
О нашем девятимесячном пути к горизонтальному шардингу Postgres-стека Figma и о возможности обеспечения (почти) бесконечной масштабируемости.
Вертикальное разбиение было относительно простым и важным инструментом масштабирования, позволившим нам быстро добиться существенных улучшений. Кроме того, оно стало важным этапом на пути к горизонтальному шардингу.
С 2020 года стек баз данных Figma вырос почти в сотню раз. Это хорошая проблема, ведь она означает, что наш бизнес расширяется. Но в то же время она стала причиной технических сложностей. В течение последних четырёх лет мы усиленно старались не отставать от прогресса и избегать потенциальных проблем, связанных с ростом. В 2020 году у нас работала единственная база данных Postgres, которая хостилась на самом большом физическом инстансе AWS, но к концу 2022 года мы уже создали распределённую архитектуру с кэшированием, репликами для чтения и десятком вертикально разделённых баз данных. Мы разбили группы связанных таблиц (например, «Figma files» или «Organizations») на отдельные вертикальные разделы, что позволило нам обеспечить удобство инкрементального масштабирования и оставить достаточно пространства для дальнейшего роста.

Несмотря на наш прогресс в сфере инкрементального масштабирования, мы всегда знали, что у этого вертикального разделения есть свои пределы. Изначально наши усилия по масштабированию были направлены на снижение загрузки CPU базой данных Postgres. С ростом и увеличением разнородности нашей инфраструктуры мы начали сталкиваться с разнообразными узкими местами. Мы изучили исторические данные и провели нагрузочное тестирование, чтобы количественно оценить пределы масштабирования баз данных с точки зрения как CPU и ввода-вывода, так и размера таблиц и записываемых строк. Выявление этих пределов было критически необходимо для прогнозирования потенциала каждого шарда. После этого мы смогли расставить приоритеты проблем масштабирования, прежде чем они не превратились в серьёзные угрозы надёжности.
Данные показали, что некоторые из наших таблиц, содержащие множество терабайтов и миллиарды строк, становятся слишком большими для единственной базы данных. При таких объёмах мы уже начали наблюдать снижение надёжности во время очисток (vacuum) Postgres, то есть необходимых фоновых операций, предотвращающих исчерпание transaction ID и поломку Postgres. Наши таблицы с наибольшим количеством операций записи разрастались так быстро, что мы могли вскоре превзойти тот максимум операций ввода-вывода в секунду (IOPS), который поддерживается Amazon Relational Database Service (RDS). Вертикальное разделение не могло нам в этом помочь, потому что наименьшей единицей разделения остаётся одна таблица. Чтобы наши базы данных не обрушились, нам требовался более мощный инструмент.
Подготовка к масштабированию
Мы создали список целей и обязательных требований, позволяющих решать кратковременные проблемы и в то же время подготавливающих нас к долговременному росту. Мы стремились к следующему:
Минимизировать влияние разработчиков: мы хотели обрабатывать основную часть нашей сложной реляционной модели данных, поддерживаемой нашим приложением. Благодаря этому разработчики приложения могли бы сосредоточиться на создании новых функций Figma, а не на рефакторинге крупных частей кодовой базы.
Обеспечить прозрачность масштабирования: в процессе масштабирования в будущем мы не хотели вносить дополнительные изменения в слой приложений. Это означало, что после любых предварительных работ по обеспечению совместимости таблиц дальнейшие масштабирования должны оставаться прозрачными для продуктовых команд.
Избежать затратных backfill: мы избегали решений, в которых задействовался backfilling крупных таблиц или каждой таблицы в Figma. Учитывая размер наших таблиц и ограничения производительности Postgres, такие backfill занимали бы целые месяцы.
Инкрементальный прогресс: мы выявили решения, которые можно развёртывать инкрементальным образом, убирая риски, связанные с крупными изменениями в продакшене. Это снизило риски масштабных сбоев и позволило команде баз данных поддерживать надёжность Figma в течение всего процесса миграции.
Избегать односторонних миграций: мы сохранили возможность отката назад даже после завершения операции физического шардинга. Это снизило риск застревания в плохом состоянии, даже когда возникнут неизвестные неизвестные.
