
Всем привет.
На написание этой статьи меня сподвигло практически полное отсутствие информации о спаривании ElasticSearch с другими системами (бд), и построении полноценного сервиса в качестве основного хранилища которого выступет ElasticSearch.
Как мы уже писали в своем проекте Indexisto мы используем ElasticSearch в качестве основного хранилища. Это позволяет нам масштабировать систему под десятки миллионов документов без лишних телодвижений и при этом сохранять отклик измеряемый десятками миллисекунд.
Если вкратце про наш проект — это браузер читалка всего на свете: сайтов, пабликов, GIF, Youtube. Каждый документ представляет из себя страничку со статей (или постом в паблике например). Документы имеют мета информацию: сайт этого документа, оригинальный url, теги и тд. ElasticSearch нам позволяет делать очень быстрые пересечения для построения фидов по интересам (несколько сайтов в одном фиде), а также функциональность Google Alert, когда можно создать фид по любому словосочетанию.
Проблемы начались когда мы решили добавить в наше приложение возможность голосований и возможность сортировать документы по популярности.

И так обо всем по порядку.
В сортировке по числовым значениям (кол-во голосов) для ElasticSearch нет никаких сложностей, а вот записывать голоса напрямую в эластик нельзя. Elasticsearch построен на базе Lucene и использует append-only хранилище. Т.е. обновление документов фактически отсутствует. Каждое изменение документа приводит к его переиндексации и влечет периодическое перестроение сегментов хранилища. Нужно помнить, что индексация ресурсоёмкий процесс. “Забороть” его железом(и верно подобранными настройками!) возможно, но встает вопрос целесообразности.
Мы храним данные о голосованиях в Redis. Это очень быстрое хранилище, идеально подходящее для подобного рода задач. Нам необходимо отсортировать документы хранящиеся в ElasticSearch (выборка по запросу) по данным которые храняться в Redis (голосам пользователей).
Начиная с версии 0.90.4 Elasticsearch предоставляет механизм Function Score Query(далее FSQ). Это довольно гибкое решение. В общем FSQ разрешает “вручную” вычислять вес документа, используемый при сортировке выдачи.
Нам достаточно того, что FSQ позволяет:
Следует заметить, что для установки callback необходимо написать плагин Elasticsearch.
Здесь я приведу упрощенный код плагина по которому проще будет понять основную идею:
Что делает этот плагин?
Схема поясняющая решение.
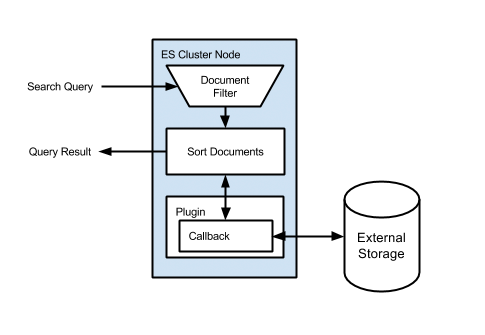
Как видно сначала исполняется любой стандарный запрос ElastiSearch, затем для каждого документа исполняется скрипт Custom Score. Вот как выглядит запрос:
Вроде бы все довольно просто. Запрос пришел на одну из нод ES, ушел на шарды и другие ноды. Каждый шард посчитал выполнил запрос, сбегал за дополнительными данными в Redis и вернул результаты ноде инициатору. Но есть подводные камни.
Обратим внимание на «для каждого документа исполняется скрипт Custom Score». Что это значит?
Например ваш query в ElasticSearch нашел один миллион документов. После этого для каждого этого документа надо сходить в Redis и взять оттуда количество голосов. Даже если мы успеваем обернуться за 1ms получется 16 минут. На самом деле конечно меньше, потому что запрос пошел параллльно с нескольких шардов, но все равно цифра будет внушительная.
Для каждого решение этой проблемы будет своим.
Например можно хранить важные данные в памяти на тех же нодах что и ES. Можно разнести горячие данные и холодные данные. В нашем случает мы понимали, что по прошествии 2 суток в с момента публикации статья перестает получать голоса, и их можно сбросить в ES — переиндексировать документ со значением накопившихся голосов. А для свежих статей мы берем голоса из Redis.
Описанное решение конечно гораздо сложнее того, что можно получить одним запросом к MySql.
Однако мы используем ElasticSearch в качестве основного хранилища из-за необходимого функционала поиска и больших масштабов, и в таком случае подобные подходы оправданны и работают.
Посмотреть как работает система можно здесь:
https://play.google.com/store/apps/details?id=com.indxnews
На написание этой статьи меня сподвигло практически полное отсутствие информации о спаривании ElasticSearch с другими системами (бд), и построении полноценного сервиса в качестве основного хранилища которого выступет ElasticSearch.
Как мы уже писали в своем проекте Indexisto мы используем ElasticSearch в качестве основного хранилища. Это позволяет нам масштабировать систему под десятки миллионов документов без лишних телодвижений и при этом сохранять отклик измеряемый десятками миллисекунд.
Если вкратце про наш проект — это браузер читалка всего на свете: сайтов, пабликов, GIF, Youtube. Каждый документ представляет из себя страничку со статей (или постом в паблике например). Документы имеют мета информацию: сайт этого документа, оригинальный url, теги и тд. ElasticSearch нам позволяет делать очень быстрые пересечения для построения фидов по интересам (несколько сайтов в одном фиде), а также функциональность Google Alert, когда можно создать фид по любому словосочетанию.
Проблемы начались когда мы решили добавить в наше приложение возможность голосований и возможность сортировать документы по популярности.

