

Недавно ко мне обратились знакомые, которые активно впиливали LLM в своей продукт, однако их смущала стоимость такого решения - они платили около 8$/час за Huggingface inference Endpoint 24/7, на что уходили просто невиданные ~100 тысяч долларов в год. Мне нужно было заресерчить какие есть способы развертывания больших текстовых моделей, понять какие где есть проблемы и выбрать оптимальных сёрвинг. Результатами этого ресерча и делюсь в этой статье)
Что такое инференс сервер?
Запуск LLM локально - не тривиальная задача. Вам необходимо необходимо взаимодействовать с видеокартой, что бы максимально быстро перемножать матрицы, выстраивать запросы в очередь, что бы ее память не переполнилась, объединять запросы из очереди в батчи по разным правилам, токенизировать текст итп.
Что бы не загромождать этой логикой основное приложение, ее можно вынести в отдельный микросервис.
Инференс сервер, это как раз такой микросервис, позволяющий работать с ЛЛМ как с черным ящиком, в который можно подать текст, и получить текст на выход.
Full support
Наверное первый и самый важный пункт при выборе сервинга - проверить может ли он запускать ту модель что вам требуется. К этому нужно быть особенно внимательным если вы запускаете что то экзотическое, типо MoE, или, не упоси господь мамбу.
Так же нужно быть уверенным что ваш сервинг поддерживает вашу видеокарту, даже если это решение от Nvidia. Функционал старых карт значительно меньше чем у новых, за это отвечает Compute Capabilites. Чем больше число - тем лучше. Если берете карточку с поддержкой ниже чем 8.0 будте готовы столкнуться с неработоспособностью некоторых функций. Так же не все серверы поддерживают распаралеливание между GPU и делаю это оптимально
Простота развертывания
К сожалению, ни у каждого ИИ стартапа есть бюджет на найм команды MLops, так что вероятнее всего развертыванием LLMки будут заниматься обычные разработчики. Так что при выборе решения для запуска моделей простота развертывания - довольно важный критерий. Среди лидеров по этому критерию выделяется Ollama - запускаете одну команду, она подтягивает все что нужно, детектит наличие карточек и запускает фоном сервинг с OpenAI compatable API. А так же в нее можно довольно легко добавить свои модели, прописав в довольно забавном Modelfile как с ними работать
GPU offload
Современные LLM имея миллиарды весов требуют десятки гигабайт VRAM для работы. Так как не все потребительские карточки могут похвастаться таким объемом памяти - очевидным решением было бы использовать RAM для хранения части весов и CPU для их обработки. То есть часть слоев находится в памяти видеокарты, после применения которых промежуточный вектор активации передается на CPU, и вычисления продолжаются там. В таком формате производительность будет сильно ограничена скоростью PCI шины, а так же тем, как мало слоев считаются на CPU (чем меньше, тем разумеется быстрее). Среди лидеров сервингов для GPU-pure есть llama cpp и опять же, замечательная обертка вокруг нее - ollama.
Quantization
Квантизация - это процесс уменьшения точности чисел с плавающей запятой в нейронных сетях. По умолчанию числа с плавающей запятой (например, float32) требуют 32 бита для представления каждого числа. Квантизация позволяет уменьшить этот объем памяти, используемый для представления чисел, путем преобразования их в числа с фиксированной точностью, такие как int8 или int4. Это позволяет сократить потребление памяти и (потенциально) увеличить скорость вычислений за счет использования более компактного формата чисел.
Однако с квантизацей нужно быть аккуратными:
Существует 100500 различных способов округлить веса модели, и не факт что вас сервинг будет поддерживать все
-
Квантизация может быть реализована не оптимальным образом (как например в vLLM), в таком случае, скорость от использования квантизации может даже упасть.

