
Эта статья посвящена программе Hello World, написанной на C. Это максимальный уровень, на который можно добраться с языком высокого уровня, не беспокоясь при этом о том, что конкретно язык делает в интерпретаторе/компиляторе/JIT перед выполнением программы.
Изначально я хотел написать статью так, чтобы она была понятна любому, умеющему кодить, но теперь думаю, что читателю полезно иметь хотя бы некоторые знания по C или ассемблеру.
▍ Начало
Всем знакома программа Hello World. На Python самой первой программой обычно бывает такая:
print('Hello World!')Она просто выводит на экран текст «Hello World!».
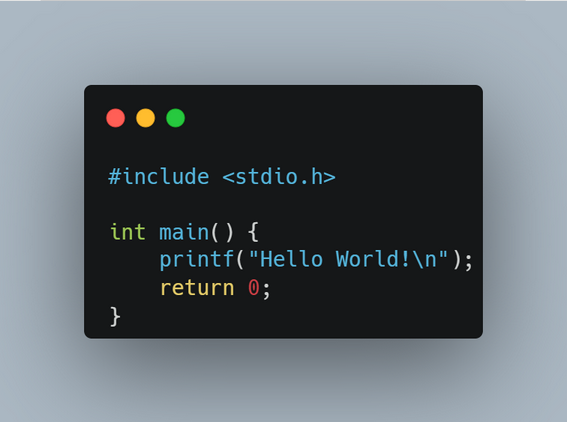
В этой статье мы рассмотрим Hello World на языке программирования C. Она имеет следующий вид:
#include <stdio.h>
int main() {
printf("Hello World!\n");
return 0;
}Эта программа делает ровно то же самое, что и программа на Python. Но в отличие от Python, здесь нельзя просто вызвать интерпретатор для запуска программы. Необходимо сначала запустить компилятор, чтобы преобразовать этот код в машинный код, который непосредственно сможет выполнять процессор компьютера. Все современные большие и важные программы пишутся таким образом.
Чтобы выполнить преобразование, необходима следующая команда:
gcc hello.c -o helloОна берёт код на C из файла
hello.c и генерирует программу на машинном языке в файле hello. Затем мы можем выполнить её при помощи такой команды:./helloИ получить результат:
Hello World!Отлично.
▍ Наша программа
Хорошо, но как мы этого добились? Во-первых, стоит взглянуть на программу. Из чего же она состоит?
$ file hello
hello: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=b74da2c9c77d221eeaa98f87f4a7a529782db280, for GNU/Linux 3.2.0, not strippedПо большей мере эта информация для нас не важна или пока не важна. Самое важное — это:
ELF executable, x86-64
Эта строка сообщает нам, что программа — это исполняемый файл ELF для архитектуры набора команд x86_64. Что это значит?
Исполняемый файл ELF — это эквивалент файла Windows
.exe, только для Linux. Это просто программа, которую может выполнять компьютер. Но это мы и так знали. Вторая часть сообщает нам, что это программа в машинном коде, которая должна выполняться в 64-битном процессоре x86, то есть в архитектуре CPU, использующейся в PC с момента появления IBM PC в 1981 году. Стоит отметить, что тогда процессоры не были 64-битными, но современные процессоры по-прежнему могут исполнять код, написанный для IBM PC (в определённой степени). Но мы отклонились от темы.То есть в этом файле находится машинный код — своего рода язык, и это единственный язык, который может понимать CPU. Где же CPU начинает выполнять его код?
$ readelf -h hello
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 13976 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30Самое важное здесь — это
Entry point address:, имеющее значение 0x1060. Это шестнадцатеричное число, указывающее местоположение в нашей программе или после её загрузки в памяти компьютера. Что же там находится?▍ Код
$ objdump -D helloЯ не буду приводить здесь полностью результат выполнения этой команды, потому что он слишком длинный. Но если просмотреть его, мы рано или поздно найдём несколько строк текста, в котором первая строка начинается с
1060:Disassembly of section .text:
0000000000001060 <_start>:
1060: f3 0f 1e fa endbr64
1064: 31 ed xor %ebp,%ebp
1066: 49 89 d1 mov %rdx,%r9
1069: 5e pop %rsi
106a: 48 89 e2 mov %rsp,%rdx
106d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
1071: 50 push %rax
1072: 54 push %rsp
1073: 45 31 c0 xor %r8d,%r8d
1076: 31 c9 xor %ecx,%ecx
1078: 48 8d 3d ca 00 00 00 lea 0xca(%rip),%rdi # 1149 <main>
107f: ff 15 53 2f 00 00 call *0x2f53(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>
1085: f4 hlt
1086: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)
108d: 00 00 00Что это значит? Первые числа перед двоеточиями — это адреса следующих за ними байтов, по сути, их позиция в файле. Следующие числа — это байты данных в файле программы, которые в данном случае обозначают машинный код. Последующий текст — это дизассемблированная версия этого кода. Язык ассемблера — это человекочитаемое представление машинного кода. Стоит отметить, что если байты слева не обозначают код, то дизассемблер всё равно попытается их дизассемблировать. Это приводит к появлению мусора и бессмысленного ассемблерного кода.
Итак, мы нашли некий код! Но это не код, который мы писали. Он автоматически добавлен в нашу программу компилятором (строго говоря, компоновщиком). По сути, этот код проводит инициализацию, а затем выполняет важную команду:
call *0x2f53(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>Эта команда приказывает компьютеру выполнить код где-то в другом месте, в данном случае — по адресу
0x2f53, который меняется на адрес 0x3fd8, когда нашу программу загружает динамический компоновщик. Здесь я не буду вдаваться в подробности.Но как бы вы ни искали, вы не найдёте ни одного из этих адресов в нашем файле. Строго говоря,
0x3fd8 находится в глобальной таблице смещений (эта тема тоже выходит за рамки статьи), но пока он пуст, поэтому что этот код определяется не в нашей программе, а в другом месте.▍ Библиотека C
Так где же он?
$ readelf -d hello
Dynamic section at offset 0x2dc8 contains 27 entries:
Tag Type Name/Value
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
0x000000000000000c (INIT) 0x1000
0x000000000000000d (FINI) 0x1168
0x0000000000000019 (INIT_ARRAY) 0x3db8
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
0x000000000000001a (FINI_ARRAY) 0x3dc0
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
0x000000006ffffef5 (GNU_HASH) 0x3b0
0x0000000000000005 (STRTAB) 0x480
0x0000000000000006 (SYMTAB) 0x3d8
0x000000000000000a (STRSZ) 141 (bytes)
0x000000000000000b (SYMENT) 24 (bytes)
0x0000000000000015 (DEBUG) 0x0
0x0000000000000003 (PLTGOT) 0x3fb8
0x0000000000000002 (PLTRELSZ) 24 (bytes)
0x0000000000000014 (PLTREL) RELA
0x0000000000000017 (JMPREL) 0x610
0x0000000000000007 (RELA) 0x550
0x0000000000000008 (RELASZ) 192 (bytes)
0x0000000000000009 (RELAENT) 24 (bytes)
0x000000000000001e (FLAGS) BIND_NOW
