, чем коротких. Второй путь (b) подразумевает, что влияние длительности видео нежелательно и распределение видео смещено в сторону длинных видео (есть дуга зависимости); и если их не устранить, прогнозы столкнутся с риском усиления смещения из-за петли обратной связи рекомендательных систем.
Влияние длительности убирается при удалении ребра ???? → ????, как показано на графе причинно-следственной связи ????1 на рис. 2(b). Далее, мы формулируем модель прогнозирования времени просмотра как E[???? |????????(????,????)] и получаем
Где ???? — пользователь, ???? — видео, ???? — продолжительность, ???? — время просмотра, do() - do-calculus, оператор корректировки, который означает удаление дуг, идущих в заданные вершины и соответственно влияния на них.
Уравнение описывает схему casual intervention: можно оценить P(????) и E[????|????,????,????] по отдельности, а затем объединить их вместе, чтобы построить окончательную оценку. В этой статье предлагается разбить распределение продолжительности P(????) на непересекающиеся группы и обучить модель прогнозирования времени просмотра E[????|????,????,????] для каждой группы.
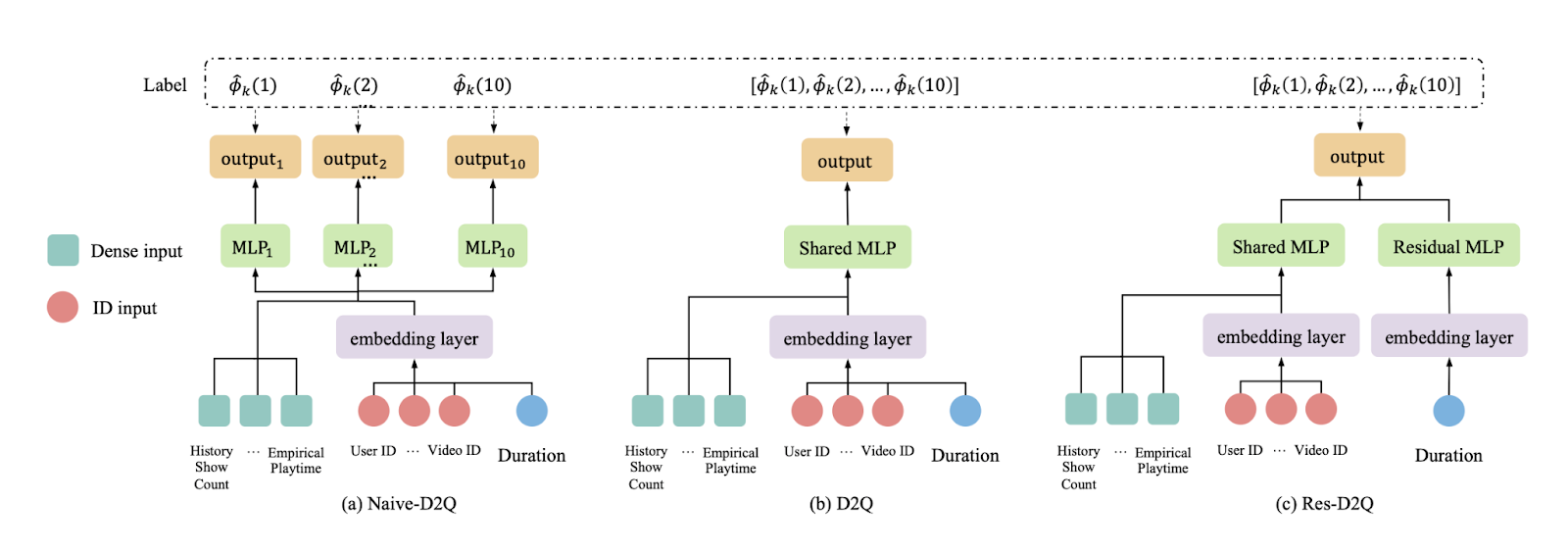
На рисунке показаны различные модели для оценки времени просмотра по группе длительности. На вход каждой модели подаются: Dense input, ID input и Duration. Dense input включает признаки, построенные по историческим статистическим показателям (например, историческим количеству показов, эмпирическому времени просмотра видео). ID input может быть представлен различными идентификаторами, такими как идентификатор пользователя или идентификатор видео, а также категориальными данными, такими как категория видео и пол пользователя. Duration - продолжительность видео.
