

В Slack всей своей инфраструктурой, опирающейся на AWS, DigitalOcean, NS1 и GCP, мы управляем с помощью Terraform. И хотя большая её часть работает на AWS, мы выбрали Terraform в противоположность их нативному сервису CloudFormation, чтобы использовать единый инструмент среди всех провайдеров сервисов. Это позволяет сохранить модель «инфраструктура как код» и механизм развёртывания универсальными. В статье мы разберём процесс развёртывания нашей инфраструктуры с помощью Terraform.
▍ Эволюция файлов состояния в Terraform

Slack начинался с одного аккаунта AWS, и все наши сервисы располагались в нём. Поначалу время структура файлов состояния Terraform являлась очень простой. У нас было по одному такому файлу для каждого региона AWS и отдельный файл для глобальных сервисов, таких как IAM и CloudFront.
├── aws-global
│ └── cloudfront
│ ├── services.tf
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── us-east-1
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── us-west-2
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── ap-southest-2
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
└── digitalocean-sfo1
├── services.tf
├── terraform.tfvars
├── terraform_state.tf
├── variables.tf
└── versions.tfДля среды разработки и продакшена существовали идентичные конфигурации, но по мере развития компании размещение всех сервисов AWS на одном аккаунте стало неприемлемым. Создавались десятки тысяч инстансов EC2, и мы начали сталкиваться с различными лимитами AWS. Консоль AWS EC2 стала непригодной для использования в us-east-1, где размещалась огромная часть нашей рабочей нагрузки. Также ввиду большого числа сформировавшихся команд стало очень сложно управлять доступом в одном аккаунте AWS. Именно тут мы и решили создать выделенные аккаунты AWS для определённых команд и сервисов. Этот процесс я подробно раскрыл в двух других статьях: Building the Next Evolution of Cloud Networks at Slack и Building the Next Evolution of Cloud Networks at Slack – A Retrospective.
Используя Jenkins в качестве механизма развёртывания, при внесении изменения в заданный файл состояния мы могли активировать соответствующий конвейер Jenkins для развёртывания этого изменения. У таких конвейеров есть две стадии: планирование (Plan) и применение (Apply). Стадия планирования позволяет проверить, что произойдёт на стадии применения. Эти файлы состояния мы объединяем в цепочку, в результате чего до перехода в продакшен изменения приходится проверять в песочнице и среде разработки.

Раньше управление внутренней инфраструктурой, базой кода Terraform и файлами состояния входило в ответственность центральной команды Ops. Но по мере создания всё большего числа дочерних аккаунтов для команд Slack количество файлов состояния значительно возросло.
Сегодня у нас уже нет централизованной команды Ops. За управление платформой Terraform отвечает команда Cloud Foundations, частью которой я и являюсь, а состояния и конвейеры Terraform перешли под ответственность владельцев сервисов. Сейчас мы используем уже почти 1,400 файлов состояния, принадлежащих различным командам. Ребята из Cloud Foundations контролируют версии Terraform, версии провайдеров, набор инструментов для управления Terraform, а также ряд модулей, предоставляющих базовую функциональность.
Как я говорил, сегодня в каждом аккаунте у нас есть по одному файлу состояния для региона и отдельный файл для глобальных сервисов, таких как IAM и CloudFront. Однако мы также стремимся создавать отдельные изолированные файлы состояния для более крупных сервисов, чтобы свести к минимуму количество ресурсов, регулируемых одним таким файлом. Это ускоряет процесс развёртывания и повышает безопасность внесения изменений в меньшие файлы состояния, поскольку количество подверженных этим изменениям ресурсов снижено.
Для хранения всех состояний Terraform мы используем корзину AWS S3 с поддержкой версионирования, где они размещаются по разным путям. Мы также задействуем функционал блокировки состояний и проверки согласованности из DynamoDB. Функция версионирования объектов при этом позволяет легко делать откат к прежним версиям состояний.
▍ Где мы выполняем Terraform?

Все наши конвейеры Terraform выполняются на выделенных воркерах Jenkins. Этим воркерам назначены роли IAM с уровнем доступа к дочерним аккаунтам достаточным, для построения необходимых ресурсов. Однако инженерам Slack также требуется место для тестирования изменений Terraform или прототипирования новых модулей. Таким местом должна выступать среда, идентичная среде воркеров Jenkins, но уже без такого уровня доступа. В связи с этим мы создали вид пространства под названием «Ops», дав инженерам возможность запускать экземпляры таких пространств с помощью веб-интерфейса.

