
MLOps: структурирование пути от концепции модели к ее реальному воздействию
В современном мире, основанном на данных, машинное обучение является символом инноваций. Однако преобразование модели из теоретической конструкции в готовый к использованию инструмент — сложная задача. MLOps — гармоничное сочетание «machine learning» и «operations», созданное для решения этой сложной задачи.
Черпая вдохновение из DevOps в разработке программного обеспечения, MLOps объединяется вокруг основных задач, предлагая структурированный путь для проектов ML на протяжении всего их жизненного цикла.
Теперь давайте углубимся в мир MLOps с помощью MLRun.
Ключевые аспекты MLOps включают в себя:
Model Development & Training: MLOps начинается с зарождения модели, объединяя лучшие практики и инструменты, помогающие эффективно создавать и обучать модели.
Feature Store. Центральное хранилище функций MLOps действует как единый репозиторий для управления функциями. Он упрощает поиск, хранение и совместное использование функций, обеспечивая согласованность и ускоряя разработку моделей.
Validation & Testing. Перед развертыванием модели проходят строгую автоматическую проверку, гарантирующую, что они соответствуют критериям производительности и готовы к решению реальных задач.
Continuous Integration & Continuous Deployment & Continuous Training (CI/CD/CT): . Благодаря динамическому характеру моделей ML конвейеры CI/CD/CT обеспечивают плавность процессов обновлений и переобучения, сохраняя модели оптимизированными и актуальными.
Scaling & Orchestration. После запуска моделей в производство может потребоваться удовлетворить меняющиеся требования. MLOps подчеркивает масштабируемость с использованием таких технологий, как контейнеризация (как Docker) и оркестровка (как Kubernetes).
Model Versioning. По мере развития моделей отслеживание их итераций имеет первостепенное значение. MLOps предоставляет инструменты для управления версиями, позволяющие легко получать доступ к различным версиям модели и управлять ими.
Monitoring & Feedback Loops. Инструменты MLOps отслеживают показатели производительности, предлагают каналы обратной связи и включают механизмы для уточнения и переобучения на основе информации в реальном времени.
End-to-End Automation. Cводя к минимуму ручное вмешательство, MLOps стремится автоматизировать этапы от предварительной обработки данных до деплоя и мониторинга модели, обеспечивая эффективность и уменьшая потенциальные ошибки.
Collaboration & Communication:. Поддерживая целостный подход, MLOps способствует сотрудничеству между учеными, инженерами по машинному обучению и ИТ-специалистами, обеспечивая синергию и согласованность целей.
Введение в MLRun: новаторские решения MLOps с открытым исходным кодом для современной эпохи
MLRun — это платформа MLOps с открытым исходным кодом, разработанная для упрощения сложностей, связанных с проектами машинного обучения. Одна из целей данного проекта, снизить сложность настройки комплексной MLOps среды, где нужно интегрировать различные инструменты вместе. MLRun также уменьшает кривую обучения, так как вам нужно изучить всего один фреймворк, оставаясь уверенным в надежной интеграции между компонентами:
Хранилище функций (feature store). Хранилище функций MLRun действует как централизованное хранилище, оптимизируя управление, хранение и извлечение функций данных. Это обеспечивает уверенность в согласованности признаков в процессе обучения и инференса.
Отслеживание экспериментов. Итеративный характер моделирования машинного обучения требует надежного отслеживания. Эксперимент MLRun отслеживает детали каждого запуска, фиксируя параметры, конфигурации и результаты. Это обеспечивает ясность эволюции модели и упрощает сравнительный анализ экспериментов.
Развертывание модели. Ключом к стратегии развертывания MLRun является его интеграция с Docker. Модели вместе со своими зависимостями упаковываются в контейнеры Docker, что обеспечивает согласованность и переносимость между средами.
Workflows. MLRun признает сложность проектов машинного обучения, которые часто включают в себя ряд взаимозависимых задач. Он поддерживает организованные рабочие процессы, обеспечивая беспрепятственное соединение и структурированное выполнение таких задач, как подготовка, обучение, проверка и развертывание моделей.
Автоматизация и CI/CD. По своей сути MLRun легко интегрируется с конвейерами непрерывной интеграции и непрерывного развертывания (CI/CD), автоматизируя задачи от интеграции кода до развертывания модели, обеспечивая гибкость и сокращая количество ручных операций.
Интеграция Kubernetes. MLRun имеет встроенную интеграцию с Kubernetes обеспечивая динамическое масштабирование в зависимости от требований проекта.
В целом MLRun — это комплексный набор инструментов MLOps. Но хоть он и объединяет различные компоненты вместе, при увелечении сложности и требований к проекту возможно будет иметь смысл перейти на отдельные инструменты для каждого этапа.
