
Привет, Хабр. Начинаем серию статей с глубоким разбором функционала СХД АЭРОДИСК серии 5. Напомним, что в серию 5 входят СХД ВОСТОК-5 и ENGINE-5, которые работают на базе унифицированного ПО АЭРОДИСК A-CORE. С общим обзором данных железок можно ознакомиться в одной из предыдущих наших статей.
В этой статье речь пойдет об основе СХД – отказоустойчивости и производительности. Как работает, как правильно настраивать и какой результат можно получить.
Мы продемонстрируем работу отказоустойчивости СХД АЭРОДИСК на базе протокола ALUA в условиях высокой нагрузки. Смоделируем отказ активных путей и покажем переключение в режиме реального времени с оптимальных на неоптимальные пути в условиях высокой нагрузки. Более того, все то же самое и даже больше мы покажем в реальном времени на нашем следующем вебинаре Около-ИТ, который состоится 21 февраля 2023 в 15:00. Зарегистрироваться на вебинар можно по ссылке.
Немного матчасти
Для организации отказоустойчивости в системах АЭРОДИСК 5 используется протокол ALUA (Asymmetric Logical Units Access). Это протокол в спецификации SCSI, используемый для управления путями к логическим томам в современных СХД среднего уровня с асимметричным доступом.
Для логических томов со включенным режимом Active/Active - ALUA часть путей контроллера являются активными/оптимальными, а часть — активными/неоптимальными. Контроллер с оптимальными путями выполняет роль владельца логического тома. В случае отказа оптимальных путей для хождения трафика используются неоптимальные пути, которые задействуют интерконнект между двух контроллеров СХД. Схематично это выглядит следующим образом.

Настраиваемся
Для демонстрации настроек и работы мы организовали следующий тестовый стенд:
Linux-сервер (6 cores, 1,70Ghz), 64 GB DDR4, 2xFC-адаптер 16G 2 порта – 1шт.
Коммутатор FC 16G – 1 шт.
СХД Аэродиск ENGINE-5 (2xIntel Xeon E5-1650 v4), 64 GB RAM, 2xFC-card 16G 2 port, 24xSAS SSD 1,8 TB) — 1 шт.
Схема подключения:

Теперь нам необходимо создать дисковые группы, в нашем случае это DDP. Используем все доступные SSD SAS диски в количестве 24 штук. Для создания перейдем в раздел «Подсистема хранения», далее «DDP» и «Создать группу».
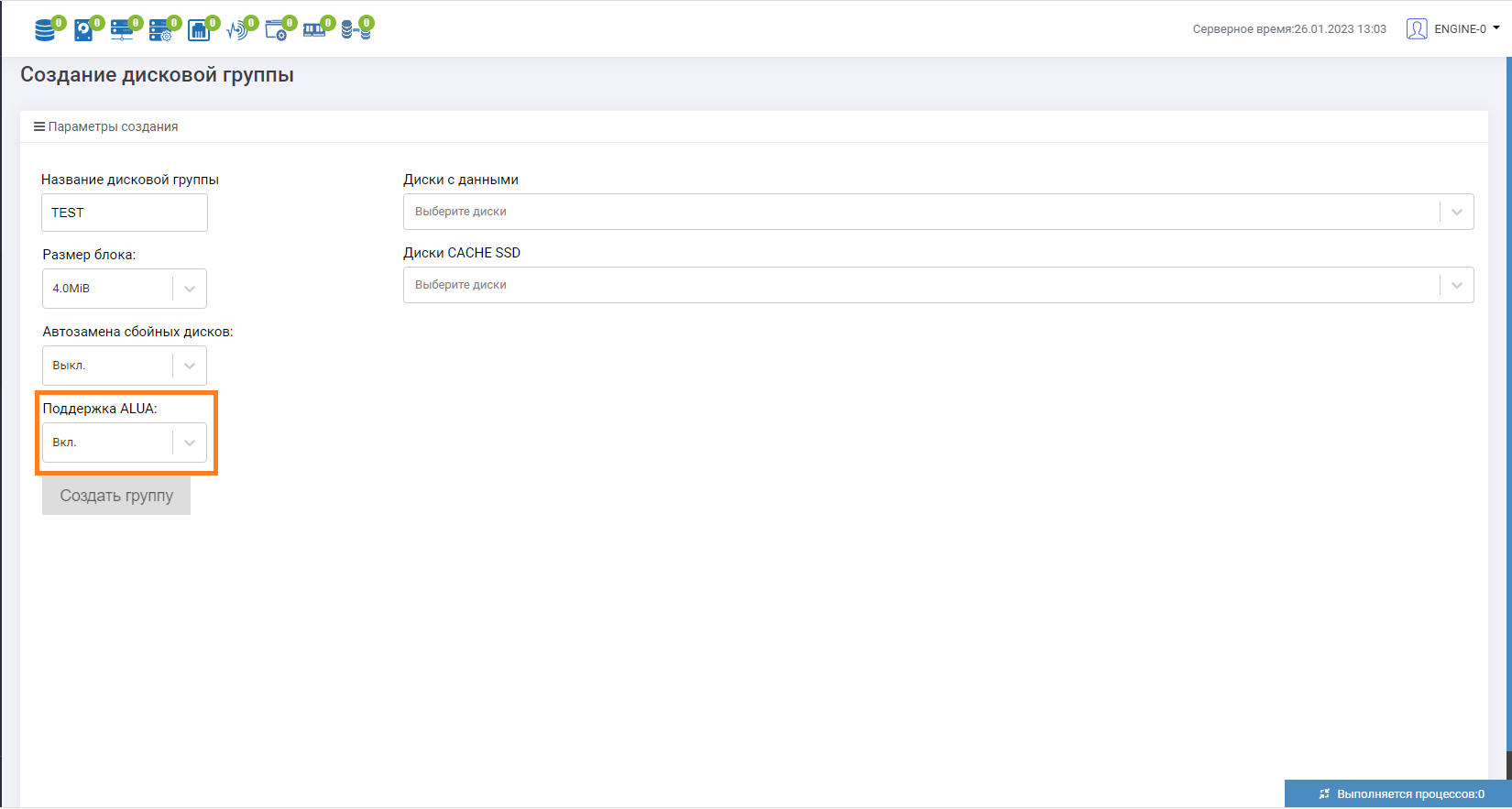
Откроется форма создания дисковой группы. Важный момент при создании пула — перевести параметр «Поддержка ALUA» в состояние «Вкл», далее задаём название дисковой группы и выбираем то количество дисков, которое необходимо для использования.
После создания группы необходимо подготовить логические тома (LUN) под тестирование. В нашем случае мы создаем 4 логических тома для каждой группы DDP с уровнем защиты RAID-10 объемом 500 ГБ каждый.

Необходимо также обратить внимание, что в системе под использование ALUA можно выбрать два типа интерфейса: NTB или INTER. Данная реализация выбора связана с различными типами систем АЭРОДИСК. В случае нашего стенда в качестве интерконнекта используется NTB, поэтому выбираем его. Сменить тип используемого интерфейса можно в правом верхнем меню, выбрав «Engine-0»/ «Engine-1» и перейдя в пункт «Настройки».

