
Сегодня я хочу рассказать о возможностях быстрого прототипирования, реализованных в платформе Ultima Businessware. Я покажу, как быстро набросать реализацию тривиального процесса (будут слайды!), расскажу как можно сократить время разработки и улучшить масштабируемость процесса разработки. Ну и заодно немного пройду по всяким мелким «плюшечкам» системы про которые я упоминал в прошлых статьях. За подробностями — прошу под кат.

Вообще, термин возник как название способа или функции среды разработки, которая позволяла за относительно небольшое время получить графический интерфейс с готовыми кнопками.
На моей практике это позволяло только провести юзабилити тесты и исправить ситуацию до того, как будет написано много кода.
В нашей же практике (автоматизации предприятий) часто возникают ситуации, когда необходимо «автоматизировать» небольшие участки. То, что называется «мешки в углу». Надо просто реализовать в системе возможность учета чего-то и где-то. Учет подразумевает, что есть операции прихода и расхода этого чего-то куда-то.
Собственно, для простых ситуаций прототипированное решение обладает достаточным функционалом, а для более сложных позволяет распределить процессы проработки интерфейса и бизнес-логики. Более того, даже в сложных бизнес-процессах, пользователь может начать ввод данных на самых ранних этапах разработки.
Чтобы понять, как устроено прототипирование, сначала необходимо разобраться с концепцией описания структур данных предметной области.
Не вдаваясь в детали (больше деталей — в выдержке из документации) все структуры относятся к следующим классам:
В свою очередь, структура предметной области описывается как набор типов справочников, типов документов, типов развязочных таблиц и итогов, взаимодействующих через скрипты — специальные классы на C#.
Тип справочника или документа задает внутреннюю структуру соответствующего объекта. Каждому типу справочника или документа соответствует класс на C# для хранения одной единицы данных.
