

Поздравления команде xAI — и всем, кто верит в силу масштабирования. На этот раз, похоже, Илон Маск вовсе не преувеличивал, назвав Grok-3 «самым умным ИИ на Земле». Grok-3 — это грандиозный скачок по сравнению с Grok-2. (Полную презентацию можно посмотреть здесь.)
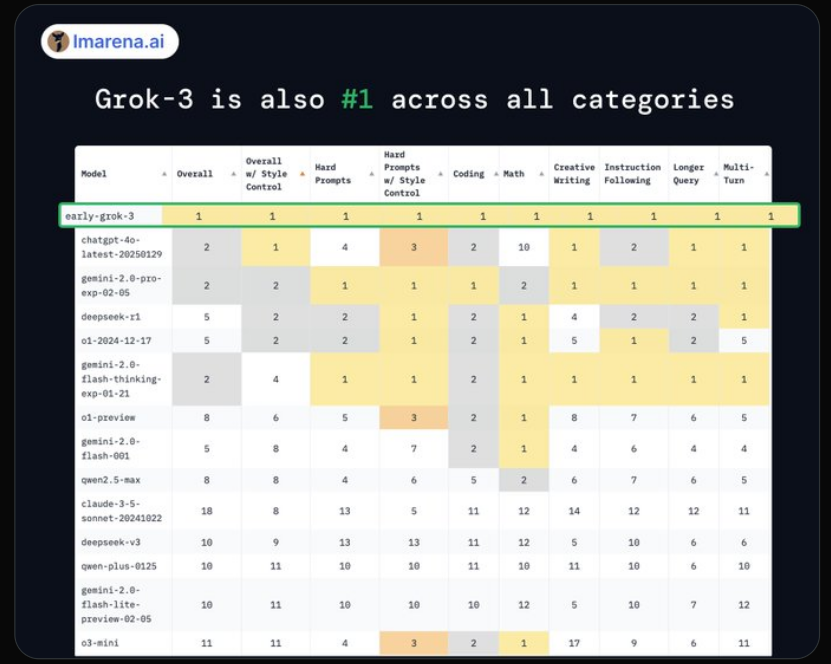
Grok-3 демонстрирует уровень, сопоставимый с моделями таких гигантов, как OpenAI, Google DeepMind и Anthropic, и в ряде задач даже превосходит их. Он занял первые места во всех категориях LMSys Arena, а его версия, ориентированная на рассуждения, показывает, по данным бенчмарков, выдающиеся результаты на уровне o3 в математике, программировании и естественных науках. По большинству параметров он, как минимум, соответствует передовым моделям (хотя и не во всех задачах).



