
Команда ОК изучила материалы конференции RecSys 2023 и сделала разбор наиболее знаковых из них. Первую часть разбора читайте здесь. И подписывайтесь на наш ТГ-канал ML — это ОК. В канале мы выкладываем разборы интересных статей по теме ML и делимся экспертизой, которую накопили за 12 лет в этой сфере.
Scaling Session-Based Transformer Recommendations using Optimized Negative Sampling and Loss Functions
В статье команда рекомендаций из маркетплейса OTTO предлагает модификацию SASRec, которая называется TRON. В этой модификации используется отличная от оригинального SASRec функция потерь и изменённая схема семплирования негативных.
В качестве функции потерь вместо бинарной кросс-энтропии, которая используется в SASRec, авторы решили использовать listwise лосс — sampled softmax (SSM).
Семплирование негативных состоит из следующих этапов:
Равномерно семплируем негативные из айтемов в батче (in-batch).
Семплируем айтемы пропорционально частоте (frequency).
Объединяем списки, полученные в пунктах 1 и 2.
Из объединённого списка после получения скоров для каждого айтема, отбирается топ K самых негативных айтемов по скору.
Эту идею коллеги взяли из соревнования на Kaggle, которое проводила компания OTTO. Такая схема решает две проблемы: во-первых, из-за меньшего количества негативных айтемов обучение происходит быстрее, а во-вторых, можно брать большое количество айтемов и использовать более широкий контекст.
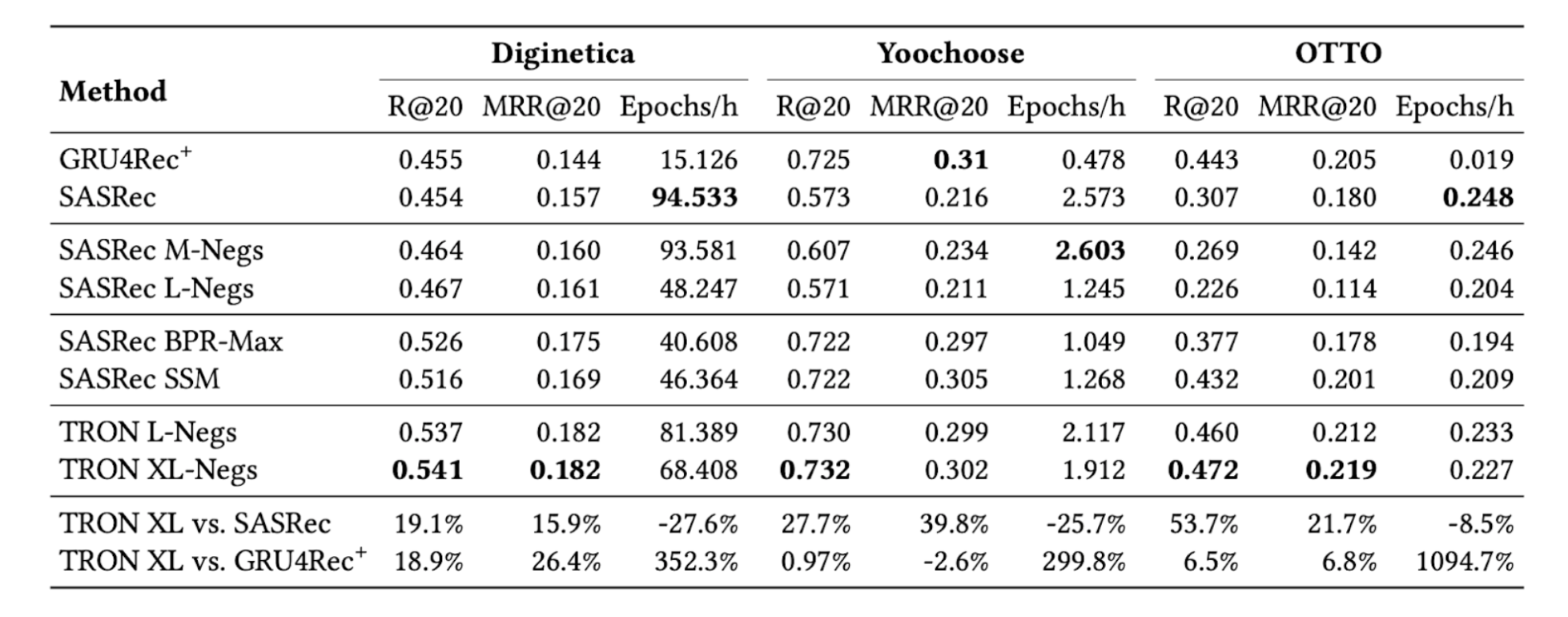
В экспериментах TRON представлен двумя наборами гиперпараметров:
TRON L-Negs. 8192 in-batch + 127 frequency негативных.