Теперь можно сформулировать, что же такое быстрое прототипирование в нашей платформе:
Для справочников и документов доступны формы списка записей и редактирования записи. Для итогов — форма построения отчета. Развязочные таблицы доступны через формы редактирования соответствующих записей справочников.
Даже если вы уже запутались — не страшно. Перейдем к практике и все станет понятно!
Давайте реализуем канонический пример «учета мешков в углу».
Заказчик (начальник склада) хочет вести учет упаковочных мешков на складах. Известно, что мешки хранятся отдельно от остальной продукции, и функция по их обработке взвалена на склад просто в “нагрузку”. Мешки бывают нескольких типо-размеров. Надо в каждый момент времени знать, где (на каком складе) сколько и каких мешков лежит. Кто когда выдавал или принимал мешки.
Из формулировки задачи понятно, что нам потребуется справочник мешков с размерами, справочник складов, итог «остатки мешков», и документ обработка мешков с табличной частью «мешки», который будет описывать две операции — приход и расход. Будем считать, что разных мешков немного (скажем до 10), так что достаточно сделать плоский список.
Поехали. Создаем новый тип справочника (чтобы не мусорить картинками, я сделал анимированный гиф):
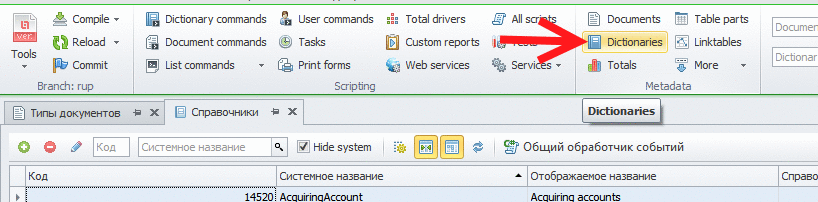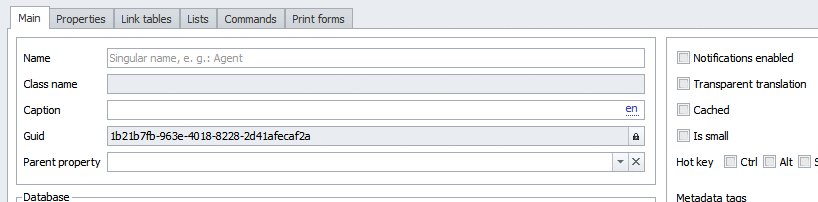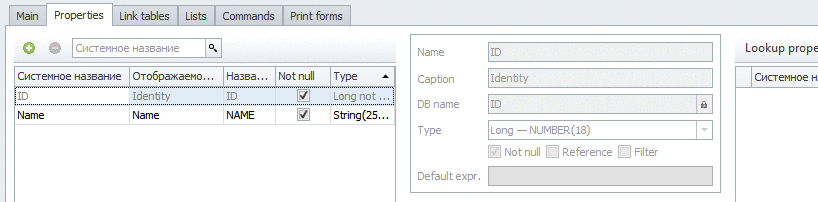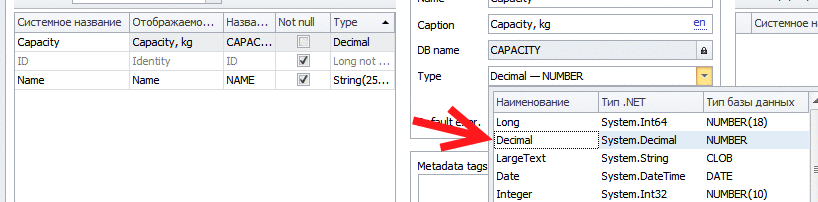
Справочник складов я создавать не буду, а воспользуюсь тем, что есть в базовом решении:
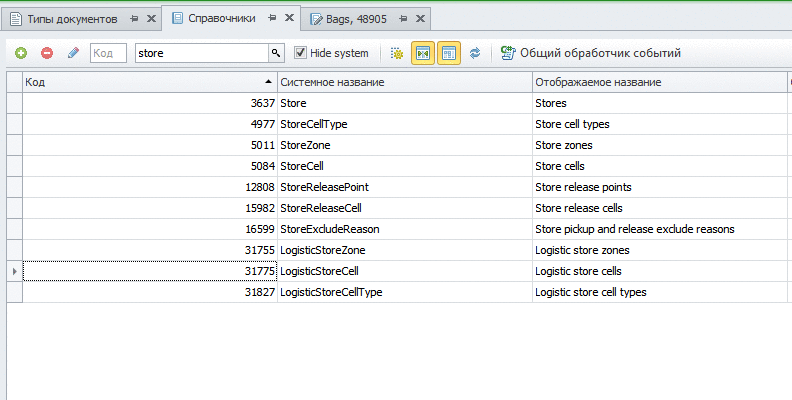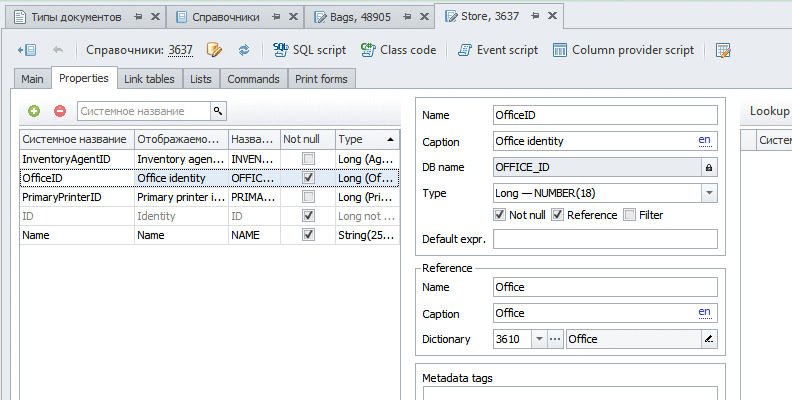
Теперь создадим итог «остатки мешков» (небольшое отступление — основной язык в системе — английский, переводы на русский язык я опускаю как несущественные для данной задачи)
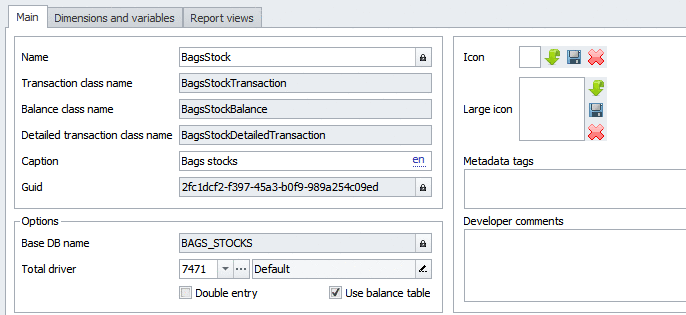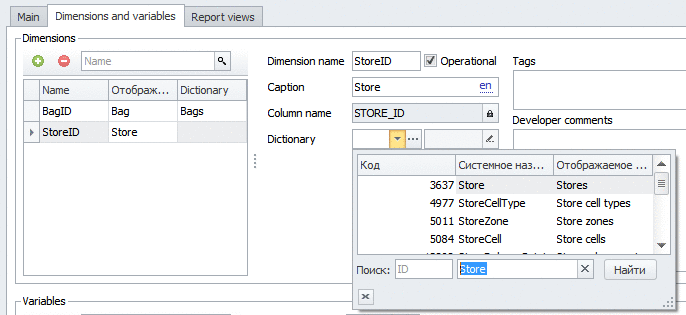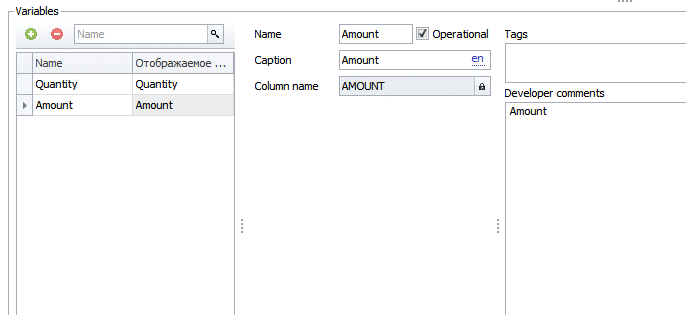
Все поля «только для чтения» генерирует платформа автоматически.
