

Вечером пятницы 23 сентября, в самое «горячее» время для Додо Пиццы, развалилась платформа Dodo IS. Приём заказов превратился в тыкву, клиенты и пиццерии 4 часа испытывали проблемы. Это было наше самое крупное падение с 2018-го года как в техническом плане, так и по недополученной выручке.
Особенная боль — то, что мы упали в прайм-тайм. Наш бизнес устроен циклично и зависит от сезона: осенью заказов больше, чем летом, а по вечерам пятницы больше в несколько раз, чем утром вторника, обычно пик заказов приходится на вечер пятницы (с 16 до 20 по Москве). Это время — самое напряжённое для системы и самое ценное для бизнеса.
У Dodo IS произошёл каскадный сбой и мы долго не могли реанимировать систему. Описываем наш путь во время этого инцидента:
Накинем ресурсов и все полетит?
Рассылка от маркетинга пушей в самый пик — может, дело в этом?
Наверняка это DDoS.
Или плохой релиз, вышедший недавно?
Короче, это что-то с базой.
В этой статье делимся постмортемом: разберём причины, опишем действия по устранению и расскажем о планах, которые позволят избежать таких падений в будущем.
Хронология событий и гипотезы
Первые алерты: ничего критичного, просто растёт нагрузка
Это была обычная пятница. Заказы принимались, алертов, которые говорили бы о сбоях системы, не было. В 16-52 прилетел алерт от MySQL о том, что много активных тредов.

График поступающих заказов — это важный индикатор реальной работы системы. Если заказы совсем перестают поступать, т.е. падают в 0 по какому-то источнику, то для пользователя это выглядит по-разному: может не открываться приложение, заказ может добавляться в корзину, но не приниматься. Т.е. не проходит ключевой сценарий — заказать пиццу не получается.
В 16-59 — алерт с бэкенда мобильного приложения, летят ошибки.

Но система продолжала работать, заказы шли. Инцидент открыли только в 17:07.
Когда команда подключилась к разбору, заказы из всех источников поступали, хоть и валились ошибки при работе бэкенда мобильного приложения (mapi — от mobile api) с базой для хранения корзин и сессий (база на CosmosDB). Нагрузка на систему продолжала нарастать, близился вечерний пик заказов.
Каких-то явных отклонений мы не увидели и решили, что это естественный рост по нагрузке — мы упёрлись в лимиты базы (MySQL и CosmosDB).

Так выглядит архитектура заказа. Есть 3 источника заказа: касса ресторана, мобильное приложение и сайт. Все они проходят через Legacy Facade (LF), а потом попадают в базу монолита. Касса частично берёт данные прямо из базы монолита.
Mapi и site (dodopizza.ru и сайты других стран) имеют своё хранилище, в основном это CosmosDB (или MongоDB, в зависимости от конфигурации) для хранения драфта корзин или предрасчётов, нужных на клиенте.
LF (Legacy Facade) — специально сделанный сервис, который выдаёт данные по http из базы. В нём есть части логики, которая когда-то была на слое репозиториев и сервисов доступов к данным в монолите. LF мы создали 5 лет назад, когда делали новый сайт и мобильное приложение, чтобы вести независимую разработку на клиентах. Логику приёма заказа, расчёта заказа, формирования меню, выдачи данных по клиенту, проверки промокодов зашили в LF.
Первая и основная гипотеза: не хватает ресурсов, надо добавить
Если трафик вырос, то не так важно, из-за чего именно: надо накинуть чуть больше ресурсов в разные части цепочки принятия заказа и всё полетит.
В 17:15 начинаем скейлить:
поднимаем поды (считай количество инстансов приложения в Kubernetes) для Кассы с 3 до 5,
поднимаем реквест-лимиты в CosmosDB,
поднимаем поды у mapi с 4 до 8.
Но это не имеет эффекта, заказы с mapi падают в 0. Понимаем, что из всей цепочки не заскейлили БД монолита. Она у нас в нормальном режиме работает на 32 ядрах — скейлим до 64.
В 17:30 заказы по всей системе падают в 0.
Некоторое время после рестарта базы это нормально. Но когда база поднялась, то отказывает уже LF, в котором находится приём заказа от всех источников. LF кидает ошибки bulkhead rejected request: выдаёт слишком много ошибок на запросы, закрыл bulkhead и не принимает от источников заказа запросы на исполнение. Разбираемся, что делать с этим.
График заказов в минуту из всех источников показывает, что с 17:30 система не работала. Просто накинуть ресурсов было недостаточно.

Параллельно отмечаем, что была массовая рассылка пушей. Может, она тоже влияет?
Днём отдел маркетинга запустил СМС и пуш-рассылку почти на 3.5 млн клиентов.
Эти рассылки имеют ограничение на отправку — не более 200 тысяч в час, а рассылка в миллионы пушей растягивается на несколько часов и до суток, потому что клиенты находятся в различных часовых поясах. Пуши рассылают регулярно, обычно это происходит во время дневного (обеденного) пика и во время вечернего, чтобы была хорошая конверсия в клик.
Такая же по объёму рассылка последний раз была в одну из пятниц июля 2022 года, и Dodo IS выдержала. Нюанс был в том, что летом заказов меньше, чем в сентябре. И в этот раз рассылка наложилась на гораздо больший пик заказов.


В 17:42 останавливаем рассылку, но и после этого поднять систему не получается. После остановки дополнительная нагрузка от открытия пушей должна была уйти, а система подняться. Этого не произошло.
Продолжаем пытаться восстановить систему.
17:46 Из-за того что мобильное приложение перестало работать, клиенты пошли на сайт заказывать пиццу. Это не удивительно, ведь приложение само предлагает перейти на сайт. Скалируем site с 5 до 7 реплик, планируем довести до 10 реплик.

В 17:49 трафик на сайт увеличился в 3 раза, с 15 до 45 тысяч запросов. В обычный будний вечер (не пик) на сайте около 20 заказов в минуту, на мобилке — около 200. Не все пользователи мобилки уходят на сайт, а где-то четверть. Это даёт такой вклад в запросы.
Сильно возросший трафик на сайте вынуждает нас продолжать увеличивать количество реплик по цепочке, в том числе для LF.
Третья гипотеза: нас жёстко DDoS-ят
Но трафик на систему всё равно достаточно большой, даже для вечернего времени. Предполагаем, что идёт DDOS-атака, которую мы не можем отразить и которую не можем заметить. Если бы это была DDOS-атака, то фродовый трафик можно было бы порезать. И ещё снизить в этот момент нагрузку. Может быть, система бы поднялась. А пока мы достоверно не задетектили атаку, трафик может быть нашим собственным.
Количество запросов после 17:25 возрастает c 11 до 40-50 тысяч.

В 18:41 эта гипотеза как будто подтверждается: отражена атака на сайт в размере 2.7 млн запросов при норме 11000 запросов.


Но ни до, ни после этой подтверждённой атаки нам не удалось найти следов каких-либо других атак. К тому же атака была на сайт, а повышенный трафик в основном шёл на mapi. Уже после инцидента мы детально разбирали трафик, смотрели самостоятельно запросы. На mapi нелегитимного трафика не было, а на сайте он был и был отражён.
Во время всего инцидента мы не исключаем версию атаки. Периодически к ней возвращаемся. Это оттягивает силы и внимание от действий по другим направлениям.
Параллельно со всем этим мы пытались восстановить систему разными действиями и получить больше данных
На втором часу сбоя имеем:
Ресурсов накидали, не помогло.
Пуши стопнули, не помогло.
Предположили DDOS, но никаких подтверждений нет.
Dodo IS лежит.
Видимо, надо копать глубже и точечно настраивать части системы, чтобы её поднять.
В 18:19 снимаем трейс с LF, изучаем. Пробуем понять, что не позволяет системе подняться.
В 18:24 выставляем настройки Bulkhead в LF до 1000/100 (BulkheadConcurrency/BulkheadQueue).
Было:
<!-- BulkHead lf-->
<add key="BulkheadConcurrency" value="150" />
<add key="BulkheadQueue" value="20" />Стало:
<!-- BulkHead lf-->
<add key="BulkheadConcurrency" value="1000" />
<add key="BulkheadQueue" value="100" />В 18:24 рестартуем LF.
Идея была в том, чтобы разжать LF, позволив ему подняться, принять в себя все запросы.
Конечно, зажата пропускная способность была не просто так. Это нормальное ограничение, чтобы не пропускать в базу много трафика и не положить её. Положить базу — значит, положить все источники приёма заказа и часть других сервисов.
Также разжатием мы хотели увидеть новую информацию, новые данные.
База данных, к которой обращался LF, к тому времени была на 64 ядрах при нормальной работе в пики на 32-х. Загрузка по CPU у неё была около 17%. Это значит, что даже увеличив количество параллельных коннектов в базу, мы бы её не положили (при разжатии балкхэдов был расчёт, что увеличенная база выдержит).
В 18:32 ушли warnings от LF bulkhead rejected request.
В 18:34 появились заказы на кассе.