Цель статьи
Главная задача — рассказать о применении MLRun в качестве инструмента MLOps, используя данные актуального соревнования на Kaggle: «Optiver — Trading at the Close». Данное соревнование посвящено прогнозированию динамики закрытия акций на американском рынке.
Знания в инвестициях не требуются. Мы будем использовать код из одного notebook и интегрируем его в автоматизированный пайплайн с помощью MLRun.
Установка MLRun локально с использованием Docker
MLRun — это универсальная платформа, поддерживающая установку на Kubernetes-кластере, облачных серверах или даже локально. Сейчас мы рассмотрим как настроить MLRun локально с помощью Docker Compose.
Шаги для настройки:
Загрузите compose. yaml файл из официальной документации MLRun [Download link].
Настройте переменные окружения:
export HOST_IP=<адрес вашего хоста>
export SHARED_DIR=~/mlrun-data
mkdir $SHARED_DIR -pЗдесь shared_DIR — директория на вашем компьютере, в которой будут сохраняться артефакты MLRun и база данных.
Запустите docker compose для установки необходимых сервисов:
docker-compose -f compose.yaml up -dПосле этого у вас будут активны следующие сервисы:
MLRun API: http://localhost:8080
MLRun UI: http://localhost:8060
Nuclio Dashboard/controller: http://localhost:8070
Первые шаги
Сначала скачайте тренировочный датасет соревнования по ссылке.
Мы делаем акцент на переходе с model-centric подхода к data-centric. И первым делом создадим feature store.
Feature Set
Feature Set — это группа признаков, которые можно объединить, формируя логическую единицу (например, «stocks» или «user_events»).
При создании Feature Set можно определить граф преобразований для входящих признаков, данные для которого могут поступать как из оффлайн-хранилищ, так и из стриминговых сервисов, например, Kafka. Когда данные проходят через созданный Feature Set с заданным графом трансформации, результирующие признаки сохраняются в оффлайн-хранилище для последующего обучения и в онлайн-формате для инференса.
Такой подход к созданию и регистрации графа преобразований позволяет гарантировать, что признаки, используемые при инференсе, идентичны тем, что использовались при обучении.

Применение MLRun для обработки Feature Set
Давайте начнем с импорта mlrun:
import mlrunСоздадим проект:
project = mlrun.get_or_create_project("stock-prediction", context="./", user_project=True)Проект в MLRun это контейнер для всей вашей работы, который хранит весь код, все функции (mlrun функции. Смотреть ниже.), пайплайны, артефакты, вроде моделей, набора данных и метрик, признаков и конфигураций.
Параметр context, это где хранится весь код проекта. Параметр user_project делает имя проекта уникальным для каждого пользователя.
Загрузим и предобработаем наши данные:
stocks_df = pd.read_csv("./optiver-trading-at-the-close/train.csv")
# Урежем данные для ускорения процесса тестирования
stocks_df = stocks_df[:50000]Если мы посмотрим на признаки, то увидим несколько связанных с той или иной ценой и ее условной суммой *_size. Именно эти признаки нас и будут интересовать, так как на их основе мы сделаем feature engineering.
stock_df.head()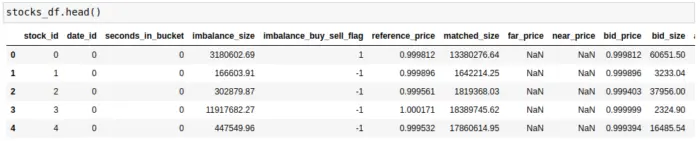
Feature Engineering:
На основе кода с Kaggle notebook соревнования мы создадим функцию imbalance_calculator, которая будет генерировать новые признаки.
def imbalance_calculator(x: pd.DataFrame, context=None) -> pd.DataFrame:
x_copy = x.copy()
x_copy['imb_s1'] = x.eval('(bid_size - ask_size) / (bid_size + ask_size)')
x_copy['imb_s2'] = x.eval('(imbalance_size - matched_size) / (matched_size + imbalance_size)')
prices = ['reference_price','far_price', 'near_price', 'ask_price', 'bid_price', 'wap']
for i,a in enumerate(prices):
for j,b in enumerate(prices):
if i>j:
x_copy[f'{a}_{b}_imb'] = x.eval(f'({a} - {b}) / ({a} + {b})')
for i,a in enumerate(prices):
for j,b in enumerate(prices):
for k,c in enumerate(prices):
if i>j and j>k:
max_ = x[[a,b,c]].max(axis=1)
min_ = x[[a,b,c]].min(axis=1)
mid_ = x[[a,b,c]].sum(axis=1)-min_-max_
x_copy[f'{a}_{b}_{c}_imb2'] = (max_-mid_)/(mid_-min_)
return x_copyТеперь имея функцию для feature engineering и набор данных, мы можем создать Feature Set:
import mlrun.feature_store as fstore
stocks_set = fstore.FeatureSet("stocks", entities=[fstore.Entity("row_id")])Первый аргумент, это название, а Entity это уникальное значение строки, индекс. В данном наборе данных, это row_id.