Обеспечивать высокую целостность данных: мы хотели избежать сложных решений, например double write, которые сложно реализовать без даунтайма или компрометации целостности. Кроме того, нам нужно было решение, которое позволит нам масштабироваться практически с нулевым даунтаймом.
Использовать наши сильные стороны: так как мы работали в условиях жёстких дедлайнов, то по возможности отдавали предпочтение решениям, которые можно развёртывать инкрементально для наших самых быстрорастущих таблиц. Мы нацеливались на использование уже имеющегося опыта и технологий.
Изучение доступных вариантов
Существует множество популярных опенсорсных и managed-решений для баз данных с горизонтальным шардингом, совместимых с Postgres или MySQL. В процессе их оценки мы рассмотрели CockroachDB, TiDB, Spanner и Vitess. Однако при переходе на любую из этих альтернативных баз данных потребовался бы сложный процесс миграции данных для обеспечения целостности и надёжности между этими двумя разными хранилищами баз данных. Кроме того, за последние несколько лет мы наработали большой опыт в надёжной и высокопроизводительной эксплуатации RDS Postgres на собственных мощностях. В процессе миграции нам пришлось бы заново нарабатывать всю экспертизу в предметной области. Учитывая нашу очень агрессивную скорость роста, у нас оставалось всего лишь несколько месяцев. Мы отдали предпочтение низкорискованным решениям, отказавшись от потенциально более простых вариантов с повышенной степенью неопределённости, в которых у нас было бы меньше контроля над результатом.
Ещё один распространённый вариант, масштабируемый по умолчанию — это базы данных NoSQL, его часто используют компании в процессе роста. Однако у нас имелась очень сложная реляционная модель данных, созданная на основе текущей архитектуры Postgres, а NoSQL API не обеспечивают подобного уровня гибкости. Мы хотели, чтобы наши инженеры занимались выпуском новых качественных фич и создавали продукты, а не переписывали почти полностью наше бэкенд-приложение; поэтому NoSQL нам не подходил.
Учитывая эти условия, мы начали исследовать вопрос создания решения с горизонтальными шардами поверх нашей вертикально разделённой инфраструктуры RDS Postgres. Нашей небольшой команде не имело смысла заново реализовывать самостоятельно горизонтально шардированную реляционную базу данных; поступив так, мы бы попытались конкурировать с инструментами, созданными огромными опенсорсными сообществами или поставщиками баз данных. Однако так как мы создавали горизонтальный шардинг конкретно под специфическую архитектуру Figma, можно было обойтись гораздо меньшим набором функий. Например, мы решили не поддерживать атомные транзакции между шардами, потому что могли обойти проблему сбоев транзакций между шардами. Мы выбрали стратегию колокации, которая минимизировала изменения, необходимые в слое приложения. Это позволило нам обеспечить поддержку подмножества Postgres, совместимого с основной частью нашей логики продукта. Также мы могли с лёгкостью поддерживать обратную совместимость между Postgres с шардингом и без шардинга. Если бы мы столкнулись с неизвестными неизвестными, то могли бы запросто откатиться к Postgres без шардинга.
Путь к горизонтальному шардингу
Даже сузив требования, мы понимали, что горизонтальный шардинг окажется самым крупным и сложным проектом, связанным с базами данных. К счастью, наша применявшаяся ранее методика инкрементального масштабирования позволила нам выиграть достаточно ресурсов для подобных инвестиций. В конце 2022 года мы приступили к реализации практически бесконечной масштабируемости баз данных, в которой самым главным был горизонтальный шардинг — процесс разбиения одной таблицы или группы таблиц с разделением данных по нескольким физическим инстансам баз данных. После выполнения горизонтального шардинга таблицы в слое приложений она сможет поддерживать любое количество шардов на физическом слое. В дальнейшем мы всегда сможем масштабироваться ещё сильнее, выполнив простой процесс разделения физического шарда. Эти операции выполняются прозрачно и в фоновом режиме, с минимальным даунтаймом и без необходимости внесения изменений в слое приложений. Эта функциональность позволит нам опережать возникновение узких мест при масштабировании баз данных, устранив одну из самых серьёзных проблем масштабирования Figma.


