
Привет, меня зовут Даша, я отвечаю за ранжирование в команде поиска Uzum Market. За время существования нашей команды мы успели накопить достаточный багаж факапов знаний, чтобы начать делиться им с вами.
Поиск — один из основных источников дохода маркетплейсов. Сценарий, где пользователь приходит на платформу с конкретной целью приобрести товар гораздо более вероятен, чем тот, где он зашел полистать ленту.
Ежедневно сотни тысяч пользователей полагаются на поиск Uzum Market, чтобы найти нужные им товары. Наша цель как команды, ответственной за поисковый движок, — предоставить им лучший сервис и помочь найти именно то, что они ищут.
С каждым днем количество товаров в нашем маркетплейсе растёт, и если раньше мы показывали десятки релевантных товаров по одному поисковому запросу, то сейчас их уже тысячи. Как правильно отранжировать товары, чтобы пользователь дошёл до чекаута? Какие данные нужны, чтобы определить релевантность товара по запросу? На какие метрики ориентироваться, чтобы измерить качество поиска?
На эти и другие вопросы мы пытаемся ответить ежедневно. И сегодня я приоткрою завесу над некоторыми решениями, которые мы уже реализовали на нашей площадке, а также расскажу про боли и трудности, с которыми пришлось столкнуться на пути к статистически значительным изменениям в метриках.
Велком всех под кат в увлекательное путешествие по внутренностям поиска Uzum Market!
Общий пайплайн поиска
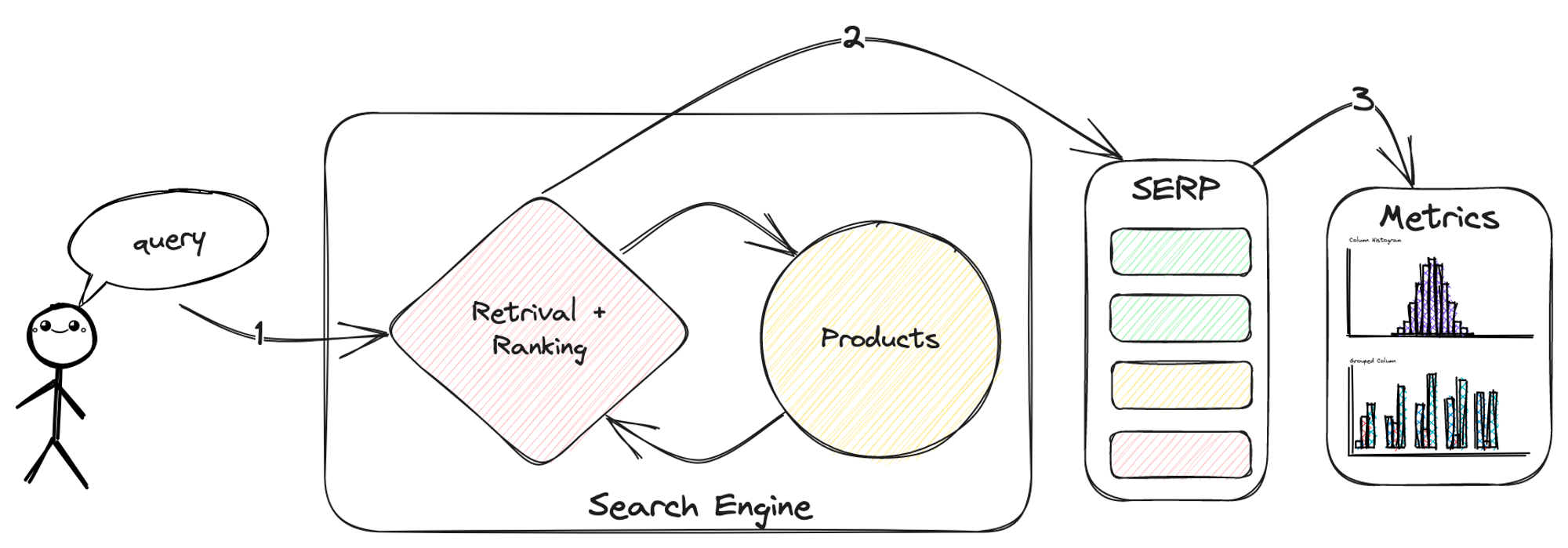
Пользователь отправляет текстовый запрос в поисковую систему (1), которая в свою очередь извлекает наиболее релевантные товары и представляет их в виде отранжированного списка SERP — search engine results page (2). Затем пользователь решает, удовлетворяет ли этот список его потребности, что уже напрямую влияет на ключевые бизнес-метрики (3).
