
Уважаемые читатели, в этой статье я хочу рассказать о тесте 18 коллекций с и без capacity и поставить точку в данном вопросе. Тесты сделаны на .net 7 с использованием BenchmarkDotNet и представлен полный код для повторения. Базовые значения 1000 и 10_000.
В данной статье не буду сильно углубляться в коллекции, но немного напишу, что да как.
Основная цель понять, насколько важно задавать начальную емкость, даже примерно и насколько все страдает, если так не делать. Сразу отмечу, что на подавляющем большинстве увиденного мною кода практически всегда не задается capacity.
Часть коллекций используется для сравнения, так как емкость там не задается по ряду причин. Мы все их знаем, иногда или всегда используем и, как по мне, стоит глянуть в сравнении как что будет.
Да, не всегда важно, согласен, но секунда дела и улучшить памяти и скорость, чем плохо?
Кратко о коллекциях, где емкость не задается:
Array. Обычный массив. Просто для сравнения с другими;
LinkedList. Связанный список;
SortedSet. Упорядоченная коллекция. Как по мне, так редкая, но пусть будет;
SortedDictionary. Ключ-значение с упорядочиванием по ключу;
ObservableCollection. Имеет сходство с List, но позволяет оповещать внешние объекты про свои изменения;
StringCollection. Коллекция строк, которая мало используется;
StringDictionary. Хэш-таблица исключительно со строками;
ListDictionary. Особенность заключается в реализации интерфейса IDictionary с использованием однонаправленного списка. Официальная документация отмечает, что лучше пользоваться данным вариантом для коллекций, которые не превышают 10 элементов.
Теперь коллекции, где можно задать емкость:
ArrayList. Хранит однородные объекты коллекций. Проще говоря, редко используется, но все же;
List. Надстройка над Array и строгая типизация;
Dictionary. Коллекция ключ-значение;
OrderedDictionary. Аналог Dictionary, только упорядочен;
SortedList. Коллекция ключ-значение с упорядочиванием по ключам;
Queue. Тут все просто. Что первое пришло, то первое обслужено (FIFO);
HashSet. Не содержит одинаковых данных;
Hashtable. Коллекция ключ-значение, но упорядоченная по хэш-коду ключа;
HybridDictionary. Для малых коллекций походит на ListDictionary, а после работает по типу Hashtable;
Stack.Реализует принцип LIFO (был последний вышел первый).
Да, иногда можно индексаторы, но это не в данном тесте.
Проверь себя (скомпилируется или нет? почему?)
Ответ в комментариях приветствуются.
[Benchmark]
public void Span_No_Capacity()
{
Span<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}Полный код можно посмотреть вот тут:
Hidden text
using BenchmarkDotNet.Attributes;
using System.Collections;
using System.Collections.ObjectModel;
using System.Collections.Specialized;
namespace Benchmarks.Benchmarks.Other;
[MemoryDiagnoser]
public class Capacity
{
[Params(1000, 10_000, 100_000, 1_000_000)]
public int NumberCount;
[Benchmark]