Горизонтальный шардинг на порядки величин сложнее, чем все наши предыдущие проекты по масштабированию. Когда таблица разносится на несколько физических баз данных, мы теряем многие свойства целостности и надёжности, которые воспринимались в базах данных ACID SQL как что-то само собой разумеющееся. Например:
Некоторые запросы SQL становятся неэффективными, или их невозможно поддерживать.
Код приложений нужно дополнить, чтобы он предоставлял достаточно информации для эффективной маршрутизации запросов на нужные шарды.
Чтобы обеспечить синхронизацию баз данных, изменения схемы необходимо координировать во всех шардах. Postgres больше не сможет обеспечивать внешние ключи и глобально уникальные индексы.
Транзакции теперь будут затрагивать несколько шардов, то есть Postgres больше нельзя будет использовать для обеспечения управления транзакциями. Необходимо внимательно следить за тем, чтобы логика продукта была устойчивой к этим «частичным сбоям коммитов» (представьте, что команда переносится из одной организации в другую, а половина её данных при этом теряется!).
Мы знали, что реализация полного горизонтального шардинга будет задачей на несколько лет. Нам нужно было по возможности избавить проект от различных рисков, в то же время обеспечивая инкрементальную выгоду. Наша первая цель заключалась в максимально быстрой реализации шардинга относительно простой, но имеющий очень высокий трафик таблицы в продакшене. Это бы доказало осуществимость горизонтального шардинга, а также дало бы нам больше времени для работы с нашей самой загруженной базой данных. Затем мы могли бы продолжить создавать дополнительные фичи, параллельно работая над шардингом более сложных групп таблиц. Внедрение даже простейшего набора функций было серьёзным мероприятием. В конечном итоге, на шардинг нашей первой таблицы команде понадобилось примерно девять месяцев.
Наше уникальное решение
Наша работа по горизонтальному шардингу основана на том, что делают многие другие, но в некоторых аспектах мы выбрали довольно необычные варианты. Вот примеры:
Колокации: мы расшардили горизонтально группы связанных таблиц в колокации (которые мы назвали «colo»), имеющие одинаковый ключ шардинга и физическую структуру шардинга. Это обеспечило разработчикам удобную абстракцию для взаимодействия с разделёнными на горизонтальные шарды таблицами.
Логический шардинг: мы отделили концепцию «логического шардинга» в слое приложений от «физического шардинга» в слое Postgres. Мы использовали виртуальные таблицы для выполнения более безопасного и экономичного развёртывания логического шардинга, прежде чем выполнять более рискованное распределённое физическое переключение.
Система обработки запросов DBProxy: мы разработали сервис DBProxy, перехватывающий запросы SQL, сгенерированные нашим слоем приложений, и динамически перенаправляющий запросы различным базам данных Postgres. DBProxy включает в себя систему обработки запросов, способную парсить и исполнять сложные запросы с горизонтальным шардингом. Кроме того, DBProxy позволил нам реализовать такие функции, как динамическая сегментация нагрузки и хеджирование запросов.
Теневая готовность приложений: мы добавили фреймворк «теневой готовности приложений», способный прогнозировать поведение реального трафика продакшена при различных потенциальных ключах шардинга. Это дало продуктовым командам чёткую картину того, какую логику приложений нужно отрефакторить или удалить, чтобы подготовить приложение к горизонтальному шардингу.
Полная логическая репликация: мы избежали необходимости реализации «логической репликации с фильтрацией» (при которой в каждый шард копируется только подмножество данных). Вместо этого мы копировали целый датасет, а затем только разрешали чтение/запись подмножества данных, принадлежащих конкретному шарду.
Наша реализация шардинга
Одно из самых важных решений при горизонтальном шардинге — выбор ключа шарда. Горизонтальный шардинг накладывает множество ограничений модели данных, связанных с ключом шарда. Например, в большинство запросов необходимо включать ключ шарда, чтобы запрос был перенаправлен на нужный шард. Некоторые ограничения баз данных, например внешние ключи, работают, только когда внешний ключ совпадает с ключом шардинга. Кроме того, ключ шарда должен равномерно распределять данные по всем шардам, чтобы избежать «горячих» точек, вызывающих проблемы с надёжностью или влияющих на масштабируемость.
