

Если у вас не просто большая компания, а целая экосистема с разными сервисами, IT-инфраструктура должна обеспечивать бесшовность. Клиенты и сотрудники могут входить в систему с разных устройств, но изменение информации в одном канале должно отображаться в других, а целостность данных сохраняться, даже если вход совершен в двух каналах параллельно. И в идеале — так, чтобы клиент не видел «внутренней кухни».
Меня зовут Владимир Паршин, я ведущий ИТ-инженер в СберТехе. Расскажу, как выстроена работа с бесшовностью в Сбере.
В статье будет про драматичное прошлое, Джастина Бибера и балансировку нагрузки. А главное — про то, какие решения СберТеха под капотом банка сейчас обеспечивают обработку данных огромного числа клиентов и сотрудников.
Почему ушли от парадигмы КСШ и к чему пришли
Архитектурное поколение назад в Сбере frontend и backend соединялись корпоративной сервисной шиной (КСШ). Она была построена на решениях IBM MQ и IBM Enterprise Service Bus.
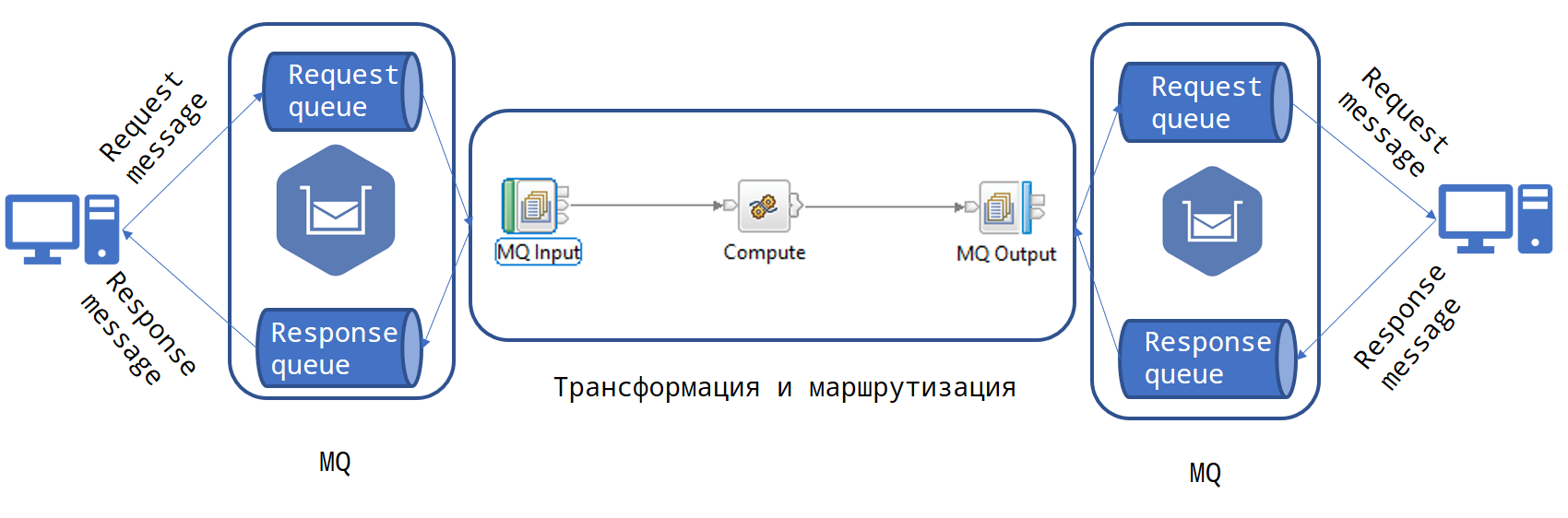
КСШ представлял собой множество программных модулей, работающих на серверах WebSphere. Запрос от клиента к бизнес-логике в backend проходил по цепочке из десятков адаптеров, каждый из которых выполнял свою функцию.
Для своего времени это было современно и надежно. Но с ростом количества обрабатываемых запросов начались сложности.
И вот какие
Запрос может пройти через длинную цепочку адаптеров, в конце которой выяснится, что целевой сервис недоступен.