При этом перед запуском инстанса они могут выбирать его размер, регион и объём диска. В случае длительного простоя эти инстансы автоматически уничтожаются. Во время конфигурирования созданных пространств все наши двоичные файлы Terraform, провайдеры, обёртки и связанные инструменты настраиваются так, чтобы их среда была идентична среде воркеров Jenkins. Однако для наших аккаунтов AWS эти пространства предоставляют доступ только для чтения. Следовательно, они позволяют инженерам планировать любые изменения Terraform и оценивать их результаты без возможности применения через свои пространства «Ops».
▍ Как мы работаем с версиями Terraform?

Мы начали с поддержки одной версии Terraform, развернув её двоичный файл и плагины для воркеров Jenkins и прочих мест, где используем Terraform, через систему управления конфигурацией Chef. Все двоичные файлы при этом были взяты из корзины S3.
Ещё в 2019 году мы обновили файлы состояния с Terraform 0.11 до 0.12. Это было обновление старшей версии, поскольку коснулось изменений синтаксиса. Тогда мы провели за этим апгрейдом целый квартал. Модули пришлось копировать с суффиксом
-v2 для поддержки новой версии Terraform. Мы написали для бинарников Terraform обёртку, которая проверяла файл version.tf в каждом файле состояния и выбирала из них нужный. После обновления всех файлов состояния мы удалили бинарник 0.11 и внесённые в обёртку изменения. В целом это был очень тяжёлый и длительный процесс.Мы просидели на версии Terraform 0.12 почти два года, прежде чем задумались о переходе на 0.13. На этот раз мы решили добавить инструменты для упрощения последующих изменений. Однако всё усложнилось тем, что примерно в то же время вышла версия AWS 4.x, мы же использовали 3.74.1. Между этими версиями произошло много серьёзных изменений, и мы решились одновременно обновить Terraform и AWS.
И хотя были доступны более новые версии Terraform (0.14 и 1.x), обновление рекомендовалось делать через версию 0.13. Мы хотели реализовать систему для развёртывания нескольких версий Terraform и плагинов, чтобы можно было выбирать нужные на основе файла состояния. Для этого мы ввели файл конфигурации версий, который развёртывался в каждом пространстве.
{
"terraform_versions":
[
"X.X.X",
"X.X.X"
],
"package_plugins":
[
{
"name": "aws",
"namespace": "hashicorp",
"versions" : [
"X.X.X",
"X.X.X"
],
"registry_url": "registry.terraform.io/hashicorp/aws"
},
{
"name": "azurerm",
"namespace": "hashicorp",
"versions" : [
"X.X.X"
],
"registry_url": "registry.terraform.io/hashicorp/azurerm"
},Мы начали развёртывать несколько версий Terraform и провайдеров. Обёртка была изменена для считывания файла version.tf в каждом файле состояния и выбора нужной версии Terraform.
Поскольку Terraform 0.13+ позволяет использовать несколько версий одного провайдера в каталоге плагинов, мы развернули в этом каталоге все версии, используемые нашими файлами состояния.
└── bin
├── registry.terraform.io
│ ├── hashicorp
│ │ ├── archive
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-archive
│ │ ├── aws
│ │ │ ├── X.X.X
│ │ │ │ └── linux_amd64
│ │ │ │ └── terraform-provider-aws
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-aws
│ │ ├── azuread
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-azuread
│ │ ├── azurerm
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-azurermЭто позволило одновременно обновить версии Terraform и AWS. В случае внесения новой версией провайдера критических изменений относительно прежней можно было откатить его обратно для конкретного файла состояния и затем уже постепенно обновить эти файлы до последних версий.
После апгрейда всех файлов состояния до актуальных версий их старые версии были удалены. Мы призвали отвечающие за сервисы команды не держаться за какие-либо конкретные версии провайдеров без весомых причин. По мере появления новых версий команда Cloud Foundations развёртывает их, а старые удаляет.
На этот раз мы создали инструмент, помогающий обновлять Terraform, и смогли запустить его для заданного состояния. Делает он следующее:
- проверяет текущую версию;
- проверяет наличие неприменённых изменений;
- проверяет, есть ли ещё файлы состояния, выполняющие поиск удалённых состояний в файлах состояния (Terraform 0.12 не способен выполнять поиск удалённых состояний в файлах Terraform 0.13+, что потенциально может нарушить некоторые из этих файлов);
- проверяет, может ли файл состояния после обновления выполнить планирование Terraform.
Изначально этот инструмент представлял собой простой bash-скрипт. Однако по мере внесения дополнительных проверок и логики он начал серьёзно усложняться, и понимать его стало трудно. Считывание синтаксиса Terraform с помощью Bash непростая задача, которая подразумевает использование множества команд сопоставления строк и
grep.В конечном счёте мы заменили этот скрипт бинарником Go. Библиотеки Go hclsyntx и gohcl существенно упростили считывание конфигурации Terraform и загрузку его элементов в структуры данных Go. Библиотека terraform-exec повысила удобство планирования в Terraform и проверки ошибок. Мы также встроили в этот бинарник возможность аналитики, в частности — проверку деревьев зависимостей модулей.
agunasekara@ops-box:service_dev (branch_name) >> terraform-upgrade-tool -show-deps
INFO[0000] welcome to Terraform upgrade tool
INFO[0000] dependency tree for this state file as follows
terraform/accnt-cloudeng-dev/us-east-1/service_dev
└── terraform/modules/aws/whitecastle-lookup
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/slack/service
└── terraform/modules/aws/alb
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/aws/aws_partition
└── terraform/modules/aws/ami
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/aws/autoscalingВ итоге стало проще оценивать, какой модуль затрагивает апгрейд заданного файла состояния.
Убедившись в корректности работы созданного инструмента, мы добавили в него возможность обновления части файлов состояния за раз. Его разработка и переход на версию 0.13 вылились в очень длительный процесс, но оно того стоило, и теперь, когда мы снова обновляем Terraform, происходит это уже в гораздо более плавном режиме.
▍ Как мы управляем модулями?