Нам показалось, что вот сейчас всё полетит, раз уж касса ресторана принимает заказы.
Но на самом деле касса ресторана принимает заказы только при выключенном сайте и мобильном приложении. Значит, проблема не решена. Когда включаем сайт и mapi (это видно по графику дальше), то всё опять ложится.
C 19:05 в логах LF много ошибок:
System.OperationCanceledException: Query execution was interrupted
System.OperationCanceledException: The operation was canceled.
-
Основные URL
/MasterDataManagement/v2/GetMenu
Статистика:

По крайней мере, мы подсветили запросы, из-за которых не проходит флоу приёма заказа.
Основной из них — запрос на получение меню GetMenu.
При этом система не выдерживает, когда включаются все источники приёма заказа.
В 19:05 — количество SlowLog запросов выросло:
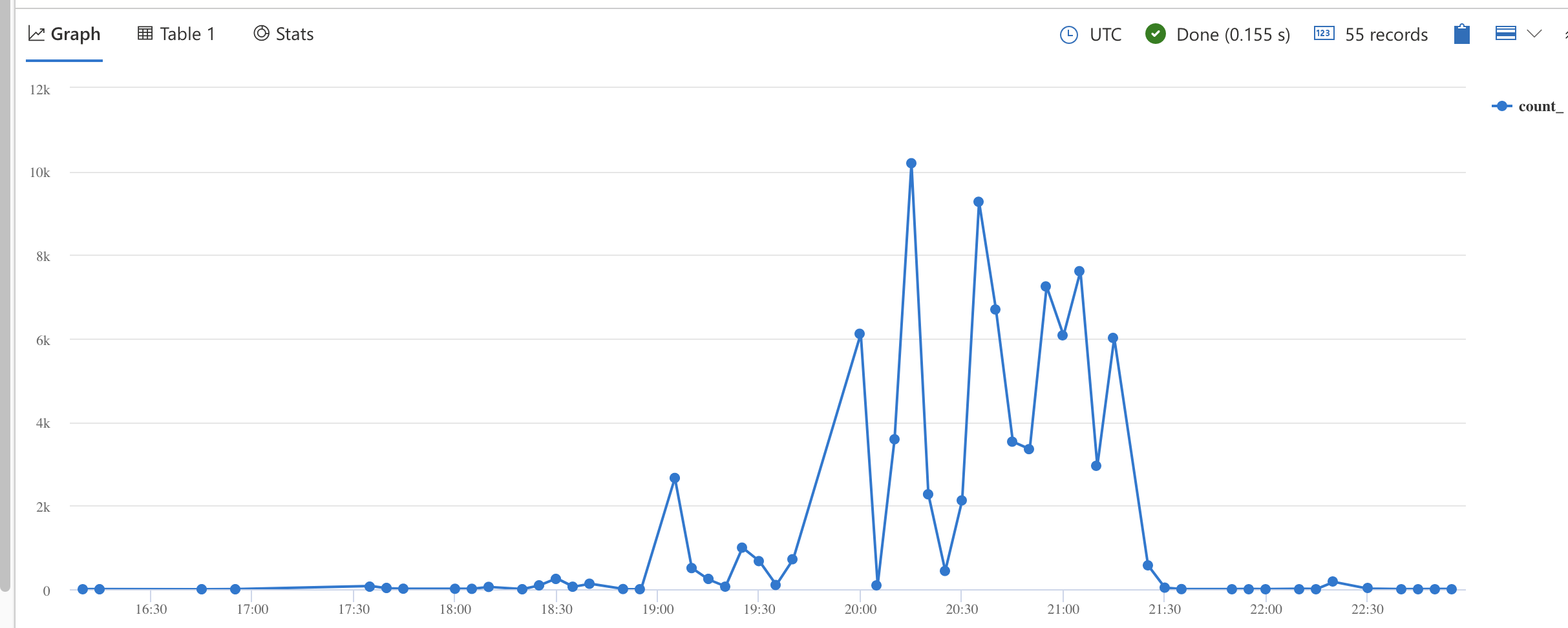
Сам запрос выглядел так
let _start_utc = datetime('2022-09-23T13:00:00Z');
let _end_utc = datetime('2022-09-23T20:00:00Z');
let _msk_start = datetime_add('hour', 3, _start_utc);
let _msk_end = datetime_add('hour', 3, _end_utc);
SreMysqlSlowLogs(MONOLITH_RU_DB, _start_utc, _end_utc)
| extend TimestampMsk=datetime_add('hour', 3, Timestamp)
| summarize count() by bin(TimestampMsk, 5m)
| render timechartПонятно, что с разжатыми балкхэдами база не выдерживает, идут ошибки. Когда балкхэды разжимали, была слабая надежда, но она не оправдалась.

В 19:19 по совету @georgepolevoy применяем Bulkhead Policy в LF , чтобы уменьшить количество принимаемых запросов к API, тем самым снизить нагрузку на БД. Для ускорения процесса решили поправить прямо в Kubernetes в Secrets configs-legacyfacade. Но поломали конфиги (там нужно было конвертировать в base64).
В 19:27 замечаем, что сегодня нагрузка на БД чуть больше обычного.

Примерно в 19:38 видим, что на базе много тредов.

19:48 — зависшие запросы к БД.

Это запрос на метапродукты (т.е. например, есть продукт Кофе американо, а у него есть объём 0,2, 0,3 и 0,4 л) и топпинги (дополнительные ингредиенты) в меню. Да, это связано с вызовом метода GetMenu, который мы видели выше, когда разжали балкхэды.
В обычной жизни запросы к топпингам выполняются за 0.05 секунды, а на инциденте — более 10 секунд. Позже мы исследовали этот запрос и никакой неоптимальности на уровне SQL в нём не было. Этого запроса просто было слишком много и он не успевал обрабатываться. В качестве митигации думаем про изменение настройки thread_handling БД c one-thread-per-connection на pool-of-threads.
Появилось предположение, что нам немного не хватает перформанса базы, чтобы прожевать все нужные запросы. К тому же, запросы идут в базу в много потоков.
В
20:24выставили настройку thread_handling pool-of-threads и перезапустили БД.В 20:27 БД перезапустилась.
В
20:28БД по CPU высокое и не спадает. До этого CPU было небольшое, а теперь опять выросло. Грузим все 64 ядра мощной базы.

В итоге изменение свойств базы с обработкой коннектов нам не помогло.
На 21:00 вся система была в разваленном состоянии. Сайт, мобильное приложение и касса ресторана не принимают заказы уже 2,5 часа.
На этот момент понятно, что в базу идёт большое количество запросов, и они связаны с меню. При этом ни большое, ни малое количество реплик веб-сервисов не позволяет системе нормально работать.
Четвёртая гипотеза: может, это плохой релиз?
Вернёмся чуть назад во времени. В 19:22 у собравшихся появляется идея посмотреть, что же выходило в этот день на продакшен из обновлений. Может, мы найдём в них какую-то зацепку, которая поможет починить всё. Смотрим на последний релиз монолита. Монолит делает запросы к базе монолита, в монолите находится LF, а значит, что-то могло повлиять на них.
Релиз был раскатан в 11:01 23 сентября и весь день проработал нормально. Обычно перформансные проблемы в релизе проявляются достаточно быстро.
Но этот релиз был раскатан в пятницу утром (в пятницу после 15 мы ничего не катим), и пока у него не было ни одного проработанного вечера. Этот вечер был первым.
Пошли изучать код релиза. В релизе было 15 задач, поэтому детальное изучение занимает время.
В 19:25 запускаем откат монолита России на 928 релиз.
В 19:27 релиз монолита падает по причине того, что под Migrator не сумел выполнить запрос к базе из-за того, что она нагружена.
Мигратор — это встроенный в релиз механизм обновления данных или схемы базы. Он используется для небольших изменений в базе, когда надо создать новую таблицу или обновить данные до 100К записей. Для больших изменений мы используем обновление базы вне релиза.
Тут происходит фатальная ошибка: вместо того, чтобы попробовать накатить релиз без мигратора, мы оставляем идею просто обновить систему и идём отрабатывать другие версии, а также изучать код всех 15 задач в поставке.
Возможно, откати мы тогда, все могло бы быть иначе.
После первой и единственной попытки откатить релиз отрабатываем версии с балкхэдами, точечными запросами в меню на базе и прочие.
В 21:18 всё таки решаем откатить на 928 релиз. Это тот релиз, который пристально изучали и в котором ничего не нашли и тот, на который мы ещё час назад попробовали откатить, но из-за мигратора не получилось. Фактически это уже был жест отчаяния: что бы мы ни делали, восстановить работу системы не выходило.
Релиз откатился примерно в 21:20.
21:26По заказам пока лучше не стало. Нагрузка на БД по CPU спала, хотя по заказам лучше не стало.21:30Пошли заказы по mapi с растущим трендом.

