

Будет ли определение размера хорошим предсказателем того, когда вы сможете получить свой результат? В нашем случае удивительной правдой оказался ответ «нет». Mattias Skarin. Real-World Kanban
Часто на системные факторы тратится больше времени доставки, чем на различные размеры пользовательских историй. Troy Magennis
Привет! Меня зовут Павел Ахметчанов, я руководитель направления улучшения процессов разработки. В статье расскажу про часто используемые методики оценок задач и есть ли в них ошибки. Посмотрим, как правильно ставить вопросы при оценке. Узнаем, что собой представляет время решения задач, а это далеко не очевидная вещь. Попробуем изменить свое мышление и получим рецепт для определения времени решения задач.
Если спросить любого начинающего исследователя этой темы «А зачем нам оценка?», он скажет, что постоянно задают вопрос «Когда вы выполните эту задачу?», на который и надо ответить с помощью этой оценки. А что, если сам вопрос задан неверно?
Поставим вопрос по-другому
«Когда вы выполните эту задачу?» — в психологии такой вопрос называется открытым, потому что на него можно дать бесконечное множество ответов и при этом вы будете правы. Но устроит ли нашего заказчика ответ «Через 5 лет»? В большинстве случаев нет.
Открытый вопрос с точки зрения математики — это вопрос, заданный простой функцией T(x1, x2, x3, …, xn), где xi — это параметры функции, нашей системы, в которую входит множество параметров, такие как зависимости задач, количество специалистов, их опыт, техническая оснащенность и многое другое, а T — это время решения задачи, ответ.
Решение такой функции в математике называется решением прямой задачи. Прямые задачи могут решаться только в закрытых системах, где мы можем прямым или косвенным способом узнать все значения xi.
В открытых же системах, где значения всех xi неизвестны, такая функция не решается и имеет множество ответов на вопрос.
Для открытых систем существует метод поиска решений, когда к заданному результату функции T мы подбираем подходящие параметры и, уже зная набор влияющих на результат параметров xi, можем сказать, что для этого T существуют вот такие наборы значений xi, чтобы получить такой результат.
Иначе говоря, зададим вопрос по-другому: «Сможем ли мы решить задачу к такому-то сроку?» Это закрытый вопрос с однозначным ответом и интересующим нас результатом. В математике такая постановка является обратной задачей, так как для ответа мы задаем ожидаемый результат функции и нам надо перебрать набор параметров, которые подходят под этот ответ, чтобы понять, достижим такой результат или нет.
Для решения обратных задач в математике существуют численные методы, теория вероятности, статистика. Зная, к какому сроку нам нужно выполнить задачу, мы можем, исходя из существующих ресурсов, определить, возможно ли решить задачу к этому сроку и при каких условиях.
Прокрутите это в голове и сравните два вопроса: «Когда вы выполните эту задачу?» и «Сможем ли мы решить задачу к такому-то сроку?» На какой вам будет проще ответить?
Даже если ответ на вопрос «Сможем ли мы решить задачу к такому-то сроку?» окажется «Нет», используя способ из численных методов, мы зададим другой срок решения задачи и сново попробуем перебрать параметры для нового срока.
Такой способ не гарантирует 100%-е попадание в сроки, но позволяет приблизится к ответу при известных переменных. И чем больше информации как о самой задаче, так и о среде ее решения будет, тем больше шансов спрогнозировать точный ответ.
Забавным в рамках этой методики может оказаться случай, когда на встречный вопрос «А когда вам надо?» вы можете получить от заказчика ответ «Вчера!». И с чувством облегчения можете ответить: «Мы уже опоздали».
Вывод. Сам по себе вопрос «А когда вы выполните эту задачу?» поставлен как открытый. Чтобы найти компромисс среди ответов, необходимо переформулировать вопрос и задать его в закрытой форме. И если ответ на этот закрытый вопрос не устраивает, повторить опыт с изменением срока или условием задачи.
Но чтобы отвечать на вопрос «Успеете выполнить эту задачу к такому-то сроку?», надо понимать, что такое время решения задач.
Что такое время решения задач
Чтобы понять, что такое время, нам нужно принять во внимание, что есть некоторый сервис — команда, на которую мы смотрим как на черный ящик. В этот черный ящик поступают задачи, а из него мы получаем результат.

Катя просит сделать определенные задачи, Коля с командой говорит: «Да, ок». С момента, когда команда берет обязательство выполнить задачу, мы начинаем отсчет времени выполнения. Когда Катерина фиксирует результат, который вернулся ей или доставлен клиенту, мы завершим отсчет этого времени. Можно визуализировать так:

У нас получится два значения времени. Разницу между этими точками дат-времени назовем Lead Time — временем выполнения задачи.
Если мы соберем время выполнения задач за какой-то период и отметим точкой на графике по горизонтали, сколько дней потратили на решение задачи, а по вертикали — сколько таких задач было решено за такое же количество дней, то распределение Lead Time можно представить на графике:

График помогает понять, что даже схожие задачи могут выполняться разное количество дней. Задача, которую вчера мы делали за 3 дня, встав с правой ноги, сегодня, когда мы встали с левой, будет выполняться дольше, например за 5 дней. На выполнение влияют разные факторы. На графике видно, что все задачи были решены в течение 11 дней, при этом значительный объем задач решается за 8 дней, хотя есть вероятность сделать задачи и за день.
Прогнозирование времени выполнения задач — это сложно
Многие исследователи пытались ответить на вопрос «Когда будут решены задачи?».
Прогноз — это сложно, стоит просто принять этот факт. Какой бы подход мы ни пробовали, это сложный когнитивный процесс, которым занимались многие: Даниэль Канеман, Трой Макгинес, Дмитрий Бакарджиев, Сти́вен Макко́ннелл и другие. Много книг посвящено тому, как оценивать интеллектуальную работу.
Мы не одиноки, и, если ошибаемся в своих прогнозах, это нормально: до нас тоже ошибались.
Одним из самых популярных изобретений для индустрии ИТ стали оценки в Story Points. Их предложил Рон Джеффрис в качестве альтернативы точной оценке по времени, которой требовали от него менеджеры. Рон придумал их для организации процесса разработки под названием XP, а уже потом они каким-то образом перешли в Scrum. Позже он написал статью с извинением за свое изобретение.
Рассмотрим примеры двух исследователей, Майка Кон и Аджая Редди, чтобы понять, что оценка времени решения задач — это действительно непросто.
Пример первый. Майк Кон активно распространяет методику оценки, основанную на Story Points, которую рекомендует использовать для оценки задач и выявления сроков их решения. Приведу пример из его старой книги «Agile. Оценка и планирование проектов». Чтобы объяснить, как же связаны Story Points с временем решения задач, он предложил такой способ:

Чтобы проверить утверждение, мы можем сами построить такой график на основе распределения Lead Time для своих команд, которые используют Story Points. В нашей компании мы провели этот эксперимент, и вот что получили:




В простом варианте можем представить эти распределения в одном из вариантов вида распределения Вэйбула, как в примере с желтым графиком:

Как видно из графиков распределений для Story Points 1, 2, 3, 5, фактический Lead Time, во-первых, не имеет вида нормального распределения, как это было в книге Майка, а во-вторых, время всех Story Points по виду распределения очень схоже. Иначе говоря, задачи разной оценки по Story Points делались за то же самое время с небольшими отличиями.
Подобный эксперимент я проводил для разных команд и не нашел значимой корреляции между оценками в Story Points и временем решения задач.
Возникает вопрос: прав ли был Майк Кон?
Ответ однозначный: нет. Он ошибся.
Второй пример — это пример Аджая Редди. Он подошел к проблеме с другой стороны в своей книге “Scrumban [R]Evolution, The: Getting the Most Out of Agile, Scrum, and Lean Kanban (Agile Software Development Series)”.
Аджай пробовал строить график корреляции между Story Points и временем решения задач, чтобы найти оптимальную формулу для Story Points.

В рамках этого эксперимента Аджай Редди искал какая оценка в Story Points лучше подходит для того, чтобы она коррелировала со временем решения задач. И в рамках эксперимента выявил, что для Story Points лучше использовать оценку как степень двойки, так как получается более линейная корреляция, если она есть.
Мы построили графики для нескольких команд (сервисов), использующих для оценки Story Points, и обнаружили типичную картину:

Возникает вопрос: как Аджай поставил свой эксперимент, что у него получилась хоть какая-то картина корреляции, а у нас не нашлось корреляции вообще?
Ответ: возможно, это был эксперимент с подгонкой результатов или частный случай когда появилась корреляция.
Вы вправе усомниться в моих выводах. Предиктивная оценка, как оценка без проработки обратной связи по результатам основанным на анализе статистики, не имеет смысла для прогнозирования сроков. И даже в экспериментах, проводимых в игровой форме, можно обнаружить, что корреляция между временем выполнения работ и оценкой Story Points либо человеко-часами или подобными способами, называемая предиктивной оценкой, ничтожна на практике.
Одну из таких игр мы проводили в качестве воркшопа вместе с Евгением Степченко на конференции Flow Days в 2022 году. Называется этот воркшоп NoEstimate. Вы можете попробовать провести этот воркшоп, чтобы лучше разобраться в теме.
Вывод: прогнозирование — это сложно, и простые методы получения результата по времени решения задачи в интеллектуальной среде могут работать только как исключительный случай, а не как хорошо отлаженная методика.
Почему задачи решаются по-разному
В понимании этого вопроса нам поможет Дейв Сноуден со своим фреймворком Cynefin. Он разделяет область методов действий на несколько доменов. В зависимости от домена методики принятия решения для систем, ситуаций и задач будут разными.
Одно из главных открытий Дейва — систематизация разных типов сред, в которых работает ваша система. И в этих средах нужно применять разные способы воздействия и методики управления. Дейв выделяет пять основных доменов: Simple, Complicated, Complex, Chaos, Confusion.
Описание фреймворка требует отдельной статьи, поэтому отмечу только, что в рамках интеллектуальной работы мы можем сталкиваться с разными ситуациями и средой и довольно часто со средой в некоторой переходной форме. Притом что большая часть методик оценки проектов и задач могут хорошо работать, если они связаны с доменами Simple и, иногда, Complicated. А во многих случаях приходится решать задачи из области Complex, Complicated и иногда Chaos.
Тот же фреймворк предлагает попробовать понять, в какой ситуации находитесь вы, и следовать из области Chaos в область Simple, используя методы дисциплины под названием «Менеджмент изменений», для упрощения системы в том числе и управления и удешевления за счет уменьшения рисков.
Не менее интересная проблема заключается в том, что люди склонны упрощать причины проблем и методы решения и при этом принимать решения на основе своего текущего состояния, в том числе эмоционального, что мешает как трезво оценить задачи, так и ошибочно принимать решения на основе нерелевантного опыта. О таких проблемах хорошо написано в книге «Думай медленно, решай быстро» Даниэль Канеман.
Часто сложность прогнозирования задач объясняют и более простым способом. Представьте, что задачу оценил Василий и он был в хорошем настроении, когда сказал, что сделает ее за два часа. А задачей начнет заниматься Петр через две недели после прогнозирования в плохом настроении. И после действий Петра над задачей будет работать Катерина, которая определит качество решения, да еще и задача будет ждать завершения других задач, над которыми работала Катерина.
Тогда как оценка Василия может повлиять на фактическое время выполнения? И это мы еще не учли, что задача, оцененная Василием, может быть заблокирована решением от другой команды. К тому же того, что она будет заблокирована на момент прогнозирования, Василий не предполагал.
Вывод. Чтобы прогнозировать, сначала нужно определить, в какой ситуации, какой системе, каком домене находится ваша система. Вы почти всегда находитесь в области работы с рисками. Для ответа на вопрос «Когда вы выполните эту задачу?» нам нужно больше информации о том, как работает система в целом в своей среде.
А возможно ли тогда построить систему, где можно давать прогноз с высокой долей попадания в срок?
Как выстроить систему, в рамках которой можно попадать в срок?
Процесс создания ценности в ИТ можно разложить на два основных этапа:
Upstream — процесс выбора и анализа задач, которые хотим реализовать.
Downstream — процесс разработки и предоставления ценности клиенту или заказчику.
Выстраивать и улучшать любую систему надо с конца процесса.
Строим Downstream. Downstream-процессом управляют либо сами команды, либо тимлиды, иногда технические лидеры.
Чтобы построить процесс с прогнозируемым сроком выполнения для Downstream, есть главное правило — создать ограничение на одновременно решаемую работу. С этим могут помочь техники WIP-лимитов, CONWIP-лимитов, а если команда работает над разными типами задач, поможет техника Capacity Allocation.
Для тех, кто использует технику Story Points или оценку в часах, методика работы WIP-лимитов будет контринтуитивной техникой. Особенно когда речь будет заходить о том, что в работу берем разные по сложности задачи. И особую сложность приносит понимание, что на самом деле Sprint — это не просто итерация на две недели, в которую набираем разные задачи. Скорее это отрезок времени, когда всей командой решается одна задача, называемая целью спринта. В большинстве случаев организации процесса Sprint вообще не нужен, так как этот инструмент, как и сам Scrum, очень контекстный и близкий к домену Complex (по Cynefin). Тут можно рекомендовать игру Featureban для лучшего понимания, как работают WIP-лимиты.
Задав ограничения на разработку, в Downstream-процессе будут выбираться задачи, которые двигаются с разной скоростью, потому что обладают разными рисками и могут быть разными типами работ. Само по себе ограничение на одновременно выполняемую работу будет балансировать фокус внимания команды.

Цель мероприятий — определить естественное ограничение количества одновременно решаемых задач в системе для всех типов, что позволит использовать это в планировании.
На какие особенности стоит обратить при построении Downstream, хорошо объяснил Алексей Пименов в своем докладе «Гарри Тимлидов и современный менеджмент».
Строим Upstream. Upstream-процессом чаще всего управляет Project Manager или Product Owner. Этот процесс отвечает на вопрос «Что именно нужно делать?».
Часто множество этапов Upstream скрываются за одним словом Backlog. Это же свойство может служить хорошим индикатором, насколько хорошо выстроен Upstream-процесс. Если пользуетесь словом Backlog, значит, у вас есть что улучшать.
Наиболее частые проблемы, связанные с Upstream:
Нет выделенных этапов отсева задач — не построена воронка правил.
Задачи на разработку могут быть взяты с любого этапа путем повышения приоритета.
Нет анализа того, какие риски переносятся из Upstream в Downstream при изменении приоритетов и нарушении правил отсева задач.
Хороший Upstream строится с помощью «воронки правил» — так, чтобы количество задач, дошедших до Downstream, было сопоставимо с тем количеством задач, которое Downstream может переработать. Зная ограничение Downstream, мы знаем, какое количество задач нужно подготовить к работе. Значит, формулируем правила отсева задач из Upstream так, чтобы оставались только те, которые можем реализовать, и те, что нужны в ближайшее время. Остальное выкидываем.
Задача Upstream в том, чтобы минимизировать риски, которые могут пройти в Downstream-процесс. С каждым этапом Upstream мы должны иметь набор правил, которые снижают риск, что задача может быть не сделана. Например, Definition of Ready — правила, сформулированные на последнем этапе перед Downstream, где мы можем проверить по чек-листу, нет ли у задач зависимостей, понятно ли они сформулированы.