TRON XL-Negs. 16384 in-batch + 127 frequency негативных.
В качестве бейзлайнов выступают GRU4Rec и различные модификации SASRec (см. картинку). Авторы сравнивают TRON с этими бейзлайнами на трёх публичных наборах данных по метрикам MRR@20 и recall@20. В итоге TRON победил в пяти из шести экспериментов, а время обучения уменьшилось на 25% по сравнению в SASRec. В A/B-тестах авторы также добились статистически значимого прироста в ~18% в метрике CTR против модели SASRec на SSM лоссе. Код предложенной модели со всеми датасетами выложен на GitHub.
Результаты показывают, что сочетание listwise лосс с отбором топ K негативных из большого семпла даёт значительный результат, поэтому такой подход можно брать на вооружение и пробовать у себя.
LightSAGE: Graph Neural Networks for Large Scale Item Retrieval in Shopee’s Advertisement Recommendation

В работе представлена реализация рекомендательной системы сингапурского онлайн-магазина Shopee. Эта рекомендательная система основана на графовой нейронной сети, где каждый пользователь представлен графом, построенным на основе активности пользователя в онлайн-магазине.
В этом графе:
вершины – айтемы, с которыми пользователь взаимодействовал;
признаки вершин – заранее обученные эмбеддинги айтемов;
рёбра – переходы пользователя от одного товара к другому.
Задача нейронной сети — порекомендовать дополнительные товары на основе графа пользователя и айтема, который он просматривает в данный момент.
Общий алгоритм работы графового рекомендера такой:
Пользователь просматривает айтем A.
Векторы признаков вершин, из которых можно попасть в айтем A за n шагов, усредняются с некоторыми весами.
Полученный вектор признаков подаётся на вход нейронной сети, которая вычисляет предсказание модели.
Авторы статьи предлагают три модификации общего алгоритма: новый алгоритм построения графа, новую архитектуру и новый подход к учёту айтемов из хвоста (long-tail).
Ключевой вклад состоит в построении графа. Идея в том, чтобы использовать только очень существенные действия пользователя для построения ребра между товарами. Мотивация — подавление шума. Например, учитывается только переход из описания айтема A на страницу айтема B. Проблема в том, что если оставить только такие рёбра, то граф получается разреженным. Чтобы уплотнить граф, авторы использовали два алгоритма добавления рёбер:
Первый — реализация алгоритма Swing за авторством исследователей Alibaba.
Второй основан на поиске по онлайн-магазину: если пользователь сделал поисковый запрос, и просмотрел айтем A и айтем B, то эти товары соединяются ребром.
Полученный граф используется для обучения модели и предсказаний.
Для улучшения архитектуры нейронной сети авторы уменьшили количество слоёв и убрали из некоторых слоёв нелинейные активации. В итоге по объёму памяти и по числу нелинейных операций сеть стала меньше конкурирующих решений.
Long-tail айтемы обрабатываются двумя разными способами — на обучении и на inference.
