

Привет, Хабр! С вами снова Антон, все еще DevOps-инженер в отделе Data- и ML-продуктов Selectel, который все еще исследует тему шеринга GPU. В предыдущей статье я рассказал, как можно использовать шеринг видеокарт в Kubernetes.
В комментариях была затронута тема динамического переконфигурирования MIG. Вопрос: можно ли настраивать деление GPU при активной нагрузке? Я погрузился подробнее в этот вопрос и нашел несколько способов, как это сделать. Интересно? Тогда добро пожаловать под кат!
Используйте навигацию, если не хотите читать текст целиком:
→ Проблема динамического разделения MIG
→ Решение от run.ai
→ Подготовка инфраструктуры
→ Активация динамического шеринга в Kubernetes
→ Как работает динамический шеринг GPU
→ Тестируем динамический MIG на практике
→ Сравнение MPS, MIG, Timeslicing
→ Заключение
Дисклеймер: для понимания данной статьи нужны навыки в работе с Helm-чартами и kubectl, а также знание Kubernetes. Если вы хотите погрузиться в эти технологии, изучайте курсы в Академии Selectel.
Проблема динамического разделения MIG
Сначала давайте вспомним, как работает MIG при разделении GPU и использовании нативных средств от NVIDIA:
- Разделение GPU происходит на уровне железа (если видеокарта — NVIDIA на базе архитектуры amphere). Таким образом, каждая партиция получает полностью изолированный графический процессор и видеопамять.
- Для разделения GPU необходимо использовать NVIDIA API или утилиту nvidia-smi, чтобы создать или удалить раздел MIG. Это разделение касается как вычислений, так и памяти.
- Партиции имеют фиксированные размеры — например, GPU A100 можно разделить максимум на семь частей.
- Для реконфигурации профилей MIG на графическом процессоре нужны права администратора и удаление всех запущенных рабочих нагрузок, что не позволяет динамически реконфигурировать профили видеокарты.
GPU-оператор не позволяет динамически изменять конфигурацию профилей MIG. То есть при попытке сменить, например, семь 1g.5gb на два 3g.20gb оператор выгрузит всю активную нагрузку из видеокарты. Это приведет к прерыванию процессов — например, запущенного инференса или пода Jupyter Lab.
Это особенно серьезная проблема при построении автомасштабируемых платформ, где нужно постоянно изменять конфигурации и искать оптимальные профили разбиения MIG.
В прошлой статье мы рассмотрели вариант, в котором заранее разбили видеокарту на семь частей и масштабировали инференс именно по этому профилю. При этом если у нас будет запущено всего две реплики, то еще пять частей GPU будут находиться в режиме ожидания. Это было бы логично, если бы две реплики занимали не 1g.5gb, а 3g.20gb.
И эта проблема, в целом, решаема. Посмотрим, как к этой проблеме подошли run.ai и мы. Причем наш вариант вы можете повторить самостоятельно.

Решение от run.ai
Рассмотрим отличный референс технического продукта на базе технологий NVIDIA от команды run.ai. Так как продукт коммерческий, в документации описываются сценарии использования без технической реализации. Однако хочу вкратце описать возможности этой платформы по части утилизации GPU. В технику мы окунемся уже на своем примере.
Их платформа абстрагирует пользователя от «премудростей распределения нагрузки по GPU». Пользователю достаточно завести задачу — платформа сама утилизирует ресурсы видеокарты. Для оптимизации этого процесса run.ai использует две взаимодополняющие технологии, которые позволяют разделять графические процессоры.
Run:ai Fractions
С помощью технологии фракционирования платформа позволяет выделить контейнеру определенный объем памяти GPU — например, 4 ГБ:
--gpu-memory 4G
Попытка выйти за пределы выделенной памяти приведет к исключению.
Также run.ai отмечают, что все запущенные рабочие нагрузки, использующие GPU, распределяют вычисления параллельно и поровну. Постараюсь объяснить. Предположим, что есть два контейнера: один с нагрузкой на графический процессор 0,25, а другой — на графический процессор 0,75. Оба получат равную часть вычислительной мощности. Если одна из рабочих нагрузок не использует видеокарту, другая рабочая нагрузка получит всю ее вычислительную мощность.
Dynamic allocation using NVIDIA Multi-instance GPU (MIG)
Run.ai предоставляет способ динамического создания раздела MIG:
- По аналогии с технологией фракционирования, с помощью флага
--gpu-memory4G можно указать необходимую нам часть памяти GPU. Платформа вызовет NVIDIA MIG API, чтобы сгенерировать наименьший возможный профиль MIG для нашего запроса и поместить его в контейнер. - MIG настраивается в соответствии с требованиями рабочей нагрузки — без необходимости сбрасывать запущенные нагрузки на GPU.
- Платформа автоматически освободит партицию, когда рабочая нагрузка завершится. Это происходит в «ленивом режиме»: партиция не будет удалена до тех пор, пока планировщик не решит, что нужен в другом месте.
- Платформа предоставляет дополнительный флаг для динамического создания определенного раздела MIG в терминологии NVIDIA. Таким образом, можно указать
--mig-profile 2g.10gb, если мы хотим разметить GPU по определенному профилю или получить определенную партицию.
Демонстрация работы динамического MIG.
По сути, все сводится к запуску нескольких команд их собственного клиента. Для задачи можно указать объем видеопамяти, профиль MIG или количество GPU — все с помощью одной команды.
Создать задачу на 5 ГБ видеопамяти можно так:
runai submit -i gcr.io/run-ai-demo/quickstart --gpu-memory 5G
Указать для задачи профиль MIG — вот так:
runai config project team-a
runai submit mig2 -i gcr.io/run-ai-demo/quickstart-cuda --mig-profile 2g.10gb
runai submit mig3 -i gcr.io/run-ai-demo/quickstart-cuda --mig-profile 2g.10gb
Так выглядит работа с динамическим MIG зарубежного коммерческого продукта. Этим примером хочу показать, что технологии существуют и уже интегрированы в платформы, которые можно использовать для конкретных задач. При этом для динамической разметки GPU они используют доступный для всех NVIDIA MIG API. Мы решили поискать возможные решения в open source и готовы поделиться с вами результатами.
Подготовка инфраструктуры
Для нашего исследования необходимо снова использовать определенную линейку GPU — A100 или A30. Selectel предоставляет почасовую аренду таких видеокарт, чем мы и воспользуемся. Развернем Managed Kubernetes:
1. Переходим в раздел Облачная платформа в панели управления.
2. Выбираем Kubernetes и нажимаем Создать кластер.
3. Выбираем пул ru-9a, базовый тип кластера и создаем группу нод:
- выбираем flavor с GPU A100,
- указываем размер диска,
- сохраняем изменения.
4. Далее можно добавить свой SSH-ключ и указать необходимую сеть.
5. Ждем. Как только кластер задеплоится, через панель можно будет достать kubeconfig.
Процесс создания кластера Managed Kubernetes.
Также нам нужно заранее позаботиться о том, где мы будем хранить наши модели. Kubernetes позволяет указывать для подов внешние хранилища, например, через протокол NFS. Для этого отлично подойдет наш новый продукт Selectel File Storage. Создать его теперь можно также из панели управления:
- Переходим в раздел Облачная платформа внутри панели управления.
- Выбираем Файловое Хранилище и нажимаем Создать.
- Выбираем пул ru-9a, указываем размер диска, тип NFS.
- После создания можно скопировать команду для подключения к файловому хранилищу. Из этой команды нам понадобится IP-адрес и путь до файлового хранилища.
Процесс создания файлового хранилища.
Настройка файлового хранилища
Чтобы запустить наш инференс, нужно скачать обученные модели из общего репозитория NVIDIA в файловое хранилище. Почему мы вообще используем сетевое хранилище, а не хранилку на самой ноде? Все просто: при создании масштабируемой системы может понадобиться горизонтальное масштабирование ноды в кластере. При использовании сетевого хранилища все инференсы на разных нодах получат доступ к нашим моделям.
Подключимся к ноде Kubernetes по SSH, чтобы подцепить файловое хранилище по протоколу NFS и положить в него наши модели. Я скопировал прямо из панели команду, которая позволит нам подключить SFS:
sudo mkdir -p /mnt/nfs && sudo mount -vt nfs "10.222.1.60:/shares/share-3010a65e-124c-4ac8-b08e-a7b2eae0b78c" /mnt/nfs
Далее перейдем в смонтированную папку и скачаем модели — мы это уже делали в прошлой статье, когда запускали докеры с инференсами. Скачаем репозиторий на виртуальную машину и подтянем заготовленные модели. Также скачаем ONNX densenet с помощью скрипта fetch_models:
git clone -b r23.05 https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh
Убедимся, что в файловом хранилище есть необходимые файлы для импорта моделей в инференс-серверы:
ls /mnt/nfs/server/docs/examples/ -l
ls /mnt/nfs/server/docs/examples/model_repository/ -l