Ответ возвращается так же по всей цепочке и мало информативен. Можно получить код 500 и не знать, где он возник. Из‑за отсутствия паттерна «circuit break» цепочка запросов не прерывается при ошибке в звене.
Центром КСШ был высокопроизводительный дорогой Hi‑End сервер. Но при постоянном росте количества транзакций любой Hi‑End рано или поздно заканчивается. Систему приходится делить на функциональные части, и для каждой создавать свою КСШ.
Для разработки и поддержки интеграционных адаптеров требуется централизованная команда программистов со специальными знаниями. С запросами на разработку к ним выстраивалась очередь из разработчиков бизнес‑логики, и результата можно было ждать месяцами.
Инфраструктура КСШ сложно изменяемая, не динамическая.
Подробно об этих сложностях мы рассказывали на конференции «HighLoad++ 2022» — подробности здесь.
Итого, архитектуру следующего поколения в Сбере решили выстроить в парадигме «Cloud Native»: множество слабосвязанных приложений, ориентированных на работу в облаке. Связь между приложениями производится через сеть микросервисов – service mesh.
Теперь интеграцию не нужно запрашивать у отдельной команды. Функции создания связи между frontend и backend отданы разработчикам бизнес-логики Сбера. Им в помощь предоставляются готовые детали конструктора – инфраструктурные модули в составе платформы Platform V.
Про вызовы, бесшовность и шардирование
И тут мы возвращаемся к началу статьи. Компании необходимо поддерживать целостность данных даже в ситуации одновременного входа по разным каналам и параллельного изменения хранящейся информации.
Микросервисы чаще всего не сохраняют данные о сессии пользователя. Но запрос рано или поздно достигает сервиса, который хранит данные в СУБД. Информацию о пользователях, транзакциях, сессиях и многое другое.
Для поддержки целостности данных и масштабирования приложений, хранящих данные в СУБД, мы разрабатываем продукт Platform V Synapse Application Sharding». Как понятно из названия, продукт работает по модели шардирования — горизонтального масштабирования приложений.
Как устроено шардирование в Сбере
По классике, шардирование данных — способ дробления информации путём разделения частей по выбранному признаку по отдельным серверам.
Например, базу данных клиентов можно разделить на несколько частей по первой букве фамилии. Важно, что серверы равноправны, а данные хранятся вместе с копией ПО их обработки. На каждом из серверов установлена полноценная СУБД с экземпляром базы данных и одинаковой структурой таблиц, но со своей собственной частью данных. Эту часть данных на своём сервере называют шардой.
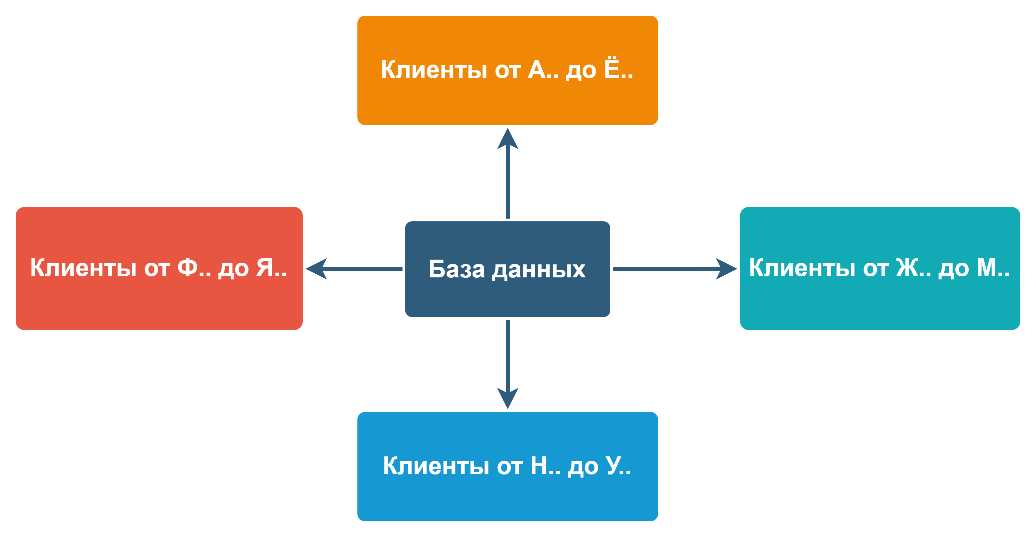
Этот подход даёт преимущество практически линейного масштабирования производительности. Особенно на логически несвязанных между собой данных, таких, как база данных клиентов. Для каждой части данных на выделенном сервере есть свои независимые процессоры и память. Накладные расходы на поиск шарды, где хранится или должна быть сохранена информация, на практике слабо зависят от степени дробления.