Batching
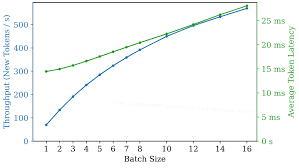
Часто ЛЛМ является узким горлышком системы, и в очереди задач перед ней скапливается много запросов. Система могла бы их обрабатывать не "по одному", а батчами, беря за раз сразу несколько запросов, и обрабатывая батчем, благодоря магии матричного умножения.
То есть при использовании батч сайза 2, модель сможет сгенерировать 2 ответа за время, менее чем в 2 раза большее чем при BS=1. К тому же следует пониать что увеличение батчсайза неумолимо увеличивает latency ответа
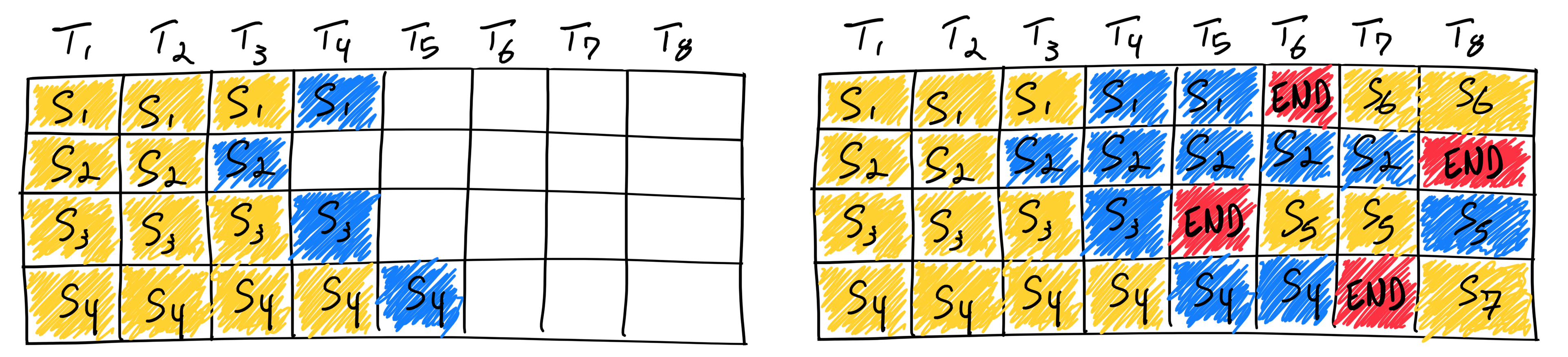
Continuous batching
Длинной очереди задач может и не быть, однако запросы все равно могут приходить параллельно. То есть пока обрабатывается один запрос, может прилететь второй.
При генерации текста LLM мы вызываем модель много раз последовательно, для генерации каждого токена. Так что мы можем сразу переключиться на генерацию следующей фразы, если в один батч попали последовательности различной длинны.
. Поддержка LoRA

Некоторые сервинги позволяют переключать адаптеры у моделй на лету. Таким образом вы можете держать в памяти 1 копию исходной модели, и большой набор лор, и генерировать ответы в разном стиле. Если вам необходим такой функционал - посмотрите в сторону lorax. Подробнее про то, как работает Lora вы можете почитать в моей другой статье (кто же такая эта ваша лора)
Скорость работы
Несмотря на то, что в целом все инференс сервера под капотом выполняют одинаковые операции, существует большое число мелких оптимизаций, благодаря которым скорость генерации текста у одних больше чем у других. Глобально это вызвано двумя причинами: неоптимальным кодом (и если его оптимизировать то начнет работать быстрее с тем же качеством) или различными улутшалками, которые ускоряют модель, засчет небольшого падения качества)
Основные параметры на которые стоит смотреть это:
Throughput - скорость генерации при оптимальном батч сайзе. Важно если у вас большой поток запросов и вы можете выбирать оптимальный батч сайз
Single thread t/s - скорость генерации без батча. Если пользователей мало, и часто батч не набирается Чуть более специфичные:
latency ms - через сколько секунд ллм сгенерирует первый токен. Может быть важно для систем с использованием TTS, где важно как можно раньше начать говорить ответ
-
prompt t/s - скорость обработки промпта. (латенси на токен).
Про то, где искать конкретные значения для разных сервингов/видеокарт/моделей - смотрите в самый конец
Заключение
Вместо того что бы просить chat gpt лить воду в заключении, просто прикреплю таблицу
Easy to use |
Offload |
Quantization |
Batching |
Speed |
MoE |
Mamba |
Comment |
|
|---|---|---|---|---|---|---|---|---|
vLLM |
+/- |
- |
- |
+ |
+ |
+ |
+ |
Best throughput |
Tensor RT |
- |
- |
+ |
+ |
+/- |
+/- |
+/- |
Сложна |
exLlama |
- |
- |
+ |
- |
+ |
- |
- |
Best single utterance throughput |
llama.cpp |
+/- |
+ |
+ |
+ |
- |
+ |
- |
Для GPU pure |
ollama |
+ |
+ |
+ |
- |
- |
+ |
- |
Самое простое решение |
deepspeed-mii |
+/- |
- |
+ |
+ |
+/- |
+ |
+/- |
Nvidia-CC >= 8.0 |
TGI |
- |
+/- (slow) |
+ |
+ |
+/- |
+ |
- |
Не смог собрать( |
Более детальное, количественное сравнение различных методов сервинга на различном железе, с точными результатам бенчмарков, можете найти в этой таблице (дополняется).
P.S. по итогу развернули deepspeed на карточках vast ai, которые обходятся в 0.2 - 0.3 $/час, что в 80 раз дешевле чем HFI, но надо повозиться)
Комментарии (18)