Что означает удовлетворенность пользователя поисковой выдачей и кто такие релевантные товары, мы разберем с вами далее. А сейчас давайте переформулируем абзац выше в виде задачи, которую мы пытаемся решить.
Имея запрос q и набор товаров P, нам нужно упорядочить элементы P таким образом, чтобы результирующий отранжированный список максимизировал показатель удовлетворенности пользователей.

Поиск, in general, можно разделить на несколько составляющих этапов:
1. Retrieval — этап получения всех релевантных товаров по запросу. На этом этапе с помощью поисковых движков (например, ElasticSearch, Solr и т. д.) мы получаем набор товаров и отвечаем на вопрос: были ли нами получены все товары, релевантные этому запросу?
2. Ranking - этап ранжирования релевантных товаров из первого этапа. На данном этапе ранжируем результаты, найденные на предыдущем этапе и отвечаем на вопрос: «Какие из найденных нами товаров наиболее релевантны запросу»?
3. Re-ranking - этап реранжирования топ N товаров из прошлого этапа. На данном этапе с помощью ML-модели реранжируем топ N товаров. Этапов реранжирования может быть несколько, с каждым шагом значение N уменьшается, а сложность модели растет.
Четвёртым этапом можно добавить реранжирование товаров на основе бизнес-факторов. Этот этап включает предпочтения, которые модель выучить не может, а бизнес очень хочет. В качестве примера можно привести буст товаров, которые учавствуют в маркетинговой промо акции.
Как удовлетворить пользователя?
Мы с вами определились с этапами пайплайна поисковой системы. Остается вопрос, как же это мерить? Пора определиться с понятием удовлетворенности пользователя.
На самом деле этот термин очень тесно связан с другим уберважным понятием мира поиска — релевантностью. Та самая удовлетворенность пользователя может быть легко переведена в понятие релевантности товаров, которые мы показываем по тому или иному запросу. И снова встает вопрос: «А как понять, что данный товар релевантен данному запросу?».
Проблема релевантности — генерализация субъективных оценок ваших покупателей. Помните, что вы не целевая аудитория и, если вам кажется, что выдача не совсем релевантна, возможно это не так. Именно по этой причине использовать асессоров для получения таргета в задачах поискового ранжирования не всегда хорошая идея. У вас есть кликстрим — используйте его! Пользователь уже оставил след в ваших логах, и теперь вы с легкостью можете разметить данные и обучить модель.
Кликстрим - фрейморк, помогающий компании в короткие сроки начать процесс анализа пользовательского поведения в продукте и монетизации этих знаний. Кликстрим позволяет нам получать фидбек от пользователей, но нам также нужно учитывать оценку текстовой релевантности товаров. Это приводит нас к понятию фичей, которые помогают определить эту самую релевантность. Такие фичи можно разделить на две большие группы:
явные и неявные пользовательские сигналы — клики, добавления в корзину, избранное, покупки и т.д.;
фичи текстовой близости.
Сбор и использование таких фичей является более масштабируемым процессом, который можно гибко настраивать под ваших юзеров, улучшая их пользовательский опыт.
Какие этапы отбора кандидатов есть у нас в Uzum Market?

В основе поиска Uzum Market — ElasticSearch, который умеет делать многие вещи прямо из коробки.
Retrival этап у нас в эластике реализован с помощью одного параметра под названием minimum_should_match. Он позволяет указать минимальное количество условий в запросе, которое должно выполняться, чтобы товар считался релевантным.
В нашем случае 100% слов в запросе должны быть в названии товара, иначе этот товар не попадает в набор для ранжирования. В случае, когда с таким условием эластик возвращает нам пустую выдачу, мы понижаем этот параметр до 70%.
Исторически для ранжирования ElasticSearch использует алгоритм Okapi BM25 [1] — Tf-idf на максималках. Он учитывает, сколько слов в запросе соответствует текстовым полям, по которым выполняется поиск в индексе. Редкие совпадения и совпадения по более коротким словам дают более высокий показатель релевантности.