0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
0x000000006ffffffe (VERNEED) 0x520
0x000000006fffffff (VERNEEDNUM) 1
0x000000006ffffff0 (VERSYM) 0x50e
0x000000006ffffff9 (RELACOUNT) 3
0x0000000000000000 (NULL) 0x0Это, среди прочего, список библиотек, используемых нашим кодом. В данном случае мы видим строку
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]Это стандартная библиотека C нашей системы — сборник процедур и функций, используемых практически всеми программами на нашем компьютере. В мире Windows аналогом этого является среда исполнения C,
msvcrt.dll или ucrt<что-то>.dll. Стоит здесь отметить, что в Linux файлы с расширением .so (Shared Object) эквивалентны файлам в Windows с расширением .dll (Dynamically Linked Library). Они содержат код, который может использовать множество различных программ.Поэтому мы снова можем применить
objdump, чтобы найти местонахождение этого кода в нашей библиотеке C и понять его предназначение; однако библиотека C огромна и сложна, а мы даже ещё не добрались до кода, который написали сами. Так что не буду вас мучить и просто скажу, что этот код выполняет инициализацию, например, получает параметры командной строки и переменные окружения нашей программы, а затем вызывает нашу функцию main(). Далее, когда мы выполняем возврат из main(), он производит выход из нашей программы с указанным нами кодом состояния.Так где же находится наша функция
main?▍ main()
Разумеется, в нашей программе. Вернувшись к дизассемблированному коду, мы увидим:
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: 48 89 c7 mov %rax,%rdi
115b: e8 f0 fe ff ff call 1050 <puts@plt>
1160: b8 00 00 00 00 mov $0x0,%eax
1165: 5d pop %rbp
1166: c3 retНаконец-то, наш код! Но что же он делает? Он:
- Подготавливает фрейм стека.
- Настраивает аргументы для вызова нашей функции.
- Вызывает Hello World.
- Очищает фрейм стека.
- Выполняет возврат из функции с кодом выхода 0.
Это то, что мы видим в исходном коде. Но что такое фрейм стека? Это часть памяти компьютера, которую наша программа использует для хранения локальных переменных, то есть переменных, объявленных внутри нашей функции
main. К счастью, мы не объявляем никаких переменных, поэтому беспокоиться об этом нам не нужно. Самое важное здесь:lea 0xeac(%rip),%rax
call 1050 <puts@plt>Эти команды:
- Задают адрес памяти нашей строки Hello World в качестве первого аргумента вызова нашей функции (косвенно).
- Вызывают функцию
puts().
Постойте, а что такое
puts()? Разве мы вызывали не printf()?Да. Однако компилятор выполнил оптимизацию. Функция printf сложна, потому что она может выводить «форматированный вывод», то есть мы можем помещать в вывод переменные. Функция выполняет преобразование их в строки и вывод этих строк, но ничего этого нам не нужно. Поэтому компилятор заменяет
printf() гораздо более простой функцией puts(), которая просто выводит строку неотформатированного текста. А где же наш текст?▍ Строка
Согласно дизассемблеру, она находится по адресу
0x0eac, который при загрузке преобразуется в адрес 0x2004. Как это выглядит?Disassembly of section .rodata:
0000000000002000 <_IO_stdin_used>:
2000: 01 00 add %eax,(%rax)
2002: 02 00 add (%rax),%al
2004: 48 rex.W
2005: 65 6c gs insb (%dx),%es:(%rdi)
2007: 6c insb (%dx),%es:(%rdi)
2008: 6f outsl %ds:(%rsi),(%dx)
2009: 20 57 6f and %dl,0x6f(%rdi)
200c: 72 6c jb 207a <__GNU_EH_FRAME_HDR+0x66>
200e: 64 21 00 and %eax,%fs:(%rax)Помните, выше я говорил, что дизассемблер пытается дизассемблировать код, даже если это не код? Вот хороший пример этого. Можете не обращать внимания на ассемблерный код, это полная бессмыслица. Но если посмотреть на адрес
0x2004, мы увидим шестнадцатеричные байты 48 65 6c 6c 6f 20 57 6f 72 6c 64 21 00, преобразуемые в строку «Hello World!», за которыми идёт завершающий нулевой символ.Но разве в нашей строке нет символа переноса строки
\n, который должен преобразоваться в ASCII-код 0x0a? Да, но это ещё один артефакт оптимизации компилятора. Функция puts() выводит строку с конечным символом переноса строки, а printf() этого не делает. Поэтому компилятор удаляет наш перенос строки, и в выводе остаётся только один.Далее мы видим нулевой байт
0x00. Он называется завершающим нулевым символом (NULL terminator) и встречается в конце всех строк C. В языке C у строк нет никакой информации о длине, так что функция, получающая в качестве аргумента строку любой длины, обрабатывает её по байту за раз, пока не встретит NULL terminator. Если бы в памяти было несколько строк без NULL terminator между ними, то функции C обрабатывали бы все строки вместе. Постепенно функции дошли бы до конца и начали считывать память, которую им не разрешено считывать, а программа вылетела бы с пугающим сообщением «Segmentation Fault».▍ Отслеживаем puts()
Итак, puts() расположена в
0x1050.Disassembly of section .plt.sec:
0000000000001050 <puts@plt>:
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmp *0x2f75(%rip) # 3fd0 <puts@GLIBC_2.2.5>
105b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)Теперь она выполняет обратный вызов в стандартной библиотеке (строго говоря, в глобальной таблице смещений, но в конечном итоге в стандартной библиотеке).
Мы не хотим читать дизассемблированный код стандартной библиотеки, но, к счастью, Glibc (наша стандартная библиотека C) имеет открытые исходники. Что же мы таким образом получим?
Псевдонимом puts() в стандартной библиотеке является _IO_puts.
int
_IO_puts (const char *str)
{
int result = EOF;
size_t len = strlen (str);
_IO_acquire_lock (stdout);
if ((_IO_vtable_offset (stdout) != 0
|| _IO_fwide (stdout, -1) == -1)
&& _IO_sputn (stdout, str, len) == len
&& _IO_putc_unlocked ('\n', stdout) != EOF)
result = MIN (INT_MAX, len + 1);
_IO_release_lock (stdout);
return result;
}То есть эта функция получает длину строки, создаёт блокировку потока вывода, выполняет проверки и вызывает _IO_sputn. Затем она отключает блокировку и возвращает количество выведенных символов.
Я поискал эту функцию, но не смог её найти. Очевидно, она выполняет какую-то работу через функцию _IO_file_jumps и вызывает calls _IO_new_file_xsputn.
size_t
_IO_new_file_xsputn (FILE *f, const void *data, size_t n)