Хотели бы обратить внимание, что с 5 версии для существующих дисковых групп возможно включение и отключение работы режима ALUA. Для этого необходимо выбрать имеющуюся группу RDG\DDP, зайти в нее и выбрать пункт «Выкл» или «Вкл» на параметре «Поддержка ALUA». Это будет работать только при условии, если отсутствует маппинг логических томов, принадлежащих к этой группе.
Все логические тома мы презентуем одному Линукс-хосту. Для инициализации томов необходимо использовать корректный файл multipath.conf. Файл можно скачать на портале с документацией, либо обратится в техническую поддержку с запросом.
Методика тестирования
В ходе тестирования будут выполняться следующие сценарии отказа путей СХД:
Отказ A/O путей при случайной нагрузке маленькими блоками 4k и переключение на A/N путь.
100%_read_4k_random
[global]
blocksize=4k
size=80%
direct=1
buffered=0
ioengine=libaio
iodepth=32
group_reporting
rw=randread
numjobs=1
runtime=1800
time_based=1
per_job_logs=0
log_avg_msec=30000
write_bw_log=/home/ubuntu/Result/4k-rand-read4_final.results
write_iops_log=/home/ubuntu/Result/4k-rand-read4_final.results
write_lat_log=/home/ubuntu/Result/4k-rand-read4_final.results
100%_write_4k_random
[global]
blocksize=4k
size=80%
direct=1
buffered=0
ioengine=libaio
iodepth=16
group_reporting
rw=randwrite
numjobs=2
runtime=1800
time_based=1
per_job_logs=0
log_avg_msec=30000
write_bw_log=/home/ubuntu/Result/4k-rand-write4-final.results
write_iops_log=/home/ubuntu/Result/4k-rand-write4-final.results
write_lat_log=/home/ubuntu/Result/4k-rand-write4-final.results
Отказ A/O путей при последовательной нагрузке большими блоками 128k и переключение на A/N путь.
100%_read_128k_seq
[global]
blocksize=128k
size=80%
direct=1
buffered=0
ioengine=libaio
iodepth=32
group_reporting
rw=read
numjobs=2
runtime=1800
time_based=1
per_job_logs=0
log_avg_msec=30000
write_bw_log=/home/ubuntu/Result/128k-seq-read-final.results
write_iops_log=/home/ubuntu/Result/128k-seq-read-final.results
write_lat_log=/home/ubuntu/Result2/128k-seq-read-final.results
100%_write_128k_seq
[global]
blocksize=128k
size=80%
direct=1
buffered=0
ioengine=libaio
iodepth=16
group_reporting
rw=write
numjobs=2
runtime=1800
time_based=1
per_job_logs=0
log_avg_msec=30000
write_bw_log=/home/ubuntu/Result2/128k-seq-write-final.results
write_iops_log=/home/ubuntu/Result2/128k-seq-write-final.results
write_lat_log=/home/ubuntu/Result2/128k-seq-write-final.results
Как мы писали выше, со стороны СХД при переключениях оптимальных путей на неоптимальные будет задействован NTB интерфейс.
В разделе «Производительность» можно настроить вывод утилизации и посмотреть скорость и передачу пакетов во время его работы.

Ниже приведены шаги тестирования по каждому шаблону:
Созданы две группы DDP по 12 дисков SAS SSD.
Созданы 4 логических тома на каждой группу по 500 ГБ и презентованы хосту
Далее запускается каждый файл с параметрами нагрузки FIO, длительность теста 30 минут.
После 10-минутного запуска нагрузки на контроллере Engine-0 отключаются одновременно 2 FC таргета, что позволит смоделировать отказ A/O путей.
В течение 5-ти минут наблюдаем за параметрами iops, mb/sec, latency во время нагрузки, фиксируем результат.
С 15-ой минуты восстанавливаем отключенные FC таргеты на контроллере Engine-0 и выполняем аналогичное отключение таргетов для соседней дисковой группы DDP, находящейся на контроллере Engine-1.
После 20-ой минуты восстанавливаем отключенные FC таргеты, завершаем тестирование, фиксируем результаты.
Результаты тестирования
Случайная нагрузка маленькими блоками 4k, 100% чтение




Случайная нагрузка маленькими блоками 4k, 100% запись




Итак, мы видим, что средняя загрузка процессора составила 40-45%, средняя утилизация памяти - 30%. После 4-ого шага тестирования, а именно отказа оптимальных путей и переключения нагрузки через NTB интерфейс, есть просадка в скорости, задержки также возрастают, но остаются на приемлемом уровне для таких условий. Дисковая группа не пытается переключиться на соседний контроллер при потере FC соединения и находится на том же самом контроллере. Аналогичный тест для второй группы соседнего контроллера показал идентичные результаты.
Последовательная нагрузка блоком 128k, 100% чтение




