
 Привет, Хаброжители!
Привет, Хаброжители!Работа с неограниченными и быстрыми потоками данных всегда была сложной задачей. Но Kafka Streams и ksqlDB позволяют легко и просто создавать приложения потоковой обработки. Из книги специалисты по обработке данных узнают, как с помощью этих инструментов создавать масштабируемые приложения потоковой обработки, перемещающие, обогащающие и преобразующие большие объемы данных в режиме реального времени.
Митч Сеймур, инженер службы обработки данных в Mailchimp, объясняет важные понятия потоковой обработки на примере нескольких любопытных бизнес-задач. Он рассказывает о достоинствах Kafka Streams и ksqlDB, чтобы помочь вам выбрать наиболее подходящий инструмент для каждого уникального проекта потоковой обработки. Для разработчиков, не пишущих код на Java, особенно ценным будет материал, посвященный ksqlDB.
Кому адресована книга
Эта книга адресована специалистам по обработке данных, желающим научиться создавать масштабируемые приложения потоковой обработки для перемещения и преобразования больших объемов данных в режиме реального времени. Подобные умения часто необходимы для поддержки интеллектуальной обработки данных, аналитических конвейеров, обнаружения угроз, обработки событий и многого другого. Специалисты по данным и аналитики, занимающиеся анализом потоков данных в реальном режиме времени и желающие усовершенствовать свои навыки, тоже смогут почерпнуть немало полезного из этой книги. В ней автору удалось отойти от привычной пакетной обработки, которая обычно доминировала в этих областях. Предварительный опыт работы с Apache Kafka не требуется, хотя некоторое знакомство с языком программирования Java облегчит знакомство с Kafka Streams.
Обзор Kafka Connect
Kafka Connect — это один из пяти API в экосистеме Kafka, он используется для подключения к Kafka внешних хранилищ данных, API и файловых систем. Когда данные находятся в Kafka, их можно обрабатывать, преобразовывать и обогащать с помощью ksqlDB. Перечислю основные компоненты Kafka Connect.
Коннекторы
Коннекторы — это упакованные фрагменты кода, которые можно внедрить в рабочие процессы (обсудим их чуть ниже). Они способствуют перемещению данных между Kafka и другими системами и делятся на две категории:
- коннекторы-источники читают данные из внешних систем в Kafka;
- коннекторы-приемники записывают данные во внешние системы из Kafka.
Задачи
Задачи — это единицы работы внутри коннектора. Количество задач может быть разным, что позволяет контролировать объем работы, выполняемой одним рабочим процессом.
Рабочие процессы
Рабочие процессы (workers) — это процессы JVM, которые выполняют коннекторы. Можно развернуть несколько рабочих процессов, чтобы распараллелить/распределить работу и добиться отказоустойчивости в случае частичного сбоя (например, если один рабочий процесс неожиданно завершится).
Конвертеры
Конвертеры — это код, осуществляющий сериализацию/десериализацию данных в Connect. Конвертер по умолчанию (например, AvroConverter) должен указываться на уровне рабочего процесса, но также есть возможность задавать конвертеры на уровне коннекторов.
Кластер Connect
Кластер Connect объединяет один или несколько рабочих процессов Kafka Connect, действующих вместе как группа и перемещающих данные в Kafka и из нее.
На рис. 9.1 показана схема работы всех этих компонентов.
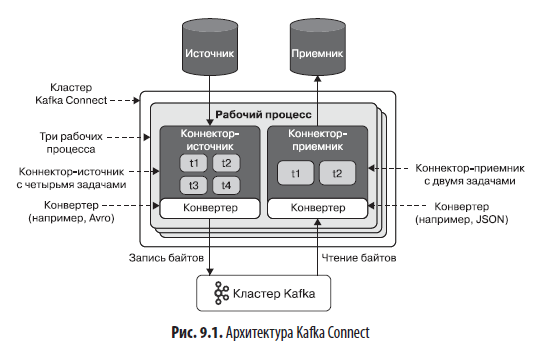
Может показаться, что все это будет трудно усвоить, но по мере чтения главы вы увидите, что ksqlDB значительно упрощает ментальную модель Kafka Connect. А теперь посмотрим на варианты развертывания Kafka Connect для использования с ksqlDB.