{
const char *s = (const char *) data;
size_t to_do = n;
int must_flush = 0;
size_t count = 0;
if (n <= 0)
return 0;
/* This is an optimized implementation.
If the amount to be written straddles a block boundary
(or the filebuf is unbuffered), use sys_write directly. */
/* First figure out how much space is available in the buffer. */
if ((f->_flags & _IO_LINE_BUF) && (f->_flags & _IO_CURRENTLY_PUTTING))
{
count = f->_IO_buf_end - f->_IO_write_ptr;
if (count >= n)
{
const char *p;
for (p = s + n; p > s; )
{
if (*--p == '\n')
{
count = p - s + 1;
must_flush = 1;
break;
}
}
}
}
else if (f->_IO_write_end > f->_IO_write_ptr)
count = f->_IO_write_end - f->_IO_write_ptr; /* Space available. */
/* Then fill the buffer. */
if (count > 0)
{
if (count > to_do)
count = to_do;
f->_IO_write_ptr = __mempcpy (f->_IO_write_ptr, s, count);
s += count;
to_do -= count;
}
if (to_do + must_flush > 0)
{
size_t block_size, do_write;
/* Next flush the (full) buffer. */
if (_IO_OVERFLOW (f, EOF) == EOF)
/* If nothing else has to be written we must not signal the
caller that everything has been written. */
return to_do == 0 ? EOF : n - to_do;
/* Try to maintain alignment: write a whole number of blocks. */
block_size = f->_IO_buf_end - f->_IO_buf_base;
do_write = to_do - (block_size >= 128 ? to_do % block_size : 0);
if (do_write)
{
count = new_do_write (f, s, do_write);
to_do -= count;
if (count < do_write)
return n - to_do;
}
/* Now write out the remainder. Normally, this will fit in the
buffer, but it's somewhat messier for line-buffered files,
so we let _IO_default_xsputn handle the general case. */
if (to_do)
to_do -= _IO_default_xsputn (f, s+do_write, to_do);
}
return n - to_do;
}Ого. И всё это ради одного Hello World. Я не буду пробовать разобраться, как работает этот код, даже с комментариями. На этом моменте я понял, что использовать Glibc, чтобы объяснить происходящее, будет очень мучительно. Поэтому я решил изучить libc musl, которая, как я знаю, должна быть меньше.
▍ musl
В musl функция puts() определена следующим образом:
int puts(const char *s)
{
int r;
FLOCK(stdout);
r = -(fputs(s, stdout) < 0 || putc_unlocked('\n', stdout) < 0);
FUNLOCK(stdout);
return r;
}То есть она получает блокировку для потока вывода, вызывает fputs и разблокирует поток вывода.
Как определена fputs()?
#include "stdio_impl.h"
#include <string.h>
int fputs(const char *restrict s, FILE *restrict f)
{
size_t l = strlen(s);
return (fwrite(s, 1, l, f)==l) - 1;
}Она получает длину нашей строки и вызывает fwrite() с потоком вывода, нашей строкой и её длиной.
Как определена fwrite()?
size_t fwrite(const void *restrict src, size_t size, size_t nmemb, FILE *restrict f)
{
size_t k, l = size*nmemb;
if (!size) nmemb = 0;
FLOCK(f);
k = __fwritex(src, l, f);
FUNLOCK(f);
return k==l ? nmemb : k/size;
}Она получает ещё одну блокировку потока вывода, вызывает __fwritex() и разблокирует поток вывода.
Как определена __fwritex()?
size_t __fwritex(const unsigned char *restrict s, size_t l, FILE *restrict f)
{
size_t i=0;
if (!f->wend && __towrite(f)) return 0;
if (l > f->wend - f->wpos) return f->write(f, s, l);
if (f->lbf >= 0) {
/* Match /^(.*\n|)/ */
for (i=l; i && s[i-1] != '\n'; i--);
if (i) {
size_t n = f->write(f, s, i);
if (n < i) return n;
s += i;
l -= i;
}
}
memcpy(f->wpos, s, l);
f->wpos += l;
return l+i;
}Код довольно большой, но основное в нём то, что он вызывает write() для объекта FILE потока вывода. Наш поток определён как stdout, так где же он определяется?
hidden FILE __stdout_FILE = {
.buf = buf+UNGET,
.buf_size = sizeof buf-UNGET,
.fd = 1,
.flags = F_PERM | F_NORD,
.lbf = '\n',
.write = __stdout_write,
.seek = __stdio_seek,
.close = __stdio_close,
.lock = -1,
};То есть функция write определена как __stdout_write(). Как она определяется?
size_t __stdout_write(FILE *f, const unsigned char *buf, size_t len)
{
struct winsize wsz;
f->write = __stdio_write;
if (!(f->flags & F_SVB) && __syscall(SYS_ioctl, f->fd, TIOCGWINSZ, &wsz))
f->lbf = -1;
return __stdio_write(f, buf, len);
}Она получает TIOCGWINSZ ioctl потока вывода и вызывает функцию __stdio_write(). Как она определена?
size_t __stdio_write(FILE *f, const unsigned char *buf, size_t len)
{
struct iovec iovs[2] = {
{ .iov_base = f->wbase, .iov_len = f->wpos-f->wbase },
{ .iov_base = (void *)buf, .iov_len = len }
};
struct iovec *iov = iovs;
size_t rem = iov[0].iov_len + iov[1].iov_len;
int iovcnt = 2;
ssize_t cnt;
for (;;) {
cnt = syscall(SYS_writev, f->fd, iov, iovcnt);
if (cnt == rem) {
f->wend = f->buf + f->buf_size;
f->wpos = f->wbase = f->buf;
return len;
}
if (cnt < 0) {
f->wpos = f->wbase = f->wend = 0;
f->flags |= F_ERR;
return iovcnt == 2 ? 0 : len-iov[0].iov_len;
}
rem -= cnt;
if (cnt > iov[0].iov_len) {
cnt -= iov[0].iov_len;
iov++; iovcnt--;
}
iov[0].iov_base = (char *)iov[0].iov_base + cnt;
iov[0].iov_len -= cnt;
}
}Мы почти добрались до конца. Она выполняет много действий, но вызывает syscall() с SYS_writev в качестве первого параметра. Как же определена syscall()?
long syscall(long n, ...)
{
va_list ap;
syscall_arg_t a,b,c,d,e,f;
va_start(ap, n);
a=va_arg(ap, syscall_arg_t);
b=va_arg(ap, syscall_arg_t);
c=va_arg(ap, syscall_arg_t);
d=va_arg(ap, syscall_arg_t);
e=va_arg(ap, syscall_arg_t);
f=va_arg(ap, syscall_arg_t);
va_end(ap);
return __syscall_ret(__syscall(n,a,b,c,d,e,f));
}syscall() получает в качестве первого аргумента номер системного вызова и переменное количество дополнительных аргументов. Вызовы va_arg() считывают эти аргументы в переменные a, b, c, d, e и f. Затем мы вызываем __syscall() с этими аргументами, после чего результат отправляется в __syscall_ret().
К сожалению, мне не удалось найти определение __syscall(). Но мне кажется, это вызвано тем, что мы зашли на территорию, относящуюся к конкретной платформе. Musl — это многоархитектурная библиотека C, поэтому дальше выполняемый код зависит от используемой нами архитектуры. Прежде чем углубляться в изучение, я рассмотрел __syscall_ret():
long __syscall_ret(unsigned long r)
{
if (r > -4096UL) {
errno = -r;
return -1;
}
return r;