Так что до сих пор я ввел с клавиатуры только Bags/Мешки, Capacity/Вместимость, BagsStock/ОстаткиМешков, BagID/Мешок, Store/Склад. Все остальное — сгенерировано системой.
Нам нужно хранить информацию о приходах и расходах мешков. Причем, в каждом приходе могут быть мешки нескольких размеров. Создаем табличную часть мешков:
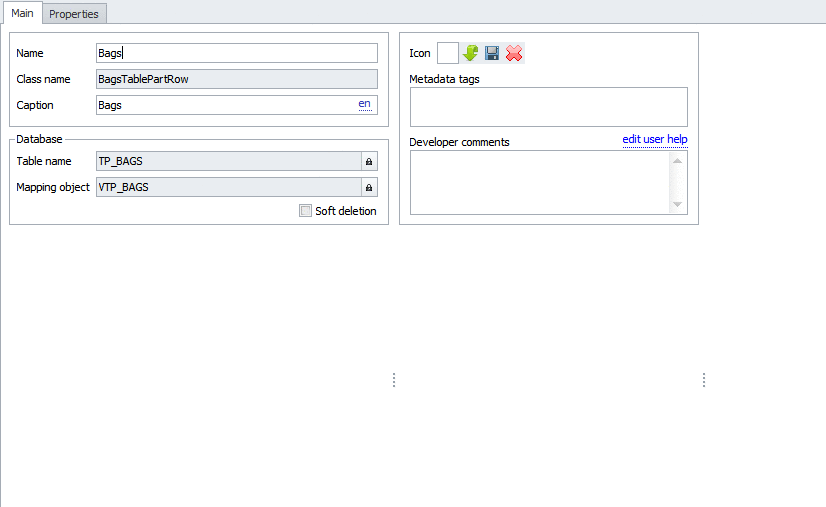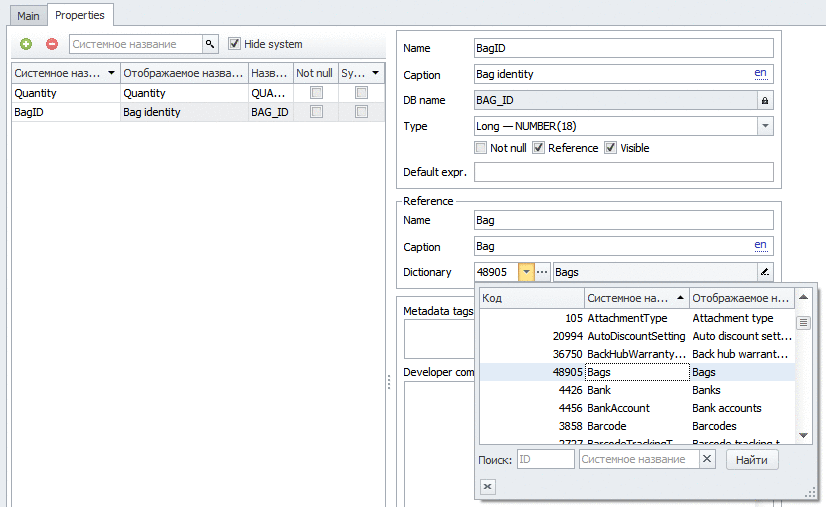
Простейшая табличная часть. В ней всего два поля — ссылка на мешок и количество.