Последовательная нагрузка блоком 128k, 100% запись




При последовательном характере нагрузки с блоком 128k мы видим более высокую утилизацию NTB интерфейса при отказе FC путей. В обоих вариантах тестов нагрузка упирается практически в максимальную пропускную способность – в нашей конфигурации это 2x16Gb. Как и в предыдущих тестах при отключении FC таргетов группа остается на том же контроллере, где и была, вся нагрузка на логические тома идет по неоптимальным путям через интерфейс NTB при некритичнм снижении производительности.
Результаты и заключение
Итак, мы разобрали механизм отказоустойчивости СХД АЭРОДИСК на базе протокола ALUA, привели пример его оптимальной настройки, запустили высокую нагрузку и смоделировали ситуацию отказа путей к основному контроллеру. СХД осталась жива и показала себя, на наш субъективный взгляд, достойно. В качестве продолжения банкета этот и другие сценарии мы вживую разберем на нашем вебинаре Около-ИТ, который состоится 21 февраля 2023 в 15:00. Зарегистрироваться на вебинар можно по ссылке.
Всем спасибо, ждем вопросов, предложений, возражений и негодований.
Увидимся, как обычно, где-то Около-ИТ, до свидания!
Комментарии (15)

ildarz
00.00.0000 00:00отключаются одновременно 2 FC таргета, что позволит смоделировать отказ A/O путей.
Но не отказ контроллера. Как насчет контроллер дернуть? :)
Почему на random r/w не восстанавливается время отклика после возврата оптимального пути?
Почему на seq write производительность неоптимального пути выше?

Viacheslav_V Автор
00.00.0000 00:00Здравствуйте, очень правильные вопросы.
Но не отказ контроллера. Как насчет контроллер дернуть? :)
Отказ контроллера демонстрировали в одной из предыдущих статей, см ссылка https://habr.com/ru/company/aerodisk/blog/447070/ с того времени логика работы кластера не изменилась.
Почему на random r/w не восстанавливается время отклика после возврата оптимального пути?
Это баг версии 5.0.0 (на ней тесты делали), исправлено в версии 5.0.1 (вышла на днях)
Почему на seq write производительность неоптимального пути выше?
В случае такой нагрузки активнее начинает работать процессор (это видно на схеме) именно за счет этого вытягивается производительность. Это, само собой, актуально когда есть свободные процессорные ресурсы, если бы процессор был бы нагружен на 80%+ была бы просадка

eStellar
00.00.0000 00:00Расскажите, пожалуйста: вы наверняка интересовались и в курсе жизни конкурентов, западных и Российских, есть ли у вас киллер-фичи технического плана, может, какие-то опции которых нет ни у кого или характеристики, по которым вы готовы обогнать ведущих зарубежных производителей ? Насколько активна сейчас ветка Восток ? Расскажите что у него под капотом, много ли проблем ? Лично мы пытались поднять простенькое СХД на 8СВ (mdadm + tgt), но упёрлись в то что не удаётся достичь производительности между двумя контроллерами (HBA и LAN) более чем 4ГБит, на 8С ситуация ещё хуже. Говорят, это решается тонким тюнингом ядра. Удалось ли вам с этим справиться ? Есть ли вообще сравнительные тесты производительности Engine и Восток со схожими параметрами ?
Viacheslav_V Автор
00.00.0000 00:00Спасибо за много интересных вопросов :-) Отвечаю
вы наверняка интересовались и в курсе жизни конкурентов, западных и Российских, есть ли у вас киллер-фичи технического плана, может, какие-то опции которых нет ни у кого или характеристики, по которым вы готовы обогнать ведущих зарубежных производителей ?
Интересовались, интересуемся и будем интересоваться!
По сравнению нашего и "ихнего" кунг-фу, не хочу тут устраивать прямой холивар, т.к. это неэтично, поэтому отвечу в общем виде.
Российские конкуренты (все) уступают нам в функциональности.
Зарубежные превосходят (логично), но есть у нас прекрасная особенность, которой у них нет. Это две принципиально разные схемы организации хранилищ в одной СХД - RDG (Raid Distributed Group) и DDP (Dinamic Disk Pool). Большинство СХД сильных зарубежных конкурентов - заложники своей схемы организации хранения. К примеру, есть массив с кучей функций и интеллектуальных фич, поддержкой больших объемов и много-много всего, но за интеллект приходится платить невысокой производительностью. Или наоборот, производительность - пушка, но функциональность слабая. Поэтому мы чтобы избавить заказчика от мук выбора "красивый или умный (тупой или страшный)", используем две схемы организации хранения RDG - интеллект, функциональность, большие объемы, DDP - производительность. Это то что выгодно нас отличает от известных нам сильных зарубежных конкурентов.
Насколько активна сейчас ветка Восток ? Расскажите что у него под капотом, много ли проблем ?
СХД Восток активно развивается и продается. Что под капотом писали в одной из предыдущих статей: https://habr.com/ru/company/aerodisk/blog/656757/
Лично мы пытались поднять простенькое СХД на 8СВ (mdadm + tgt), но упёрлись в то что не удаётся достичь производительности между двумя контроллерами (HBA и LAN) более чем 4ГБит, на 8С ситуация ещё хуже. Говорят, это решается тонким тюнингом ядра. Удалось ли вам с этим справиться ?
Проблем с разработкой на Эльбрусе хватает, но они решаемы любым взрослым коллективом разработчиков. И да, вы правы, решать их надо доработкой ядра, которой мы активно занимаемся не без поддержки коллег их АльтЛинукса (отдельное спасибо Михаилу Шигорину).
Есть ли вообще сравнительные тесты производительности Engine и Восток со схожими параметрами ?
Есть см. статья https://habr.com/ru/company/aerodisk/blog/520888/