}Эта функция просто проверяет валидность возвращаемого __syscall() значения; если оно невалидно, то системный вызов завершился неудачно, поэтому она возвращает -1.
▍ Системные вызовы
Итак, в последних нескольких этапах вызова Hello World задействованы системные вызовы. Что такое системный вызов? Как бы ни была велика библиотека C, некоторые вещи она ни за что не выполнит. Одна из таких вещей — общение с оборудованием. Эта способность оставлена для ядра — части операционной системы, управляющей доступом к устройствам ввода-вывода, памяти и времени CPU. В нашем случае это ядро Linux. В мире Windows это
ntoskrnl.exe, которое отображается в Диспетчере задач как System.Это значит, что в конечном итоге наш вызов puts() должен попросить операционную систему выполнить для нас некие действия. В данном случае мы просим операционную систему записать какой-то текст в поток вывода. Запись в поток выполняется при помощи системного вызова
write. В Musl используется схожий системный вызов writev, способный записывать несколько буферов в массив. Давайте изучим, как musl выполняет системные вызовы.static __inline long __syscall0(long n)
{
unsigned long ret;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n) : "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall1(long n, long a1)
{
unsigned long ret;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1) : "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall2(long n, long a1, long a2)
{
unsigned long ret;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1), "S"(a2)
: "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall3(long n, long a1, long a2, long a3)
{
unsigned long ret;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1), "S"(a2),
"d"(a3) : "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall4(long n, long a1, long a2, long a3, long a4)
{
unsigned long ret;
register long r10 __asm__("r10") = a4;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1), "S"(a2),
"d"(a3), "r"(r10): "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall5(long n, long a1, long a2, long a3, long a4, long a5)
{
unsigned long ret;
register long r10 __asm__("r10") = a4;
register long r8 __asm__("r8") = a5;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1), "S"(a2),
"d"(a3), "r"(r10), "r"(r8) : "rcx", "r11", "memory");
return ret;
}
static __inline long __syscall6(long n, long a1, long a2, long a3, long a4, long a5, long a6)
{
unsigned long ret;
register long r10 __asm__("r10") = a4;
register long r8 __asm__("r8") = a5;
register long r9 __asm__("r9") = a6;
__asm__ __volatile__ ("syscall" : "=a"(ret) : "a"(n), "D"(a1), "S"(a2),
"d"(a3), "r"(r10), "r"(r8), "r"(r9) : "rcx", "r11", "memory");
return ret;
}Мы добрались до самого дна. Эти семь функций musl использует для выполнения системных вызовов на платформе x86_64. Каждая из них получает своё количество аргументов для системного вызова.
У каждой из функций есть директива __asm__. Она встраивает ассемблерный код в вывод машинного языка компилятора. Мы выполняем системные вызовы к операционной системе, задавая в отдельных регистрах CPU свои параметры и исполняя команду
syscall. Затем управление передаётся ядру, которое считывает наши параметры и исполняет системный вызов.▍ Ядро
Далее ядро Linux должно выполнить действие, запрошенное системным вызовом. Системный вызов
write просит ядро открыть файл opened в файловой системе или записать его в поток, что мы и делаем в том случае.Системный вызов
write получает три параметра: дескриптор файла, в который нужно выполнять запись, записываемый буфер и количество записываемых байтов. Действие системного вызова writev библиотеки musl отличается, но пока давайте рассмотрим write.Куда же конкретно мы выполняем запись?
$ ps
PID TTY TIME CMD
15705 pts/0 00:00:00 bash
23332 pts/0 00:00:00 ps
$ cd /proc/15705/fd
$ readlink 1
/dev/pts/0Это зависит от ситуации.
В данном случае я выполняю программу
hello в эмуляторе терминала GNOME (это графическое приложение). Для ядра он выглядит как псевдотерминал (pty). Поэтому ядро сохраняет сообщение Hello World в буфер, а при выполнении программы эмулятора терминала она считывает и отображает его.Разумеется, мы ещё не закончили. Затем эмулятор терминала должен отрендерить текст во фрейм (потенциально использовав для этого GPU), отправить этот фрейм в X server/compositor, который комбинирует его с остальными запущенными приложениями (тоже использующими GPU), например, с текстовым редактором, в котором я пишу эту статью, а затем отправляет его снова в ядро, которое его отображает.
Ух! Я многое опустил, потому что это не имеет особого значения и в вашей системе может выглядеть совершенно иначе. Допустим, вы можете быть подключены удалённо, в таком случае ядро отправляет текст на
sshd, который затем отправляет его (в зашифрованном виде) обратно в ядро в пакете, который должен быть передан через Интернет. Или же вы можете использовать физический терминал, подключённый к адаптеру serial-to-USB. Тогда ядро должно поместить текст в пакет USB и передать его дальше. Вы также можете использовать консоль буфера кадров, это стандартный способ взаимодействия с ОС, если не установлен GUI. В этом случае ядро должно отрендерить текст в фрейме и вывести его на дисплей.Я имею в виду, что дальше может произойти что угодно, и нам это не важно. Отправляемое сообщение Hello World — это всего лишь системный вызов от одной программы, один из миллионов системных вызовов от тысяч программ, запущенных в данный момент на вашем компьютере.
▍ Заключение
Итак, современные программные системы на современном оборудовании настолько сложны и запутанны, что не имеет никакого смысла пытаться полностью разобраться в одной крошечной операции, выполняемой компьютером. Очевидно, что мне пришлось многое опустить. Я не рассмотрел пограничные случаи, дополнительную информацию и другие операции, выполняемые компьютером. Я не объяснил, как работает ядро. Всё это могут объяснить другие люди, а вы можете изучить в своё свободное время.
Если вы прочитали всю статью целиком, спасибо.
— Так как же на самом деле работает программа Hello World?
— Лучше не спрашивайте.
Telegram-канал со скидками, розыгрышами призов и новостями IT ?

