
Мы ведем техрадар с 2018 года: собираем технологии и инструменты, которые используем в Lamoda Tech, и фиксируем их область применения в компании. В 2018 и 2020 году мы подробно рассказывали на Хабре, с чего начинали и как менялся со временем наш стек.
В этой статье поделимся очередной итерацией и зафиксируем изменения, которых за три года накопилось немало. Скажу прямо: рассказывать о них на большую аудиторию всегда волнительно, но необходимо. Поэтому если вам интересно сверить часы, обсудить тренды или просто подискутировать — велкам)
Оглавление:
В предыдущих сериях
Расскажу о нас в двух словах, чтобы было понятно, о чем идет речь. Lamoda — это крупнейшая в России и СНГ онлайн-платформа по продаже товаров из сферы моды, красоты и лайфстайла, занимает первое место в рейтинге Similarweb в категории «Мода и одежда». Ежемесячно нашими продуктами пользуется 17 млн пользователей в России, Беларуси и Казахстане.
У нас два автоматизированных склада и собственные точки выдачи заказов, своя служба доставки LM Express, контакт-центр в Волгограде, B2B-интеграция с известными брендами и ритейлерами. В Lamoda Tech создаем digital-продукты для пользователей Lamoda, а так же занимаемся автоматизацией бизнес-процессов компании.
За годы существования (с 2011 года) мы накопили наследие, которое в последние годы нам удалось переложить на современные рельсы и начать активнее развивать продукт.
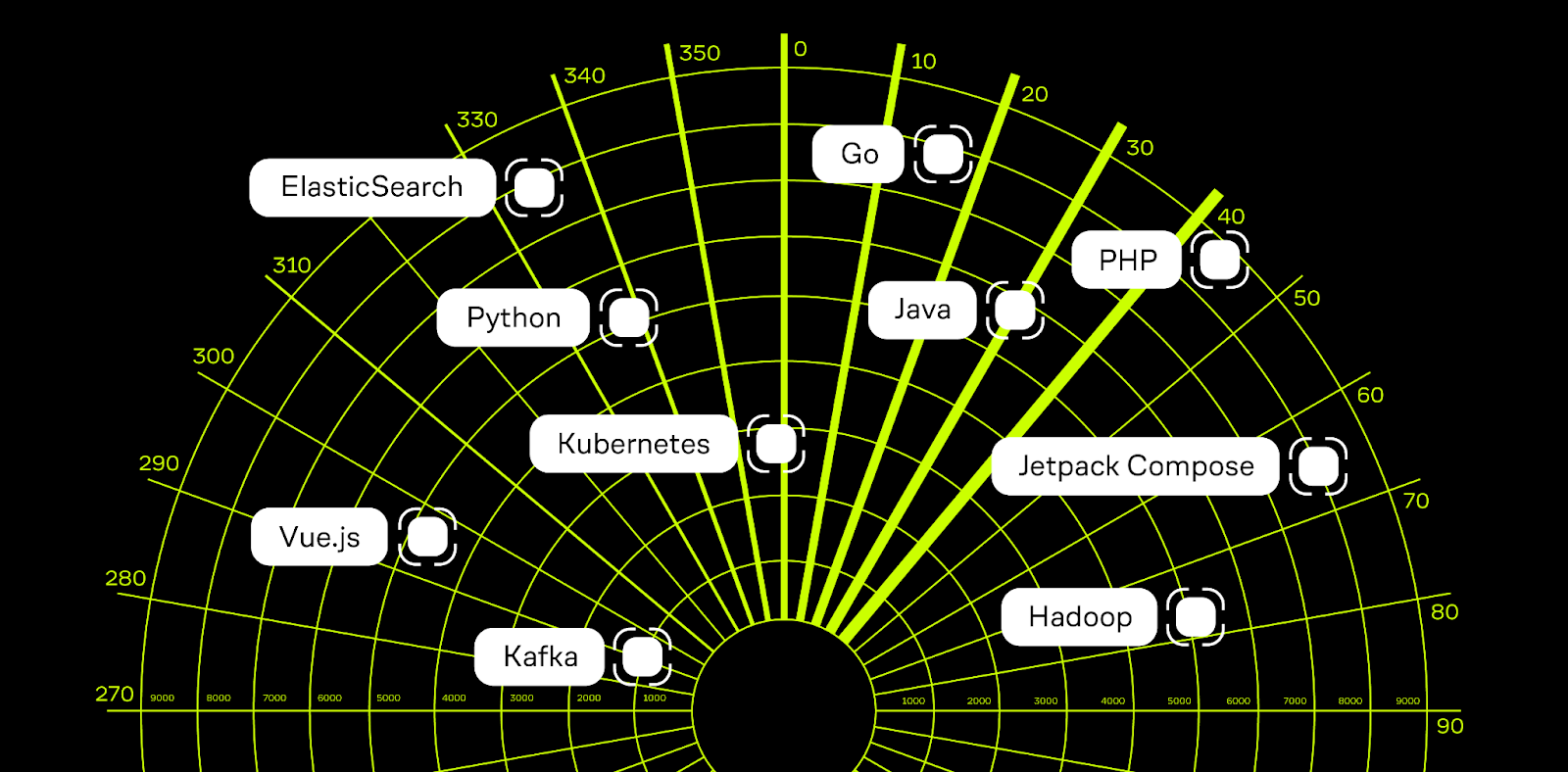
Ок, перейдем к делу и посмотрим на то, как выглядит техрадар Lamoda Tech сегодня.
Я не буду сухо перечислять смену фреймворков и вендоров в каждой категории, а постараюсь посмотреть на картинку сверху — и расскажу о больших процессах, которые сейчас происходят в нашей разработке.
Напомню, что означают четыре слоя (статуса принятия технологии) на радаре:
ADOPT — это технологии и инструменты, которые внедрены и активно используются;
