

Я помню то замечательное время, когда сборка релизной версии мобильного приложения сводилась к тому, что нужно было выставить debug = false и запустить экспорт apk-файла. Проходит 2 минуты, пока пыхтит IDE, и все готово. Все усилия сосредотачивались на необходимости указать данные сертификата подписи. Это было совсем недавно. Cейчас процесс сборки того самого приложения разросся настолько, что, если мне, вдруг, потребуется выполнить все операции самостоятельно, и даже если я все вспомню и проделаю безошибочно (во что я не верю), то это займет не час, который сегодня кажется непозволительно долгим, а, скорее всего, сутки, после чего терапевт обязан будет прописать мне больничный по усталости недели на две.
Итак, процесс сборки мобильного приложения. Попробую рассказать, из чего он у нас состоит — не потому, что в последнее время стало модным катать посты о CI той или иной мобильной команды (с покером, русалками и прочими обязательными атрибутами), а потому, что это отличный опыт, который я получил, работая над Почтой Mail.Ru для Android, и потому, что этой возможности, вероятнее всего, не было бы, работай я в другой команде, над другим проектом или в другой компании.
Для любого процесса важным решением является выбор системы, на базе которой будет строиться вся сборка. Билдами должен заниматься билд-сервер. Это логично. Но какой выбрать?
Вопрос неоднозначный, каждый выбирает то или иное решение, основываясь на своем опыте, на задачах, которые стоят перед системой, и на ресурсах, которыми он располагает. Кому-то нравятся бесплатные решения, потому что не нужно объяснять своему руководителю, на что тебе потребовались $N000 в год и почему нельзя без этого обойтись. Кого-то мотивирует наличие community или опыт огромного числа команд, которые этими решениями уже воспользовались и довольны результатом. Количество точек зрения стремится к количеству людей, которые задавались этим вопросом. Я не могу сказать, что чей-то аргумент верный, или чье-то возражение несущественно. Зато, каких бы взглядов ни придерживался разработчик, столкнувшийся с такой проблемой, большинство согласится, что по большому счету все популярные решения, представленные на рынке, отличаются лишь удобством настройки, интеграцией со смежными системами, возможностями расширения и поддержкой со стороны community либо разработчиков системы.
В общем, выбор билд-сервера — это тема для отдельного холивара. Скажу лишь, что мы выбрали Atlassian’овское решение Bamboo Build Server. Основных причин несколько, одна из них — простота интеграции с issue tracker’ом, который мы используем в проекте, а также с системами code review и хостинга репозиториев. В этом ребята молодцы: все удобно, все под рукой, и, что самое важное, практически все предусмотренные решения и опции отлично вписываются в процесс разработки нашей команды
Bamboo
Bamboo — весьма распространенное решение, его использует огромное количество команд во всем мире. Подробно со схемой работы этого CI/CD Tool можно ознакомиться на сайте официальной документации, я же позволю себе вольный перевод небольшой части этого документа во избежание разночтений в терминологии.
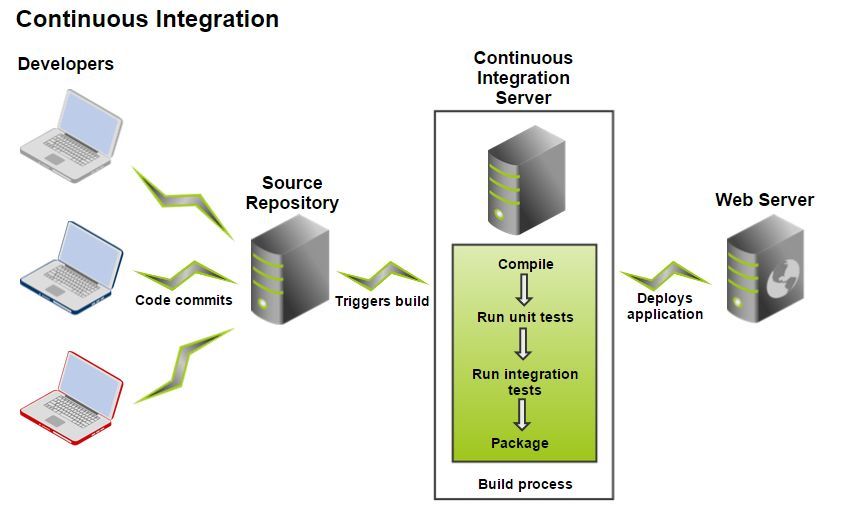
Задача Continuous Integration сервера заключается в том, чтобы выполнить всю работу по сборке, тестированию, деплою в тестовую среду проекта. CI сервер связывается с репозиторием, получает определенную ревизию проекта, выполняет все необходимые действия и предоставляет готовый результат сборки команде проекта.
| Проект |
|
| Билд-план (Plan) |
|
| Стадия (Stage) |
|
| Работа (Job) |
|
| Задача (Task) |
|
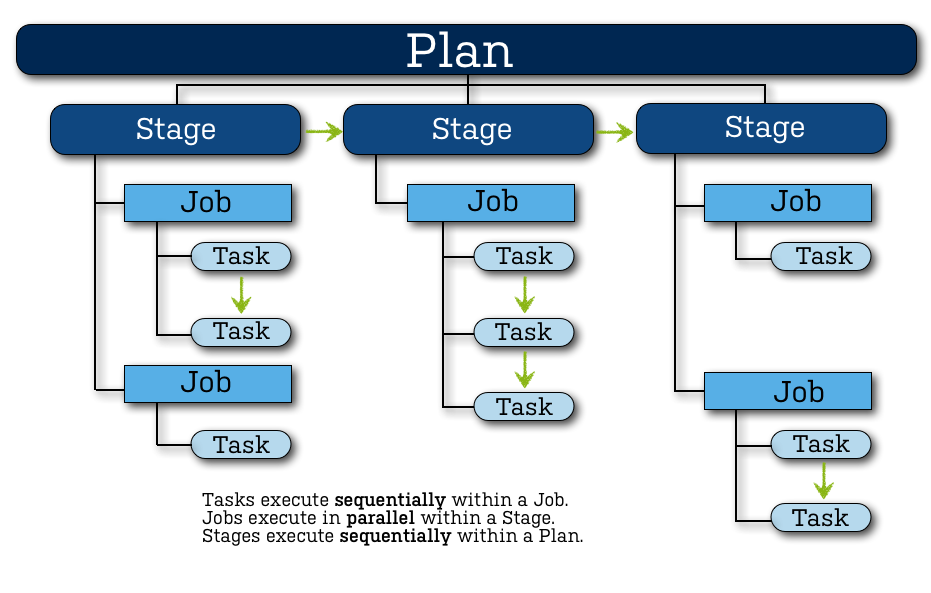
Более или менее схожее разделение доступно в любой системе сборки, оно обеспечивает необходимую гибкость в построении всего процесса. На первый взгляд кажется, что это чрезмерное усложнение. Так было и с нашим проектом, когда мы только начали использовать Bamboo, но постепенно все устаканилось, появилось четкое понимание того, какая часть всего процесса сборки должна быть масштабирована, какая должна оставаться изолированной, и в рамках предложенных концепций сложилась достаточно стройная структура.