Из зала подсказывают, что в качестве ключа шардирования буквы алфавита не используют уже лет 15. Действительно, в промышленных системах используются хэш-функции, позволяющие более равномерно распределять данные. Но, чтобы не усложнять, продолжим использовать примеры шардирования по первой букве.
Дробление данных решает проблему производительности. Проблема надёжности и доступности же решается созданием серверов с полной копией данных – реплик. При этом количество аппаратных средств умножается минимум на два. Избыточность – это надёжно, но накладно. Особенно на большом объёме данных.
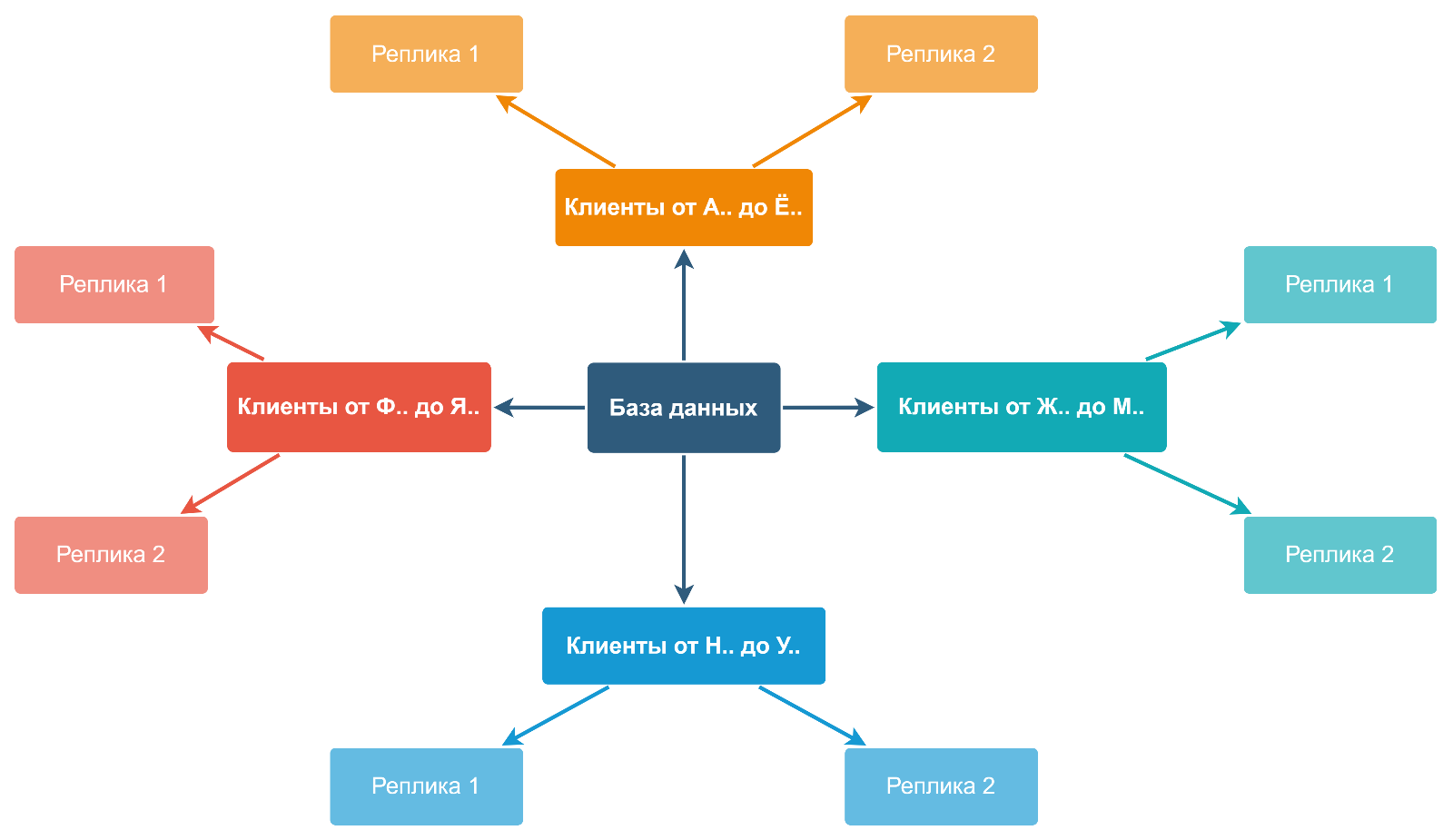
Application Sharding на шардирование смотрит шире. Поскольку он работает с REST-запросами, а не SQL, как реляционная СУБД, мы можем рассматривать данные не просто как таблицы. С точки зрения клиентских запросов можно рассматривать реплики как шарды приложений.