Figma работает в браузере, и над одним файлом Figma могут совместно параллельно трудиться несколько пользователей. Поэтому наш продукт оснащён довольно сложной реляционной моделью данных, хранящей метаданные файла и организации, комментарии, версии файлов и так далее.
Мы думали над возможностью использовать один и тот же ключ шардинга для каждой таблицы, но для нашей модели данных не нашлось ни одного подходящего кандидата. Чтобы добавить унифицированный ключ шардинга, нам бы пришлось создать составной ключ, добавить столбец в схему каждой таблицы, выполнить объёмные backfill для его заполнения, а затем существенно отрефакторить логику продукта. Вместо этого мы подстроили наше решение под уникальную модель данных Figma и выбрали несколько ключей шардинга наподобие UserID, FileID и OrgID. При помощи одного из этих ключей можно выполнить шардинг почти каждой таблицы в Figma.
Мы ввели концепцию colo, предоставляющих разработчикам продукта удобную абстракцию: таблицы внутри colo поддерживают межтабличные join и полные транзакции с ограничением одним ключом шардинга. Основная часть кода приложений и так уже взаимодействовала с базой данных таким образом; это минимизировало работу, которую необходимо было проделать разработчикам приложений, чтобы подготовить таблицу к горизонтальному шардингу.


После выбора ключей шардинга нам нужно было обеспечить равное распределение данных по всем базам данных бэкенда. К сожалению, многие имевшиеся у нас ключи шардинга использовали ID с автоинкрементом или с префиксом в виде меток времени Snowflake. Это бы привело к образованию существенных «горячих» точек, когда один шард содержит большинство данных. Мы изучили возможность миграции на более рандомизированные ID, но для этого потребовалась бы затратная по деньгам и времени миграция данных. Поэтому вместо неё мы решили использовать для маршрутизации хэш ключа шардинга. Если выбрать достаточно случайную хэш-функцию, то мы гарантируем равномерное распределение данных. Недостаток такого подхода заключается в том, что сканирование диапазонов по ключам шардов будет менее эффективным, так как последовательные ключи будут хэшированы в разные шарды базы данных. Однако такой паттерн запросов нечасто используется в нашей кодовой базе, так что мы с готовностью пошли на такой компромисс.
«Логическое» решение
Чтобы устранить риски развёртывания горизонтального шардинга, мы хотели изолировать процесс подготовки таблицы в слое приложений от физического процесса разбиения на шарды. Для этого мы отделили «логический шардинг» от «физического». После этого мы могли разделить две части нашей миграции, чтобы по отдельности реализовать и избавить от рисков. Для отката назад логического шардинга в случае обнаружения багов достаточно было бы просто изменить конфигурацию. Откатить физическую операцию с шардами можно, но для обеспечения целостности данных потребуется более сложная координация.
После выполнения логического шардинга таблицы все операции чтения и записи будут работать так, как будто уже выполнен горизонтальный шардинг таблицы. С точки зрения надёжности, задержек и целостности система выглядит так, как будто был произведён горизонтальный шардинг, однако данные по-прежнему физически расположены на одном хосте базы данных. Когда мы убедились, что логический шардинг работает как задумано, то приступили к операции физического шардинга. Этот процесс заключается в копировании данных из единой базы данных, разделения его по нескольким бэкендам с последующим перераспределением трафика чтения и записи по новым базам данных.

Система обработки запросов, которая смогла
Для поддержки горизонтального шардинга нам нужно было существенно изменить архитектуру стека бэкенда. Изначально наши сервисы приложений общались напрямую со слоем пула соединений (PGBouncer). Однако горизонтальный шардинг требует гораздо более сложного парсинга, планирования и исполнения запросов. Для его поддержки мы создали новый сервис на Golang под названием DBProxy. DBProxy расположен между слоем приложений и PGBouncer. Он содержит логику сегментации нагрузок, улучшенной наблюдаемости, поддержки транзакций, управления топологией базы данных, а также легковесную систему обработки запросов.