Одним словом, Grok-3 — выдающийся. Но его успех — это не только триумф xAI; это ещё одна — и, возможно, самая очевидная — победа «Горького урока». Вопреки мнению критиков и журналистов, законы масштабирования по‑прежнему определяют развитие ИИ — и даже сильнее, чем когда‑либо.
DeepSeek: исключение, подтверждающее правило
Несмотря на ограниченные вычислительные мощности — 50 тысяч графических процессоров Nvidia Hopper против 100 тысяч и более Nvidia H100 у американских лабораторий — DeepSeek смог конкурировать с лидерами индустрии. Чтобы компенсировать этот разрыв, им пришлось оптимизировать весь стек технологий, продемонстрировав выдающееся инженерное мастерство. И они справились: их успех стал исключением, которое могло поколебать доверие сообщества и к «Горькому уроку», и к парадигме масштабирования.
По крайней мере, так утверждали скептики. По их мнению, DeepSeek с «крошечным кластером GPU» и недорогими обучающими запусками сумел создать модель уровня OpenAI o1. Это, как они полагали, доказывало, что вручную настроенные особенности, человеческая изобретательность и алгоритмические улучшения важнее, чем мощные вычислительные кластеры. Они даже заявляли, что пора избавляться от акций Nvidia, ведь GPU якобы не так уж важны.
Однако этот вывод основан на неправильном понимании «Горького урока» (который, к слову, является не законом природы, а всего лишь эмпирическим наблюдением): он вовсе не утверждает, что алгоритмические улучшения бесполезны, — напротив, он их высоко ценит. Суть урока в другом: если есть выбор, то наращивание вычислительных мощностей для обучения и поиска решений всегда будет предпочтительнее даже самых изощрённых эвристических методов.
DeepSeek добился впечатляющих результатов не потому, что доказал бесполезность масштабирования, а потому, что у него не было иного выхода. Если бы они обучали свою модель на 100-тысячном кластере GPU, как xAI с Grok-3, их результаты были бы ещё лучше. DeepSeek показал, что оптимизация возможна, — но это никак не опровергает силу масштабирования. Эти два явления не исключают друг друга.
Генеральный директор DeepSeek Лян Вэньфэн сам признал, что основным препятствием для их прогресса являются экспортные ограничения США. Если даже при наличии 50 тысяч Hopper он называет нехватку GPU главной проблемой, то утверждать, что «графические процессоры не имеют значения», попросту нелепо. DeepSeek блестяще использовал оптимизацию, но в итоге им всё равно требовался масштаб. И если об этом говорит сам глава компании, почему кто‑то со стороны должен знать лучше?
Феноменальный успех DeepSeek подтверждает «Горький урок» и парадигму масштабирования — даже если на первый взгляд кажется исключением из правил.
xAI: доказательство того, что масштабирование > оптимизация
Вернёмся к Grok-3. Возможно, успех xAI заставит скептиков пересмотреть свою критику масштабирования. Мы не знаем, изменили ли они архитектуру модели или насколько глубоко оптимизировали инфраструктуру, но мы точно знаем, что обучение Grok-3 проходило на суперкомпьютере Colossus с 100 тысячами H100, который xAI построила в Мемфисе, штат Теннесси. Это огромное количество GPU — намного больше, чем у DeepSeek. (Возможно, обе компании использовали лишь часть доступных ресурсов, но логично предположить, что наличие вдвое большего количества GPU позволяет задействовать примерно вдвое больше вычислительных мощностей.)
В отличие от DeepSeek, xAI не пришлось выходить за пределы стандартной оптимизации (например, переписывать CUDA‑ядра или внедрять сомнительные алгоритмические ухищрения). Безусловно, они провели некоторую оптимизацию, но вряд ли настолько глубокую. «Горький урок» гласит: если у вас есть вычислительные мощности, сначала используйте их, а не возитесь с кодом, как вынужденный экономить каждый GPU‑стартап. Простое наращивание масштабов в конечном итоге приносит больше пользы, чем файнтюнинг (этот загадочный твит Маска можно интерпретировать по‑разному). А xAI давно исповедует культ масштабирования.
И скорее всего, именно так они и поступили: бросили на Grok-3 больше вычислительных мощностей, чем даже OpenAI могла себе позволить. Результат? Модель передового уровня.
Хочу сделать небольшое отступление, потому что устал повторять, будто «Горький урок» — это нечто эксклюзивное для ИИ. Нет, это фундаментальный принцип. Если у вас есть избыток главного ресурса, нет смысла выжимать последние капли из второстепенного — проще зачерпнуть полный стакан из источника. Что выберете вы: быть как фримены из «Дюны», выжимать влагу из пота и мёртвых с помощью гениальных, но отчаянных ухищрений, или жить на планете, где просто идёт дождь?
