
 «Ещё пару лет назад вы не могли разговаривать с приложением Google в городском шуме или прочитать вывеску на иностранном языке с помощью переводчика Google Translate, или мгновенно найти фотографии своего лабрадуделя, — пишет Google в официальном блоге. — Наши приложения просто не были достаточно умными. Но за короткий промежуток времени они стали намного, намного умнее. Сейчас, благодаря машинному обучению всё это доступно. Несмотря на весь прогресс, которого мы добились, всё ещё остаются возможности для улучшения. Поэтому мы создали совершенно новую систему машинного обучения, которую назвали TensorFlow. Она быстрее, умнее и гибче, чем наша старая система, так что её намного проще приспособить к новым продуктам и исследованиям».
«Ещё пару лет назад вы не могли разговаривать с приложением Google в городском шуме или прочитать вывеску на иностранном языке с помощью переводчика Google Translate, или мгновенно найти фотографии своего лабрадуделя, — пишет Google в официальном блоге. — Наши приложения просто не были достаточно умными. Но за короткий промежуток времени они стали намного, намного умнее. Сейчас, благодаря машинному обучению всё это доступно. Несмотря на весь прогресс, которого мы добились, всё ещё остаются возможности для улучшения. Поэтому мы создали совершенно новую систему машинного обучения, которую назвали TensorFlow. Она быстрее, умнее и гибче, чем наша старая система, так что её намного проще приспособить к новым продуктам и исследованиям».Итак, компания Google выложила свою новейшую разработку TensorFlow во всеобщее пользование под свободой лицензией Apache 2.0.
TensorFlow — чрезвычайно масштабируемая система, которая способна работать как на одном смартфоне, так и на тысячах серверов в дата-центре. Google использует TensorFlow практически повсеместно, от распознавания речи до поиска фотографий в Google Photos.
Новый TensorFlow позволяет создавать и тренировать нейросети до пяти раз быстрее, чем система предыдущего поколения DistBelief.
На иллюстрации ниже — композитное изображение, которое соответствует оптимальному стимулу для нейрона-классификатора кошки во время испытания нейросети, построенной с помощью DistBelief в 2012 году.

К тому же, TensorFlow не ограничивается только нейросетями, а обрабатывает большие объёмы сложных данных: от фолдинга белков до массивов астрономических данных. Любые вычисления, которые можно выразить в виде графа потока данных.
Google выражает надежду, что с помощью открытой библиотеки исследователи и разработчики будут обмениваться наработками не только в виде научных статей, но и непосредственно в виде исходного кода на C++ или Python. Это ещё больше ускорит исследования в области машинного обучения.
«Машинное обучение находится на ранней стадии развития — компьютеры всё ещё не могут понимать то, на что с лёгкостью способен четырёхлетний ребёнок. У нас впереди много работы. Но TensorFlow положит хорошее начало, и мы можем всё одолеть вместе», — пишет Google.
Дополнительно:
Техническое описание программной модели и её в TensorFlow
Примеры графов потоков данных
Комментарии (8)

devpony
10.11.2015 12:50+22015 год. Гугл. Но почему API только для морально устаревшего второго питона?




megalol
По сути это комбинация системы матричных расчетов с символьным движком. Берется функция, которую можно представить в виде графа, затем для нее вычисляется градиент и генерируется высокопроизводительный код и для функции, и для градиента. Полученный результат можно и оптимизатору скормить.
Так как любая нейросеть по сути является такой функцией, область применения понятна — вместо того, чтобы вручную писать код backpropagation для каждой системы, это делает библиотека. Однако для любых задач, где требуется градиентный спуск, такой подход применим. Таких библиотек уже как минимум две (Theano и Torch7), однако гугл предлагает следующее:
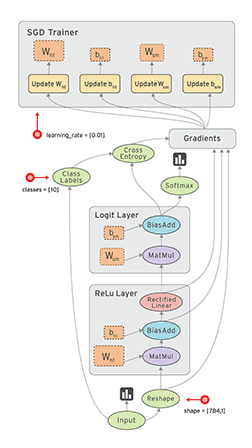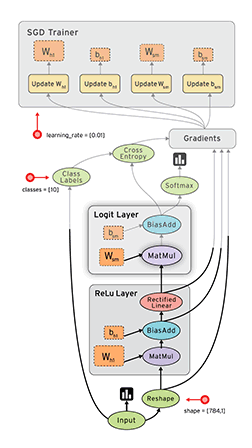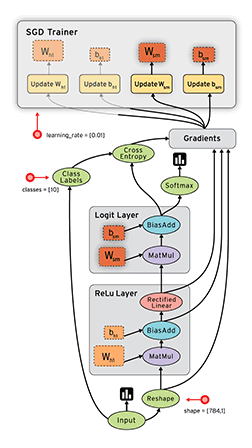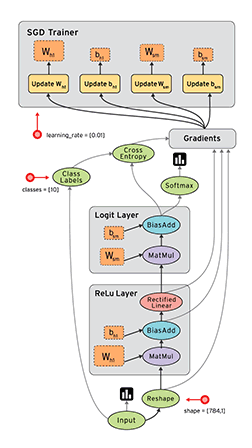
1. Визуализация (как на картинке).
2. Поддержка спектра устройств от мобильников, GPU до распределенных систем.
Мощная штука.
SkidanovAlex
Ну в Theano очень медленная компиляция, которая почти убивает возможность писать LTSM нейронки в ней, а в Torch, если я правильно понимаю, нет символьного движка, поэтому Torch ближе к Caffe чем к Theano или TensorFlow. Не говоря о том, что Torch — это Lua, то есть уже Pandas, например, не подцепить (хотя я слышал там были какие-то успехи в создании python bindings).
Поэтому TensorFlow — это очень приятная новость. По существу это юзабельная версия Theano. Да еще и все слои и update-функции прямо в библиотеке, ничего доставлять не надо. В Theano ничего нет, надо ставить Lasagne или Keras.