Это помогает решать «проблему Джастина Бибера» — когда к одной из шард возникает аномальный рост количества запросов или объёма данных. По аналогии со страницей Джастина Бибера в соцсетях, на которого подписывается больше людей, чем на других звезд.
Если одна из частей данных вдруг становится «Бибером», рост запросов к ней можно обработать за счет большого количества реплик, по которым «размазывается» трафик. Разница между шардами и репликами при обработке запроса размывается, поэтому можно говорить о маршрутизации на узел (хост сети), а не на шарду.
Запросы от фронтального слоя, приходящие на условный «Nginx», могут балансироваться по узлам приложений в бэк-офисе. С умножением на два количества серверов для создания избыточности данных, умножается на два и количество серверов для их обработки.
Правда, сейчас есть ограничение. Для обеспечения целостности данных с узла с репликой приложение может только читать, не писать. Но большая часть запросов происходит именно на чтение.
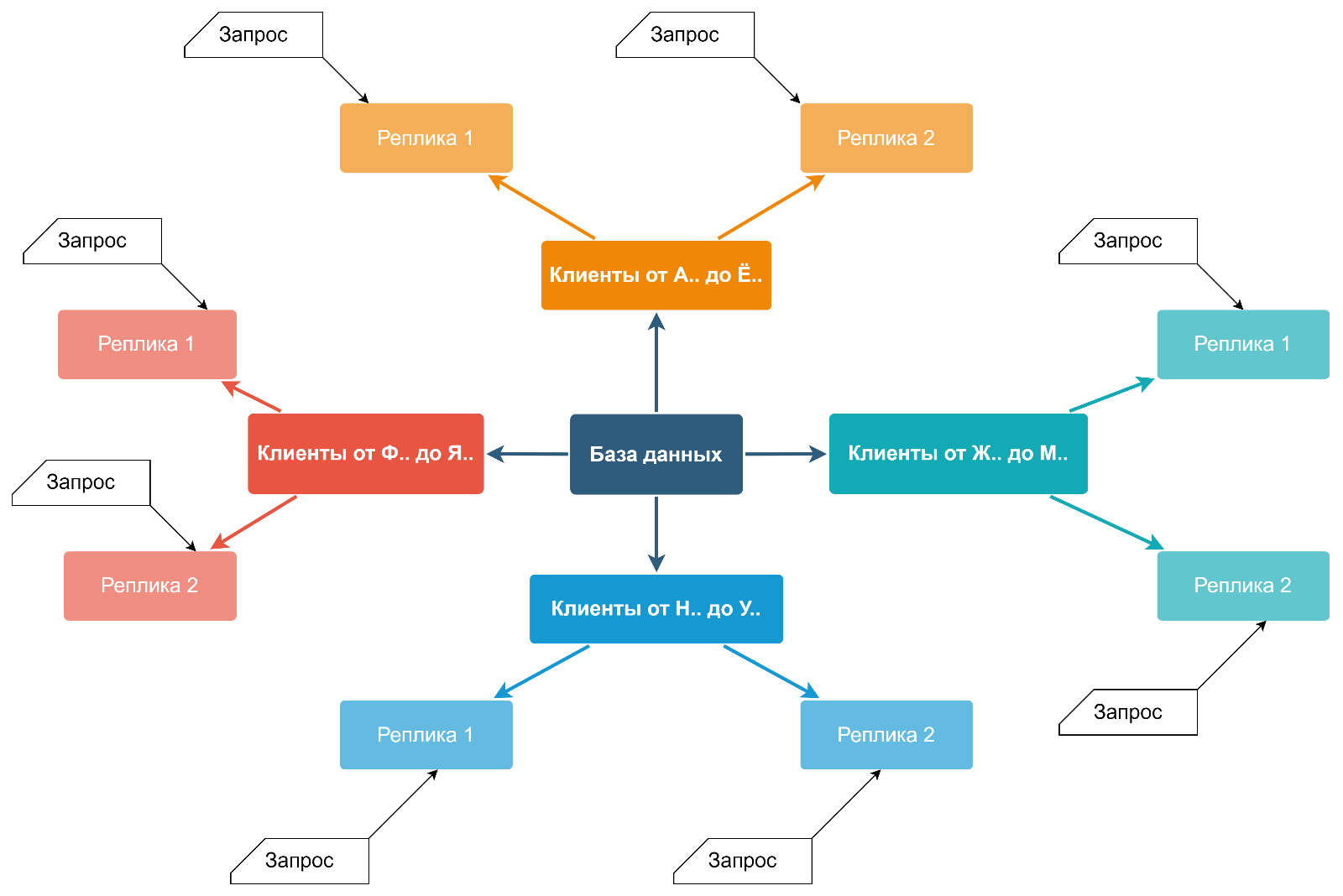
Но и это ещё не все преимущества шардирования приложений. В Сбере принята методология CI/CD. Команды постоянно занимаются доработкой существующего ПО и внедрением нового функционала. Частью этой работы является канареечное тестирование и green-blue развёртывание — постепенный перевод пром-клиентов на новый сервис.
Application Sharding обеспечивает поддержку постепенного развёртывания. Для этого создаётся отдельная шарда с новым релизом обработчика и репликой реальных данных. При green-blue развёртывании трафик постепенно перенаправляется на новый релиз. При канареечном тестировании часть данных, определяемая стратегией балансировки, уходит на шарду с новой версией.