Комментарии (38)

kozlov_de
17.04.2024 13:20+13нда...
такая анатомия это не привлекательные наружные половые органы
это кишки и кости, разбросанные по операционному столу

redfox0
17.04.2024 13:20+5Вот-вот. Было ожидание прочитать про crt0, про отличие Position-Independent Executable file от более простого способа (и считающимся небезопасным из-за более простого взлома). Про секции бинарника - тоже ни слова.

leen_vl
17.04.2024 13:20+5Тем не менее, неплохо показано, что за простейшим принтфом стоит просто адова куча работы программистов всех времен и народов. И это автор еще не прошелся по железу.



vitaly_il1
17.04.2024 13:20Здорово, спасибо!
Кстати, насколько помню, в 80-е в RSX11 на PDP11 был двухступенчатый компилятор, которой на первом этапе выдавал ассемблерный код.

vanxant
17.04.2024 13:20+6на PC со времён TurboC есть ключики компилятора, которые будут выдавать ассемблерный код. В случае с
gccэто ключик-S(и ещё конечно можно и нужно отладочный-gи-fverbose=asm)

unreal_undead2
17.04.2024 13:20+1Ну так и сейчас тоже самое, попробуйте спрятать /usr/bin/as:
$ gcc hello.c
gcc: fatal error: cannot execute ‘as’: execvp: No such file or directory
compilation terminated.