Наши файлы состояния и модули расположены в одном репозитории, и мы с помощью функционала CODEOWNERS назначаем ревью конкретного файла состояния соответствующей команде.
Для модулей мы использовали относительный путь.
module "service_dev" {
source = "../../../modules/slack/service"
whitecastle = true
vpc_id = local.vpc_id
subnets = local.public_subnets
pvt_subnets = local.private_subnetsИ хотя такой подход существенно упрощает тестирование изменений модулей, он также имеет некоторые риски, поскольку нарушает другие файлы состояния, этот модуль использующие.
Мы также опробовали предлагаемый GitHub подход к планированию путей.
module "network" {
source = "git::git@github-url.com:slack/repo-name//module_path?ref=COMMIT_HASH"
network_cidr_ranges = var.network_cidr_ranges
Private_subnets_cidr_blocks = var.private_subnets_cidr_blocks
public_subnets_cidr_blocks = var.public_subnets_cidr_blocksЭтот подход позволил нам прикреплять файл состояния к конкретной версии модуля. Однако был при этом и один серьёзный недостаток. Каждая команда Plan/Apply в Terraform должна клонировать весь репозиторий (напомню, что у нас весь код Terraform находится в одном), что оказалось очень длительным процессом. Кроме того, хэши Git не особо удобны для чтения и сопоставления.
▍ Собственный каталог модулей