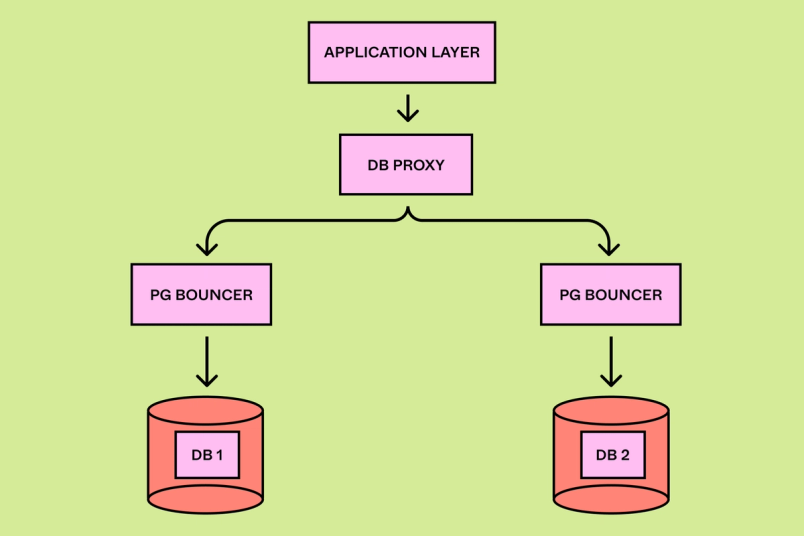
Система обработки запросов — ядро DBProxy. Её основные компоненты:
Парсер запросов, который читает отправленный приложением SQL и преобразует его в Abstract Syntax Tree (AST).
Логический планировщик, который парсит AST и извлекает из плана запроса тип запроса (insert, update и так далее) и ID логического шарда.
Физический планировщик, сопоставляющий ID логического шарда из запроса с физическими базами данных. Он переписывает запросы, чтобы они исполнялись на соответствующем физическом шарде.



Можно воспринимать «распределение-сборку» (scatter-gather) как игру в прятки по всей базе данных: вы отправляете свой запрос каждому шарду (распределение), а затем собираете вместе ответы от каждого (сборка). Это интересный процесс, но если перемудрить, то ваша быстрая база данных превратится в тормозную, особенно в случае сложных запросов.
Некоторые запросы достаточно просто реализовать в системе с горизонтальным шардингом. Например, запросы к одному шарду фильтруются по одному ключу шарда. Нашей системе обработки запросов достаточно просто извлечь ключ шарда и направить запрос на соответствующую физическую базу данных. Мы можем «перекинуть» сложность исполнения запроса на Postgres. Однако если в запросе отсутствует ключ шардинга, нашей системе обработки запросов необходимо выполнить более сложный процесс scatter-gather. В этом случае нам необходимо распределить запрос по всем шардам (этап распределения), а затем собрать вместе результаты (этап сборки). В некоторых случаях, например, при сложных сборках, join и вложенном SQL, реализация этого процесса scatter-gather может быть очень комплексной. Кроме того, слишком большое количество scatter-gather повлияет на масштабируемость горизонтального шардинга. Так как наши запросы должны обойти каждую базу данных, каждый scatter-gather вносит тот же объём нагрузки, как и в базе данных без шардинга.


Если бы мы поддерживали полную совместимость с SQL, то наш сервис DBProxy стал бы во многом похож на систему обработки запросов базы данных Postgres. Мы хотели упростить наш API, чтобы минимизировать сложность DBProxy, а также снизить объём работ, необходимых со стороны разработчиков приложений, которым бы пришлось переписывать все неподдерживаемые запросы. Чтобы определить нужное подмножество, мы создали фреймворк «теневого планирования», что позволило пользователям определить потенциальные схемы шардинга для их таблиц, а затем выполнить теневой этап логического планирования поверх реального трафика продакшена. Мы выполняли логирование запросов и связанных с ними планов запросов в базе данных Snowflake, где потом могли провести офлайн‑анализ. На основании этих данных мы выбрали язык запросов, который поддерживает 90% самых частых запросов, но позволяет избежать наихудших случаев сложности в нашей системе обработки запросов. Например, разрешены все сканирования диапазонов и точечные запросы, но join допускаются только при объединении двух таблиц в одной colo и если join находится в ключе шардинга.
Взгляд в будущее
Затем нам нужно было разобраться, как инкапсулировать логические шарды. Мы изучили разбиение данных при использовании отдельных баз данных Postgres и схем Postgres. К сожалению, при логическом шардинге приложения для этого потребовались бы физические изменения в данных, которые реализовать так же сложно, как и физическое разбиение на шарды.