greefon
00.00.0000 00:00Большинство СХД сильных зарубежных конкурентов - заложники своей схемы организации хранения. К примеру, есть массив с кучей функций и интеллектуальных фич, поддержкой больших объемов и много-много всего, но за интеллект приходится платить невысокой производительностью.
Поэтому мы чтобы избавить заказчика от мук выбора "красивый или умный (тупой или страшный)", используем две схемы организации хранения RDG - интеллект, функциональность, большие объемы, DDP - производительность. Это то что выгодно нас отличает от известных нам сильных зарубежных конкурентов.
Честно говоря, выглядит это совсем наоборот. Не зарубежные конкуренты - заложники своей схемы организации хранения данных, а Аэродиск. И отличия сплошь невыгодные.
RDG ("интеллект, функциональность, большие объемы") - прямо на старте вынуждает выбирать уровень RAID для всего пула. Как так? Это "интеллект и функциональность"?
DDP - здесь уровень RAID можно выбирать для тома, размещаемого в пуле. Но вот только диски для чанков этого тома, физические диски, нужно выбирать из пула вручную. И следить за тем, чтобы пространство на физических дисках в пуле при множестве RAID-групп (т.е. томов) распределялось равномерно. Особенно интересно это всё начинает выглядеть при количестве дисков в пуле большим 10, т.к. нужно теперь учитывать, что у тома с RAID-5 (например) физических дисков должно быть меньше 11, иначе производительность падает. Очень похоже на тетрис, только не так весело.
В обоих случаях это такой дремучий олдскул, что смотреть страшно
И в обоих случаях отсутствуют такие ставшие уже привычными вещи как распределенные spare диски и быстрое восстановление после сбоя
Не стоит забывать, что производительность с включенным дополнительным функционалом (дедупликация, компрессия) падает кратно.
А что внутри Аэродиска делает ZFS? Кто кого взял в заложники?
Одним словом, муки выбора уже при первоначальной настройке СХД такие, что и не снились "зарубежным конкурентам". И ладно бы в результате можно было бы получить какую-то уникальную гибкость или производительность. Но ведь нет, в обоих случаях нет.
Российские конкуренты (все) уступают нам в функциональности.
А вот это чистая правда
Viacheslav_V Автор
00.00.0000 00:00Здравствуйте, благодарю за хорошую оценку (приятно) и за повод для дискуссии :-).
RDG ("интеллект, функциональность, большие объемы") - прямо на старте вынуждает выбирать уровень RAID для всего пула. Как так? Это "интеллект и функциональность"?
Интеллект и функциональность в RDG - это когда вы можете:
создавать большие двухслойные пулы с большим количеством дисков;
из коробки реализовать файловый и блочный доступ с одного пула
делать много разных вариантов снапшотов: стандартные ROW снэпшоты, снэпклоны, связанные клоны, группы консистентности, локальные реплики
создавать не только классические Рэйды 1/10/5/50/6/60, но и рэйд с тройной четностью
использовать глобальную автозамену дисков для любых типов пулов
ускорять производительность разными вариантами кэшей
назначать политики перестроения для разных типов данных в зависимости от задачи
экономить место за счет компрессии и дедупликации для больших архивов
ну и делать прочие полезные телодвижения с тонкими томами, VLAN-ами репликацией и метрокластером.
ну а если после всего вышеперечисленного по прежнему вас будет волновать, что вас "вынуждают выбирать уровень RAID для всего пула", то во-первых, никто не мешает создать несколько пулов, а во-вторых не только мы, но и также не менее прекрасные ребята из NetApp-а с вами категорически не согласятся и скажут, что это благо! :-)
DDP - здесь уровень RAID можно выбирать для тома, размещаемого в пуле. Но вот только диски для чанков этого тома, физические диски, нужно выбирать из пула вручную. И следить за тем, чтобы пространство на физических дисках в пуле при множестве RAID-групп (т.е. томов) распределялось равномерно. Особенно интересно это всё начинает выглядеть при количестве дисков в пуле большим 10, т.к. нужно теперь учитывать, что у тома с RAID-5 (например) физических дисков должно быть меньше 11, иначе производительность падает. Очень похоже на тетрис, только не так весело.