Получается, что независимо от того, с какой формулировкой к нам приходит задача, мы стараемся снизить до минимума количество рисков, что она будет не сделана.
При этом надо осознавать важную деталь: чем больше рисков вы набираете себе в процесс, тем выше вероятность влияния последствий не только на одну задачу, но и на все остальные.
Одних правил нам будет недостаточно — нужно убедиться в том, что весь процесс Downstream и Upstream был стабильным, чтобы прогнозы, сформулированные на основе наблюдений, сбывались и в будущем.
Строим стабильный процесс и попробуем ответить на вопрос «Успеете к 20 января выполнить эту задачу?»
Категоризируем поступающие задачи. Для начала мы должны разобраться, четко ли сформулирован результат, которого ожидает заказчик.

Давайте сначала определим категории задач, где:
Chaos — задача не ясна, до конца непонятен ожидаемый результат, как ее решать.
Complex — цель задачи определена, но неизвестно, каким образом можно реализовать эту задачу.
Complicated — понятно, как реализовать задачу, но еще неизвестен оптимальный способ ее решения.
Simple — это понятная задача, для которой есть лучшие практики ее реализации.
К нам в систему могут приходить разные задачи — как категории Chaos, так и Simple.
И на входе нам сразу нужно разбить их на эти категории. Если с задачами категории Simple все понятно, нам надо ее только сделать, то для остальных задач необходимо еще провести дополнительные исследования, чтобы снизить риски, связанные с ними.
Мы пробуем перенести задачу из Chaos в категорию Complex, пытаясь ответить на вопросы:
Какую проблему мы решим этой задачей?
Какой конкретно результат ожидается?
Есть ли зависимости у этой задачи, как их разрешить?
И дальше можем упростить задачу, понизив категорию с Complex до Complicated. Отвечаем на вопросы:
Понятно ли, как технически реализовать задачу?
Был ли у нас прошлый опыт и есть ли best practice для решения?
И в конце пробуем упростить от Complicated до Simple:
Какой лучший способ решения задачи подходит?
Кто может решить эту задачу?

К процессу Downstream мы стараемся подвести задачи с наименьшими рисками по их реализации.


Создавая правила с ответами на вопросы, которые митигируют риски не сделать задачу, мы стараемся увеличить вероятность ее завершения, категоризирует задачи по рискам. С этим нам может помочь и прошлый опыт исследования статистики по таким категориям.
Примеры категоризации на основе постановки задачи и технических возможностей решения задачи:


А вот схематический пример воронки отбора задач на основе двухфакторной системы:

Но даже если задачи поступают в разработку хорошо сформулированными, все равно возможны нежданчики.
Нежданчики могут появиться, если:
Система еще не сбалансирована и плохо подобраны ее ограничения. Например, набираем слишком много задач, а значит, и рисков провала.
От нас требуют реализации задач, которые прошли не все этапы Upstream и впихиваются в процесс реализации с осознанными рисками.
Берем задачи, на которые забиваем, потому что переключаемся на другие. Такое поведение как раковая опухоль: она незаметна до тех пор, пока не заболеет вся система, и с ходу непонятно почему.
Неожиданные внешние блокировки. Они хорошо заметны, и на самом деле проще всего решаются.
Исключительные факторы. Например, сыграл какой-либо Bus-фактор или иное событие из категории «серых» или «черных» лебедей.
С некоторыми нежданчиками можно научится работать. Их тоже можно систематизировать по мере наблюдения и вносить правила для митигирования рисков «серых лебедей». С этим может помочь ретроспективный анализ.
Посмотрим на частотную диаграмму по времени решения задач и ответим на вопрос «Есть ли у нас длинный хвост в распределении?».


Хвост можно посчитать на примере формулы отношения значения времени 98% к 50% (процентиль). Если это значение превышает 5,6, можем считать, что хвост у распределения длинный-толстый (Fat tails, Long-fat tail). Формулу предложили исследователи из Kanban University в книге Essential Upstream.
Проведя анализ того, какие задачи решаются в нашей систему с задержками, мы можем выделить общие проблемы и классифицировать их выделив группы таких задач. Эти кластеры могут быть количественно оценены просто по сумме задач в этом кластере. Затем мы определяем количество задач в каждой группе и их общий влияние на процесс. Решение проблем начинаем с той категории, где произведение количества задач и их влияния максимально.
Кстати, для начала вашего опыта, кластеризации задач по проблемам вы можете использовать свою оценку в Story Points в качестве категорий, избегая при этом арифметических операций над значениями SP. Так как SP в этом случае будут обозначать именно категорию, а не количественное значение объема работ.
Важно помнить, что сам контекст системы изменяется и нужно следить, как со временем изменяется и ее поведение.
Меняющийся контекст. Меняются сезоны, команда, продукт, клиенты.
Как отследить изменения системы, которые могут происходить с течением времени?