В целом, нужно хорошо понимать, что билд-сервер или CI-сервер — это важная часть автоматизации процесса разработки ПО. Возлагая на этот модуль все задачи и работы, которые необходимо проделать на разных этапах и уровнях подготовки приложения к релизу в маркет, мы получаем своеобразный Application Release Pipeline. Он, в свою очередь, дает возможность легко определить, какие задачи вошли в тот или иной билд, на каком этапе сейчас релиз, какие проблемы возникают при интеграции нового функционала, на какой стадии подготовки hotfix’a мы сейчас находимся и многое другое.
Итак, мы плавно подошли к описанию того, как это сделано в нашей команде.
Задачи
Наш проект сборки разделен на несколько стадий, отражающих основные задачи на текущий момент:
- Сборка — включает в себя все варианты сборки, которые могут понадобиться по ходу Release pipeline: alpha, beta, release. Да-да, у нас отличаются именно сборки проекта, а не только их статус. Различия продуктовые: различные ресурсы, наличие или отсутствие настроек и т.д.
- Проверка — самая емкая и технически сложная часть всего этапа сборки приложения: статический анализ кода, юнит-тестирование, функциональное UI-тестирование, проверка локализации.
- Деплой. В настоящий момент абстрагированн от всей сборки, он как бы находится сбоку. Таким образом, в случае необходимости мы можем задеплоить в любую среду (альфа, бета, релиз) какую угодно ревизию/ветку/тип приложения.
На этом, в принципе, можно и закончить рассказ, но я, пожалуй, проявлю назойливость и предоставлю подробности.
Сборка
Сейчас мы разрабатываем сразу три проекта с единой code base, назовем их Проект 1, Проект 2 и Проект 3. Конечно, различия между ними не такие радикальные, как между шахматами и видеоплеером, так как все три продукта относятся к категории почтовых клиентов. Тем не менее, у них разный дизайн, есть отличия в функционале, они по-разному взаимодействуют с сервером. Все это диктует свои требования к сборке, тестированию и разработке продукта.
Feature Branch Workflow
Любая сборка начинается с чекаута ревизии проекта из системы контроля версий. Казалось бы, зачем на этом заострять внимание — ведь чекаут может сделать каждый? Действительно. Но из какой ветки стоит это сделать?
Мы для работы над продуктом используем Feature Branch Workflow. Об этом подходе можно почитать отдельно. Главное его преимущество для меня — изолированность изменений. При таком подходе каждый разработчик может в рамках задачи перевернуть хоть весь проект, отдать это в тестирование, и если QA даст аппрув, то проверенный и функционирующий код попадет в общую ветку. Данный подход минимизирует риски попадания дефекта в релиз, за счет того, что определена последовательность действий: сначала проверка, потом мердж в основную ветку проекта.
Чтобы проверить эти изолированные изменения, у нас должна быть сборка, на которой мы сможем прогнать автотесты, и которую мы отдадим в ручное тестирование на одобрение от команды QA. Bamboo предоставляет из коробки необходимое для этого решение. Называется оно Branch Plan и заключается в том, что у билда определяется главная ветка (например, alpha), а все ветки, которые матчатся по указанному шаблону, рассматриваются как feature branch. Для них создается клон билд-плана, но с той разницей, что чекаут будет происходить из этой ветки, а не из главной ветки билд-плана. Выглядит это примерно так.
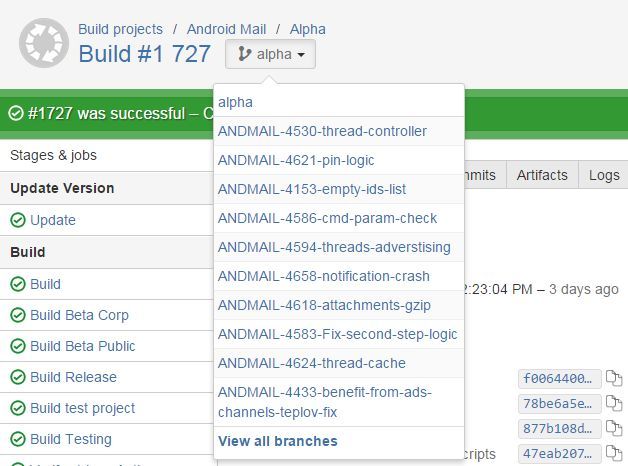
В просмотре билд-плана мы можем переключаться между основной веткой и существующими бранчами, просматривая результаты всех локальных статусов.
Сам branch plan выглядит так же, за исключением того, что имеет ссылку на задачу.

С таким флоу ветка неизбежно начинает устаревать с того момента, как ее создали. Для раннего обнаружения конфликтов с основной веткой, чтобы тестировался актуализированный код, нужно постоянно обновлять свою ветку во время разработки. Bamboo умеет это делать автоматически перед тем, как начнет собирать проект. В случае конфликта сборка не испечется, а разработчик должен будет сначала проапдейтить свою ветку и потом уже пушнуть эти изменения. Тогда перед сборкой конфликта не будет, и все пойдет своим чередом.
Product Flavors
Допустим, у нас есть проект, который нужно собирать в нескольких вариациях, изменяя ресурсы, код и конфиги. Существует несколько вариантов того, как это реализовать. Мы руководствовались тем, что все условия сборки, все конфигурации и прочая описательная часть должны находиться в скрипте сборки. В нашем случае для решения этой задачи идеально подходит Gradle. Для него есть хороший Android-плагин, который позволяет гибко настраивать большинство стандартных и нестандартных параметров для сборки сложного проекта.
Давайте разберемся, сколько вариантов сборки мы активно используем и поддерживаем.


Начнем с того что у нас три основных Product Flavors: Проект 1, Проект 2 и Проект 3.
Product Flavor — это представление ветки продукта. В большинстве случаев это разные приложения, которые имеют разные пакеты, разные сертификаты подписи, разные исходники и ресурсы. Для каждого приложения у нас есть несколько вариантов сборки, а именно:
- debug — подписывается дебажным ключом, может отлаживаться, не обфусцируется;
- alpha/branch alpha — обфусцированная сборка, отличается конфигами для аналитики, сборками крешей, ресурсами, дебажными настройками, доступными в приложении;
- beta corp — бета-версия, которая имеет включенные логи, доступный отладочный режим;
- beta — максимально приближенная к релизу сборка, которая отличается аналитикой, сборкой крешей, имеет выключенные логи, отладочный режим и не имеет дебажных настроек;
- release — продакшн-версия приложения, практически все дополнительные опции выключены, аналитика и сбор статистики настроены на боевые проекты в этих системах и т.д.;
- unit/UI testing — сборки, которые имеют перезаписанные манифесты, что позволяет, например, включить разрешения на чтение SMS, необходимых для автоматизированного тестирования входа (авторизация, регистрация, двухфакторная авторизация) с использованием SMS-кода.