Всё поднялось. Невероятно. Но что это было? Почему? Может, дело в релизе?
И во время инцидента, и после ничего плохого в коде релиза не нашли. Уже после инцидента гипотеза, что были проблемы в релизе была основной для изучения. Мы на неделю остановили поставки новых версий, изучали вдоль и поперёк, но ничего негативного в релизе не обнаружили. В конце первой недели после сбоя накатили тот же релиз, что был в момент сбоя. Он работал хорошо.
Анализ инцидента
Частью описания постмортема является анализ инцидента. Мы его делаем, отвечая на несколько вопросов:
Что навредило. Что мы делали на инциденте, что нам не помогало. Это лишние или ошибочные действия.
Скорее всего, скейл базы с 32 до 64-х ядер только ухудшил положение дел. После скейла очистился кеш БД и это привело к дальнейшему каскадному сбою.
Удвоение количества подов mapi, сайта было лишним и только создавало нагрузку на дальнейшие сервисы (LF), увеличение количества подов LF увеличило на базу и привело к каскадному сбою.
Мы полностью отводили трафик от mapi и сайта для всех стран (меняли selector в k8s service), а правильнее было бы отводить трафик от Ingress до сервиса для конкретной страны. Это влияло на другие страны. Плюс шел трафик на инстанс mapi из других стран, а это усложняло разбор.
Полный возврат трафика на mapi и сайт в час пик. Как только мы включали эти сервисы — система падала.
Чего нам не хватало на инциденте. Этот вопрос помогает уже сформировать список задач на будущее.
Не хватает экспертизы, чтобы смотреть метрики MySQL. У нас есть ранбук, но его никто не отрабатывал на реальных кейсах.
Не сразу нашли ответственного, чтобы отключить маркетинговую рассылку пушей, не хватило актуальной схемы с зонами ответственности.
В
SHOW FULL PROCESSLISTне хватает информации, с какого приложения идут запросы. Например, по имени пользователя. Везде только read_user и write_user. Нет 100% уверенности, какой именно компонент грузит БД, приходится искать по коду Dodo IS. Сначала эти пользователи использовались в монолите, где тоже невозможно разделить, какие части сервисов какие запросы делают. Но потом другие сервисы тоже стали использовать тех же пользователей.Не хватает информации, сколько каждый сервис может держать RPS. Это бы помогло в расчёте, сколько можно добавить реплик приложения, сколько нужно добавить реплик LF.
Нет процесса по плановому мониторингу метрик в PMM о состоянии MySql-инстансов БД. Мы могли бы заранее увидеть проблемы с cache и с другими настройками. Нужны дополнительные алерты.
Не хватает поэтапного заведения трафика на приложения (1, 10, 50, 100%), чтобы кеши всех нижележащих сервисов успели прогрузиться.
Что пошло не так. Здесь больше случайные факторы или оставшиеся нюансы.
Перестал работать мониторинг. Увеличение количества реплик приложений повлияло на количество собираемых метрик нашей системой мониторинга, из-за чего ей перестало хватать оперативной памяти, приложения мониторинга были остановлены по OOM (OutOfMemory) и в дальнейшем не смогли запуститься. Нагрузку давала также Grafana, так как все стали её активно использовать при расследовании инцидента.
Не запустился innotop из пакета MySQL Swissknife(это наш внутренний инструмент для доступа к базам). Выдавало ошибку при работе с VPN.
Для запуска innotop на bastion-сервере пришлось отключить SSL на БД монолита.
База данных «ушла в пике» и почему-то выполняла простейшие запросы по 10-15 секунд, что не позволяло прогреть кеши в LF и начать нормальную работу.
Не скалировался нодпул для нод с Прометеем при указании 32 нод, а при указании 30 нод всё заработало. Причины: 32(nodes)*128(max pods per node) = 4096 адресов, а у нас subnet с /20 маской, всего на 4096 адресов, поэтому система не дала создать такой пул.
Не раскатился предыдущий релиз с первого раза. Следовало завершить откат релиза, а не бросать его при получении ошибки от мигратора.
Отвлеклись на атаку на сайт.
Скопилась очередь SMS, текущее количество подов communications не справлялось с рассылкой. При этом большинство СМС уже не стоило отправлять, так как срок их действия истёк.
Отвлекались на анализ атаки через SMS.
Какие действия помогли решить инцидент
Отключение сайтов и mapi убрало нагрузку на БД и позволило продолжить принимать заказы через кассу ресторана.
Откат релиза поздно вечером, когда трафик уже был невысокий, перезапустил систему и позволил ей запуститься.
Подробная хронология и анализ действий позволяет найти первопричину и исправить её.
Самая глубокая причина, до которой удалось докопаться
В базе данных с заказами России был неверно сконфигурирован кеш по работе с таблицами.
, а потом резко увеличилось количество открытых дескрипторов (перестали влезать в кеш). Сначала увеличилось количество тредов(16:40), потом пошли первые алерты(16:52).")
Массовая рассылка пуш-уведомлений для мобильных приложений вызвала нагрузку на mapi, которое в свою очередь нагрузило LF, который увеличил количество запросов к БД.
При этом в БД перестали попадать в кеш файловых дескрипторов таблиц, это увеличило количество тредов в Idle состоянии. Mapi при этом перестало работать, из-за недостаточного количества реплик на них была 100% нагрузка на CPU.
В попытке вернуть mapi в работоспособное состояние мы удвоили количество реплик приложения, тем самым вызвали срабатывание Bulkhead-механизма в LF (он сразу отклонял часть поступающих запросов), а также ещё сильнее нагружали БД, что привело к каскадным сбоям по всей системе.
Подробно про файловые дескрипторы в MySQL
Дело в том, что таблицы в MySQL представлены в виде файлов. Для доступа к файлам используются файловые дескрипторы операционной системы. В целях оптимизации, MySql создаёт кеш дескрипторов до таблиц. Если кеш заполнен и в нём нет нужного дескриптора, то:
удаляются неиспользуемые дескрипторы, в первую очередь те, которые использовались реже всего;
если удалять нечего, то создается новый дескриптор, кеш временно увеличивается, как только таблица становится не нужна, то дескриптор удаляется из кеша. Операция по получению дескриптора может быть долгой. Воспроизвести поведение не удалось.
Настройки кеша у БД были такие:
max_connections = 5000
table_open_cache = 2000
-
open_files_limit = 27098
-
максимум из
10 + max_connections + (table_open_cache * 2)+2048 (for Windows)max_connections * 5
-
Effective value — реальный размер кеша вычисляется по формуле MAX((open_files_limit – 10 – max_connections) / 2, 400) = MAX(11044, 400) = 11044 дескрипторов.
В минуту приходит около 6000 select запросов, в секунду — 100 запросов. Если в каждом из них в среднем по 5 JOIN, то будут открыты 500 дескрипторов. При этом, если запросы будут выполняться 2 секунды, то вновь пришедшие запросы не смогут воспользоваться кешом и будут ходить мимо него, ожидая открытия нового файлового дескриптора, замедляя свое выполнение и увеличивая количество Idle threads.
Документация:
Решения
Быстрые временные решения
Стоп на время фича-разработки в части Приём заказа. Субботник по стабильности.
Ограничение рассылки пушей. По мере исправления и выполнения задач, мы разрешали пускать все больше пушей.
Долгосрочные системные решения:
-
Поменять настройки кеша файловых дескрипторов в базе. Улучшить работу базы.
Увеличить значение настройки table_open_cache с 2000 до 40000.
Узнать про innodb_log_file_size (сейчас 512 МБ, а нужно 3 Гб).
Innotop должен работать локально из-под VPN с SSL подключением до MySQL.
Сделать innodb-buffer-pool-load-at-startup.
Настроить процесс мониторинга метрик MySql БД монолита России и стран.
Исследовать SlowLog на предмет Full Scan запросов при рестарте LF.
Актуализировать ранбук «Большое количество тредов на БД».
-
Переработать систему нагрузочного тестирования. Мы должны были отлавливать узкие места и проблемы заранее, а не на продакшен-среде.
Переработать сценарии. Надо добиться точности соответствия нагрузке на базу монолита.
Актуализировать профиль нагрузки с продовыми показателями. Сценарий нагрузки с рассылкой и открытием пуш-уведомлений был некорректным. Более года назад у нас были сценарии проверки открытия пуша на нагрузке. Но тогда рассылки были небольшие и сценарий был не критичным. Сейчас же количество рассылки выросло в несколько раз и вклад этого сценария стал больше. Это не учитывали в профиле нагрузки.
Актуализировать инфраструктуру ld и prod окружений.
Сделать возможность запуска нагрузки на разных стендах (сейчас все только на одном). Этим мы уберём узкое место в тестировании. Из-за этого узкого места мы не можем проверять достаточно сценариев.
Усилить состав инженеров по нагрузке.Наймем больше перфоманс инженеров, подключим разработчиков.
-
Увеличить способность системы выдерживать нагрузки. Все концы сходятся в нескольких точках отказа. Каждый домен вносит свой запутанный вклад в нагрузку LF и базы.
Оптимизировать выдачу меню. Источники заказа (сайт, mapi, касса) ходят за меню в LF, там оно кешируется, а при протухании кеша строится заново из базы монолита. Протухание кеша может быть из-за рестарта подов, потому что кеш в памяти.
Вынести расчёт заказа из монолита в отдельный сервис.
Оптимизировать открытие приложения после клика на пуш.
-
Улучшения в текущих сервисах
Актуализировать настройки Bulkhead для LF
Не отправлять пользователей из мобильного приложения на сайт, если он не доступен
Научиться поэтапно открывать трафик до сервисов mapi и сайта
Настроить HPA для mapi, сайта и LF
Добавить startup пробы для LF, для прогрева кешей
Механизм по отведению трафика сайта и mapi от LF
Проверить работу reaction. Назначил не того IC
Инструментировать все кеши метриками и трейсами system.diagnostics
-
Улучшить мониторинг и инструкции при работе со сбоями.
Мониторинг не выдерживал такого количества участников инцидента (в пике на созвоне было более 20 человек). В середине инцидента мы потеряли метрики, их пришлось руками восстанавливать. Надо переходить с Prometheus на VictoriaMetrics.
Текущие изменения в получении меню
Меню — ключевой объект для приёма заказа. В нём сочетается много данных:
список продаваемых товаров — для каждой пиццерии он несколько свой;
описание продукта, карточка продукта. Есть особые карточки по особым дням, например, новогодняя пицца с бужениной и клюквенным соусом;
сложные продукты (метапродукты) сочетают в одной карточке несколько товаров. Открывая Кофе, мы видим Кофе с объёмом 0,2, 0,3, 0,4 л;
цены плюс персональные цены для некоторых пользователей;
сама структура меню включает разные категории: пицца, комбо, закуски и т.д.;
«стопы», т.е. какой-то продукт может закончится в пиццерии и будет поставлен в стоп продаж. В меню такой продукт отображается как не продающийся в данный момент.
Примеры меню:
Вся эта сборка происходит в момент запроса GetMenu. Конечно, кешируется на всех уровнях всё, что возможно. Но всё равно цепочка запросов последовательная, в случае каскадного сбоя (который и был у нас) загрузка достаточно тяжелая: клиентская часть приёма заказа(iOS, Android, касса) + кеши → mapi + его база + кеши → LF + кеши → база данных и её кеши.
При такой архитектуре основная работа происходит при запросе, количество которых может резко возрасти. Например, когда происходит рассылка пушей. Система может хорошо работать, когда разогрета, но холодный старт, загрузка всех кешей — узкое место.