При обучении айтемы из хвоста группируются по похожести. Векторы признаков усредняются внутри групп для дальнейшего использования в графе.
На inference стратегия меняется — eсли long-tail айтем соединён ребром с айтемом, который сейчас просматривает пользователь, то он обрабатывается как обычный айтем (усреднение по соседям не применяется). В противном случае — long-tail айтем обрабатывается так же, как и при обучении (применяется алгоритм усреднения).
Общая архитектура показана на картинке. Описанный в статье алгоритм был внедрён в продакшен. Он продемонстрировал более высокую точность по сравнению с конкурентами на офлайн-данных и на A/B-тестировании. В эксперименте выросло число заказов и прибыль онлайн-магазина.
Multi-task Item-attribute Graph Pre-training for Strict Cold-start Item Recommendation

Статья посвящена задаче рекомендации strict cold-start (SCS) товаров, то есть таких товаров, которые модель не видела в момент обучения, потому что у них нет истории взаимодействия с пользователями. То есть на инференсе про SCS-товары известно только их описание.
Основная идея в том, что множество атрибутов товаров стабильно – новые атрибуты появляются значительно реже новых товаров. Таким образом, даже у SCS-товара большая часть атрибутов не будут новыми и на их основании можно охарактеризовать сам товар.
Предлагаемая в статье архитектура состоит из следующих шагов (см. картинку):
Атрибуты выделяются из текста как словосочетания с существительными, к этому множеству шумных атрибутов также добавляются точные атрибуты, такие как бренд товара. Товары представлены конкатенацией входящих в них атрибутов.
В первом блоке модели для атрибутов и товаров строятся эмбеддинги с помощью PLM (BERT), затем с помощью интерпретатора (MLP) эмбеддинги приводятся к более информативному виду, фильтруется шум. После этого эмбеддинги проходят GNN, чтобы выучить связи «товар-атрибут».
Во втором блоке выучиваются корреляции между товарами. Идея этого блока состоит в том, что товары, которые покупал один и тот же пользователь, имеют некоторое сходство. Чтобы выучить это сходство, используется BERT4Rec, которому на вход подается последовательность эмбеддингов покупок пользователя.
В третьем блоке в эмбеддинги товаров добавляется информация об отзывах пользователей. Чтобы не путать с атрибутами, выделяемая из отзыва информация называется терм отзыва. Термы выделяются из текста отзыва как эмоциональные фразы. Затем эмоция во фразах упрощается до уровня «плохой», «хороший». Эмбеддинги полученных термов строятся аналогично эмбеддингам атрибутов с помощью PLM, интерпретатора и GNN.
Эксперимент проводился на трёх датасетах (Yelp, Amazon-home, Amazon-sports), таким образом, что на тесте на вход модели подавались только SCS-товары. При сравнении с моделями, обучаемыми на том же датасете, представленная в статье модель показала прирост NDCG@5 до 64% и Recall@5 до 47%. При сравнении с предобученной UniSRec по метрикам было примерно равенство, что авторы тоже считают успехом, поскольку предобучалась UniSRec на существенно большем датасете. В статье есть ссылка на репозиторий с исходным кодом и датасетами, подробно анализируются гиперпараметры.
Rethinking Multi-Interest Learning for Candidate Matching in Recommender Systems

Статья предлагает новый метод для решения задачи Multi-Interest Learning. В этой задаче пользователь представляется не единственным эмбеддингом, а набором из k эмбеддингов-интересов. Обучение интересов происходит в два этапа (см. рисунок):
Item representation. Последовательность айтемов, которыми интересовался пользователь, представляется в виде матрицы эмбеддингов размерности n x d, где n – длина последовательности, d – размерность эмбеддинга.
Multi-interest routing. Полученная матрица эмбеддингов умножается на обучаемую routing matrix размерности n x k. Routing matrix определяет соответствие айтемов интересам. В итоге получаем матрицу интересов пользователя размерности k x d.