TRIAL — технологии и инструменты, которые уже прошли этап тестирования и готовятся к тому, чтобы работать в продакшене (или даже уже работают там);
ASSESS — инструменты на уровне эксперимента, которые в данный момент оцениваются и пока не влияют на продакшн. С их участием реализуются только тестовые проекты;
HOLD — в этой категории у нас есть экспертиза, но упомянутые инструменты используются только при поддержке существующих систем — новые проекты на них не запускаются.

Продолжаем переход на Go
Сейчас Go является для нас основной платформой: все новые сервисы мы пишем на нем, а также постепенно переводим на него существующие PHP-сервисы. Golang — удобный инструмент, он был изначально создан для написания небольших и быстрых программ, а это отлично подходит для построения сервисно-ориентированной архитектуры, которую мы используем в работе. Также Go дает прирост производительности при минимальных затратах на оптимизацию.
Легко догадаться, что мы любим Go и планируем вкладываемся в сообщество. Разрабатываем тулинг для быстрого создания и тестирования сервисов, написали opensource-инструмент для их тестирования — Gonkey — и сейчас добавили в него больше возможностей для работы с моками, проверки и оптимизации. Создали внутренний (пока что) инструмент для генерации проектов — Scratch. Нанимаем большое количество разработчиков, в том числе junior-уровня.
Фронтенд: Vue.js и эксперименты с BFF
Главное во фронтенде — перевод всего JS-кода на Vue. Сперва это была вторая версия, потом, когда Vue 3 стал стандартом на официальном сайте, мы решили сразу делать все на нем, чтобы потом не переписывать. Мы перевели весь процесс сборки проекта с webpack 4 на Vite, что, в первую очередь, упростило конфигурации сборщика, а во-вторую — значительно уменьшило время пересборки проекта в процессе разработки и время полной сборки билда.
