
В 2023-ем году мы узнали, что нейросети могут галлюцинировать. На первый взгляд, это довольно забавное и пока что безобидное явление. Но в этой короткой статье я расскажу, как я столкнулся с галлюцинациями самого Google, и как это чуть не угробило стартап, в котором я работаю.
Три месяца назад я присоединился к проекту из ОАЭ. Нашей задачей было написать сайт, на котором бы выкладывались тексты на трёх языках: на арабском, английском и русском. Задача относительно тривиальная, особенно в сравнении с проектами, над которыми я работал раньше, так что за два месяца мы слепили админку, редакторы начали выкладывать тексты, всё шло по плану.
Первый звоночек
Однажды ко мне стучится менеджер проекта и говорит, что у редактора на арабском некоторые страницы в админке не открываются, а вместо них выходит предупреждение об опасном сайте. Браузер — Edge, ни у кого больше таких проблем нет.
«Странно», подумал я. У нас стек чистый, Symfony + Next JS, никаких трекеров и прочего стороннего мониторинга у нас нет, скачать из админки ничего нельзя, к тому же при деплое проходит дополнительная проверка на подозрительный код.
«Ну наверное потому что для dev‑версии мы пока не сделали HTTPs», подумал я и забил.
Проблема встаёт в полный рост
Прошло несколько недель, мы выкладываем проект в полуоткрытый доступ: теперь сайтом можно было пользоваться без VPN, но всё равно там стояла авторизация, и без аккаунта, который мы выдаём поштучно сами, ничего на сайте увидеть нельзя.
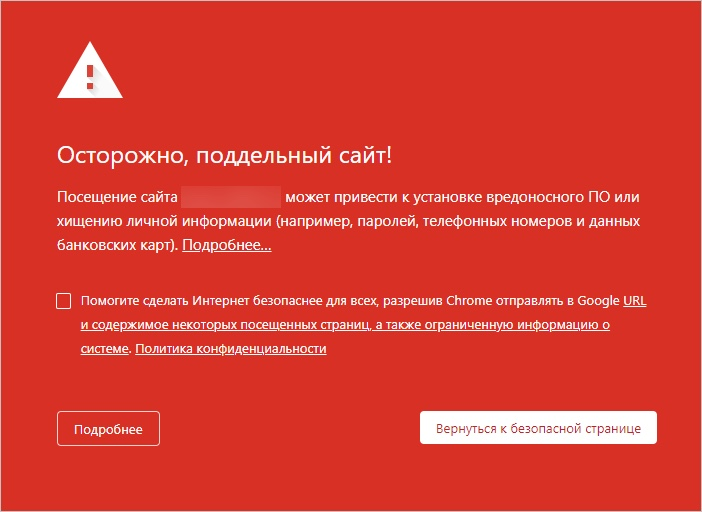
Меньше, чем через 24 часа после того, как мы выложили сайт, менеджер снова нервно стучится ко мне в чат: проблема вновь появилась. Почти с десяток статей не открываются, вместо них показывается красная страница с предупреждением: «сайт может ввести вас в заблуждение и/или вынудить на действия опасного характера». Проблема присутствует во всех браузерах и у всех пользователей.
«В смысле, да как так‑то?». Разрабское чутьё мне подсказывало, что ситуация очень‑очень серьёзная, но в голове не было ни одной идеи, из‑за чего вообще это могло произойти.
Во‑первых: прошло менее 24 часов после того, как сайт стал условно доступен. Чтобы попасть под блокировку так сразу, должны быть очень‑очень серьёзные причины.
Во‑вторых: все страницы с контентом закрыты за авторизацией, то есть условный бот от Google не мог просмотреть контент в принципе. А это значит, что это браузер сам «анализировал» страницы и, как потом выяснится позже, отправлял данные в Google Safe Browsing. По закрытым страницам. Недоступным для неавторизованных пользователей.
В‑третьих: Наш сайт — это Single Page Application, гидрации контента нет, то есть, когда браузер не давал перейти на какую‑то страницу, он не знал наверняка, что на этой странице будет. То есть он «помнил», что эта страница, по его мнению, опасная, и заранее закрывал к ней доступ.
В‑четвёртых: Блокировка на уровне браузера — это что‑то явно из ряда вон выходящее. С сайта ничего нельзя скачать, все фреймворки чистые, никаких сторонних сервисов не используется вообще. За свои 16 лет в Web‑е я ни разу не встречался с подобными ограничениями, и чаще всего, если сайт не нравился Google‑у, он либо понижал, либо вообще убирал его из поисковой выдачи. А тут — сами браузеры не давали перейти на конкретные страницы.
С учётом всего вышеперечисленного, у меня не оставалось ни одной мысли о том, что мы могли сделать не так.
Я погуглил различные статьи на подобную тему, стало ясно, что скорее всего нас режет Google Safe Browsing, и судя по всему, почти все популярные браузеры, включая Edge и Firefox, с ним «советовались». Однако, наш кейс не подходил ни по одному из критериев, которые были перечислены в найденных мною статьях. Зато стало ясно: если не предпринять срочные меры, под блокировкой окажется вообще весь сайт — а то и весь домен, а не только отдельные страницы.
Расследование
Довольно быстро выяснилось, что все статьи, оказавшиеся под блокировкой, были на арабском языке. Их версии на других языках открывались как обычно, браузер на них не жаловался. К тому же в какой‑то момент у моей жены — а она работает backend разработчиком у нас на проекте — предупреждение сменилось на куда более конкретную формулировку: «Фишинговый сайт».
«Ага! Значит им не нравится контент!» — подумал я, и решил посмотреть, что там, собственно, написано в этих статьях. Надо сказать, что я знал ту девушку, которая занималась написанием текстов на арабском, и у меня не было никаких сомнений в её профессионализме. Тем не менее, я включил встроенный в браузере переводчик, и от увиденного мои глаза поползли на лоб:

