
Всем привет! С вами снова я, Аргентум! Сегодня я продолжу нашу серию статей об ядре Linux (память в linux, исключения и прерывания в linux)
В этой статье мы будем изучать способ организации сети в мире серверов и то, как она эволюционировала от использования традиционного сетевого стека ядра Linux к виртуализации сети с использованием OVS и к обработке нагрузки телекоммуникационных компаний с использованием NFV и SR-IOV.
Сетевой стек Linux
В этой статье мы рассмотрим основной поток IPv4/TCP-трафика в ядре Linux после выступления Иржи Бинца на DevConf CZ 2018 , где он прекрасно изложил поток пакетов для целых 7 уровней OSI в ядре Linux. Прежде чем мы перейдем к пути потока, нам следует ознакомиться с некоторыми вспомогательными инструментами и концепциями:
"Кольцевые" (ring) буферы
При загрузке сетевого адаптера и загрузке его модуля драйвера ядром драйверы начинают с выделения очередей или буферов Rx (получение) и Tx (передача), называемых кольцевыми буферами, в памяти устройства, обычно это часть DMA пространства ядра памяти вы можете проверить максимальные и настроенные размеры этих буферов:
$ ethtool -g INTERFACE_NAME
Ring parameters for INTERFACE_NAME:
Pre-set maximums:
RX: 4096 <<<<<<<<<<<<<<<, Max size in bytes
RX Mini: 2048
RX Jumbo: 4096
TX: 4096 <<<<<<<<<<<<<<<, Max size in bytes
Current hardware settings:
RX: 1024 <<<<<<<<<<<<<<<, Configured size in bytes
RX Mini: 128
RX Jumbo: 512
TX: 512 <<<<<<<<<<<<<<<, Configured size in bytesВ более ранних версиях ядра пакет, поступающий в эти буферы, вызывал аппаратное прерывание ЦП для каждого пакета, что очень навязчиво, но, к счастью, был введен NAPI, чтобы помочь с этой проблемой, ниже вы узнаете об этом больше.
Буферы сокетов (sk_buff)
sk_buff (буфер сокетов) , Linux взаимодействует с пакетом/ячейкой/сегментом или любым другим полученным сетевым блоком, используя буфер сокетов (sk_buff), а данные и метаданные (заголовки) каждого sk_buff обрабатываются отдельно, поэтому ядру не нужно перемещать пакет в памяти буфер сокета действует как ведро, он хранит данные сегмента до тех пор, пока он не будет обработан, буферы сокетов не уничтожаются вместе с пакетами, они освобождаются и перераспределяются в новые пакеты, а также, когда они используются, ЦП создает новые sk_buffs (новые ведра) для обработки дополнительного трафика.
Примечание: «sk_buff» и «skb» взаимозаменяемы, в то время как вы обнаружите, что skb широко используется в коде ядра, из которого
состоит sk_buff (показано на рисунке ниже):
буфер пакетов (данные sk_buff) : место, где фактический пакет и данные хранятся в памяти пространства ядра (пространство памяти DMA — концепция DMA будет рассмотрена ниже), указанная с помощью структуры sk_buff, размер выделенного SKB равен на TCP MSS+Headroom, чтобы позволить MSS изменяться в соответствии с модификациями соединения и пользователя.
sk_buff struct (Метаданные буфера сокетов) : Метаданные о пакете, хранящемся в буферах пакетов (Данные), которые включают указатели и значения, они выглядят следующим образом: имейте в виду, что это всего лишь часть структуры sk_buff, чтобы прочитать подробности sk_buff. .h struct, вы можете найти ее здесь :
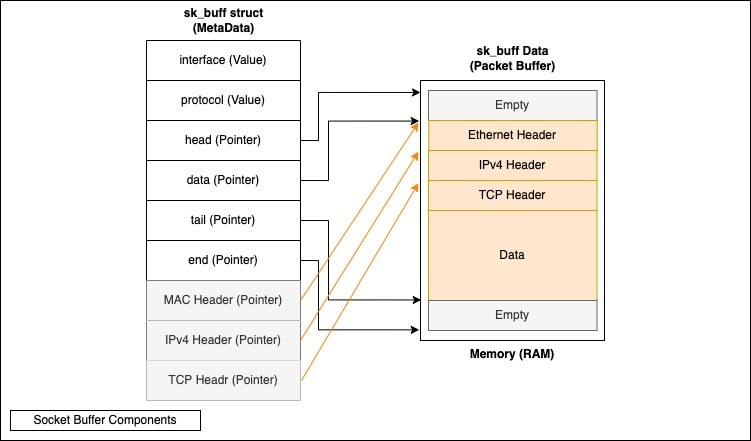
Interface (input_dev) : относится к имени интерфейса, на который прибыл пакет.
Protocol : IPv4, IPv6 и так далее.
Head : указатель на начало sk_buff, который фактически начинается с пустого места, предоставляющего место для дополнительных заголовков, например тега VLAN для instacnce.
Data : указатель данных не указывает на начало данных, а скорее используется динамически в функциях стека для извлечения и отправки заголовков, поэтому, например, в ядре, когда вы говорите «вытолкнуть заголовок Ethernet», все, что на самом деле происходит, это то, что данные указатель перемещается в начало IP-заголовка, поэтому никакие заголовки физически не помещаются в память.
Tail : указывает на конец части данных и начало пустой части sk_buffer. Опять же, эта пустая часть используется для пакетов разного размера, поскольку размер sk_buffer соответствует настроенному MTU.
End : указывает на конец sk_buff в памяти.
Указатели заголовков MAC, IP и TCP всегда хранятся в метаданных sk_buff, что позволяет вызывать их напрямую без необходимости выполнять действия по извлечению и отправке sk_buff.
Клонирование : можно клонировать заголовок SKB, но не данные.
Примечание. Пакет не дублируется в ядре, фактические данные пакета остаются в буферах пакетов. При каждом клонировании или копировании буфер пакетов остается нетронутым, вместо этого создается новый sk_buff (AKA SKB), поэтому новые метаданные указывают на существующие. буфер пакетов, хотя копирование пакета в ядре не происходит, пакет копируется, достигает приложения и SKB освобождается.
Базовая геометрия sk_buff
sk_buff— это основная сетевая структура, представляющая пакет.
struct sk_buffсам по себе является структурой метаданных и не содержит никаких пакетных данных. Все данные хранятся в связанных буферах.
sk_buff.headуказывает на основной «головной» буфер. Головной буфер разделен на две части:
буфер данных, содержащий заголовки и иногда полезную нагрузку; это часть skb, над которой работают обычные помощники, такие как
skb_put()илиskb_pull();общая информация (struct skb_shared_info), которая содержит массив указателей на данные, доступные только для чтения, в формате (страница, смещение, длина).
Опционально skb_shared_info.frag_listможет указывать на другой скб.
Базовая схема может выглядеть так:
---------------
| sk_buff |
---------------
,--------------------------- + head
/ ,----------------- + data
/ / ,----------- + tail
| | | , + end
| | | |
v v v v
-----------------------------------------------
| headroom | data | tailroom | skb_shared_info |
-----------------------------------------------
+ [page frag]
+ [page frag]
+ [page frag]
+ [page frag] ---------
+ frag_list --> | sk_buff |
---------Общие skbs и клоны skb
sk_buff.users— это простой счетчик ссылок, позволяющий нескольким объектам поддерживать жизнь . skbs с , называются общими skbs (см. Ресурсы ).struct sk_buffsk_buff.users != 1skb_shared()
skb_clone()позволяет быстро дублировать skbs. Ни один из буферов данных не копируется, но вызывающая сторона получает новую структуру метаданных ( ). &skb_shared_info.refcount указывает количество skbs, указывающих на одни и те же пакетные данные (т.е. клоны).struct sk_buff
dataref и skbs без заголовков
Транспортные уровни отправляют клоны skbs полезной нагрузки, которые они хранят, для повторной передачи. Чтобы позволить нижним слоям стека добавлять свои заголовки, мы разделили его skb_shared_info.datarefна две половины. Младшие 16 бит подсчитывают общее количество ссылок. Старшие 16 бит указывают, сколько ссылок предназначены только для полезной нагрузки. skb_header_cloned()проверяет, разрешено ли skb добавлять/записывать заголовки.
Создатель skb (например, TCP) помечает свой skb как sk_buff.nohdr (через __skb_header_release()). Любой клон, созданный из отмеченного skb, будет sk_buff.hdr_lenзаполнен доступным запасом. Если существует единственный клон, он может изменять запас по желанию. Последовательность вызовов внутри транспортного уровня следующая:
<alloc skb>
skb_reserve()
__skb_header_release()
skb_clone()
// send the clone down the stack
Это не очень универсальная конструкция, и она зависит от правильных действий транспортных уровней. На практике обычно имеется только один skb, предназначенный только для полезной нагрузки. Наличие нескольких skbs только для полезной нагрузки с разной длиной hdr_len невозможно. Скбы, предназначенные только для полезной нагрузки, никогда не должны покидать своего владельца.
Информация о контрольной сумме
Интерфейс для разгрузки контрольной суммы между стеком и сетевыми драйверами выглядит следующим образом...
Функции, связанные с контрольной суммой IP
Драйверы рекламируют возможности разгрузки контрольной суммы в функциях устройства. С точки зрения стека это возможности, предлагаемые драйвером. Драйвер обычно объявляет только те функции, которые он способен передать на свое устройство.
Функции устройства, связанные с контрольной суммой |
|
|
Драйвер (или его устройство) способен вычислить одну контрольную сумму IP (дополняющую до единицы) для любой комбинации протоколов или уровней протоколов. Контрольная сумма вычисляется и устанавливается в пакете для интерфейса CHECKSUM_PARTIAL (см. ниже). |
|
Драйвер (устройство) может проверять контрольную сумму только простых пакетов TCP или UDP через IPv4. Это неинкапсулированные пакеты вида IPv4|TCP или IPv4|UDP, где поле «Протокол» в заголовке IPv4 — TCP или UDP. Заголовок IPv4 может содержать параметры IP. Эту функцию нельзя установить в функциях для устройства, для которого также установлен NETIF_F_HW_CSUM. Эта функция устаревает (см. ниже). |
|
Драйвер (устройство) может проверять контрольную сумму только простых пакетов TCP или UDP через IPv6. Это неинкапсулированные пакеты вида IPv6|TCP или IPv6|UDP, где поле следующего заголовка в заголовке IPv6 — TCP или UDP. Заголовки расширений IPv6 не поддерживаются этой функцией. Эту функцию нельзя установить в функциях устройства, для которого также установлен NETIF_F_HW_CSUM. Эта функция устаревает (см. ниже). |
|
Драйвер (устройство) выполняет разгрузку контрольной суммы приема. Этот флаг используется только для отключения функции контрольной суммы RX для устройства. Стек будет принимать указание контрольной суммы приема в пакетах, полученных на устройстве, независимо от того, установлен ли NETIF_F_RXCSUM. |
Контрольная сумма полученных пакетов устройством
Индикация проверки контрольной суммы установлена в sk_buff.ip_summed. Возможные значения:
-
CHECKSUM_NONEУстройство не выполнило контрольную сумму этого пакета, например, из-за отсутствия возможностей. Пакет содержит полную (хотя и не проверенную) контрольную сумму в пакете, но не в skb->csum. Таким образом, skb->csum в этом случае не определен.
-
CHECKSUM_UNNECESSARYАппаратное обеспечение, с которым вы имеете дело, не вычисляет полную контрольную сумму (как в
CHECKSUM_COMPLETE), но оно анализирует заголовки и проверяет контрольные суммы для определенных протоколов. Для таких пакетов будет установленоCHECKSUM_UNNECESSARY, в порядке ли их контрольная сумма.sk_buff.csumхотя в этом случае все еще не определено. Драйвер или устройство никогда не должны изменять поле контрольной суммы в пакете, даже если контрольная сумма проверена.CHECKSUM_UNNECESSARYприменимо к следующим протоколам:TCP: IPv6 и IPv4.
UDP: IPv4 и IPv6. Устройство может применить CHECKSUM_UNNECESSARY к нулевой контрольной сумме UDP для IPv4 или IPv6, в этом случае сетевой стек может выполнить дополнительную проверку.
GRE: только если контрольная сумма присутствует в заголовке.
SCTP: указывает, что CRC в заголовке SCTP проверен.
FCOE: указывает, что CRC в кадре FC проверен.
sk_buff.csum_levelуказывает количество последовательных контрольных сумм, найденных в пакете, минус одна, которая была проверена какCHECKSUM_UNNECESSARY. Например, если устройство получает пакет IPv6->UDP->GRE->IPv4->TCP и устройство может проверить контрольные суммы для UDP (возможно, ноль), GRE (установлен флаг контрольной суммы) и TCP,sk_buff.csum_levelбудут установлены до двух. Если устройство могло проверить только контрольную сумму UDP, а не GRE, либо потому, что оно не поддерживает контрольную сумму GRE, либо из-за того, что контрольная сумма GRE неверна, skb->csum_level будет установлен в ноль (контрольная сумма TCP в этом случае не учитывается). . -
CHECKSUM_COMPLETEЭто самый общий способ. Устройство предоставило контрольную сумму всего пакета, видимую
netif_rx()и заполнившую ееsk_buff.csum. Это означает, что для реализации этого аппаратному обеспечению не нужно анализировать заголовки L3/L4.Примечания:
Даже если устройство поддерживает только некоторые протоколы, но способно генерировать skb->csum, оно ДОЛЖНО использовать CHECKSUM_COMPLETE, а не CHECKSUM_UNNECESSARY.
CHECKSUM_COMPLETE не применим к протоколам SCTP и FCoE.
-