Процесс занял почти полгода. Правда, еще не все компоненты перешли на Composition API: мы в процессе. Также внедряем TypeScript, и в ближайшее время сделаем его обязательным для новых фичей.
Нам интересно двигаться в сторону BFF — Backend For Frontend: мы видим, что этот подход становится все более популярным. И чем крупнее компания, тем больше нужна эта прослойка в сервисе. Сейчас смотрим в сторону Nuxt 3 и небольшими шажками подстраиваем весь проект под его инфраструктуру и API. Но мы пока только движемся в эту сторону и думаем, действительно ли нам это нужно.
Основные страницы Lamoda перешли на SPA, также на некоторых страницах мы внедрили SSR на Node.js в качестве теста.
Мобильная разработка
У нас здесь есть несколько трендов, общих для iOS и Android. В первую очередь это модуляризация: все новые фичи мы создаем в отдельных модулях и постепенно разделяем всю функциональность наших приложений. Большая часть работы уже проделана, но она продолжается.
Также активно продвигаем декларативный подход к описанию UI: он позволяет видеть изменения в UI без компиляции и запуска. В больших проектах каждая компиляция — это десятки или сотни секунд ожидания, и декларативный подход действительно облегчил разработку. Сейчас мы используем Jetpack Compose для описания UI в Android и SwiftUI на iOS.
Теперь о различиях.
Android
В архитектуре Android все переходит в реактивность: это позволяет эффективнее работать с потоками данных и реагировать на входящую информацию. Плюс это отлично дружит с новыми интерфейсными концепциями, поэтому мы двигаемся в сторону MVVM-архитектуры.
Совместно с дизайнерами активно развиваем нашу дизайн-систему. Сейчас у нас есть специальные экраны в приложении, где дизайнеры и разработчики могут посмотреть и потрогать основные дизайн-компоненты, а также переиспользовать их.
За последние несколько лет покрыли большую часть нашего приложения UI-тестами. Пишем их с помощью Kaspresso.
К слову, мы любим пробовать новые интересные библиотеки и плагины. Последнее, что интегрировали — Relay, плагин для генерации Compose-функций из дизайна в Figma. Этот эксперимент у нас еще в процессе.
С 2020 года мы публикуем наше приложение в магазине приложений App Gallery от Huawei. Компанию отключили от сервисов Google, и у них появился свой маркет. Нам нужно было быстро адаптироваться под эту ситуацию: теперь наше приложение можно легко скачать и установить на устройства от Huawei. Мы рассказывали об этом в статье.
iOS
Разработка приложения на iOS за два года сильно изменилась. Значительно ускорилось время компиляции, несмотря на то, что количество фич, а значит, и кода, увеличилось многократно. Этого удалось достичь в первую очередь благодаря разбиению проекта на SPM-пакеты. Теперь новичкам гораздо проще изучать проект, а более опытным разработчикам — релизить новые фичи и покрывать их тестами.
С увеличением команды и растущим потоком фич необходимо было упростить и написание тестов. Для этого нам помогли библиотеки Quick и Nimble, которые позволяют писать тесты гораздо быстрее и компактнее.
Кроме этого, мы начали внедрять дизайн-систему и разрабатывать отдельное приложение-песочницу для дизайнеров полностью на SwiftUI. Это позволит в будущем быстрее переводить часть фич из UIKit на SwiftUI.
Глобальная проблема всех больших приложений на iOS — поддержка старых версий. Наличие iOS 12 сильно тормозило нас, но в самое ближайшее время мы планируем отказаться от ее поддержки — и уже думаем об отказе от iOS 13. Это откроет нам новые возможности.