Нам надо изменить архитектуру. Нужен сервис, который бы заранее строил готовое меню, выкладывал бы его в JSON как статический контент, а дальше источники приёма заказа уже получали бы меню как файл. Тогда мы бы не зависели от кешей, тяжелые операции построения меню были бы отделены от критических операций получения меню.
Работа такого сервиса:

RMQ — шина, по которой должны распространяться события об изменении продукта, структуры меню, цен, карточки продукта и т.д.
DMS — библиотека, которая обрабатывает события в Consumers, учитывает данные? уже хранящиеся в сервисе, обогащает их текущими пришедшими через события. На выходе получается DataWindow – витрина данных.
RegisterBuilder делает итоговый JSON, помещая его в Storage, это blob.
Или тот же путь подготовки данных, только верхнеуровнево:

DataCatalog — сервис справочников. Он порождает события изменения меню, цен и все остальные.
MenuService — наш сервис, который готовит меню. Он же ещё и порождает событие MenuChangedEvent, которое mapi/site/касса могут использовать для отслеживания каких-то изменений.
menu.json — собранная версия меню для конкретной пиццерии. В нём не содержатся персонализированные цены, они получаются отдельным обогащением, но без них уже можно взять это JSON и построить на клиенте по нему меню по точке продаж.
Таким образом, работа по созданию меню перекладывается из цикла запроса пользователя в асинхронный режим. Когда пользователь открывает мобильное приложение после прилёта маркетингового пуша, mapi надо только сходить в blob storage и скачать там JSON. Можно JSONи закешировать у себя, а инвалидировать кеш по событию menuChangedEvent. В любом случае, выдача меню не будет включать в себя построение его на лету.
Все это уже делалось и до сбоя 23 сентября, просто не успело полностью выйти. Мы форсировали работы по раскатке.

23 сентября 2022 года произошло самое крупное и долгое падение системы с 2018 года. Быстро разобраться и восстановить систему не получилось, поэтому нам пришлось приостановить разработку фич и сосредоточиться на поиске и исправлении глубинных причин.
В итоге мы оптимизировали меню, перерабатываем сценарии нагрузочного тестирования, улучшаем мониторинг и много еще чего.
Одной проблемы не было. Был комплекс проблем. Именно поэтому они все сыграли в некоторой синергии и дали такой эффект. В сложных системах нет одной первопричины(см How Complex System Failed).
Подробный анализ помогает нам разобраться в причинах и пофиксить всё, что может вызвать подобные падения в будущем. Надеюсь, это было интересно и полезно для вас.
Полезные ссылки:
Шаблон постмортема Dodo Engineering.
Комментарии (83)

mishamota
16.01.2023 09:59+15Да уж... Который раз убеждаюсь: совместить в одной СУБД бизнес-критикал функционал (заказы) и всякий маркетинг (пуши) - путь к факапу.
Имхо, упомянутые "витрины данных" - правильное направление.
MRD000
16.01.2023 13:11+1С одной стороны, возможно. С другой стороны, в теории это мелкий процент нагрузки должен быть.
В mysql (не знаю сильно про другие) очень важно работать с индексами. Просто поиск по данным очень долгий (хотя та же Aurora более оптимизирована, например). В данной статье как раз то, что система работает на кэше, как раз и подсказывает, что возможно проблема в этом. В моей практике программисты очень редко попадают в индексы в mysql, потому что там попать далеко не всегда просто, ошибки не прощаются :)

vaital3000
16.01.2023 13:15+4Проблема еще в том, что пуши конвертируются в открытие приложения, загрузку меню, а в итоге возможно и в совершение заказа..

mixsture
16.01.2023 17:25+10А по-другому и быть не может. Это следует из классов OLAP и OLTP систем. У них почти противоположное развитие, они всегда мешают друг другу и из-за этого очень плохо смешиваются.
OLAP система (в вашем варианте «маркетинг») — оперирующая выборкой больших объемов данных с агрегацией. Основными оптимизационными шагами тут служат либо докидывание индексов на все эти агреграции, либо хранение предрассчитанных данных.
А «заказы» из вашего варианта — это OLTP система — для них требуется быстро проводить операции записи и очень простого чтения (поиск по ключу в таблице как правило). А для оптимизации тут часто применяют партиционирование (мол, только какая-то последняя часть из таблицы нужна, а в остальные куски почти никогда не залезаем).
Все оптимизационные шаги для OLAP ухудшают OLTP составляющую и наоборот.
Поэтому хорошим подходом является разделение этих 2х систем — у каждой своя СУБД. Одно только это разделение разнохарактерной нагрузки уже хорошо проявляется на системе, т.к. каждая СУБД подстраивается под свой характер нагрузки.

Thomas_Hanniball
16.01.2023 10:09+191. С момента инцидента прошло 4 месяца. Как-то долго писался этот постмортем.
2. Прочитал всю статью и понял, что у вас в команде нет DBA. Если бы он был, то большая часть проблем бы не возникла.
3. Перешёл на сайт dodo.dev. Там в jobs есть вакансия SRE DBA. Типа актуальная, но при переходе по ней редиректит на dodobrands.huntflow.io/vacancy/sre-dba-1, где указано, что вакансия уже в архиве. Судя по всему, SRE DBA уже наняли.
4. Проблема с архитектурой, т.к. единой точкой отказа является монолитная база данных Mysql. В разделе Решения не нашёл ничего, чтобы касалось разбиения этой базы не несколько более мелких, чтобы в случае проблем, ложился лишь 1 канал продаж, а не все сразу.
5. Статья интересная, было приятно прочитать про внутреннюю «кухню» компании.
pritchin Автор
16.01.2023 10:26+7Сам постмортем мы писали около 3х недель. 1 неделя после сбоя ушла на отработку гипотезы с "косячным" релизом, потом подбивали детали, еще гоняли нагрузку, определили проблемы с кэшом в базе. Долго переносил в статью.
Ога, DBA нет. Тоже проблема. Я не написал, но мы в конце года как раз нашли именно DBA себе.
Закрыли в конце декабря,
Не написал тоже(слишком длинно выходило уже), но все верно. Например, в единой монолитной базе находятся промоакции и хранение додокоинов(программа лояльности), находятся данные о зонах доставки. Мы это сейчас выносим, но результаты будут позже. Уверен, ребята напишут об этом отдельно.

passing1by
16.01.2023 17:42+1а не проще заодно ещё бд сменить? хотя бы на tidb и clickhouse? разнести функционал и жить спокойно? dba поможет облегчить инциденты, синтаксис у tidb схожий с mysql, функционал поддерживается, а большие выборки по меню и тп вынести в клик.

beskaravaev
19.01.2023 00:12-1Вы ведь додокоины пилили совсем недавно? Как так вышло, что это не отдельный микросервис с отдельной базой?

oldDBA
16.01.2023 19:46+8" в команде нет DBA"
Зацепило.
Как погруженный в тему - не всегда можно предвидеть. Имея весьма нескромный опыт в кровавом энтерпрайзе и построив эшелонированную оборону от разработки до деплоя на прод, несколько раз ловил epic fail.
В качестве примера - была задача по ограничению доступной инфы на экране признаку VIP. VIP'ов было пара сотен, что на фоне миллионов клиентов даже в пределы погрешности не укладывалось. Задачку примитивная, скинули джуну, по феншую фичу даже протестировали на паре офисов и забыли до отмашки заказчиком. Через пару месяцев вместе с глобальным обновлением включили в релиз - как крыжик в настройках...
Джун, ему простительно, реализовал прекрасно: на каждый (ты вдруг VIP'ом стал внезапно) got/lost focus элемента формы проверка через select * from vip, дальше поиск по массиву уже на клиенте...
В форме, центральной, было несколько десятков закладок, пара сотен статических и, в зависимости от, еще минимум сотня динамических элементов. А в момент открытия формы, как мы потом узнали, каждый (!) элемент генерил эти 2 события. И в понедельник утром > 5 тыс. ничего не подозревающих пользователей пришли на работу. И не могли открыть форму, приложение "висело", они его срубали и открывали заново. Восточные регионы успели, а следующие часовые пояса уже нет, что внесло свои коррективы в понимание проблемы. Мы докидывали сервера приложений, которые принимались переваривать все новые сессии пользователей, а старые никуда не девались, пока не дорабатывали до конца или мы не перегружали сервак. Между БД и серверами приложений гнался немеренный траффик. К БД было подключено несколько десятков и других приложений, и там тоже началась деградация.
Тем, кто не очень в теме БД, простой select из базы в таком виде грубо: declare stmt/open cursor/fetch 200+ rows/close cursor, каждое действие это несколько пакетов, каждый фетч страница в 4Кб, умноженное на число строк в таблице - 200+ и умноженное на 2*300 раз за контрол на форме на каждого пользователя=5000 и каждую зависшую сессию - умножить еще на 2. И все это в единицу времени. "Ватага зайцев мочит льва."
Мы ddos-или собственную инфру. И самое главное, не понимали причину, поднимали новые сервера => создавали все новую нагрузку, положили сеть. Снять дампы или включить детальный мониторинг было нереально. А причину, без инструмента и исходных данных, искали, как вы понимаете, теоретически, в последних-предпоследних-предпредпоследних изменениях. Судорожные откаты к результату не приводили, управлять пользователям мы в тот момент не умели. А про крыж в настройках никто не подумал, потому что дата файла с этими настройками из репозитория (феншуй епрст!) оказалась, как можно догадаться, 2-х месячной давности.
Как DBA отвечу:
И разработка и ревью изменений БД - было. И на деве, тесте, предпроде и, частично на проде, были настроены мониторинги - кривые запросы к БД отлавливались автоматом по целому сету условий. Но на экранах радаров эту мелочь не заметили, от пары юзверей пусть даже несколько тысяч запросов, из кеша в пару тестовых записей, которые относительно нескольких сотен транзакций в секунду, не попали в top-100 ни по одному показателю.
Графики нагрузки на продуктивные БД имели историю, анализ, с указанием причин изменений ключевых показателей, объяснения динамики и "красные линии", с историчностью в несколько лет и разбирались на еженедельной основе вместе с разрабами. И с точки зрения написанного кода, и бизнес-показателей, внедрения новых фич и тп. Не говоря уже про даш-борды и алерты для группы онлайн-мониторинга 24х7.
"Можно придумать защиту от дурака, но только неизобретательного" ИТ-шная мудрость