CHECKSUM_PARTIALКонтрольная сумма настроена для выгрузки на устройство, как описано в описании вывода для CHECKSUM_PARTIAL. Это может произойти с пакетом, полученным непосредственно из другой ОС Linux, например, виртуализированного ядра Linux на том же хосте, или может быть установлено во входном пути в GRO или удаленной выгрузке контрольной суммы. В целях проверки контрольной суммы контрольная сумма, указанная в skb->csum_start + skb->csum_offset, и любые предыдущие контрольные суммы в пакете считаются проверенными. Любые контрольные суммы в пакете, находящиеся после выгрузки контрольной суммы, не считаются проверенными.
Контрольная сумма при передаче для НГСО
Стек запрашивает разгрузку контрольной суммы для sk_buff.ip_summedпакета. Ценности:
-
CHECKSUM_PARTIALДрайверу необходимо подсчитывать контрольную сумму пакета, видимого с помощью hard_start_xmit(), до
sk_buff.csum_startконца, а также записывать/записывать контрольную сумму по смещениюsk_buff.csum_start+sk_buff.csum_offset. Драйвер может проверить, что значения csum_start и csum_offset являются допустимыми значениями, учитывая длину и смещение пакета, но он не должен пытаться проверить, что контрольная сумма относится к допустимой контрольной сумме транспортного уровня — проверка входит в компетенцию стека. что csum_start и csum_offset установлены правильно.Когда стек запрашивает разгрузку контрольной суммы для пакета, драйвер ДОЛЖЕН убедиться, что контрольная сумма установлена правильно. Драйвер может либо выгрузить вычисление контрольной суммы на устройство, либо вызвать skb_checksum_help (в случае, если устройство не поддерживает выгрузку для конкретной контрольной суммы).
NETIF_F_IP_CSUMиNETIF_F_IPV6_CSUMустаревают в пользуNETIF_F_HW_CSUM. Новые устройства следует использоватьNETIF_F_HW_CSUMдля указания возможности разгрузки контрольной суммы. skb_csum_hwoffload_help() может быть вызван для разрешенияCHECKSUM_PARTIALна основе возможностей контрольной суммы сетевого устройства: если пакет не соответствует им, вызывается skb_checksum_help() или skb_crc32c_help() (в зависимости от значенияsk_buff.csum_not_inet, см. выгрузку контрольной суммы не-IP (CRC) ). решить контрольную сумму. -
CHECKSUM_NONEКонтрольная сумма skb уже проверена протоколом, или контрольная сумма не требуется.
-
CHECKSUM_UNNECESSARYЭто имеет то же значение, что и CHECKSUM_NONE для разгрузки контрольной суммы при выводе.
-
CHECKSUM_COMPLETEНе используется при выводе контрольной суммы. Если драйвер обнаруживает пакет с этим значением, установленным в skbuff, он должен обрабатывать пакет так, как если бы он
CHECKSUM_NONEбыл установлен.
Разгрузка контрольной суммы (CRC) без IP
|
Эта функция указывает, что устройство способно выгружать SCTP CRC в пакете. Чтобы выполнить эту разгрузку, стек установит значения csum_start и csum_offset соответственно, установит для ip_summed значение |
|
Эта функция указывает, что устройство способно выгружать CRC FCOE в пакете. Чтобы выполнить эту разгрузку, стек установит ip_summed |
Контрольная сумма на выходе с помощью GSO
В случае пакета GSO (skb_is_gso() имеет значение true), разгрузка контрольной суммы подразумевается флагами SKB_GSO_* в gso_type. Очевидно, что если gso_type равен SKB_GSO_TCPV4или SKB_GSO_TCPV6, подразумевается разгрузка контрольной суммы TCP как часть операции GSO. Если контрольная сумма выгружается с помощью GSO, тогда ip_summed равен CHECKSUM_PARTIAL, и оба значения csum_start и csum_offset указывают на самую внешнюю выгружаемую контрольную сумму (при инкапсуляции UDP возможны две выгруженные контрольные суммы).
Прерывания ядра (IRQ или SoftIRQ)
Я уже затрагивал тему прерываний и исключений, IRQ и SoftIRQ в моей статье.
Проще говоря, прерывания используются для того, чтобы остановить процессор от того, что он делает, и вместо этого работать со стороны прерывателя. Существуют модели прерываний, каждая из которых включает в себя множество типов, но ниже вы можете видеть, что эти прерывания делятся на две категории.
Прерывания верхней половины (аппаратное прерывание) : такого рода прерывания очень дорогостоящие, и в результате обработчик прерываний маскирует их после первого использования, а затем после этого драйвер сетевой карты начинает использовать вместо этого SoftIRQ (программное прерывание), которое может быть прерывается сам по себе, вы можете наблюдать эти прерывания:
$ cat /proc/interrupts
CPU0 CPU1
0: 171 0 IO-APIC 2-edge timer
1: 0 9 IO-APIC 1-edge i8042
8: 1 0 IO-APIC 8-edge rtc0
9: 0 21 IO-APIC 9-fasteoi acpi
16: 494 0 IO-APIC 16-fasteoi snd_hda_intel:card1
17: 372236 1575 IO-APIC 17-fasteoi ehci_hcd:usb1, ehci_hcd:usb2, ehci_hcd:usb3, ath9k
18: 268 0 IO-APIC 18-fasteoi ohci_hcd:usb4, ohci_hcd:usb5, ohci_hcd:usb6
19: 49197 4164 IO-APIC 19-fasteoi ahci[0000:00:11.0]
25: 5 100550 PCI-MSI-0000:00:01.0 0-edge radeon
28: 0 28 PCI-MSI-0000:00:01.1 0-edge snd_hda_intel:card0
NMI: 0 0 Non-maskable interrupts
LOC: 1852383 1696841 Local timer interrupts
SPU: 0 0 Spurious interrupts
PMI: 0 0 Performance monitoring interrupts
IWI: 1 0 IRQ work interrupts
RTR: 0 0 APIC ICR read retries
RES: 351662 366757 Rescheduling interrupts
CAL: 689212 789962 Function call interrupts
TLB: 19390 18975 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
DFR: 0 0 Deferred Error APIC interrupts
MCE: 0 0 Machine check exceptions
MCP: 23 23 Machine check polls
ERR: 1
MIS: 0
PIN: 0 0 Posted-interrupt notification event
NPI: 0 0 Nested posted-interrupt event
PIW: 0 0 Posted-interrupt wakeup eventКаждое прерывание (аппаратное прерывание) идентифицируется вектором , который представляет собой однобайтовый идентификатор в диапазоне 0–255, от 0 до 31 — это так называемые прерывания-исключения (немаскируемые), диапазон 32–47 — маскируемые прерывания, от 48 до 255 отведены под программные прерывания (SoftIRQ).
Вкратце, есть 3 типа аппаратных прерываний, с которыми вы столкнетесь в приведенных выше выводах: MSI-X, MSI и устаревшие IRQ. Вкратце, MSI означает прерывания, сигнализируемые сообщениями, которые заменяют старый способ обработки прерываний с использованием одного физического контакта в Разъем процессора для каждого устройства.
Вы можете прочитать о MSI и других типах аппаратных прерываний здесь.
Нижние половины прерываний (программное прерывание) : SoftIRQ запускает очередь для каждого процессора, вы можете найти их в выводе ps в формате [ksoftiqd/CPU_Number], эти очереди опрашивают драйвер устройства для обработки трафика, а не аппаратное обеспечение устройства (NIC). прерывая процессор каждый раз, когда он получает трафик, вы можете увидеть очереди приема и передачи:
$ ps aux | grep ksoftirqd
root 15 0.0 0.0 0 0 ? S 18:53 0:00 [ksoftirqd/0]
root 23 0.0 0.0 0 0 ? S 18:53 0:00 [ksoftirqd/1]
argentum 5376 33.3 0.1 6588 2176 pts/0 S+ 20:58 0:00 grep --color=auto ksoftirqd
$ watch -n1 grep RX /proc/softirqs
Every 1,0s: grep RX /proc/softirqs
NET_RX: 396 337 0 0
$ watch -n1 grep TX /proc/softirqs
Every 1,0s: grep TX /proc/softirqs
NET_TX: 1 1 0 0
Другие концепции
DMA (прямой доступ к памяти) : устройства NIC представляют собой устройства PCIe, раньше, чтобы записать что-то в память, им приходилось прерывать ЦП, поэтому ЦП копирует пакет в регистр, а затем записывает его в память, DMA обеспечивает отсутствие ЦП. ресурсы с прямым доступом к памяти без прерывания работы ЦП, например, когда сетевая карта (сетевая интерфейсная карта — аппаратное обеспечение) имеет сегмент Ethernet, который она хочет записать в память, она использует DMA для прямой записи в память, не теряя ценного В циклах ЦП эти вызовы записи DMA, поступающие от сетевой карты, перенаправляются северным мостом на материнской плате в ОЗУ вместо ЦП. Подробнее о распределении памяти можно прочитать в этой англоязычной статье "Выделение памяти для DMA в Linux — автор BLAKE RAIN" .
Кольцевые буферы : драйверы сетевых карт и сетевых карт совместно используют кольцевые буферы TX и RX, которые в основном состоят из указателей на расположение буферов пакетов в памяти. Они не содержат данных, а являются лишь указателями памяти.
Верхняя половина и нижняя половина : когда сетевой адаптер передает пакет по DMA в память (DMA — это место в пространстве памяти ядра, к которому сетевая карта имеет доступ без необходимости использования ЦП), Intrupet (SoftIRQ — запрос мягкого прерывания) отправляется NIC передает ЦП информацию о том, что новый пакет прибыл и ожидает обработки. Верхняя половина относится к действиям, предпринятым ЦП в первую очередь, поэтому вместо того, чтобы останавливать все для обработки этого пакета, что может быть навязчивым, он просто подтверждает прерывание и планирует нижнюю половину (то есть остальную часть действия, которая будет предпринята для обработки пакета) на потом.
Переключение контекста: процесс перемещения между контекстом UserSpace и контекстом KernelSpace для процесса, который потребляет циклы ЦП.
Системные вызовы . Проще говоря, системные вызовы используются пользователем в UserSpace для запроса службы из KernelSpace.
-
NAPI — для полученного трафика : (Новый API — требуется аппаратная поддержка), Расширение для драйверов устройств, предназначенное для сетевых устройств, чтобы снизить количество прерываний при получении пакетов, что вступает в силу при получении огромного количества пакетов, но все равно работает в сочетании с обычным процессом прерывания, он также помогает регулировать трафик. Если сетевой адаптер получает слишком большой трафик, NAPI выполняет отбрасывание пакетов на уровне сетевого адаптера без необходимости предупреждать/прерывать ядро, NAPI эффективен только для пакетов получать события .
SoftIRQ : Система «softIRQ» в ядре Linux — это система, которую ядро использует для обработки работы вне контекста IRQ драйвера устройства. IRQ (прерывания) драйверов устройств обычно имеют наивысший приоритет для ядра Linux и приостанавливают любые другие типы прерываний по мере их поступления, KsoftIRQ — это очередь, инициируемая как поток для каждого процессора на очень ранних стадиях ядра, они обрабатывают постановку в очередь SoftIRQ, вы можете увидеть счетчики этих очередей, используя
$ cat /proc/softirqsISR (Процедура обслуживания прерываний) : функция в ядре, отвечающая за выяснение характера прерывания и того, какие действия необходимо выполнить, после чего ЦП возобновляет обработку ранее приостановленных процессов.
Сетевые интерфейсы
Сетевые интерфейсы — это канал связи между устройством и сетью. Физически сетевые интерфейсы могут осуществляться через сетевую карту ( NIC ) или могут быть более абстрактно реализованы как программное обеспечение. Вы можете иметь несколько сетевых интерфейсов, работающих одновременно. Определенные интерфейсы можно активировать (активировать) или отключить (деактивировать) в любое время. Утилита сообщает список активных на данный момент сетевых интерфейсов ifconfig. Файлы конфигурации сети необходимы для обеспечения правильной работы интерфейсов.
Для конфигурации семейства Debian базовый файл конфигурации сети — /etc/network/interfaces. Для конфигурации системы семейства RedHat информация о маршрутизации и хосте содержится в файлах /etc/sysconfig/network. Скрипт настройки сетевого интерфейса eth0находится по адресу /etc/sysconfig/network-scripts/ifcfg-eth0. Для конфигурации систем семейства SUSE информация о маршрутизации и хосте, а также сценарии настройки сетевого интерфейса содержатся в /etc/sysconfig/networkкаталоге.
Стек протоколов TCP/IP
Собственно, что есть сеть? Сеть - это более 2х компьютеров, объединенных между собой какими-то проводами каналами связи, в более сложном примере - каким-то сетевым оборудованием и обменивающиеся между собой информацией по определенным правилам. Эти правила "диктуются" стеком протоколов TCP/IP.
Transmission Control Protocol/Internet Protocol (Стек протоколов TCP/IP) - если сказать простым языком, это набор взаимодействующих протоколов разных уровней (можно дополнить, что каждый уровень взаимодействует с соседним, то есть состыковывается, поэтому и стек, имхо, так проще понять), согласно которым происходит обмен данными в сети. Каждый протокол - это набор правил, согласно которым происходит обмен данными. Итого, стек протоколов TCP/IP - это набор наборов правил
Тут может возникнуть резонный вопрос: а зачем же иметь много протоколов? Неужели нельзя обмениваться всем по одному протоколу?
Все дело в том, что каждый протокол описывает строго отведенные ему правила. Кроме того, протоколы разделены по уровням функциональности, что позволяет работе сетевого оборудования и программного обеспечения становится гораздо проще, прозрачнее и выполнять "свой" круг задач.