Для офлайн и онлайн экспериментов использовались данные платформы Kuaishou. Модели сравнивались по метрикам MAE, XAUC и XGAUC. XAUC – это расширение метрики AUC, где для каждой сэмплированной пары видео предсказанный порядок по watch-time сравнивается с реальным. Метрика показывает насколько предложенная модель, предсказывающая watch time, совпадает с идеальным ранжированием. XGAUC – это XAUC с усреднением по пользователю. Предложенная модель обошла другие по XAUC и XGAUC метрикам, по MAE была меньше. В качестве baseline была взята WLR модель – взвешенная логистическая регрессия по квантилям продолжительности видео, а D2Q и Res-D2Q - предложенные DL подходы.
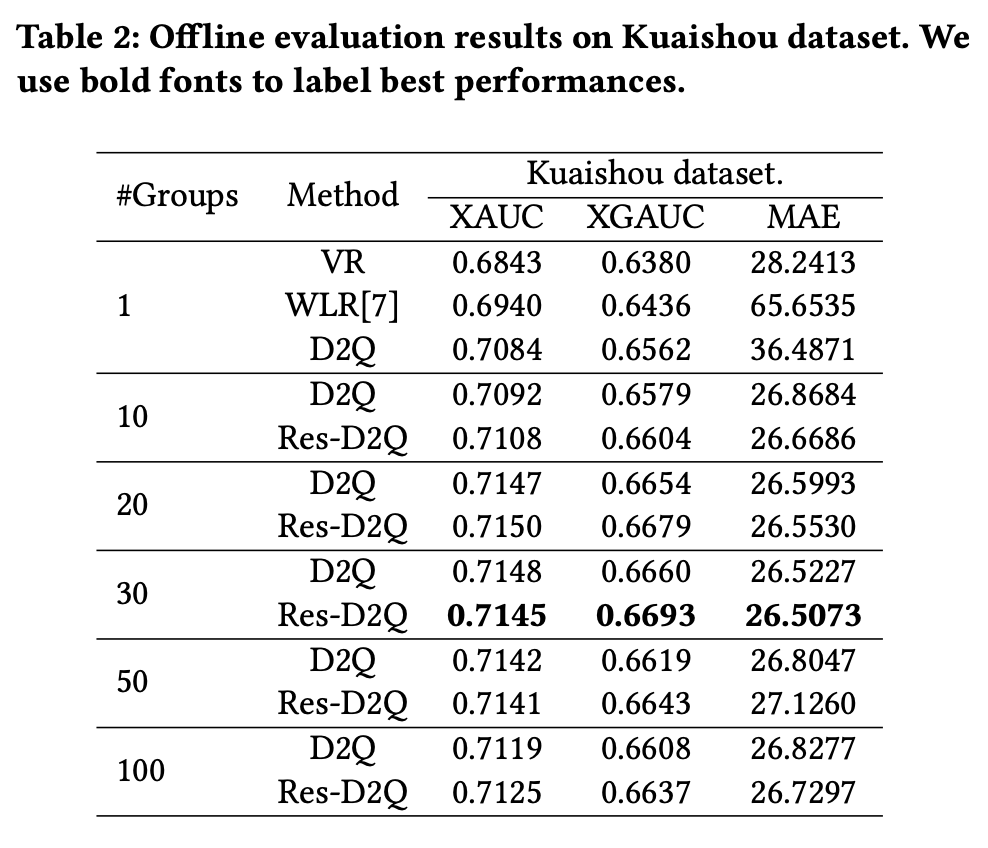
Онлайн эксперименты показали, что предложенный подход увеличивает watch time и количество лайков.
Анализ
Статья раскрывает проблему duration bias в предсказании watch time и предлагает методы борьбы с ним.
Предложенный подход показывает лучшее качество как в оффлайн так и онлайн экспериментах.