Тестирование: автоматизация и новые инструменты
Frontend
В конце 2019 года мы переехали с Jest+Puppeteer на Codecept JS+Puppeteer, и сейчас активно используем их в наших тестах. Puppeteer упрощает начало работы по автоматизации браузера, управляя Chrome с помощью нестандартного протокола DevTools. Пока автотесты для десктопа и мобильного сайта — это некий помощник, которыми покрыты только самые критичные моменты, например, релизы. Если бы мы это проверяли руками, у нас бы ушел на это целый день, а автотесты прогоняются за 20 минут. Мы постоянно ищем новые подходы, и сейчас добавили возможность покрытия аналитики прямо внутри автотестов.
Mobile
Начали писать автотесты для приложений. Для Android мы делаем это с помощью Kaspresso и языка программирования Kotlin, и неплохо продвинулись: с конца 2020 года написано около 200 автотестов. Сейчас у нас в планах автоматизировать аналитику, которая тяжело тестируется.
На iOS мы создали инфраструктуру для автотестов на базе фреймворка XCUITest и языка Swift. Написали некое подобие своего фреймворка поверх XCUI-теста и сделали так, что автотесты на iOS сильно похожи на автотесты на Android — так удобнее для наших тестировщиков.
Backend
Что касается бэкенд-инструментов. Очень больно после ухода Postman: пропала возможность его оплачивать, поэтому мы пользуемся только штатной версией. Основная проблема — отсутствие киллер-фичей. Например, раньше у нас была возможность делиться своими коллекциями, а в бесплатной версии коллекции хранятся только локально. Никакого альтернативного решения нет, потому что у нас строгие требования к безопасности, и мы не можем взять решение без авторизации.
Мы долгое время пользовались TestRail, а теперь переходим на Test IT. По сути, это аналогичная тест-менеджмент система, тут нет роста в плане функциональности — это просто переход из схожей системы в схожую.
Будущее тестирования плотно завязано на развитии тестовых стендов. У нас сейчас такая ситуация, что монолиты мы тестируем автоматически почти на всех уровнях. В микросервисах, чтобы протестировать, например, процесс движения заказа по внутренним системам, нам нужно развернуть все в тестовой инфраструктуре. И нам нужно продумать фреймворк для стабильной работы. Создание такого инструмента пока только у нас в планах.
Big Data & Machine Learning
За последние 3 года у нас существенно возросло количество ML-решений и пайплайнов, которые их поддерживают. В качестве оркестратора процессов обработки больших данных продолжаем активно использовать Apache Airflow: с его помощью данные из различных внешних систем загружаются в Hadoop, регулярно запускаются процессы построения признаков и обучения моделей, а также рассчитываются продуктовые метрики и АБ-репорты.
Для разработки пайплайнов машинного обучения используем PySpark и Python — оба 3-й major-версии, а в качестве основных ML библиотек (фреймворков) — CatBoost и PyTorch. Для экспериментов с Deep Learning моделями используем Yandex DataSphere, где есть возможность арендовать необходимое нам кол-во GPU.
С продуктовой точки зрения мы продолжаем идти в сторону персонализации Lamoda под каждого клиента. Для этого учимся заворачивать ML-модели в сервисы и применять их в онлайне под нагрузкой: уже сейчас персонализация отлично работает в каталоге и основывается на предпочтениях конкретного пользователя. Впереди еще много работы и задач, связанных с надежным и эффективным масштабированием data-driven продуктов — и этим задачам в ближайшее время мы планируем уделить отдельное внимание.

Миграция в облака во всех системах
Текущую инфраструктуру, которая у нас располагается в ЦОДах, мы постепенно переносим в облако, используя как lift-and-shift подход, так и разворачивая новую инфраструктуру в PaaS.
Чтобы код хорошо работал на облаке, мы меняем и его инфраструктуру. Например, пишем модули: это расширяет функциональность и дает возможность переиспользовать модули в разных частях инфраструктуры.
В следующие два года планируем рост использования методологии GitOps. Все сервисы, которые так или иначе относятся к разработке — анализ кода, сборщики кода, инструменты, которые деплоят код, — они будут разворачиваться в виде управляемых ресурсов или в виде инфраструктурного кода.