В пайплайне нашего поиска на всех этапах с разными коэффициентами и весами используются фичи текстовой близости или BM25 фичи, которые учитывают не только запрос и название товара, но и название категории, синонимы запроса, фильтры, а также полный путь категорий.
Системы текстового матчинга хорошо справляются с задачей поискового ретривала, но они не учитывают фичи товара, а также явные и неявные пользовательские сигналы. Для улучшения релевантности результатов поиска нам нужно оптимизировать порядок, в котором отображаются товары.
В идеальном мире мы бы обучили state-of-the-art нейронку, способную переранжировать все товары из этапа ретривала за несколько миллисекунд. Но в реальности мы сталкиваемся с ограничениями производительности поискового движка, которые не позволяют нам реализовать такое решение. Вместо этого для второго этапа ранжирования мы используем простую логистическую регрессию, которую внутри команды мы также называем линейной формулой ранжирования.
Линейная формула ранжирования
На этапе ранжирования всего набора релевантных товаров из ретривала нужен простой и понятный алгоритм, который будет быстро работать, а также показывать неплохой результат. Напомню нашу цель: мы хотим поднять наверх топ N релевантных товаров, которые попадут на следующий этап и будут реранжироваться уже умной ML-моделью.
Самый простой алгоритм — это логистическая регрессия. Добавляем в формулу логистической регрессии параметры товара, а затем каждый параметр домножаем на соответствующий буст, который в свою очередь определяет «важность» товара. Чем больше буст у параметра, тем больше этот параметр влияет на общий score товара в выдаче, по которому происходит ранжирование.
Изначально в качестве параметров (фичей) мы использовали только текстовую близость, и наша линейная формула выглядела так:
score := float64(0)
score += product_title_boost_uz * bm25_product_title_uz
score += product_title_boost_ru * bm25_product_title_ru
score += category_title_synonym_boost_ru * bm25_category_title_synonym_ru
score += category_title_synonym_boost_uz * bm25_category_title_synonym_uz
score += category_title_boost_ru * bm25_category_title_ru
score += category_title_boost_uz * bm25_category_title_uz
score += full_name_boost * bm25_full_name
score += category_full_name_boost * bm25_category_full_nameПриложение Uzum Market является билингуальным, то есть работает на двух языках: русском и узбекском. Все названия категорий и товаров имеют две фичи BM25: одна с постфиксом "ru" для русского языка и другая с постфиксом "uz" для узбекского языка. Последние два параметра, которые мы используем, называются "full_name". Они представляют собой сконкатенированные поля для обоих языков, а также фильтры и ключевые слова, относящиеся к соответствующему товару или категории. Это позволяет нам обеспечивать более точный поиск для пользователей вне зависимости от их языковых предпочтений.
А как подобрать эти бусты?
Один из подходов, которые мы пробовали, — обучение логистической регрессии и использование ее коэффициентов в качестве бустов. Этот подход можно усложнить, используя разницу в фичах между двумя товарами или pairwise подход [2]. Результаты этих экспериментов мы не будем рассматривать в рамках сегодняшней статьи. Скажу только, что подход неплохо работает, когда в линейной формуле вы используете другие фичи, помимо BM25. Внутри одного запроса товары скорее всего будут иметь схожие значения BM25 фичей, и эластику будет сложно отранжировать ваши товары.
Хочу еще раз подсветить, что текстовый матчинг сам по себе недостаточен для точного ранжирования. При первом запуске мы столкнулись с тем, что в топ-1000 товаров, которые реранжируются более сложной ML-моделью, попадали товары с низким или отсутствующим рейтингом, но имеющие схожие названия с запросом. Бизнес был недоволен, и нам нужно было найти быстрое решение. Для устранения товаров с низким рейтингом из топа мы добавили рейтинг как фичу в нашу линейную формулу.
Теперь, помимо 8 фичей BM25, мы учитываем рейтинг товара, в частности, байесовский рейтинг [3]. Пример формулы для расчета байесовского рейтинга может быть следующим:
Bayesian Rating = ( (C * m) + (avg * sum) ) / (C + sum)где:
C— коэффициент, который определяет вес среднего рейтинга относительно общего количества отзывов;m— минимальное количество отзывов, необходимое для учета товара при расчете рейтинга;avg— средний рейтинг всех товаров;sum— сумма рейтингов выбранного товара.