Внешняя и встроенная интеграция с Connect
Интеграция с Kafka Connect в ksqlDB может работать в двух разных режимах. В этом разделе описываются оба режима и рассказывается, когда их использовать. Начнем с внешней интеграции.
Внешняя интеграция
Если у вас уже есть готовый кластер Kafka Connect или вы хотите развернуть Kafka Connect отдельно от ksqlDB, то существует возможность использовать внешнюю интеграцию с Kafka Connect. Для этого необходимо в ksqlDB настроить URL кластера Kafka Connect, определив свойство ksql.connect.url. После этого ksqlDB сможет обращаться к внешнему кластеру Kafka Connect напрямую, создавать коннекторы и управлять ими. Пример конфигурации внешнего режима показан ниже (он будет сохранен в файле свойств сервера ksqlDB):
ksql.connect.url=http://localhost:8083При работе в режиме внешней интеграции любые коннекторы (источники и приемники), необходимые приложению, должны действовать во внешних рабочих процессах. Обратите внимание, что при работе в режиме внешней интеграции рабочие процессы, как правило, размещаются отдельно от сервера ksqlDB, потому что одно из основных преимуществ этого режима заключается в отсутствии необходимости использования ресурсов компьютера совместно с ksqlDB. На рис. 9.2 показана схема работы Kafka Connect в режиме внешней интеграции.
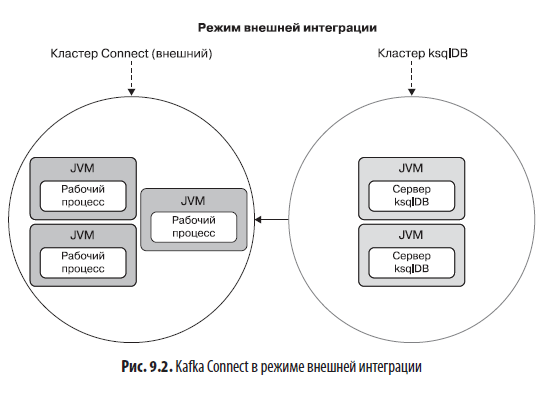
Вот некоторые ситуации, когда может появиться желание использовать режим внешней интеграции с Kafka Connect:
- требуется независимо масштабировать рабочие нагрузки и ввод/вывод данных и/или изолировать ресурсы для этих различных видов рабочих нагрузок;
- ожидается большой трафик через темы источников/приемников;
- уже есть действующий кластер Kafka Connect.
Далее рассмотрим режим встроенной интеграции, который используем в учебных проектах в этой книге.
Встроенная интеграция
В режиме встроенной интеграции рабочий процесс Kafka Connect выполняется под управлением той же JVM, что и сервер ksqlDB, в распределенном режиме Kafka Connect. Это означает возможность распределения работы между несколькими взаимодействующими экземплярами рабочего процесса. Количество рабочих процессов Kafka Connect совпадает с количеством серверов ksqlDB в кластере ksqlDB. Режим встроенной интеграции предпочтительнее использовать, когда:
- требуется одновременно масштабировать рабочие нагрузки потоковой обработки и ввода/вывода;
- ожидается небольшой или средний трафик через темы источников/приемников;
- желательны простота поддержки интеграции данных, отсутствие необходимости управлять отдельным развертыванием Kafka Connect и независимо масштабировать рабочие нагрузки интеграции/преобразования данных;
- допускается перезапуск рабочих процессов Kafka Connect с перезапуском серверов ksqlDB;
- допускается совместное использование вычислительных ресурсов/памяти ksqlDB и Kafka Connect.
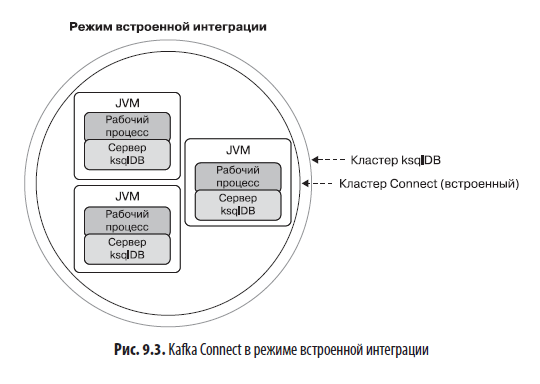
Для запуска в режиме встроенной интеграции необходимо установить конфигурационное свойство ksql.connect.worker.config сервера ksqlDB, указав путь к конфигурациям рабочих процессов Kafka Connect. Не забывайте, что рабочие процессы — это процессы Kafka Connect, в рамках которых фактически действуют коннекторы источников и приемников. Вот пример настройки этого свойства в файле свойств сервера ksqlDB:
ksql.connect.worker.config=/etc/ksqldb-server/connect.propertiesНо какая информация должна быть определена в конфигурационном файле рабочего процесса, на который ссылается свойство ksql.connect.worker.config? Мы поговорим об этом в следующем разделе.