Для наблюдения за изменениями существует контрольная карта.. В контрольной карте нужно следить за средне-плавающей, разбросом, и она сможет подсказать, как меняется система.
Ниже — примеры с базовыми методиками анализа по контрольной карте.

Как работает контрольная карта

Пример стабильной и предсказуемой системы в случае небольшого разброса

Пример, когда система дестабилизируется и время выполнения задач постепенно увеличивается. Это случай, когда договоренности по срокам будут нарушены

Пример, когда происходит системное улучшение и это приводит к сокращению как разброса, так и времени выполнения задач
Если удалось добиться стабильности системы, несмотря на меняющейся контекст, значит, ваши прогнозы и оценки будут гарантированы этой стабильностью.
Контрольная карта кроме свойства показывать динамику изменения системы может определить два типа проблем, которые подскажут, как нужно действовать для стабилизации системы.
Широкий разброс — это то, что коррелирует с «толстым хвостом» на частотной диаграмме и требует постепенных изменений всей системы. Если у вас есть широкий разброс, значит, нужно проводить изменения с конца процесса, улучшая систему через поиск узких мест и устранение ограничений системы, как рекомендовал в своей книге «Цель» Элияху Голдратт.
Исключительные случаи — когда время выполнения некоторых задач выходит за пределы 85% По таким задачам стоит разобрать причины отклонений и внести изменения в правила или устранить причины.
Такими действиями вы будете повышать предсказуемость времени решения задач, а значит, и повышать надежность своей оценки.
Использование 85% — наиболее часто применяемый критерий для определения исключительных случаев для Lead Time. В разных средах процентиль может быть разным, но ниже не рекомендуется выбирать критерий отсева 85%: это основано на эмпирических наблюдениях.
О том, как можно работать с контрольной картой в JIRA, я рассказывал в докладе «Control Chart в Jira, все ее тайны»:
После того как вы стабилизировали систему, категоризировали входящие задачи, научились брать задачи с наименьшим риском и при этом ваша система имеет явное ограничение на количество задач (а значит, и рисков), мы можем определить время решения задач.
Определяем время выполнения задач. Мы смотрим на распределение вероятности типов задач. При этом для каждого типа можем смотреть на отдельные графики распределения.

При анализе Lead Time используйте статистику по отдельным типам для определения времени решения задач
Выделив распределения Lead Time по типам, для каждого типа задач мы можем определить критерий, на который будем опираться при определении срока решения задачи.
Вот пример, когда для этого типа работ мы в качестве гарантированного срока решения берем 85% и говорим, что эти задачи мы решаем за 7 дней.

На распределении видно, что 85% задач были решены за 7 дней
Вы можете построить автоматический расчет дней по процентилям для разных типов работ, как это сделано у нас во внутренней системе статистики процессных метрик T-Meter:

По моим наблюдениям, часто для определения критерия срока выполнения задач в ИТ используют именно 85% в качестве срока, на который готовы взять обязательство перед заказчиком или клиентом.
На самом деле это достаточно рискованно. В хорошо выстроенной и стабильной системе риски не должны составлять более 5%, а значит, если вы сможете гарантировать сроки по 95% и при этом удовлетворить заказчика или клиента таким прогнозом, то вы минимизируете не только риски, но и последствия для вас. Надо помнить, что риски могут иметь и накопительный эффект.
Теперь же вернемся к вопросу «Успеете к 20 января выполнить эту задачу?». Понимая ваше распределение и срок, можно определить и вероятность завершения задачи к этому сроку.