Вместо этого мы решили представить наши шарды при помощи виртуальных таблиц (view) Postgres. Мы могли создавать по несколько виртуальных таблиц на каждую таблицу, и каждая из таких таблиц соответствовала подмножеству данных в конкретном шарде. Это выглядит так: CREATE VIEW table_shard1 AS SELECT * FROM table WHERE hash(shard_key) >= min_shard_range AND hash(shard_key) < max_shard_range). Все операции чтения и записи таблицы направляются через этих виртуальные таблицы.
Создав шардированные виртуальные таблицы поверх наших нешардированных физических баз данных, мы смогли обеспечить логический шардинг ещё до того, как приступать к рискованным операциям физического шардинга. Доступ к каждой из виртуальных таблиц выполняется через её собственный шардированный сервис пулинга соединений. Пулеры соединений продолжают указывать на физический инстанс без шардирования, что создаёт впечатление наличия шардинга. Нам удалось избежать риска благодаря постепенному развёртыванию шардированных операций при помощи feature flag в системе обработки запросов, и каждый раз за считанные секунды выполнять откат, просто перенаправляя трафик обратно к основной таблице. К тому времени, когда мы запустили наш первый решард, мы были уверены в безопасности топологии с шардингом.

Разумеется, применение виртуальных таблиц повлекло за собой и риски. Виртуальные таблицы повышают нагрузку, а в некоторых случаях и могут фундаментально изменять способ оптимизации запросов планировщиком запросов Postgres. Для проверки этой методики мы собрали корпус запросов из санированных запросов продакшена и провели нагрузочные тесты с виртуальными таблицами и без них. Нам удалось убедиться, что виртуальные таблицы в большинстве случаев лишь минимально повышают нагрузку, а в наихудших случаях снижение производительности составляет менее 10%. Также мы создали фреймворк теневых операций чтения, который мог отправлять весь реальный трафик чтения через виртуальные таблицы, чтобы можно было сравнить производительность и корректность виртуальных таблиц и запросов без виртуальных таблиц. Таким образом мы подтвердили, что виртуальные страницы оказались вполне рабочим решением, минимально влияющим на производительность.
Работа с топологией
Для выполнения маршрутизации запросов DBProxy должен понимать топологию наших таблиц и физических баз данных. Так как мы разделили концепции логического и физического шардинга, нам нужно было как-то представить эти абстракции в своей топологии. Например, нам нужна была возможность сопоставления таблицы (users) и её ключа шарда (user_id). Аналогично, нам требовалось сопоставлять ID логического шарда (123) с соответствующими логическими и физическими базами данных. При реализации вертикального разбиения мы воспользовались простым жёстко прописанным файлом конфигурации, сопоставлявшим таблицы с их разделом. Однако при переходе к горизонтальному шардингу нам понадобилось нечто более сложное. При разбиении на шарды наша топология будет меняться динамически, поэтому DBProxy должен быстро обновлять своё состояние, чтобы не перенаправлять запросы к неправильной базе данных. Так как каждое изменение в топологии обратно совместимо, эти изменения никогда не находились на критическом пути нашего сайта. Мы разработали топологию баз данных, инкапсулирующую сложные метаданные горизонтального шардинга и способную вносить обновления в реальном времени меньше, чем за секунду.