Итого:
8 Build Types * 3 Product Flavors = 24 Application Variants
Зачем столько? Попробую ответить. Одна из типичных задач, которую приходится решать, имея три разных продукта, которые публикуются в разные среды, — разделять аналитику. И делать это необходимо, иначе статистика из альфа-версии приложения будет искажать существующую в продакшне картину. Для сбора статистики по крешам мы используем HockeyApp. В нем у нас раздельные проекты по разным вариантам сборки. Это позволяет легко отделять, например, креши Проекта 1 от крешей Проекта 2, бета-версию от релизной версии и т.д.
В build.gradle нашего проекта этот конфиг выглядит следующим образом.
productFlavors {
project1 {
...
android.buildTypes {
alpha {
hockeyApp {
[appId: 'b45-------1b', note: project.issues, releaseType: '2']
}
}
beta {
hockeyApp {
[appId: 'c9d-------86', note: {''}, releaseType: '0']
}
}
publicBeta {
...
}
release {
...
}
}
}
project2 {
...
android.buildTypes {
alpha {
hockeyApp {
[appId: '1ac-------73', note: project.issues, releaseType: '2']
}
}
...
}
}
project3 {
...
android.buildTypes {
alpha {
hockeyApp {
[appId: 'dcd-------3c', note: project.issues, releaseType: '2']
}
}
...
} }
Таким образом, мы можем конфигурировать различные значения для любых вариантов сборки. Что касается ресурсов и исходников, здесь используется примерно тот же принцип, за исключением одной особенности: есть возможность мерджить ресурсы из разных вариантов. В нашем проекте есть ресурсы, одинаковые для всех приложений — например, разметка экрана написания письма. Если бы такие файлы приходилось копировать в каждый пакет ресурсов и держать отдельно, то при изменении верстки экрана написания письма нужно было бы менять аж три файла. К счастью, gradle + android plugin умеют делать мердж ресурсов.
Расскажу чуть подробнее, как это происходит — возможно, кто-то сможет решить свои повседневные задачи, используя тот же подход.
Мы определили несколько папок с ресурсами (все они лежат в корне проекта).
- res — общие ресурсы для всех вариантов приложения: здесь лежат общие селекторы, разметки, темы, стили и т.д.;
- res_project1 — ресурсы, которые уникальны для Проекта 1: сюда попадает практически вся графика, которая используется в приложении, строки, которые содержат название проекта, специфичные логотипы или разметку — в общем, все, что относится только к Проекту 1;
- res_project23 — здесь немного другая картина: в пакет res_ project23 попадают все ресурсы, которые не пересекаются с Проектом, но одинаковы для Проекта 2 и Проекта 3. Подобная группировка ресурсов помогает решить проблему, когда продуктово Проекты 2 и 3 очень похожи между собой, при этом достаточно сильно отличаются от Проекта 1. В противном случае, пришлось бы копировать одни и те же ресурсы в папки res_project2 и res_project3;
- res_ project2 — ресурсы, уникальные для Проекта 2: на данный момент это цвета, графика, тексты. Все остальное лежит в общих пакетах;
- res_ project3 — аналогично для Проекта 3, в этом пакете остается только уникальная подборка ресурсов для этого приложения.
В результате для каждого билд-варианта мы мерджим несколько пакетов, чтобы получить общий набор ресурсов для приложения:
- Проект 1 = res + res_project1;
- Проект 2 = res + res_project23 + res_ project2;
- Проект 3 = res + res_project23 + res_ project3.
Это основа. Для более глубокой кастомизации можно, например, добавить специфичные ресурсы, код для тестовой сборки и т.д. Весь closure с исходниками выглядит у нас примерно так:
sourceSets {
main {
manifest.srcFile 'AndroidManifest.xml'
java {
srcDir 'src'
exclude '**/instrumentTest/**'
}
resources.srcDirs = ['src']
aidl.srcDirs = ['src']
renderscript.srcDirs = ['src']
res.srcDirs = ['res']
assets.srcDirs = ['assets']
}
androidTest {
manifest.srcFile 'src/instrumentTest/AndroidManifest.xml'
java.srcDir 'src/instrumentTest/Java'
}
project2 {
res.srcDirs = ['res_project2', 'res_project23']
java.srcDirs = ['src_common']
assets.srcDirs=['assets_ project2]
manifest.srcFile 'res_ project23/AndroidManifest.xml'
}
project3 {
res.srcDirs = ['res_project3', 'res_ project23]
assets.srcDirs=['assets_project3']
java.srcDirs = ['src_project3']
manifest.srcFile 'res_ project23/AndroidManifest.xml'
}
project1 {
res.srcDirs = ['res_project1']
java.srcDirs = ['src_common']
assets.srcDirs=['assets_project1']
manifest.srcFile 'res_project1/AndroidManifest.xml'
}
testingUi {
manifest.srcFile 'ui_testing/AndroidManifest.xml'
}
}
Осталось дело за малым. В конфиге билд-проекта нужно запустить правильный таск для того, чтобы получить желаемую .apk, например, gradle assembleProject1PublicBeta. Естественно, при наличии такого большого числа вариантов сборки мы решили не собирать их все последовательно, а распараллелить этот процесс. Итого мы получили 6 параллельных работ, которые выполняются в рамках стадии сборки. Каждая работа публикует 3 артефакта на каждый продукт.
Предполагаю, что у тех, кто дочитал до этого момента, появился вопрос: а зачем же собирать бету и релиз при каждой сборке проекта? Вопрос, действительно, очень интересный. Мы пришли к этому решению не сразу, а спустя много времени. Исторически бета и релизные сборки строились отдельно, используя ту же ревизию либо контракт о том, что код там тот же самый. Потом мы поняли, что такой подход таит в себе много проблем, а самая неприятная заключается в том, что статус сборки ты узнаешь уже после того, как принял решение опубликовать бету. По закону Мерфи, естественно, билд оказывается красным. По любой причине. Чем больше изменений, тем больше вероятность того, что они негативно повлияют на сборку, причем мы не можем ничего с этим сделать. Можно только сократить временной интервал между моментом внесения ошибки и моментом ее обнаружения. А в идеальном случае еще и сделать это изолированно от общей ветки. Если абстрагироваться от проекта и сборки именно бета или релизной версии и посмотреть на процесс автоматизации, то одним из основных показателей качества всего подхода к автоматизации билд-процесса мне сейчас видится, наверное, возможность узнать о возникших проблемах максимально быстро, а самое главное — узнать ДО того, как эти изменения попали в общую ветку.