Бенчмарк метрик на датасете отличается в 3-м знаке после запятой, что кажется недостаточным. Возможно стоило выбрать другую метрику, где различие более явное или отразить доверительный интервал текущих метрик.
В статье не приведено сравнения с сильным baseline таких как xgboost на табличных признаках, а сравниваются только свои DL подходы Naive-D2Q, Res-D2Q и D2Q. Как baseline используется Weighted LogReg, который уверенно побеждают предложенные DL модели.
Не проведено сравнение с другими способами борьбы с bias – causal embedding и inverse propensity weighting.
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Автор разбора @pekshechka
Ранжирование рекомендательной системы состоит из двух этапов: Multi-Task Learning (MTL), который прогнозирует различные типы фидбэка пользователей (клики, лайки и т. д.) и Multi-Task Fusion (MTF), который объединяет результаты MTL в один окончательный рейтинг удовлетворения пользователя. Именно о втором этапе идет речь в статье. Чтобы оптимизировать долгосрочную удовлетворенность пользователей, авторы предлагают структуру BatchRL-MTF, которая включает в себя Batch Reinforcement Learning и Online Exploration. Также авторы предлагают подход Conservative-OPEstimator для тестирования модели оффлайн (в обзор не влез, извините). Модель была развернута на крупномасштабной промышленной платформе коротких видео, обслуживающей сотни миллионов пользователей.
Детали
Для этого обзора желательно быть знакомыми с основными принципами RL. Неплохой краткий гайд есть у OpenAI. Итак, что у нас есть?
Batch RL (offline policy). С практической точки зрения это означает, что обучение будет происходить только на логах, никаких симуляций, никакого обучения в онлайне. Offline policy – это по сути off-policy, но мы должны гарантировать, что уже после первой итерации обучения модель будет достаточно хороша для продакшена. Это означает, что для Batch RL очень важен вопрос устойчивости модели.
Online exploration. Помимо того, как обучать модель, авторы затрагивают тему того, как сделать Online exploration. Это очень важный вопрос в контексте Batch RL, из-за partial observation — в логах у нас преобладают те видео, которые продакшен модель считала хорошими. Это приводит к extrapolation error: модель очень плохо работает для айтемов, мало представленных в данных.
Основная задача – получить final ranking score для ранжирования айтемов. Авторы определяют эту функцию как
где ???? = (????1, . . . , ????????) – предсказания для разных типов фидбека, ???? = (????1, . . . , ????????) – фиксированные гиперпараметры, ???? = (????1, . . . , ????????) – персонализированные веса, которые мы хотим оптимизировать.
Определим несколько величин:
State space S: данные пользователя и его 500 последних видео вместе с фидбэком.
Action space A: Это вектор весов типов фидбека ???? = (????1, . . . , ????????) из final ranking score.
Instant reward ????(????, ????): мгновенная награда за просмотр.
где ???????? - значение фидбека, который оставил пользователь в видео, а ???????? - вес этого фидбека, подобранный эвристически.
Batch Reinforcement Learning for MTF
Авторы используют Batch-Constrained deep Q-learning (BCQ), основанную на Actor-Critic архитектуре. Actor состоит из двух моделей: Action Generative Network ???????? = {????????1, ????????2} и Action Perturbation Network ????????(????, ????, ????).
Action Generative Network – это variational auto-encoder (VAE) ????????. Энкодер ????????1 принимает на вход текущее состояние (state) ???? и действие (action) ????, и на выходе отдает ???? и ???? нормального распределения. Далее мы сэмплируем латентный вектор ???? ∼ N(????, ????2). Декодер ????????2, получая на вход ???? и текущее состояние ????, генерирует действие ????, которое старается приблизить к оригинальному.
VAE нужен для устойчивости и борьбы с extrapolation error: он помогает обогатить данные новыми парами состояние-действие. На этом этапе мы генерируем несколько действий для текущего состояния.
Action Perturbation Network по состоянию и действию выдает perturbation ???? ∈ [−????, ????] (???? – гиперпараметр). С его помощью обновляется текущее действие как ???????? + ????????. Action Perturbation Network оптимизируется как actor в actor-critic подходе, максимизируя Q-function.