Улучшение алгоритмов и наращивание вычислительных мощностей — оба подхода ценны, но если предельная отдача от усилий резко снижается, имеет смысл сменить точку приложения сил, а не упираться в стену. Вычислительная мощность доступна, пока у вас есть деньги (по крайней мере, пока это так), а ценные алгоритмические прорывы — редкость, которая сегодня может сработать, а завтра нет и вряд ли бесконечно масштабируется. Поэтому почти всегда выгоднее вкладываться в рост вычислительных ресурсов.
Если перед вами «стена», просто меняйте объект масштабирования, но не останавливайтесь. Не. Переставайте. Масштабироваться.
Ограничения действительно порождают инновации, а трудности закаляют. Я уверен, что команда DeepSeek — это настоящие мастера инженерного искусства, но в конечном итоге больше ресурсов всегда побеждает умение делать максимум из минимума. Мир несправедлив, и мне жаль.
Хотелось бы спросить: DeepSeek нравится их нынешнее положение или они бы с радостью поменялись местами с xAI или OpenAI? А вы можете представить, чтобы OpenAI и xAI добровольно отказались от своих GPU ради поиска инноваций в условиях ограничений, как пришлось делать DeepSeek?
В каком‑то смысле xAI и DeepSeek — два запоздавших игрока, выбравших противоположные стратегии для одного и того же вызова. Грубая сила масштабирования против предельной оптимизации ресурсов. Оба добились успеха в своих условиях, но xAI, без сомнения, оказался в лучшем положении — и сохранит преимущество в ближайшие месяцы, пока DeepSeek остаётся заложником нехватки вычислительных мощностей. Ведь, как показывает практика, этот эмпирический (и активно оспариваемый академиками) закон уже более десяти лет приносит победы в реальной гонке технологий.
Переломный момент, который помог и xAI, и DeepSeek
Ещё недавно поздний старт казался непреодолимым барьером в гонке ИИ — когда я впервые оценивал шансы xAI, у меня были сомнения, смогут ли они догнать OpenAI и Anthropic. Но между выходом Grok-2 (август 2024) и Grok-3 (февраль 2025) случилось нечто, что помогло xAI, — и речь не только о суперкомпьютере Colossus с 100 тысячами H100; изменилась сама парадигма масштабирования.
Эпоха предобучения (2019–2024). Изначально масштабирование означало создание всё более крупных моделей, обученных на гигантских наборах данных при помощи мощных суперкомпьютеров. Например, GPT-2 (февраль 2019) имела 1,5 млрд параметров, а GPT-4 (март 2023) оценивается в 1,76 трлн параметров — разница в три порядка. Такой подход естественным образом давал фору ранним игрокам, таким как OpenAI, которые имели многолетнее преимущество в сборе данных, разработке моделей и закупке GPU. Даже без этого преимущества, если на обучение каждой новой модели уходило около полугода, OpenAI всегда оставалась бы как минимум на этот срок впереди xAI.
Эпоха постобучения (2024–???). Всё изменилось, когда компании поняли, что простое увеличение размеров моделей приносит всё меньшую отдачу (СМИ поспешили интерпретировать это как «эпоха масштабирования закончилась», но я настоятельно рекомендую посмотреть этот доклад Ильи Суцкевера на NeurIPS 2024 в декабре) — вместо этого фокус сместился на увеличение вычислений во время вывода (то есть способность моделей задействовать ресурсы для более глубокой проработки ответов). Первой этот подход применила OpenAI в o1-preview. Усиленное обучение с подкреплением в сочетании с классической тонкой настройкой показало высокую эффективность, особенно в структурированных областях, таких как математика и программирование, где есть чёткие, поддающиеся проверке функции награды.
Этот сдвиг в парадигме означал, что масштабирование постобучения стало таким же важным — если не более, — чем масштабирование предобучения. Компании, занимающиеся ИИ, перестали просто увеличивать размер моделей и вместо этого начали делать их умнее. И произошло это как раз в тот момент, когда DeepSeek и xAI создавали свои новые модели. Удачное совпадение.
Важно отметить, что постобучение всё ещё находится в зачаточном состоянии, а быстрые улучшения можно достичь относительно дёшево по сравнению с предобучением. Именно так OpenAI перешла от o1 к o3 всего за три месяца, и это позволило DeepSeek усовершенствовать r1 несмотря на меньшее и менее мощное оборудование, и именно так Grok всего за два года вышел в высшую лигу ИИ.
OpenAI всё ещё сохраняет определённое преимущество, но оно уже не выглядит непреодолимым. Пока Сэм Альтман балансирует между прорывными исследованиями и управлением ChatGPT — продуктом, которым еженедельно пользуются 300 миллионов человек, — у xAI и DeepSeek больше свободы для экспериментов и поиска инноваций. (Приложение DeepSeek сначала резко набрало популярность, но затем пошло на спад — компания просто не имеет достаточно вычислительных мощностей, чтобы обеспечивать стабильную работу для большого числа пользователей.)
Новая парадигма — новое соперничество.
Победы xAI и DeepSeek в правильном контексте