Проверка
Автоматическая проверка качества в мобильных приложениях — это, безусловно, тренд последнего года. По моему опыту, для многих это остается чем-то нереальным. Все об этом говорят, но практически никто не видел. Мы занимаемся такими задачами в рамках нашего проекта уже 2 года, и за это время уже сложилось довольно четкое понимание большинства тонкостей, с которыми приходится сталкиваться любому разработчику. Все эти проблемы и решения являются достаточно новым и неустоявшимся сегментом для мобильных приложений, хотя веб уже давно прошел этот путь и имеет достаточное количество стандартизированных решений.
Первый вопрос, который возникает у большинства: что же мы будем автоматизировать? Разработчик ответит: мы будем тестировать код, менеджер тут же начнет спорить, что тестировать нужно функционал. Я считаю, что тестировать нужно и то и другое.
Вообще, если говорить о нашем приложении, то все проверки делятся на несколько категорий:
- Статический анализ: я не знаю, почему этому подходу уделяется так мало внимания, это очень мощный инструмент, позволяющий применять формализованные правила ко всему проекту, а не к отдельным классам;
- UnitTesting: старые добрые юнит-тесты, которые позволяют убедиться в том, что класс работает именно так, как ожидает разработчик или пользователь этого класса;
- UiTesting: функциональные/end-to-end тесты, которые проверяют конечный результат: то, что увидит пользователь, и как он будет с этим работать.
Статический анализ
В качестве статического анализатора мы используем уже готовые решения. Для Android это Lint, который стал за последнее время весьма эффективным инструментом, позволяющим следить за качеством android-specific кода, ресурсов разметки, графики и т.д. Помимо всего прочего, он позволяет добавлять свои проверки, специфичные для контракта внутри проекта. Одним из таких контрактов является то, что никакие layout-related параметры не должны находиться в стилях. Например, свойства layout_margin\ layout_alignParentTop или что-то подобное. С точки зрения синтаксиса никто не запрещает выносить эти свойства в стили, но в таком случае сам стиль используется не для определения визуальной составляющей какого-то UI-компонента, а для хранения каких-то значений, которые потом можно не писать в файле разметки. Другими словами, стиль используется как контейнер атрибутов. Мы решили, что это разные вещи, которые стоит разделять, потому что, во-первых, LayoutParams все-таки относятся к разметке, а во-вторых, они относятся не к тому контролу, в тэге которого эти атрибуты прописываются, а к его паренту, в котором он лежит.
Если разобраться, то в любом более или менее состоявшемся проекте, в котором есть гайды по написанию кода, ресурсов разметки, присутствуют шаблоны для решения типичных для этого приложения задач, таких вещей достаточно много. Их можно отслеживать на этапе код-ревью, документировать, напоминать о них каждый раз в начале рабочего дня или же рассчитывать на то, что, однажды ознакомившись с этими пожеланиями, в дальнейшем все будут их выполнять. Как говорится, блажен кто верует, но лично мне намного спокойнее работать, зная, что я сам об этом не забуду и ничего не пропущу, торопясь скорее закрыть надоевший таск. Нужно формализовать такие проверки, добавить их в процесс сборки с удобными отчетами и не беспокоиться о том, что, взявшись за новую задачу, ты неожиданно обнаружишь проскочивший все проверки код, от которого волосы дыбом встают.
Писать свои проверки достаточно легко, даже увлекательно. По ходу добавления любых статических проверок сразу появляется куча идей, как статически выявлять какие-то другие проблемы. Для Lint в этом помогут гайды и официальная документация. Разрабатывать правила можно прямо в Android Studio.
tools.android.com/tips/lint-custom-rules
tools.android.com/tips/lint/writing-a-lint-check
Для java-кода также есть давно изобретенные статические анализаторы. Я не буду перечислять все, расскажу только о том, что мы используем FindBugs. Когда мы выбирали инструмент, то хотели получить удобный формат, достаточный объем правил, по которым будет осуществляться проверка, и возможность добавления своих правил. На данный момент мы написали необходимые проверки, такие как проверка закрытых курсоров, проверка того, что инстанс AccountManager’a получается всегда с application context’ом, проверка того, что обязательный для вызова метод onEventComplete вызывается при шаблонных использованиях класса событий, и другие. Добавлять свои правила, которые будут определять внутрикомандные договоренности, предотвращать распространенные ошибки из-за невнимательности — это отличная практика, которая сокращает время на код-ревью и тестирование, а также гарантирует, что такие ошибки как минимум не попадут в будущем в продакшн-версию приложения. В качестве пособия по написанию проверок мы использовали статью FindBugs, Part 2: Writing custom detectors. Там наглядно показано, как создавать свой плагин, добавлять детекторы и использовать это в процессе проверки. Отчет предоставляется либо в отформатированном HTML-документе, либо в виде XML-отчета, где коротко и по делу написано, в каком классе/методе найдена ошибка, код ошибки, строка и т.д. Этого обычно достаточно, чтобы понять, где ты только что не убрал за собой :-).
Замечательно, не правда ли? Огромный набор правил и распространенных ошибок уже готов, есть и возможность его дополнить, остается только найти в себе смелость и приступить к использованию.
Однажды я обратил внимание на то, что в нашем проекте используются SNAPSHOT версии библиотек. Очевидно, что это допустимо только в бранче для задачи, когда эти изменения вносятся в используемую библиотеку. После того как код влит в основную ветку, никаких SNAPSHOT’ов в проекте быть не должно. В данном случае причина достаточно прозаична и характеризует большинство подобных ошибок. После того как задачу протестировали и решили, что эта версия достигла всех definition of done, разработчик был настолько счастлив, что забыл влить библиотеку в основную ветку, определить новую версию этой библиотеки и поменять версию в основном проекте. Проблема в том, что ни Lint, ни FindBugs не могут проверить скрипт сборки. Более того, даже если эти проверки добавить в сам build.gradle, то необходимо знать, где это допустимо, а где нет. Очевидно, что это допустимо в бранче, в котором сейчас и меняется библиотека, но недопустимо после того, как он попадает в общую ветку. Вот так мы начали использовать git pre-receive хуки для того, чтобы следить за происходящим в проекте на уровне репозитория.