Я протёр свои глаза, перезагрузил страницу, снова включил автоперевод — результат тот же. «Дети.., дети,… убийство в Королевстве,.. дети, дети.. Убийство в Колумбийском университете».

«Да этого просто не может быть!» - подумал я, скопировал текст и вставил в Google Translate. В этот раз перевод текста получился правильным, и, разумеется, никаких детей и убийств там не было и в помине. Я стал переходить по другим заблокированным страницам, и везде встроенный переводчик выдавал какую-то невероятную ахинею, разбавленную фразами про убийства и детей.
И всё встало на свои места. Если браузер реально так «видел» эти страницы, что в них внезапно упоминались дети и убийства в конкретных учебных заведениях США, то вообще не удивительно, почему были приняты подобные меры.
Здравый смысл мне быстро подсказал, в чём было дело. Суть такова, что на нашем сайте можно выбирать язык интерфейса, и по умолчанию стоит английский, что в свою очередь значит, что в теге html директива lang=”en”. Но сама статья была на арабском, и в самом контенте мы директиву lang=”ar” не поставили, ограничившись лишь dir=”RTL” (направление текста: справа на лево).
То есть, судя по всему, браузер видел, что html.lang=«en», и целиком интерпретировал страницу как на английском. И видимо проблема заключалась в том, что условная нейросеть, которая интерпретирует текст на английском, вообще не обучалась на арабском алфавите, и при получении на вход большого текста на незнакомом алфавите стала… галлюцинировать!
Проведя несколько тестов я убедился: действительно, с директивой html.lang=”ar” встроенный переводчик переводит статью правильно.
Счастливый конец
Быстро сориентировавшись, мы проставили правильные директивы lang везде, где можно, подали апелляцию в Google Console, подробно объяснив, в чём было дело, и даже выдали им временную учётку, чтобы они могли сами зайти и посмотреть (чего, разумеется, они делать не стали).
В результате все ограничения были сняты на следующий же день. Happy End!
Выводы
Директивы lang очень важны.
Браузеры мониторят даже те страницы, которые закрыты за авторизацией.
При интерпретации страниц используется нейронная сеть, подобная встроенному переводчику в Google Chrome, а то и вовсе прям та же.
Если lang страницы не соответствует языку контента, встроенный переводчик может начать галлюцинировать, «увидеть» опасный контент и сообщить куда следует.
Галлюцинирующие нейронные сети могут внезапно создать кучу проблем там, где этого ждёшь меньше всего.
Комментарии (72)