И теперь просто добавим в граф наш imbalance_calculator в виде feature set transformation:
stocks_set.graph.to(name="imbalance_calculator", handler="imbalance_calculator")Нам также необходимо добавить таргеты, куда будут сохраняться признаки. Нам нужен оффлайн и онлайн. В качестве оффлайн для простоты будем использовать файл. parquet в нашей директории, а в качестве онлайн redis:
from mlrun.datastore.targets import ParquetTarget, RedisNoSqlTarget
offline_target = ParquetTarget(
name="stocks", path=f"./stocks.parquet"
)
online_target = RedisNoSqlTarget(path ="redis://0.0.0.0:6379")
stocks_set.set_targets([offline_target, online_target], with_defaults=False)По умолчанию, оффлайн и онлайн находятся на платформе Iquazio — V3IO frames service, от создателей mlrun, поэтому мы ставим with_defaults=False. Чтобы использовать их, вам нужно создать аккаунт и установить credentials.
Вы можете поднять redis с помощью redis-stack, который содержит ui, в котором можно просматривать признаки:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latestRedisInsight — http://localhost:8001
Теперь можно визуализировать наш stock_set граф:
stocks_set.plot(rankdir="LR", with_targets=True)
Таким образом, в процессе добавления, данные сначала проходят через `imbalance_calculator`, после чего результаты сохраняются в форматах parquet для последующего обучения и в redis для инференса.
Теперь сделаем ingest, то есть отправим в этот граф наш набор данных:
stocks_df = fstore.ingest(stocks_set, stocks_df)Результат можно будет увидеть в MLRun UI localhost:8060 в Feature Store проекта, в RedisInsight и соответственно в parquet файле в директории проекта.
Создание и использование Feature Vector
После формирования Feature Set, следующим шагом является создание Feature Vector. Feature Vector представляет собой входные данные для модели и состоит из группы признаков, собранных из разных Feature Set’s. В нашем случае у нас только один Feature Set, таким образом, мы будем использовать все его признаки.
Пример того, как создать Feature Vector из Feature Set, можно найти в пользовательском интерфейсе MLRun:
fv_name = "stocks_fv"
features = ["stocks.*"]
stocks_fv = fstore.FeatureVector(
fv_name,
features=features,
label_feature="stocks.target",
description="Predict US stocks closing movements"
)Здесь label_feature указывает на то, что мы стремимся предсказать. После создания, Feature Vector можно сохранить и просмотреть в пользовательском интерфейсе MLRun:
stocks_fv.save()Автоматизация обучения и деплоя модели
Теперь, имея на руках Feature Vector, давайте автоматизируем процесс обучения модели. Наша цель — регулярно обновлять и деплоить модель на основе новейших данных, которые поступают в наши оффлайн и онлайн хранилища. Для имитации потока данных мы будем использовать Kafka.
В качестве модели для предсказания закрытия акций выберем XGBRegressor. Хотя во многих случаях ансамбли моделей могут улучшить производительность, в этом примере мы сосредоточимся на простом решении, чтобы лучше понять базовую концепцию.
Функция Обучения с MLRun
Сначала, создадим файл trainer. py с функцией для обучения:
%%writefile trainer.py
import mlrun
from mlrun.execution import MLClientCtx
from mlrun.frameworks.xgboost import apply_mlrun
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
def train(context: MLClientCtx, dataset: mlrun.DataItem, objective: str, tree_method: str, n_estimators: int, label_column: str = "target", model_name: str = "stock_prediction_xgboost"):
# Получение данных
df = dataset.as_df()
X = df.drop(label_column, axis=1)
y = df[label_column]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Инициализация модели
model = XGBRegressor(objective=objective, tree_method=tree_method, n_estimators=n_estimators)
# Интеграция MLOps
apply_mlrun(model=model, model_name=model_name, x_test=X_test, y_test=y_test)
context.logger.info(f"training '{model_name}'")
model.fit(X_train, y_train)MLRun предоставляет встроенную интеграцию со многими фреймворками, включая XGBoost. Функция apply_mlrun автоматически сохраняет артефакты обучения, такие как модель, тестовый датасет, метрики и статистики обучения специфичные для XGBoost.
