
Нагрузочное тестирование представляет собой вид нефункционального тестирования и предполагает проверку работы системы под высокой нагрузкой. Может показаться, что это звучит скучно, но на самом деле весь процесс планирования, оценки и проведения нагрузочных тестов системы похож на решение сложной головоломки, и это может быть очень увлекательно.
Самой сложной частью может стать процесс планирования, потому что нам нужно думать о реальных сценариях, а не просто угадывать количество (виртуальных) пользователей, которых хотим имитировать. Важная часть процесса планирования — посмотреть на Кривую Гаусса и не забывать, что даже если тысячи пользователей используют приложение, какова вероятность того, что несколько пользователей нажмут на одну и ту же кнопку (попадут в один и тот же эндпоинт) в одно и то же время, исчисляемое миллисекундами?
Я только что сказал, что нагрузочное тестирование — это весело, и сразу же перешел к математике, вероятности и прочему, как скучно. (На самом деле нет!)
Resource Object Model нам в помощь
Недавно я был назначен на очень динамичный крупномасштабный проект, в котором мы использовали k6 для тестирования множества нефункциональных аспектов, таких как:
нагрузка, производительность, всплески и выносливость;
горизонтальная масштабируемость инфраструктуры;
аварийные сигналы Amazon CloudWatch;
блокировки баз данных;
мониторинг Prometheus.
Все тесты проводились на реальных, похожих на производственные средах в различных регионах. Проект требовал быстрого и эффективного внедрения тестов, при этом бэкенд постоянно находился в состоянии улучшения и оптимизации. Поддерживать множество тестовых скриптов, созданных для каждого сценария, региона или исполнителя теста, было попросту невозможно.
Чтобы решить эту задачу и запустить тесты с 15 000+ виртуальных пользователей с одной машины, я использовал Resource Object Model. Это оказалось идеальным решением с минимальным потреблением ресурсов.
Работа со сценариями экстремального давления
Если пропустить некоторые части процесса планирования, все, что нам нужно, — это мощный инструмент, который поможет подвергнуть эндпоинты «экстремальному давлению». Под экстремальным давлением следует понимать 10 000 пользователей, которые одновременно или с небольшим шагом увеличивают нагрузку на один и тот же эндпоинт. Один инструмент на рынке действительно выделяется простотой и количеством виртуальных пользователей, которых мы можем генерировать на наших рабочих станциях, и это единственный и неповторимый Grafana k6.
Grafana k6 — это инструмент для проведения нагрузочного тестирования с открытым исходным кодом, который делает тестирование производительности простым и продуктивным для инженерных команд. Это бесплатный, гибкий, многофункциональный инструмент, ориентированный на разработчиков.
Используя k6, вы можете тестировать надежность и производительность систем и выявлять регрессии производительности и проблемы раньше. k6 поможет создавать масштабируемые, отказоустойчивые и производительные приложения.
k6 разработан Grafana Labs и сообществом.
Покажите, как нагнетать давление в системе!
На сайте K6 Open Source представлена отличная документация и руководство по эксплуатации. Я лично с их помощью смог за день создать свой первый нагрузочный тест с имитацией 10 000 виртуальных пользователей.
Давайте воспользуемся общедоступным API Rick and Morty, чтобы продемонстрировать, как выглядит нагрузочный тест.
Примечание: Я использую API Rick and Morty только в демонстрационных целях, и я не выполнял приведенный ниже скрипт. Не подвергайте его экстремальной нагрузке, поскольку сайт/эндпоинт созданы не для этого!