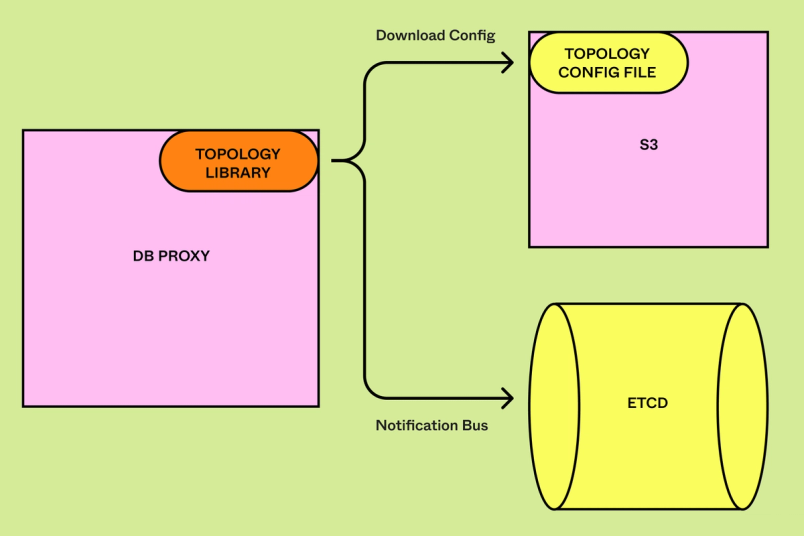
Разделение логической и физической топологии позволило нам также частично упростить управление базами данных. Например, в средах вне продакшена мы можем поддерживать ту же логическую топологию, что и в продакшене, но отправлять данные из гораздо меньшего количества физических баз данных. Это экономит нам средства и снижает сложность без необходимости внесения большого количества изменений между средами. Библиотека топологии также позволила нам реализовать в нашей топологии инварианты (например, ID каждого шарда должен сопоставляться ровно с одной физической базой данных), что было крайне важно для поддержания корректности системы в процессе создания горизонтального шардинга.
Физический процесс шардинга
После подготовки таблицы к шардингу остаётся последний этап — физический переход от нешардированных к шардированным базам данных. Для горизонтального шардинга мы смогли повторно использовать большую часть той же логики, но было и несколько заметных отличий: вместо переноса данных «из одной в одну» базу данных, нам пришлось переносить «из одной в N». Нам нужно было обеспечить устойчивость перехода к новым режимам отказа, при которых операция шардинга может завершиться успешно только для подмножества наших баз данных. Тем не менее, для многих компонентов с самой высокой степенью риска мы смогли избавиться от риска ещё в процессе вертикального разбиения. Благодаря этому мы гораздо быстрее смогли реализовать нашу первую операцию физического шардинга.
Мы прошли долгий путь
Когда мы начинали эту работу, нам было известно, что горизонтальный шардинг станет многолетней инвестицией в будущую масштабируемость Figma. Мы выпустили первую таблицу с горизонтальным шардингом в сентябре 2023 года. Нам удалось успешно выполнить переход со всего десятью секундами частичной доступности первичных баз данных; при этом доступность реплик никак не пострадала. После шардинга мы не наблюдали никаких регрессий с точки зрения задержек и доступности. После этого мы занимались относительно простым шардингом наших баз данных с наибольшей частотой операций записи. В этом году мы будем выполнять шардинг всё более сложных баз данных, состоящих из десятков таблиц и тысяч точек вызова в коде.
Чтобы избавиться от последних ограничений масштабирования, нам потребуется провести горизонтальный шардинг всех таблиц Figma. Система с полным горизонтальным шардингом принесёт нам множество других преимуществ: повышение надёжности, экономию и увеличение скорости разработки. На пути к этому нам нужно будет решить следующие задачи:
Поддержка обновлений схем с горизонтальным шардингом;
Генерация глобально уникальных ID для первичных ключей с горизонтальным шардингом;
Атомные транзакции между шардами для критически важных для бизнеса сценариях использования;
Глобально распределённые уникальные индексы (на данный момент уникальные индексы поддерживаются только для индексов, включающих ключ шардинга);
Модель ORM, повышающая скорость разработки и совместимая с горизонтальным шардингом;
Полностью автоматизированные операции решардинга, способные выполнять разделение на шарды нажатием одной кнопки.
Выиграв себе время для дальнейшего развития, мы также заново пересмотрим свою исходную методику собственного горизонтального шардинга RDS. Этот путь начался 18 месяцев назад с крайне сжатых сроков. Хранилища NewSQL продолжали эволюционировать и совершенствоваться. У нас наконец-то появилась достаточная пропускная способность, чтобы переосмыслить имеющиеся компромиссы и сделать выбор: продолжать двигаться по нынешнему пути или перейти на опенсорсное или managed-решение.
В процессе реализации горизонтального шардинга мы совершили огромный прогресс, но наши сложности — это только начало. Нас ждёт исследование других частей нашего стека горизонтального шардинга.
sshikov
Так и не понял из текста, что же скрывается под "множество терабайтов и миллиарды строк". Это мешает понять, какими же реально масштабами они оперируют.