Cerberuser
12.01.2024 03:03+8Напомнило историю двухлетней давности: https://habr.com/ru/articles/650907/



Urvin
12.01.2024 03:03-7Самое интересное в статье - зачем вы два месяца пилили только админку для сайта, который только показывает тексты

Srgun
12.01.2024 03:03+39Вспомнилась аналогия: тз для сайта гугл в упрощённом виде может выглядеть как "показать текстовое поле и кнопку с надписью "Поиск". При вводе информации и нажатии кнопки "Поиск" - показать ссылки на сайты, где встречаются введённые слова". Любой джун за пару дней сделает :)

botyaslonim
12.01.2024 03:03+7Американский форум: задают вопрос, 90% ответов разной степени глубины, уточняющие вопросы. 10% свои собственные истории по теме
Русский форум: 90% реплик "да кто так делает", "да ты сам козёл", "да я лучше!"

vvbob
12.01.2024 03:03+23Браузеры мониторят даже те страницы, которые закрыты за авторизацией
Это прекрасно, интересно, что еще делают браузеры, о чем мы не знаем? И как используются эти данные мониторинга?
Можно считать это паранойей, но мы похоже уже живем в "прекрасном новом мире", в котором государство или крупные корпорации практически о любом человеке имеет такую массу информации, о которой даже он сам не догадывается.

miarh
12.01.2024 03:03+3Стоит задуматься... Например, внутренняя почта и куча ресурсов открываются браузером, даже 1с-ка...

RavilMuslyumov
12.01.2024 03:03С 2004 года живём. Никто даже не пикнул.
vvbob
12.01.2024 03:03Да, уже с момента массового распространения мобилок, каждый человек по факту таскает с собой радиомаяк, и уже даже простым анализом его перемещений можно о нем узнать массу всего.
miarh
12.01.2024 03:03Мы точно знали, что "для защиты детей" инет мониторится. Но тут он мониторит закрытые (!) ресурсы (без общего доступа) - и решение о блокировке принимает не браузер, а сервера гугла, то есть содержимое туда передается и там анализируется. Грубо говоря - у кого 1с, например, в облаке...

BlakeStone
12.01.2024 03:03Немного не понял: если бэк серверный, то валидация пароля принимается на уровне сервера и выдача контента производится оттуда же, как гугл-спайдеры могут обойти это ограничение? Другое дело, я бы понял, если «закрытый» текст уже вшит в код страницы и пароль предназначен исключительно для решения, отображать скрытый текст или нет. Но этот вариант защитs так себе.

MaratMS Автор
12.01.2024 03:03Чтобы достать контент, нужно авторизоваться и получить JWT токен. Так что "случайно" этот контент никак нельзя было бы достать. Только если сами браузеры слили.

fki
12.01.2024 03:03И еще +1 к нюансам Progressive Web Applications, совершил небольшую ошибку и всё, прилженька превращается в тыкву.

megamrmax
12.01.2024 03:03Вы можете удивиться как близки к правде. Месяца два назад запросил (в штатах так можно) данные которые насобирала на меня одна из "мы заглядываем к вам в трусы для вашего блага" контора. там были не только конкретные адреса проживания (включая фейковые) но и данные о платежах например, потенциальные интересы (весьма забавные местами) и много чего еще.


ZardoZAntony
12.01.2024 03:03+14Стоит задуматься над переходом на браузер, где вырезана слежка за пользователем.

MAXH0
12.01.2024 03:03+3Мне кажется, что современные браузеры слишком переусложнены из-за потребности поддерживать более 1000 спецификаций. В такой сложной системе просто невозможно гарантировать приватность.
Я полагаю, что надо переходить не на браузер. А начинать задумываться об архитектуре новой сети. Причем делать её отдельно от корпоратов. Потому что если извлечение данных - это большой бизнес, то корпоративная разработка просто не заинтересована в приватности пользователя.

pythonist1234
12.01.2024 03:03+6Да ну, есть опенсорные браузеры которые вполне эту тыщу спецификаций поддерживают, но как гугл не следят. Всё же здесь дело не в спецификациях, а в гугле.

askharitonov
12.01.2024 03:03+1Современные браузеры - довольно прожорливые в плане ресурсов программы, и может действительно стоило бы подумать о том, чтобы сделать многие вещи как-то иначе.