import http from 'k6/http';
import { sleep, check } from 'k6';
import { Rate } from 'k6/metrics';
export const options = {
vus: 10000,
//duration: '10s',
};
export let errorRate = new Rate('errors');
export function setup() {
console.log(">>>>>>>>>> STARTING <<<<<<<<<<<<");
}
export default function () {
check(http.get('https://rickandmortyapi.com/api'),
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
let allCharacters = http.get('https://rickandmortyapi.com/api/character');
check(allCharacters,
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
check(http.get('https://rickandmortyapi.com/api/character/'.concat(allCharacters.json().results[0].id)),
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
let allLocations = http.get('https://rickandmortyapi.com/api/location/')
check(allLocations,
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
check(http.get('https://rickandmortyapi.com/api/location/'.concat(allLocations.json().results[0].id)),
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
var allEpisodes = http.get('https://rickandmortyapi.com/api/episode/');
check(allEpisodes,
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
check(http.get('https://rickandmortyapi.com/api/episode/'.concat(allEpisodes.json().results[0].id)),
{
'status was 200': (r) => r.status == 200
}
);
sleep(1);
}
export function teardown(data) {
console.log(">>>>>>>>>> TESTING COMPLETED <<<<<<<<<<<<");
}Весь скрипт выглядит просто. По большей части мы отправляем запрос и проверяем HTTP-код ответа. Если нам понадобится добавить еще один тест, мы просто создадим новый скрипт, копируя существующий, поменяем эндпоинты API и вуаля — у нас есть новый тест. Звучит очень просто. Однако что произойдет, если команда разработчиков внесет изменения в бэкенд? Скрипты наверняка сфейлят, и нам придется вносить изменения непосредственно в файлы тестов. Еще хуже то, что некоторые ресурсы API используются в нескольких скриптах — придется вносить одинаковые изменения в несколько скриптов.
Реализация паттерна Resource Object Model