Для разделения данного набора протоколов по уровням была разработана модель сетевого взаимодействия OSI (англ. Open Systems Interconnection Basic Reference Model, 1978 г., она же - базовая эталонная модель взаимодействия открытых систем). Модель OSI состоит из семи различных уровней. Уровень отвечает за отдельный участок в работе коммуникационных систем, не зависит от рядом стоящих уровней – он только предоставляет определённые услуги. Каждый уровень выполняет свою задачу в соответствии с набором правил, называемым протоколом. Проиллюстрировать работу модели OSI можно следующим рисунком: Как передаются данные?
Из рисунка видно, что существует 7 уровней сетевого взаимодействия, которые делятся на: прикладной, представлений, сеансовый, транспортный, сетевой, канальный, физический. Каждый из уровней содержит свой набор протоколов. Список протоколов по уровням взаимодействия хорошо представлен в Википедии:

Сам стек протоколов TCP/IP развивался параллельно с принятием модели OSI и "не пересекался" с ней, в результате получилось небольшое разногласие в несоответствии стека протоколов и уровней модели OSI. Обычно, в стеке TCP/IP верхние 3 уровня (прикладной, представления и сеансовый) модели OSI объединяют в один — прикладной. Поскольку в таком стеке не предусматривается унифицированный протокол передачи данных, функции по определению типа данных передаются приложению. Упрощенно интерпретацию стека TCP/IP относительно модели OSI можно представить так:

Данную модель сетевого взаимодействия еще называют модель DOD (от англ. Department of Defense — Министерство обороны США).
Адресация
В сети, построенной на стеке протоколов TCP/IP каждому хосту (компьютеру или устройству подключенному к сети) присвоен IP-адрес. IP-адрес представляет собой 32-битовое двоичное число. Удобной формой записи IP-адреса (IPv4) является запись в виде четырёх десятичных чисел (от 0 до 255), разделённых точками, например, 192.168.0.1. В общем случае, IP-адрес делиться на две части: адрес сети (подсети) и адрес хоста:

Как видно из иллюстрации, есть такое понятие как сеть и подсеть. Думаю, что из значений слов понятно, что IP адреса делятся на сети, а сети в свою очередь делятся на подсЕти с помощью маски подсетИ (корректнее будет сказать: адрес хоста может быть разбит на подсЕти). Изначально, все IP адреса были поделены на определенные группы (классы адресов/сети). И существовала классовая адресация, согласно которой сети делились на строго определенные изолированные сети:

Нетрудно посчитать, что всего в пространстве адресов IP - 128 сетей по 16 777 216 адресов класса A, 16384 сети по 65536 адресов класса B и 2 097 152 сети по 256 адресов класса C, а также 268 435 456 адресов многоадресной рассылки и 134 317 728 зарезервированных адресов. С ростом сети Интернет эта система оказалась неэффективной и была вытеснена CIDR (бесклассовой адресацией), при которой количество адресов в сети определяется маской подсети.
Существует так же классификация IP адресов, как "частные" и "публичные". Под частные (они же локальные сети) сети зарезервированы следующие диапазоны адресов:
10.0.0.0 — 10.255.255.255 (10.0.0.0/8 или 10/8),
172.16.0.0 — 172.31.255.255 (172.16.0.0/12 или 172.16/12),
192.168.0.0 — 192.168.255.255 (192.168.0.0/16 или 192.168/16).
127.0.0.0 — 127.255.255.255 зарезервировано для петлевых интерфейсов (не используется для обмена между узлами сети), т.н. localhost
Кроме адреса хоста в сети TCP/IP есть такое понятие как порт. Порт является числовой характеристикой какого-то системного ресурса. Порт выделяется приложению, выполняемому на некотором сетевом хосте, для связи с приложениями, выполняемыми на других сетевых хостах (в том числе c другими приложениями на этом же хосте). С программной точки зрения, порт есть область памяти, которая контролируется каким-либо сервисом.
Для каждого из протоколов TCP и UDP стандарт определяет возможность одновременного выделения на хосте до 65536 уникальных портов, идентифицирующихся номерами от 0 до 65535. Соответствие номера порта и службы, использующей этот номер можно посмотреть в файле /etc/services или на сайте http://www.iana.org/assignments/port-numbers. Весь диапазон портов делиться на 3 группы:
0 до 1023, называемые привилегированными или зарезервированными (используются для системных и некоторых популярных программ)
1024 — 49151 называются зарегистрированными портами.
49151 — 65535 называются динамическими портами.
IP протокол, как видно из иллюстраций находится ниже TCP и UDP в иерархии протоколов и отвечает за передачу и маршрутизацию информации в сети. Для этого, протокол IP заключает каждый блок информации (пакет TCP или UDP) в другой пакет - IP пакет или дейтаграмма IP, который хранит заголовок о источнике, получателе и маршруте.
Если провести аналогию с реальным миром, сеть TCP/IP - это город. Названия улиц и проулков - это сети и подсети. Номера строений - это адреса хостов. В строениях, номера кабинетов/квартир - это порты. Точнее, порты - это почтовые ящики, в которые ожидают прихода корреспонденции получатели (службы). Соответственно, номера портов кабинетов 1,2 и т.п. обычно отдаются директорам и руководителям, как привилегированным, а рядовым сотрудникам достаются номера кабинетов с большими цифрами. При отправке и доставке корреспонденции, информация упаковывается в конверты (ip-пакеты), на которых указывается адрес отправителя (ip и порт) и адрес получателя (ip и порт). Простым языком как-то так...
Следует отметить, что протокол IP не имеет представления о портах, за интерпретацию портов отвечает TCP и UDP, по аналогии TCP и UDP не обрабатывают IP-адреса.
Для того чтобы не запоминать нечитаемые наборы цифр в виде IP-адресов, а указывать имя машины в виде человекопонятного имени "придумана" такая служба как DNS (Domain Name Service), которая заботится о преобразовании имен хостов в IP адрес и представляет собой огромную распределенную базу данных. Об этой службе я обязательно напишу в будущих постах, а пока нам достаточно знать, что для корректного преобразования имен в адреса на машине должен быть запущен демон named или система должна быть настроена на использование службы DNS провайдера.
Маршрутизация

Давайте рассмотрим (на иллюстрации) пример инфраструктуры с несколькими подсетями. Может возникнуть вопрос, а как же один компьютер соединиться с другим? Откуда он знает, куда посылать пакеты?
Для разрешения этого вопроса, сети между собой соединены шлюзами (маршрутизаторами). Шлюз - это тот же хост, но имеющий соединение с двумя и более сетями, который может передавать информацию между сетями и направлять пакеты в другую сеть. На рисунке роль шлюза выполняет pineapple и papaya, имеющих по 2 интерфейса, подключенные к разным сетям.
Чтобы определить маршрут передачи пакетов, IP использует сетевую часть адреса (маску подсети). Для определения маршрута, на каждой машине в сети имеется таблица маршрутизации (routing table), которая хранит список сетей и шлюзов для этих сетей. IP "просматривает" сетевую часть адреса назначения в проходящем пакете и если для этой сети есть запись в таблице маршрутизации, то пакет отправляется на соответствующий шлюз.
В Linux ядро операционной системы хранит таблицу маршрутизации в файле /proc/net/route. Просмотреть текущую таблицу маршрутизации можно командой netstat -rn (r - routing table, n - не преобразовывать IP в имена) или route. Первая колонка вывода команды netstat -rn (Destination - назначение) содержит адреса сетей (хостов) назначения. При этом, при указании сети, адрес обычно заканчивается на ноль. Вторая колонка (Gateway) - адрес шлюза для указанного в первой колонке хоста/сети. Третья колонка (Genmask) - маска подсети, для которой работает данный маршрут. Колонка Flags дает информацию об адресе назначения (U - маршрут работает (Up), N - маршрут для сети (network), H - маршрут для хоста и т.п.). Колонка MSS показывает число байтов, которое может быть отправлено за 1 раз, Window - количество фреймов, которое может быть отправлено до получения подтверждения, irtt - статистика использования маршрута, Iface - указывает сетевой интерфейс, используемый для маршрута (eth0, eth1 и т.п.)
Как видно в примере ниже, первая запись (строка) указана для сети 128.17.75, все пакеты для данной сети будут отправлены на шлюз 128.17.75.20, который является IP адресом самого хоста. Вторая запись - это маршрут по умолчанию, который применяется ко всем пакетам, посылаемым в сети, не указанные в данной таблице маршрутизации. Здесь маршрут лежит через хост papaya (IP 128.17.75.98), который можно считать дверью во внешний мир. Данный маршрут должен быть прописан на всех машинах сети 128.17.75, которые должны иметь доступ к другим сетям. Третья запись создана для петлевого интерфейса. Данный адрес используется, если машине необходимо подключиться к самой себе по протоколу TCP/IP. Последняя запись в таблице маршрутизации сделана для IP 128.17.75.20 и направляется на интерфейс lo, т.о. при подключении машины к самой себе на адрес 128.17.75.20, все пакеты будут посылаться на интерфейс 127.0.0.1.
Если хост eggplant пожелает послать пакет хосту zucchini, (соответственно, в пакете будет указан отправитель - 128.17.75.20 и получатель - 128.17.75.37), протокол IP определит на основании таблицы маршрутизации, что оба хоста принадлежат одной сети и пошлет пакет прямо в сеть, где zucchini его получит. Если более подробно сказать.. сетевая карта широковещательно кричит ARP-запросом "Кто такой IP 128.17.75.37, это кричит 128.17.75.20?" все машины, получившие данное послание - игнорируют его, а хост с адресом 128.17.75.37 отвечает "Это я и мой MAC - адрес такой-то...", далее происходит соединение и обмен данными на основе arp таблиц, в которых занесено соответствие IP-MAC адресов. "Кричит", то есть этот пакет посылается всем хостам, это происходит потому что, MAC-адрес получателя указан широковещательный адрес ( FF:FF:FF:FF:FF:FF ). Такие пакеты получают все хосты сети.
Пример таблицы маршрутизации для хоста eggplant:
[root@eggplant ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
128.17.75.0 128.17.75.20 255.255.255.0 UN 1500 0 0 eth0
default 128.17.75.98 0.0.0.0 UGN 1500 0 0 eth0
127.0.0.1 127.0.0.1 255.0.0.0 UH 3584 0 0 lo
128.17.75.20 127.0.0.1 255.255.255.0 UH 3584 0 0 loДавайте рассмотрим ситуацию, когда хост eggplant хочет послать пакет хосту, например, pear или еще дальше?.. В таком случае, получатель пакета будет - 128.17.112.21, протокол IP попытается найти в таблице маршрутизации маршрут для сети 128.17.112, но данного маршрута в таблице нет, по этому будет выбран маршрут по умолчанию, шлюзом которого является papaya (128.17.75.98). Получив пакет, papaya отыщет адрес назначения в своей таблице маршрутизации:
[root@papaya ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
128.17.75.0 128.17.75.98 255.255.255.0 UN 1500 0 0 eth0
128.17.112.0 128.17.112.3 255.255.255.0 UN 1500 0 0 eth1
default 128.17.112.40 0.0.0.0 UGN 1500 0 0 eth1
127.0.0.1 127.0.0.1 255.0.0.0 UH 3584 0 0 lo
128.17.75.98 127.0.0.1 255.255.255.0 UH 3584 0 0 lo
128.17.112.3 127.0.0.1 255.255.255.0 UH 3584 0 0 loИз примера видно, что papaya подключена к двум сетям 128.17.75, через устройство eth0 и 128.17.112 через устройство eth1. Маршрут по умолчанию, через хост pineapple, который в свою очередь, является шлюзом во внешнюю сеть.
Соответственно, получив пакет для pear, маршрутизатор papaya увидит, что адрес назначения принадлежит сети 128.17.112 и направит пакет в соответствии со второй записью в таблице маршрутизации.
Таким образом, пакеты передаются от маршрутизатора к маршрутизатору, пока не достигнут адреса назначения.
Стоит отметить, что в данных примерах маршруты
128.17.75.98 127.0.0.1 255.255.255.0 UH 3584 0 0 lo
128.17.112.3 127.0.0.1 255.255.255.0 UH 3584 0 0 loНе стандартные. И в современном linux вы такого не увидите.
OVS - openvswitch
Open vSwitch (OVS) — это многоуровневый программный коммутатор. Он предназначен для обеспечения массовой автоматизации сети посредством программного расширения, сохраняя при этом поддержку стандартных интерфейсов и протоколов управления. Open vSwitch хорошо подходит для работы в качестве виртуального коммутатора в средах с виртуальными машинами.