На горизонтальной оси времени показана дата Deadline когда необходимо поставить задачу. Красным графиком показан график распределения времени если начать задачу от 18 числа, и это уже поздно, чтобы успеть. Зеленый график - это случай если начать с 17 числа, и можно успеть задачу с небольшим риском. Желтый график показывает случай с гарантированной поставкой, а фиолетовый с реализацией намного заранее до нужной даты. Если ваша вероятность успеть к сроку составляет меньше 85%, вы рискуете не успеть
Итак, мы получаем рецепт, как правильно прогнозировать выполнение задач:
-
Исследуйте свою систему и среду, в которой она работает:
Что в ней Downstream?
Выстроен ли Upstream?
Что приходит в систему, что и с какими характеристиками из нее выходит?
Где начинается отсчет времени Lead Time?
Какие есть нежданчики и узкие звенья?
-
Настройте свой Downstream:
Определите ограничение количества задач в Downstream.
Задайте ограничение явно, сделай так, чтобы все согласились с этим ограничением и следовали этому правилу.
Все, что взяли в Downstream, старайтесь завершать полностью.
-
Настройте свой Upstream:
Выработайте правила, почему мы не возьмем эту задачу в работу.
Распределите эти правила «воронкой», создав процесс отбора задач.
-
Категоризируйте входящие задачи:
По типам работ.
Рискам, которые в них входят.
-
Стабилизируйте систему, работая над нежданчиками:
Исследуйте причины задержек задач, системные они или нет.
Для системных проблем меняйте общие правила системы или ресурсы.
Для частных случаев улучшайте правила входящих задач — Definition of Ready.
Выстраивайте систему постепенно под узкое звено своего процесса.
Контролируйте изменения контекста и поведение системы, используйте контрольную карту или другие инструменты анализа для исследования динамики системы.
Определите время решения задач на основании статистики, задайте свой SLA с минимальными рисками реализации и сроком, который может удовлетворить заказчика или клиента.
Прогнозирование и оценка не нужны
Исследуя вопрос о прогнозировании времени выполнения задач и проводя множество интервью по этой теме, часто выясняется, что время выполнения задач, в большинстве случаев, не так важно. Чаще нужно показывать регулярный результат — и не обязательно к какому-то сроку.
Поэтому перед тем, как начнете проводить изменения в вашей системе, убедитесь, что фокус внимания направлен на достижение действительной цели, а не на то, что просто на слуху.
Может быть, текущая система оценки задач вам не нужна, если большую часть информации для прогнозирования вы можете получить из статистики. Тогда зачем тратить на нее время, которое можно потратить на донесение ценности вашего продукта?
Сам же прогноз по времени часто важен в тех случаях, когда нужна синхронизация между разными командами, проектами, регуляторными факторами или маркетинговыми акциями. В противном случае вам стоит рассмотреть так ли необходимо тратить время на ненужную деятельность по оценке и прогнозированию.
Что мы выносим
Прогнозирование — это сложно.
Убедитесь, действительно ли вам нужна оценка задач, кому она нужна и какую проблему она решает?
Предиктивная оценка, основанная только на предположении, такая как Story Points или человеко-часы, не связана с фактическим временем решения задач. Она может выступать только как частный случай предварительной категоризации.
На время решения задач больше влияют системные факторы. Прогнозирование времени решения задачи неотделимо от того, как выстроена вся система создания ценности. А потому и нет универсального способа оценки задач для прогнозирования.
Формулируйте вопрос о сроках выполнения задач как закрытый, чтобы легче было анализировать и выявлять риски, связанные с реализацией.
Вы получили рецепт, как сделать ваши прогнозы надёжными: хотите, чтобы ваши сроки выполнялись, стройте стабильную систему поставки и делайте оценки по ее возможностям. И да, это не так просто, как популярные методики.
Полезные ссылки:
Книга “Real-World Kanban: Do Less, Accomplish More with Lean Thinking, Mattias Skarin.
Книга Forecasting and Simulating Software Development Projects: Effective Modeling of Kanban & Scrum Projects using Monte-carlo Simulation, Troy Magennis.
Книга «Думай медленно решай быстро», Даниэль Канеман.
Книга, «Сколько стоит программный проект», Сти́вен Макко́ннелл
Книга, «Agile. Оценка и планирование проектов», Mike Cohn, не рекомендую.
Книга Scrumban [R]Evolution, The: Getting the Most Out of Agile, Scrum, and Lean Kanban (Agile Software Development Series), Ajay Reddy.
Книга Cynefin — Weaving Sense-Making into the Fabric of Our World, David Snowden.
Книга Actionable Agile Metrics for Predictability: An Introduction, Daniel S. Vacanti.
Книга Essential Upstream, Patrick Steyaert.
Книга No estimates. How to measure project progress without estimating, Vasco Duarte.
Книга «Одураченные случайностью. О скрытой роли шанса в бизнесе и в жизни», Нассим Николас Талеб.
Книга «Черный лебедь», Нассим Николас Талеб.
Презентация Probabilistic Planning, Дмитрий Бакарджиев.
Статья Story Points Revisited, Ron Jeffries.
Статья «Почему аджайл не серебряная пуля и модель Киневина (Cynefin Framework)», David J. Snowden, перевод Алексей Бушманов
Статья «Что такое предсказуемость выполнения задач и как ее понять?», Павел Ахметчанов.
Статья «Как работает метод Монте-Карло», Павел Ахметчанов.
Статья «Время в процессе: что мы реально о нем знаем?», Alexei Zheglov, перевод Артур Нек.
Статья «Анализ диаграммы распределения времени выполнения заказа», Alexei Zheglov, перевод Артур Нек.
Игра No Estimate, интерпретация от Евгения Степченко.
Видео «О WIP-лимитах. Что такое WIP-лимит, как он работает и на что влияет», Алексей Пименов.
Видео «Capacity Allocation — как совмещать разработку продукта, поддержку, выплачивать техдолг», Алексей Пименов.
Видео «Работа с узкими звеньями процесса», Алексей Пименов.
Видео «Как прогнозировать время выполнения задач? Методики прогноза», Павел Ахметчанов.
Видео «Гарри Тимлидов и современный менеджмент», Алексей Пименов.
Комментарии (21)