public void Array_Capacity()
{
int[] items = new int[NumberCount];
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void LinkedList_No_Capacity()
{
LinkedList<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items.AddLast(i);
}
}
[Benchmark]
public void SortedSet_No_Capacity()
{
SortedSet<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void SortedDictionary_No_Capacity()
{
SortedDictionary<int, int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void ObservableCollection_No_Capacity()
{
ObservableCollection<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void StringCollection_No_Capacity()
{
StringCollection items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i.ToString());
}
}
[Benchmark]
public void StringDictionary_No_Capacity()
{
StringDictionary items = new();
for (int i = 0; i < NumberCount; i++)
{
string item = i.ToString();
items.Add(item, item);
}
}
[Benchmark]
public void ListDictionary_No_Capacity()
{
ListDictionary items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void ArrayList_Without_Capacity()
{
ArrayList items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void ArrayList_With_Capacity()
{
ArrayList items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void List_Without_Capacity()
{
List<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void List_With_Capacity()
{
List<int> items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void Dictionary_Without_Capacity()
{
Dictionary<int, int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void Dictionary_With_Capacity()
{
Dictionary<int, int> items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void OrderedDictionary_Without_Capacity()
{
OrderedDictionary items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void OrderedDictionary_With_Capacity()
{
OrderedDictionary items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void SortedList_Without_Capacity()
{
SortedList items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void SortedList_With_Capacity()
{
SortedList items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void Queue_Without_Capacity()
{
Queue items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Enqueue(i);
}
}
[Benchmark]
public void Queue_With_Capacity()
{
Queue items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Enqueue(i);
}
}
[Benchmark]
public void HashSet_Without_Capacity()
{
HashSet<int> items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void HashSet_With_Capacity()
{
HashSet<int> items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i);
}
}
[Benchmark]
public void Hashtable_Without_Capacity()
{
Hashtable items = new();
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void Hashtable_With_Capacity()
{
Hashtable items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items[i] = i;
}
}
[Benchmark]
public void HybridDictionary_Without_Capacity()
{