Работа сетей
По сетям в интернете материала, наверное, больше, чем по линуксам. Но я всё же постараюсь объяснить основы и по мере продвижения курса буду затрагивать различные детали работы сети, связанные с той или иной темой. Сразу предупрежу, что я очень сильно упрощаю, так как это не курс по сетям, я расскажу только то, что считаю необходимым на данном этапе.
В былинные времена для проброса тегированного трафика в гипервизор использовались всевозможные костыли и подпорки различной степени неожиданности (tuntap, brctl, vconfig, ebtables и прочее), что приводило к захламлению операционной системы, хостящей гипервизор, большим количеством ненужных виртуальных сетевых интерфейсов, мозолящих глаза в выводе ifconfig и вообще огорчало администраторов необходимостью строить стандартное сетевое устройство (коммутатор) из отдельных частей как какой-то велосипед. Помимо поддержки 802.1q от коммутатора на самом деле сегодня требуется еще много функций. Так необходимость в виртуальном устройстве максимально соответствующем по функционалу стандартному современному управляемому коммутатору привела к появлению проекта Open vSwitch (далее — OVS).

Open vSwitch — это многоуровневый программный коммутатор, лицензированный по лицензии Apache 2 с открытым исходным кодом. Наша цель — внедрить платформу переключения качества продукции, которая поддерживает стандартные интерфейсы управления и открывает функции пересылки для программного расширения и контроля.
Open vSwitch хорошо подходит для работы в качестве виртуального коммутатора в средах виртуальных машин. Помимо предоставления стандартных интерфейсов управления и видимости на уровне виртуальной сети, он был разработан для поддержки распределения по нескольким физическим серверам. Open vSwitch поддерживает несколько технологий виртуализации на базе Linux, включая KVM и VirtualBox.
Основная часть кода написана на независимом от платформы языке C и легко переносится в другие среды. Текущая версия Open vSwitch поддерживает следующие функции:
Стандартная модель VLAN 802.1Q с магистральными портами и портами доступа
Объединение сетевых карт с LACP или без него на восходящем коммутаторе
NetFlow, sFlow(R) и зеркалирование для повышения видимости
Конфигурация QoS (качество обслуживания), а также применение политик
Туннелирование Geneve, GRE, VXLAN, STT, ERSPAN, GTP-U, SRv6, Bareudp и LISP.
Управление ошибками подключения 802.1ag
OpenFlow 1.0 плюс многочисленные расширения
База данных транзакционных конфигураций с привязками C и Python.
Высокопроизводительная переадресация с использованием модуля ядра Linux
Open vSwitch также может полностью работать в пользовательском пространстве без помощи модуля ядра. Эту реализацию пользовательского пространства должно быть проще портировать, чем коммутатор на основе ядра. OVS в пользовательском пространстве может получить доступ к устройствам Linux или DPDK. Примечание. Открытый vSwitch с каналом данных пользовательского пространства и устройствами, отличными от DPDK, считается экспериментальным и требует снижения производительности.
Основными компонентами этой программы являются:
ovs-vswitchd — демон, реализующий переключение, а также сопутствующий модуль ядра Linux для переключения на основе потоков.
ovsdb-server — облегченный сервер базы данных, который ovs-vswitchd запрашивает для получения своей конфигурации.
ovs-dpctl — инструмент для настройки модуля ядра коммутатора.
Скрипты и спецификации для сборки RPM для Red Hat Enterprise Linux и пакетов deb для Ubuntu/Debian.
ovs-vsctl — утилита для запроса и обновления конфигурации ovs-vswitchd.
ovs-appctl — утилита, которая отправляет команды запущенным демонам Open vSwitch.
Open vSwitch также предоставляет некоторые инструменты:
ovs-ofctl, утилита для запроса и управления коммутаторами и контроллерами OpenFlow.
ovs-pki — утилита для создания и управления инфраструктурой открытых ключей для коммутаторов OpenFlow.
ovs-testcontroller — простой контроллер OpenFlow, который может быть полезен для тестирования (но не для производства).
Исправление для tcpdump, позволяющее анализировать сообщения OpenFlow.
Гипервизорам необходима возможность связывать трафик между виртуальными машинами и внешним миром. В гипервизорах на базе Linux это означало использование встроенного коммутатора L2 (мост Linux), который работает быстро и надежно. Итак, резонно задаться вопросом, почему используется Open vSwitch.
Ответ заключается в том, что Open vSwitch ориентирован на развертывание виртуализации с несколькими серверами, а это среда, для которой предыдущий стек не очень подходит. Эти среды часто характеризуются высокодинамичными конечными точками, поддержкой логических абстракций и (иногда) интеграцией или разгрузкой специального коммутационного оборудования.
Следующие характеристики и особенности проектирования помогают Open vSwitch справиться с вышеуказанными требованиями.
Все состояние сети, связанное с сетевым объектом (например, виртуальной машиной), должно быть легко идентифицируемым и допускающим перенос между различными хостами. Это может включать традиционное «мягкое состояние» (например, запись в таблице обучения L2), состояние пересылки L3, состояние маршрутизации политики, списки ACL, политику QoS, конфигурацию мониторинга (например, NetFlow, IPFIX, sFlow) и т. д.
Open vSwitch поддерживает настройку и миграцию как медленного (конфигурация), так и быстрого состояния сети между экземплярами. Например, если виртуальная машина мигрирует между конечными хостами, можно перенести не только связанную конфигурацию (правила SPAN, ACL, QoS), но и любое действующее состояние сети (включая, например, существующее состояние, которое может быть трудно восстановить). Кроме того, состояние Open vSwitch типизируется и поддерживается реальной моделью данных, что позволяет разрабатывать структурированные системы автоматизации.
Реагирование на динамику сети
Виртуальные среды часто характеризуются высокими темпами изменений. Виртуальные машины приходят и уходят, виртуальные машины перемещаются вперед и назад во времени, изменения в логической сетевой среде и так далее.
Open vSwitch поддерживает ряд функций, которые позволяют системе управления сетью реагировать и адаптироваться к изменениям среды. Сюда входит простая поддержка учета и видимости, такая как NetFlow, IPFIX и sFlow. Но, возможно, более полезным является то, что Open vSwitch поддерживает базу данных состояния сети (OVSDB), которая поддерживает удаленные триггеры. Таким образом, часть программного обеспечения оркестрации может «наблюдать» за различными аспектами сети и реагировать, если/когда они изменяются. Сегодня это активно используется, например, для реагирования и отслеживания миграции виртуальных машин.
Open vSwitch также поддерживает OpenFlow как метод экспорта удаленного доступа для управления трафиком. Для этого существует ряд применений, включая обнаружение глобальной сети посредством проверки трафика обнаружения или состояния канала (например, LLDP, CDP, OSPF и т. д.).
Обслуживание логических тегов
Распределенные виртуальные коммутаторы (такие как VMware vDS и Cisco Nexus 1000V) часто поддерживают логический контекст внутри сети путем добавления или управления тегами в сетевых пакетах. Это можно использовать для уникальной идентификации виртуальной машины (способом, устойчивым к аппаратному спуфингу) или для хранения какого-либо другого контекста, который имеет значение только в логическом домене. Большая часть проблемы создания распределенного виртуального коммутатора заключается в эффективном и правильном управлении этими тегами.
Open vSwitch включает в себя несколько методов для указания и поддержки правил тегирования, каждый из которых доступен удаленному процессу для оркестрации. Кроме того, во многих случаях эти правила тегирования хранятся в оптимизированной форме, поэтому их не нужно связывать с тяжелым сетевым устройством. Это позволяет, например, настраивать, изменять и переносить тысячи правил тегирования или переназначения адресов.
Аналогичным образом Open vSwitch поддерживает реализацию GRE, которая может обрабатывать тысячи одновременных туннелей GRE, а также поддерживает удаленную настройку для создания, настройки и отключения туннелей. Это, например, можно использовать для соединения частных сетей ВМ в разных дата-центрах.
Интеграция оборудования
Путь пересылки Open vSwitch (внутриядерный путь передачи данных) предназначен для «разгрузки» обработки пакетов на аппаратные наборы микросхем, независимо от того, размещены ли они в классическом корпусе аппаратного коммутатора или в сетевой карте конечного хоста. Это позволяет пути управления Open vSwitch управлять как чисто программной реализацией, так и аппаратным коммутатором.
В настоящее время предпринимаются многочисленные попытки портировать Open vSwitch на аппаратные чипсеты. К ним относятся несколько коммерческих чипсетов кремния (Broadcom и Marvell), а также ряд платформ конкретных поставщиков. В разделе «Портирование» документации обсуждается, как можно сделать такой порт.
Преимущество интеграции оборудования заключается не только в производительности в виртуализированных средах. Если физические коммутаторы также предоставляют абстракции управления Open vSwitch, то как физическими, так и виртуализированными средами хостинга можно управлять с помощью одного и того же механизма автоматического управления сетью.
Во многих отношениях Open vSwitch нацелен на другую точку в пространстве проектирования, чем предыдущие сетевые стеки гипервизора, фокусируясь на необходимости автоматического и динамического управления сетью в крупномасштабных средах виртуализации на базе Linux.
Цель Open vSwitch — сделать внутренний код как можно меньшим (что необходимо для производительности) и повторно использовать существующие подсистемы, когда это применимо (например, Open vSwitch использует существующий стек QoS). Начиная с Linux 3.3, Open vSwitch включен в состав ядра, а пакеты для утилит пользовательского пространства доступны в большинстве популярных дистрибутивов.
Что нужно знать о VLAN
VLAN — это виртуальные сети, которые существуют на втором уровне модели OSI и реализуются с помощью коммутаторов второго уровня. Не вдаваясь в подробности, можно сказать, что это группа портов коммутатора, разделенная на логические сегменты сети. Каждый такой сегмент имеет свой маркер (тег PVID). Каждая группа портов VLAN’а знает о своей принадлежности к определенной группе благодаря этим тегам.
Существует два типа портов: access и trunk. В access подключаются конечные сетевые устройства, в trunk подключаются только другие trunk-порты. Если с компьютера пакет попадает на access-порт, то он помечается тегом (PVID), и далее коммутатор отправляет этот пакет только на порты точно с такими же VLAN ID или на trunk-порт. При отправке кадра конечному узлу тег снимается, так что они понятия не имеют о том, что находятся в каком-либо VLAN’е.
Когда пакет попадает на trunk-порт, он передается как есть, тег не снимается. Таким образом, внутри trunk-порта передаются пакеты с несколькими тегами (PVID).
Стоит заметить, что access-порт можно настроить так, чтобы тег на выходе не снимался, тогда для принятия пакета конечный клиент должен знать, в какой VLAN он подключен. Не все сетевые карты и/или ОС поддерживают работу с VLAN по умолчанию. Как правило, это зависит от драйвера сетевой карты.
Установка и начало работы
Пакет OpenVSwitch поставляется из стандартного репозитория Ubuntu/Debian, поэтому установка простая. Выполняем команду:
sudo apt install openvswitch-switchДля работы с сетевыми интерфейсами используется утилита ovs-vsctl. Проверим, какая версия OpenVSwitch установлена:
sudo ovs-vsctl -VВывод утилиты:
ovs-vsctl (Open vSwitch) 2.9.0
DB Schema 7.15.1Создание виртуальных интерфейсов
Для создания виртуального коммутатора сначала необходимо создать мост до реального сетевого устройства. Реальный сетевой порт, по сути, будет являться одним из портов виртуального коммутатора.
Создаем мост:
sudo ovs-vsctl add-br bridgeswitchДобавляем к мосту сетевой интерфейс:
sudo ovs-vsctl add-port bridgeswitch eth0Теперь можно перейти к добавлению виртуальных портов:
sudo ovs-vsctl add-port bridgeswitch test-interface -- set interface test-interface type=internalВ команде выше мы обозначили создание виртуального интерфейса test-interface, привязанного к бриджу bridgeswitch. После двойной черты, обозначающей начало новой строки, указываем тип интерфейса.
Виртуальных коммутаторов, как и виртуальных интерфейсов можно создавать неограниченное количество. В последствие, виртуальные сетевые интерфейсы будут подключаться к виртуальным машинам.
На этом все. Теперь, выполнив команду:
sudo ovs-vsctl showможно увидеть список всех мостов и виртуальных интерфейсов:
ovs-vsctl show
8e5433c6-c82d-46b0-8378-543c40e4e9c0
Bridge bridgeswitch
Port test-interface
Interface test-interface
type: internal
Port "enp5s0"
Interface "eth0"
Port bridgeswitch
Interface bridgeswitch
type: internal
ovs_version: "2.9.0"С виртуальным интерфейсом test-interface можно работать как с обычным физическим, то есть появляется возможность конфигурировать его на локальной машине. Это бывает полезно, когда нужно обеспечить работу сервера в нескольких вланах, используя одну сетевую карту в качестве транка. Или, например, задать серверу несколько ip адресов. Для этого создается несколько виртуальных интерфейсов и для каждого прописывается конфигурация. Но я не рекомендую это делать. Если возникнет ситуация как в примере выше, то лучше использовать возможности systemd-networkd или ip.
Для удаления портов используйте следующую команду:
sudo ovs-vsctl del-port bridgeswitch test-interfaceДля удаления бриджа:
sudo ovs-vsctl del-br bridgeswitchДобавление VLAN
Одним из больших плюсов работы с OpenVSwitch является поддержка VLAN. Для этого нужно обозначить теги на виртуальных портах и настроить сетевую карту как транковый интерфейс.
Создадим новый виртуальный коммутатор:
sudo ovs-vsctl add-br vlanswitchДобавляем реальную сетевую карту к виртуальному коммутатору:
sudo ovs-vsctl add-port vlanswitch eth0Делаем порт коммутатора транковым и описываем теги, которые будут проходить через коммутатор:
sudo ovs-vsctl set port eth0 trunks=10,20,300,400,1000Добавляем виртуальный сетевой интерфейс и присваиваем ему тег:
sudo ovs-vsctl add-port vlanswitch testvlan20 tag=20 -- set interface testvlan20 type=internalТеперь можно посмотреть конфигурацию:
ovs-vsctl show
8e5433c6-c82d-46b0-8378-543c40e4e9c0
Bridge vlanswitch
Port vlanswitch
Interface vlanswitch
type: internal
Port "testvlan20"
tag: 20
Interface "testvlan20"
type: internal
Port "enp5s0"
trunks: [10, 20, 300, 400, 1000]
Interface "enp5s0"
ovs_version: "2.9.0"Включение Netflow на виртуальном коммутаторе OpenVSwitch
Если возникает необходимость вести учет сетевого трафика, проходящего через интерфейсы, то заставить OpenVSwitch отправлять пакеты Netflow на адрес коллектора можно одной командой:
ovs-vsctl -- set Bridge vlanswitch netflow=@nf /
-- --id=@nf create NetFlow targets="192.168.1.1:5566" /
active-timeout=30Необходимо только указать имя виртуального коммутатора, ip адрес и порт назначения и период, через который будут отправляться данные (в секундах).
Чтобы обновить или изменить параметры, указанные в предыдущей команде, выполняем:
ovs-vsctl set Netflow vlanswitch active_timeout=60Чтобы прекратить отправлять данные на Netflow коллектор, достаточно очистить настройки Netflow для виртуального коммутатора:
ovs-vsctl clear Bridge vlanswitch netflowОсновы сети