Я знаю, что многие команды не считают нужным тратить время на настройку правил, подходящих для проекта на уровне системы контроля версий, т. к. “у нас нет дураков, никто не будет удалять все ветки в репозитории”, или по каким-то другим причинам, например, из-за нехватки времени. Для нас это пройденный этап: мы пришли к решению, что лучше потратить немного больше времени, но быть уверенными в безопасности и качестве продукта. Для этих целей pre-receive хуки подходят очень хорошо: мы можем определить, что изменения добавляются в общую ветку, и проверить, что HEAD этой общей ветки не содержит нежелательного кода. В лучшем случае никто никогда не узнает о наличии такой проверки, но, как показывает практика, достаточно случайной ошибки, чтобы появилась возможность знатно проколоться. Pre-receive hook отлично подойдет для проверки всех исправленных TODO и FIXME, которые разработчик охотно расставляет, но забывает исправить. Он, также, прекрасно справляется с типичными проблемами логирования, — добавлением вывода new Throwable() ко всем интересующим разработчика функциям, потому что в ветке нашелся очень сложный и требующий множества деталей баг. Для нас, возможность отслеживать совершенные ошибки автоматически важна для понимания того, что мы не наступим еще раз на те же грабли. Ошибки совершают все, важно лишь какие выводы ты после этого делаешь. Наш вывод состоит в том, что помимо исправления, нужно приложить усилия к тому, чтобы эти ошибки впредь не совершать.
Unit Testing
Здесь по большому счету все обыденно. Для некоторых классов написаны проверки, которые позволяют убедиться, что класс работает именно так, как задумывалось, и заодно показывают клиенту класса пример, как им можно воспользоваться. В данный момент юнит-тесты запускаются на реальных устройствах но не устанавливают реальное соединение, если это необходимо. Кстати, о необходимости устанавливать соединение: когда разработчик размышляет, как тестировать тот или иной модуль, чаще всего он первым делом думает, каким образом подменить зависимости класса, чтобы изолировать тестирование от действующей среды. В случае с сетевым соединением это может показаться непростой задачей, потому что сетевое взаимодействие не заменяется вызовом одного метода, требует мокать целый слой логики. Мы некоторое время сопротивлялись тому, чтобы с помощью хука в коде приложения подменять ответ сервера и выполнять все последующие действия с ним. Дело в том, что такой подход увеличивает риск того, что тестироваться будет не тот код, который работает в боевом приложении. Каждый раз, когда встает вопрос, стоит ли менять интерфейс класса для удобства тестирования, стоит ли добавлять в процесс выполнения функции дополнительные условия, чтобы «замокать» какие-то зависимости, я стараюсь придерживаться следующей позиции: в первую очередь весь написанный код должен быть безопасен с точки зрения функций приложения. Если дополнительные условия, добавленные в код, требуют отдельной проверки, то для тестов не нужно этого делать. Это главная причина, по которой нас не устроил обычный сеттер, который бы просто заменял ответ, брал бы его из другого источника.
В итоге мы пришли к другому решению, на мой взгляд, более честному. Вот так выглядит один из тестов, который проверяет, что при определенном ответе команда выдает статус “error_folder_not_exist”
@AcquireCookie
@LargeTest
public void testDeleteNonExistingFolder() {
DeleteFolder delete = runDeleteFolder(999);
assertERROR_FOLDER_NOT_EXIST(delete);
}
В этом тесте мы делаем честный запрос на сервер, то есть команда работает абсолютно так же, как и в приложении. Проблема в том, что юнит-тест зависит от того, как настроена сеть на устройстве, на котором он выполняется. А ниже идет второй тест, который проверяет абсолютно то же самое, но уже подставляя желаемый ответ, не выполняя реального запроса и не взаимодействуя с сервером.
@MockMethod(response = RESPONSE_NOT_EXISTS)
public void testDeleteNonExistingFolderMock() {
testDeleteNonExistingFolder();
}
Таким образом, мы имеем возможность управлять выполнением тестов — это нужно, например, для того, чтобы статус билда не учитывал ответ сервера. Мы полагаемся на то, что протокол взаимодействия описан, и, убедившись в корректности формирования запроса (с помощью юнит-тестов, разумеется), можем быть уверены, что сервер даст корректный ответ. А при корректном ответе остается лишь убедиться в том, что приложение его интерпретирует соответствующим образом. Однако, например, для ночной сборки неплохо было бы убедиться еще и в том, что не нарушен контракт взаимодействия с сервером. Для этого будут запускаться все тесты, в том числе и те, которые реально с ним взаимодействуют. Это даст нам дополнительную подушку безопасности на случай, если из-за какого-то бага контракт взаимодействия с сервером нарушен. Мы узнаем об этом из результатов тестов, а не из пользовательских отзывов в маркете. Если для нас так важно проверять функционал от начала до конца, то можно сделать эти тесты основными и выполнять их для каждой сборки приложения.
Дело в том, что мы не хотим постоянно зависеть от сервиса, но при этом нам нужно мониторить ситуацию и в виде ежедневных отчетов получать информацию о том, что все хорошо, или же о том, что какая-то часть приложения не в порядке. Здесь я предпочитаю разделять наше приложение и сторонние сервисы, которые критичны для его полноценной работы, но не являются зоной нашей ответственности. Мы можем обнаружить в нашем приложении проблему, связанную с работой стороннего сервиса, но не можем ее исправить. Наша задача состоит в том, чтобы сообщить о проблеме, дождаться исправления и прогнать тесты на работу с этим сервисом, чтобы убедиться в том, что проблема устранена.
UI Testing
С точки зрения пользователя, это самые честные тесты. С точки зрения разработчика — самые сложные. Самые честные, потому что тестируют конечный продукт, а не какую-то его часть. Свалить вину на кого-то другого не выйдет: любой баг — это баг приложения, и неважно, в чем его причина, в несовершенстве Android в кривых руках другого разработчика или в чем-то еще. В любом случае, ошибку нужно исправить. К преимуществам такого black-box тестирования можно отнести и то, что для нас, по сути, нет разницы, как реализован функционал, какая архитектура у приложения и т. д. Если два бага в приложении наложились друг на друга, и в итоге пользователь увидел правильный результат — нас это устраивает. Если во всем множестве случаев баги приложения позволяют получать корректные результаты для пользователя — нас это устраивает с точки зрения проверки функционала.
Если юнит-тесты проверяют, работает ли код именно так, как задумывал разработчик, то UI-тесты скорее предназначены для того, чтобы продуктовая команда убедилась в корректности выполнения пользовательских сценариев в приложении.
На пользовательские сценарии также завязаны и баги. Один из лучших способов исправить баг приложения, получив сценарий его воспроизведения, — написать тест. Убедиться в том, что проблема присутствует. Исправить проблему в коде приложения (если нужно, то сопроводить дополнительными юнит-тестами на модуль, в котором какое-либо поведение не было закрыто) и удостовериться, что теперь тест проходит успешно. В этом случае нет необходимости задействовать весь бюрократический аппарат, в котором несколько человек должны проаппрувить, что баг исправлен, что ничего нового не сломалось и т. д. Вся соль в том, что если тест написан вдумчиво, и именно с целью обнаружения и выявления проблемы, то в случае его успешного прохождения уже есть повод считать проблему решенной. Чем больше таких кейсов закрыто тестами, тем качественнее проверка, потому что тем выше вероятность, что мы ничего не упустили.