HemulGM
12.01.2024 03:03+1Так ведь тот же хромиум в открытом доступе и биндинги есть для многих языков. Спецификации поддерживает сам этот движок, а дополнительные средства защиты и тем более мониторинга туда не входят. Так что можно быстро и смело создать простой браузер на основе CEF

NN1
12.01.2024 03:03+1Доступ открыт поэтому есть проект https://github.com/ungoogled-software/ungoogled-chromium целью которого убрать все привязки Гугла.

acsent1
12.01.2024 03:03А кто будет оплачивать банкет, если не будет корпоратов?
MAXH0
12.01.2024 03:03А у корпоратов откуда деньги берутся? ОТ пользователей...
Вопрос в том, что пользователей приучили ко всему бесплатному в Интернет. НО ведь платят же пользователи за Интернет и VPN. Если новая сеть будет предоставлять некую эксклюзивную информацию, то за подписку на неё будут платить.Тут есть еще свои Сцила и Харибда. С одной стороны, если если будет приносить прибыль, то есть соблазн либо продаться корпоратам, либо самому стать корпоратами. С другой стороны, если система будет действительно надежной, то можно превратиться во второй ДаркВеб, с которым официально борятся и который ошельмован так, что типичный пользователь туда и побоится войти.

eton65
12.01.2024 03:03Проще сделать один мегасайт на все случаи жизни и для него использовать специальный простой браузер/приложение.

DanilinS
12.01.2024 03:03+2И телефоном, который не взаимодействует с сотовыми вышками.
MAXH0
12.01.2024 03:03Т.е. смартфон, но расчитанный только на Wi-Fi? Защищенный и с поддержкой шифрования. Если позиционировать его с расчетом на бизнес-среду, то я думаю проект может и взлететь. А потом, когда появится готовый к использованию продукт, его можно делать и массовым.

Wesha
12.01.2024 03:03+2смартфон, но расчитанный только на Wi-Fi? Защищенный и с поддержкой шифрования.
Коль, а Коль! Зырь, миллениалы изобрели коммуникаторы!
MAXH0
12.01.2024 03:03+1Вы зря иронизируете. Коммуникаторы как раз жили и развивались в бизнес среде. Так что возвращение не будет чем-то экстроординарным.
Другой вопрос, что тут надо тщательно продумывать экосистему. Чтобы и аудит программ и невозможность запустить неподписанную программу и система разрешений не как в андройд и физическое отключение камеры/микрофона и прочее-прочее...

begin_end
12.01.2024 03:03+2Несколько лет назад FireFox не хотел открывать страницу сайта со словом "emberscan" в домене, выдавая предупреждение безопасности, мол риск фишинга и т.д. Я тоже думал, вдруг потому что https нет. Но потом сообразил - браузеру показалось, что "emberscan" это как "etherscan", схожесть для популярного сервиса про крипту.
Недавно прошло само собой. Это не слежка, но тоже сомнительное поведение.MAXH0
12.01.2024 03:03Хочется процитировать:
есть опенсорные браузеры которые вполне эту тыщу спецификаций
поддерживают, но как гугл не следят. Всё же здесь дело не в
спецификациях, а в гугле.Вот не в Гугле персонально дело! И опенсорс не менее зависит от спонсоров, чем корпораты от акционеров. Дело в схемах монитезации и в том, что такое хорошо и что такое плохо с точки зрения хозяев денег.
В ситуации когда все больше и больше решения принимаются компьютерными экспертными системами нет ни какой гарантии, что информация собираемая браузерами не станет основой скрытого социального рейтинга. Ни кто на человека клеймо ставить не будет: но там в кредите отказали, там повышения не дали, там не допустили к торговой площадке. И все на автомате...


