
математических задач при помощи моделирования случайных величин. Представление об истории метода и простейшие примеры его применения можно найти в Википедии.
В самом методе нет ничего сложного. Именно эта простота объясняет популярность данного метода.
Метод имеет две основных особенности. Первая — простая структура вычислительного алгоритма. Вторая — ошибка вычислений, как правило, пропорциональна
Однако одну и ту же задачу можно решать различными вариантами метода Монте-Карло, которым отвечают различные значения
Общая схема метода
Допустим, что нам требуется вычислить какую-то неизвестную величину m. Попытаемся придумать такую случайную величину
Рассмотрим
На основе Центральной предельной теоремы (или если хотите предельной теоремы Муавра-Лапласа) не трудно получить соотношение:
где
Это — чрезвычайно важное для метода Монте-Карло соотношение. Оно дает и метод расчета
В самом деле, найдем
В зависимости от целей последнее соотношение используется по разному:
- Если взять k=3, то получим так называемое «правило
»:
- Если требуется конкретный уровень надежности вычислений
,
Точность вычислений
Как видно из приведенных выше соотношений, точность вычислений зависит от параметра
В этом пункте хотелось бы указать важность именно второго параметра
Вычисление определенного интеграла эквивалентно вычислению площадей, что дает интуитивно понятный алгоритм вычисления интеграла (см. статью в Википедии). Я рассмотрю более эффективный метод (частный случай формулы для которого, впрочем, тоже есть в статье из Википедии). Однако не все знают, что вместо равномерно распределенной случайной величины в этом методе можно использовать практически любую случайную величину, заданную на том же интервале.
Итак, требуется вычислить определенный интеграл:
Выберем произвольную случайную величину
Математическое ожидание последней случайной величины равно:
Таким образом, получаем:
Последнее соотношение означает, что если выбрать
Таким образом, для вычисления интеграла, можно использовать практически любую случайную величину
Можно показать, что
Численный пример
Теория, конечно, дело хорошее, но давайте рассмотрим численный пример:
Вычислим значение интеграла с применением двух различных случайных величин.
В первом случае будем использовать равномерно распределенную случайную величину на [a,b], т.е.
Во втором случае возьмем случайную величину с линейной плотностью на [a,b], т.е.
Вот график, указанных функций
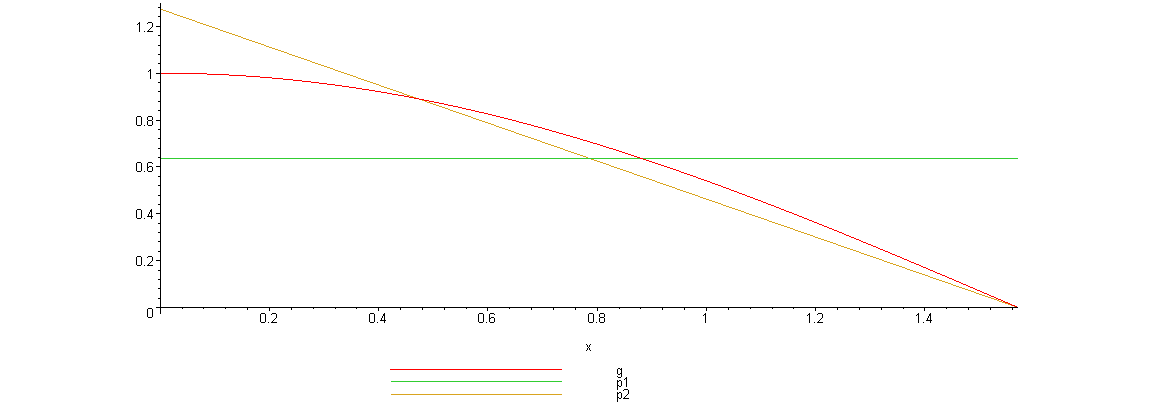
Нетрудно видеть, что линейная плотность лучше соответствует функции
restart;
with(Statistics):
with(plots):
#исходные функции
g:=x->cos(x):
a:=0:
b:=Pi/2:
N:=10000:
#плотности распределений
p1:=x->piecewise(x>=a and x<b,1/(b-a)):
p2:=x->piecewise(x>=a and x<b,4/Pi-8*x/Pi^2):
#графики
plot([g(x),p1(x),p2(x)],x=a..b, legend=[g,p1,p2]);
#Точное значение интеграла
I_ab:=int(g(x),x=0..b);
#функция метода Монте-Карло для вычисления приближенного вычисления интеграла
#не стоит ее использовать при реальных расчетах
INT:=proc(g,p,N)
local xi;
xi:=Sample(RandomVariable(Distribution(PDF = p)),N);
evalf(add(g(xi[i])/p(xi[i]),i=1..N)/N);
end proc:
#Приближенное значение интеграла
I_p1:=INT(g,p1,N);#c равномерной плотностью
I_p2:=INT(g,p2,N);#c линейной плотностью
#Абсолютная погрешность
Delta1:=abs(I_p1-I_ab);#c равномерной плотностью
Delta2:=abs(I_p2-I_ab);#c линейной плотностью
#Относительные погрешности в процентах
delta1:=Delta1/I_ab*100;#c равномерной плотностью
delta2:=Delta2/I_ab*100;#c линейной плотностью
#Вычисление дисперсий
Dzeta1:=evalf(int(g(x)^2/p1(x),x=a..b)-1);
Dzeta2:=evalf(int(g(x)^2/p2(x),x=a..b)-1);
#Оценка погрешности в первом случае
3*sqrt(Dzeta1)/sqrt(N);
#Оценка погрешности во втором случае
3*sqrt(Dzeta2)/sqrt(N);
Файл с данной программой можно взять тут
Точное значение интеграла легко вычислить аналитически, оно равно 1.