Если вы читаете данную статью, значит вы знаете что такое сеть. Разве что стоит отметить, что почти все компании имеют какие-то внутренние сервисы и для них организуется так называемая локальная сеть. Но мы ещё к этому придём. Итак, для того, чтобы различные компьютеры с разными операционными системами и программами могли взаимодействовать между собой, существует универсальная сетевая модель, называемая OSI, которая определяет стандарты. Эта модель делит взаимодействие на шаги, так называемые уровни, и каждый уровень имеет свои правила. Набор этих правил определяет, как именно должно происходить взаимодействие и называется протоколом. Названия каких-то протоколов вы наверняка где-то видели - IP, DNS, HTTP. Хотя стандартная модель OSI предполагает 7 уровней, администраторы чаще всего работают со вторым, третьим, четвёртым уровнями и объединяют 5, 6 и 7 уровни в один, чаще всего называя седьмым.

Первый уровень - физический, предполагает стандарты и технологии для физического взаимодействия. Технологии бывают разные - ethernet, wifi, оптика. Для работы с сетью на каждом компьютере имеются сетевые адаптеры - чаще всего это ethernet адаптер, ну и wifi на ноутбуках.

Скорее всего, по работе, вы будете взаимодействовать с ethernet-ом. Для соединения одного компьютера с другим используются кабели определённых категорий, чаще всего в наше время это cat 5. Он состоит из 8 медных проводов, по которым и ходят сигналы. Кабели скручены по два по определённому стандарту и такая пара проводов называется витой парой. И по работе нужно бывает обрезать эти кабели до нужной длины, вставлять их в коннектор и обжимать. Погуглите «обжим витой пары», посмотрите на ютубе, так как новичков часто спрашивают об этом на собеседованиях.
cat 5 поддерживает до 1 гигабита в секунду - 1 gbps. gbps означает gigabits per second. Скорость работы сети исчисляется в битах и чтобы понять пропускную способность в байтах просто делите на 8, так как 1 байт - это 8 бит. Т.е. cat 5 в идеале может передавать файлы со скоростью 1024/8 - 128 мегабайт в секунду. Но на самом деле чуть меньше, так как окружение всё таки влияет.