Отлично — хранилище готово для монтирования в наши поды.
Активация динамического шеринга в Kubernetes
Nebuly Operating System
NOS — это модуль с открытым исходным кодом для эффективного запуска ML-ворклоадов в Kubernetes, максимизирующий утилизацию GPU и оптимизирующий производительность рабочих нагрузок.
В настоящее время доступными функциями являются:
- Dynamic GPU partitioning — позволяет распределять поды, запрашивающие доли GPU. Шеринг выполняется автоматически на основе ожидающих и запущенных подов, так что они могут запрашивать только те ресурсы, которые строго необходимы;
- Elastic Resource Quota management — собственные CRD, которые позволяют увеличить количество запущенных подов с помощью управления квотами в namespaces.

На изображении как раз продемонстрировано, где при использовании NOS утилизация GPU превосходит стандартный подход и максимально экономит ресурсы. В этом примере можно использовать на одну видеокарту меньше, что сократит много расходов с учетом текущей стоимости GPU.
В данной статье мы также рассмотрим, как можно использовать Dynamic GPU partitioning для динамического шеринга видеокарт. Попробуем провести несколько тест-кейсов с MIG и MPS.
Для начала подготовим кластер, активировав MIG на видеокарте A100, и установим необходимые Helm-чарты.
Активируем MIG на нодах в K8S
Лучше заранее активировать MIG на выбранной видеокарте. Для этого подключимся к ноде по SSH, выполним команду активации и посмотрим, что скажет утилита nvidia-smi:
В данном случае «приаттачена» карта A100. Активируем MIG на видеокарте с помощью специальной команды:
nvidia-smi -mig 1