Нам нужен был более удобный и простой способ управления модулями, в связи с чем было решено создать для этой цели внутренний инструмент. Теперь у нас есть конвейер, активируемый при каждом внесении изменения в репозиторий. Этот конвейер проверяет все модули на предмет изменений и в случае обнаружения таковых создаёт новый архив tar соответствующего модуля, загружая его в корзину S3 с новой версией.
agunasekara@ops-box:~ >> aws s3 ls s3://terraform-registry-bucket-name/terraform/modules/aws/vpc/
2021-12-20 17:04:35 5777 0.0.1.tgz
2021-12-23 12:08:23 5778 0.0.2.tgz
2022-01-10 16:00:13 5754 0.0.3.tgz
2022-01-12 14:32:54 5756 0.0.4.tgz
2022-01-19 20:34:16 5755 0.0.5.tgz
2022-06-01 05:16:03 5756 0.0.6.tgz
2022-06-01 05:34:27 5756 0.0.7.tgz
2022-06-01 19:38:21 5756 0.0.8.tgz
2022-06-27 07:47:21 5756 0.0.9.tgz
2022-09-07 18:54:53 5754 0.1.0.tgz
2022-09-07 18:54:54 2348 versions.jsonОн также загружает файл versions.json, где содержится история изменений данного модуля.
agunasekara@ops-box:~ >> jq < versions.json
{
"name": "aws/vpc",
"path": "terraform/modules/aws/vpc",
"latest": "0.1.0",
"history": [
{
"commithash": "xxxxxxxxxxxxxxxxxxxxxxxxx",
"signature": {
"Name": "Archie Gunasekara",
"Email": "agunasekara@email.com",
"When": "2021-12-21T12:04:08+11:00"
},
"version": "0.0.1"
},
{
"commithash": "xxxxxxxxxxxxxxxxxxxxxxxxx",
"signature": {
"Name": "Archie Gunasekara",
"Email": "agunasekara@email.com",
"When": "2022-09-08T11:26:17+10:00"
},
"version": "0.1.0"
}
]
}Ещё мы создали инструмент под названием tf-module-viewer, который позволяет командам легко перечислять версии модуля.
agunasekara@ops-box:~ >> tf-module-viewer module-catalogue
Search: █
? Select a Module:
aws/alb
aws/ami
aws/aurora
↓ aws/autoscaling
Используя этот новый подход к каталогизации модулей, теперь можно закреплять их в пути vendored_modules, и обёртки нашего бинарника Terraform при выполнении
init будут копировать эти модули из каталога S3.module "service_dev" {
source = "../../../vendored_modules/slack/service"
whitecastle = true
vpc_id = local.vpc_id
subnets = []
pvt_subnets = local.private_subnetsОбёртка считывает необходимую версию модуля из файла конфигурации, после чего перед выполнением
init скачивает нужные версии модулей в путь vendored_modules.modules:
aws/alb: 0.1.0
aws/ami: 0.1.9
aws/aurora: 0.0.6
aws/eip: 0.0.7▍ Идеально ли это решение? Нет…

Этот подход было решено использовать не во всех файлах состояния. Реализовали мы его только для имеющих строгие требования к соответствию. Другие файлы по-прежнему ссылаются непосредственно на модули, используя относительный путь в репозитории. Кроме того, подход с каталогизацией усложняет быстрое тестирование изменений, поскольку сначала необходимо внести эти изменения в модуль и загрузить его в каталог, после чего уже файл состояния сможет на этот модуль сослаться.
Модули Terraform могут иметь несколько выводов, условных ресурсов и конфигураций. Когда модуль обновляется и загружается в каталог, инструмент под названием Terraform Smart Planner просит пользователя протестировать все файлы состояния, использующие этот модуль, открепив его. Однако это необязательная процедура, в связи с чем изменения могут сработать для одних файлов, нарушив другие. Причём пользователи не узнают об этих проблемах, пока не обновят версию закреплённого модуля на последнюю. И хотя для исправления проблемы достаточно вернуться к прежней версии, это всё равно представляет неудобство, и для использования новой версии потребуется загрузить в каталог уже исправленный модуль.
▍ Как мы создаём конвейеры для файлов состояния?