DWM
16.01.2023 22:57-1А почему VIP-ам ограничивалась информация на экране?
Если я правильно понимаю, проверку на VIP вообще не нужно было делать, а просто принимать эту информацию с бекенда. Либо во время разработки логику конструктора изменить, чтобы обычным пользователям одна страница отправлялась, а випам чуть-чуть другая.

xDimus
17.01.2023 19:30А что за база была? В mysql даже обычный show processlist дает информацию для размышления. Если успеть его выполнить до полного зависания ).

web3_Venture
16.01.2023 11:16Не очень ясны графики статистики, тот же Order , показывает около 350 заказов в минуту , тоесть в час 350*30*2= 21000 обрабатывается 21к заказов? бредово звучит.
Хотя потом вы пишите "В обычный будний вечер (не пик) на сайте около 20 заказов в минуту, на мобилке — около 200. "
zaharus000
16.01.2023 11:59+2200+20 в "несезон" и 350 "в" -- вполне сходится, разве нет?
У додо 883 пиццерии, 21000/883 = 24 заказа в час на пике, выходит вполне реалистично


muradali
16.01.2023 12:42+3Усложнение систем идет такими темпами, что скоро настанет момент, когда понять проблему и устранить ее будет в принципе невозможно и останется только "попробовать перезагрузить виндовс" ))
MRD000
16.01.2023 12:52+4Часто вижу похожие подходы к анализу проблемы. Обычно начинается паника и идет клич от руководства найти проблему. Создается такой режим ожидания. В этом режиме нередко кто-то бросает случайную идею и на неё все разом набрасываются. Обычно никто не задает вопросов может ли эта идея реально быть причиной, стоит ли найти подтверждение вначале. Иногда я видел, что на такие идеи могло уходить до пары часов. Попробовали - не получилось. Дальше опять режим ожидания новой случайной идеи.
Самое интересное, когда в этом случае инцидент сам собой решается (например, какая-то пиковая нагрузка проходит) и образуется такая непонятность, то ли решили проблему, то ли она сама.
Причем понятно почему это происходит. Приложения (как open source, так и свои) не очень часто выдают реальную ошибку. К примеру, на любую проблему с базой данных не в режиме отладки WordPress выводит что-то похожее на "something is wrong with the database". Плюс, часто начинает сбоить все и везде и ошибки лезут с разных сторон. Нередко ошибки также спрятаны на уровне warning и т.п. Действительно, найти в этом круге сообщения об ошибках, которые являются коренной проблемой непросто.
vaital3000
16.01.2023 14:30Хорошее замечание.
Я обычно приходя на инциденты, пытаюсь смотреть туда, куда другие еще не смотрят и искать новые гипотезы... Если то, что делают другие - верный путь, они найдут решение и без меня, а если нет, есть шанс найти реальную проблему.
По поводу мониторинга, метрик у нас много, от ошибок в логах, до "Percona Monitoring and Management", которые позволяют обычно докопаться до сути, но вот такие крупные инциденты затрагивают очень много подсистем и искать причинно-следственные связи становится довольно сложно.

iamkisly
16.01.2023 14:17+13Это была обычная пятница.
У нас в МТС (да, не IT отдел) есть негласное правило не накатывать изменения на сеть в пятницу. Потому что пятница.. это пятница. Пока новые параметры будут загружены на сеть, пока пройдет несколько часов для сбора статистики, а еще нужно время для ее анализа. В итоге в лучшем случае проблема будет найдена на последних часах рабочего дня, а в худшем - в понедельник утром. Имхо в пятницу можно заняться множеством других дел, и не накатывать свежие релизы.

Telmah
16.01.2023 18:53такие правила обычно пишутся
кровьюкрасными глазами тех кто потом это чинит в пятничный вечер-субботу-воскресенье. есть даже обычно жёсткие правила о запрете установок менее чем за 2-3 часа до конца рабочего дня вне зависимости от дня недели

TimsTims
16.01.2023 20:15+1Да какая разница? Инцидент мог бы произойти и в любой другой день. Понедельник, вторник или в среду. Точно также утром бы все обвалилось. Если просто не лить в пятницу, чтобы не чинить все выходные, это значит, что всё обвалился допустим в понедельник, а чинить будут весь вторник и всю среду, когда всем надо работу работать...
Конкретно правило "не лить в пятницу" никак бы не спасло от этого инцидента.
Сегодня мы не льем в пятницу. Завтра не заливаем за 2 недели до и 2 недели после нового года. После завтра запрещено заливать в полнолуние или если Меркурий в ретрограде...

CrzyDocTI
17.01.2023 02:03+1простой пример - в пятницу разработчик запланировал отдохнуть и когда ему позвонили в 20.00 с вопросом по его функционалу - уже не отвечает.
запрет в пятницу, перед праздниками - привязан не к бизнес логике а к людям сопровождающим систему.
ПС. поднимать в понедельник-вторник гораздо веселее и продуктивнее когда команда отдохнула на выходных, чем в пятницу-субботу когда команда думает об остывшей пицце а не о работе.
TimsTims
17.01.2023 11:10-2простой пример - в пятницу разработчик запланировал отдохнуть и когда ему позвонили в 20.00 с вопросом по его функционалу - уже не отвечает.
Поменяйте пятницу на четверг. Разработчик также может будет недоступен, ничего не поменялось:
в четверг разработчик запланировал отдохнуть и когда ему позвонили в 20.00 с вопросом по его функционалу - уже не отвечает

SabMakc
17.01.2023 11:35+2Так то оно так, только 2 нюанса:
В четверг шансы на подобный отдых намного меньше. Тем более меньше ситуаций "Я уже выехал из города на все выходные. Связи нет и не будет.".
Даже если подобное случилось, разработчик будет на связи уже в пятницу (через считанные часы), а не через два дня, в понедельник.
Так что правило "не лить обновления в пятницу" достаточно популярно. Как и "не обновляться перед длинными выходными" по тем же причинам.
Хотя в данном случае оно бы не помогло, с этим я тоже полностью согласен. Хотя бы потому, что в данном случае, пятница вечер - это пик нагрузки. И не говоря уже о том, что с обновлением инцидент не связан.
TimsTims
18.01.2023 08:31Хотя в данном случае оно бы не помогло
Я именно про это и хотел сказать. Конечно деплоиться утром лучше, чем вечером. И что в будний день лучше чем в выходной. Но конкретно в этой истории из статьи, постулат "Никогда не деплоиться в пятницу" вообще как будто приплетён сюда по чистому совпадению, что у Dodo сбой произошел тоже в пятницу. If (today() == "Пятница") then DoNotDeploy();
Как мы видим в статье, сбой обнаружили ещё днём, в рабочее время, когда все были онлайн и на работе. Должны были (в теории) решить за вполне ещё рабочее время. В итоге решили на 3 часа позже конца рабочего дня.
Заменить пятницу на любой другой день недели - события бы произошли абсолютно те же самые, постулат "не деплоиться в пятницу" ничего бы не изменил. При этом я отвечал на комментарий выше, где советовалось просто "не деплоиться в пятницу", как будто это помогло бы.

Lobey
19.01.2023 00:25-2Всё так. Но выручка сети пиццерий в пятницу в разы больше выручки в другие будние дни. Случись эта неприятность во вторник - потеряли бы миллионы рублей. Но случилась она в пятницу и потери измерялись десятками миллионов.
Стоит ли изменение релизной политики этих денег? Спросите у автора.
К слову, да, во многих компаниях релизы не делаются ни по пятницам, ни в последние несколько дней перед праздниками.

mayorovp
19.01.2023 06:55+1Какая разница когда там релиз? Упало-то от нагрузки, а не от релиза. Баг мог хоть полгода ждать пока маркетологи не разошлют свои пуши в одну из пятниц...
TimsTims
19.01.2023 08:47выручка сети пиццерий в пятницу в разы больше выручки в другие будние дни. Случись эта неприятность во вторник - потеряли бы миллионы рублей. Но случилась она в пятницу и потери измерялись десятками миллионов.
Стоп. Запрет на релизы в пятницу ведь связаны с тем, что люди обычно в пятницу уходят по раньше, и никого не найти все выходные.
Или запрет на релизы по пятницам связаны всё-же с тем, что по пятницам выручка больше?
По моему, вы натягиваете одну причину нерелизов на другую, и это получается чистым совпадением. Представьте, что день максимальной выручки у них был бы по средам. И по средам нет запретов на релиз. Точно также потеряли бы десятки миллионов. И запреты на релизы по пятницам никак бы не помог.
Ещё раз: Запреты на релизы по пятницам проводятся по совершенно другим причинам, и защищает абсолютно от других причин и последствий (когда никого нет на связи, ни до кого не дозвониться, и от этого чинят все выходные). Как мы видим по статье, ни одна из этих причин не наступила - все сотрудники были на связи, и были доступны, починили в тот же день. Единственное совпадение было то, что это была тоже пятница.


Serj1979
16.01.2023 15:55+12Очень долго читал. И нашёл ответ на ваши проблемы в другой статье хабра:
https://habr.com/ru/post/709328/
Извините за обидную прямоту.
Но 64 ядра... Kubernetes...
Сайт Додо из 20 товаров. 220 заказов в МИНУТУ, Карл!
А рекламные пуши нормальные люди вообще выделяют на отдельное железо. И они не должны мешать сервисной части бизнеса.
Это не дерево изделия "Самолёт" из 5000000 запчастей, каждая из которых имеет габариты, размер, число зубьев на венце, напряжение питания и т.д. и. т.п. И такие базы крутятся на обычном i7 процессоре с 64 Гб ОЗУ. ОЗУ - характеристика для кеширования реально критическая в сервере. А сколько там ядер 64 или 564 - так забудьте про микросервисы (как написано здесь https://habr.com/ru/post/709328)!

