
Голосовая связь с нами давно: первые телефоны изобрели ещё в конце 19-го века, а мобильные — в середине 20-го. В начале 2000-х начал набирать популярность ещё один способ связи — интернет-звонки. Идея по сути та же — общаться на расстоянии, только ещё проще и дешевле. Плюс онлайн-звонки дают много дополнительных функций: от возможности видеть собеседников по видеосвязи до формата, когда вы вместе смотрите кино, находясь в разных точках планеты. Технологии идут вперёд, и тем не менее мы снова и снова переспрашиваем: «Слышно меня?».
Разберёмся в статье с вопросами качества передачи голоса в звонках. Например, почему может быть плохо слышно того, кто звонит из автомобиля? В чём особенность использования динамиков вместо наушников? Что происходит со звуком участника звонка, если у него плохой интернет? Можно ли измерить качество звука в цифрах?
Меня зовут Алексей Шпагин, я более десяти лет занимаюсь VoIP-телефонией и сейчас руковожу командой бэкенда VK Звонков. Наш сервис — это бесплатное средство видеосвязи для всех пользователей ВКонтакте и не только. За день в нём проходит примерно шесть миллионов онлайн-встреч, а количество одновременных звонков достигает 15 000. Расскажу, как мы улучшаем качество звука.
Из чего складывается качество звука
Когда все собирались в переговорных, общались в коридорах или на своих рабочих местах, никаких преград для разговора не было — каждого хорошо видно и слышно. Но за последнее время общение мигрировало в онлайн, и совещания перешли в сервисы видеоконференций.
Если система видеосвязи нормально работает, мы разговариваем с людьми так же, как в жизни, ощущаем эффект присутствия. Если же при общении в звонке нам что-то мешает и эффекта присутствия нет, значит, у системы недостаточно высокое качество.
Требования к передаче звука в системе видеозвонков

Рассмотрим требования к звуку в системе для видеозвонков.
Непрерывность звукового потока. Если звук прерывается или сильно искажается — это уже некомфортно, нет ощущения живого общения. Звук должен быть непрерывным.
Минимальная latency. В жизни скорость распространения звука в воздухе достаточно высокая: нет задержки, которую мог бы заметить человек. Но если людей разделяет электронная система, то неизбежно возникает некоторое отставание между сказанным и услышанным — это называется latency. Latency в пределах 200 мс почти незаметна, а вот задержка в секунду и больше делает общение в режиме диалога практически невозможным.
Отсутствие артефактов в звуке — для сохранения эффекта присутствия система не должна вносить каких-то дополнительных щелчков, треска или клиппинга.
Достаточный частотный диапазон. Человек в среднем воспринимает звук в частотном диапазоне от 20 Гц до 20 кГц. По теореме Котельникова, для адекватной передачи непрерывного сигнала частота дискретизации должна быть как минимум в два раза больше верхней границы нужного диапазона. Поэтому для VK Звонков мы выбрали частоту 48 кГц — используемый нами WebRTC её поддерживает.

Исторически в IP-телефонии применялась частота дискретизации 8 кГц. При такой частоте аудио звучит не очень и добиться эффекта присутствия невозможно.
Измерение качества передачи речи
Как работать с качеством и разборчивостью голоса в системе для аудио- или видеосвязи?
Мы используем оценку MOS (mean opinion score) для измерения качества звука. Это метрика от 1 до 5.

Иллюстрации в третьем столбце показывают, сколько усилий требуется слушающему для восприятия того или иного фрагмента речи. При максимальном качестве звука нужно меньше сил и энергии на расшифровку сказанного. При минимальном качестве понимать слова и смысл становится очень трудно.
Однако MOS, равный 5, недостижим — это как КПД 100%.