Настройка рабочих процессов Connect
Kafka Connect имеет множество параметров настройки, подробно описанных в официальной документации Apache Kafka (https://oreil.ly/UWnW3). В этом разделе будут представлены только наиболее важные из них на примере настройки рабочего процесса Kafka Connect. При запуске в режиме встроенной интеграции настройки следует определить в файле (например, connect.properties) и сослаться на него в свойстве ksql.connect.worker.config в конфигурации сервера ksqlDB. При запуске в режиме внешней интеграции настройки рабочего процесса передаются в аргументах запуска Kafka Connect. Пример конфигурации показан в следующем листинге:
bootstrap.servers=localhost:9092 (1)
group.id=ksql-connect-cluster (2)
key.converter=org.apache.kafka.connect.storage.StringConverter (3)
value.converter=org.apache.kafka.connect.storage.StringConverter (4)
config.storage.topic=ksql-connect-configs (5)
offset.storage.topic=ksql-connect-offsets
status.storage.topic=ksql-connect-statuses
errors.tolerance=all (6)
plugin.path=/opt/confluent/share/java/ (7)(1) Список пар хост/порт брокеров Kafka, которые следует использовать для подключения к кластеру Kafka.
(2) Строковый идентификатор кластера Connect, которому принадлежит этот рабочий процесс. Рабочие процессы, настроенные с одним и тем же идентификатором group.id, принадлежат одному кластеру и могут совместно использовать рабочую нагрузку для выполнения коннекторов.
(3) «Класс конвертера для преобразования между форматом Kafka Connect и сериализованной формой. Управляет форматом ключей в сообщениях, записываемых в Kafka или извлекаемых из него, а поскольку класс не зависит от коннекторов, это позволяет любому коннектору работать с любым форматом сериализации. Примерами распространенных форматов могут служить JSON и Avro». (Документация Connect; https://oreil.ly/08AW5.)
(4) «Класс конвертера для преобразования между форматом Kafka Connect и сериализованной формой. Управляет форматом значений в сообщениях, записываемых в Kafka или извлекаемых из него, а поскольку класс не зависит от коннекторов, это позволяет любому коннектору работать с любым форматом сериализации. Примерами распространенных форматов могут служить JSON и Avro». (Документация Connect.)
(5) Kafka Connect использует несколько дополнительных тем для хранения информации с настройками коннекторов и задач. Здесь мы просто используем стандартные имена этих тем с префиксом ksql-, потому что будем работать в режиме встроенной интеграции (то есть рабочие процессы будут выполняться под управлением той же JVM, что и экземпляры серверов ksqlDB).
(6) Свойство errors.tolerance позволяет настроить политику обработки ошибок по умолчанию в Kafka Connect. Допустимые значения: none (немедленный отказ при возникновении ошибки) и all (полное игнорирование ошибок или, при использовании со свойством errors.deadletterqueue.topic.name, пересылка всех ошибок в тему Kafka по вашему выбору).
(7) Список путей в файловой системе, перечисленных через запятую, где находятся плагины (коннекторов, конвертеров, преобразователей). Как устанавливать коннекторы, вы увидите далее в этой главе.
Как видите, основная масса конфигурационных параметров рабочих процессов довольно проста. Тем не менее некоторые настройки стоит изучить подробнее, потому что они связаны с решением важной задачи сериализации данных — это свойства конвертеров (key.converter и value.converter). В следующем разделе мы детально рассмотрим конвертеры и форматы сериализации.
Конвертеры и форматы сериализации
Классы конвертеров, используемых в Kafka Connect, играют важную роль в сериализации и десериализации данных. В нашем учебном проекте Hello, world, представленном в предыдущей главе (см. раздел «Учебный проект» главы 8), мы использовали инструкцию из примера 9.1, чтобы создать поток в ksqlDB.