Мы уйдем от стандартной модели виртуализации, где большинство сервисов — это виртуальная машина. И придем к системе, связанной с управляемыми ресурсами в облаках. Да и в целом облачные технологии будут появляться не только в разработке ПО, но и в data-аналитике, и в маркетинге: их использование выйдет на новый уровень.
Поиск новых вендоров
Сейчас мы находимся в процессе замещения части софта, который у нас был до этого, на альтернативы. Это касается продуктов Microsoft, Oracle и ряда некоторых вендоров: ищем замену, чтобы не потерять в качестве, надежности и всем остальном.
Например, сейчас достаточно много функциональности, связанной с хранилищем данных, у нас обеспечивается одним продуктом — Oracle Database. Это сердце хранилища, которое совмещает три направления: система хранения данных, система обработки данных и система распространения данных. Мы хотим построить новую платформу данных, опираясь на продукты, которые позволят сделать не хуже, чем у нас есть сейчас, — а может быть, даже лучше.
На новой платформе планируем использовать несколько решений, которые будут отдельно хранить, считать, распространять, визуализировать, управлять и отвечать за безопасность и мониторинг. Как и многие сейчас, мы нацелены на Yandex Cloud. Это будущее, и у нас есть время на то, чтобы подробно спроектировать новую платформу и основательно подойти к выбору продуктов.
Во внутренних учетных системах мы планировали перейти на Microsoft Dynamics 365 finance and operations, но решили остановиться на миграции только операционного контура, а финансовый блок перевести на платформу 1С. В Dynamics появилось много нового с технической стороны: новая среда разработки, visual-студия, единая среда отладки для любого кода на уровне клиент-сервера. Axapta принесла новые функциональные модули — например, Electronic Reporting: целый модуль для работы с электронной отчетностью.
Заключение
Мы ведем техрадар довольно давно, с 2018 года. И каждое его обновление, на самом деле, — это честный, хоть и очень болезненный, взгляд на самих себя. Что у нас есть? Сделали ли мы то, чего хотели? Кто мы сейчас?
Делиться техрадаром на большую аудиторию тем более волнительно. Но мы считаем, что делиться нужно. Видеть его полезно не только нам, но и другим компаниям и разработчикам — чтобы понимать рынок, оценивать уровень своего и чужого развития и выбирать направление, куда двигаться дальше.
Нас техрадар держит в тонусе, каким бы он ни был.
Поэтому — продолжаем наблюдения.
Комментарии (11)


aleks_raiden
11.07.2023 10:50+1Вместо Postman есть, к примеру, Insomnia

k_claim
11.07.2023 10:50+1У Insomnia нет SSO, а это в больших компаниях зачастую является требованием для безопасности.

tyrus_rus
11.07.2023 10:50+2Нам интересно двигаться в сторону BFF — Backend For Frontend: мы видим, что этот подход становится все более популярнымЗвучит слегка иронично: Ламода старается следить за модой в архитектуре web технологий.
Но не следует слепо идти за модой, даже если в каждом утюге об этом свистят. BFF - это прошлое, как треуголки. Да - было красиво, да - было полезно, но ТОГДА, с тем интернетом, с теми браузерами и теми стеками. Сейчас у вас есть WASM, сокеты и возможность исследование новые способы рендеринга в браузере (не через JS - вспоминаем картинку как он работает). Не надо смотреть назад - смотрите вперед и не бойтесь экспериментировать с чем то новым (у вас же наверняка куча программистов C++). Это будет гораздо интереснее читать. И возможно вы станете новым законодателем моды :)
По BFF. Вам не хватает контрактов? Вы запутались в этом зоопарке? Так сходите к фронтам, у них этого гораздо больше! и ниче, справляются. Вам на бэке это тяжело поддерживать? Поэтому я топлю чтобы в простых проектах B4F фронтеры сами его себе писали на (хоты бы даже) ноде. Это получается и просто и работает (часто даже с общшим кодом фронта и бэка). Вариантов куча.