Теперь опишем документ с этой табличной частью (табличная часть одного типа может использоваться в нескольких документах или несколько раз в одном)

В созданном документе в шапке только склад с(или на) которого будет производится выдача или прием товара. У документа есть два состояния (в нашей терминологии — подтипа), которые определяют, как этот документ влияет на итог.
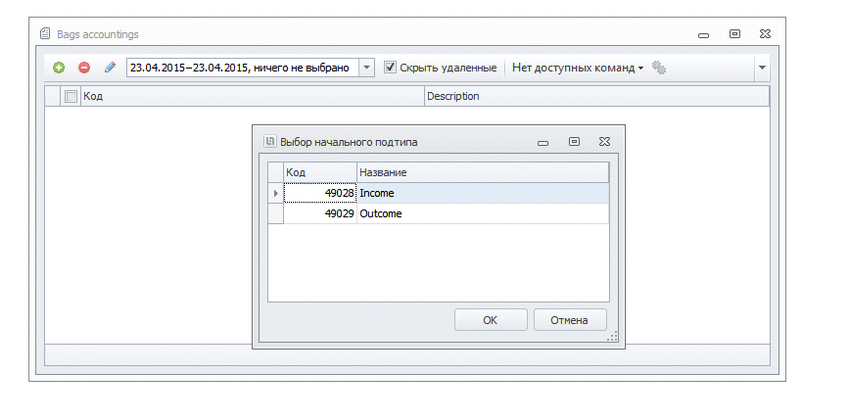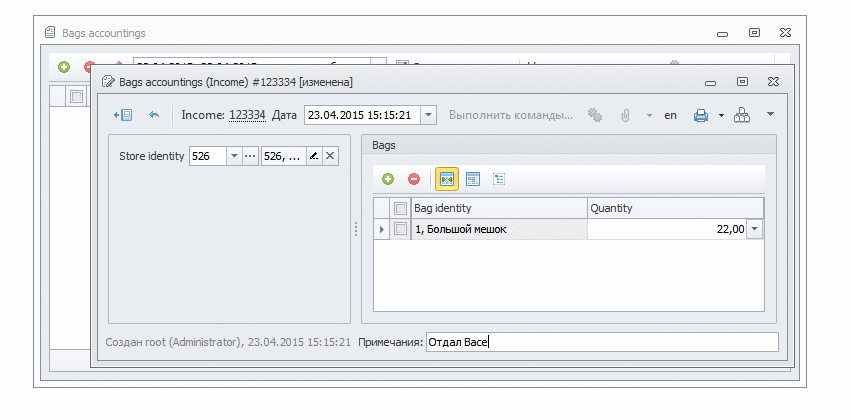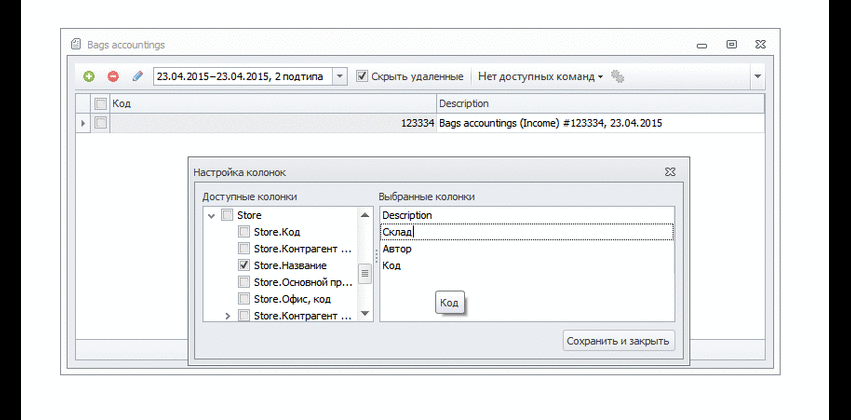
Вуаля: после трех минут кликанья мышкой мы уже можем создавать новые мешки и документы для приема и расхода этих мешков!