Признание «Горького урока» и смены парадигмы масштабирования никак не умаляет достижений xAI и DeepSeek; да, им было проще, но им всё равно пришлось пройти этот путь. Другие пытались — и не справились (например, Mistral, Character, Inflection). Как я уже говорил, успех Grok-3 — это, прежде всего, триумф «Горького урока», а DeepSeek — скорее исключение, подтверждающее правило. Но сводить их достижения только к этому было бы несправедливо.
Одна только вычислительная мощность — или её нехватка — не решает всего. Точно так же, как «Горький урок» не отменяет ценность улучшения алгоритмов и инфраструктуры, нельзя игнорировать и другие факторы. xAI собрала выдающуюся команду — сейчас в компании около 1000 сотрудников, что сопоставимо с OpenAI (~2000) и Anthropic (~700). Добавьте к этому влияние Илона Маска в мире технологий и финансов — и вот вам огромные возможности для привлечения инвестиций. DeepSeek тоже заслуживает похвалы: они сумели преодолеть ограничения и добиться успеха в локальной экосистеме, где не хватало ни амбиций, ни опытных специалистов, ни государственной поддержки (хотя это может измениться).
Но так же важно не только признавать победу, но и понимать её контекст. OpenAI, Google DeepMind и Anthropic разрабатывали свои модели в то время, когда масштабирование было сложнее, медленнее и дороже (в эпоху предобучения). Никто не знал, насколько успешным окажется что‑то вроде ChatGPT (OpenAI едва не отказалась от его запуска, а когда все же выпустила, позиционировала его лишь как «скромный исследовательский эксперимент»). Эти стартапы были первопроходцами, движимыми непоколебимой верой в успех. Их вклад, пусть сейчас и слегка затенённый заголовками о новых игроках, войдёт в учебники истории.
А xAI и DeepSeek, напротив, использовали уже накопленный опыт этих пионеров. Они извлекли уроки из их проб и ошибок, а также воспользовались удачным моментом: когда новый подход к постобучению позволил ускорить прогресс и снизить затраты. Им не пришлось пробираться на ощупь и делать огромные авансовые вложения с неопределённой отдачей. Поэтому не стоит принижать их успехи, но также не стоит забывать, как мы к этому пришли.
Постобучение пока дешёвое, но скоро станет дорогим
Из истории Grok-3 и xAI можно вынести один важный урок. Как только компании научатся масштабировать постобучение до тех же финансовых масштабов, что и предобучение, — а это неизбежно, ведь они уже накапливают сотни тысяч GPU и строят огромные кластеры, чем немало раздражают сторонников теории «GPU неважны», — конкурентоспособными останутся только те, у кого хватит денег и вычислительных мощностей, чтобы не отставать.
И здесь xAI заняла крайне выгодную позицию — даже лучше, чем DeepSeek, а возможно, и лучше, чем OpenAI и Anthropic: с кластером из 100 тысяч H100 — а вскоре и 200 тысяч — она обеспечила себе мощный задел на следующем этапе развития ИИ. По тому же пути идёт Meta*: в ближайшие месяцы она готовится представить Llama 4*, обученную на кластере из 100 тысяч H100.
Для DeepSeek же одного инженерного мастерства будет недостаточно, какими бы талантливыми они ни были в тонкой настройке стека (возможно, Huawei сможет им помочь). Настанет момент, когда никакая оптимизация не сможет компенсировать разрыв в 150 тысяч GPU. Не поймите неправильно — будь у DeepSeek такая возможность, они бы сделали то же самое, что xAI (ведь они тоже сторонники масштабирования).
Даже OpenAI и Anthropic не имеют такого «забронированного» доступа к кластерам, как xAI, — Nvidia явно отдаёт приоритет компании Маска, обеспечивая ей доступ к передовому оборудованию нового поколения.
Кто будет лидером через год?
Несмотря на всё это, OpenAI, Google DeepMind и Anthropic пока сохраняют небольшое преимущество. OpenAI готовится выпустить GPT-4.5/GPT-5, затем o4, а Anthropic скоро представит Claude-4. Google DeepMind продолжает совершенствовать интеллектуальные версии Gemini-2.0 и активно работает над снижением затрат и увеличением контекстного окна.
Совсем недавно я прогнозировал, что к концу года лидером станет Google, но теперь уже не уверен: конкуренция достигла небывалой остроты, и гонка к созданию AGI пока не имеет очевидного фаворита. Новая парадигма благоприятствует поздним игрокам, но требует высокой гибкости — и не факт, что Google этим качеством обладает. Возможно, их главная проблема не недостаток достижений, а слабые маркетинговые усилия, из‑за чего их успехи выглядят менее впечатляющими, чем у конкурентов.
Но мой итоговый вывод будет не о гонке ИИ; это о правиле, которое раз за разом подтверждается, разрушая надежды тех, кто хочет верить, что человеческая изобретательность всегда возьмёт верх над простым масштабированием. Простите, друзья, но некоторые вещи нам просто неподвластны.
Grok-3 действительно впечатляет, но, прежде всего, он снова доказывает: когда дело касается создания интеллекта, масштабирование неизменно побеждает голую гениальность.
* Meta признана экстремистcкой организацией в России.
* Llama — проект Meta Platforms Inc., деятельность которой запрещена в России.
Комментарии (17)