Про чанки вручную вы ошибаетесь, возможно перепутали что-то. Чанки у нас в DDP распределяются автоматически и равномерно. Для этого при создании пула надо выбрать количество дисков для него, дальше система сама все распределит в зависимости от свободного места. Специально следить за этим не надо. Возможно когда-было не так, но я если честно не помню такого, если напомните, буду признателен.
А ещё Куриман подсказывает, что набивать в DDP-тома много дисков не рекомендуется, о чем мы везде пишем и говорим, для этого есть RDG, там это разумно.
В обоих случаях это такой дремучий олдскул, что смотреть страшно
тогда отвернитесь, но помните, что в таком положении дремучий олдскул будет смотреть на вас, находясь у вас за спиной :-)
И в обоих случаях отсутствуют такие ставшие уже привычными вещи как распределенные spare диски и быстрое восстановление после сбоя
опять вы что-то перепутали. Hotspare диски у нас глобальные-универсальные. Т.е. один диск может подменить своего сбойного собрата в любом типе пула.
не очень понял, что вы имеете в виду под "быстрое восстановлением после сбоя"
если вы говорите о перестроении при выходе из строя диска , то тут у нас также два вполне годных инструмента для его ускорения: 1)частичное восстановление (только поврежденные данные) 2)политика перестроения. Разве этого мало?
если вы говорите о восстановлении после сбоя той или иной части СХД (ноды, порта, БП итп), то на аппаратном уровне все задублировано, а на программном работает целая связка кластерных служб и переключение выполняется за секунды и без прерывания доступа. На крайнем вебинаре мы подробно рассказали об этом, а также продемонстрировали выход из строя портов и дисков в прямом эфире. Вот запись пожалуйста
Не стоит забывать, что производительность с включенным дополнительным функционалом (дедупликация, компрессия) падает кратно.
-
Тут полностью с вами согласен, есть такая у нас боль. Именно поэтому мы везде рекомендуем эти функции не использовать для задач с высокой производительностью. Но это не значит, что мы не будем развивать это направление. Еще как будем.
А что внутри Аэродиска делает ZFS? Кто кого взял в заложники?
прочитав это замечание, другие опенсорс компоненты СХД Аэродиск обиделись и загрустили. Почему? Потому-что про них опять забыли, а они не менее важны! :-). Давайте не будем их обижать и вспомним их тоже: linux, net-tools, udev, smartctl, zfs, lvm, drbd, smb, chrony, ipmitool, prometheus, iperf, scst, iscsi_driver, fc_driver, multipath, snmp, snmptrap, python, javascript, flask, react, sqlite, postgresql, redis, gunicorn, nginx
а если серьезно, то мы всегда говорили, что опенсорса внутри у нас много и подробно рассказывали какого. Не вижу в этом ничего плохого. Наоборот, в прямых хороших руках, которые растут из плеч, и в которых есть хорошим напильник, опенсорсные поделки превращаются в инструменты уровня предприятия, а сообщество получает профит в виде новых разработок.
Более того, мы настолько любим тему опенсорса, что скоро один из наших продуктов реализуем в опенсорс версии со своим репозиторием, сообществом, блэкджеком и хохломой. Не переключайтесь!
Российские конкуренты (все) уступают нам в функциональности.
А вот это чистая правда
Ещё раз благодарю за теплые слова :-), для нас это ценно!
Спасибо, буду рад дискуссии.
greefon
00.00.0000 00:00Хорошо, давайте подискутируем.
Ваши зарубежные конкуренты характеризуются глубокой интеграцией программных и кастомных аппаратных компонентов и тщательной "вылизанного" проприетарного стека программного обеспечения. В совокупности это позволяет как увеличить скорость работы СХД в целом, в любых терминах (IOPS, BW, latency), так и повысить её надежность. В качестве примеров таких решений можно упомянуть NVRAM в фaйлерах Netapp, или технологии FlashLink в Huawei OceanStor. Таких примеров десятки. Те же Dorado обладают такой высокой производительностью потому, что используют SSD с контроллерами собственной разработки, часть функционала которых вынесена на уровень массива (например, сборка мусора).