Вот, смотрите сами:
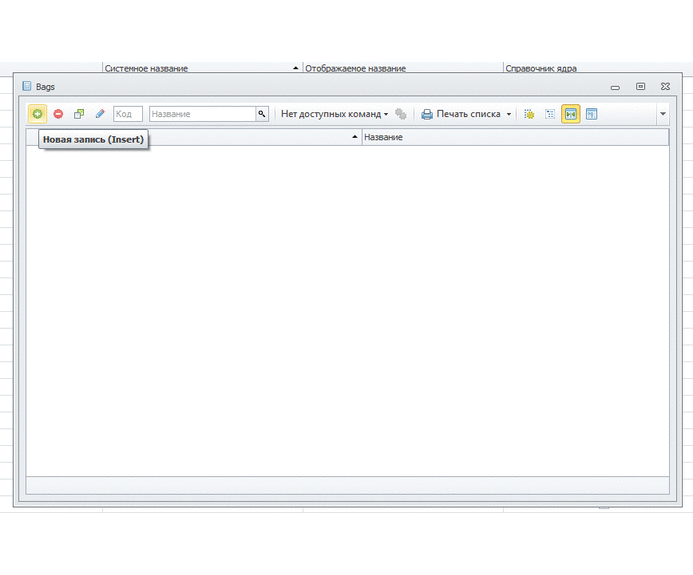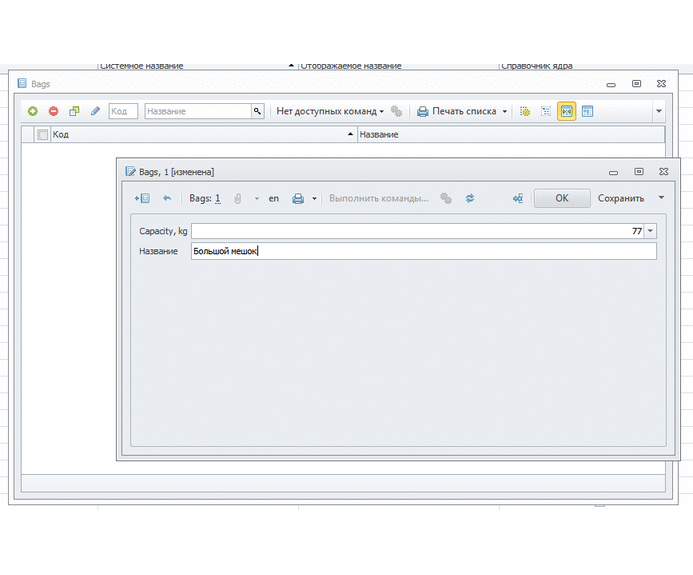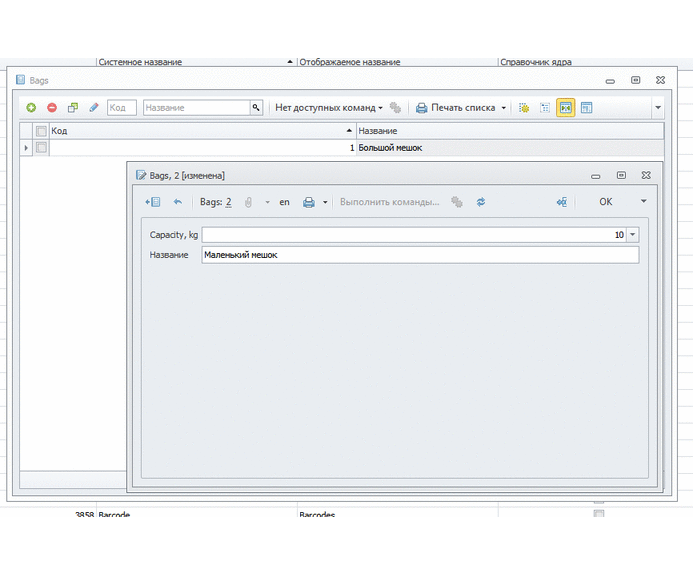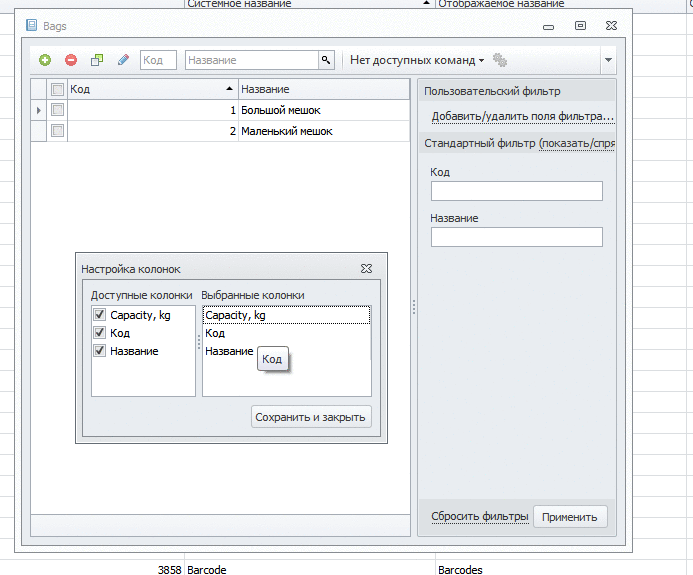
Можно раздать права пользователям, они могут настраивать себе колонки. В форме есть все настройки, группировки и фильтры по любым колонкам. Аналогично с документами:
Раздача прав происходит на отдельные подтипы, так же работают все настройки.