Авторы статьи рассказывают про две проблемы, с которыми они столкнулись при решении задачи multi-interest learning, и предлагают модификацию REMI, которая позволяет решить эти проблемы.
Проблема 1: Sampled Softmax Loss. Типичный размер каталога айтемов в современных рекомендерах – сотни тысяч. Чтобы не считать функцию потерь по всем айтемам, предлагается использовать Sampled Softmax Loss. Для подсчёта ошибки он берёт только позитивный айтем и небольшое число негативных айтемов.
Проблема заключается в том, что в качестве негативных айтемов могут быть выбраны айтемы, которые выступают в качестве других интересов пользователя. Рассмотрим пользователя, чья последовательность включает продукты питания, электронику и сумки. В качестве позитивного айтема пусть выступает сумка. В качестве негативных айтемов будут выбраны айтемы, непохожие на сумку. Например, компьютер (интерес — электроника), хлеб (интерес — продукты) или пиджак. Однако эти айтемы могут выступать в качестве других положительных интересов пользователя.
Чтобы решить эту проблему авторы статьи предлагают новый подход к негативному семплированию. Идея заключается в том, чтобы в качестве негативных брать только те айтемы, с которыми пользователь ещё не провзаимодействовал, и эмбеддинги которых близки к эмбеддингу позитивного айтема.
Проблема 2: Multi-Head Attention. Авторы статьи заметили, что после нескольких эпох обучения интересы «фокусируются» на отдельных айтемах из последовательности пользователя. В итоге каждый интерес пользователя представлен только одним айтемом. Для решения этой проблемы авторы вводят регуляризатор дисперсии для routing matrix.

Сравнение производительности различных методов производилось на трех открытых наборах данных. Во всех экспериментах REMI превзошел как single-interest, так и multi-interest конкурентов.
STRec: Sparse Transformer for Sequential Recommendations

С самого зарождения архитектуры трансформера стали появляться её реализации для задач рекомендаций, в частности для последовательных рекомендаций (Sequential Recommender Systems, SRS). Ключевая особенность архитектуры трансформера – механизм внимания, который до сих пор используется в неизменном виде в большинстве моделей SRS. Его недостаток в том, что он вычисляет веса внимания между всеми возможными парами айтемов. Это ощутимо съедает вычислительные ресурсы и память, что негативно сказывается на производительности модели.
В статье авторы предлагают использовать новый механизм внимания, учитывающий взаимодействие только между значимыми элементами. Это должно положительно повлиять на качество предсказания, и при этом позволит обучать и использовать модель на меньших ресурсах.
В качестве отправной точки авторы взяли классическую архитектуру SRS – SASRec. Изучив матрицу внимания этой модели, исследователи обратили внимание (каламбур!) на феномен разреженного внимания. Рассмотренная матрица оказывается низкоранговой в двух аспектах (см. диаграмму):
лишь небольшая часть взаимодействий оказывает влияние на выход (зелёные столбцы на рисунке);
векторы весов внимания (строки на тепловой карте) оказываются одинаковыми.
Чтобы учесть феномен разреженного внимания, авторы придумали архитектуру Sparse Transformer model for sequential Recommendation (STRec). Её базовая структура такая же, как и у SASRec. Отличается механизм внимания, который авторы называют cross-attention. Он подсчитывает внимание между исходной последовательностью айтемов и некоторой выборкой из этой последовательности. Шанс айтема быть выбранными выучивается моделью и зависит от времени взаимодействия пользователя с айтемом. Интуиция в том, что больше всего на рекомендации влияют айтемы, с которыми пользователь взаимодействовал недавно (это видно на диаграмме с матрицей внимания). В этой модели вычислительная сложность снижается за счёт кратного уменьшения количества пар айтемов, по которым считается внимание.