HybridDictionary items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void HybridDictionary_With_Capacity()
{
HybridDictionary items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Add(i, i);
}
}
[Benchmark]
public void Stack_Without_Capacity()
{
Stack items = new();
for (int i = 0; i < NumberCount; i++)
{
items.Push(i);
}
}
[Benchmark]
public void Stack_With_Capacity()
{
Stack items = new(NumberCount);
for (int i = 0; i < NumberCount; i++)
{
items.Push(i);
}
}
}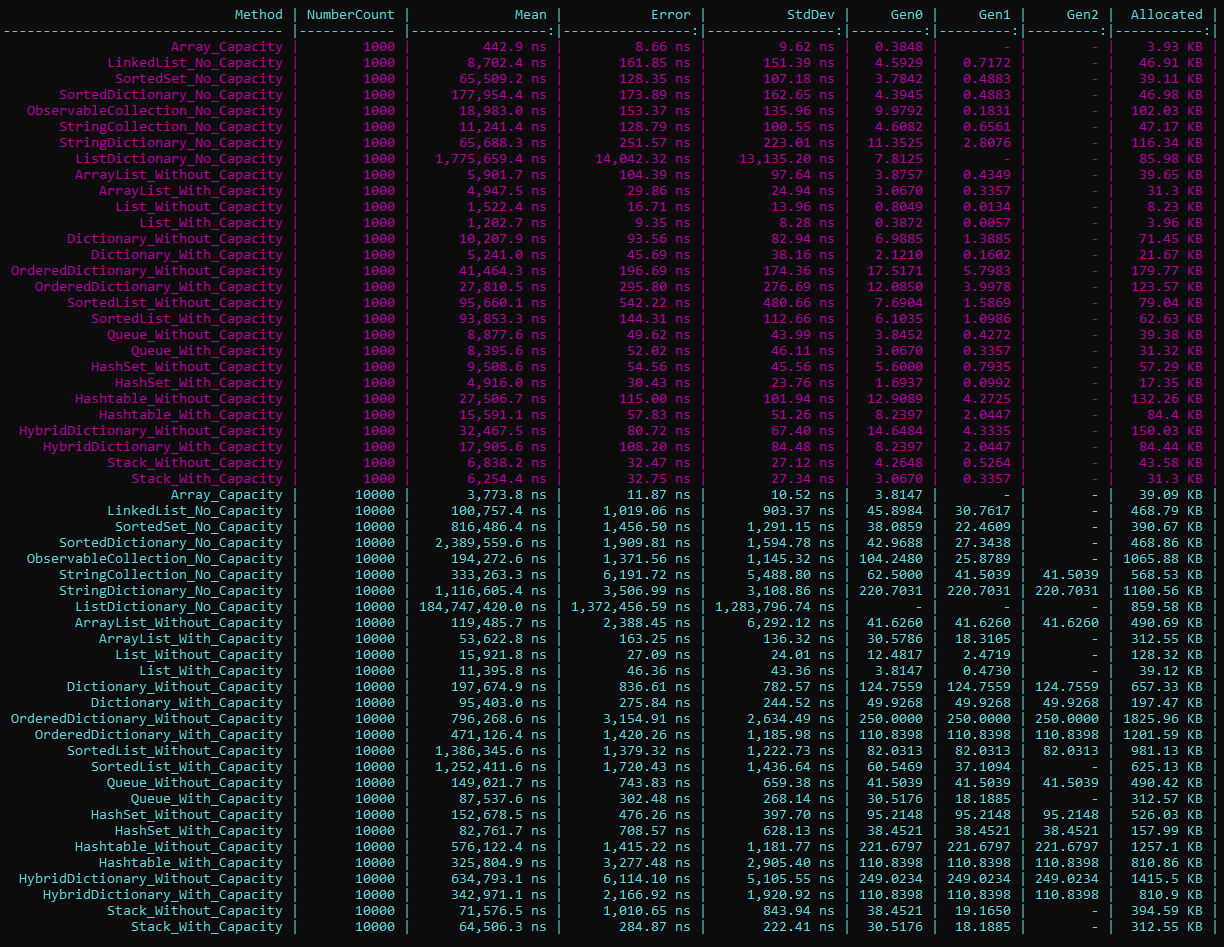
Так что быстрей?
Быстрей уделить секунды и поставить любой, пусть примерный, но все же capacity везде, где возможно. Да, я упустил многое, в том числе StringBuilder и т.д., но там суть та же.
Выводы
Для каждой коллекции вывод един - с capacity лучше, чем без. Вроде очевидно, но теперь вы видите, сколько можно терять времени и памяти, если не делать столь простой оптимизации, используя ту или иную коллекцию.
Цель статьи просто собрать воедино почти все возможные данные на сегодня и сказать, что задавать начальную емкость выгодно не то слово как, но почти никто этого не делает.
В комментариях, кто готов, напишите, а вы реально тратите секунды на такую оптимизацию, что на массе дает в разы круче эффект или все же лучше стековерфлоу и копипаст, где почти никогда не задают емкость, от чего мы все страдаем?
Так как, начнем задавать?
Комментарии (5)

DBalashov
07.06.2023 05:37+2Когда в руках молоток - всё вокруг превращается в гвозди (с)
Ты открыл для себя BenchmarkDotNet? :)
HashSet. Не имеет однотипных данныхКак это понимать? Hashset<T> как раз наоборот является generic-коллекцией и как раз хранит однотипные данные.

devspec
07.06.2023 05:37На самом деле статьи довольно полезные.

shai_hulud
07.06.2023 05:37Аналогичное мнение, может мне сейчас и не надо, а завтра понадобится и найдется через гугл. Не самому же их делать :)
@Geronom побенчмаркай пожалуйста словари/деревья на добавление/удаление/поиск, включая concurrent, в свежем доднете. Маленькие на 100, большие на 1000, и огромные на 10-100к.

sshikov
07.06.2023 05:37фигня это все
Не, ну не совсем фигня, такие измерения имеют право на жизнь конечно.
Фигня знаете в чем? В том что автор меряет в основном время, забывая что он де факто увеличил расход памяти (начальный). И не учитывает очевидный случай, когда заданный заранее (большой) capacity не понадобится. А память меж тем мы уже выделили с запасом. Ну а дальше окажется, что таких коллекций у нас в коде кучка, они ведут себя по разному, а память меж тем мы уже… ну вы помните. Выделили для всех, указали capacity.
И дальше что? Дальше своп, сборка мусора, и все прелести нехватки памяти, да? Ну может и нет, я согласен, всяко бывает. Но вопрос правильной оценки capacity априори автором даже не ставится. А стоило бы.
a-tk
Если бы Вы ещё добавили, почему именно так, было бы гораздо полезнее для джуна. Не все умеют читать документацию.