MinimumLaw
17.04.2024 13:20+2Все хорошо. И в целом не новость. Едиственный вопрос, который меня всегда слегка заботит, это почему printf? Разве канонический HelloWorld на C не должен быть таким
#include <unistd.h> char msg[] = "Hello, world!\n"; int main(void) { write(STDOUT_FILENO, msg, sizeof(msg)); return 0; }P.S.
И не надо мне говорить, что результат, возвращаемый write в целом надо бы проверять. В исходном варианте возвращаемое printf тоже игнорируется.
unreal_undead2
17.04.2024 13:20+3У Кернигана/Ритчи printf.
MinimumLaw
17.04.2024 13:20+2Я не спорю с метрами. Я спрашиваю мнение общественности. Особенно той ее части, что работает преимущественно с языком С и спускается к ассемблеру по мере необходимости.
Тем более, что это далеко не идеал, если копнуть поглубже. Например const перед char в общем случае был бы весьма уместен.
unreal_undead2
17.04.2024 13:20+1Что может быть каноничнее K&R? Причем там даже так (во втором издании, которое типа под ANSI стандарт):
#include <stdio.h>
main()
{
printf("hello, world\n");
}
Никаких return и типов у main, какой уж там const...
MinimumLaw
17.04.2024 13:20+1Так, собственно, отсюда и вопрос... Дело ведь в том, что язык С изначально пытался занять очень много стульев сразу и претендовал на роль панацеи. Мы не будем тыкать в современные языки, которые ведут себя ровно так же - это проходит со временем. Вот и С довольно быстро разделился.
"Кроссплатформенный ассемблер с элементами структурного синтаксиса" (с) - это современный язык С. Все остальные его реинкарнации потихоньку сходят на нет, уступая место более удобным инструментам. И POSIX в таком варианте наше все. А это read/write, а еще atoi/atof и парные им ftoa/ftol.
"Переносимый между платформами язык С" - это безусловно K&R. В таком варианте безусловно printf/scanf, с соответствующими слоями абстракции. Ну и понятно, что в конце-концов именно "Переносимы С" обрел потомка виде С++ и сильно сдал свои позиции.
Вот отсюда и вопрос. Правда ли, что K&R с их "переносимым С" стоит сегодня рассматривать как канонический вариант использования языка. Да, безусловно, если еще комплект system-utils, sed, find, gawk и прочего прикладного софта нижнего уровня, который написан на таком С. Но все же, современный С это сильно больше язык загрузчиков, ядер операционных систем и драйверов. Другими словами тот самый "кроссплатформенный ассемблер". Или это у меня профдеформация и на самом деле все не так?