Что за стратегия балансировки
Для перенаправления и балансировки запросов по узлам нужен маршрутизатор. Именно к нему обращается приложение при выполнении запроса к обработчику. Маршрутизатор указывает, на какой узел идти за данными. В нём также хранится информация о стратегиях поиска информации в дереве топологий для балансировки.
Маршрутизатор ищет подходящий маршрут с учетом входных параметров запроса, стратегий маршрутизации и топологии узлов сервисов. Следит, чтобы клиент, получивший данные через некоторый узел, по возможности направлял данные и получал ответы от него же. Это предотвращает неконтролируемый рост нагрузки на множество разных узлов.
В Platfrom V Synapse Application Sharding входит компонент, реализующий функцию такого маршрутизатора — Application Router. Он не создаёт шарды самостоятельно, а работает уже описанными. А так одна из основных функций Application Router — балансировка нагрузки, то ее способ определятся стратегией узла. Стратегия может задаваться через пользовательский интерфейс или импортироваться из конфигурации в файле.
В Сбере с его сотней фабрик и множеством бизнес‑приложений, узлов просто огромное количество, для их описания существует иерархическая структура — дерево топологии. Оно строится посредством Kubernetes Operator либо создаётся в графическом интерфейсе пользователя.
Вот как это выглядит:
Верхний уровень — сегмент — тип потребителя информации. Например, сегмент «Сотрудник».
Второй уровень — сектор — тип функциональной подсистемы, которая может обработать тот или иной запрос. Сюда входит бизнес‑логика и различные продукты Platform V, которые её поддерживают — СУБД, брокеры сообщений или что‑то другое.