Критик (Q-function) оптимизируется как критик в actor-critic подходе через уравнение Беллмана с twin-delayed подходом.
Итоговый алгоритм BatchRL-MTF Policy выглядит так:
Для текущего состояния генерируем несколько действий с помощью VAE.
Каждое действие модифицируем с помощью perturbation, полученного из Action Perturbation Network.
Выбираем действие с максимальным значением Q-function.
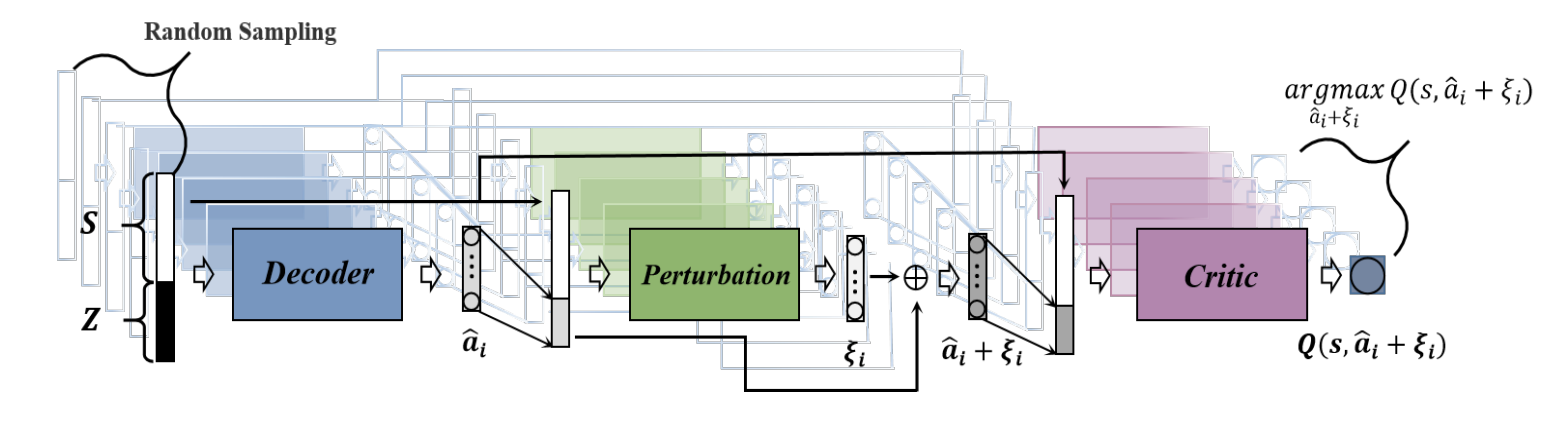
Online Exploration
Есть два подхода к exploration:
Random Exploration. Генерируем вес нормальным распределением, ограничивая его [-1, 1]. Этот подход позволяет улучшить покрытие пространства состояние-действие.
Action-Noise Exploration. К исходному весу фидбэка добавляем нормально распределенный шум ???? ∼ N (0, 0.1). Этот подход позволяет лучше исследовать область около потенциально высоких значений.
Идея авторов – объединить эти два подхода в равных пропорциях для формирования датасета, такой подход назвали Mixed Multi-Exploration.
Результаты
Предложенный подход побеждает почти все бейзлайны (а для тех, которые не побеждает, авторы показывают их меньшую устойчивость). Мое мнение – статья интересная, много сильных моделей в бейзлайне, обширное ablation study. Недостатки:
Эвристика для подсчета instant reward.
Завидую авторам, что они могут позволить себе Random Exploration в проде.
Не очень понятна связка BCQ и Random Exploration. BCQ заточен под работу без хорошего Exploration. Например, декодер VAE в сеттинге авторов в половине случаев учится приближать случайные действия, а в другой половине учится приближать action, генерируемый старой политикой. Кажется, что в таком случае мы должны получать ????, близкие к действиям от старой политики, но с сильным смещением к 0. И что это только портит потенциальный импакт от Random Exploration. Хотелось бы больше сравнений Mixed Multi-Exploration и Random Exploration с обучением без Exploration.
Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation
Автор разбора @yaulyanenko
Авторы статьи решают популярную задачу в RecSys – подбор рекомендации для trigger item. В их случае это подбор следующих видео после текущего в китайском сервисе Kuaishou (ближайший аналог – TikTok). При этом помимо релевантности необходимо развивать разнообразие предлагаемых видео, чтобы пользователи не застревали в своем информационном коконе. Авторы представили фреймворк для переранжирования с учетом “развязанных” (disentangled) признаков – Feature Disentanglement Self-Balancing Re-ranking framework (FDSB). Этот подход применили на данных сервиса Kuaishou, оценили этот подход offline, а также провели А/Б тесты, которые показали небольшое, но улучшение и метрик просмотров, и разнообразия.
Детали
Существующие подходы к разнообразию обычно учитывают разнообразие на уровне объектов, а не на уровне их свойств. При этом прямой подход к рекомендациям на уровне исходных признаков (например, нахождение и объединение релевантных элементов для каждой характеристики) может оказаться неэффективным на практике.
Авторы сформулировали задачу рекомендаций в парадигме многофакторного ранжирования, которая совместно учитывает предпочтения пользователей, релевантность и разнообразие при переранжировании.
Фреймворк состоит из 2 ключевых компонент:
disentangled attention encoder (DAE) – “развязанный” attention encoder. Тут используется multi-head attention над верхнеуровневыми признаками объекта. Он позволяет получить те самые независимые “развязанные” признаки.
self-balanced multi-aspect ranker – самобалансирующийся механизм для учета одновременно и релевантности, и разнообразия на уровне каждого “развязанного” признака (а не объекта).