Кстати. Фильтровать или выбирать колонки можно не только из свойств соответствующего объекта, но и из связанных с ним.
В примере с документом колонка “Автор” содержит имя пользователя, которое указано в справочнике пользователей. Аналогично, можно вывести название офиса, в котором находится склад и так далее.
Однако, пока у нас не выстрелил созданный итог. Вот тут придется взять клавиатуру в руки и показать, чем программист от админа отличается.
Нужно написать вот такую программу:
И аналогично для расхода с обратным знаком:

Пройти по строчкам и для каждой из них сгенерировать проводку по итогу остатки мешков.
Теперь, после приходования и расходования мешков мы можем воспользоваться готовой формой построения отчета и крутить в ней данные как угодно:
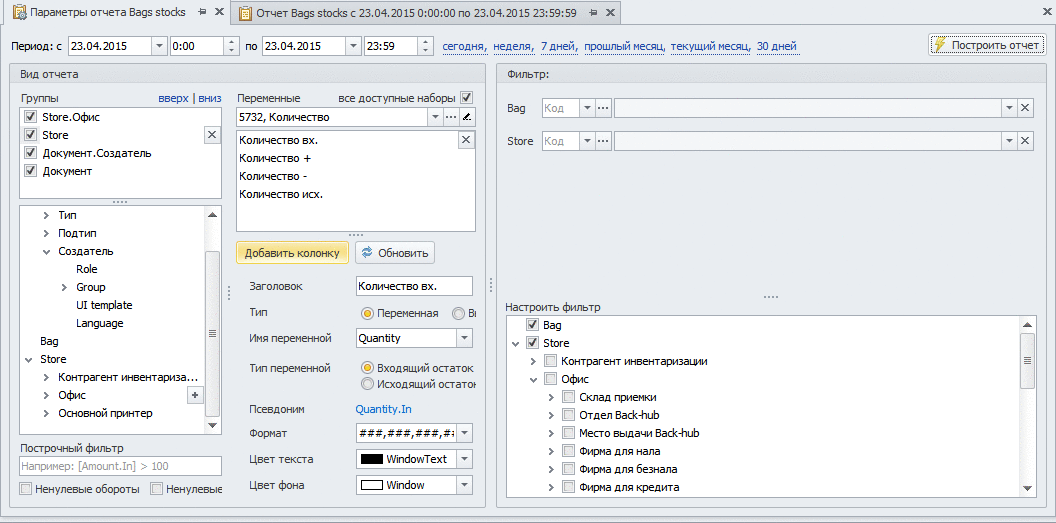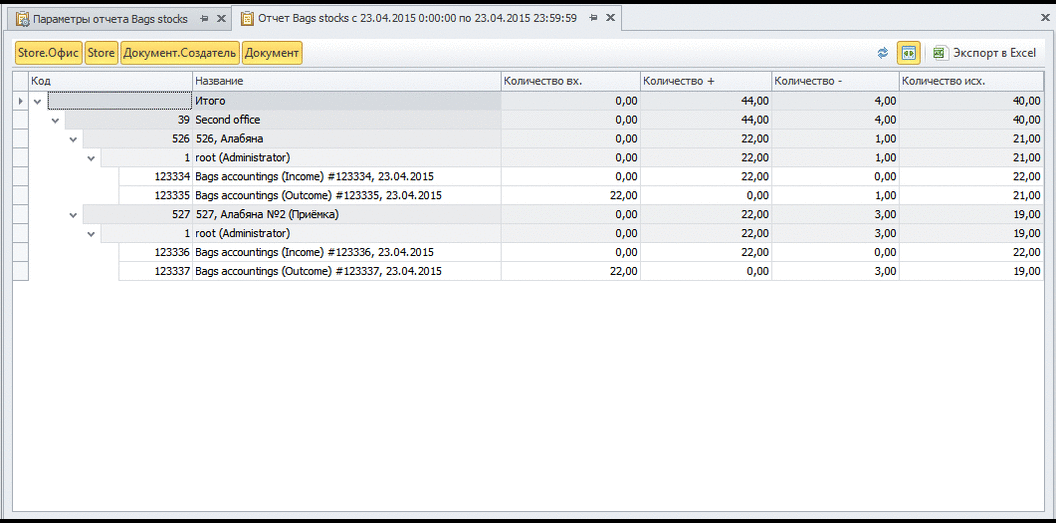
На то, чтобы проделать все операции мне потребовалось 5 минут 32 секунды.