IRS
16.01.2023 19:02+3да норм статья, я читал и смеялся. для 4 заказов в секунду 64 ядер нынче мало оказывается
mixsture
16.01.2023 15:58+8Вы делали странные вещи. Вы же очень быстро определили предполагаемый источник проблемы: много тредов в sql (вам даже алерт на это приходил) + внешний поток запросов вобщем-то обычный. Т.е. это однозначно sql. Там появился тяжелый запрос.
Соотв, круг сузился до изменения релиза (кто-то неоптимальный запрос добавил) и/или изменения самих настроек СУБД.
Скейлинг ядер для sql это как надежда на соломинку, чаще всего ведь упирается все в disk-intensive, а вовсе не в cpu-intensive (по крайней мере в моем опыте было так всегда). И манипуляции очередью и скоростью приема в нее — примерно такая же надежда — есть относительно небольшая вероятность, что запросы ожидают друг друга и sql сервер их выполнит по очереди намного хуже, чем тоже самое сделаете вы, принудительно подавая по одному.
mixsture
16.01.2023 16:08+4Нам надо изменить архитектуру. Нужен сервис, который бы заранее стоил готовое меню, выкладывал бы его в JSON как статический контент, а дальше источники приёма заказа уже получали бы меню как файл. Тогда мы бы не зависели от кешей, тяжелые операции построения меню были бы отделены от критических операций получения меню.
Но это тоже вариант кеша (как неких предрассчитанных данных, уводящих БД от нормальных форм), поэтому никуда вы не ушли. Это кеш с хранением между перезапусками и инвалидацией при записи. То, что вы хотите сделать — можно, например, в битриксе подсмотреть. Называется «управляемый кеш».
Этот подход хорошо работает, потому что число операций записи обычно на порядки меньше операций чтения. Соотв, секунда проигранная при записи вполне может давать профит в 100 секундах при чтениях. Более того, чаще всего нормирование времени на операции записи мягче, т.к. это внутренний сотрудник пишет — он может подождать +1 секунду, а вот клиент может и уйти.

pil0t
16.01.2023 17:42+2Из того что ещё можно сделать "малой кровью" - например ReadOnly реплика БД, на которую "заварачивать" часть запросов - то же получение меню, может даже большинство GET запросов.
vaital3000
16.01.2023 18:13+2У нас у монолита раньше было 3 сервера - Мастер, Read-реплика как раз для таких кейсов + AHD реплика для жирных отчетов.
Через какое то время отпилы и оптимизации довели уровень нагрузки на read-реплику упал до минимальных значений и ее убрали, завернув эти запросы в мастер.
Финально по итогам последних падений мы снова ее вернули, вероятно временно.

Mike-M
16.01.2023 18:09+3Уважаю людей и компании, которым хватает смелости признавать свои ошибки, приносить извинения, компенсировать причиненный вред, установить причины проблемы и предотвратить её появление вновь.
В длинном списке «Долгосрочные системные решения» не увидел одного из самых главных пунктов:- Периодически проверять пиковую нагрузку на проде. Как только она приблизится к нагрузке на тестовом стенде для нагрузочного тестирования, масштабировать стенд.
pritchin Автор
17.01.2023 08:55+1Да, это хорошее дополнение. Действительно, уже позже мы стали разбираться в соответсвии профиля нагрузки реальному проду и стало понятно, что актуальность там хромает. Часто что-то меняется в сценариях(как в примере с пушами), а это мы пропускаем. Надо улучшать

jenki
16.01.2023 18:20+1Описываем наш путь во время этого инцидента:
Накинем ресурсов и все полетит?
Рассылка от маркетинга пушей в самый пик — может, дело в этом?
Наверняка это DDoS.
Или плохой релиз, вышедший недавно?
Короче, это что-то с базой.У вас же мониторинг по идее должен быть настроен и не простейший на дефолтных дашбордах графаны, а что-то более серьёзное. Если у вас есть подозрение на нехватку ресурсов, система мониторинга и алертинга должна должна сообщить об этом. Если идёт атака, это можно увидеть в мониторинге. Не хватает возможностей собственного мониторинга, можете глянуть дополнительно в Azure. Короче, это в вас что-то сделано с мониторингом из рук вон плохо.
Это была обычная пятница
у собравшихся появляется идея посмотреть, что же выходило в этот день на продакшен из обновленийНу ту вы сами себе злобные буратины. Кто же в пятницу заливает измнения, тем более на прод? Это же табу! Только резервные копирование и прочая безопасная активность.
Вообще скадывается впечатление, что архитектура застряла во вемена MVP и только росла вертикальным масштабированием железных ресурсов, а мониторинг в зачаточном состоянии.
TimsTims
16.01.2023 20:26+1Кто же в пятницу заливает измнения, тем более на прод? Это же табу!
А если бы они заливали его в четверг, эффект был бы другим?
jenki
18.01.2023 15:53+1Очень немаловероятно. Некоторые в пятницу уже подустали за неделю и имеют меньший фокус внимания, у кого-то планы на вечер и они спешат сделать работу быстрее, чтобы не задерживаться, а есть те, которые всеми мыслями и одной ногой в субботе. Это тот самый человеческий фактор.
Кроме этого для пятницы характерен (не всегда и не для всех, но всё же) больший наплыв посетителей (offline or online) что вызывает большую нагрузку на сервисы. Поиск ошибки и её осправление, когда твои сервисы хорошенько нагружены занятие на самое простое. Не замечали интересную вещь? Apple релизит по вторникам.

Rast1234
16.01.2023 19:05За prometheus обидно, что ж его сразу выкидывать-то.. а про bulkheads не понятно - почему про них так много, но нет хотя бы вкратце, как они у вас используются. как глобальный лимит запросов на LF? если да, и у LF есть известный жестко заданный лимит запросов к нему, есть ли у него SLA? и у остальных сервисов, получается, заданных лимитов нет, и наверно SLA нет, потому что нагрузку не считали по-честному?


ShashkovS
16.01.2023 22:56+4Читаю, и сразу на будущее хочется прикрутить «Graceful Degradation» — возможность контролируемо срезать нагрузку. В духе «упёрлись в базу» — сразу отключили «Воронеж» (в смысле самый неэффективный по выручке на один запрос регион/ресторан+источник (источник — мобилка или сайт). Потом — следующий, и так пока поднимется.
GbrtR
17.01.2023 02:13В некоторых конторах есть «команда быстрого реагирования» — если задница случится, они имеют опыт, знания, права доступа и главное сработаны друг с другом, чтобы подобные проблемы быстро решать. Плюс тренировки по подобным сценариям. Часто это не выделенная команда, а виртуальная, но реально помогает минимизировать время реагирования.

Awake
17.01.2023 06:48+4Я, если честно, от dodo в плане инфраструктуры ожидал много большего. Одна база, которую в итоге положили довольно тривиальным образом. Никакого смысла нет в том, что настройки были неправильные. Вы всегда где-нибудь продолбаетесь с настройками, что-то случится с диском, в конце концов что-то случится с серваком. DBA тут поможет отсрочить неизбежное. Не иметь реплики базы - это вообще нечто странное в моей картине мира.
Весь продолб в изначальной архитектуре, которая спроектирована так, чтобы всё влияло на всё. Я в страшном сне представить не могу, что рассылка пушей может положить всю систему. Какого чёрта вообще? Есть же OLAP-хранилища, ну в конце концов под это можно просто отдельную базу использовать даже с базовыми настройками. Шардов на базе нет (что в случае потока заказов (а это прям TS-данные) довольно очевидное решение), ну или TSDB в конце концов. Сами же берёте неоптимальные решения, в итоге получается жёсткий непродакшн-реди.
Рад, что вы дошли до меню в json, но камон, на дворе 2023 год, этому довольно устоявшемуся решению уже лет 10. Есть сильно более эффективные возможности.
У вас упал прометеус вместе с продом - это вообще просто прекрасно. Ребят, прометеус в 10 раз больше данных прекрасно переваривает, это вы натворили там дичь полную.
И вам очень правильно насыпают. 4 заказа в секунду - и вам не хватает 64 ядер на базе? Вы блин, шутите что ль? На кого это рассчитано вообще?
Я не считаю ваш пост-мортен адекватным. Это явное сглаживание ситуации и отсутствие поиска реальных ошибок.

trublast
17.01.2023 08:19+3Часто в проектах, выросших из маленьких, а не разработанных с нуля под хайлоад, так и бывает: ресурсов на то чтобы переделать "правильно" нет, разработчики пилят для бизнеса новые фичи, которые должны приносить больше денег. Изменить архитектуру невозможно, потому что на это нет ни ресурсов ни желания - все опасаются сломать поток денег. И все серьезные сдвиги в архитектуре происходят только по итогам факапов. А пока факап не случился - бывает и сессии пользователей хранят в базе mysql, постепенно доводя муську до инстанса в 256 ядер с терабайтом ОЗУ.
Бизнес выделит ресурсы на "переделать правильно" когда почувствует, что теряет деньги.
mayorovp
17.01.2023 08:20Я в страшном сне представить не могу, что рассылка пушей может положить всю систему. Какого чёрта вообще?
Любая рекламная компания, включая пуши, способна положить систему независимо от архитектуры.