DAE используется для получения тех независимых признаков, которые далее будут использованы на следующем этапе переранжирования. Его устройство выглядит так:
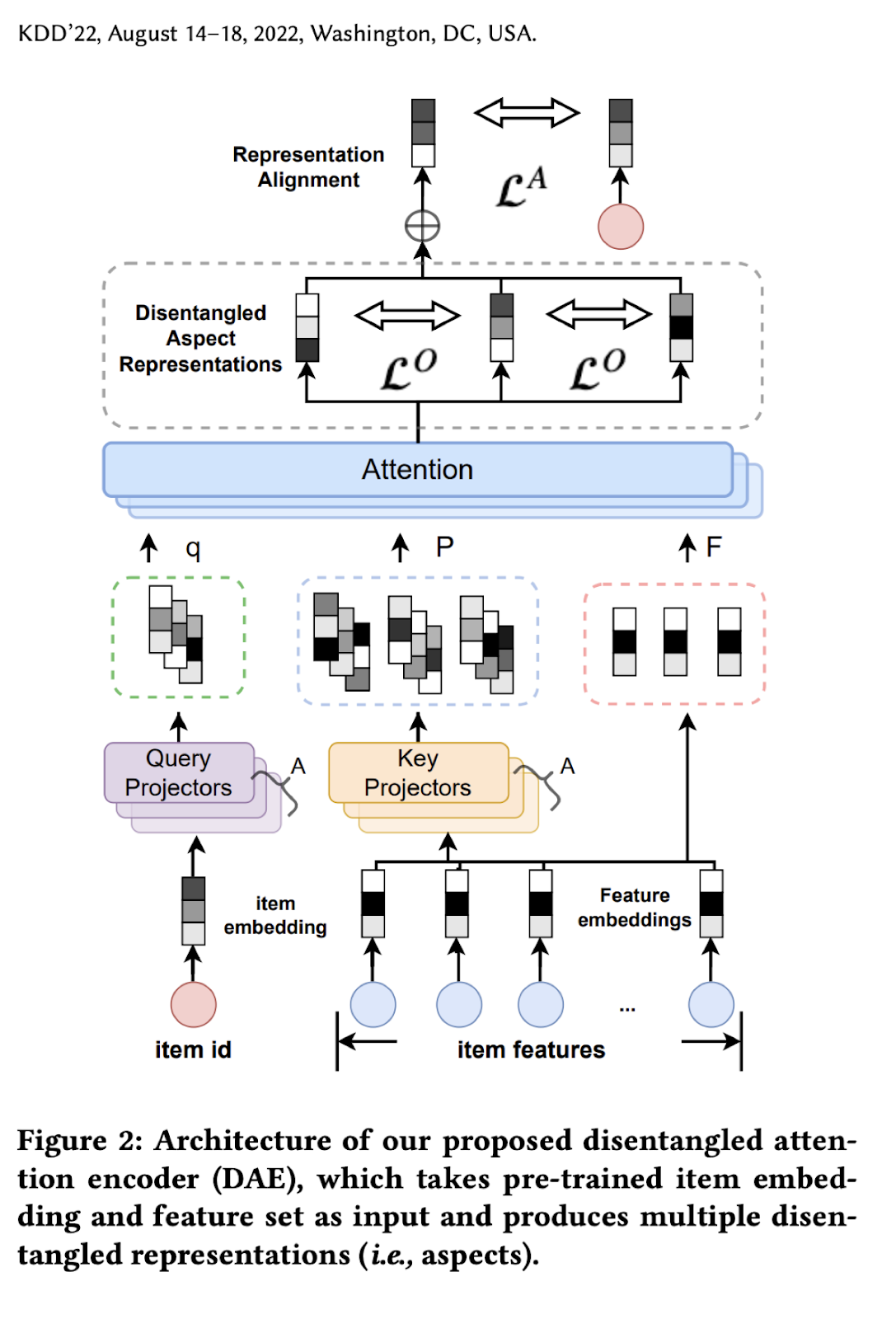
На вход подаются уже полученные заранее векторы объектов, а также исходные признаки, пропущенные через обучаемый embedding слой. Здесь важно пояснить, откуда эти исходные признаки, и зачем нужны какие-то другие. Часто объекты сопровождаются какими-то дополнительными признаками (тэгами/лейблами/описанием), но сами по себе они обычно избыточны и скоррелированы. Поэтому авторы ставят задачу получить вектор не связанных между собой (disentangled) признаков, которые они называют aspects (чтобы избежать путаницы с исходными признаками).
Вторая часть разработанного фреймфорка Self-balanced Multi-aspect Re-Ranker заключается в следующем:
-
На каждом шаге считаются два score на основании aspects:
score релевантности отражает, насколько рекомендованный объект близок к trigger объекту;
score разнообразия отражает, насколько рекомендованный объект далек от остальных рекомендованных объектов.
Рекомендации формируются с помощью жадного алгоритма, который старается учитывать оба скора. Так алгоритм старается подбирать каждый следующий элемент таким образом, чтобы он учитывал и релевантность, и разнообразие по aspects. Подробное описание жадного алгоритма в деталях можно посмотреть в оригинальной статье.
Эксперименты
Авторы собрали данные по лайкам по 369K пользователей и 241K видео. Для построения исходных эмбеддингов объектов использовалась обычная коллаборативная фильтрация. Далее к ним применили описанный выше DAE. В статье они приводят интересную картинку, иллюстрирующую, что такое aspects:

Авторы сравнили результаты предложенного ранжирования с другими алгоритмами, и (конечно же) получили преимущество в оффлайн-метриках.