vindy123
20.04.2024 12:33+6Мой личный блог
Кажется, до соевых en masse начало доходить, что за фразу "подписывайтесь на мой телеграм канал по ссылке" тут сливают карму. С интересом наблюдаю за попытками зайчиков это как-то наивно замаскировать сейчас.

freQuensy23 Автор
20.04.2024 12:33А вы считаете это неправильным? Вроде это правило хорошего тона оставлять контакт в статье
vindy123
20.04.2024 12:33+3Извините, если я был чересчур резок в предыдущем комментарии. Наверняка вы осведомлены об этой чуме, пожирающей хабр, впрочем.

lair
20.04.2024 12:33+7Вроде это правило хорошего тона оставлять контакт в статье
Ваши контакты - в подписи под статьей, предоставлены Хабром, ничего дополнительного в тело статьи включать не нужно.
freQuensy23 Автор
20.04.2024 12:33Не поленился, проанализировал те статьи что выходят на хабре. Из 10 не новостных технический статей в 7и был контакт пользователя (ютуб канал/телеграм канал итп), так что кажется что это уже база?

mazagama
20.04.2024 12:33+1В некоторых странах принято испражняться в источники воды, питающей нехилую часть территории. Но это же не значит что нужно за ними повторять.
freQuensy23 Автор
20.04.2024 12:33А можете как то более четко обосновать в чем причина проблем от оставления ссылки на личный блог посвященный тематике статьи? Я просто правда не понимаю почему это кого то задевает? Если это как то нарушает правила или делает кого-то жизнь настолько невыносимой, то я готов немедленно отредачить статью и убрать ссылку, но хотел бы хоть какие то аргументы. В правилах хабра прямым текстом написано что оставлять ссылки на персональные блоги можно (пункт 1, раздел "исключения")
vindy123
20.04.2024 12:33+6Я вам постараюсь объяснить. Хабр раньше был ресурсом технарей для технарей. Изначально хабр не был рекламной площадкой, а сейчас стал. Многим это не нравится. Многим не нравятся попытки забайтить немного подписчиков себе, сделав технически неглубокую статью ради ссылки на свою телегу в конце. Многим не нравятся попытки автора сделать вид, что за публикацей была какая то другая мотивация, когда его носом тыкают в это.

ACO-Andrew
20.04.2024 12:33+2А прогнать текст статьи через одну из "моделек" на предмет исправления ошибок (sic! в двух языках сразу!) сложно? И есчо, а что такое "сервинг"?
freQuensy23 Автор
20.04.2024 12:33да вроде прогонял( Сразу извиняюсь за ошибки, сам их совсем не вижу. Но если вы посоветуете исправления, через Ctr + Enter можете подать их, сразу исправлю(
ACO-Andrew
20.04.2024 12:33"Выбираем правильный инеференс: Как мы сэкономили 70к $ на ЛЛМках" - WTF is инеференс?


Zoolander
20.04.2024 12:33Ollama - это сервер с бэкендом llama.cpp
lama.cpp может работать не только на GPU

sshmakov
Очень познавательно, но вопрос не раскрыт. Так как же вы сэкономили 70к$?
freQuensy23 Автор
Отказались от HFI и стали запускать модельки сами
freQuensy23 Автор
расписано в пункте p.s. под статьей?