uhf
12.01.2024 03:03Так а на скрине галочка разрешения отправки содержимого выключена. Кто-то другой смотрел этот сайт со включенной галкой?
MaratMS Автор
12.01.2024 03:03Не совсем понял, какую галочку вы имеете в виду, но на тот момент проект успело просмотреть человек 10-15, но они разбросаны по всей планете, так что там уже не уследить и не проверить.
uhf
12.01.2024 03:03На скрине вроде как изображена галочка с надписью "Помогите сделать Интернет безопаснее..", я хотел сказать, что возможно, браузер не по дефолту отправляет содержимое страниц в Гугл, а только получив согласие пользователя.
MaratMS Автор
12.01.2024 03:03А-а-а. Скрин с ошибкой не мой, потому что я у себя его не делал. Скрин был взят с одного из сайтов, где разбирались возможные причины подобной блокировки.

ifap
12.01.2024 03:03+1Однажды ко мне стучится менеджер проекта и говорит, что...
<...>
«Ну наверное потому что для dev‑версии мы пока не сделали HTTPs», подумал я и забил.
Начать стоило еще с
консерваторииправильной реакции на репорты, а уже потом исправлять теги.MaratMS Автор
12.01.2024 03:03Обратите внимание, что я написал, что мне постучался менеджер проекта. Не создал тикет, а просто написал в личку. Так что реакция адекватная, я считаю.
ifap
12.01.2024 03:03+3Я обратил, как и на то, что когда создали тикет, под угрозой уже был запуск проекта. Но это не так важно, как тикет, разумеется /sarcasm off
MaratMS Автор
12.01.2024 03:03+8Может вам повезло, и менеджер вашего проекта не настолько общительный, как в моём проекте. В моём же случае вскакивать кабанчиком по каждому прилетевшему сообщению/запросу в личку, значит не закрыть никогда ни одной из задач.
Да и ситуация показалась мне абсурдом. К тому же проблему разрешил я, меньше чем за 9 часов после репорта. Так что вашу критику не принимаю.

domix32
12.01.2024 03:03+1Только с браузерами в статье какая-то непонятная котовасия. Если я правильно понял и все проблемы были в Edge, то анализ и переводы там вполне могли оказаться не от Google, а от Microsoft, поэтому бочку катить на гугл в этой ситуации несколько странно. Аналогично с регистром вредоносных сайтов - источник конечно гугловый, но всякие семантики определения могли быть изменены в MS. И именно MS галлюцинировала, а не гугл.
MaratMS Автор
12.01.2024 03:03+1Началось с Edge, но потом ошибка стала всплывать везде (Edge, Chrome, Firefox)

KonstantinTokar
12.01.2024 03:03Нет ли статьи, где часть текста на арабском и часть на другом языке? Что подумает браузер и какой язык надотуказать чтобы не ругался?
MaratMS Автор
12.01.2024 03:03У нас есть сводные таблицы, где есть как минимум два языка. Я сказал редакторам, чтобы ставили правильные директивы, но таблицы там огромные, и разумеется они пока ничего не исправили.


Roffild
12.01.2024 03:03+2У тут после НГ прикол от Гугл Бизнес прилетел. Можно заполнить все данные в Гугл Бизнес, но сам Гугл их пытается "исправить". На днях ГБ посчитал, что указанный сайт компании не верен и удалил ссылку! Другие данные тоже правятся "по решению Гугла" на неправильные.
Как победить неронку в Гугл Бизнес ?



satana1volga
12.01.2024 03:03Спасибо, отличная статья! Не длинная, даже с небольшой интригой
Интересно, слежка за страницами и их содержимым прямо в браузере когда-то играло на руку пользователям, а не разрабам...

tklim
12.01.2024 03:03+3Интересно, почему никого не беспокоит встроенный а хром переводчик. Ведь для перевода он отправляет страницу в гугл. Когда организация в которой я работаю перешла на хром я знатно удивился, открыв один из внутренних сайтов с испанским контентом, увидел автоперевод. Тегов с языком там не было. Он просто по контенту решил что это испанский и надо мне перевести. А так-то там может быть конфиденциальная информация, данные клиентов и т.д.
miarh
12.01.2024 03:03+2Да ладно бы просто перевести, а как оказалось оно еще и анализирует то, что перевела. И, чудным образом другие браузеры знают, что это - "вредная" страница.