Использование Функций в MLRun
MLRun использует концепцию «Функций», представляющих собой Docker контейнеры, выполняющие кастомный код в реальном времени или пакетном режиме. Чтобы запустить нашу обучающую функцию, нам потребуется такая Функция.
Преобразуем наш код в MLRun "job" пакетную-функцию, которая запускает код в Kubernetes Pod:
regressor_fn = mlrun.code_to_function(
name="custom-trainer",
filename="trainer.py",
kind="job",
image="mlrun/mlrun",
handler="train",
)Теперь у нас есть Функция со своим image и кодом. Чтобы использовать эту Функцию позже, ее необходимо добавить в проект:
project.set_function(regressor_fn)И соответственно, сохранить сам проект, что изменит project. yaml файл в рабочей директории, который отвечает за всю конфигурацию проекта:
project.save()Теперь мы можем запустить эту Функцию с помощью run_function из mlrun указав ее название:
train_run = mlrun.run_function(
"custom-trainer",
name="custom-trainer-run",
handler="train",
params={
"label_column": "target",
"objective": "reg:absoluteerror",
"tree_method": "hist",
"n_estimators": 5000
},
inputs={"dataset": project.get_artifact_uri("stocks_fv", "feature-vector")},
local=True
)В этой функции, dataset это ссылка на наш Feature Vector. Вы также можете получить эту ссылку напрямую из UI.
Мы используем local=True, что вместо запуска Функции в контейнере, запускает ее локально.
После завершения работы, вы можете просмотреть выводы функции:

outputs — это артефакты, которые сохраняются в базу данных проекта, которые затем можно получить для использования.
Когда мы будем рассматривать pipeline ниже, outputs Функции будет использоваться для передачи в качестве параметров в следующую.
Model Serving: От Батча к Real-time
После обучения модели следующим шагом в нашем пайплайне является ее «serving». Для этого нам потребуется создать кастомную функцию для развертывания модели.
%%writefile serving.py
import numpy as np
from cloudpickle import load
from mlrun.serving.v2_serving import V2ModelServer
import mlrun
class RegressorModel(V2ModelServer):
def load(self):
"""Load and initialize the model and other components."""
model_file, _ = self.get_model(".pkl")
self.model = load(open(model_file, "rb"))
self.feature_service = mlrun.feature_store.get_online_feature_service('stocks_fv')
def preprocess(self, body: dict) -> list:
"""Preprocess input data before prediction."""
vectors = self.feature_service.get([{'row_id': row_id} for row_id in body['inputs']])
vectors[0].pop('target', None)
body['inputs'] = list(vectors[0].values())
return body
def predict(self, body: dict) -> list:
"""Predict using the model."""
feats = np.asarray([body["inputs"]])
result = self.model.predict(feats)
return result.tolist()Для обучения мы использовали Функцию MLRun типа «job», которая работает в батч режиме. Теперь нам нужна функция типа «serving», которая является real-time и работает на основе Nuclio — Serverless Functions.
Когда мы используем serving Функцию с кастомной логикой инференса модели, нам необходимо создать класс, который наследуется от mlrun.serving.v2_serving.V2ModelServer и реализует как минимум два метода load и predict. Выше мы добавили preprocess, также можно добавить postprocess, validate и explain.
Чтобы создать serving Функцию для класса выше, один из вариантов, это также вызвать code_to_function, только с kind=`serving`:
serving_fn = mlrun.code_to_function(
"stocks_serving",
filename="serving.py",
kind="serving",
image="mlrun/mlrun"
)Чтобы serving_fn могла работать, в нее необходимо передать модель. Для этого нужно вызвать add_model:
serving_fn.add_model(
"stock_prediction_xgboost",
model_path=train_run.outputs[“model”],
class_name="RegressorModel"
)В качестве model_path здесь передается результат предыдущей функции обучения, uri модели, которая уже является артефактом.
Можно посмотреть граф serving_fn:
serving_fn.spec.graph.plot()
Теперь мы можем запустить имитацию сервера для обращения к модели через api:
local_server = serving_fn.to_mock_server()Так как мы добавили модель, мы также можем вывести список моделей, которые есть у данной Функции, или сервиса:
local_server.test("/v2/models/", method="GET")
Создание MLRun Workflow
Теперь, когда у нас есть все компоненты, перейдем к созданию MLRun Workflow. Эти рабочие процессы (workflows) представляют собой Directed Acyclic Graph (DAG), которые последовательно запускают различные функции MLRun.