Ares_ekb
20.12.2023 16:31Ради интереса посчитал свою статистику :)
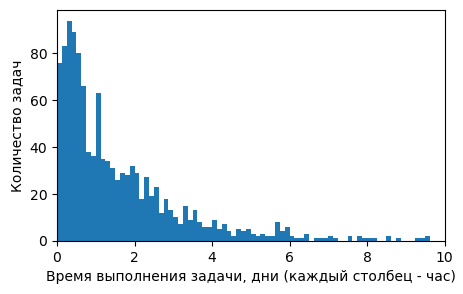
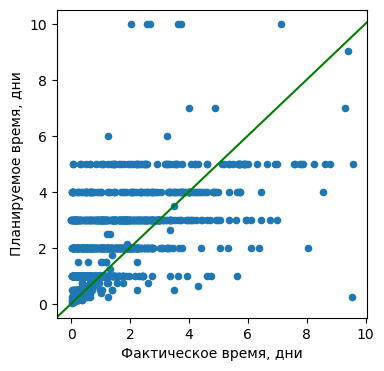
Для большого количества задач фактическое время совпадает с оценкой с точностью до дня. В целом я обычно завышаю оценку на 1-2 дня:
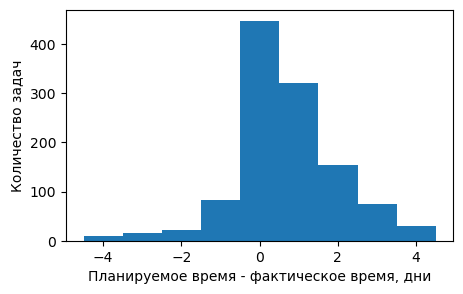
Хотя я делаю это осознанно, интересно какое было бы распределение в противном случае. Возможно не получается нормальное распределение из-за того, что люди склонны перестраховываться или давать другим людям запас времени на задачу.
В сумме у меня получилась перестраховка на 42% - я реально посчитал, а не взял это число из Автостопом по галактике :). Правда это по мелким задачам. Возможна ситуация, что задачу завершили раньше, но завели по ней ещё несколько багов, которые тоже исправили раньше. Но если посмотреть в сумме за год, то эта перестраховка в итоге выходит примерно в ноль.
Кстати, что интересно я от разных людей слышал про коэффициент риска равный квадратному корню из двух - sqrt(2) = 1.41, что удивительно близко к моей интуитивной перестраховке.

sbase
20.12.2023 16:3142% - Это почти стандартный размер буфера критической цепи. Там размер буфера - 50% длительности цепи.

hipnosis Автор
20.12.2023 16:31>Возможно не получается нормальное распределение из-за того, что люди склонны перестраховываться или давать другим людям запас времени на задачу.
Нормальное распределение не получается потому, что это время. Оно не умеет ходить назад. И если задаться анализом временных рядов, то работать будете всегда с логарифмическими распределениями в положительную сторону.
А вот распределение пропускной способности, вполне может подчиняться нормальному распределению.
hipnosis Автор
20.12.2023 16:31Отмечу что, когда мы говорим про Lead Time, хорошо все таки рассматривать в качестве исследуемых элементов работы элементы уровня "Customer Work Item". Если вы приводите метрики для задач которые являются результатом декомпозиции CWI, и измерение Lead Time по ним, действительно начинается от согласования с заказчиками на их реализацию, то ваша картина очень похожа больше на сервис поддержки, или выборку по багам. Там возможны такие показатели.




Didntread
20.12.2023 16:31Итак, мы получаем рецепт, как правильно прогнозировать выполнения задач
Поделюсь бесплатным рецептом. Допустим, вы "спрогнозировали" и обозначили дедлайн команде к 1 января. Постарайтесь либо с вашей стороны, либо со стороны клиента создать буфер, на всякий случай. Пусть это будет неделя/месяц за который в нормальной ситуации клиент платить не будет, а если наступит плохой случай, у команды разработки будет время спокойно все доделать.
sbase
20.12.2023 16:31Главное его не только создать но и контролировать его расход. В этом случае можно шаг-за-шагом прийти к CCPM, потому что там и про размеры буферов есть и про их потребление и про их контроль.
hipnosis Автор
20.12.2023 16:31

OlegZH
20.12.2023 16:31Очень не хватает примера. Чтобы прочувствовать и понять.
А то (на первый взгляд) кажется, что вся эта непредсказуемость проистекает из-за отсутствия должной декомпозиции до элементарных операций, длительность выполнения которых надёжно определяется.
А ещё есть такой момент. Когда берутся за какой-то проект, то не имеют заранее всех нужных библиотек. Их делают по ходу реализации проекта. Было бы любопытно посмотреть на ситуацию, когда контора получает лицензию на производство определённого ПО только при наличии заранее созданного набора инструментов. Ведь, если эти инструменты есть, то и создание каждого ПО можно будет заранее предсказывать.
sbase
20.12.2023 16:31В последнее время я замечаю что вся непредсказуемость возникает из-за.... "Да ну нафиг оценивать в днях, давай в майках, или вообще не будем оценивать.". А потом начинаются попытки применить "процессы поддержки" где SLA есть и атомарность для основной разработки. И в итоге "статистика что-то не очень".
>Было бы любопытно посмотреть на ситуацию, когда контора получает лицензию на производство определённого ПО только при наличии заранее созданного набора инструментов.
Это называется "Сертификация компании по уровню CMMI", правда Мотороле это не очень помогло, но модель хорошая и понятная.
>А ещё есть такой момент. Когда берутся за какой-то проект, то не имеют заранее всех нужных библиотек
Эта проблема может быть решена правильным алгоритмом планирования "от конца" , простой вариант алгоритма тут: https://pulsemanagement.org/rules-create-plan/ , полный в вариант в книге Детмера , называется "мыслительный процесс дерево перехода". Но... "это сложно". Хотя если нужно выполнить проект в срок то есть два пути: или планировать как выше указал или стандартизировать все операции и считать по функциональным точкам.