Пример 9.1. Создание потока, читающего данные из темы users
CREATE STREAM users (
ROWKEY INT KEY,
USERNAME VARCHAR
) WITH (
KAFKA_TOPIC='users',
VALUE_FORMAT='JSON'
);Эта инструкция сообщает ksqlDB, что тема users (KAFKA_TOPIC='users') содержит записи со значениями, сериализованными в формат JSON (VALUE_FORMAT='JSON'). Если есть свой производитель, записывающий в тему данные в формате JSON, то довольно легко рассуждать о формате. Но что, если Kafka Connect используется, например, для потоковой передачи в Kafka данных из PostgreSQL? В какой формат сериализуются данные из PostgreSQL, когда они записываются в Kafka?
Здесь в игру вступают настройки конвертеров. Для управления форматами сериализации ключей и значений записей, которые обрабатывает Kafka Connect, можно настроить свойства key.converter и value.converter, определив в них соответствующие классы конвертеров. В табл. 9.1 перечислены наиболее часто используемые классы конвертеров и соответствующие им форматы сериализации ksqlDB (то есть значение, которое указывается в свойстве VALUE_FORMAT при создании потока или таблицы, как было показано в примере 9.1).
В табл. 9.1 также отмечено, какие конвертеры опираются на Confluent Schema Registry для хранения схем записей, что может пригодиться, если потребуется более компактный формат сообщений. Schema Registry позволяет хранить схемы записей, то есть имена и типы полей, вне самих сообщений.

Для каждого конвертера в табл. 9.1, требующего реестра схем, нужно добавить дополнительное конфигурационное свойство: { key | value }.converter.schema.registry.url. Например, в этой книге мы будем работать в основном с данными Avro, поэтому, чтобы коннекторы записывали значения в этом формате, можно обновить конфигурацию рабочего процесса, как показано в примере 9.2.
Пример 9.2. Конфигурация рабочего процесса, использующего AvroConverter для преобразования значений записей
bootstrap.servers=localhost:9092
group.id=ksql-connect-cluster
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=io.confluent.connect.avro.AvroConverter (1)
value.converter.schema.registry.url=http://localhost:8081 (2)
config.storage.topic=ksql-connect-configs
offset.storage.topic=ksql-connect-offsets
status.storage.topic=ksql-connect-statuses
plugin.path=/opt/confluent/share/java/(1) Использовать AvroConverter для сериализации значений в формат Avro.
(2) Конвертеру Avro требуется Confluent Schema Registry для хранения схем записей, поэтому нужно указать URL этого реестра схем, определив свойство value.converter.schema.registry.url.
Сейчас, узнав, как задать формат сериализации данных в Kafka Connect, и подготовив конфигурацию для рабочих процессов в Kafka Connect (см. пример 9.2), перейдем к учебному проекту и на практике установим и используем некоторые коннекторы.
Учебный проект
В этом учебном проекте мы используем коннектор-источник JDBC для потоковой передачи данных из PostgreSQL в Kafka. Затем создадим коннектор-приемник Elasticsearch для записи данных из Kafka в Elasticsearch. Полный код этого проекта и инструкции по настройке окружения (включая экземпляр PostgreSQL и Elasticsearch) можно найти в репозитории на GitHub (https://oreil.ly/7ImWJ).
Начнем с установки коннекторов.
Установка коннекторов
Существует два основных способа установки коннекторов источников и приемников:
- вручную;
- автоматически, через Confluent Hub.
Более простой метод загрузки коннекторов, который будет использоваться в этой книге, позволяет устанавливать коннекторы с помощью инструмента командной строки, разработанного в Confluent. Этот инструмент с названием confluent-hub можно установить, следуя инструкциям в документации Confluent (https://oreil.ly/31Sd9). После установки Confluent Hub установка самих коннекторов не вызывает никаких сложностей. Вот синтаксис команды установки коннектора:
confluent-hub install <владелец>/<компонент>:<версия> [параметры]Например, следующая команда установит коннектор-приемник Elasticsearch:
confluent-hub install confluentinc/kafka-connect-elasticsearch:10.0.2 \
--component-dir /home/appuser \ (1)
--worker-configs /etc/ksqldb-server/connect.properties \ (2)
--no-prompt (3)(1) Каталог, куда должен быть установлен коннектор.