Для меня, пришедшего из мира автоматизации тестирования, первое, что пришло в голову, это попытаться реализовать в проекте нагрузочного тестирования какой-нибудь шаблон Page Object Model (POM), он же Resource Object Model (ROM). Я знаю, что это, скорее, анти-паттерн, а не реальный паттерн, но мой мозг подсказывает мне сделать это. Я всегда стремлюсь к единому источнику истины, одному месту для всех работ по сопровождению и скриптов, построенных, как Lego, из ранее созданных объектов. Возможно, ROM немного влияет на производительность тестов, но я предпочитаю DRY KISS (Do Not Repeat Yourself & Keep It Short and Simple).
Построение прочного фундамента
Идея создания прочного фундамента проекта основывается на чистой структуре папок/файлов/классов проекта. Давайте создадим такую же структуру папок, как в нашей документации по API:
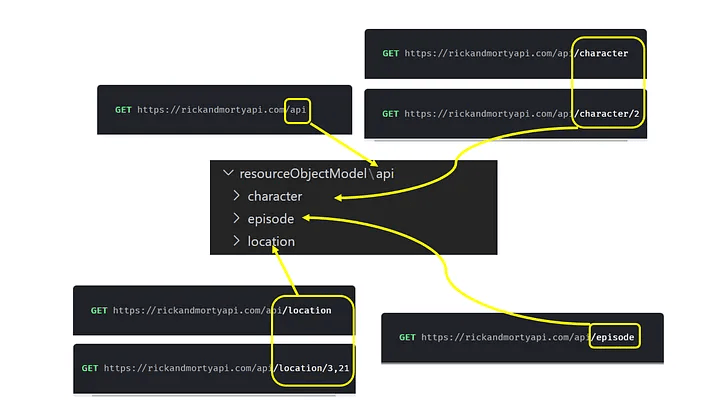
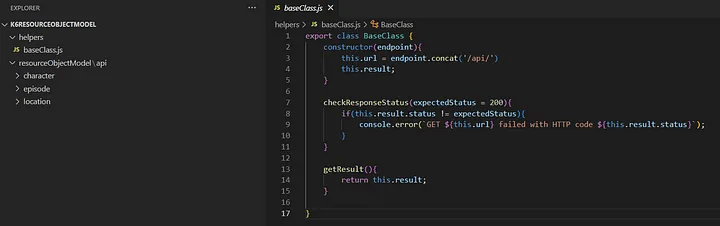
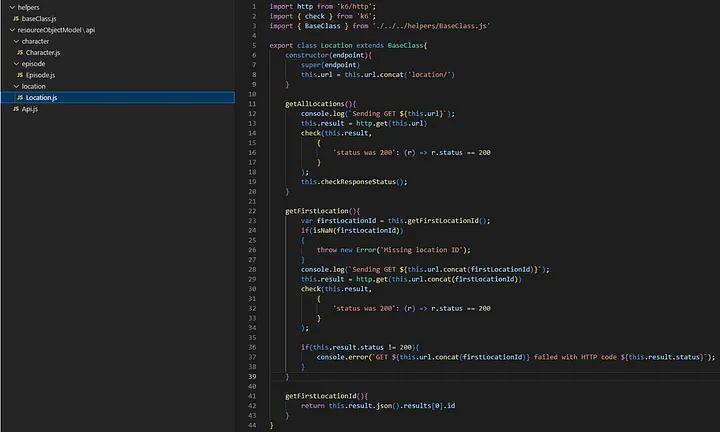
Кроме того, важно иметь папку для хранения всех классов-хелперов, которые будут поддерживать потребности в тестировании. По этой причине я создал папку helper с baseClass.js, в которой будут реализованы общие методы для всех остальных классов, такие как:
Проверка кода состояния ответа API
Получение объекта результата
Создание моделей объектов ресурсов
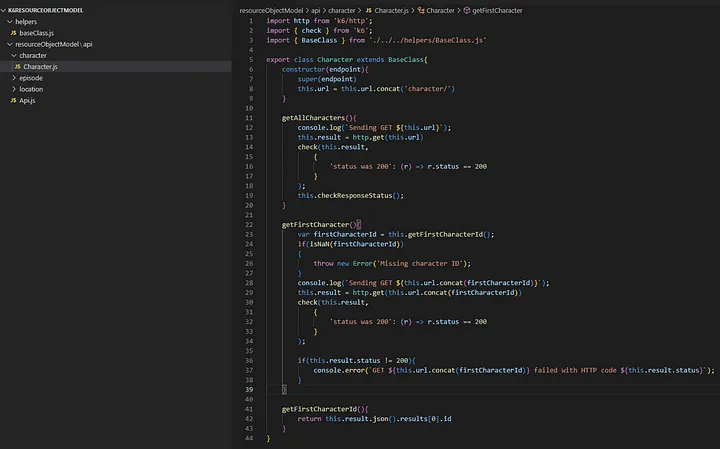
Теперь пришло время создать ROM. Первая из них — "получить все эндпоинты ресурса".
GET https://rickandmortyapi.com/api
Этот ресурс реализует только метод GET, и наш класс ресурса должен реализовать только метод getEndpoints().

В случаях, когда на одном ресурсе реализовано несколько методов, таких как POST, PUT, DELETE и другие, мы не будем создавать новые классы, а добавим их как методы к существующему объекту ресурса с соответствующей реализованной логикой.
Следуя той же логике, теперь мы можем создавать и реализовывать и другие ресурсы.
GET https://rickandmortyapi.com/api/character
GET https://rickandmortyapi.com/api/episode
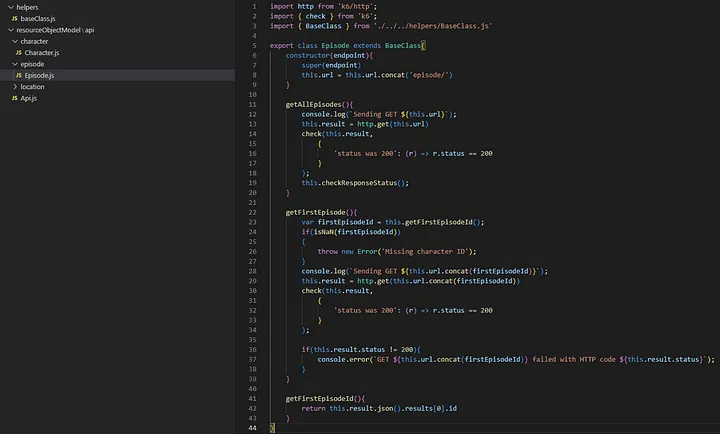
GET https://rickandmortyapi.com/api/location
Что дальше?
Пока все хорошо. Мы создали прочный фундамент для проекта нагрузочного тестирования. Чтобы завершить миссию по созданию простого и повторно используемого фреймворка для тестирования, нужно обратить внимание еще на пару моментов: варианты тестирования (тестовые сценарии) и настройку тестовой среды для выполнения сценариев по требованию. На мой взгляд, все это можно уместить в одном конфигурационном файле.
