
На hh/gt не нашел ни единого упоминания о этом замечательном расширении для Google Chrome. Хочу поделиться им с сообществом, потому как в последнее время оно помогает мне каждодневно экономить минут 10 — уж очень много скриншотов из социальных сетей на разных языках которые с помощью этого плагина переводятся в два клика.
Встречайте — Project Naptha (Chrome webstore).
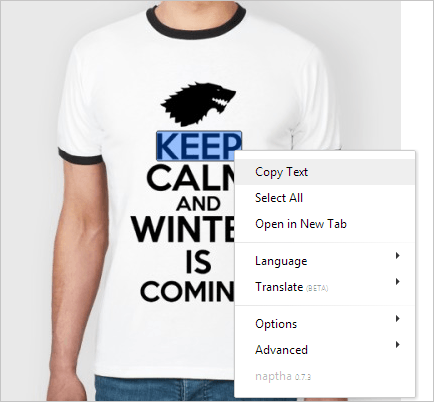
Список возможностей:
Проект был создан Kevin Kwok и представляет собой систему OCR (Optical character recognition), реализованную в JavaScript в виде браузерного расширения.
Project Naptha, несмотря на простоту для конечного пользователя, довольно сложный внутри.
Прежде всего, перед тем как непосредственно распознавание текста началось, нужно определить где собственно находятся блоки с текстом на картинке. Довольно нетривиальная задача, учитывая то, что текст может располагаться поверх совершенно разных фонов и сам по себе иметь разные цвета. Для реализации этого механизма Naptha использует проект Майкрософта Stroke Width Transform (SWT) — эффективный алгоритм, который отталкивается от того, что шрифты обычно имеют примерно равномерную толщину линий (font-weight) и, следовательно, легко отделить блоки текста от остального шума на картинке.
Оригинал:

После SWT:
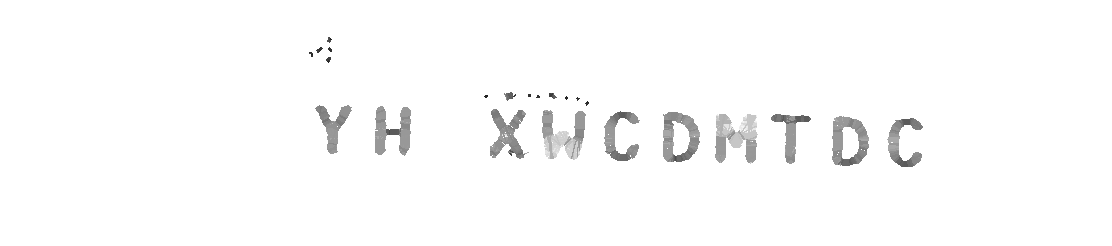
Naptha конечно же не распознает каждую картинку на открытой странице — это бы было крайне расточительно по отношению к ресурсам. Вместо этого начинает распознавание расположения блоков текста только после… нет, не наведения мыши на картинку (mouseover) как вы могли подумать, а предположения о том, что курсор будет над картинкой, основываясь на его движении. Дальше Web Workers (мультипоточность в фоне) работают над распознаванием расположения текста на картинке без какого-либо ощутимого торможения браузера.
Когда вы выбрали блок текста и клинкули “Copy Text” (Ctrl+C), он посылается на сервер с Ocrad OCR — движком с открытым кодом для распознавания текста. Ocrad попытается распознать кусок растровой картинки в текст, что может занять пару секунд, и после завершения вернет распознанный текст, который можно будет вставить обычным образом куда угодно (Ctrl+V).
Функция перевода пока что в бете, для того чтобы ее попробовать нужно отправить запрос на их электронный адрес. Предполагается что она будет работать схоже c уже работающим аналогом в Google Translate на мобильных устройствах:
Проект все еще находится в стадии тестирования, но даже на текущий момент он достаточно хорош чтобы использовать его в работе. Можно конечно придираться к деталям и возможным тормозам, но этот продукт, насколько я знаю, единственный в своем роде и он уже экономит мое время.
Встречайте — Project Naptha (Chrome webstore).
Список возможностей:
- копировать текст с картинки
- выделить весь текст
- гуглить выделенный текст
- переводить выделенное (бета)
- проговорить (TTS) выделенное
Проект был создан Kevin Kwok и представляет собой систему OCR (Optical character recognition), реализованную в JavaScript в виде браузерного расширения.
Project Naptha, несмотря на простоту для конечного пользователя, довольно сложный внутри.
Прежде всего, перед тем как непосредственно распознавание текста началось, нужно определить где собственно находятся блоки с текстом на картинке. Довольно нетривиальная задача, учитывая то, что текст может располагаться поверх совершенно разных фонов и сам по себе иметь разные цвета. Для реализации этого механизма Naptha использует проект Майкрософта Stroke Width Transform (SWT) — эффективный алгоритм, который отталкивается от того, что шрифты обычно имеют примерно равномерную толщину линий (font-weight) и, следовательно, легко отделить блоки текста от остального шума на картинке.
Оригинал:
После SWT:
Naptha конечно же не распознает каждую картинку на открытой странице — это бы было крайне расточительно по отношению к ресурсам. Вместо этого начинает распознавание расположения блоков текста только после… нет, не наведения мыши на картинку (mouseover) как вы могли подумать, а предположения о том, что курсор будет над картинкой, основываясь на его движении. Дальше Web Workers (мультипоточность в фоне) работают над распознаванием расположения текста на картинке без какого-либо ощутимого торможения браузера.
Когда вы выбрали блок текста и клинкули “Copy Text” (Ctrl+C), он посылается на сервер с Ocrad OCR — движком с открытым кодом для распознавания текста. Ocrad попытается распознать кусок растровой картинки в текст, что может занять пару секунд, и после завершения вернет распознанный текст, который можно будет вставить обычным образом куда угодно (Ctrl+V).
Функция перевода пока что в бете, для того чтобы ее попробовать нужно отправить запрос на их электронный адрес. Предполагается что она будет работать схоже c уже работающим аналогом в Google Translate на мобильных устройствах:
Проект все еще находится в стадии тестирования, но даже на текущий момент он достаточно хорош чтобы использовать его в работе. Можно конечно придираться к деталям и возможным тормозам, но этот продукт, насколько я знаю, единственный в своем роде и он уже экономит мое время.