В результате имеем: абсолютно пригодный к использованию интерфейс.
К сожалению, не могу выложить всю документацию в одной статье, поэтому я опустил подробности вроде локализации свойств, не стал показывать формы для управления правами и прочим. Главное, что уже сейчас можно вводить данные. Если потребуется более сложная логика — она легко дорабатывается, а главное, теперь можно параллельно заниматься разработкой экранных форм, вебсервисов, интеграционных тестов и прочей бизнес-логики. И каждый из разработчиков будет иметь инструменты для проверки своей работы.
Кстати — на сей момент написано всего 10 строк кода, в которых довольно таки непросто ошибиться — и все. Больше никакого программирования, делать ничего не надо, и, как следствие из законов Мерфи — ошибок нет!
И это еще одна из причин, основываясь на которых, мы утверждаем, что стоимость поддержки решений Ultima ниже, чем у конкурентов. Даже если включить в анализ почасовую стоимость специалиста.

Быстрое прототипирование
Вообще, термин возник как название способа или функции среды разработки, которая позволяла за относительно небольшое время получить графический интерфейс с готовыми кнопками.
На моей практике это позволяло только провести юзабилити тесты и исправить ситуацию до того, как будет написано много кода.
В нашей же практике (автоматизации предприятий) часто возникают ситуации, когда необходимо «автоматизировать» небольшие участки. То, что называется «мешки в углу». Надо просто реализовать в системе возможность учета чего-то и где-то. Учет подразумевает, что есть операции прихода и расхода этого чего-то куда-то.
Собственно, для простых ситуаций прототипированное решение обладает достаточным функционалом, а для более сложных позволяет распределить процессы проработки интерфейса и бизнес-логики. Более того, даже в сложных бизнес-процессах, пользователь может начать ввод данных на самых ранних этапах разработки.
Чтобы понять, как устроено прототипирование, сначала необходимо разобраться с концепцией описания структур данных предметной области.
Не вдаваясь в детали (больше деталей — в выдержке из документации) все структуры относятся к следующим классам:
- Справочники
Содержат “статичную” информацию. Например товары, офисы, склады. - Развязочные таблицы
Содержат информацию о связях много-ко-много между различными справочниками - Документы и табличные части
Документы соответствуют событиям в предметной области. Например продажа, или покупка. Каждый документ состоит из “шапки” — набора полей и табличных частей. Табличная часть содержит перечисление различных атрибутов. Например сколько, почем и каких товаров мы продали. - Итоги
Этот объект — самый сложный для понимания, поэтому его я всегда объясняю через аналогии. Знакомым с OLAP — это куб. Есть измерения, переменные. Одно из измерений — временное. Для разработчиков, знакомых с 1C — это регистр (хотя и со значительно более сложной структурой), ну и последняя аналогия — бухгалтерский счет. Если все еще непонятно, попробуйте прочитать документацию. Или просто посмотрите, что будет дальше.
В свою очередь, структура предметной области описывается как набор типов справочников, типов документов, типов развязочных таблиц и итогов, взаимодействующих через скрипты — специальные классы на C#.
Тип справочника или документа задает внутреннюю структуру соответствующего объекта. Каждому типу справочника или документа соответствует класс на C# для хранения одной единицы данных.
Теперь можно сформулировать, что же такое быстрое прототипирование в нашей платформе:
Быстрое прототипирование — возможность автоматической генерации полнофункциональных форм редактирования данных на основе описания метаданных с контролем прав доступа, редактирования внешнего вида в ран-тайм и прочих функций.
Для справочников и документов доступны формы списка записей и редактирования записи. Для итогов — форма построения отчета. Развязочные таблицы доступны через формы редактирования соответствующих записей справочников.
Даже если вы уже запутались — не страшно. Перейдем к практике и все станет понятно!
Step-By-Step пока от монитора не ослеп
Давайте реализуем канонический пример «учета мешков в углу».