На этом этапе добавление бОльшего количества фичей не имеет смысла, поскольку все они будут учитываться на этапе реранжирования. Таким образом, включение рейтинга товара оказалось эффективным способом улучшить качество ранжирования без излишней сложности.
Итоговый скор линейной формулы ранжирования состоит из параметров текстовой близости и байесовского рейтинга.
Какую метрику для оценки ранжирования ретривала выбрали мы?
Recall@k - метрика, которую мы мерим на этом этапе по нескольким причинам:
позволяет оценить долю релевантных товаров, которые были обнаружены в топ-k результатов поиска;
стабильна и хорошо усредняется по различным запросам;
Мы считаем товар релевантным в рамках поисковой сессии, если пользователь совершил целевое событие (клик/добавление в корзину/покупка). Параметр k определяет, сколько первых товаров из результатов поиска учитываются при расчете Recall.
Представим, что наше целевое событие — покупка, тогда значение Recall@k для каждой сессии рассчитывается по формуле:
recall_k = 0
for query in queries:
query_weight = sessions_with_query_num / total_sessions_num
recall_k += query_weight * items_ordered_in_session_k / items_ordered_in_sessionгде:
queries— набор уникальных запросов, для которых мы считаем метрику;query_weight— частота запроса;sessions_with_query_num— количество сессий с запросом;total_sessions_num— количество всех сессий;items_ordered_in_session_k— число купленных товаров, входящих в топ-k;items_ordered_in_session— общее число товаров, купленных в рамках сессии.
В случае, если ваш ретривал содержит несколько тысяч документов, а реранжируете моделью вы только топ-100, в итоговый SERP может не попасть часть релевантных товаров. Именно поэтому оптимизация исходного этапа ранжирования является важным шагом на пути к LTR реранжированию.
Learning to rank

Поскольку задача LTR ранжирования хорошо описана во многих статьях [4], мы можем опустить теорию и сразу перейти к тому, как этот этап реализован у нас.
Для первой итерации мы использовали готовый LTR плагин [5], который был создан командой OpenSearch специально для ElasticSearch, чтобы уменьшить time-to-market и нагрузку на бэкенд команду. Мы обучили Xgboost Ranker модель c pairwise loss-ом, которая аппроксимирует NDCG@40 и прогнозирует оценку релевантности для каждого товара. Далее загрузили нашу модель в эластик вместе с описанием фичей и добавили этап rescore в запрос.
Во время выполнения поискового запроса модель берет топ-1000 товаров с прошлого этапа (линейная формула ранжирования) и делает предикт для каждой пары запрос-товар, а затем сортирует товары на основе итоговых скоров. Этот подход достаточно прост в реализации, но, не имея ранее опыта заведения такой системы, мы успели столкнуться с проблемами не только до запуска AB, но и после. Обо всем по порядку.
Как мы обучали нашу модель и какие сигналы брали для таргета?
Для ответа на вопрос выше нам с вами стоит поговорить про данные, которыми мы располагаем. Для полноценного рассказа про сбор данных командой дата-инженеров потребуется отдельная статья, поэтому здесь я с вами поделюсь верхушкой айсберга. Нам как дата-саентистам зачастую большего не нужно.
Мы в Uzum Market тщательно следим за нашими пользователями и записываем их активность в кликстрим. Мы знаем кто и в какой сессии кликнул на товар, добавил его в корзину и, вероятно, даже купил. Мы умеем прослеживать эту цепочку. На первый взгляд может показаться, что это достаточно просто, но давайте зададимся вопросом: разве все совершают покупку внутри первой поисковой сессии? Представьте вы решили купить кофеварку. Зашли на свой любимый маркетплейс Uzum Market, вбили «кофеварка» в строку поиска и начали листать страницы с предложенными товарами, обращая внимание на характеристики, рейтинг и цену. Скорее всего, параллельно вы посмотрели несколько обзоров на топовые кофеварки 2023. После чего заглянули на сайты конкурентов, сравнили цены, взвесили все за и против и только через пару дней (а может, и недель) вернулись в корзину Uzum Market и довели дело до конца. Уверена, что многие сейчас узнали себя.