Конечно, сделать все это намного сложнее, чем сказать. Но обо всем по порядку: начнем с выбора фреймворка, на основе которого мы будем строить свои тесты. Опять же, я не открою Америку, написав, что фреймворков сейчас достаточно много, но нельзя посоветовать какой-то один, который решит 99% всех проблем. Можно начать писать собственный идеальный фреймворк, сделав ставку на то, что ваш коэффициент кривизны рук меньше, чем у конкурентов, и надеясь, что через месяц все ваши проблемы будут решены, а через полгода, посчитав стоимость такого решения, вернуться к этому выбору вновь. Я не очень люблю делать чужую работу, и, возможно, поэтому считаю такой подход утопическим. Утопией мне видится и кроссплатформенное тестирование, потому что слишком велики различия между Android и iOS. Написать один набор тестов, который будет проверять и одно приложение, и другое, кажется очевидным решением только на первый взгляд. Разная навигация внутри приложения, разная разметка в рамках одного экрана, разное поведение системы в ответ на сворачивание приложения, не говоря уже о том, что даже функционал может отличаться, потому что любой качественный продукт будет учитывать все особенности платформы для того, чтобы предоставить пользователю наилучший опыт.
Исторически мы в проекте использовали Robotium. Это весьма известное решение, которое используется большим количеством команд как у нас в стране, так и за рубежом. Интересно, что всех его пользователей объединяет горячая нелюбовь к этому самому фреймворку. Он медленный, нестабильный, на нем неудобно писать тесты. Но все, тем не менее, регулярно возвращаются к его использованию. То ли дело Espresso! Он быстр как ветер, стабилен как экономика Соединенных Штатов и т. д. Вот что делает репутация поискового гиганта с проектами, которые он взял под свое крыло. Мы писали на Robotium 2 года, поэтому я могу довольно уверенно сказать, что ответственность за нестабильность и низкую скорость лежит скорее на клиенте, который пишет эти тесты. Давайте в этом разберемся. Причина проблем со скоростью зачастую кроется не в несовершенстве алгоритмов Robotium, не в его архитектуре, а в том что в тестах есть злоупотребление так называемым Sleep Pattern’ом. Суть его заключается в том, что любую проблему можно решить, добавив sleep(N * 1000) перед той строчкой, где проблема была обнаружена. В основе этого лежит следующая простая вещь: тесты выполняются в потоке, отличном от главного потока приложения (UI Thread). Соответственно, синхронизация, которая выполнена с помощью Sleep(), не является хорошим решением проблемы. Отсюда итог: хоть 10 секунд жди между шагами в тестах, результат гарантирован не будет. В Instrumentation-based тестах есть штука, которая ждет, когда же UI Thread приложения закончит операции, которые сейчас находятся в процессе. Класс android.app.Instrumentation имеет метод:
/**
* Synchronously wait for the application to be idle. Can not be called
* from the main application thread -- use {@link #start} to execute
* instrumentation in its own thread.
*/
public void waitForIdleSync() {
validateNotAppThread();
Idler idler = new Idler(null);
mMessageQueue.addIdleHandler(idler);
mThread.getHandler().post(new EmptyRunnable());
idler.waitForIdle();
}
Его использование, как мы на своем опыте убедились, решает большинство проблем с тем, что View не найдена, хотя скриншоты показывают, что все отображается, а также с тем, что View находится в промежуточном состоянии, анимируя свои свойства от одного значения к другому и т.д.
Естественно, истории о том, что Espresso многократно лучше, не давали нам покоя. План по переходу на этот фреймворк созрел давно; к тому же Google сейчас уделяет достаточно много внимания вопросу автоматизированного тестирования, поэтому есть предпосылки к тому, что Espresso будет развиваться активнее. Решимости добавили и убеждения Lead developer’а в том, что для перехода с Robotium на Espresso достаточно поменять TestRunner. Мы попробовали, и тесты действительно работали. Теперь мы можем, не меняя старых тестов за раз, писать новые сценарии и при этом пользоваться всеми преимуществами Espresso. Для нас это определило переход на рельсы нового фреймворка. Мы запустили тесты и замерли в ожидании результатов.
Espresso действительно оказался быстрее, хотя драматических изменений не произошло. Сейчас все наши тесты разбиты на ~26 пакетов, и в каждом было замечено ускорение. Но суммарные изменения в скорости прохождения тестов укладываются в 4%. На мой взгляд, это не является существенным преимуществом. Намного больше, с моей точки зрения, дает возможность писать аналог waitForIdleSync для любого ожидания в приложении: не только для задач интерфейса и анимации, но и для задач загрузки данных из сети и с диска — для любых взаимодействий, результатом которых мы должны оперировать, делая проверку в коде теста. Эта фича называется CustomIdlingResource и она действительно очень выгодно выделяет Espresso по сравнению с Robotium. Несмотря на то, что идея очень простая, а именно — дать возможность зарегистрировать свою реализацию интерфейса ожидания idle состояния, custom idling resource позволяет управлять синхронизацией между тестами и приложением. Таким образом можно дожидаться, когда в приложении пройдут все асинхронные операции, например, что в совокупности с idle состояние главного потока, говорит о том, что ожидание можно заканчивать и приступать к проверкам состояния приложения.
Естественно, Espresso — это не сказочный джинн. Он не может решить все ваши проблемы, он не способен написать тесты за вас, и он не в силах выполнять задачи по поддержанию тестовой инфраструктуры, запуску тестов и сбору отчетов.
Помимо тестирования непосредственно функционала внутри приложения, распространенная задача, которую приходится решать в контексте автоматизированной проверки качества, — это взаимодействие вашего продукта с другими приложениями, которые могут быть установлены на телефоне пользователя. В качестве примера можно взять, например, Sharing из другого приложения (для почтового клиента это достаточно актуально) или статус-бар уведомления. В обоих случаях сценарий затрагивает другое приложение, которое работает в другом процессе. Все Robotium/Espresso-подобные фреймворки становятся слепыми, как только дело касается другого процесса. К счастью, решение, которое позволяет писать cross-app functional UI tests, уже существует и называется UI Automator. Если раньше пришлось бы выбирать между тем или иным фреймворком либо поддерживать разные проекты, каждый из которых будет заточен под разные проверки, то с релизом Testing Support Library, анонсированной на минувшей конференции Google I/O 2015, мы можем объединить преимущества каждого подхода и использовать тот инструментарий, который потребуется в каждом отдельном случае. Это означает, что для почтового клиента, к примеру, мы можем автоматизировать такой сценарий:
- Запустить приложение, перейти в список писем.