В системах видеоконференций и IP-телефонии аудиокодеки сжимают данные с потерями: закодировали фрагмент аудио, декодировали — и уже потеряли в качестве. И это ещё даже через интернет не передавали.
Методики и алгоритмы измерения качества речи
В классическом варианте оценка MOS основывается на опросе людей, которых просят оценить фрагмент записи по пятибалльной шкале. У нас вкалывают роботы: автоматизированные алгоритмы предсказывают, что бы сказал живой человек, услышав тот или иной отрывок речи.
Рассмотрим, какие бывают алгоритмы и как устроено автоматическое измерение качества речи.
Первый вариант:
достаточно высококачественный референсный сигнал подаётся в звонок;
выполняются процедуры кодирования и декодирования, производится передача через интернет;
получается искажённый сигнал;
референсный и искажённый сигнал сравниваются алгоритмом, предсказывающим оценку MOS.

Второй вариант — это безреференсные метрики. Всё примерно то же самое, но алгоритм работает только с искажённым сигналом и пытается оценить его качество, не используя исходный сигнал.

Мы ВКонтакте применяем референсную метрику ViSQOL и безреференсную метрику NISQA. Специально комбинируем эти подходы для большей объективности оценки.
Есть и другие метрики. POLQA — стандарт для оценки качества звука в системах WebRTC и им подобных, но это закрытое вендорское решение. AQuA — позиционируется как аналог POLQA. Но наши тесты показали, что на определённых кейсах AQuA ведёт себя хуже, чем POLQA.
Также упомяну PESQ — устаревшую метрику, которая очень широко применяется в VoIP-телефонии. Но, к сожалению, она применима только на 8 и 16 кГц частоты дискретизации — нам это не подходит.

Стенд для измерения качества звука в VK Звонках
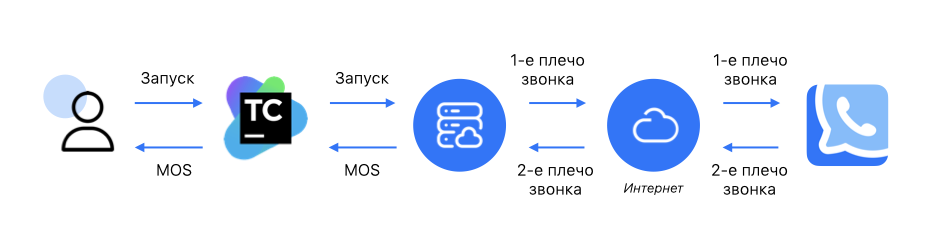
Вот так устроен наш стенд для изменения качества звука:
слева пользователь — это разработчик или QA-инженер, который хочет измерить качество звука;
инженер запускает job в TeamCity;
TeamCity дёргает двух ботов — тестовых клиентов в облаке. Первый бот делает звонок, второй его принимает;
звонок проходит через наш сервис, и первый бот, который делал звонок, начинает проигрывать референсный файл;
этот сигнал, проходя через интернет и VK Звонки, претерпевает какие-то искажения;
бот, который принимает звонок, записывает принятый искажённый сигнал;
затем референсный и искажённый сигналы подаются на алгоритм оценки, полученная метрика попадает обратно в TeamCity, в котором наш пользователь наблюдает результат измерения в терминах MOS.
Важный момент: в схеме есть облачко, обозначающее интернет. Это действительно честный интернет, то есть тестовые клиенты отделены от сервиса интернетом, они не находятся в одном и том же дата-центре и не ходят в сервис по локальным IP-адресам. При тестировании на стенде с интернетом проявляются все связанные с ним проблемы.
Примеры проблем при передаче звука
Рассмотрим две группы: проблемы, связанные с особенностью передачи данных через интернет, и проблемы акустического характера.
Сетевые проблемы
Данные по сети передаются пакетами: мы получаем звук с микрофона пользователя, нарезаем на небольшие кусочки, как правило, по 20 мс, которые пакетизируются и отправляются в виде UDP-пакета. Ниже на схеме передатчик последовательно отправляет пакеты: P1, P2, P3 и так далее.