Вы можете возразить мне: а как же покупки товаров, которые мы делаем регулярно, или поставки лаков в салоны красоты? Вряд ли они ждут дни, чтобы решить, какие пилочки закупать.
Мы тоже задали себе эти вопросы и провели большую аналитическую работу, по результатам которой выяснили, что в 99% случаев наши пользователи совершают покупку за 14 или менее дней после сессии, в которой произошло последнее добавление товара в корзину. Таким образом, мы с вами пришли к нашему понятию атрибуции покупки.
Цель атрибуции — соотнести GMV (Gross Merchandise Value или валовая стоимость товара) купленных товаров с частью продукта, где пользователь последний раз видел конкретный купленный им товар. Атрибуция помогает понять, какие части продукта генерируют наибольшую прибыль.
Вот как выглядит процесс атрибуции сейчас:
Берутся данные по всем купленным товарам за определенный календарный день;
В данных кликстрима берутся события взаимодействия пользователя с купленным им товаром. Взаимодействия пользователя и товара включают в себя показы в разных частях продукта, добавления в корзину и оплату товара;
Из этих событий формируются цепочки. Одна цепочка — это события конкретного пользователя и товара в течение последних 14 дней до момента покупки.
Теперь мы можем использовать покупку как таргет к определенной сессии. Эта статья про поиск, поэтому нас интересуют покупки, атрибуцированные к поисковой выдаче. Однако покупка — довольно редкий сигнал, на таком скудном наборе данных будет сложно обучить хорошую модель. Мы пошли дальше и использовали 3 разных сигнала в качестве таргета.
Для каждой уникальной троицы (сессия, запрос, товар) мы посчитали таргет следующим образом:
добавление в корзину товара = 1
покупка товара = 2
товар остался без взаимодействий со стороны пользователя = 0
Напомню, что для обучения бустинга мы использовали XGBoost Ranker с pairwise loss, которому все равно на конкретные значения таргета. То есть мы могли выбрать таргеты 5, 10, 15 или 25, 34, 77. Модель обучалась бы одинаково, ведь главное для ранжирования — порядок.
С таргетом все понятно, а на каких данных будем учить?
Сбор датасета мы начали с поисковых сессий пользователя, в которых было событие ATC — добавление товара в корзину. Далее при помощи атрибуции мы добавили покупки к сессиям с ATC, если такие были. Сессии только с кликами слишком шумные, поэтому их было решено опустить.
 Сбор сессий с ATC из кликстрима. (2) Обогащение товаров фичами из Feature Store и из ElasticSeacrh. (3) Объединение данных в финальный датасет.")
(1) Сбор сессий с ATC из кликстрима. (2) Обогащение товаров фичами из Feature Store и из ElasticSeacrh. (3) Объединение данных в финальный датасет.
Фичи товара и их важность для модели LTR
Пайплайн подготовки датасета для обучения модели представлен выше на рисунке. Единственная часть этого пайплайна, которая еще не была мной раскрыта, это как раз фичи, которые мы используем для тренировки модели.
Хранилище фичей товаров у нас называется Feature Store. Оно обновляется ежедневно, и в нем мы храним два типа фичей:
daily— сюда входят как фичи за определенный день, так и фичи, просуммированные за весь период до текущего дня;moving— фичи, которые собираются за определенный период до сегодняшнего дня (например, за 3/7/14/30 дней).
На графике ниже представлена важность фичей нашей бустинговой модели. Мы не можем поделиться конкретными фичами, поэтому объединили их в смысловые группы и примерно расположили на графике.

Как мы и ожидали, самыми важными фичами оказались разного рода конверсии и покупки товара, а также текстовая близость между запросом и различными текстовыми характеристиками товара.
Факапы Челленджы
В самом начале статьи я говорила, что нами было накоплено достаточно знаний. Не все их можно назвать факапами, так что тут мы поменяем термин на челленджи. Далее я расскажу о трех основных челленджах, на которые мы потратили больше времени, чем планировали изначально.