И так обо всем по порядку.
В сортировке по числовым значениям (кол-во голосов) для ElasticSearch нет никаких сложностей, а вот записывать голоса напрямую в эластик нельзя. Elasticsearch построен на базе Lucene и использует append-only хранилище. Т.е. обновление документов фактически отсутствует. Каждое изменение документа приводит к его переиндексации и влечет периодическое перестроение сегментов хранилища. Нужно помнить, что индексация ресурсоёмкий процесс. “Забороть” его железом(и верно подобранными настройками!) возможно, но встает вопрос целесообразности.
Задача
Мы храним данные о голосованиях в Redis. Это очень быстрое хранилище, идеально подходящее для подобного рода задач. Нам необходимо отсортировать документы хранящиеся в ElasticSearch (выборка по запросу) по данным которые храняться в Redis (голосам пользователей).
Решение FUNCTION_SCORE_QUERY
Начиная с версии 0.90.4 Elasticsearch предоставляет механизм Function Score Query(далее FSQ). Это довольно гибкое решение. В общем FSQ разрешает “вручную” вычислять вес документа, используемый при сортировке выдачи.
Нам достаточно того, что FSQ позволяет:
- установить callback(java), на вход которого поступает очередной документ из выборки
- присваивает переданному на вход документу вес(поле “_score”), равное результату вычисленному в callback-е.
Следует заметить, что для установки callback необходимо написать плагин Elasticsearch.
Здесь я приведу упрощенный код плагина по которому проще будет понять основную идею:
public class AbacusPlugin extends AbstractPlugin {
@Override
public String name() {
return "myScore.plugin";
}
@Override
public String description() {
return "My Score Plugin";
}
// called by Elasticsearch in a initialization phase(reflection magic)
public void onModule(ScriptModule module) {
module.registerScript(
"myScore", // NOTE: script name
MyScriptFactory.class
);
}
/*
* Script Factory should implement NativeScriptFactory
*/
public static class MyScriptFactory implements NativeScriptFactory {
// Some Score Calculation Service
private final MyScoreService service;
public MyScriptFactory() {
service = new MyScoreService();
}
@Override
public ExecutableScript newScript(
@Nullable Map<String, Object> params // script params
) {
return new AbstractDoubleSearchScript() {
/*
* called for every filtered document
*/
@Override
public double runAsDouble() {
// extract document ID
final String id = docFieldStrings("_uid").getValue();
// extract some other document`s field
final String field = docFieldStrings("someField").getValue();
// calc score by ID and some other field
return service.calcScore(id, field);
}
};
}
}
}
Что делает этот плагин?
- регистрирует скрипт сортировки в функции onModule
- реализует фабрику скриптов в классе MyScriptFactory который имплементит интерфейс NativeScriptFactory
- создает сам класс сортировки наследуясь от абстрактного класса: AbstractDoubleSearchScript
- класс сортировки реализует функцию runAsDouble (предполагается что возвращаемя вычисленная score будет double)
- функция runAsDouble вызывается для каждого документа который попал в выборку запроса. Доступ к содержимому документа обеспечивает функция абстрактного класса AbstractDoubleSearchScript.docFieldStrings
- в коде плагина вы так же видите сервис MyScoreService() которые собственно и отвечает за присвоение новых score документам. Этот сервис и ходит в Redis за значениями количества голосов. В вашем случае это может быть любой другой сервис, который ходит куда угодно
Схема поясняющая решение.

Как видно сначала исполняется любой стандарный запрос ElastiSearch, затем для каждого документа исполняется скрипт Custom Score. Вот как выглядит запрос:
{
"function_score": {
"boost_mode": "replace", // to ignore score
"query": ..., // some query
"script_score": {
"lang": "native",
"script": "myScore" // script name
"params": { // script params(optional)
"param1": 3.14,
"param2": "foo"
},
},
}
}
Проблемы
Вроде бы все довольно просто. Запрос пришел на одну из нод ES, ушел на шарды и другие ноды. Каждый шард посчитал выполнил запрос, сбегал за дополнительными данными в Redis и вернул результаты ноде инициатору. Но есть подводные камни.
Обратим внимание на «для каждого документа исполняется скрипт Custom Score». Что это значит?
Например ваш query в ElasticSearch нашел один миллион документов. После этого для каждого этого документа надо сходить в Redis и взять оттуда количество голосов. Даже если мы успеваем обернуться за 1ms получется 16 минут. На самом деле конечно меньше, потому что запрос пошел параллльно с нескольких шардов, но все равно цифра будет внушительная.
Решение проблемы
Для каждого решение этой проблемы будет своим.
Например можно хранить важные данные в памяти на тех же нодах что и ES. Можно разнести горячие данные и холодные данные. В нашем случает мы понимали, что по прошествии 2 суток в с момента публикации статья перестает получать голоса, и их можно сбросить в ES — переиндексировать документ со значением накопившихся голосов. А для свежих статей мы берем голоса из Redis.
Выводы
Описанное решение конечно гораздо сложнее того, что можно получить одним запросом к MySql.
Однако мы используем ElasticSearch в качестве основного хранилища из-за необходимого функционала поиска и больших масштабов, и в таком случае подобные подходы оправданны и работают.
Посмотреть как работает система можно здесь:
https://play.google.com/store/apps/details?id=com.indxnews