Аэродиск Engine N2, с другой стороны, это кластер из двух типовых серверов со сложным стеком опенсорсного ПО, который при сравнимой вычислительной мощности и характеристиках дисков всегда будет позади зарубежных конкурентов.Большинство СХД сильных зарубежных конкурентов - заложники своей схемы организации хранения. К примеру, есть массив с кучей функций и интеллектуальных фич, поддержкой больших объемов и много-много всего, но за интеллект приходится платить невысокой производительностью.
Поэтому цитата выше выглядит как преднамеренное введение в заблуждение. Массив с кучей функций и интеллектуальных фич (возьмем ту же линейку OceanStor) будет быстрее Аэродиска, особенно при включении этих самых интеллектуальных фич.
Также интересно, что вы одной рукой хаете зарубежных конкурентов, а другой рукой их же приводите в пример:прекрасные ребята из NetApp-а с вами категорически не согласятся и скажут, что это благо!
К слову, это далеко не единственных подход. Не будем забывать, что WAFL родился более 20 лет назад. Эта технология оказалась удивительно живучей, во много благодаря заточенности программных и аппаратных составляющих массива именно под неё, но уж точно не является единственной или удобной.
К слову, производительность RAID-DP даже на SATA/NL-SAS дисках очень-очень приличная, не требующая в общем-то кэширования в виде SSD. С другой стороны, производительность вашей реализации RAID6 на Engine на тех же дисках настолько удручающе низка, что требует обязательного использование кэширующих SSD для реорганизации записи (как я предполагаю). Т.е. вы вынуждены имитировать NVRAM (которых еще и синхронизируется между контроллерами в случае Netapp) c помощью обычных SSD. Я прав?
Также по тексту у вас очень много недопониманий и передергиваний. Например:Распределенные spare диски - это такие spare диски, которые не требуют выделение физического диска (дисков) под spare. Вместо этого резервируется резервируется свободное место в пуле, кратное емкости входящих в него одиночных дисков. Таким образом, при перестроении массива в случае сбоя, данные пишутся (восстанавливается четность) на все диски в пуле сразу, а не на один spare, что ощутимо быстрее.
Про DDP и выбор дисков. При создании тома в группе DDP вы выбираете не количество дисков (по крайней мере в 4.0.3), а указываете конкретные физические диски, на которых разместятся чанки пула. Их количество, конечно, должно соответствовать заданной DP схеме, типа 4+1 для RAID5. И это я даже не погружаюсь в дебри вашего RAID Performance Guide, или как он там называется
"Никто не мешает создать несколько пулов" - мешает ограниченное количество дисков. В этом и есть смысл интеллектуального распределения чанков томов по физическим дискам, дающее гибкость, удобство эксплуатации.
"долгое перечисление реализованных технологий" - на практике оказывается, что включение этих технологий либо приводит к кратному снижению и без того невысокой производительности (компрессия, дедупликация, тонкие тома), либо они ведут себя по-разному в зависимости от сценария (ROW-снапшоты только для тонких томов DDP, но тонкий том это кратное падение производительности, а для толстых томов используются COW снапшоты, и это тоже кратное падение производительности, причем накопительное каскадное)
и т.д. и т.п.
Давайте еще раз коротко скажу. Аэродиск привносит в процесс настройки СХД много избыточной сложности, при этом даже при идеальной настройке и соблюдении всех рекомендаций производительность вашего решения окажется ниже "зарубежных конкурентов", а включить богатый функционал скорее всего не получится, поскольку он будет очень заметно тормозить систему.
И это я даже не переходил к качеству организации интерфейса, допускающего "выстрелы в ногу". Т.е. штатными документированными действиями в интерфейсе можно парализовать систему так, что потребуется вмешательство поддержки и подключение с рутовыми правами для прибития повисших сервисов. Той самой опенсорсной вязанки, которую вы собираете вместе с помощью скриптов. И не рассказывал про недокументированные и неочевидные особенности, которые позволяют собрать вроде бы работающую конфигурацию, которая в результате не позволит перенести дисковую группу с контроллера на контроллер. Опять же, из-за недоработки внутренней логики скриптов.