Обратите внимание, что передатчик отправляет данные равномерно, поэтому на схеме слева расстояние между пакетами одинаковое. Дальше пакеты попадают в интернет — и приходят к приёмнику не так гладко, как нам бы хотелось.
Пакеты могут теряться. На схеме пакет P4 помечен как потерянный.
Пакеты могут «дрожать», то есть приходить через неравные промежутки времени. Например, пакеты Р1 и Р2 практически слиплись. Р3 от них отстаёт, а Р5 за счёт потерянного Р4 отстаёт ещё больше.
Пакеты могут задерживаться или меняться местами. Например, на схеме пакеты Р1 и Р2 переставлены местами, сначала пришёл P2.
Если мы используем мобильный интернет, то проблемы усиливаются. При хорошем Wi-Fi перебоев меньше, на проводе — ещё лучше. Поэтому качество связи в интернет-звонках напрямую зависит от типа выбранного соединения.
Как компенсировать сетевые проблемы
Первый, самый базовый механизм — это Jitter Buffer. Jitter Buffer выравнивает трафик, накапливает некоторое количество пакетов и компенсирует дрожание. Он может подождать какой-то пакет, если тот задерживается или переставлен местами с другим пакетом и так далее.
Но есть нюанс: слишком большой Jitter Buffer увеличивает задержку. Поэтому мы вынуждены держать баланс между размером Jitter Buffer и latency.
Вторая, менее стандартная техника — это NACK (negative acknowledgment). Мы привыкли к acknowledgment’ам, подтверждающим, что данные получены. В этом случае на каждый пакет в обратную сторону отправляется acknowledgment. Однако в real-time коммуникации мы не можем себе такого позволить, так как это будет тормозить трафик и бесконтрольно увеличивать latency. Потому вместо обычного ACK применяем NACK — отправляем обратно запрос, только когда недосчитались какого-то пакета. Ниже на схеме иллюстрация механизма negative acknowledgment.

Что видим на схеме:
от передатчика последовательно идут пакеты Р1, Р2, Р3. Но Р4 потерялся;
приёмник понимает, что Р4 потерялся, только когда получил следующий пакет Р5;
как только приёмник получил Р5 и увидел пробел в последовательности, он отправляет NACK;
тем временем передатчик продолжает отправлять пакеты Р6, Р7, Р8;
передатчик принимает NACK, понимает, что нужно заново отправить P4, и делает ретрансмит.
Отличная схема, но она будет хорошо работать только на коротких RTT. Не всегда возможно дождаться ретрансмита из-за ограничений на latency и Jitter Buffer — мы не можем вечно ждать потерянный пакет.
Третья технология — это FEC (forward error correction). При кодировании в bitstream добавляется дополнительная информация, которая позволит компенсировать небольшие потери. FEC, в отличие от NACK, хорошо работает и на больших RTT.

Из таблицы с результатами эксперимента видно, что в условиях packet loss = 5% и без FEC оценка MOS = 3,94, с включённым FEC — MOS = 4,19. Конечно, мы вывели эту фичу в продакшен.
Ещё один способ борьбы с сетевыми проблемами — это RED (Reduandancy). Он чем-то похож на FEC, но они работают на разных уровнях. FEC — на уровне кодека, а RED — на уровне RTP. В один RTP-пакет помещается 2 или более аудиокадров.