Да, в предыдущей статье MIG на нодах активировался с помощью GPU-оператора, который мы использовали для разметки MIG. Но, к сожалению, он не предназначен для динамического шеринга MIG. А решение, которое мы будем использовать для динамической разметки, не умеет автоматически активировать MIG. Из двух зол приходится выбирать меньшее.
Устанавливаем чарт GPU-оператора
GPU-оператор устанавливает несколько компонентов, в том числе nvidia-device-plugin. По умолчанию в Managed Kubernetes плагин уже установлен на нодах с GPU, поэтому сначала удаляем дефолтный плагин:
kubectl delete daemonset/nvidia-device-plugin-daemonset -n kube-system
Далее устанавливаем GPU-оператор с помощью Helm. В этот раз укажем, что migManager устанавливать не нужно. Вместо него мы воспользуемся другим сервисом, который умеет динамически размечать конфигурацию MIG:
helm install --wait --generate-name \
-n kube-system \
nvidia/gpu-operator --version v22.9.0 \
--set driver.enabled=true \
--set migManager.enabled=false \
--set mig.strategy=mixed \
--set toolkit.enabled=true
Устанавливаем чарт nebuly/nos
Устанавливаем nebuly/nos Helm-чарт и, в отдельное пространство имен, nebuly-nos. Оставим дефолтные значения, дополнительные параметры нам не понадобятся:
helm install oci://ghcr.io/nebuly-ai/helm-charts/nos \
--version 0.1.2 \
--namespace nebuly-nos \
--generate-name \
--create-namespace
С доступными значениями можно ознакомиться по ссылке, а основная документация по установке есть на сайте.
Как работает динамический шеринг GPU
ReplicaSet GPU Partitioner отслеживает ожидающие поды, которые не могут задеплоиться из-за нехватки запрашиваемых ресурсов MIG/MPS. Если он находит такие модули, то проверяет их текущее «состояние разбиения GPU» в кластере. После — ищет новый профиль разделения, который позволил бы задеплоить их без удаления используемых ресурсов.
Модуль делает это с помощью внутреннего планировщика Kubernetes, так что перед выбором разбиения имитирует деплой. Так он проверяет, действительно ли шеринг позволит задеплоить ожидающие поды. Если для планирования ожидающих модулей можно использовать конфигурацию с несколькими разделами, ReplicaSet GPU Partitioner выберет ту, которая приведет к наибольшему числу планируемых подов.
Более того, в случае разбиения по MIG каждая модель GPU (A100 — 19 конфигураций, A30 — 5 конфигураций) позволяет создавать только определенные комбинации профилей MIG (партиции, geometries). Поэтому GPU Partitioner учитывает это ограничение при попытке найти новое разбиение.
Доступные партиции MIG для каждой модели видеокарты определяются параметром
gpuPartitioner.knownMigGeometries в values.yaml. Файл похоже на конфиг-мапу, определяемую в операторе GPU при конфигурации менеджера MIG.Динамический MIG
Фактическое разбиение на партиции выполняется с помощью DaemonSet MIG-agent, который запускает поды на всех нодах с лейблом
nebuly.com/gpu-partitioning: mig, который создает и удаляет профили в соответствии с GPU Partitioner.В нашем случае поды выглядят так:

MIG-agent предоставляет разделителю GPU используемые и свободные ресурсы всех графических процессоров. Он это делает с помощью аннотаций узлов:
nos.nebuly.com/status-gpu-‹index>-‹mig-profile>-free: <quantity>
nos.nebuly.com/status-gpu-<index>-<mig-profile>-used: <quantity>
MIG-agent также отслеживает аннотации ноды и каждый раз, когда желаемое разделение MIG не соответствует текущему состоянию, пытается применить его, создавая и удаляя профили MIG на целевых графических процессорах. GPU Partitioner определяет партиции графических процессоров с помощью аннотаций в следующем формате:
nos.nebuly.com/spec-gpu-‹index>-<mig-profile>: <quantity>
Обратите внимание: в некоторых случаях MIG–agent не может применить желаемую партицию, указанную GPU Partitioner.
- MIG-agent никогда не удаляет ресурсы MIG, используемые подом.
- Часть конфигураций MIG требует, чтобы профили создавались в определенном порядке. Но MIG не всегда может удалить и повторно создать существующие профили в порядке, нужном новой партиции MIG.
В этих случаях MIG-agent пытается применить разделение, создавая как можно больше требуемых ресурсов, чтобы максимально увеличить количество планируемых модулей. Это может привести к тому, что MIG-agent применит партицию лишь частично.
В целом, особо любопытные разработчики могут покапаться внутри исходников NOS и понять, как они добились динамического разделения GPU. Пока я дошел только до имплементации библиотеки C++ для работы с NVIDIA API. Уверен, где-то там и кроются все ответы.
- Клиент на Go, который и реализует партицирование GPU. И еще один фрагмент.
- Репозиторий, в котором можно посмотреть хидеры С-библиотеки по работе с MIG.
- Фрагмент кода на C++, в котором описано добавление нового профиля MIG: профили складываются из количества gpu compute instance и видеопамяти.

В целом, где-то в этом методе и кроется вся магия партицирования. Мы же воспользуемся их готовым инструментом и проверим, действительно ли можно динамические разделять GPU на различные партиции MIG.
Тестируем динамический MIG на практике
В прошлой статье мы реализовали следующую схему небольшой «высоконагруженной» инференс-платформы. За активную нагрузку на видеокарту мы взяли Triton Inference Server, который деплоили на партиции MIG. При этом мы заранее сделали разметку MIG на семь партиций 1g.5gb в Kubernetes.
Однако у этого подхода есть проблема: при небольшой нагрузки могут простаивать одни из партиций MIG. Также разбиение на меньшие части не всегда может быть хорошим вариантом.

С помощью NOS в данной схеме мы можем сделать так, чтобы разметка партиций на видеокарте выбиралась автоматически и переконфигурировалась по требованию. Тогда при деплое Triton Inference Server с необходимым ресурсом (например, 2g.10gb), если в GPU можно выделить данную партицию, сервисы NOS автоматически разметят видеокарту и выделят ресурсы поду.
Если на GPU уже есть активная нагрузка, то переконфигурирование GPU произойдет безболезненно для запущенных процессов. Рассмотрим несколько тест-кейсов с динамическим MIG.
Шеринг неразмеченной GPU
Дано
- Kubernetes, нода с GPU A100.
- MIG активирован на GPU, но без размеченных профилей MIG.
- NOS установлен.
Ожидание: сервисы NOS увидят новый под, которому требуется, например, 1g.5gb. После разметят под на нужный профиль, а также автоматически выделят ресурсы в Kubernetes.
Эксперимент
Изначально nvidia-smi показывает следующее:

Как видно, на ноде есть карта A100 с включенным MIG. При этом разметки по партициям нет.
Задеплоим наш инференс-сервер с помощью следующего манифеста (3g.20gb — требуемый ресурс):
apiVersion: apps/v1
kind: Deployment
metadata:
name: tritonserver
labels:
app: tritonserver
spec:
replicas: 1
selector:
matchLabels:
app: tritonserver
template:
metadata:
labels:
app: tritonserver
spec:
volumes:
- name: models
nfs:
server: 10.222.2.34
path: /shares/share-f70da758-a056-4944-80c1-f10e2b2aa919/server/docs/examples/model_repository
readOnly: false
containers:
- name: tritonserver
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:23.09-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["/opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=true"]
resources:
limits:
nvidia.com/mig-3g.20gb: 1
После деплоя зайдем в логи nos-gpu-partitioner и посмотрим, какую конфигурацию он применил:
{"level":"info","ts":1699477577.4484377,"msg":"found 1 pending pods","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76"}
{"level":"info","ts":1699477577.4485033,"msg":"1 out of 1 pending pods could be helped","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76"}
{"level":"info","ts":1699477577.4493506,"msg":"computed desired partitioning state","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76","partitioning":{"DesiredState":{"nebuly-node-d91s8":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-2g.10gb":2,"nvidia.com/mig-3g.20gb":1}}]}}}}
{"level":"info","ts":1699477577.449568,"msg":"applying desired partitioning","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76"}
{"level":"info","ts":1699477577.4496982,"msg":"partitioning node","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76","node":"nebuly-node-d91s8","partitioning":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-2g.10gb":2,"nvidia.com/mig-3g.20gb":1}}]}}
{"level":"info","ts":1699477577.470942,"msg":"plan applied","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-798585c99b-hl7pl","namespace":"default"},"namespace":"default","name":"tritonserver-798585c99b-hl7pl","reconcileID":"4b1817fa-96af-4a24-a11f-ed9ad7209c76"}
В логах можно увидеть, что сервис нашел под, который ожидает ресурс 3g.20gb. Далее он выбрал подходящую конфигурацию MIG из доступных —
"Resources":{"nvidia.com/mig-2g.10gb":2,"nvidia.com/mig-3g.20gb":1} — и успешно разметил видеокарту.Если вызвать nvidia-smi, можно увидеть, что разметка прошла успешно и сервер задеплоился:

Результат: NOS подобрал наиболее подходящую конфигурацию под MIG (выбрал одну из 19 конфигураций для A100) и активировал ее в GPU. При этом под сам автоматически забрал себе ресурс.
Шеринг неправильно размеченной GPU
Дано
- Kubernetes, нода с GPU A100.
- MIG активирован на GPU, размечен на nvidia.com/mig-2g.10gb":2,«nvidia.com/mig-3g.20gb»:1.
- NOS установлен.
Ожидание: при изменении требований к ресурсу пода, которого нет в текущей конфигурации MIG, произойдет динамическое переконфигурирование в GPU.
Эксперимент
Изменим в манифесте сервера Triton требования к ресурсу GPU, которого нет в текущей конфигурации MIG:
resources:
limits:
nvidia.com/mig-3g.20gb: 1
Как было.
resources:
limits:
nvidia.com/mig-1g.5gb: 1
Как стало.
После деплоя зайдем в логи nos-gpu-partitioner и посмотрим, какую конфигурацию MIG он применил:
{"level":"info","ts":1699478343.5615623,"msg":"found 1 pending pods","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb"}
{"level":"info","ts":1699478343.5615838,"msg":"1 out of 1 pending pods could be helped","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb"}
{"level":"info","ts":1699478343.562547,"msg":"computed desired partitioning state","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb","partitioning":{"DesiredState":{"nebuly-node-d91s8":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-3g.20gb":1}}]}}}}
{"level":"info","ts":1699478343.5626013,"msg":"applying desired partitioning","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb"}
{"level":"info","ts":1699478343.562712,"msg":"partitioning node","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb","node":"nebuly-node-d91s8","partitioning":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-3g.20gb":1}}]}}
{"level":"info","ts":1699478343.580485,"msg":"plan applied","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver-5c768747fc-95cvb","namespace":"default"},"namespace":"default","name":"tritonserver-5c768747fc-95cvb","reconcileID":"f33fd246-b583-456e-b9b6-1c3b783b65bb"}
Как видно из логов, переконфигурирование прошло успешно. Выбрана следующая конфигурация:
"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-3g.20gb":1
При этом сервер пересоздался. Если выбран тип деплоя RollingUpdate, сначала появится новый под и под переконфигурируется с активной нагрузкой на старой партиции 3g.20gb. То есть пока новый под на 1g.5gb не поднимется, старый не задестроится.

Результат: NOS подобрал наиболее подходящую конфигурацию под MIG для новых требований. При этом учел, что нужно сохранить 3g.20gb для старой версии пода.
Шеринг неправильно размеченной GPU с активной нагрузкой
Дано
- Kubernetes, нода с GPU A100.
- MIG активирован на GPU, размечен на nvidia.com/mig-1g.5gb":3,«nvidia.com/mig-3g.20gb»:1.
- На 1g.5gb есть активная нагрузка в виде сервера Triton.
- NOS установлен.
Ожидание: при деплое второго экземпляра пода, где нужен, например, ресурс 2g.10gb, NOS сделает переразметку профилей MIG. При этом старый под не задестроится.
Эксперимент
Задеплоим второй экземпляр Deployment с двумя репликами, которому нужен ресурс 2g.10gb. Его в текущей разметке нет, но есть активная нагрузка на 1g.10gb. NOS должен подобрать такую конфигурацию MIG, где есть 1g.10gb и две штуки 2g.10gb одновременно.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tritonserver2
labels:
app: tritonserver2
spec:
replicas: 2
selector:
matchLabels:
app: tritonserver2
template:
metadata:
labels:
app: tritonserver2
spec:
volumes:
- name: models
nfs:
server: 10.222.2.34
path: /shares/share-f70da758-a056-4944-80c1-f10e2b2aa919/server/docs/examples/model_repository
readOnly: false
containers:
- name: tritonserver2
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:23.05-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["/opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=false"]
resources:
limits:
nvidia.com/mig-2g.10gb: 1
Для чистоты эксперимента будем отправлять запросы на инференс-сервер с помощью утилиты perf_client, как мы делали в прошлых статьях для проверки пропускной способности.
Задеплоим сервис для доступа извне к инференс-серверу:
apiVersion: v1
kind: Service
metadata:
name: tritonserver
labels:
app: tritonserver
spec:
selector:
app: tritonserver
ports:
- protocol: TCP
port: 8000
name: http
targetPort: 8000
- protocol: TCP
port: 8001
name: grpc
targetPort: 8001
- protocol: TCP
port: 8002
name: metrics
targetPort: 8002
type: LoadBalancer
Запустим perf_client для постоянного обращения к инференс-серверу:
perf_client -i http -u triton-server -m densenet_onnx --concurrency-range 60:100 -u <load_balancer_ip>:8000
Посмотрим в логи nos-gpu-partitioner:
{"level":"info","s":1699478976.830188,"msg":"1 out of 1 pending pods could beheped","controller":"mig-artitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-kgt58","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-kgt58","reconcileID":"c82b3391-c484-4228-999f-640522961941"}
{"level":"info","ts":1699479439.9892967,"msg":"found 2 pending pods","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96"}
{"level":"info","ts":1699479439.9893067,"msg":"2 out of 2 pending pods could be helped","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96"}
{"level":"info","ts":1699479439.9899423,"msg":"computed desired partitioning state","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96","partitioning":{"DesiredState":{"nebuly-node-d91s8":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-2g.10gb":2}}]}}}}
{"level":"info","ts":1699479439.9899855,"msg":"applying desired partitioning","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96"}
{"level":"info","ts":1699479439.990069,"msg":"partitioning node","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96","node":"nebuly-node-d91s8","partitioning":{"GPUs":[{"GPUIndex":0,"Resources":{"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-2g.10gb":2}}]}}
{"level":"info","ts":1699479440.007275,"msg":"plan applied","controller":"mig-partitioner-controller","controllerGroup":"","controllerKind":"Pod","Pod":{"name":"tritonserver2-56bd8b6775-2cnng","namespace":"default"},"namespace":"default","name":"tritonserver2-56bd8b6775-2cnng","reconcileID":"f13eff4d-75b5-4d8b-b9e2-002feb92ab96"}
NOS подобрал следующую конфигурацию:
"nvidia.com/mig-1g.5gb":3,"nvidia.com/mig-2g.10gb":2
Утилита nvidia-smi показывает активную нагрузку на третьей партиции:

При этом сервер Triton на 1g.5gb не прекращал работать. Perf_client не показал дополнительных задержек или отклонений во время смены конфигурации:
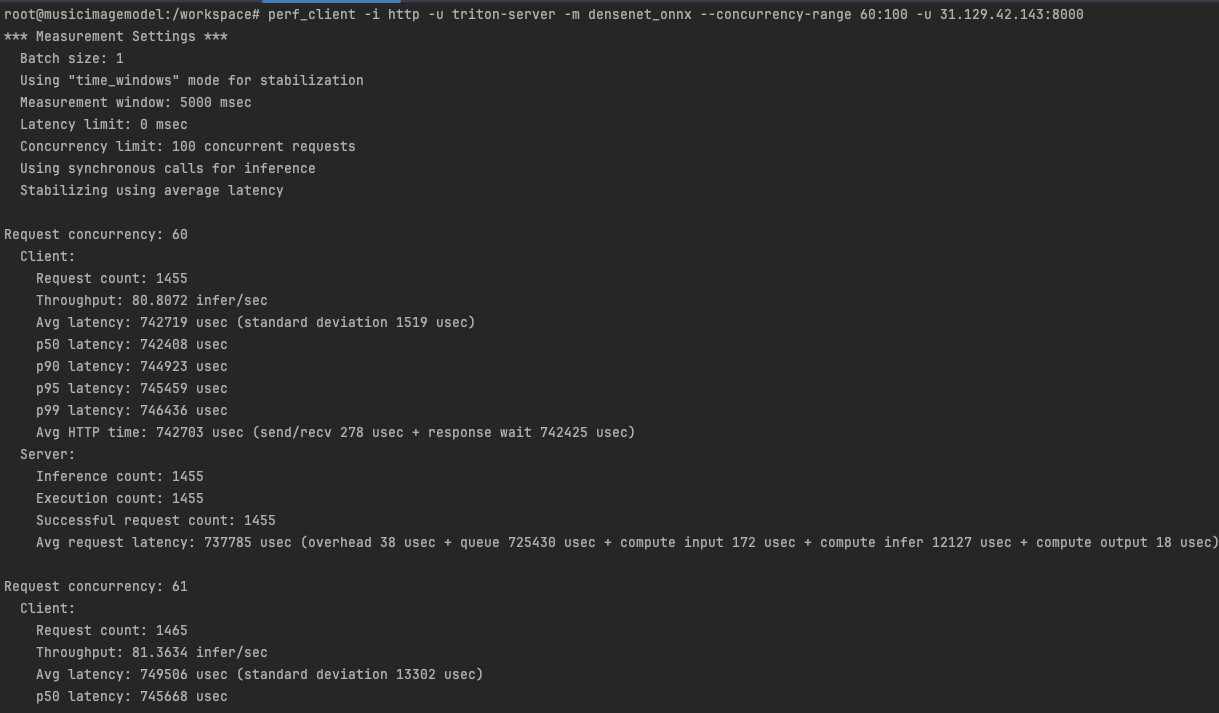
Результат: Действительно, даже при активной нагрузке происходит разбиение MIG, если есть доступная новая конфигурация. При этом переконфигурирование происходит безболезненно для уже существующей нагрузки.
Вывод
Данные кейсы продемонстрируют, как работает динамическая конфигурация MIG. Если ранее с помощью оператора GPU мы могли активировать MIG и разметить профили заранее, с помощью NOS мы можем динамически размечать карту на различные партиции по требованию ресурсов.
Сравнение MPS, MIG, Timeslicing
Остается только вопрос: какую технологию шеринга GPU выбрать? Давайте сравним технологии, которые мы разбирали в цикле наших статей.
Multi-Process Service (MPS)
Для начала разберемся, что такое MPS — ранее мы его не рассматривали.
Multi-Process Service (MPS) — это клиент-серверная реализация интерфейса прикладного программирования CUDA (API) для одновременного запуска нескольких процессов на одном графическом процессоре.
В MPS сервер управляет доступом к GPU, обеспечивая параллелизм между клиентами.
Они подключаются к серверу через клиентскую среду выполнения, которая встроена в библиотеку драйверов CUDA и может прозрачно использоваться любым приложением CUDA.
MPS обеспечивает детальный контроль над графическим процессором, назначенным каждому клиенту, позволяя устанавливать произвольные ограничения как на объем выделенной памяти, так и на доступные вычисления. Это основное его преимущество.
Плагин Nebuly k8s-device-plugin использует эту функцию для предоставления доступа к ресурсам графического процессора Kubernetes с произвольным объемом выделенной памяти, определенным пользователем. Также есть issue, который позволяет запускать MPS поверх MIG.
По сравнению с сокращением времени, MPS устраняет накладные расходы, связанные с переключением контекста. За счет параллельного запуска процессов и совместного использования пространства — повышает производительность вычислений.
Более того, MPS предоставляет каждому клиенту собственное адресное пространство памяти GPU. Это позволяет применять ограничения памяти к процессам, преодолевая проблемы совместного использования с сокращением времени.
При этом важно: процессы, совместно использующие GPU через MPS, не полностью изолированы друг от друга. Технология не обеспечивает изоляцию ошибок и защиту памяти. Это значит, что клиентский процесс может завершиться сбоем и привести к перезагрузке графического процессора, что повлияет на все другие процессы. Однако эту проблему часто можно решить путем правильной обработки ошибок CUDA и сигналов SIGTERM.
Сравнение технологий шеринга GPU
В этом разделе мы сравним технологии совместного использования GPU и посмотрим, как они влияют на производительность рабочих нагрузок.
Мы протестируем:
- Multi-Process Service (MPS),
- Multi-Instance GPU (MIG),
- TimeSlicing.
Я буду опираться на статью. Наша задача — повторить эксперименты на развернутой инфраструктуре и прийти к тем же выводам.
Для начала ознакомимся с отличиями между этими технологиями.
| Технология шеринга |
Поддержка Nos |
Уровень изоляции рабочей нагрузки |
Плюсы |
Минусы |
| Multi-instance GPU (MIG) |
+ |
Наилучший |
|
|
| Multi-process server (MPS) |
+ |
Средний |
|
|
| TimeSlicing |
— | Отсутствует |
|
|
Мы будем измерять производительность каждой технологии шеринга видеокарт, запуская набор модулей на одной и той же GPU. Каждый модуль имеет простой контейнер, который постоянно выполняет активную нагрузку на модели YOLOS. Время выполнения каждого инференс-запроса будем собирать в Prometheus.
Мы выполним этот эксперимент несколько раз. Каждый раз — с разным количеством реплик, работающих на одном и том же графическом процессоре (1, 3, 5 и 7). В теории мы должны прийти к такому результату:

Будем использовать Kubernetes, который развернули для тестирования динамического MIG. Вот его характеристики:
- 6 vCPU,
- 87 ГБ RAM,
- 100 ГБ диск,
- 1 A100 GPU 40 ГБ — в отличии от демонстрации NOS, где используется карта A100 с 80 ГБ,
- драйвер nvidia 525.
Склонируем репозиторий и перейдем в папку demos/gpu-sharing-comparison. Ознакомимся с Readme и подготовим инфраструктуру. Отмечу: кластер Kubernetes я пересоздал и удалил все поды c Triton-сервером ю и чарты (оператор GPU, NOS), которые использовал в предыдущем разделе.
Для установки всех необходимых компонент необходимо импортировать kubeconfig от нашего кластера, запустить команду
make install для установки оператора GPU. В values.yml можно заметить, что migManager стоит в False — это связано с тем, что функцию конфигурирования MIG берет на себя NOS:driver:
enabled: true
toolkit:
enabled: true
migManager:
enabled: false
mig:
strategy: mixed
devicePlugin:
enabled: false
daemonsets:
priorityClassName: system-node-critical
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
node-feature-discovery:
worker:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "nvidia.com/gpu"
operator: "Equal"
value: "present"
effect: "NoSchedule"
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
Далее установил NOS и nvidia-device-plugin. В values.yml задаем конфигурацию TimeSlicing. указываем максимум — семь возможных ресурсов:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nos.nebuly.com/gpu-partitioning
operator: NotIn
values:
- mps
- key: nvidia.com/gpu.present
operator: Exists
selectorLabelsOverride:
app: nvidia-device-plugin-daemonset
migStrategy: mixed
config:
map:
default: |
version: v1
sharing:
timeSlicing:
renameByDefault: true
failRequestsGreaterThanOne: true
resources:
- name: nvidia.com/gpu
replicas: 7
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
Последним устанавливаем cert-manager и kube-prometheus. В values.yml задаем скоуп метрик GPU:
сadditionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
serviceMonitorSelectorNilUsesHelmValues: false
В примере мы запускаем тесты, создавая Deployment с одним подом, в котором запущен клиентский контейнер Benchmarks Client. Далее создадим различные окружения Deployment для каждой технологии шеринга GPU.
В каждом Deployment Benchmarks Client всегда запрашивает фрагмент GPU с 5 ГБ памяти. Название ресурса, запрашиваемого контейнером benchmarks, зависит от конкретной технологии шеринга:
- MIG — nvidia.com/mig-1g.5gb: 1
- MPS — nvidia.com/gpu-6gb: 1
- TimeSlicing — nvidia.com/gpu.shared: 1
В данном эксперименте мы будем менять количество реплик в Deployment, который содержит в себе YOLOS-small модель для создания активной нагрузки на GPU:
apiVersion: apps/v1
kind: Deployment
metadata:
name: benchmarks-client
namespace: nos-gpu-sharing-comparison
spec:
selector:
matchLabels:
app.kubernetes.io/component: benchmarks-client
replicas: 7
template:
metadata:
labels:
app.kubernetes.io/component: benchmarks-client
spec:
securityContext:
runAsNonRoot: true
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
containers:
- image: ghcr.io/telemaco019/demos/gpu-sharing-comparison:latest
name: benchmarks-client
imagePullPolicy: Always
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- "ALL"
resources:
limits:
cpu: "500m"
memory: 4Gi
ports:
- name: prometheus
containerPort: 8000
terminationGracePeriodSeconds: 10
Последовательность эксперимента
- Активируем одну из технологий шеринга GPU на ноде.
- Создадим под с бенчмарком, который запрашивает ресурс GPU.
- Подождем три минуты.
- Вычислим среднее время ответа интересна за последние две минуты.
Соответственно, измерять результаты мы будем по метрике — среднему времени ответа инференса за две минуты. Наименьшее время покажет наилучшую технологию.
Запускаем тест на Timeslicing
Воспользуемся следующей командой:
make deploy-ts
При этом необходимо каждый раз менять количество реплик в deployment benchmarks-client, манифест которого описан выше. Менять необходимо в последовательности 1-3-5-7.