werter_l
00.00.0000 00:00Глянул цену вашего гипервизора.
И, эээ, обомлел.
500к? Вы серъезно?
Чем оно лучше того же proxmox-а, к-ый я могу просто скачать с офиц. сайта и пользовать вообще без денег? Что в вашем продукте уникального?
Viacheslav_V Автор
00.00.0000 00:00Нет ничего лучше бесплатного хорошего софта. Пользуйтесь на здоровье!

0xcffaedfe
00.00.0000 00:00Минутка негатива:
Достался в наследство: AeroDisk Engine N1, загорелия желанием апгрейдить это дело, докинуть дисков, обновить прошивку, но как это бывает обычно у "Российский" производителей, столкнулся с рядом проблем.
Апдейтов нет.
Апдейты только при наличии активной техподдержки.
Вендорлок на диски (при чем продают только с поддержкой) В сухом остатке все сводится к: выбросите и купите новую вот вам опросник.
b01d
Это по прежнему китайский сервер с софтверным райд за оверпрайз?
csharpreader
А можно поподробнее со ссылками?
Мне после вашей реплики удалось нагуглить вот такое:
Как делается российское железо для СХД Аэродиск Восток на Эльбрусах (itnan.ru)
ildarz
Вы только что описали (почти) любые современные СХД. :)
Viacheslav_V Автор
Здравствуйте, к счастью вы ошибаетесь.
По железу, если очень грубо, то так
1)корпуса, материнки, бэкплейн, плюс часть элементов питания российские
2)процессоры в зависимости от модели, Восток - российские, Engine - зарубежные
3)диски и адаптеры, а также ряд элементов питания зарубежные
Подробности можно почитать тут
https://habr.com/ru/company/aerodisk/blog/504306/
По софту. Функционал A-Core значительно шире чем просто программный рэйд, можете посмотреть подробнее тут
https://aerodisk.ru/wp-content/uploads/2022/07/Tehnicheskoe_opisanie_-AERODISK-VOSTOK-5_ENGINE-5.pdf
Viacheslav_V Автор
А по поводу цены на СХД, ранее отвечали на этот вопрос в нашем ТГ канале, предлагаю вам ознакомиться
https://t.me/aerodisk_official/96