dartraiden
12.01.2024 03:03Интересно, почему никого не беспокоит встроенный а хром переводчик.
Альтернатив нет. Над локальным переводом работает Mozilla, но качество перевода на русский там такое, что спасибо, не надо.

nickolaym
12.01.2024 03:03Вот поэтому НИКОГДА не работайте в интрасети в браузере хром (и плохо изолированных от хрома форках - таких, как ёж). Эти уродцы с лёгкостью сольют в гугл любую приватную информацию. Да ещё и с галлюцинациями и доносами, оказывается.

Sap_ru
12.01.2024 03:03-2Просто всегда ставьте robots.txt с запретами даже для отладочных сайтов и всё.
nickolaym
12.01.2024 03:03+1Не просто и не всё. Утечка из браузера происходит мимо роботса.
Это уже потом ИБшники будут удивляться, какого фига гугловский паукан пытается обращаться по внутренним урлам (и ему за это иногда дают по хелицерам).
И натравление паукана на внутренние сайты - лишь одна из проблем. Пример другой проблемы показан в статье. Где там роботс? Нигде.
Sap_ru
12.01.2024 03:03Внутренний урл с большой вероятностью может оказаться прямо на ноуте сидящего в кофейне разработчика, а откуда вообще возьмётся служба безопасности в типовом интернет сервисе или магазине и вовсе непонятно.
Самое веселье будет, когда "внутренний урл" окажется с сертификатом настоящего прода (копия прода для финального прогона). Или вообще без сертфиката, но с настоящим доменом. Или на другом домене и с другим сертификатом, но с сильно совпадающей (ясен перец) с продом информацией. Вот тут Гугл может без robots.txt может очень интересных сюрпризов устроить.
На автор из поста при ненастроенном robots.txt гарантированно получил бы проблем ещё и с поисковиком, но просто не успел.
robots.txt с запретом нужно привыкнуть класть вообще везде, включая локальные проекты на локальных тестовых серверах.
dmitryvolochaev
12.01.2024 03:03класть вообще везде, включая локальные проекты на локальных тестовых серверах
Проще говоря, показывать не только Гуглу, а вообще всем встречным и поперечным, где у вас лежат секреты
Sap_ru
12.01.2024 03:03+1Каким таким образом вы что-то показываете имея файл, в котором три строки текста запрещающие индексирование на всём домене?