Профит RED проверяли на большем проценте потерь пакетов, который эмулирует неважную сеть: packet loss = 10%, delay = 200 мс. С включённым RED оценка MOS существенно выросла — с 3,6 до 4,14. Естественно, это тоже вывели в продакшен.
И последний из инструментов компенсации сетевых эффектов — это PLC (packet loss concealment). Он приходит на помощь, когда с точки зрения сети уже сделать ничего нельзя: пакет окончательно потерялся и образовался разрыв в данных. Алгоритмы PLC позволяют достроить недостающий фрагмент — по сути, придумать, какой звук там мог бы быть. На иллюстрации это пунктирная линия.
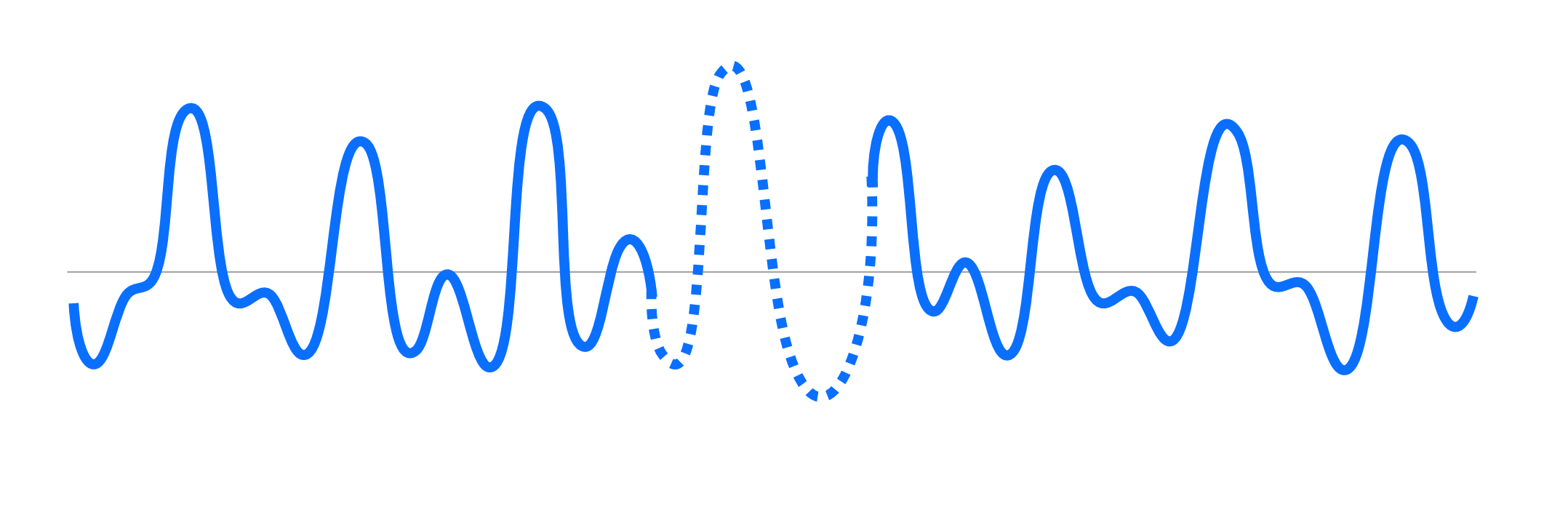
Если пропусков мало и они недлинные, то мы даже не услышим PLC. Но если packet loss большой, то работа PLC проявляется в виде металлического призвука в голосе.
Акустические проблемы
Прежде всего, это внешние шумы. Они повсюду.

Например, вы звоните из транспорта, из офиса, когда рядом кто-то разговаривает, из автомобиля, с шумной улицы или даже из дома, где сосед что-то сверлит. Сервису конференц-связи нужно уметь подавлять шумы и оставлять только полезный сигнал — голос. Для этого мы используем в VK Звонках свой шумодав, основанный на machine learning.
Шумоподавление
Качество шумоподавления мы проверяем таким экспериментом:
сначала берём качественный референс без шумов, прогоняем через нашу систему и получаем некоторую оценку MOS = 3,91;
потом к исходному сигналу подмешиваем шум — например, лай собаки. Причём по громкости сопоставимый с полезным сигналом, то есть достаточно навязчивый. Прогоняем через систему, получаем MOS = 1, т. е. самый плохой звук, в котором практически невозможно разобрать речь;
далее берём референс, шум и прогоняем через нашу систему, но с включённым шумоподавлением. Получаем MOS = 2,79.