(2) Местоположение конфигурационных файлов рабочих процессов. Место установки (определяется параметром --component-dir) будет добавлено в plugin.path, если это еще не было сделано.
(3) Чтобы обойти стороной интерактивные шаги (например, подтверждение установки, принятие лицензионного соглашения и т. д.), можно разрешить интерфейсу командной строки работать с рекомендуемыми значениями/значениями по умолчанию. Это полезно для установки из сценария.
Точно так же можно установить коннектор-источник PostgreSQL:
confluent-hub install confluentinc/kafka-connect-jdbc:10.0.0 \
--component-dir /home/appuser/ \
--worker-configs /etc/ksqldb-server/connect.properties \
--no-promptОбратите внимание, что в режиме встроенной интеграции потребуется перезапустить сервер ksqlDB, если коннекторы устанавливались после запуска экземпляра сервера ksqlDB. Выполнив установку коннекторов, необходимых приложению, можно создавать их экземпляры и управлять ими в ksqlDB. Мы обсудим этот вопрос в следующем разделе.
Создание экземпляров коннекторов в ksqlDB
Вот как выглядит синтаксис создания коннектора:
CREATE { SOURCE | SINK } CONNECTOR [ IF NOT EXISTS ] <identifier> WITH(
property_name = expression [, ...]);Предположим, что у нас уже есть экземпляр PostgreSQL, доступный по адресу postgres:5432, в этом случае можно установить коннектор-источник для чтения из таблицы titles, выполнив следующую команду в ksqlDB:
CREATE SOURCE CONNECTOR `postgres-source` WITH( (1)
"connector.class"='io.confluent.connect.jdbc.JdbcSourceConnector', (2)
"connection.url"=
'jdbc:postgresql://postgres:5432/root?user=root&password=secret', (3)
"mode"='incrementing', (4)
"incrementing.column.name"='id', (5)
"topic.prefix"='', (6)
"table.whitelist"='titles', (7)
"key"='id'); (8)(1) Оператор WITH используется для передачи конфигурации коннектора (зависит от конкретного коннектора, поэтому необходимо заглянуть в документацию, чтобы узнать список доступных конфигурационных свойств).
(2) Класс Java коннектора.
(3) Коннектору-источнику JDBC требуется URL для подключения к хранилищу данных (в данном случае к базе данных PostgreSQL).
(4) Коннектор-источник ОВИС поддерживает несколько режимов запуска. Поскольку мы предполагаем передавать любые новые записи, добавляемые в таблицу titles и имеющие столбец с автоматическим приращением значения, можно установить режим incrementing. Этот и другие режимы, поддерживаемые данным коннектором, подробно описаны в документации (https://oreil.ly/w8Grb).
(5) Имя столбца с автоматическим приращением, который коннектор-источник будет использовать для определения новых строк.
(6) Каждая таблица передается в отдельную тему (например, таблица titles будет передаваться в тему titles). При желании можно задать префикс для имени темы (например, если настроить префикс ksql-, данные будут передаваться в тему ksql-titles). В этом проекте мы не будем использовать префикс.
(7) Список таблиц для потоковой передачи в Kafka.
(8) Значение, используемое в роли ключа записи.
После выполнения инструкции CREATE SOURCE CONNECTOR в консоли должно появиться сообщение, подобное следующему:
Message
-----------------------------------
Created connector postgres-source
-----------------------------------Теперь создадим коннектор-приемник для вывода записей из приложения в Elasticsearch. Эта инструкция очень похожа на инструкцию создания коннектора-источника:
CREATE SINK CONNECTOR `elasticsearch-sink` WITH(
"connector.class"=
'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
"connection.url"='http://elasticsearch:9200',
"connection.username"='',
"connection.password"='',
"batch.size"='1',
"write.method"='insert',
"topics"='titles',
"type.name"='changes',
"key"='title_id');Как видите, конфигурации разных коннекторов различаются. Большинство имен конфигурационных параметров говорят сами за себя, а определение назначения остальных я оставляю вам в качестве самостоятельного упражнения. Соответствующие описания конфигурационных параметров ElasticsearchSinkConnector можно найти в справочнике по настройке Elasticsearch Sink Connector (https://oreil.ly/o8h7j). И снова после выполнения инструкции CREATE SINK CONNECTOR в консоли должно появиться сообщение:
Message
--------------------------------------
Created connector elasticsearch-sink
--------------------------------------После создания экземпляров коннекторов в ksqlDB с ними можно взаимодействовать разными способами. В следующих разделах мы рассмотрим некоторые из доступных вариантов взаимодействия.