BFF - это еще и перекладывание части головной боли с фронта опять же на бэк. Но зачем? Ваш фронт не справляется? Значит что-то не так на фронте (или в людях или пора менять архитектуру). ИМХО бэк должен заниматься только и только данными, и ничего не знать о фронте и его зоопарке девайсов, компонент и т. п.
Еще использование BFF говотрит о том что явный перекос в силах команд в сторону бэка. Но опять же это не значит что надо отдавать им флаг и пусть рулят. Эт сигнал что надо усиливать фронт-команду
beDenz
11.07.2023 10:50+1Еще использование BFF говотрит о том что явный перекос в силах команд в сторону бэка.
Здесь вы попали прямо в точку. В латехе действительно большой перекос в сторону бэкенда. Причина проста - это работа с тремя платформами(web, android, ios) которые должны работать синхронно и максимально идентично. Поэтому концентрация бизнес логики на бэкенде решает вопрос дублирования этой логики на клиентах и вопрос поддержки, проблема физического обновления приложений на смартфонах все еще актуальна: многие пользователи не спешат обновляться на более свежие версии.
Но не следует слепо идти за модой
Скорее не погоня за модой, а исторически сложившаяся ситуация. Когда, то у каждой платформы был свой бэкенд. Потом появился единый api для мобилок. Но как оказалось, в нем не было учтено весь функционал web-платформ. Поэтому приходиться поддерживать bff для агрегации данных с разных сервисов.
Поэтому я топлю чтобы в простых проектах B4F фронтеры сами его себе писали на (хоты бы даже) ноде.
Так оно и получилось, что bff по большей части ушло в ответственность фронтов. Пока там go, но в планах есть переход на nodejs. Если конечно, раньше не получится переход полностью на единый api, в эту сторону сейчас идет активное движение

trawl
По поводу Postman:
Если пользуетесь продуктами JetBrains, можно использовать их встроенный http-клиент. Где-нибудь в проекте создаёте папочку, кидаете туда файл с окружениями
http-client.env.json:Добавляете его в
.gitignore, чтобы свои токены не светить.Создаёте файл с запросами
Открываете этот файлик в IDE, слева от каждого запроса появляется кнопочка
run(зелёный треугольник).Вверху в выпадашке
Run with:выбираете свойenv(в моём случаеmy-env), жмётеrunи смотрите ответ.Коллекции запросов можно прямо в репе и хранить, если нужно их шэрить
JetBrains, конечно тоже России рукой махнули, но у многих остались fallback-лицензии
sherbinko
Действительно, всегда удивляло: зачем вообще люди используют postman вместо удобного клиента от JetBrains. А автоматизированные тесты проще в той же Java-е написать
micronull
Так же поддерживаются e2e тесты, gRPC, есть консольная версия и docker image.
Мы у себя к сожалению пока пользуется postman, из-за того что они значительно опередили jetbrains и мигрировать будет больно.
Поддержка вполне работает и оплачивать картами иностранных банков по прежнему можно.
k_claim
Спасибо за подробное описание. У нас есть сервисы где команды решили пойти по этому пути и успешно пользуются этим DSL.
Этот подход предполагает хранение "коллекций запросов" в репозитории приложения. Postman же предлагает решение с централизованным хранилищем, которое в довесок включает в себя пространства команд и другие плюшки (например, генерация коллекций по сваггеру).
У нас львиная доля работы с Postman - это межсервисные флоу, потому когда-то его и выбрали. Чтобы достичь того же с решением JetBrains, нужно создать единый репозиторий и поддерживать его. Теперь, конечно, это касается и Postman.
Но есть еще один важный момент - чтобы перейти на решение JetBrains, нужно переписать все коллекции. Зачем, если следующий шаг будет тот же?