Как я уже говорил, для развёртываний Terraform мы используем Jenkins. При наличии сотен файлов состояния мы задействуем сотни конвейеров и стадий. Для создания этих конвейеров мы используем собственную библиотеку Groovy с плагинами Jenkins Job DSL. В процессе разработки нового файла состояния команда либо создаёт полностью новый конвейер, либо добавляет этот процесс в качестве стадии существующего. Для этого мы добавили DSL-скрипт в каталог, который Jenkins считывает по расписанию, выстраивая все наши конвейеры. Однако это не самый удобный для пользователя опыт, так как процесс написания Groovy для создания нового конвейера требует много времени, и в нём легко допустить ошибки.
Тем не менее прекрасный инженер моей команды по имени Эндрю Мартин посвятил свой день инноваций решению этой проблемы. Он написал небольшую программу, считывающую простой файл YAML и создающую сложные DSL-скрипты, которые Jenkins может использовать для построения конвейеров. Этот новый подход кардинально упростил создание новых конвейеров состояний Terraform.
pipelinename: Terraform-Deployment-rosi-org-root
steps:
- path: accnt-rosi-org-root/env-global
- path: accnt-rosi-org-root/us-east-1
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/sandbox
next:
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/dev
next:
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/prod-staging
next:
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/prodКонфигурация выше приведёт к созданию следующего конвейера в Jenkins:
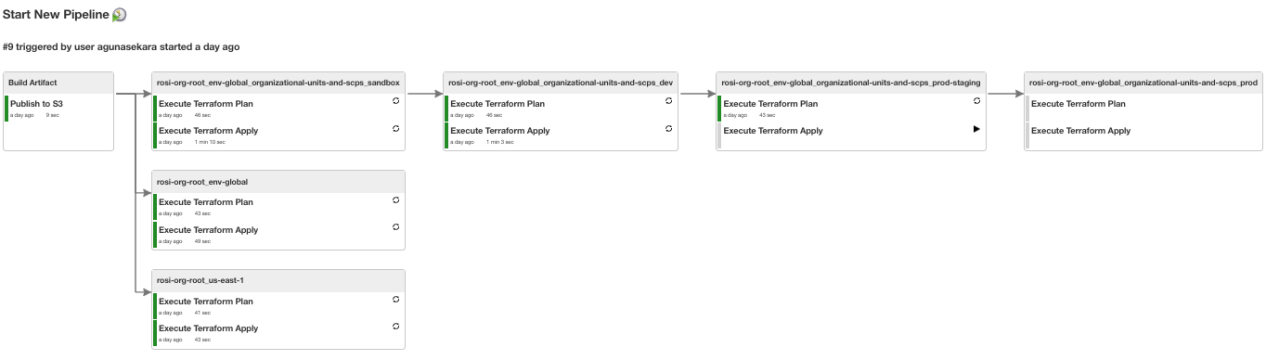
▍ Как мы тестируем изменения в Terraform?

Как уже говорилось, каждый файл состояния имеет в своём конвейере стадию планирования, которая должна быть успешно пройдена, прежде чем можно будет перейти к стадии применения. Однако для этого изменения уже должны быть внесены в мастер-ветку репозитория Terraform. Но к сожалению, в случае неудачных изменений конвейер даст сбой и будет заблокирован. Кроме того, если внести такие провальные изменения в широко используемый модуль, то под удар могут попасть несколько файлов состояния.
Чтобы это исправить, мы ввели инструмент под названием Terraform Smart Planner, который можно применять при внесении изменений в репозиторий. Он находит все файловые состояния, на которые влияет внесённое изменение, запускает планирование для каждого и выдаёт результат в пул-реквесте. Аналогичным образом Terraform Smart Planner работает и при обновлении модуля. Однако он попросит пользователя открепить все модули, закреплённые с использованием каталога, о чём мы говорили выше, если в этих модулях были произведены изменения.

Получение этого вывода в теле пул-реквеста невероятно помогает ревьюерам, поскольку они видят, на какие ресурсы влияет конкретное изменение. Это также помогает обнаруживать все косвенно подверженные такому влиянию файлы состояния и все изменения ресурсов в них. Благодаря этому, мы можем уверенно подтверждать пул-реквест или требовать внесения дополнительных изменений.
Кроме того, мы выполняем аналогичную проверку CI для каждого пул-реквеста и блокируем слияния со всеми компонентами, где планирование Terraform нарушено.
▍ Напоследок

Модель нашего использования Terraform далека от идеала, и здесь для улучшения пользовательского опыта можно внести ещё множество улучшений. Команда Cloud Foundations тесно сотрудничает с командами сервисов в Slack, собирая обратную связь и внося доработки в процессы и инструменты, управляющие нашей инфраструктурой. Мы также создали собственных провайдеров Terraform для управления своими уникальными сервисами, попутно сделав вклад в аналогичные опенсорсные решения. Сейчас в этом направлении проделывается очень много увлекательной работы, и если вам интересно принять в ней участие, обратите внимание на нашу страницу с вакансиями.

VitalySh
Общаться с копипастой дело малопродуктивное, но честно скажу, что вся статья звучит как жуткий набор костылей, в стиле - мы превозмогали как могли. Что мешает делать как тот же Яндекс? Сделали хороший инструмент для себя - выложили в опенсорс, все рады. Что же является итогом этой статьи? Мы поженили ужа с ежом.
Есть такие инструменты как terragrunt, pulumi, crossplane, а также множество других замечательных GitOps инструментов. Прочтите историю слака как страшную сказку на ночь и забудьте.
OkGoLove
Тот же terragrunt решает часть проблем, но добавляет ворох новых. И не всегда эти новые проблемы сколько-либо решаемы, в отличие от проблем ванильного терраформа.