CodeRush
17.04.2024 13:20+1Я не думаю, что бывает какой-то "канонический вариант использования языка" в принципе, потому что С для прошивок и С для прикладных программ - очень разные языки, и тут в статье показан второй как раз. Первый при этом никуда не девается, и со вторым если и пересекается, то не очень сильно.
Буквально недавно объяснял интернам важность правильного указания выравнивания у структур и опасность добавления новых переменных в середину этих самых структур, являющихся частью XNU ABI, и понял, что первому языку не учат нигде, кроме как на работе, а с привычками, сформированными вторым, потом приходится бороться годами.
Или другой пример: Intel в свое время решили, что вместо стандартных memcpy и memset у них в EFI будут gBS->CopyMem и gBS->SetMem, а стандартной библиотеки не будет совсем. И все бы ничего, только вот компиляторы по стандарту языка С99 имею право заменять присваивания структурных переменных на вызов memcpy, и получается полная херня, когда тебе линкер сообщает, что линковать не будет, потому что у тебя нет memcpy, а у тебя в коде его и нет нигде, иди ищи присваивание, удачи.
MinimumLaw
17.04.2024 13:20первому языку не учат нигде, кроме как на работе, а с привычками, сформированными вторым, потом приходится бороться годами
Я вас категорически приветствую!
Да, черт возьми. Собственно по этой причине я и открыл эту ветку комментариев. С наивной надеждой хоть что-то поменять. Только вот... Конструктивный диалог получается разве что со старыми знакомыми. Понятно, что определение "канонический вариант" оно лукаво и не описывает суть проблемы. Но я не знаю как переформулировать более грамотно.
Радует, что понимание того, что язык С разный для разных задач есть не только у меня. Обидно, что нас крайне мало.
CodeRush
17.04.2024 13:20+1И я вас, Алексей.
Судя по почти сотне плюсов этой не очень хорошей, на мой взгляд, статье, в которой вроде бы препарировать начали, но как-то действительно раскидали все кишки по столу, а цельной картины не нарисовали, сейчас на Хабре существует запрос на обучающие статьи по языку "С для прошивок", и присутствуют несколько людей, способных такие статьи писать. Только вот статей не появляется, и приходится комментировать всякий переводной шлак.
Если вы хотите что-то реально поменять, пишите не комментарии, а статьи, такого же примерно формата. "Вот так выглядит Hello World для какой-нибудь умной пуговицы на 8051", или "пишем на С прошивку для самодельного паяльника Т12", или "какой-нибудь промышленный 1Ггц\16к осциллограф за миллиард управляется древним Intel Atom или AMD Geode LX, ковыряем установленную на нем Windows XP" и т.п.
Ничего нельзя сделать, задавая вопросы в комментариях, если мы хотим, чтобы молодежь училась и интересовалась, надо её учить и интересовать. Я тоже пойду учить и интересовать, когда уволюсь из корпорации. Мой бывший начальник Xeno Kovah уже так и сделал в 2020 году, и теперь делится знаниями на OpenSecurityTraining2, про который я тут в комментариях тоже без конца повторяю, как попугай.
MinimumLaw
17.04.2024 13:20Если вы хотите что-то реально поменять, пишите не комментарии, а статьи
Да, именно тут и есть замкнутый круг. Я могу рассказывать на работе молодому поколению. Как правило в режиме ответов на вопрос "что это было?", "а почему так нельзя?" или "а что так можно было"? Тогда появляются структурные и функциональные схемы железок, тогда появляются тайминги и прочие радости нашего уровня. Я честно пытался хоть из чего-то похожего сделать статью. Получается или слишком узко и нишево, или очередной пример такого вот варианта.
Ну или да... Ржут надо мной коллеги-схемотехники. Говорят ты за столько лет уже лекцию "радиоэлектроника для программистов" можешь снимать и на youutube выкладывать. Она и начинающим схемотехникам полезной окажется. За три поколения воспитанников отточил... Может правда как-нить заняться... Тогда может быть текстовая версия и здесь появится. Но пока есть интересная работа и тупо не до того... И это, пожалуй, самое главное.
Вообще получается парадоксальная ситуация - есть потребность в специалистах, но никто не знает как именно их готовить. Ибо инструмент один, а навык его использования оттачивается только в процессе работы. Я даже не знаю с чем бы сравнить... Ну, возможно, MIDI-клавиатура (синтезатор) в музыкальной студии против концертного рояля в консерватории. Т.е. инструмент один, а подход (и, безусловно, результат) разный. При чем и тот и другой результат востребованы. И принципиально нет каких-то серьезных ограничений, по которым пианист-виртуоз не смог бы записать на синтезаторе партии всех инструментов, или музыкант-клавишник современной популярной группы не смог бы исполнить условного Моцарта в условной консерватории, но... Эти миру сосуществуют рядом практически не соприкасаясь. Лишь изредка случается миграция в ту или иную сторону.
Похоже что пока так и останется. Меня на работе учили, я учу и мои последователи учить будут. Может оно и правильно. Ну а здесь будем ловить минусы от тех, кто идет параллельным путем.
unreal_undead2
17.04.2024 13:20современный С это сильно больше язык загрузчиков, ядер операционных систем и драйверов
А на этом уровне и POSIX с его write нет, только прямая запись в порты или видеопамять. Согласен, что ниша C сейчас ближе к ядру и чтобы начать писать на нём новый прикладной софт нужны особые причины. Но legacy много, не только масштаба sed/find, но и, скажем, PostgreSQL или Nginx.
MinimumLaw
17.04.2024 13:20На этом уровне как раз и формируется POSIX. Собственно здесь же он и начинает использоваться. В частности и для абстракций высшего уровня. И не только для самого языка С.
Что же до PostgreSQL или Nginx, то.... Может быть Legacy, а может быть разумный выбор инструмента для оптимального решения конкретной задачи.
Все меняется. Кто сейчас помнит самый популярный некогда почтовик sendmail? Уж даже не спрашиваю кто им пользуется... Так что когда становится реально надо, legacy переписывается.

alexandrustinov
17.04.2024 13:20+1Что же до PostgreSQL или Nginx, то.... Может быть Legacy, а может быть разумный выбор инструмента для оптимального решения конкретной задачи. Все меняется. Кто сейчас помнит самый популярный некогда почтовик sendmail?
postfix тоже написан на C. Не на C++. И не на Rust
Причина скорее всего в отсутствии реальных, т.е. достаточно стабильных альтернатив для именно кроссплатформенной разработки.
Но за рамками кроссплатформы современный C как язык общего назначения даже вместе с POSIX это довольно сомнительное мероприятие, т.к. читабельность типового С кода вида:
namespace_classname_t result = namespace_classname_methodname(&object_nameb, param_A, param_B);объективно ну очень сильно проигрывает типовому "не С" коду:
var result = object.methodname(paramA, paramB);В С прям очень сильно не хватает разумной реализации C with Classes and Namespaces.
Можно конечно сказать ну так и пишите на C++, но в силу его переразвитости подобный совет - это все равно что вместо ручного шуруповерта или перфоратора предлагать всем проходческий угольный комбайн покупать и осваивать, только для того, чтоб картину на гвоздь на стене повесить. И потом на этом комбайне еще и в булочную так и ездить, и на работу в офис, и за детьми в детский садик, веселить публику многочасовыми компиляциями.
А современный POSIX он уже скорее даже вреден. Т.к. не только замер в развитии, да еще и регрессирует. К примеру пометил
ucontext.hустаревшим, и не предложив альтернативы. Продвигает напрочь устаревшие fork() и system() вместо clone() и т.д. И вообще ничего не говоря про events, кроме select(), страшно далеки они там в комитете от народа.Как там в POSIX будет про epoll(), kqueue(), IOCPs ? Cовсем никак? так уже лет 15 прошло, неужели до сих пор договориться не смогли?
А vectors/ArrayList/resizable arrays, duallinked lists с hashmaps, и прочие нормальные строки (которые size+pointer) в С и POSIX наверное уже никогда не дождемся, так и будем каждый свои самодельные велосипеды (в каждый проект свои, особо эффективные, на макросах) прикручивать до конца столетия?
MinimumLaw
17.04.2024 13:20Давайте так - каждое из утверждений имеет свои "за" и свои "против". В общем случае хочется думать, что если обозначенные проблемы реально являются проблемами они будут решены. Пусть и не в рамках языка С, который однажды окажется в учебниках по истории IT и редко где в реальной жизни.
unreal_undead2
17.04.2024 13:20А современный POSIX он уже скорее даже вреден.
И какую альтернативу предлагаете для общения с ядром в Линуксе и т.п.? Да, заметной части прикладного кода достаточно высокоуровневых фреймворков (но тогда и писать можно на каком нибудь go или Java), но иногда надо чётко знать, как и какие сисколлы вызываются.
alexandrustinov
17.04.2024 13:20И какую альтернативу предлагаете для общения с ядром в Линуксе и т.п.?
К сожалению альтернативой POSIX и является сам Linux. Обеспечение совместимости только с относительно свежими Linux и только.
И тотальное забвение необходимости совместимости с MacOS, FreeBSD, Solaris, AIX, и кто там еще живой. Про Windows и говорить не стоит.
В противном случае POSIX совместимость является типичным чемоданом без ручки - затраты на поддержание регрессионных тестов это еще ладно (можно поднять ферму из виртуалок и гонять там через Jenkins автотесты), это просто потеря времени, а вот то что функционально приходится весьма серьезно самоограничиваться, к примеру в части clone() - это уже сильно хуже, это потеря функциональности.
MinimumLaw
17.04.2024 13:20И тотальное забвение необходимости совместимости с MacOS, FreeBSD, Solaris, AIX, и кто там еще живой. Про Windows и говорить не стоит.
Смело, модно, молодежно.
Вообще говоря, posix с самого начала был "чемоданом без ручки". Примерно как знаменитый автомат Калашникова. Каждому конкретному бойцу он неудобен - масса, габариты, кучность, убойная сила.... Но для каждого рода войск и прочих неармейских подразделений своя модификация. При сохранении базовых принципов и взаимозаменяемости основных частей.
В этом смысле Linux, как альтернатива Posix ничего кроме улыбки не вызывает. Posix не запрещает clone() и прочие так любые вашему сердцу моменты. А если единственная целевая аудитория это Linux - ну и славненько.