Aquahawk
17.01.2023 11:34+1Вообще нет. Очень зависит от архитектуры. Есть куча примеров когда архитектура делается правильно, с расчётом на скачкообразную нагрузку и переваривает огромные маркетинговые активности. Как вы думаете живут бизнесы которые покупают рекламу во время чемпионатов или когда запускаются массовые рекламные кампании.
mayorovp
17.01.2023 11:46Пиковые нагрузки архитектурно фиг решишь (если сложить всё в очередь и разгребать её 4 часа не вариант).
Можно сделать такую систему, которая бы хоть как-то работала при нехватке ресурсов вместо того чтобы падать полностью — но проблему в целом можно решить только достаточными ресурсами и отсутствием ошибок вроде этого ихнего GetMenu
Aquahawk
17.01.2023 12:20+1Сгладишь, ещё как. Есть куча примеров когда можно разменять throughput на latency и при нагрузке начать подтормаживать при этом кратно увеличив способность переваривать запросы. В большинстве обычных систем, чем больше нагрузка тем меньше производительность, но это не всегда так, есть варианты и наоборот. Из самого простого и на слуху это вставка в Clickhouse, когда они старгетились на throughput и при росте нагрузки можно копить данные в кеширующих стораджах и вставлять большими пачками, в итоге затраты на вставку строки упадут (https://clickhouse.com/docs/ru/introduction/performance/). И таких примеров много, сервер вставший в 100% CPU тоже на самом деле может быть более эффективен, если он написан правильно и вычитывает из каждого сокета больше данных за раз. Это уже достаточно сложные вопросы, но системы которые не деградируют под нагрузкой существуют. Это сложно, это дорого, это не всегда получается, это иногда с грохотом падает, но это бывает.
mixsture
17.01.2023 15:18Да и этот подход отлично работает везде, не только в кликхаус. Если есть много однотипных операций, то лучше их сложить в кучку и затем обработать пакетно. Потому что при обработке по одному мы по сути делаем запрос к БД в цикле, много раз переключая контекст между СУБД и приложением (получается сложность O(n log n), где «log n» привносит СУБД со своими поисками по деревьям и только в случае хорошего плана запроса, а «n» привносит цикл), а при пакетной обработке в идеале можно свести переключение контекста к 1 — т.е. одним запросом собрать из СУБД все необходимые данные (получаем сложность условно ближе к O(log n)).
Но все равно стоит учитывать, что у оптимизации потолок близко и, как правило, она производится с убывающей эффективностью — каждый следующий шаг даст все меньше прироста. А у наращивания железа почти не существует :)Aquahawk
17.01.2023 16:04По первой части согласен, но это специально организовывать надо, и кстати микросервисы тут как раз вредят, не удивлюсь если каждый микросервис будет ходить в базу и что-то запрашивать.
А по второй части как раз всё сложно, если где-то закралась нелинейные затраты на обработку клиента от их количества(всего в базе) то масштабирование не поможет в принципе. Поможет только выяснение почему это происходит и замена функционала, иногда с отказом от каких-то бизнес требований. Тогда достаточно долго можно будет переваривать значительные объёмы клиентов на скромном железе. Короче баланс нужен. Пытыться вывезти всё на одном серваке не нужно, но и десятки серваков для обработки десятка запросов в секунду тоже не нужно.
hyperm
17.01.2023 08:57+1добрый день, я может что то упустил, заранее извиняюсь, но не очень понял, если ошибка в каскадной нагрузке на бд при получении меню из за большого количества пушей, как откат к предыдущей версии помог решить эту проблему?
Aquahawk
17.01.2023 11:52+3Ребят, что-то явно не так. На таком железе надо обрабатывать ну если не тысячи запросов в секунду то сотни. Что-то где-то совсем не так. Или очень много бесполезных запросов, когда можно было сделать один, или где-то все данные денормализованы до пятой нормальной формы и в базе джоин на джоине джоином погоняет. Или индексы не там где надо, или где-то кто-то выбирает всю базу чтобы посчитать количество(случай из практики, через ORM) Очень часто академически красивые подходы и производительность радикально расходятся на практике. Если вы хотите ускориться то нужно строить полную карту того что происходит от того, как пользователь открыл приложение, до того какие запросы упали в базу. Всё, Днс, домены, https с его keep-alive, какой там сервер, куда и что он положил, через все медиаторы и балансировщики до EXPLAIN ANALYZE на базе. А вдруг у вас постоянные реконнекты к базе, или ещё какая-нибудь ересь. Во сколько потоков вы в неё идёте? И глазами смотреть, нет ли там лишнего. Именно "вдоль" процесса, а не "сбоку". Сбоку это смотреть на массу, типа через этот серевер лезет столько и таких запросов в секунду. Таким образом нельзя сложить целостную картину. "Водль" это проследить путь всех данных одного конкретного пользовательского действия типа открыл приложуху, выбрал заказ, заказал, оплатил, получил уведомления, принял заказ, оставил отзыв. Вот берёте это всё, бьёте на этапы и в ниточку выкладываете всё что произошло, путь в глубину и назад, как прошли данные. Подозреваю что собрав это в одну карту вы ооочень удивитесь сколько там всего лишнего, и какие вещи идут чудовищно неэффективно. Жопное чувство говорит, что что-то идёт сильно не так, радикально, на порядки. Вот пример https://habr.com/ru/post/580066/comments/#comment_23523460 где конечно всё проще и речь просто про более простые запросы, но человек смог осознать что те цифры к которым он привык и которые он воспринимает нормально, отличаются от нормальных на несколько порядков.
Начните думать о миллионах клиентов которые будут делать в тысячу раз больше запросов и попробуйте делать инфраструктуру из этого расчёта, быстро выяснится что просто залить железом не получится но можно придумать как справиться. Подумайте как работают онлайн игры, сколько там игровых заказов в игровых пиццериях печётся? Миллионы. И там есть и таргетинг, и все монетизационные метрики и персональные офферы, всё тоже самое, только на миллионы заказов за вечер.
vaital3000
17.01.2023 16:17+1Заказы в секунду/минуту != запросы в секунду/минуту.
Вот прямо сейчас графана говорит о 5500 запросов в секунду при 200 заказах в минуту.
Кроме получаения меню клиентами и приемом заказа, базой пользуются пиццерии, чтобы видеть эти заказы, менять их статус, списывать ингредиенты, следить за закончившимися, чтобы останавливать продажи необходимых продуктов, отправлять курьеров, и много чего еще.
В разделе про DDOS есть цифры, там говориться, что норма 11000 rpm на сайт, при том что там очень маленький процент заказов, как пример только на мобильное апи сейчас при 200 заказах в минуту около 500rps.Aquahawk
17.01.2023 16:31+15500 запросов в секунду при 200 заказах в минуту.
5500 запросов в секунду это 330 тысяч запросов в минуту при 200 заказах в минуту, т.е. 1650 запросов на заказ, ничего не смущает? Т.е. ваша инфраструктура построена так, что в целом по компании, чтобы продать одну пиццу нужно 1650 запросов. Нет, я понимаю что не все клиенты делают заказ, но это очень странно. Ну и просто запросы вида раздача статики и картинок они к вопросу отношения не имеют, у вас легла база на приёмке заказов, на очень маленькой интенсивности этих заказов для этой базы. Я хочу сказать что такое железо должно нормально переваривать 200 заказов в секунду. Может я конечно чего-то не понимаю, во выглядит оочень всё это странно.
vaital3000
17.01.2023 17:06Статика идет с cdn и не входит в эти цифры, это запросы на nginx.
И я же говорю, что на этой базе не только прием заказа. В каждой пиццерии открыты экраны менеджеров, где они смотрят метрики, заказы, двигают пиццы по трекеру, передают курьерам, Dodo IS это не только принять заказ.
Да и сам прием заказа с просчетом акций, у которых много условий и сложных триггеров может быть, которые нужно на каждое изменение корзины прогонять, тоже не просто получить меню..
Безусловно можно на этом железе сильно ускориться, но это не малые вложения в разработку, у бизнеса возникнут вопросы, если мы на полгодика перестанем выпускать новые фичи, но сократим расходы на инфру в пару раз.
Многие низковисящие фрукты мы уже собрали, каждое последующее улучшение дает меньший результат при тех же вложениях, тут уже нужно найти баланс, который всех устроит.Aquahawk
17.01.2023 19:09+1т.е. это 1650 динамических запросов которые в базу лезут или скрипты крутят? На один заказ. Да хоть коневеер из 500 стадий и это не должно столько занимать. Я понимаю кухня всё такое, курьеры. В своё время я видел как несколько лет подряд в веб версии facebook мессенджер хреначио по 2 запроса в секунду постоянно с целью проверит, а нет ли новых сообщений. Вы уже влипаете в то, что не понимаете что происходит с системой и как её оживить. Жесть. Ребят, я много чего видел, но чтобы сохранить контроль в будущем нужно на порядки снижать количество запросов. Что-то не так с организацией данных и процессов.
vaital3000
17.01.2023 19:42У нас 882 пиццерии.
В каждой открыты планшеты(Раскатка, Начинение, Печь, Упаковка, Выдача, Мотивация, Доставка).
Одна или более кассы ресторана.
Экран с метриками у менеджера смены.
У каждого курьера мобильное приложение.
Интерфейсы для проведения ревизий и заготовок.
(это кроме клиенских запросов c сайта и мобильного приложения и я еще не все перечислил)
Естественно не все запросу лезут в базу(много чего за кэшами) + это запросы в сервисы, у которых разные базы(микросервисы, все дела)mixsture
18.01.2023 16:21Есть у меня подозрение, что у вас много устройств и вы используете poll-модель — т.е. опрашиваете раз в какое-то время СУБД об изменившихся данных (считая, что любые из них могли измениться). Это может порождать очень много запросов с ростом числа устройств.
Если это так, то подумайте о push-модели. Когда каждое из устройств подписывается на изменения ровно того, что ему сейчас нужно. И только когда к нему приходят события изменения этого — тогда и переспрашивает у СУБД (а может и вообще не переспрашивать, если все полезные данные можно передать с событием).
Aquahawk
17.01.2023 19:35-1меня всё ещё не отпускает, даже если каждый слайс колбасы в пепперони списывать отдельным запросом, я не понимаю как столько получить. Или у вас конверсия в покупку с приложения 1%? Я думаю значительно значительно больше. Короче очень не понятно зачем и как можно нагенерить столько осмысленных динамических запросов.
vaital3000
17.01.2023 20:06+1А можно на эти метрики посмотреть ночью. У меня получилось 18 тысяч запросов на один заказ...
Dodo IS - это не только прием закаказа. Это автоматизация всей деятельности пиццерии, и даже если заказы не принимаются, там есть что поделать (провести ревизии, принять поставки, выгрузить данные в бухгалтерию и т.д.)Aquahawk
17.01.2023 20:33+1Я всё это понимаю, ревизии списания, бухгалтерия, уверен что и учёт сроков хранения и поставщики и всякие температуры в холодильниках, и охрана труда и рабочее время, и даже вполне возможно зарядка курьерских самокатов. Я всё это понимаю и понимал с самого начала. Это не укладывается в мою голову. Ни микросервисы, ни масштабирование никак не позволят мне уместить в голову такое количество запросов, со всем экранами в 880 пиццериях. Я понимаю что там много информационных потоков, но это не отменяет того что, по моим кожножопным ощущениям перерасход ресурсов происходит в сотни раз. Не в два раза, а в сотни. 18 тысяч запросов на один заказ это что-то за гранью моего понимания вообще, мы в каких-то разных мирах крутимся. В наши игры играют миллионы пользователей ежедневно со всего глобуса всегда, и нет, нигде никаких подобных вещей я не видел. И в большинстве этих игр это полноценная онлайн игра, это клики каждые несколько секунд, а у ботоводов и то чаще. Всё это обрабатывается, всё это анализируется, всё это работает. Там крутятся персонифицированные офферы, локализация на десятки языков, динамическая подстановка контента для разных регионов и языков, чаты, викторины, игры, да миллион всего. И да, там где надо, мы держим стейт игрока в памяти, имеем постоянный коннект и базу пинаем раз в тысячелетие. Я видел разные бизнесы, кинотеатры, вендинг, финтех с тонной графиков. Но то о чём вы говорите я понять ну никак вообще не могу.