Заказчик (начальник склада) хочет вести учет упаковочных мешков на складах. Известно, что мешки хранятся отдельно от остальной продукции, и функция по их обработке взвалена на склад просто в “нагрузку”. Мешки бывают нескольких типо-размеров. Надо в каждый момент времени знать, где (на каком складе) сколько и каких мешков лежит. Кто когда выдавал или принимал мешки.
Из формулировки задачи понятно, что нам потребуется справочник мешков с размерами, справочник складов, итог «остатки мешков», и документ обработка мешков с табличной частью «мешки», который будет описывать две операции — приход и расход. Будем считать, что разных мешков немного (скажем до 10), так что достаточно сделать плоский список.
Поехали. Создаем новый тип справочника (чтобы не мусорить картинками, я сделал анимированный гиф):

Справочник складов я создавать не буду, а воспользуюсь тем, что есть в базовом решении:

Теперь создадим итог «остатки мешков» (небольшое отступление — основной язык в системе — английский, переводы на русский язык я опускаю как несущественные для данной задачи)

Все поля «только для чтения» генерирует платформа автоматически.
Так что до сих пор я ввел с клавиатуры только Bags/Мешки, Capacity/Вместимость, BagsStock/ОстаткиМешков, BagID/Мешок, Store/Склад. Все остальное — сгенерировано системой.
Нам нужно хранить информацию о приходах и расходах мешков. Причем, в каждом приходе могут быть мешки нескольких размеров. Создаем табличную часть мешков:

Простейшая табличная часть. В ней всего два поля — ссылка на мешок и количество.
Теперь опишем документ с этой табличной частью (табличная часть одного типа может использоваться в нескольких документах или несколько раз в одном)

В созданном документе в шапке только склад с(или на) которого будет производится выдача или прием товара. У документа есть два состояния (в нашей терминологии — подтипа), которые определяют, как этот документ влияет на итог.
Вуаля: после трех минут кликанья мышкой мы уже можем создавать новые мешки и документы для приема и расхода этих мешков!
Вот, смотрите сами:

Можно раздать права пользователям, они могут настраивать себе колонки. В форме есть все настройки, группировки и фильтры по любым колонкам. Аналогично с документами:

Раздача прав происходит на отдельные подтипы, так же работают все настройки.
Кстати. Фильтровать или выбирать колонки можно не только из свойств соответствующего объекта, но и из связанных с ним.
В примере с документом колонка “Автор” содержит имя пользователя, которое указано в справочнике пользователей. Аналогично, можно вывести название офиса, в котором находится склад и так далее.
Однако, пока у нас не выстрелил созданный итог. Вот тут придется взять клавиатуру в руки и показать, чем программист от админа отличается.
Нужно написать вот такую программу:
foreach(var r in document.Bags)
{
transactions.Add(new BagsStockTransaction
{
BagID = r.BagID,
StoreID = document.StoreID,
Quantity = r.Quantity,
Amount = 0
});
}
И аналогично для расхода с обратным знаком:

Пройти по строчкам и для каждой из них сгенерировать проводку по итогу остатки мешков.
Теперь, после приходования и расходования мешков мы можем воспользоваться готовой формой построения отчета и крутить в ней данные как угодно:

Итого
На то, чтобы проделать все операции мне потребовалось 5 минут 32 секунды.
В результате имеем: абсолютно пригодный к использованию интерфейс.
К сожалению, не могу выложить всю документацию в одной статье, поэтому я опустил подробности вроде локализации свойств, не стал показывать формы для управления правами и прочим. Главное, что уже сейчас можно вводить данные. Если потребуется более сложная логика — она легко дорабатывается, а главное, теперь можно параллельно заниматься разработкой экранных форм, вебсервисов, интеграционных тестов и прочей бизнес-логики. И каждый из разработчиков будет иметь инструменты для проверки своей работы.
Кстати — на сей момент написано всего 10 строк кода, в которых довольно таки непросто ошибиться — и все. Больше никакого программирования, делать ничего не надо, и, как следствие из законов Мерфи — ошибок нет!
И это еще одна из причин, основываясь на которых, мы утверждаем, что стоимость поддержки решений Ultima ниже, чем у конкурентов. Даже если включить в анализ почасовую стоимость специалиста.

GROOVY
Наваяю аналогичное на 1С за 2 минуты. Кодить руками не буду вообще. Еще и отчет более человеческий, с отборами и группировками по остаткам нарисую.
spuf
«пруф или не было!»