Получившаяся модель оценивалась на датасетах ML-20M, Gowalla и Amazon-Electronics по двум составляющим:
качеству предсказания;
эффективности затрачиваемых ресурсов.

По качеству предсказаний STRec победил другие модели в 6 экспериментах из 9 (см таблицу 2), но существенного прироста метрик авторы не получили (и не ожидали). А вот что ожидали, так это уменьшение времени предсказания и требуемых ресурсов (см. таблицу 3). Тут представленное решение — практически абсолютный чемпион. Конкуренцию смогла составить лишь сеть Informer.

Таким образом:
Обоснованные преобразования в механизме внимания позволили существенно сократить требуемые ресурсы, и при модель превзошла по качеству ряд конкурентов.
С помощью гиперпараметров можно регулировать размер семпла и до определённого порога решение всё ещё будет лучше базовой архитектуры — SASRec. (рисунки 4-5)
Код для воспроизведения экспериментов выложен в открытый доступ, а вот сама статья – нет.
Замечание. Авторы используют понятие sparsity скорее как маркетинговый ход: подход больше похож на обрезку матрицы запросов, и его можно описать словом shrinking, которое в статье также встречается.
Заключение
Завершаем разбор #recsys23 отчётом о воркшопе LARGE-SCALE VIDEO RECOMMENDER SYSTEMS. Воркшоп был посвящен видео лишь отчасти – скорее получилась FAANG-тусовка, на которой представители топовых компаний делились опытом и планами масштабирования рекомендеров. В этом посте – основные выводы, которые мы сделали из воркшопа.

Foundation modes. YouTube и Netflix рассказывают, что обучают большие мультимодальные нейросети. Они используются в нескольких рекомендерах как универсальные базовые модели (см. пример архитектуры на рисунке). Докладчик из YouTube приводит такие данные: c 2015 года количество параметров выросло в тысячу раз, размер данных – в пять раз. Вдохновение черпают в успехе LLM, и это оправдано, потому что:
у рекомендаций последовательная природа, почти как в текстах;
модель можно обучать и применять на несколько модальностей: видео, фото, посты;
большие компании собирают достаточно данных для обучения больших моделей;
улучшение базовой модели быстро разлетается по всем рекомендерам, где она используется.
В то же время при внедрении foundation models в рекомендациях возникают сложности:
Предложение в тексте – это просто последовательность слов, в то время как последовательности действий пользователя более сложные: они состоят из различных действий и в них меньше структуры. Вопрос в том, как всё\ это учесть в модели.
Количество эмбеддингов в рекомендациях на порядки больше, чем в LLM. Например, на YouTube загружено порядка миллиарда видео, а токенов в языковых моделях – «всего» сотни тысяч. Поэтому масштабирование больших рекомендательных моделей и инфраструктура для них – отдельная сложная задача.
Objectives. Ещё одна важная тема в индустриальных рекомендерах – выбор метрики, которую оптимизировать. Netflix практикует multi-task, Google Brain работает над определением долгосрочных целей пользователей, YouTube и KuaiShou используют подходы из Reinforcement Learning. В любом случае все согласны, что простая оптимизация CTR больше не работает. Особенно для трансформерных моделей – они слишком выразительные и легко ломают business value, если обучены на неудачную метрику.
Incremental training. Важно не только иметь мощную модель, но и заставить её как можно быстрее реагировать на изменения мира: появление новых пользователей и айтемов, возникновение трендов или глобальных событий. Эти вопросы обсуждались в докладах YouTube и Netflix.
Несмотря на то что воркшопы считаются менее престижными, чем основная конференция, этот получился по-настоящему программным. Мы (ML-команда OK) считаем, что тренды из этого поста будут определять индустриальные рекомендеры в ближайшие годы. Особенно приятно, что мы сами работаем в этих направлениях и обязательно поделимся с вами успехами.
Спасибо, что читали наш разбор #recsys23!