JordanCpp
17.04.2024 13:20Можно конечно сказать ну так и пишите на C++, но в силу его переразвитости подобный совет - это все равно что вместо ручного шуруповерта или перфоратора предлагать всем проходческий угольный комбайн покупать и осваивать, только для того, чтоб картину на гвоздь на стене повесить. И потом на этом комбайне еще и в булочную так и ездить, и на работу в офис, и за детьми в детский садик, веселить публику многочасовыми компиляциями.
С++ не заставляет в каждой строке кода, использовать все фишки всех стандартов. Выберите те конструкции которые вам нужны и используйте их. Не вижу проблемы с переразвитостью.
alexandrustinov
17.04.2024 13:20С++ не заставляет в каждой строке кода, использовать все фишки. Не вижу проблемы с переразвитостью.
Так не прокатит. Даже ограниченный набор приводит к пережевыванию сотен тысяч строк заголовочных файлов с шаблонами, в которых наскладирован этот многовековой legacy, который радостно будет предложен для парсинга в тот-же clangd. И это на старте, с libstdc++. Плюс компиляция - да, pch помогает, но это тоже полумера (ибо все на шаблонах).
И модули? А какие такие модули? :)
А если пытаться еще какие третьесторонние библиотеки на C++ подключать, с Boost и прочими прелестями...
Да даже на простой autocomplete в VScode в C++ проектах смотреть очень грустно, он прям столько тебе "полезного" пытается предложить, задумчиво так.
Но выкинуть это лишнее никак нельзя. Даже initializer lists дефиницию оказывается нельзя взять и выкусить в свой строго отдельный заголовочный файл (чтоб не тянуть весь libstdc++) - там прям гвоздями прибито к libstdc++, что просто удивительно. Только копируешь дефиницию в свой отдельный .hpp файл с другим namespace - и оно сразу перестает работать магическим образом. Фантастика (хотя может и починили уже, но не уверен).

kekoz
17.04.2024 13:20+4Потому, что системный вызов write не имеет отношения к языку C. А “Hello world” от Кернигана и Ричи — она именно про язык, частью которого является и стандартная библиотека. Потому и printf.
alexandrustinov
17.04.2024 13:20она именно про язык, частью которого является и стандартная библиотека.
Стандартная библиотека не является частью языка.
Хоть стандартная, хоть не стандартная, это всего лишь библиотека, и это очень хорошо, что в мире C и даже в мире C++ вполне можно выкинуть стандартную библиотеку на старте и использовать что-то принципиально иное. Причем это не случайность, это как раз базовые требования, иначе бы не была возможна кросскомпиляция для каких микроконтроллеров.

ReadOnlySadUser
17.04.2024 13:20+1Всё оч просто: попробуйте скомпилировать ваш код в Windows, после чего поймёте почему printf)


JordanCpp
17.04.2024 13:20+3А теперь представьте, тоже самое на js. console.log(
'Hello World!');
От там будет, марианская впадина:) Электрон...

gurux13
17.04.2024 13:20Похожая статья, которую я когда-то переводил, если интересно ещё немного почитать на тему. В частности, немного про обработку в ядре.
unreal_undead2
Раз уж в конце дошли до сисколлов, надо было с ядра и начать - fork (точнее clone)/exec для создания нового процесса и попытки выполнить наш бинарник, загрузка ядром ни разу не нашего бинарника, а ld-linux.so, который грузит уже и сам бинарник, и нужные динамические библиотеки с настройкой связей, и только после этого переход на стартовый адрес.
neyronon
Про работу с эльфийским заголовком тоже было бы не плохо подробнее рассказать в контексте минимально необходимой информации для загрузки и выполнения приложения в оперативной памяти.