Челлендж 1: Проблема бизнес бустов
Мы запускаем AB с LTR моделью впервые. Выдача стала существенно лучше, это видно невооруженным взглядом. Команда радуется, веселые стикерпаки уже пошли в бой.
 и SERPа, отражированного Линейной моделью, а затем реранжированный моделью LTR (справа на скрине)")
Но погодите-ка: бизнес спрашивает, когда мы починим поиск. Все в недоумении. Просим пояснить, и в ответ получаем такой скриншот.

Фотографии товаров в топ-10 по запросу «наколенники» оказались не фотостудийными. Фотостудийность товара — наш внутренний флаг, который принимает boolean значение:
1 — если изображение, используемое в карточке товара на нашем маркетплейсе, прошло через нашу фотостудию, и мы уверены в качестве картинки;
0 — если изображение, используемое в карточке товара на нашем маркетплейсе, НЕ проходило через нашу фотостудию, и мы НЕ уверены в качестве картинки.
Здесь важно упомянуть, что фотостудия Uzum Market платная для продавцов. То есть бизнес заинтересован в том, чтобы товары со студийными фото были выше в поисковой выдаче.
Итак, вернемся к нашей проблеме. Мы никак не учли этот признак, и модель подняла их слишком высоко. В этот момент мы поняли, что нам нужен этап с бизнес-бустами, который будет идти за LTR-ранжированием и исправлять то, что модель выучить не может.
В запрос эластика мы добавили второй rescore на топ-N товаров, в котором товарам с флагом студийной фотокарточки прибавлялся буст +X. В примере ниже заменим X на 100, для наглядности. Так нестудийные товары резко опустились вниз.

На самом деле именно такие штуки как бизнес-факторы «ломают» поиск. Релевантные товары опускаются ниже, из-за чего метрики становятся хуже. Это вечный trade-off между бизнесом и вашей моделью, который неплохо контролируется с помощью бизнес-бустов на вашей стороне.
Челлендж 2: Cold Start
Всеми нелюбимая проблема новых товаров, казалось бы, давно изжила себя, и есть тысяча и один способ ее устранить. Однако в поиске все не так очевидно. Все зависит от вашего кейса.
Новый товар появляется на площадке. Статистики нет, средняя глубина просмотра SERPа не более 3 страниц, по запросу он не показывается. Кажется, мы никогда не получим пользовательский фидбек по товару. Что делать? Опять буст? Если мы накинем буст на новый товар, то весь наш топ заполнится новыми товарами, без рейтинга, без покупок, но уже со студийной фотокарточкой, и к нам снова придет бизнес с вопросом «когда почините поиск»?
Чтобы ограничить количество новых товаров в топе, но периодически подкидывать их выше и собирать по ним статистику, части новых товаров мы рандомно добавляем буст прямо в таргет модели при обучении. Таким образом, модель учится давать буст новым товарам, но не делает это в 100% случаев и не заполняет ими топ по всем запросам.
Уверена, вы сейчас думаете о том же, о чем я хочу дальше написать. Перед нами 2 параметра, за которыми нам одновременно нужно следить: количество новых товаров в топ-k и оценка релевантности выдачи @k. Когда первых может стать слишком много, релевантность выдачи сильно упадет и наши пользователи, не говорят уже про бизнес, будут неудовлетворены. Если же мы выкрутим релевантность выдачи на максимум, то новых товаров там не будет вовсе, и мы вернемся к проблеме холодного старта.
Что можно сделать с этим tradeoff-ом?
Степеней свободы в данном случае у нас две:
значение буста, который мы добавляем в таргет новым товарам;
доля новых товаров, которым мы искусственно увеличиваем таргет;
Значение буста большой роли не играет, ведь ранкеру неважны конкретные значения таргета, о чем мы говорили ранее в разделе про сигналы для таргета. Главное, чтобы ваш буст не превратил один сигнал в другой, а стал чем-то между.