- Открыть написание нового письма, ввести тему, получателя, прикрепить вложения.
- Получить push-уведомление на подключенный ящик.
- Перейти по уведомлению, проверить содержимое нового письма.
- Выйти с экрана нового письма по back-кнопке.Удостовериться, что мы вернулись на экран написания письма, и что все заполненные поля сохранены.
В данном примере мы можем спокойно пользоваться прежним фреймворком для того, чтобы переходить по моделям списка писем, чтения письма, написания нового письма и т.д., а для шагов 3 и 4 мы можем использовать uiAutomator framework, чтобы проверить текст уведомления, убедиться, что в уведомлении присутствуют необходимые кнопки, и перейти по уведомлению в приложение. Затем тест будет дальше использовать API Espresso, и нам не придется писать еще одну реализацию существующих моделей под второй фреймворк. Для меня как для разработчика это лучшая новость, которая могла появиться в контексте библиотек для автоматизации тестирования.
Конечно, все это кажется несложным лишь на первый взгляд. За кадром осталась куча собранных граблей и наступание в самые неприятные субстанции — порой казалось, что вся эта идея просто не может быть реализована.
В дальнейшем мы отдельно расскажем о том, как выстроена инфраструктура, как обеспечивается круглосуточная готовность устройств к работе, как распределяются тесты на разные product flavors по разным сборкам, как тестируются разные реализации в зависимости от версии операционной системы, форм-фактора устройства и т.д. Ведь у нас за плечами такие долгие два года борьбы с adb, usb, VirtualBox и многими другими инструментами и технологиями. Впереди осталось больше работы, чем уже проделано, но мы понимаем, что все это было не зря.
P.S. Мы ищем Android-разработчика в команду Почты. Если вакансия вас заинтересовала — смело пишите Марии.
Комментарии (14)

Artem_Manaenko
23.12.2015 21:07+2Офигенная статья!
Скажите, а сколько Android-разработчиков в Вашей команде?rus1f1kat0r
24.12.2015 10:50+2Спасибо, рад что понравилось :)
В нашей команде сейчас 12 человек. У нас есть разработчики, которые пилят фичи для QA, занимаются поддержкой и развитием всей инфраструктуры для автоматизации QA, остальные разработчики занимаются фичами для продукта, но тем не менее вся команда пишет тесты.

Artem_zin
23.12.2015 21:46+1юнит-тесты запускаются на реальных устройствах
Ох лол… // Robolectric, mocked android.jar, plain java модули, etc
Привет от Android команды Yandex.Mail :)rus1f1kat0r
24.12.2015 10:39+2Привет :) спасибо за коммент.
В общем, если это был не троллинг, то ответ такой:
- Я не исключаю других вариантов, я лишь хотел рассказать о том, как это делаем мы.
- Об этих техниках мы прекрасно знаем и, возможно, пользовались бы, если бы не отбросили их в самом начале. Тут более уместна формулировка «почему на девайсах?», — потому что сам по себе запуск unit тестов без девайса не дает никаких преимуществ, но в свою очередь, требует отдельной настройки. В нашем случае это отдельный вид агентов, который должен работать на отдельном железе. Отсюда различия мне на данный момент видятся такие:
- девайс дешевле
- легче перераспределяются ресурсы, если агенты универсальны (агент для юнит тестов может выполнять задачи по ui тестированию и наоборот)
- дешевле поддержка однотипных агентов.
- Ориентироваться в построении процесса сборки стоит, как мне кажется, на результат, а не на процесс, поэтому мы стараемся детально анализировать результат, получаемый от каждого изменения\нововведения, если профита нет, то тратить на какую-то плюшку свой временной ресурс мы не станем.
Одним из таких условий может быть «запрет на покупку дополнительных девайсов», у нас такой проблемы нет. - Отдельно, я бы еще отметил, что за счет такого подхода мы ловили совсем случайные баги, связанные, например, с памятью. Понятно, что это можно проверять отдельно, но это в том случае если знаешь где потенциальная проблема. В нашем кейсе, скорее всего, мы бы пропустили этот баг и поймали бы его намного позже.
Если целью коммента было набросить говна на вентилятор, то ответ такой:
Некоторые и женщин искусственных выбирают, — как говорится, каждому своёArtem_zin
24.12.2015 13:50Это был не троллинг :)
потому что сам по себе запуск unit тестов без девайса не дает никаких преимуществ
Это не так, запуск юнит тестов на JVM дает два больших преимущества:
1. Скорость, тесты на JVM гонятся в гораздо быстрее чем на устройствах
2. Не нужно подключать устройство для запуска тестов, а на CI не нужно поднимать эмуляторы, которые еще медленнее, чем девайсы.
Судя по статье вы запускаете не все юнит тесты на каждый билд, очевидно, из-за скорости их работы, хотя это просто отметает весь смысл в юнит тестах т.к. их основное назначение — быстро проверить работоспособность кода.
девайс дешевле
Чем компьютер на котором уже собирается билд? Дешевле чем $0? :)
легче перераспределяются ресурсы, если агенты универсальны (агент для юнит тестов может выполнять задачи по ui тестированию и наоборот)
Не вижу противоречий с тестами на JVM.
Я просто слабо себе представляю процесс разработки, если бы мне приходилось подключать девайс или поднимать эмулятор чтобы просто прогнать юнит тесты.
В Yandex.Mail мы боремся со скоростью работы JVM тестов, тк весь набор выполняется пару минут, запускаем параллельно и всё такое… Был удивлен, что кто-то гоняет юнит тесты на девайсах и пишет, что всё ок :)
Но, энивей, спасибо за то, что делитесь своим опытом!rus1f1kat0r
24.12.2015 16:01ок, профит про скорость я понял, цифра в 2 минуты безусловно хороша сама по себе, но я бы предпочел иметь для сравнения вторую цифру, — запуск того же набора тестов на девайсе. На мой взгляд, тогда 2 минуты станут репрезентативными для оценки преимуществ того или иного подхода. Дело в том, что я буквально то же самое слышу про решения, которые используются другими командами, каждый хвалит свое болото. В принципе это нормально, и я привык искать причину таких решений, а потом оценивать насколько это актуально в моих проблемах и задачах, а не пытаться объяснить все факты банальной тупостью всех окружающих. Спасибо за информацию, ваш поинт я услышал, на досуге попробуем померить и если прирост в скорости будет существенным, то непременно заново рассмотрим такую возможность.