Вывод списка коннекторов
В режиме интерактивной интеграции иногда полезно получить список всех работающих коннекторов и их состояние. Инструкция получения списка коннекторов имеет следующий синтаксис:
{ LIST | SHOW } [ { SOURCE | SINK } ] CONNECTORSДругими словами, можно получить список всех коннекторов, только коннекторов-источников или только коннекторов-приемников. К настоящему моменту мы создали только два коннектора, источник и приемник, поэтому воспользуемся следующим вариантом, чтобы вывести информацию об обоих:
SHOW CONNECTORS;В консоли должен появиться такой вывод:
Connector Name | Type | Class | Status
---------------------------------------------------------------------
postgres-source | SOURCE | ... | RUNNING (1/1 tasks RUNNING)
elasticsearch-sink | SINK | ... | RUNNING (1/1 tasks RUNNING)Команда SHOW CONNECTORS выводит некоторую полезную информацию об активных коннекторах, включая их состояние. В данном случае оба коннектора имеют по одной задаче в состоянии RUNNING. Другие состояния, которые можно увидеть, включают: UNASSIGNED, PAUSED, FAILED и DESTROYED. Увидев такое состояние, как FAILED, вы наверняка захотите выяснить причину. Например, если коннектор postgres-source потеряет соединение с базой данных PostgreSQL (это можно сымитировать, просто остановив экземпляр PostgreSQL), то появится такой вывод:
Connector Name | Type | Class | Status
---------------------------------------------------------------------
postgres-source | SOURCE | ... | FAILED
--------------------------------------------------------------Но как получить дополнительную информацию о коннекторе, например, чтобы выяснить причину неудачной отработки задач? В этом вам поможет возможность получения описаний коннекторов в ksqlDB. Рассмотрим ее ниже.
Получение описаний коннекторов
ksqlDB упрощает получение состояния коннекторов, предлагая инструкцию DESCRIBE CONNECTOR. Например, если коннектор postgres-source потеряет соединение с хранилищем данных, как обсуждалось в предыдущем разделе, можно попробовать запросить его описание, чтобы получить дополнительную информацию. Например:
DESCRIBE CONNECTOR `postgres-source`;Если имеет место ошибка, то в консоли появится вывод с трассировкой этой ошибки, как показано ниже:
Name : postgres-source
Class : io.confluent.connect.jdbc.JdbcSourceConnector
Type : source
State : FAILED
WorkerId : 192.168.65.3:8083
Trace : org.apache.kafka.connect.errors.ConnectException (1)
Task ID | State | Error Trace
---------------------------------------------------------------------
0 | FAILED | org.apache.kafka.connect.errors.ConnectException (2)(1) Трассировка стека в этом примере приводится неполностью, но в случае фактического сбоя вы должны увидеть полную трассировку стека исключения.
(2) Разбивка по задачам. Задачи могут находиться в разных состояниях (например, одни могут находиться в состоянии RUNNING, а другие — в состоянии UNASSIGNED, FAILED и т. д.).
Однако чаще вы будете видеть задачи в работоспособном состоянии. Вот пример вывода инструкции DESCRIBE CONNECTOR:
Name : postgres-source
Class : io.confluent.connect.jdbc.JdbcSourceConnector
Type : source
State : RUNNING
WorkerId : 192.168.65.3:8083
Task ID | State | Error Trace
---------------------------------
0 | RUNNING |
--------------------------------Теперь, научившись создавать коннекторы и получать их описания, давайте узнаем, как их удалять.