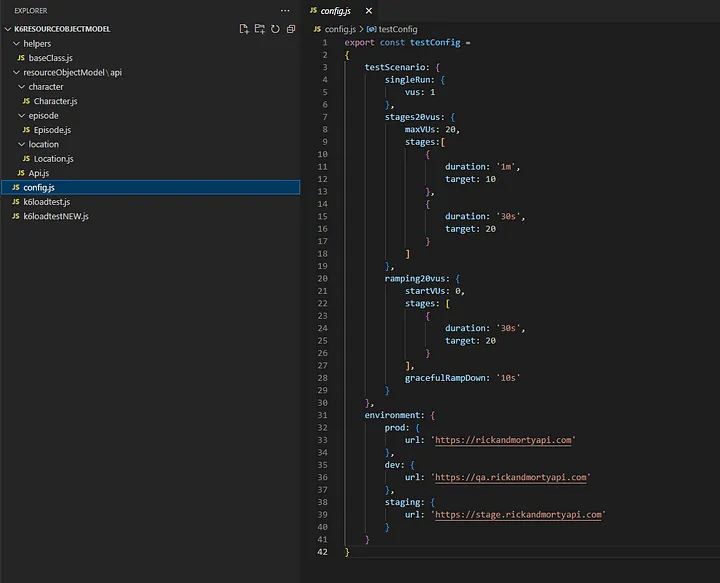
TestConfig JSON имеет два свойства: testScenario для исполнителя и настройки сценария и environment для URL среды и других настроек или возможностей, связанных со средой.
Создание первого теста ROM
В начале этой статьи я показал тест, созданный старым добрым способом. Теперь у нас есть все недостающие части для создания нового теста из повторно используемых объектов ROM. Посмотрите на новый тест на скриншоте ниже.
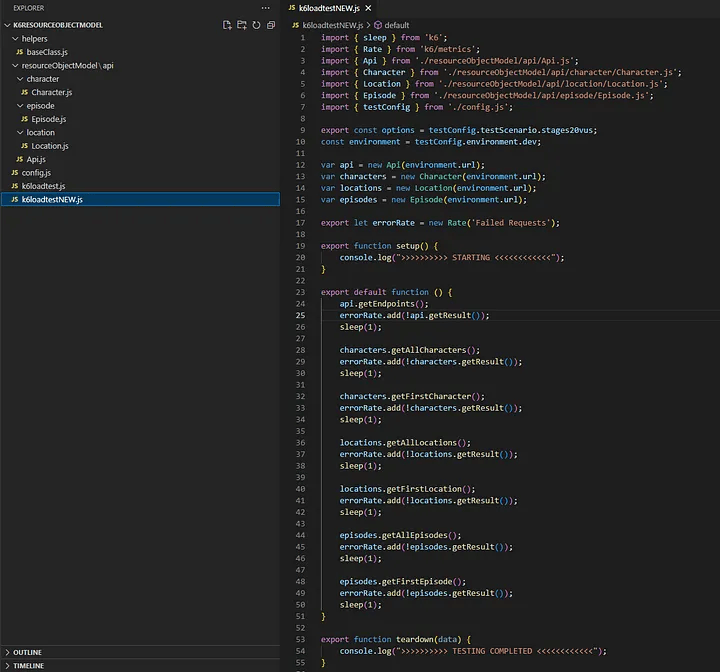
В начале теста мы устанавливаем значение option из свойств файла config.js. Мне кажется, это очень полезно, поскольку IntelliSense дает возможность выбирать из ранее настроенных сценариев тестирования. Та же логика применима к настройке окружения.
После настройки начальных опций и среды мы создаем экземпляры ROM, чьи методы вызываем в функции по умолчанию. Выглядит неплохо, верно? А лучше всего то, что тест имеет уникальный вид «установил и забыл».
Простота — это ключ
В конце концов, моя интуиция относительно ROM меня не подвела, и выбор в пользу простоты, а не сложности, привел к более оптимизированному нагрузочному тестированию. Я уверен, что есть еще хорошие способы достижения того же уровня поддерживаемости и возможности повторного использования. Поделитесь своими вариантами в комментариях. В конце концов, важно постоянно работать над улучшением работы и образа мышления.
Скоро состоится открытый урок, на котором рассмотрим инструменты shift left performance testing и сравним два наиболее популярных из них. Записаться на урок можно на странице онлайн-курса «Нагрузочное тестирование».