Насчет того что не все тесты запускаются, здесь, к сожалению, вы не поняли изначальную мысль. Идея заключается в том, чтобы разделить проверку работоспособности кода и интеграционные проверки, то есть проверка выполнения контракта по взаимодействию клиента и сервера.
Про разделение агентов тоже к сожалению, вы меня не поняли. Когда инфраструктура разрастается и количество задач порядочно увеличивается, то необходимо разделять обязанности агентов. Собирать 15 билдов параллельно на одной машине будет не быстрее, чем собирать их последовательно. Это влечет за собой либо увеличение вычислительной мощности одной машины, либо разделение на несколько машин. Поэтому не буду опровергать утверждение про $0, надеюсь, что вы поделитесь тем, как этого можно добиться.
Говоря о приоритетах, главным приоритетом для нас является проверка качества для конечного пользователя, а они используют приложение на девайсах.
Экономия это не главный приоритет у нас на данный момент, поэтому наши точки зрения расходятся.
В Yandex.Mail мы боремся со скоростью работы JVM тестов, тк весь набор выполняется пару минут, запускаем параллельно и всё такое… Был удивлен, что кто-то гоняет юнит тесты на девайсах и пишет, что всё ок :)
В этом мире столько удивительных вещей, вы просто себе не представляете! Еще мы делаем приложение лучше и удобнее для пользователя, а не боремся с JVM, надеюсь, что это вас также не разочарует :)
К сожалению переписка в комментах не самый эффективный инструмент обмена информацией :)Artem_zin
24.12.2015 16:56цифра в 2 минуты безусловно хороша сама по себе, но я бы предпочел иметь для сравнения вторую цифру, — запуск того же набора тестов на девайсе
Согласен, к сожалению, не знаю сколько наши юнит и интеграционные тесты будут выполнятся на устройстве, предполагаю, около 8-10 минут. Могу лишь сказать их текущее количество 730 (увеличиваем с каждым дрём и новый код покрывать обязательно), есть еще функциональные тесты, их порядка 200-300, но они на устройствах.
Собирать 15 билдов параллельно на одной машине будет не быстрее, чем собирать их последовательно.
Мм, я не об этом говорил, но в целом, на 32х ядерной машинке с 96гб памяти параллельно будет быстрее :)
Про $0 на JVM тесты я имел в виду то, что для запуска JVM тестов не требуется ничего кроме текущей машины, на которой собирается билд, а для запуска на устройстве/эмуляторе требуется, собственно, устройство/эмулятор.
Говоря о приоритетах, главным приоритетом для нас является проверка качества для конечного пользователя, а они используют приложение на девайсах.
Не вижу связи с запуском юнит тестов на устройствах.
В этом мире столько удивительных вещей, вы просто себе не представляете! Еще мы делаем приложение лучше и удобнее для пользователя, а не боремся с JVM, надеюсь, что это вас также не разочарует :)
Напротив, я очень рад, что вы тестируете Android проекты! Просто удивлен некоторыми деталями %)

ctacka
24.12.2015 18:00А зачем вы сборку распараллелили не до конца? Почему все 24 сборки не сделать параллельными?
И еще вопрос по сборкам iOS приложений. Я делал CI для iOS приложений, и у меня получились какие-то велокостыли (хотя работает ОК). Хотелось бы узнать, как вы делаете.rus1f1kat0r
25.12.2015 09:42Есть такие идеи, но пока время на сборку не переваливает за какие-то пороги. Большую часть времени в сборке все равно занимают UI тесты, соответственно, пока это не самое узкое место.
А с какими проблемами вы столкнулись при сборке iOS приложений?

mickvav
01.01.2016 02:36Ох, ребята, когда mail.ru научится делать папки более второго уровня вложенности, а?
Blumfontein
Как и зачем? (на КДПВ)
AloneCoder
это грузовой корабль тащущий корпуса для других
ese
на фото Blue Marlin
121212121
Трудно поверить, но это не фейк.
Из интернетов:
«Blue Marlin – представляет собой корабль с огромной площадью на палубе для перевозки крупногабаритных грузов, в том числе и других кораблей. Особенностью этого корабля дока является способ загрузки плавучих грузов.
Технические характеристики корабля дока Blue Marlin:
(данные характеристики корабль получил после реконструкции в 2004 году)
Полная грузоподъемность 76 000 тонн
Площадь палубы 11 227 m2 (63 м x 178,2 м)
Скорость хода на балласте 13,3 узлов
Общая длина 224,8 метра
Глубина погружения палубы 13,3 метра
Экипаж 24 человека
Мощность дизельного двигателя: 17 000 л.с.
IMO: 9186338
MMSI: 306589000
Blue Marlin построен в 1999 году, введен в эксплуатацию 25 апреля 2000 года, но в 2004 году он претерпел существенную модернизацию, в частности добавились новые двигатели для маневренности, увеличилась возможность погружения на большую глубину и существенно увеличилась полезная площадь палубы. Палуба была расширена для возможности перевозить крупные буровые платформы. Рекордом за всю историю стало перемещение платформы Thunder Horse PDQ общим весом 60000 тонн.
Если нужно загрузить иной корабль на палубу или плавучую боровую платформу, то Blue Marlin погружается вводу так, что палуба, на которой будет находиться груз, находится ниже ватерлинии, далее этот корабль – док в полузатопленном положении подводится под габаритный плавучий груз и начинает всплытие. В конечном итоге плавучий груз оказывается на палубе этого плавучего дока и может транспортироваться в любую точку по воде.
Корабль – док оборудован 60 каютами для экипажа и лиц, которые сопровождают груз, тренажерным залом, сауной и бассейном.
В ноябре 2005 года судно «Blue Marlin» вышло из порта Корпус-Кристи, штат Техас, для перемещения радара морского базирования Х-диапазона в Адак, Аляска, через южную оконечность Южной Америки и Перл-Харбор, Гавайи. Судно прибыло в Перл-Харбор 9 января 2006 года, пройдя 15 000 миль. В январе 2007 года судно «Blue Marlin» было нанято для перевозки двух самоподъемных буровых установок, Rowan Gorilla VI и GlobalSantaFe Galaxy II, из Галифакса в Северное море.
Пятиэтажный «штабель» из речных судов и понтонов был погружен на судно в шанхайском порту Наньтун, после чего судно MV Blue Marlin отправилось в путь и спустя 58 дней, 22 марта, прибыло в Нидерланды, в порт назначения.
ВМС США использовали судно «Blue Marlin» для перевозки эсминца USS Cole обратно в Соединенные Штаты после того, как корабль был поврежден в результате террористической атаки террориста-смертника из Аль-Каиды в Адене, одном из портов. Во второй половине 2003 года, судно «Blue Marlin» прошло реконструкцию, в результате которой была увеличена емкость и добавлены два убирающихся движителя для улучшения маневренности.»