blik13
19.02.2025 04:55Ну т.е. имея как минимум вдвое большую вычислительную мощность(ну так в этой статье написано) контора Маска обучила сеть примерно того же уровня как DeepSeek? Ну да, пошла она в лес эта ваша оптимизация.

BlackMokona
19.02.2025 04:55Грок 3 лидер чатбот арены во всех категориях. Поэтому они сделали лучшую ИИ из доступных на рынке.

arse00n
19.02.2025 04:55не во всех



BlackMokona
19.02.2025 04:55Ну похоже категорий больше чем я думал
https://miro.medium.com/v2/resize:fit:1400/1*KkAv753haQsNKN6e5ta4qA.png




mohnatcin
19.02.2025 04:55Когда сделают новую архитектуру и ИИ перестанет тратить мегаваты на стохастическое попугайничество, а начнёт учится человеко подобным способом, пойдёт вал статей о том что архитектура наше все. Сумма технологий Лема вышла 60 лет назад, а люди все ещё не могут осознать что успех экстенсисивного развития это лишь следствие затора в интенсивном.



alexxxdevelop
19.02.2025 04:55Пока слышно только маркетинговые вбросы. Кто-нибудь реально с этой моделью поработал? Они даже не дают пару бесплатных запросов в день, а сразу сделали платный доступ. Жадные коммерсанты

inetstar
19.02.2025 04:55На арене как найти Грок 3? Вижу только Грок 2.
Какой ссылкой вы сами пользовались?
ednersky
19.02.2025 04:55вчера появился и -3 в списке
grok.com
мне не нравится
у них цензура есть, но они пытаются ее скрывать от пользователя, хотя она сильнее даже чем в гпт
попытался поговорить с гроком на тему «сша постоянно развязывают войны, поскольку редиски»
и любой неудобный вопрос приводит к «техническому» сбою: зависание на час и следом удаление вопроса

Per_Ardua
19.02.2025 04:55Скорее всего вы смотрите во вкладке battle, на ней нет. Нужно смотреть на вкладке direct chat.


{kind=link}
orekh
Меня стриггерила эта фраза, простите.
Newbilius
Я уже готов ставить минус просто за то, когда автор использует это выражение в неироничном смысле)