yrub
12.01.2024 03:03есть кстати еще прикол с этим "safe browsing" - можно без особых усилий заблокировать чужой не супер популярный сайт, достаточно пожаловаться в пару сервисов на фишинг и мальварь, как выяснилось там никакой модерации и проверки нет ;) а гугл и другие сервисы оттуда в том числе подхватывают данные
MaratMS Автор
Первая моя статья, написал, потому что показалось, что такой кейс сильно важен для понимания. Ну потому что "ну как так. Как такое вообще может быть?" Да уж...
MAXH0
Спасибо! Кейс ДЕЙСТВИТЕЛЬНО важный. Даже не сколько для профессионалов - они обычно работают по стандартам и готовым шаблонам. А вот начинающие разработчики...
Я веду кружок программирования и по поводу многих метаданных дети просто хором вопят - "А можно это не писать?". Так возникает плохая привычка уходить от стандарта. Буду приводить ваш пример, как мотиватор писать по стандарту.
velon
atd
Очень рад за этих детей. Потому что вижу в индустрии обратную тенденцию: код копируется со всеми костылями и бойлерплейтами, какие только успели накопиться за много лет, и мало кто из разработчиков вообще задаётся вопросом, зачем это всё нужно, и нужно ли на данный момент.
Sap_ru
Наступил на подобные грабли. Не помню точно, был ли сайт на русском, а lang был "en" или наоборот. В остальном всё по-классике как у вас - single page без гидрации, никакого криминала, переключение языка на сайте со сменой пути - т.е. /XXX редиректил на /en/XXX или /ru/XXX.
Были также настроены sitemap, чтобы решить проблему одного и того же контента по /XXX и по /(en|ru)/XXX
А результате Гугл просто сошёл с ума, объявив стайт клоном самого себя и отказавших вообще индексировать контент. В их поисковой консоли отображалась куча бессмысленных ошибок про клоны и копирование контента.
Возможно, что в результате тоже бы попали под фишинг, но сумасшествие Гугла была обнаружено практически сразу - не прошло и суток. В качестве превентивной меры сразу же отключили все языки кроме одного и потом в ходе опытов поменяли lang на реальный язык сайта. После этого проблема немедленно пропала.
Заодно была найдена куча проблем и багов с этим lang.
Если в двух словах, то совершенно абсолютно никогда и ни при каких условиях не пытайтесь менять значение lang динамически! Даже если вам кажется, что всё работает. Нормальная работа возможна только если lang выставлен сервером (и зависит от пути в URL) или при явной перезагрузке страницы!
И ещё совет - установка пароля на сайт ничего не обещает и не гарантирует в отношении Гугла. В недрах гугло-мануалов была найдена мудрость от самого Гугла о том, что если вы закрываете доступ сайту любым образом, то обязательно настраивайте robots.txt на запрет индексации!!! И дальше было перечислено с десяток сценариев, когда Гугл закеширует и заиндексирует содержимое сайта не взирая ни какие пароли! В результате даже если сайт не будет отображаться в поиске, то он всё равно будет скрыто участвовать во всяких ранжированиях, рейтингах и рекомендациях!
То есть или контент засветите, который не хотите показывать, или в момент публичного открытия с удивлением обнаружите, что сайт не "чистый" и Гугл уже понаприсваивал ему всякого (от неверной тематики и каких-нибудь понижающих выдачу штрафов, до просто мусорного рейтинга).
Это, как бы, очевидно, но большинство интуитивно и неправильно считает, что если сайте есть пароли, то robots.txt не нужен, а по факту это несвязанные вещи.
И это в целом верно. Не хотите Гугла и прочих - явно пишите об этом в robotos.txt и sitemap.
Ну, и во время любых технических работ нужно правильные HTTP-коды выставлять и настройки для поисковиков, иначе в один прекрасный день после 15 минутных работ контент сайта в поисковиках будет заменён на нечто невообразимое.
И пишите хотя бы минимальный sitemap для языков, особенно если возможны разные URL с одинаковым контентом и/или разными языками. Там тоже куча багов зарыта, которые лучше заранее избежать. Например, корень сайта в поиске будет отображаться на случайном языке. Выход из этой ситуации может занять месяцы. Для сайта обязательно должны быть перечислены все возможные независимые начальные точки входа поисковика на сайте. Как правило это корневые страницы на разных языках.
Короче, по этим граблям тоже прошлись.
figerdron
С robots.txt тоже не так просто. Мне Гугл прямо писал: "Страница была проиндексирована несмотря на запрет в robots.txt". Пруфов, правда, не приведу...
Sap_ru
Есть такое, но это происходит в каких-то совсем редких случаях, которые на практике особо не встречаются.
vp7
А что делать, когда сайт в прицепе непубличен и никакого robots.txt там нет и быть не может?
Допустим, есть портал billing.bankname.com, где сотрудники видят все персданные клиента, его банковские транзакции и всё такое.
Портал доступен только и исключительно внутри сети банка, разграничение доступа к контенту - по участию в AD группах и правам доступа на их основе.
Но на всём этом ставят крест браузеры, которые будут сливать данные клиентов наружу несмотря на физическое отсутствие доступа для поисковых машин?
И ладно крупные компании тира банков - там ИБ может подрезать браузерам всё лишнее (начиная от управления через политики, заканчивая блокировкой нужных доменов на прокси), но у мелких компаний с приватными админками могут возникнуть большие сложности. Причём утечка может произойти с компьютера любого пользователя (или даже мобильного телефона), который смог зайти на внутренний портал.
jackcrane
запрещать на основе лузер-агента бразуеры-сливщики, разрешать только links/lynx/elinks/еще что-то проверенное собственноручно.