На втором уровне, который называется канальным, компьютеры могут различать друг друга. Для этого на каждом сетевом адаптере, на каждом порту есть специальный MAC адрес. Он выглядит как 12 букв и цифр, поделённых двоеточиями по два - 00:1B:44:11:3A:B7. Он уникальный и выставляется производителем адаптера ещё на заводе. Так как мак адрес позволяет опознавать другие компьютеры, можно подключать больше компьютеров друг к другу. Компьютеров может быть много, но нереально на каждом компьютере иметь сотни портов и прокидывать тысячи кабелей от одного компьютера к другому.
Чтобы связать несколько компьютеров в одну сеть чаще всего используются коммутаторы, в простонародье - свитчи. В простом варианте это устройства, имеющие кучу портов - от 4 до 96, если не говорить о каких-то редких. Если не хватает или устройства расположены на разных этажах - можно подключать несколько свитчей друг к другу. В свитчах есть как минимум таблица мак адресов - свитч запоминает, за каким портом находится какой мак адрес. Когда один компьютер хочет связаться с другим, он обращается к определённому мак адресу, свитч это видит и связывает два устройства через свои порты.
Но такой подход годится, когда компьютеров не слишком много - десяток, сотня, не более. Компьютеров может быть очень много, некоторые могут менять мак адрес, скажем, после замены сетевого адаптера, да и в целом работать с мак адресами не удобно. Поэтому мак адреса используются только в локальных сетях. Скажем, у вас дома, если у вас несколько устройств, или в небольших офисах, в отделах больших компаний и т.п. Представьте небольшой город. Каждое здание - это один компьютер. Локальная сеть - это уличные дороги, связывающие здания.
Так вот, третий уровень модели OSI - сетевой. И на нём вводится понятие IP адрес. У каждого компьютера в локальной сети есть IP адрес - как и у каждого здания в городе есть свой адрес. IP адреса позволяют взаимодействовать компьютерам, находящимся в разных сетях. На самом деле они и в локальных сетях используются, просто компьютер находит соответствующий мак адрес по IP. Есть различные версии протокола IP - ipv4 и ipv6. Более популярный и простой - ipv4 и мы поговорим о нём.

Итак, IP адрес состоит из 4 чисел, разделённых точкой. Числа от 0 до 255. Т.е. технически IP состоит из 4 байт, каждый байт может уместить 8 бит, а каждый бит принять 2 значения. Итого 2 в 8 степени. Получается около 4 миллиардов адресов. Но этого не хватает - у одного компьютера может быть несколько адресов, у каждой виртуалки свои адреса, телефоны и прочие устройства - в общем, много всего. Но сеть позволяет сделать так, чтобы у разных компьютеров были одинаковые адреса, правда не в рамках одной локальной сети.
Скажем, у большинства населения по домам одинаковые IP адреса, допустим 192.168.0.100. Из примера с городом - в разных городах могут быть одинаковые адреса, скажем «улица Ленина, 20». В одном городе так делать не стоит, а в разных - без проблем.
Чтобы компьютеры могли понять, какой адрес находится в их сети, а какой в другой, есть маска подсети. Она указывается рядом с IP адресом. Она тоже состоит из 4 чисел, разделённых точкой, также имеющих значение от 0 до 255. Для примера возьмём самую популярную маску, скорее всего, используемую у вас дома - 255.255.255.0. Последнее число - 0 - говорит о том, что у вас в сети может быть 256 значений, т.е. 256 адресов. Но, на самом деле, первое и последнее значение зарезервированы. В данном случае 0 используется как адрес сети, как адрес самого города. А 255 - broadcast - способ обратиться ко всем компьютерам в этой сети. Скажем, если у вашего компьютера IP адрес - 192.168.0.100 с маской 255.255.255.0, то для него локальной сеткой будут компьютеры с адресами от 192.168.0.1 до 192.168.0.254, адресом сети будет 192.168.0.0, а броадкаст адресом будет 192.168.0.255. Кстати, нередко маску пишут как /24. Это означает, что первые три числа - 255, а это максимальное значение 8 бит. 8+8+8 = 24. Не будем усложнять тему подсетей на сегодня, поэтому продолжим.
Почему именно 192.168? Есть список зарезервированных IP сетей, выделенных для частного пользования в домах и компаниях. И придя в гости или в какие-то компании, вы будете натыкаться на схожие подсети и IP адреса.

Так вот, допустим, компьютер видит, что какой-то IP адрес находится в другой сети, как он к нему обратится? Для этого есть такой механизм, как маршрутизация, в простонародье - роутинг. Обычно для этого используются маршрутизаторы или роутеры - как, например, ваш домашний роутер. Он находится с вами в одной сети, но у него есть выход и в другую сеть, благодаря чему он может связывать компьютеры вашей сети с компьютерами другой. Обычно роутерам дают граничные IP адреса - либо 1, либо 254, чтобы было понятнее, что это роутер. А на компьютере, при настройке IP адреса, также можно указать gateway - шлюз - и тут указывается адрес роутера. Если вы его указали - компьютер при необходимости связи с другой сетью будет обращаться к роутеру, а тот будет связываться с той стороной. Но роутер не будет передавать мак адреса, только IP адрес.

И интернет, в сильно упрощённом виде - это набор роутеров и свитчей - в домах стоят роутеры, которые подключены к роутеру вашего провайдера, а он соединён с роутерами других провайдеров. И все эти связи и формируют интернет. При этом, посмотрите на схему - у домашних компьютеров могут быть одинаковые адреса. Из интернета нельзя попасть в вашу домашнюю сеть - 192.168.0.0 - так как она зарезервирована для частного использования и любой желающий может её у себя поднять. Но при этом, у вашего роутера есть и внешний адрес, например - 5.5.5.5. И когда вы выходите в интернет, ваш роутер подменяет ваш адрес на свой внешний, чтобы вам могли ответить. Такая технология называется NAT - преобразование сетевых адресов. Скажем, если website увидит запрос от 192.168.0.100, то он не будет знать, кому посылать ответ. Но ваш роутер при запросе подменяет ip адрес, website видит адрес 5.5.5.5 и отвечает ему. А роутер перенаправляет ответ вам, так как при NAT-е он запоминает ваш запрос и ждёт на него ответ.
При этом, website или любой другой компьютер в интернете не могут напрямую обратиться к вашему компьютеру, опять же, потому что 192.168.0.0 - недоступен из интернета. Другие компьютеры могут обратиться к вашему внешнему адресу - 5.5.5.5 - но роутер сам по себе не будет перенаправлять запросы на ваш компьютер, так как это слишком опасно, в интернете много вредоносных программ. Да и NAT позволяет держать за одним внешним IP адресом множество компьютеров. Скажем, ваш телефон, компьютер, ноутбук и телевизор в интернет выходят с одного адреса. В компаниях так делают сотни и тысячи компьютеров. Безопасность и экономия IP адресов.
Внутри компании может быть множество сетей, например, сеть для серверов и сеть для пользователей. В таких случаях NAT обычно не используется, так как бывает нужно, чтобы и пользователи могли достучаться до серверов и сервера могли подключиться к компьютерам пользователей. Поэтому внутри компании не используют одинаковые IP адреса для сетей.
Так вот, всё это был уровень 3 модели OSI - layer 3 - или просто l3. Первые три уровня формируют карту подключений - как дороги в городах. Есть дома, у каждого дома свой адрес, каждый дом находится в каком-то городе и, чтобы добраться из одного города в другой, надо поехать к выходу из города, оттуда доехать до другого города и потом до нужного дома. Компьютер - роутер - другой роутер - другой компьютер. Но суть сетей не в том, чтобы доехать куда-то, а в том, чтобы доставлять посылки, ну или по компьютерному - пакеты. Компьютеру один надо доставить пакет до компьютера два.

И тут мы добираемся до уровня 4 - транспортный. Посылки ведь бывают разные и их можно доставлять по разному. К примеру, в американских фильмах почтальоны у дома бросают газеты по утрам. Подует ветер, унесёт собака или ещё что - не страшно, всего лишь газета. Допустим, в сетях так работает доставка «пакетов времени» - NTP. Ваш компьютер может запрашивать у сервера текущее время и сервер отправляет вашему компьютеру ответ. И это происходит, допустим, раз в 10 минут. Но если вдруг ваш компьютер не получит ответ - небольшой сбой в сети - ничего страшного. Вы всё равно через 10 минут заново запросите. То есть пакет отправляется, но отправителю не нужно знать, доставился ли пакет или нет. Такой протокол доставки называется UDP.

Но, зачастую, в пакетах может быть важная информация и потерять её не хотелось бы. В таких случаях используют другой протокол - TCP. При TCP соединении отправитель должен убедиться, что пакет дошёл, для этого он ждёт подтверждения от второй стороны. И если в течение определённого времени ответа нет, он заново отправляет копию пакета.

На этом же уровне мы с вами познакомимся с такой вещью, как порты. Не физические порты, а tcp или udp порты. Если компьютер - это дом, то порт - это квартира в этом доме. И абсолютно все дома - многоквартирные. Вы не можете просто принести пакет и положить в дом - курьер должен забрать от двери и доставить до двери. За каждой дверью живёт определённый человек, выполняющий определённую задачу. Допустим, когда вы заходите на сайт через браузер, ваш комп использует какой-то порт для отправки запроса. Браузер знает, что сайты выдаёт вебсервер, а он живёт на 80 порту. И курьер идёт в определённый дом с таким-то IP адресом и стучится в 80 дверь. Ждёт сколько-то. Если вебсервер действительно там живёт, то он отвечает курьеру, отдаёт ему пакет и курьер возвращает обратно ответ на тот порт, с которого был отправлен запрос. Если же никого за 80 дверью нет - грустный курьер возвращается ни с чем и браузер говорит, что не смог достучаться до вебсервера. Портов может быть 65 тысяч, при этом, обычно, для приёма используется 3-4 порта, а порты для исходящих запросов выдаются динамически и зависят от количества соединений.