Пайплайны MLRun могут быть запущены локально или как часть Kubeflow Pipelines. Они автоматизируют выполнение различных этапов ML-процесса, таких как сбор данных, обучение модели и развертывание. Пайплайн можно запускать как по рассписанию, так и через триггеры, например при data или model drift.
%%writefile workflow.py
import mlrun
from kfp import dsl
@dsl.pipeline(
name="Stock prediction pipeline",
description="Predict US stocks closing movements"
)
def pipeline(vector_name: str = "stocks_fv"):
project = mlrun.get_current_project()
train_run = mlrun.run_function(
"custom_trainer",
name="custom_trainer_run",
handler="train",
params={
"label_column": "target",
"objective": "reg:absoluteerror",
"tree_method": "hist",
"n_estimators": 500
},
inputs={"dataset": project.get_artifact_uri("stocks_fv", "feature-vector")},
outputs=["model"]
)
serving_fn = mlrun.code_to_function(
"stocks-serving",
filename="serving.py",
kind="serving",
image="mlrun/mlrun"
)
serving_fn.add_model(
"stock_prediction_xgboost",
model_path=train_run.outputs["model"],
class_name="RegressorModel"
)
serving_fn.deploy()Здесь мы не делаем сбор и обработку данных, так как у нас есть Feature Store, в который данные будут поступать через платформу стриминг ивентов, такую как kafka. Чуть позже мы запустим real-time функцию, которая будет получать ивенты от kafka и передаваться в Feature Store для выполнения трансформаций и сохранения результатов в offline (parquet) и online (redis) store.
В нашем же Worklow, мы добавляем декоратор @dsl.pipeline(…), чтобы он работал на Kubeflow.
В inputs для функции обучения мы передаем uri Feature Vector — project.get_artifact_uri("stocks_fv", "feature-vector"), который получает из offline хранилища актуальные обработанные признаки в нужном формате, которые добавляются туда в реальном времени.
Обученная модель передается в Функцию serving для ее дальнейшего использования — train_run.outputs["model"].
И последнее, чтобы сделать деплой, мы просто запускаем serving_fn. deploy(), которая создает API сервис и оборачивает его в докер контейнер, который автоматически деплоится на Kubernetes кластер.
После завершения пайплайна у нас должно быть рабочее api с моделью. Когда мы запускали имитацию сервера, мы обращались к модели следующим образом:
sample_id = "4_410_107"
model_inference_path = "/v2/models/stock_prediction_xgboost/infer"
local_server.test(path=model_inference_path, body={"inputs": [sample_id]})Теперь же, мы можем создать модуль для обращения к модели с помощью requests, или использовать curl:
curl -X 'POST' 'http://host:32768/v2/models/stock_prediction_xgboost/infer' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"inputs": ["4_410_107"]}'Деплой Feature Set для real-time сервиса с Apache Kafka
Теперь наша задача — развернуть Feature Set, который будет работать в реальном времени, принимая события от Apache Kafka.
Установка Apache Kafka через Docker
Загрузите конфигурационный файл для Apache Kafka:
curl -sSL https://raw.githubusercontent.com/bitnami/containers/main/bitnami/kafka/docker-compose.yaml > docker-kafka-compose.yamlЗапустите Kafka используя Docker Compose:
docker compose -f docker-kafka-compose.yml up -dСоздайте топик под названием `stocks_topic`:
docker exec -it chris-kafka-1 kafka-topics.sh --create --topic stocks-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1Интеграция с MLRun
Получите ваш FeatureSet:
stocks_set = fs.get_feature_set("stocks", project="stock-prediction-user_name")Установите KafkaSource для получения ивентов:
from mlrun.datastore.sources import KafkaSource
kafka_source = KafkaSource(
brokers=['0.0.0.0:9092'],
topics="stocks-topic",
initial_offset="earliest",
group="my_group",
)И сделаем деплой нашего ingestion сервиса:
stocks_set_endpoint = fstore.deploy_ingestion_service(
featureset=stocks_set, source=kafka_source
)Теперь можно делать запрос к задеплоенному Ingestion сервису через api, который будет преобразовывать новые данные в нужные признаки, позволяя нам быть уверенными, что один и тот же формат используется как во время обучения, так и во время инференса.
Навигация в будущее MLOps
Мы успешно завершили наше путешествие по введению в MLRun и общие понятия MLOps. Надеюсь, что этот туториал стал полезным в вашем изучении и применении инструментов для машинного обучения.
По любым вопросам пишите мне в телеграм — @NLavrenov00

denis-isaev
Забавно, к чему только этот Ops не прилепляли, наверное, скоро появится книга за авторством Дудя и Щербакова - "КуниOps: жизненный цикл любви" :)