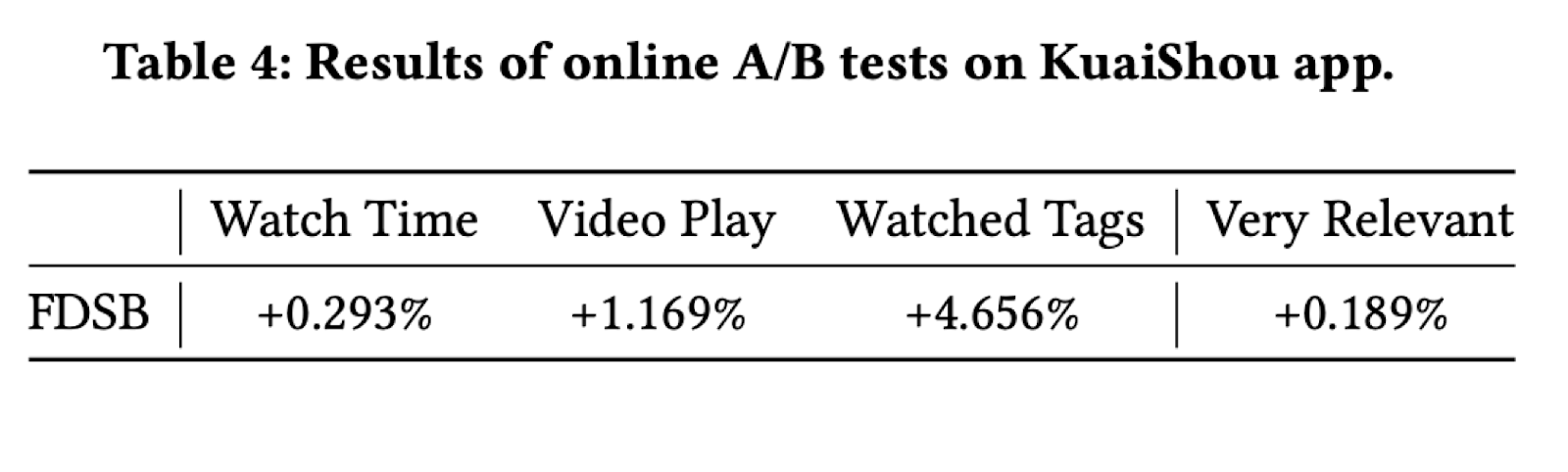
Однако на оффлайн-экспериментах они не остановились и провели A/Б тестирование данного подхода. Он показал прирост во времени просмотров, их количестве, а также в разнообразии просмотренных тегов:
Также в статье авторы показали, как предложенный подход был реализован в продакшен сервисе.
Анализ
Статья достаточно прикладная. В ней предложен подход к решению проблемы недостаточного разнообразия при сохранении релевантности. Здорово, что авторы не просто показали классическую таблицу со сравнением различных оффлайн-метрик, но также привели результаты А/Б-эксперимента. Единственное, не до конца понятно, почему, именно такой подход работает, хотя некоторая интуиция за ним определенно есть.
Заключение
В работе над рекомендательными системами не всегда получается воспользоваться результатами, полученными на переднем крае науки. Тем не менее, разбирать статьи нужно. Потому что то, о чем писали в статьях несколько лет назад, сейчас – распространенная индустриальная практика. Возможно уже совсем скоро использование методов causal inference или reinforcement learning в рекомендерах станет обыденностью. Мы будем держать вас в курсе, до новых встреч!
OBIEESupport
Это вы серьезно считаете обзорами? Знаете, в науке есть понятие "братская могила" - научный сборник, который никогда не будет востребован ни одним из его соавторов.
Давайте я напомню принцип хорошего обзора.
Постановка задачи на оптимизацию ( у вас - социальный граф). Он имеет кучу исследованных и переоткрытых в сборниках ИПУ РАН свойств. Есть и много другой русскоязычной литературы.
Введение переменных, по которым будет делаться оптимизация. Будут ли это мгновенные реакции (клики на рекламу), средние по времени - просмотр, заливка, обмен фактами, долговременные - подписка на сервис/человека.
Составление уравнений для оптимизации. Точность модели и уравнения, анализ погрешности.
Методика решения/оптимизации - численный, либо структурный анализ.
Выводы.
Итого: все вами написанное это описание статей, а не обзоры. Извините за прямоту. Одноклассники должны быть классными во всем!
anokhinn Автор
Спасибо за прямоту!
Ни я, ни мои коллеги, которые помогали со статьей, не придали значения терминологической разнице между обзором и описанием, которую вы указываете. В будущем мы будем иметь ее в виду. Мы действительно стараемся быть классными во всем. Если захотите нам помочь (в том числе с разбором статей), у нас есть классные вакансии (например https://team.vk.company/vacancy/9721/, https://team.vk.company/vacancy/8787/).