И тут же познакомимся с таким понятием, как фаервол. Вы можете не хотеть, чтобы кто-то кроме вас или определённые люди могли подключаться к каким-то портам вашего сервера. И вы можете поставить вахтёра, который будет встречать курьеров на входе в дом - если кто-то не будет соответствовать её правилам, она просто запретит курьеру входить. Правила обычно выглядят так - от каких адресов к каким портам есть доступ, или к каким нету. Такие фаерволы называются персональными и стоят в самой системе. Очень часто на роутерах ставят сетевые фаерволы - они уже проверяют на входе в сеть, всё равно что посты на въезде в город.
За tcp и udp портами уже находятся сами приложения - обычно это какие-то демоны в системе. Это уже 5, 6 и 7 уровни модели OSI. Один порт - одна программа, но у программы может быть несколько портов. Допустим, вебсервер использует как 80 порт, так и 443. Есть стандарты, какие программы за какими портами живут. Это можно поменять, но зная, что делаешь. Скажем, если поменять стандартные порты вебсервера, то браузеры не будут открывать сайты, пока не укажешь в браузере порт вручную. Но обычные пользователи этого не знают и откуда им знать, на какой порт вы поменяли?
На этом уровне уже работают программы, тот же самый вебсервер и браузер. Обе программы для взаимодействия используют протоколы, например, HTTP. Как и браузеры могут быть разные, так и программы на серверах, выступающие вебсервером. И именно использование единого протокола HTTP позволяет всем работать со всеми, независимо от браузера или вебсервера или операционной системы.

Итак, мы с вами вкратце рассмотрели модель OSI. И когда один компьютер пытается послать что-то другому, этот процесс напоминает упаковку коробок и отправку. Для примера, вы хотите открыть какую-то страничку в интернете. Ваш браузер упаковывает ваш запрос в коробку, на которой пишет информацию согласно протоколу HTTP. Дальше ваша операционная система берёт эту коробку и наклеивает на него ещё одну наклейку, в которой добавляет информацию по протоколу TCP, с какого source порта был отправлен запрос и на какой destination порт. Потом добавляет ещё одну наклейку - с какого IP адреса был запрос и на какой. Потом ещё одну наклейку - с какого мак адреса и на какой. Потом компьютер преобразует полученный пакет в 0 и 1 и отправляет на свитч. Весь этот процесс называется энкапсуляцией. Свитч преобразует начало - и смотрит, на какой мак адрес нужно отправить - на роутер. Видит в таблице мак адрес роутера - 12 порт. Свитч отправляет на роутер. Роутер раскрывает начало и смотрит, а на какой адрес нужно отправить. Допустим, этот адрес роутеру неизвестен - он отклеивает наклейку l3 и клеит свою, заменяя ваш IP адрес на свой, для NAT-а, и оставляя вашу наклейку у себя в архиве. Дальше отправляет на свой шлюз - другой роутер. Другой роутер тоже раскрывает, смотрит, не знает - отправляет на свой шлюз - третий роутер. Где-то в промежутке есть ещё свитчи и ещё роутеры и так десятки раз, пока не дойдёт до нужного сервера. В итоге доходит до нужного роутера, который видит нужный сервер в своей сети, он переклеивает наклейку с мак адресом и отправляет на нужный сервер. Сервер преобразует 0 и 1 в данные и видит свой мак адрес, понимает, что это ему. Начинает дальше отклеивать наклейки - видит, что запрос пришёл на его IP адрес. Снимает ещё одну наклейку - видит, tcp порт 80. За последними двумя шагами следит firewall - а можно ли доставлять пакеты на 80 порт с этого IP адреса? Если можно, пакет по итогу доходит до вебсервера. Потом вебсервер готовит ответ, распихивает по разным пакетам, начинает энкапсулировать и отправлять на свой роутер. И весь этот процесс происходит в доли секунд, прозрачно для пользователя, проходя огромные расстояния через сушу и океаны.

Ладно, как два компьютера общаются разобрались. Теперь стоит упомянуть два важных протокола, обеспечивающих удобство работы. Без них можно, но сложно. Начнём с DHCP. Это протокол позволяет выдавать IP адреса динамически. В отличии от MAC адреса, IP адрес не выдаётся на заводе, на каждом компьютере он настраивается отдельно. Но нельзя же каждому пользователю вручную писать свой адрес. Во-первых, это требует определённых знаний, во-вторых - просто неудобно, когда у вас большое количество компьютеров. Поэтому очень часто в сети есть DHCP сервер - им может быть и домашний роутер, и умный свитч, и даже отдельная виртуалка с линуксом. Когда какой-то компьютер подключается к сети, он отправляет всем в этой сети специальный запрос, мол есть ли в этой сети DHCP сервера? Этот запрос видит DHCP сервер и отвечает пользователю. DHCP решает, какой именно IP адрес выдать из свободных и даёт пользователю этот адрес, вместе с маской подсети, адресом шлюза и другими настройками. На серверах, обычно, IP адреса выдаются статически, т.е. вручную и на постоянно, а на компьютерах пользователей динамически. Т.е. эти адреса могут измениться при следующем включении.

Второй протокол - DNS - преобразует IP адреса в имена, имена в IP адреса и не только. Вы же в браузере не пишете IP адреса гугла? У гугла серверов много, откуда вам знать и зачем вам помнить их IP адреса? В браузере вы пишете доменное имя, к которому хотите подключиться - google.com. При этом ваш браузер отправляет DNS запрос на специальные сервера. Они у вас также настраиваются при настройке сети, могут выдаваться DHCP сервером. Так вот, написали вы в браузере google.com - ваш браузер отправляет запрос с этим именем на прописанный в системе DNS сервер. DNS сервер либо знает этот адрес, либо обращается к другим DNS серверам, которые также могут обращаться дальше, пока не найдут ответ, кто же находится за этим именем. В итоге DNS возвращает вам IP адрес и ваш браузер отправляет HTTP запрос на этот адрес.
Сеть - громадный и сложный механизм, который для конечных пользователей упрощён до уровня выключателя. В средних и больших компаниях сеть администрируют целые отделы сетевых администраторов, которые изучают сети годами.
Коротко о сетевом потоке
Продолжаем нашу статью.

Рисунок B: простое объяснение того, что выделяется и как пакеты проходят через ядро:
1) На самом раннем этапе загрузки ядра ЦП выделяет буферы пакетов (буферы RX и TX) и строит дескрипторы файлов.
2) ЦП сообщает сетевой карте, что были созданы новые дескрипторы, которые сетевая карта может начать использовать.
3) DMA (память с прямым доступом) извлекает дескрипторы.
4) Пакет достигает сетевого адаптера.
5) DMA Записывает пакет в кольцевой буфер RX.
6) Сетевая карта информирует драйвер, который информирует ЦП о том, что новый трафик готов к обработке с использованием аппаратного прерывания (IRQ) .
8) После первого аппаратного прерывания обработчик прерываний маскирует его, и вместо этого драйвер использует использование программного прерывания (SoftIRQ) , которое гораздо менее затратно для ЦП (аппаратные прерывания не могут быть прерваны, что очень дорого обходится ЦП).
9) SoftIRQ вызывает подсистему NAPI (просыпается), которая вызывает функцию опроса драйвера сетевой карты.
9) ЦП обрабатывает входящие пакеты.
10) По истечении определенного времени бюджета SoftIRQ система NAPI снова переходит в спящий режим, если бюджет SoftIRQ заканчивается, ЦП переходит к следующей задаче, и счетчик time_squeezed в файле /proc/net/ softnet_stats увеличивается на 1.
При инициализации сетевого адаптера драйвер выполняет следующие действия:
1) Распределяет очереди Rx и Tx в памяти (пространство DMA).
2) Включите NAPI, который по умолчанию отключен.
3) Зарегистрируйте обработчик прерываний.
4) Включить аппаратные прерывания.
Заключение
Вся информация бралась из открытых источников
Полезные материалы:
Английский:
Linux Conf 2017 - Kernel-bypass networking for fun and profit (Video)
Kernel-bypass techniques for high-speed network packet processing (PDF)
Kernel-bypass techniques for high-speed network packet processing (Video)
Intel - DPDK Open vSwitch: Accelerating the Path to the Guest (4 Part Video)
Illustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiving Data
Stack Overflow - Ring Buffers and DMA Memory - illustration of the process
С вами был доктор Аргентум, всем до встречи.
Комментарии (5)

jackcrane
22.12.2023 14:51нужно ли бить сетевиков за россказни про "классы адресов A, B, C" или не нужно - науке не известно. но вот за модель OSI (я называю ее "модель SOSI") - точно нужно. ни одной сети, сделаной по ней, не существует (были сети типа X.25, но их давно сдали на цветмет). в наследство от нее нам достались только чудовищная ASN.1 нотация, адреса типа "почта X.400" и пожалуй все.

sshikov
22.12.2023 14:51Зато (если я вас правильно понял), упоминание модели OSI в тексте такого рода сразу позволяет вам понять ценность(?), которую несет подобная статья, разве нет?
А вот ASN.1 я не понимаю, чем вам не угодила. Она просто работает. Скажем, мне недавно было нужно найти описание формата файлов кербероса (а конкретно keytab). Я был бы просто счастлив, если бы нашел ASN.1 нотацию - это означало бы, что я могу взять инструмент, и написать парсер. Но я ее не нашел - и в итоге, я имею три разных парсера, которые по разному парсят один и тот же файл.
Ну да, она возможно сто раз неудобная, и инструментарий для ее поддержки архаичный, что правда, то правда.
jackcrane
22.12.2023 14:51зачем лазить в keytab чем-то кроме родных утилит ?
формат бинарный, может быть изменен без предупреждения, минимум один раз уже менялся, backup/restore только целиком.
приведу аналогию: это все равно что читать /var/log/lastlog чем-то кроме last(8).
или эвент логи виндовс чем-то кроме гуевых глюкал и wevtutil.exe.
aborouhin
Для анонсированного в начале статьи рассказа о виртуализации OVS, ради которого я начал это читать, в итоге в тексте так и не нашлось места :( Зато в середине статья делает впечатляющий прыжок от детального и рассчитанного на очень глубокое погружение в тему описания нюансов реализации сетевого стека в ядре Linux к жанру "что такое сети с нуля для самых маленьких" :)
DrArgentum Автор
Нашел в черновиках, добавил. Спасибо за отзыв