По абсолютному значению MOS ≈ 3. Конечно, не идеально, но это качественно лучше, чем без шумоподавления — из неразборчивого сигнала мы сделали вполне разборчивый.
Voice activity detection
Voice activity detection, или VAD — детектор речи, позволяющий отдельно обрабатывать речевой и неречевой сигнал. Например, не отправлять в сеть тишину. Мы имплементировали собственный VAD на базе machine learning некоторое время назад, и его обновления также проверяем на тестах.

Результат тестированияВ этот раз оценка MOS с VAD получилась немного хуже, чем без него. Поэтому решили ещё доработать модель и новую версию в продакшен не пустили.
Signal to Noise Ratio
Примерно такая же ситуация с SNR (Signal to Noise Ratio). Дело в том, что шумоподавление не только отрезает шум, но и немного ухудшает качество исходного сигнала, даже если в нём не было исходного шума. Если человек сидит в тихом помещении и с хорошим микрофоном, то шумоподавление для него может быть избыточным и в итоге негативно скажется на качестве звука.

SNR оценивает соотношение сигнала и шума, а затем решает, надо включать для этого пользователя шумоподавление или нет.
Мы включили SNR вместе с VAD, и измерения показали, что стало немного хуже. Поэтому ей тоже пока дали красный свет. Будем дорабатывать и дообучать модель.
Акустическое эхо

Вот как появляется эхо в звонке: пользователь слушает собеседников через динамики, и всё, что ему говорят во время звонка, попадает в микрофон. Кроме того, сигнал от динамиков переотражается в комнате и также попадает в микрофон. Сам пользователь тоже может при этом что-то говорить. Таким образом, микрофон принимает смесь сигнала из динамиков, отражённого сигнала и того, что человек говорит. Если не применять каких-то специальных средств, вся эта смесь попадёт в звонок, и другие участники будут слышать себя через первого пользователя. Мы боремся с этим эффектом с помощью эхоподавления.
Используем стандартное эхоподавление от WebRTC, плюс у нас есть фишка: когда первый пользователь начинает что-то говорить, мы немного приглушаем его динамик. Так уменьшается громкость попадания сигнала в микрофон, и переотражение может затухнуть, не дойдя до микрофона (или дойти с очень слабой амплитудой).
В целом проблема double talk, когда два человека пытаются поговорить одновременно и сидят с динамиками, актуальна в мировом масштабе. Для нас это пока тоже некоторый челлендж, но мы с этим работаем.
Применение инструментов измерения качества голоса
Мы можем использовать описанный выше стенд для измерений в разных окружениях — лабораторном, на стейджинге или в продакшене:
при разработке какой-то фичи мы можем на dev-окружении измерить качество звука и сделать объективные выводы;
можем в рамках регрессионного тестирования перед релизом прогнать измерения и убедиться, что качество аудио стало лучше или как минимум не упало;
можем сравнить две версии продукта, например, если есть подозрение на деградацию, начиная с какого-то релиза;
можем оценить эффект от новой фичи на продакшене: с помощью фича-тоггла включать и выключать какую-то фичу, делать измерения и выводы, помогает нам она или нет, делает ли качество звука выше;
мониторим продакшен: регулярно запускаются два тестовых клиента, через продакшен-окружение один звонит другому, происходит оценка качества звука, за которой мы постоянно следим.