Также для просмотра бенчмарков необходимо сделать форвард порта для Prometheus:
make port-forward-prometheus
Далее смотрим значение нашей метрики по формуле (спустя 2 минуты после деплоя):
avg(sum(rate(inference_time_seconds_sum[2m])) / sum(rate(inference_time_seconds_count[2m])))

Это необходимо будет сделать и для последующих экспериментов.
Запускаем тест на MPS
Для начала необходимо понять, как работает nvidia-device-plugin от nebuly. В целом, настройка MPS не отличается от настройки TimeSlicing.
Нам достаточно передать в конфиге плагина настройки для MPS и указать, как будет называться лейбл для ресурса GPU. А также — сколько реплик и памяти мы закладываем на одну партицию.
Конфигурация выглядит следующим образом:
version: v1
flags:
migStrategy: none
sharing:
mps:
failRequestsGreaterThanOne: true
resources:
- name: nvidia.com/gpu
rename: nvidia.com/gpu-6gb
memoryGB: 6
replicas: 7
devices: ["0"]
Соответственно, мы выделяем под каждую партицию 5 ГБ видеопамяти, что невозможно сделать с TimesSlicing, и переименовываем nvidia.com/gpu в nvidia.com/gpu-5gb
Порядок активации MPS на ноде
1. Активируем MPS на ноде с помощью лейбла:
kubectl label nodes <gpu-node> nos.nebuly.com/gpu-partitioning=mps
2. Создадим Deployment с бенчмарком, который запрашивает ресурс GPU:
spec:
template:
spec:
hostIPC: true
securityContext:
runAsUser: 1000
make deploy-mps
3. Подождем пару секунд, пока NOS автоматически не выделит поду запрашиваемую конфигурацию.
При правильной настройки MPS-сервера в логах контейнера nvidia-mps-server должно отобразиться примерно следующее:

Также вывод nvidia-smi показывает, что сейчас запущено семь реплик нашего бенчмарка — и все на одной видеокарте. Еще один процесс — nvidia-cuda-mps-server, который управляет потоками на уровне CUDA:
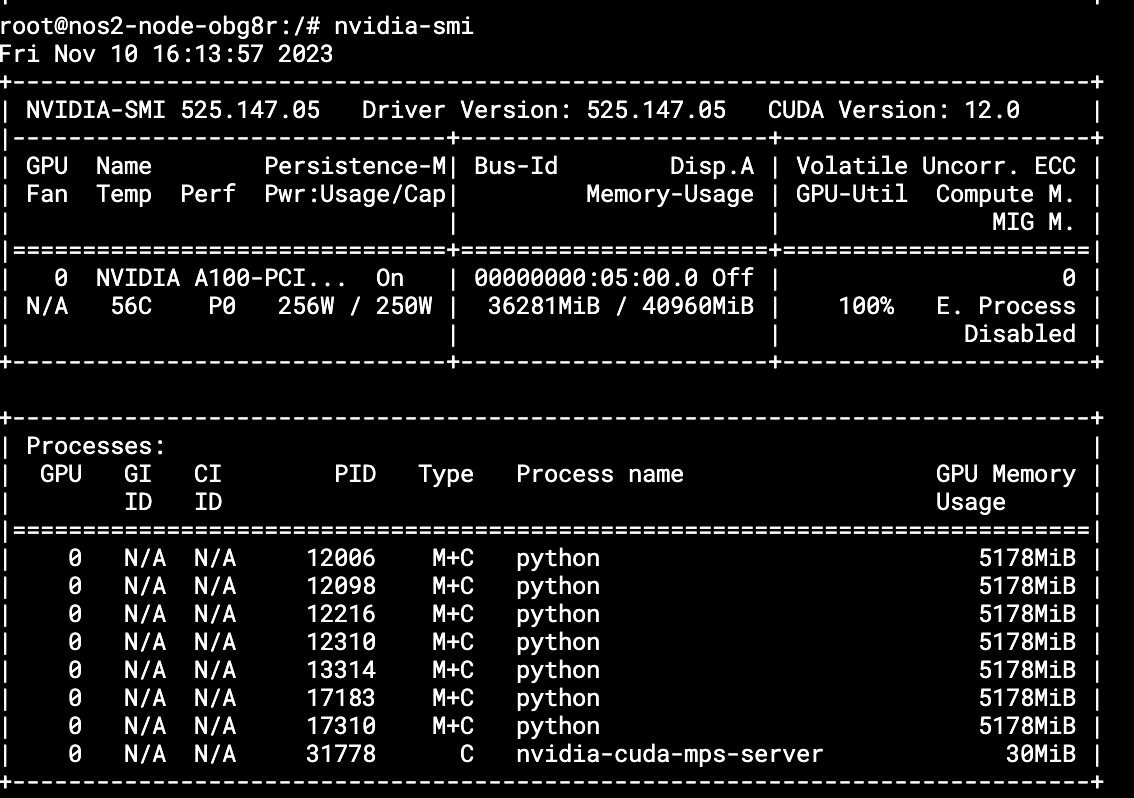
Я пробовал запускать на 5 ГБ видеопамяти, но модель просто не отрабатывала. Cuda server не давал ей запуститься и она не занимала активную нагрузку. Также потребовалось установить 525 драйвер NVIDIA, изначально 470 схема не работала.
Запускаем тест на MIG
Запустим тесты для первой, третьей, пятой и седьмой реплик и зафиксируем результаты в таблице. В качестве партиции выберем 1g.5gb.
1. Для начала активируем MIG на ноде:
sudo nvidia-smi -i 0 -mig 1
2. Активируем динамический MIG:
kubectl label nodes <gpu-node> nos.nebuly.com/gpu-partitioning=mig
3. Создадим Deployment с бенчмарком с нужной конфигурацией:
make deploy-mig
4. Подождем пару секунд, NOS динамически подберет нужную конфигурацию MIG. При запуске всех семи реплик nvidia-smi должен показать следующее:

На самом деле, выбранная модель для бенчмарка не вмещается в наименьшую партицию MIG, на предыдущих тестах мы видели, что модель занимает больше 5 ГБ.
Но это не помешало запуститься ей на партиции MIG, в отличие от теста с MPS, где в ограничениях по памяти нужно было указать минимум 6 ГБ. В TimeSlicing ограничений по памяти нет, поэтому там реплики разделяют общее адресное пространство.
Воспользуемся преимуществом динамического MIG. Изменим требования к ресурсам, чтобы одной реплике выделялся 2g.10gb. NOS автоматически переконфигурирует MIG на 3 части 2g.10gb и 1 часть 1g.5gb.
Также проведем замеры на одной и третьей репликах (5 и 7 не получится, так как не хватает места в видеокарте). Если смотреть nvidia-smi, можно обнаружить, что занимаемая память не слишком увеличилась. Но результаты бенчмарка лучше почти в два раза. Это связано с тем, что на каждую партицию добавилось еще по одному compute unit.

Анализируем результаты
Ниже — таблица, в которой мы зафиксировали значение формулы из Prometheus на разном количестве запущенных реплик:
| 1 pod |
3 pod |
5 pod |
7 pod |
|
| TimeSlicing |
0.09050836608163315 |
0.30085825146380296 |
0.4993968177888305 |
0.6004496900353387 |
| MPS |
0.0906609925383058 |
0.17016109033480073 |
0.2528740288475843 |
0.3348583714126451 |
| MIG (1g.5gb) |
0.35469598418669795 |
0.3557782260357195 |
0.35432991796849783 |
0.3674875746845398 |
| MIG (2g.10gb) |
0.20145802699181992 |
0.20089925431643463 |
— | — |
Для лучшей визуализации построим график зависимости среднего отклика инференса за две минуты от количество реплик:

Выводы
При использовании разных технологий шеринга GPU на видеокарте аллоцируется разный объем видеопамяти.
- В случае с MIG модель «съела» меньше всего памяти.
- MPS не запускал модель, если в требованиях к ресурсам указано меньше памяти, чем эта модель действительно потребляет. При этом для успешного деплоя в GPU пришлось указать объем больше, чем в MIG.
- TimeSlicing потребляет больше всего видеопамяти.
Также важно, какое количество compute unit задействовано в ворклоаде.
- При разделении MIG и выборе наименьшей партиции с одним compute unit время ответа будет меньше, чем в MPS. Это связано с тем, что мы выделяем только один compute unit для ворклоада, в отличие от MPS, где используются все семь и регулируются потоками через MPS Cuda server. Если указать партицию с двумя compute unit, результаты будут сопоставимы с MPS (только максимальное количество реплик снизилось до трех).
- TimeSlicing показывает плохие результаты, так как для каждой реплики выделяется квант времени работы ворклоада.
- Наилучшая изоляция происходит при применении MIG, так как для ворклоада выделяется отдельная видеокарта. При этом динамический шеринг с помощью MIG позволяет нам управлять деплоем ворклоадов без опасений о завершении работы текущих ворклоадов.
Заключение
В этой статье мы посмотрели, как можно использовать на практике динамический MIG, как это реализовано в коммерческих проектах и в open source, а также сравнили различные технологии шеринга GPU.
Использовать данные технологии или нет — зависит от ваших потребностей и задач. Надеюсь, я смог объяснить, в чем преимущества и особенности каждого из решений. Если у вас есть вопросы, задавайте их в комментариях!
Шеринг GPU в инференс-платформе
Недавно мы окунулись в тему изучения инференс-платформ. Оказалось, это достаточно актуальная тема на рынке. Возможно, вы заметили, что в своих статьях я часто использовал NVIDIA Triton Inference Server — и это не просто так. Поделитесь обратной связью, насколько вам бы хотелось узнать об особенностях этого инференс-сервера в контексте утилизации GPU, и тогда мы напишем новую статью.
Другие статьи по теме
Комментарии (6)

Nikkon-dev
24.11.2023 20:44+1Пара замечаний:
- Приведенные ссылки на код лишь указывают на использование стандартного NVML API - того же самого, который используется nvidia-smi. Реальная логика находится здесь https://github.com/nebuly-ai/nos/blob/d5cc1d72b8ee52b79b8751c0b49122366e026ce1/internal/controllers/migagent/actuator.go#L152C25-L152C25. Здесь же видно, как именно происходит попытка создания-удаления и что при каждом чихе перезапускается nvidia-device-plugin на ноде.
- Ограничение не реконфигурацию MIG улучшилось в новых поколениях - H100 может изменить конфигурацию MIG при наличии активных CUDA контекстов. Естественно поменять/удалить партицию, на которой запущен CUDA контекст все еще нельзя.
antonaleks605 Автор
24.11.2023 20:44Спасибо за ценный комментарий.
По поводу ссылок - действительно интересная находка, добавим ее с ссылкой на вас)
По поводу H100 - на данный момент нет возможности потестировать, но надеемся в скором времени появится и также отпишемся о результатах!

Negash
24.11.2023 20:44+1node-autoscaler работает с nos?
antonaleks605 Автор
24.11.2023 20:44В целом nos можно также использовать с hpa и prometheus адаптер, как я приводил пример с gpu-оператором в предыдущей статье. С node-autoscaler кейс мы не проверяли, но звучит интересно. Обязательно попробуем и отпишемся о результатах!
red5
Да, очень интересно.
antonaleks605 Автор
Спасибо за обратную связь! Уже насобирали пару интересных особенностей этого инференс сервера, поэтому ждите обновлений)