Третий уровень — контур — тип среды исполнения. Чаще всего — это конкретная сервисная сеть (service mesh) на кластере Kubernetes, которая обеспечивает промышленную обработку, green‑blue развёртывание или тестирование.
Четвёртый уровень — узлы, обеспечивающие избыточность хранения информации и параллелизм обработки запросов.
Пример адреса в топологии — «employers.session.sandbox.dc1». Этому адресу в соответствие может быть подставлен конкретный URL.
Кроме иерархии, маршрутизация может производиться исходя из канала обслуживания клиента, по которому пришёл запрос. Например, мобильным пользователям могут предоставляться для обработки запросов не те узлы, по которым обрабатываются офисные. Это обеспечивает стабильность работы в офисе, даже если все мобильные пользователи одновременно зайдут в систему.
С учётом приведенной выше иерархии Application Router участвует в обработке запроса так. Пользователь входит на своём устройстве в приложение Сбера. Запрос через шлюзы и другие инфраструктурные компоненты Synapse попадает в Application Router, который предоставляет для обработки адрес узла в иерархии, исходя из:
сегмента пользовательского приложения;
сектора банковского приложения, обслуживающего запрос этого типа;
рабочего контура;
доступных реплик;
канала обслуживания клиента, через который зашёл пользователь;
политики безопасности;
стратегии маршрутизации (балансировки).
Благодаря усложнению правил балансировки, соответствующим описанием правил маршрутизации можно добиться того, что клиент получит доступ к узлу, максимально подходящему по критериям пользователю. Например, наиболее близкому к пользователю географически. То есть, снизится задержка между запросом и ответом, и будет задействовано минимальное число каналов передачи данных.
Чтобы предоставлять такой маршрут максимально быстро, Application Router имеет две части.
Первая часть – высокопроизводительная – написана на Rust, реализует функциональный шардинг или шардинг диапазонами.
Почему именно Rust
Rust выбран не случайно: маршрутизатор приложений, разработанный по принципу обратного прокси, является узким местом, и должен обрабатывать входящие запросы максимально быстро. Если клиент запрашивает маршрут к узлу с использованием относительно простых правил шардирования, ответ так же возвращается максимально быстро.
Раньше такие задачи чаще всего решались с помощью C++. Но «плюсы» известны тем, что ими легко «выстрелить себе в ногу». Нужно внимательно следить за выделением и освобождением ресурсов, много неочевидных вещей. Поэтому в качестве альтернативы С++ мы выбрали Rust, который, ко всему прочему, поддерживается при разработке ядра Linux.
Вторая часть реализует параметрический шардинг, предоставляя более сложную логику выбора.
Про табличный шардинг и решардирование
В Application Sharding также входит компонент межкластерной индексации, применяющий СУБД Pangolin. Компонент используется для реализации табличного шардинга. Одна из инсталляций уже содержит почти миллиард записей по различным ключам шардирования.
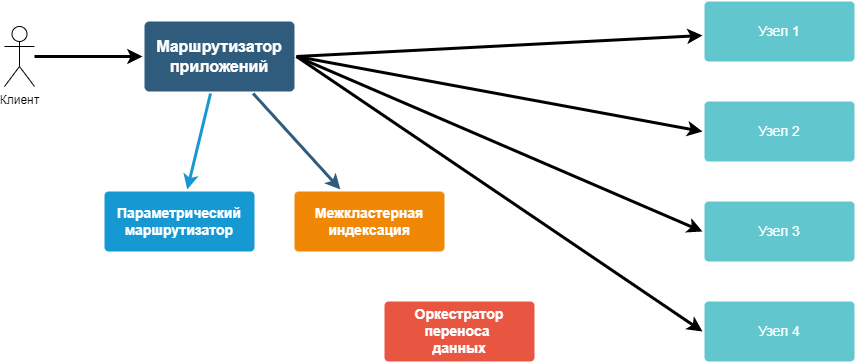
Ещё одна ключевая функция продукта — решардирование. Её реализует компонент оркестрации переноса данных Data Transfer Orchestrator. Он управляет переносом данных между шардами одного приложения. Состоит из приложений:
«Мастер» — центральное хранилище состояний процессов в рамках переноса данных между шардами. Обеспечивает контроль обработки переноса;
«Агент» — непосредственный исполнитель заранее описанного процесса переноса.