Итоги
В интернет-звонках важно в первую очередь качество передачи речи. Чтобы его оценить, используется метрика MOS, основанная на опросах, и алгоритмические метрики, позволяющие программно оценить MOS. Существуют референсные и безреференсные метрики — в VK Звонках мы используем оба варианта: ViSQOL и NISQA.
Проблемы, связанные с особенностью передачи данных через интернет, помогают компенсировать технологии: Jitter Buffer, PLC, NACK, FEC и RED.
Проблемы акустического характера нивелируем с помощью VAD, SNR, нейросетевого шумо- и эхоподавления.
Инструменты измерения качества голоса можно применять на всех этапах разработки, на dev-, staging- и production-окружениях. Это позволяет оценить результаты от внедрения каждой фичи, провести регрессионное тестирование, сравнить разные версии продукта и мониторить качество звонков на продакшене.
Эта статья написана по мотивам доклада на HighLoad++ в ноябре в Москве. На следующей конференции — Saint HighLoad++ 2023, 26–27 июня в Санкт-Петербурге — выступлю с продолжением истории и расскажу о способах объективной оценки качества видео. Пишите в комментариях, что вам было бы интереснее всего узнать по теме, и приходите слушать :)
Комментарии (5)

VADemon
13.04.2023 12:54Как я понял, используете Opus. Все описанные дополнения - поверх кодека? Я не говорю про очевидные Voice Activation (понятно) и PLC (емнип, встроена в кодек). По описанию фич самого кодека, в нем припрятано много всего. Например, при плохом соединении битрейт адаптируется? А размер фрейма? Ведь при толстом канале с большими потерями можно уменьшить окно фрейма на лету, тем самым уменьшив последствия потери отдельного фрейма. FEC делается силами самого кодека?

aleksandrsevo64y
13.04.2023 12:541. Используйте высокоскоростное интернет-соединение: Чем быстрее ваше соединение, тем меньше задержки и потерь данных при передаче голоса.
2. Используйте качественный микрофон: Микрофон должен быть четким и иметь минимальный уровень шума.
3. Используйте наушники или акустическую систему: Это позволит избежать эхо и обратной связи, что может повлиять на качество передачи голоса.
4. Используйте программное обеспечение с высоким качеством звука: Skype, Zoom и другие программы предлагают высокое качество звука, которое позволяет передавать голос без потерь.
5. Избегайте использования Wi-Fi: Wi-Fi может быть нестабильным и не гарантирует высокое качество передачи голоса.
6. Избегайте шумных мест: Шумные места могут повлиять на качество звука и привести к потере данных.
7. Проверьте настройки звука: Убедитесь, что настройки звука на вашем компьютере или устройстве настроены на максимальное качество.
8. Проводите тесты передачи голоса: Перед началом важного разговора проведите тесты передачи голоса, чтобы убедиться в качестве звука и стабильности соединения.
Serenevenkiy
13.04.2023 12:54+1В соседнем топике про флекзозоскелеты тоже есть «суммирующий» комментарий от Александра с цифрами в имени. https://habr.com/ru/articles/728956/#comment_25443204 Это кто-то бота прикрутил к Хабру? Вообще довольно полезно получилось.
Александр, вы человек?
LuggerFormas
Какой ptime, какой в итоге latency, какой битрейт (частоту сказал, битс-пер-сэмпл не сказал)?
Субьективный MOS уноси откуда принес, ТТХ раскрывай
Какой конкретно кодек и алгоритм VAD? А то налил воды про lossless, а в таблице только lossy.
"В чём особенность использования динамиков вместо наушников?" - я худею
LuggerFormas
Секрет успеха - берем фуллбенд, запихиваем его в трещащий по швам канал, а потом срезаем фильтром наглухо ибо "шумы".
Для мобил с тарифицируемым трафиком - самый смак, чего себе отказывать. А вообще без кодека не думали слать? Лосслесс "искаропки"!
Поймите мое возмущение - такая статья от студента, полазившего недельку по функциям того же дискорда - норм, обьяснит вообще с чем это едят. Для тимлида - низкий технический уровень, очень много общих фраз, мало конкретики. Еще и очень сомнительные решения в некоторых местах. Как минимум "шумодав" и "эффект присутствия" - "или крестик снимите, или трусы наденьте".