Ghool
18.01.2023 01:08+1Вы зря привязались к количеству заказов.
Если разбить запросы на разные задачи и считать «количество запросов на задачу» - будет более адекватное число.
Это как взять современный телефон и посчитать, сколько времени мы используем относительно количества звонков в день. Получится, что на то, чтобы совершить один звонок длительностю в 5 минут у нас уходит 2-8 часов.
Просто неверный вариант подсчёта
Aquahawk
18.01.2023 11:25-1Они делают пиццу. Если бы чтобы звонить мне нужно было торчать в телефоне 2 часа я бы его выкинул. В телефоне торчат не для того чтобы звонить. Пиццерия же всё делает чтобы делать и продавать пиццу. Принимает товар чтобы делать пиццу, блюдёт сроки, чтобы делать пиццу, показывает меню чтобы продавать пиццу, принимает заказ чтобы продавать пиццу. Да это бизнес процесс, да он состоит из сотен стадий. Да он большой и сложный. И да, он выглядит несуразно избыточным, когда на то, чтобы обрабатывать несколько пицц в секунду тратится столько серверных мощностей.
Ghool
18.01.2023 18:24Я понимаю вашу логику, но она не применима к этому случаю.
Это как сказать:
«Мне нужен телефон чтобы звонить и пользоваться интернетом. Почему у него 100500 кнопочек в настройках?»
Да, было бы круто, если бы запросов было бы меньше. Но сильно меньше на самом деле не получится. Раза в 3-10 меньше - да, наверное можно. Только.. нужно ли? Что за самоцель «сделать меньше запросов». Цели другие важны: сделать пользователю удобно.
И тому, кто заказывает, и тому кто готовит, и всем остальным пользователям.
Aquahawk
17.01.2023 13:31А как так получилось что вот тут https://dodo.dev/manager#stack можно выиграть в bullshit bingo от количества новомодных технологий, сайт весь выглядит весь из себя "не как все", а в разделе вакансий https://dodo.dev/manager#jobs все кроме одной ведут на устаревшие вакансии? И список там и на huntflow отличается. Зачем кто-то вложил время, деньги и душу в этот сайт в 2021, если он застыл без поддержки и обновления?

velipre_xella
17.01.2023 16:25Релиз в пятницу - к хлопотным выходным. Вроде 100 лет уже этой народной мудрости, не?

Didimus
17.01.2023 19:5219:21 дежурная смена принимает решение остановить реактор, пиццы перестают выпекаться и медленно остывают

ashagraev
18.01.2023 01:17+1Мне кажется, основная проблема — в использовании SQL-базы (тем более, MySQL) на интерактивном трафике. Можно очень долго заниматься оптимизациями, но глобально это не изменит того факта, что SQL-базы тяжело масштабируются в целом.
Нам надо изменить архитектуру. Нужен сервис, который бы заранее строил готовое меню, выкладывал бы его в JSON как статический контент, а дальше источники приёма заказа уже получали бы меню как файл. Тогда мы бы не зависели от кешей, тяжелые операции построения меню были бы отделены от критических операций получения меню.
Это один из вариантов, но файлики — это может быть в целом не очень удобно, и с ними бывают свои приколы. Одна из стандартных архитектур в таком случае — это SQL-база, которая служит в роли ground truth, и NoSQL-базы, которые служат собственно интерфейсом к данным. Может быть некий батч-процесс, запускаемый очень часто (например, несколько раз в минуту), который вытягивает нужные данные из SQL-базы, раскладывает правильным образом по NoSQL-базам, и те в свою очередь уже занимаются обслуживанием запросов. Это существенно более гибко, чем файлики, потому что размер файлика со временем может начать неконтролируемо расти, да и просто раскладывать его по куче машин — проблематично и чревато всякого рода проблемами типа "на части машин остался старый вариант файла, а никто не заметил".
На самом деле, вместо прослойки из NoSQL-баз может быть простой сервис, который собирает in-memory версию (тот самый "json") и отдаёт его напрямую из памяти. В части случаев это удобнее. Такой сервис асинхронным background-тредом ходит в SQL-базу и регулярно обновляет свой стейт, а наружу торчит интерфейс, который на каждый запрос делает несколько хеш-лукапов в памяти — это тоже очень быстро, бесконечно горизонтально масштабируется, ну и в этом сервисе можно писать любую бизнес-логику.
Самое главное — никаких, никаких, никогда никаких синхронных запросов в SQL-базу на интерактивном трафике.

alexhott
18.01.2023 08:32+1Я так понял причину так и не нашли и воспроизвести поведение не удалось?
Жуть как не люблю такие вещи когда вроде чета сделал но не точно, сидишь потом постоянно как на бочке с порохом.

jirfag
18.01.2023 12:33Спасибо за интересный пост-мортем!
>Не хватает поэтапного заведения трафика на приложения (1, 10, 50, 100%), чтобы кеши всех нижележащих сервисов успели прогрузиться."
Пара комментов про этот action item из опыта починки аналогичных инцидентов:
лучше иметь рубильник для возврата нагрузки произвольной плавности от 0 до 100%. Переход с 50% до 100% легко может свалить систему заново.
в зависимости от специфики бизнеса возможно рубильник нужен не только по проценту, но и как-то более умно
выглядит, что этот action item важнее всех остальных вместе взятых, тк он самый обобщаемый на произвольные инциденты. В инцидент-менеджменте важна фокусировка. На практике, когда много action items, то они как-то паралеллятся, и в итоге может оказаться, что из-за этого самый важный action item сделан только через месяц.
довольно много тонкостей как делать этот рубильник надежно: по запросам / пользователям / заказам; делать ли его в форме rps лимита или concurrency лимита (link); если concurrency то на каком уровне - все in progress заказы или еще как-то; если по запросам то как решать проблемы этого подхода; и др.
кэши это лишь частный случай. Могут быть очереди запросов.
-
советую изучить теорию про metastable failure state (там внутри также крутая pdf-ка), она довольно хорошо структурирует произошедшее и объясняет почему этот action item самый ключевой. Например, из теории становится понятным почему ребут системы после отката версии помог, а следующее при починке только ухудшило ситуацию:
увеличение размера очереди запросов (BulkheadQueue), лучше наоборот уменьшать
увеличение лимита на concurrency (BulkheadConcurrency) в 7 раз, лучше наоборот уменьшать
-
апскейл сервисов перед базой без апскейла базы перед этим. Лучше опять таки наоборот - даунскейлить сервис, чтобы базе полегчало скорее

coolcold
18.01.2023 16:33На уровне ощущений и интуиции, кажется что технический руководитель (CTO или Head of Engineering) всего этого вырос из разработки (шёл по пути как developer). Так ли это?

B7W
18.01.2023 21:12Спасибо за разбор. Читать было увлекательно.
Но почти сразу начали возникать вопросики :-)
Не могли бы вы поделиться уточнениями:По первому алерту видно что началось все с БД.
На этом этапе разве не увидили в мониторинге что с БД явно что то не то?
Разве не было в cookbook минимальных указаний в какие метрики сломтреть/что делать с БД в этом случае?У вас нет метрик среднего времени и количество обработанных запросов на backend?
Если бы тормозила БД/сервисы то в этих метриках наверное можно было бы увидеть что проблема не в DDOS а в каком то узком горлошке внутри.Неужели в логах не было кикаких ошибок?
Я прям не могу поверить что приложения нигде не чихали и все проглатывали и до последнего момента не было понятно что БД не тянет.-
Я правильно понял что основная БД одна без реплик?
Как тогда происходит увеличение CPU? Все останавливается, DODO IS встает колом, и через пару минут начинает оживать?
А часто такое делаете? Это обкатаный этап? Я правильно понял что сначала накинули экземплятров приложений и следом перезагрузили БД?
Просто звутит как выстрелить себе в ногу... увеличить нагрузку на БД (которая вроде как и так вышла за алерт) и потом еще ее перезапустить...
jmdorian
Ссылка на шаблон постмортема выдает 403. За материал спасибо, очень познавательно.
gayka_m8
Поправили, должно открываться.