sshikov
20.12.2023 16:31должной декомпозиции до элементарных операций
Во-первых, это далеко не бесплатно, т.е. это работа (и она еще занимает время), и во-вторых, далеко не всегда вы вообще понимаете, на какие операции нужно декомпозировать. И пока всю систему не спроектируете - не узнаете. Ну т.е. я бы сказал, что тут компромисс между точностью прогноза, и моментом, когда вы можете его дать. Чем позже - тем у вас как правило в наличии более точная декомпозиция задач, и более точный прогноз. Но магически получить прогноз раньше на год с той же точностью вы не сможете.
hipnosis Автор
20.12.2023 16:31Спасибо за обратную связь.
Пример с разбором я планирую сделать в следующей статье, или в статье через одну.

mad_nazgul
20.12.2023 16:31Наконец то нормальный подход к оценки времени.
Хорошо бы чтобы эта статья выросла в курс для менеджеров по управлению проектом. ????

anz
20.12.2023 16:31Это как вы хорошо завернули! Непонятные задачи сделайте понятными, и тогда они будут прогнозируемы и оцениваемы. Все верно :)
А где время на упрощение и ресерч? Зачастую в задачах с большой неопределенностью это отнимает бОльшую часть времени.
hipnosis Автор
20.12.2023 16:31@anzв общем вы верно уловили конву. Только добавлю, что в статье говорится и о проблеме того, что в работу не всегда берутся задачи которые хорошо проработаны, а значит определенный риск переноситься на команду разработки — что собственно вы и подсветили во втором абзаце вашего сообщения.
И чем больше набранных рисков уходит на Downstream тем больше шансов того, что какие-то из них сработают.
Собственно и весь процесс Upstream нужно тюнить под то, чтобы как можно меньше рисков уходило в Downstream.
Я думаю подробнее расписать свой опыт настройки процесса в следующей статье, где хочется раскрыть более подробнее проблему с рисками и процессом Upstream
sshikov
На мой взгляд, ответ на второй вопрос (от человека, разбирающегося в планировании), никогда не будет "Да" или "Нет", а будет что-то вроде "Да, с вероятностью 0.01". То есть, скорее всего нет, но может быть что и да.
И ничего при этом на практике от смены постановки вопроса не поменяется, потому что знать эту вероятность вы все равно будете очень приблизительно. По крайней мере для задач, которые вы никогда раньше не делали, и не имеете четкого представления об их сложности. То есть, вместо нечеткого ответа на вопрос "когда" вы получите такой же нечеткий ответ на вопрос, с какой вероятностью мы получим результат, разве нет?
hipnosis Автор
>По крайней мере для задач, которые вы никогда раньше не делали, и не имеете четкого представления об их сложности.
Для задач о которых мы мало что знаем, вероятность будет низкая, действительно.
Однако если имеем ответ когда это надо, нам будет проще искать инфомрацию для ответа на этот вопрос.
sshikov
Все еще не улавливаю, почему проще-то? Ведь по сути, чтобы понять, сумеем ли мы выполнить задачи к такому-то, нам все равно нужно:
получить список задач, определиться с зависимостями между ними, построить критический путь
для каждой задачи прикинуть распределение времени выполнения
получить распределение времени выполнения всех задач на критическом пути
Ответ "Да, мы успеваем" эквивалентен тому, что дата старта + время выполнения задач с критического пути с определенной вероятностью меньше требуемой даты завершения.
Единственное что меняется, если мы фиксируем дату завершения - это наверное объем работ. И его можно сократить, если мы понимаем, что не успеваем. Но чтобы понять - все равно надо проделать вот этот весь анализ. Про который вы сами написали, что он сложный :)
Ну т.е. если совсем просто - информация-то для анализа все равно нужна та же самая, разве нет? Мне кажется, эта простота - чисто психологическая. Нам удобнее иметь дело с задачей в такой постановке.
hipnosis Автор
Да, все верно, нам все равно нужно собрать информацию которая позволит ответить на вопрос.
Считаю, что изменение формы вопроса, позволяет начать сбор это информации проще. Как отметил в статье, при закрытом вопросе легче воспринимается и логика рассуждения и поиска дополнительной информации. Это полезно тогда когда еще очень мало информации, в самом начале.
Однако, если у вас уже есть наработанный аппарат по прогнозированию, например вы собрали модель своего процесса и используя Монте-Карло определяете сроки, то вам уже не так важно будет как поставлен вопрос о сроках.