Куда идем дальше и над чем работаем
На финишной прямой разработки – полностью новый релиз Application Router, написанный на языках Go и Rust. В нём поддержаны многие классические методы шардирования данных:
шардинг по консистентным хэшам;
параметрический шардинг;
шардинг диапазонами;
функциональный шардинг;
табличный шардинг единичными ключами и диапазонами.
Про выбор языка Rust в новом релизе мы писали выше — это оптимальная замена C++ без присущих «плюсам» минусов с выделением ресурсов.
Go выбрали как альтернативу Java — и вот почему. Java для работы нужна Java Virtual Machine, «съедающая» время при запуске в контейнере. А нам нужно приложение в исполняемом процессором коде с малым временем запуска и небольшими расходами на runtime. Go, для которого есть множество библиотек на все случаи жизни, отлично подходит.
В новом релизе будут поддержаны вызовы не только REST, но и gRPC. А еще топология «N-ЦОД», в которой ЦОДы являются логическими сущностями, связанными с физическими. Это позволит автоматически распределять реплики по разным физическим центрам обработки данных.
В конечном итоге планируем прийти к тому, что при минимальной избыточности оборудования потеря одного ЦОДа не будет заметна пользователям. Репликация на уровне СУБД не понадобится — ее будет осуществлять Application Router. Причём речь идёт о репликации больше чем на два ЦОДа в разных регионах.
Для ускорения выдачи маршрута к шарде в новом релизе будет реализована трёхуровневая модель анализа запроса. Высокоскоростная часть, написанная на Rust, и представляющая собой обратный прокси, принимает запросы и маршрутизирует их по простым правилам – диапазонам или функционально. Если используется параметрический шардинг, то анализ опускается на второй слой. В случае табличного шардинга вызывается третий слой межкластерной индексации.
Как итог, релиз дополнит функциональность продукта, который сегодня может стать надежной заменой зарубежным решениям. Platform V Application Sharding включен в РРПО и может быть интегрирован в ЗОКИИ. Кроме того, продукт позволит снизить затраты на серверы для избыточного хранения за счёт внедрения стратегии трёх ЦОДов, один из которых избыточен.
Архитектура N-ЦОД подразумевает такое разделение данным между небольшими ЦОДами, что потеря одного любого из них не приведёт к потере данных. Выигрыш о оборудовании достигается при распределении данных по более, чем двум ЦОДам. Если центров два, то в резерве работает 50% оборудования. Если данные распределены по четырём ЦОДам, то в резерве работает всего 25% оборудования. Алгоритмы работы с данными усложняются, но процент избыточности серверов уменьшается.
Заключение
В этой статье были описаны возможности продукта Platform V Application Sharding, заложенные в нём идеи, которые позволяют распределить большие объёмы информации по различным хостам сети, поддерживать высокую доступность данных и при этом максимально упростить администрирование структуры хранения.


SSukharev
Хеш функция для шардироаания? Дальше можно не читать. Если у вас данные рамазаны по нодам и нужен джойн с другими размазанными данными в десятках таблиц то, что будет, если данные у вас разложились как придётся по хеш функции?
kostyaBro
Вам просто надо выбрать правильный ключ который вы будете подавать в эту функцию, такой что-бы данные с разными ключами вряд-ли взаимодействовали бы друг с другом.
SSukharev
Ага, а хеш ключ в этой конструкции видимо нужен просто для того, что бы был.
mishamota
А что значит "вряд ли"?
Банальный пример: таблицы клиентов, поставщиков, договоров. Договоры ссылаются на две другие таблицы. Запрос - получить всех контграгентов (клиентов и поставщиков) по диапазону договоров. Собственно, "правильный ключ" (чтобы без дублирования и в одном шарде всё) тут не подобрать, как ни хэшируй.
Описанное в статье - частное решение для древовидных структур (агрегатов), которые можно от корня делить по шардам. Общая задача же, как правило, шире.