Удаление коннекторов
Удаление коннекторов может понадобиться для их перенастройки или безвозвратного удаления. Синтаксис удаления коннектора:
DROP CONNECTOR [ IF EXISTS ] <идентификатор>Например, чтобы удалить коннектор PostgreSQL, можно выполнить следующую инструкцию:
DROP CONNECTOR `postgres-source` ;После удаления коннектора в консоли должно появиться подтверждение, что коннектор действительно удален. Например:
Message
-------------------------------------
Dropped connector "postgres-source"
-------------------------------------Проверка коннектора-источника
Один из быстрых способов проверить работоспособность коннектора-источника PostgreSQL — записать некоторые данные в базу данных, а затем вывести содержимое темы. Например, создадим таблицу titles в экземпляре Postgres и заполним ее некоторыми данными:
CREATE TABLE titles (
id SERIAL PRIMARY KEY,
title VARCHAR(120)
);
INSERT INTO titles (title) values ('Stranger Things');
INSERT INTO titles (title) values ('Black Mirror');
INSERT INTO titles (title) values ('The Office');Это инструкция PostgreSQL, а не ksqlDB.Наш коннектор-источник PostgreSQL должен автоматически извлечь данные из этой таблицы в тему titles. Чтобы убедиться в этом, воспользуемся инструкцией PRINT:
PRINT `titles` FROM BEGINNING ;ksqlDB должен вывести:
Key format: JSON or KAFKA_STRING
Value format: AVRO or KAFKA_STRING
rowtime: 2020/10/28 ..., key: 1, value: {"id": 1, "title": "Stranger Things"}
rowtime: 2020/10/28 ..., key: 2, value: {"id": 2, "title": "Black Mirror"}
rowtime: 2020/10/28 ..., key: 3, value: {"id": 3, "title": "The Office"Обратите внимание, что ksqlDB, как сообщается в первых двух строках вывода, пытается определить формат ключей и значений записей в теме titles. Поскольку для ключей у нас используется StringConverter, а для значений — AvroConverter (см. пример 9.2), этот результат вполне ожидаем.
Точно так же для проверки коннектора-приемника нужно создать принимающую тему, а затем запросить данные из нижестоящего хранилища. Мы оставим это читателю в качестве самостоятельного упражнения (можете заглянуть в репозиторий [https://oreil.ly/gs18X], и вы увидите, как это сделать).
Пришло время посмотреть, как напрямую взаимодействовать с кластером Kafka Connect, и перечислить случаи, когда это может понадобиться.
Взаимодействие с кластером Kafka Connect напрямую
Иногда может потребоваться взаимодействовать с кластером Kafka Connect напрямую, без участия ksqlDB. Например, некоторые конечные точки Kafka Connect предоставляют информацию, недоступную в ksqlDB, и позволяют выполнять важные действия, такие как повторный запуск задач, потерпевших неудачу. Я не собираюсь давать здесь исчерпывающие инструкции по работе с Connect API, а просто приведу несколько примеров запросов, которые вы можете выполнить в своем кластере Connect. Они перечислены в следующей таблице.
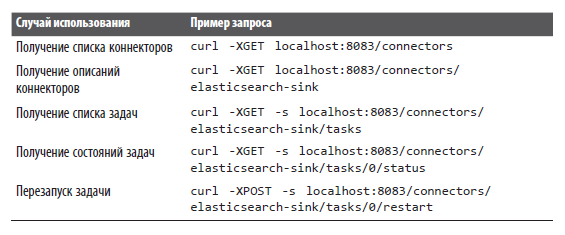
Наконец, посмотрим, как проверить схемы при использовании форматов сериализации, применяющих Confluent Schema Registry.
Анализ управляемых схем
Некоторые форматы сериализации из перечисленных в табл. 9.1 требуют Confluent Schema Registry для хранения схем записей. При их использовании Kafka Connect будет автоматически сохранять схемы в реестре Confluent Schema Registry. В табл. 9.2 показаны примеры запросов к конечной точке Schema Registry, которые помогут проанализировать управляемые схемы.

Полную справку по API можно найти в справочнике по Schema Registry API (https://oreil.ly/Q26Si).
Об авторе
Митч Сеймур — инженер и технический руководитель группы Data Services в Mailchimp. Используя Kafka Streams и ksqlDB, он создал несколько приложений для потоковой обработки, которые каждый день обрабатывают миллиарды событий с задержкой менее секунды. Активный участник сообщества пользователей и разработчиков программного обеспечения с открытым исходным кодом, пропагандирует технологии потоковой обработки на международных конференциях (Kafka Summit London, 2019), рассказывает о Kafka Streams и ksqlDB на местных встречах разработчиков и публикует свои статьи в блоге Confluent.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Kafka Streams