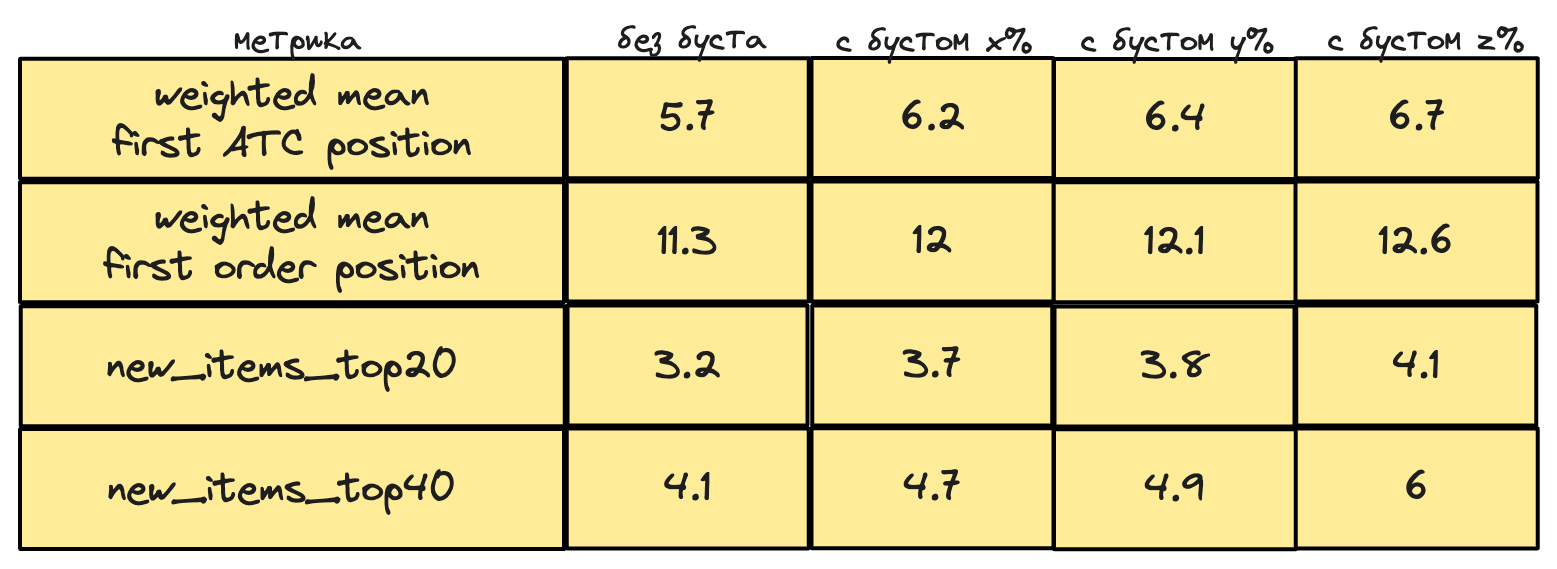
Чтобы ответить на вопрос, как значение доли рандомных товаров будет влиять на нашу выдачу, мы посчитали следующие статистики:
weighted mean first ATC position/weighted mean first order position- офлайн метрики, про которые поговорим в следующем Чэллендже, взвешенные на частоту запросаnew_items_top_k- среднее количество новых товаров в топ k по 100к запросов, взвешенных на частотураспределение первых позиций новых товаров в запросах по перцентилям
Результаты вы можете видеть в таблице ниже, буст z>y>x. Реальные значения были заменены на синтетические, однако динамику увеличения количества новых товаров можно легко проследить.
Этот подход довольно неплохо показывает себя в поисковом ранжировании, но мы планируем его улучшать и делать что-то более умное.
Челлендж 3: Определение метрики
Если вы работали или работаете в команде поиска, то вам не раз приходила оценка поиска от вашего CTO, отсюда и лучшая метрика вашего поиска — CTO@k, где k напрямую коррелирует с его свободным временем????.
Шутки в сторону, как мерить этот ваш LTR?
Если мы говорим про онлайн-метрики или бизнес-показатели, тут все просто. Деньги, revenue, ARPU, ARPPU, conversion to purchase — все, что душе угодно. Проблема этих метрик в том, что они долго красятся в AB и к ним очень сложно найти коррелирующую офлайн-метрику, которую возможно посчитать.
Если мы вспомним про этапы, из которых состоит поиск, то кажется здесь одной метрикой не обойтись. State-of-art метрик не существует, каждая компания пытается выбрать максимально скоррелированную офлайн-метрику к тем показателям, которые хочет растить бизнес.
Какие метрики выбрали мы?
Мы учим наш Ranker оптимизировать NDCG@40, поэтому логично взять эту метрику для валидации в офлайне. Рост NDCG@40 говорит нам о том, что мы поднимаем более релевантные товары выше.
Вторая метрика это наш вариант MRR (Mean Reciprocal Rank) — mean_first_atc_position или ее аналог для покупок — mean_first_order_position.
Это метрика основана на предположении о том, что чем выше товар в выдаче, который пользователь добавил в корзину или купил, тем лучше. Мы можем с легкостью взять исторические сессии с ATC, отранжировать товары внутри них с помощью LTR-модели и посмотреть, на какую позицию передвинулся в среднем товар, который заинтересовал пользователя. Почему мы считаем этот показатель не только по покупкам, но и по добавлению в корзину?
покупок мало;
ATC — действие, предшествующее покупке.
А какие метрики выбрал бизнес?
Конечно же, деньги. Во всех наших AB-экспериментах мы мерим как общие бизнес-показатели по всему маркетплейсу, так и показатели только из поиска:
ARPU/ARPPU— доход с пользователя/доход с покупателя;cr2atc— конверсия в добавление в корзину;cr2purchase— конверсия в покупку.
Про daily метрики
Важно отметить, что все метрики мы мерим как daily-метрики.
В daily-метриках основная единица — это не пользователь, а пользователе-день (или покупателе-день). То есть если пользователь зашел к нам вчера и сегодня, он будет посчитан дважды (как будто это было два разных пользователя). Таким образом, метрики выше превращаются в следующие:
ARPU_daily— общепринятое обозначение — ARPDAU (Average Revenue Per Daily Active User);ARPPU_daily— общепринятое обозначение — ARPPDAU;cr2atc_daily;cr2purchase_daily.
Любители статистики уже поняли, что таким образом мы получаем ratio-метрики [6], которые не так просто правильно считать в AB.
P.S. Первый раз мы посчитали неправильно. Теперь мы умеем в линеаризацию и используем ее всегда для подсчетов проведенного AB.
Как мы собираемся улучшать поиск?
На этом наши основные челленджи заканчиваются и мы приближаемся к завершению этого увлекательного путешествия. Есть многое, о чем я еще не успела рассказать, и множество задач, которые мы хотим выполнить в ближайшем будущем. Приоткрою несколько направлений, на которые мы настроены в этом и следующем году.
Отдельный сервис для ранжирования
В наших планах написать отдельный сервис для ранжирования результатов поиска. Сервис позволит отказаться от использования плагина Learning-to-Rank (LTR) внутри эластика, а также принесет массу преимуществ:
Гибкость и масштабируемость: самостоятельный сервис даст нам свободу в управлении и масштабировании ранжирования, не ограничиваясь функциональностью LTR плагина.
Независимость: используя собственный сервис, мы сможем легко обновлять версии ElasticSearch, не оказывая влияния на ранжирование поиска.
Улучшенное качество ранжирования: мы сможем использовать собственные алгоритмы ранжирования, адаптированные к нашим потребностям и данным.
Расширенные возможности: отдельный сервис позволит внедрить pairwise фичи — фичи, которые вычисляются для каждой уникальной пары запрос-товар, что даст более точное понимание релевантности товаров и улучшит качество ранжирования.
Внедрение векторного поиска
В ElasticSearch версии 8.0 была реализована функция векторного поиска на этапе ретривала с использованием ANN (приближенный поиск ближайших соседей). Включение этого функционала в запросы обогатит процесс ретривала и приведет к следующим преимуществам:
Улучшенная релевантность: векторный поиск позволит находить товары, которые близки к запросу, но не имеют точных совпадений в названии.
Гибкость и эффективность: использование ANN для векторного поиска обладает высокой производительностью и эффективностью. Это позволяет нам быстро выполнять запросы и обрабатывать большие объемы данных.
Адаптивность к изменениям: ANN позволит легко адаптироваться к изменениям в предпочтениях пользователей и меняющимся трендам, обеспечивая более актуальные результаты поиска.
В следующих статьях мы обязательно поделимся результатами и расскажем о сложностях, с которыми столкнемся. Наше путешествие с ML в мире e-commerce продолжается, и мы нацелены на достижение новых результатов!