Результаты одного моделирования при
Для равномерно распределенной случайной величины:
Для случайной величины с линейной плотностью распределения:
В первом случае относительная погрешность более 21%, а во втором 2.35%. Точность
Думаю, данный модельный пример показывает важность выбора случайной величины в методе Монте-Карло. Выбрав, правильную случайную величину, можно получить более высокую точность вычислений, при меньшем числе итераций.
Конечно, так не вычисляют одномерные интегралы, для этого есть более точные квадратурные формулы. Но ситуация меняется при переходе к многомерным интегралам, т.к. квадратурные формулы становятся громоздкими и сложными, а метод Монте-Карло применяется лишь с небольшими изменениями.
Количество итераций и генераторы случайных чисел
Не трудно видеть, что точность вычислений зависит от количества
При решении некоторых задач для получения приемлемой точности оценки требуется брать очень большое число
Если в качестве источника случайности используется некоторое физическое явление (физический датчик случайных чисел), то все работает отлично.
Часто для вычислений по методу Монте-Карло применяют датчики псевдослучайных чисел. Главная особенность таких генераторов – наличие некоторого периода.
Метод Монте-Карло можно использовать при значениях
При проведении больших расчетов нужно убедиться, что свойства генератора случайных чисел позволяют вам провести эти расчеты. В стандартных генераторах случайных чисел (в большинстве языков программирования) период чаще всего не превосходит 2 в степени разрядности операционной системы, а то и еще меньше. При использовании таких генераторов нужно быть чрезвычайно осторожным. Лучше изучить рекомендации Д.Кнута, и построить свой генератор, имеющий наперед известный и достаточно большой период.
Литература
Популярные лекции по математике 1968. Выпуск 46. Соболь И.М. Метод Монте-Карло. М.: Наука, 1968. — 64 с.
Комментарии (9)

mickvav
13.01.2016 15:50+1А чего MISER и VEGAS забыли?
Да, и оставлю тут
www.gnu.org/software/gsl/manual/html_node/Monte-Carlo-Integration.html
vasiatka
13.01.2016 20:14Указанные алгоритмы несколько выходят за рамки данной заметки.
Vegas — алгоритм или лучше сказать, конкретное решение, приближающее распределение используемой случайной величины к |g(x)| / I. Иными словами выбирает плотность распределения пропорционально |g(x)| на сколько это возможно. О необходимости этого я говорил.
MISER — алгоритм, разбивает область интегрирования на две части рекурсивно до некоторой глубины. К каждой полученной области, применяется метод Монте-Карло. А количество итераций алгоритма в каждой области выбирается так, чтобы суммарная дисперсия получаемой оценки была минимальной.
Но, возможно, ссылка на библиотеку кому-то пригодится.

dimview
13.01.2016 18:05+1> и построить свой генератор
Зачем изобретать велосипед, когда есть PCG32? Ну или можно взять любой готовый блочный шифр и шифровать им числа от 0 до обеда.vasiatka
13.01.2016 21:30> и построить свой генератор
Да, не удачно выразился. Не о велосипеде речь. Хотел сказать, что-то типа «найти подходящий генератор (проверенный, с нужными свойствами), отличный от стандартного, и реализовать его в своей программе», а получилось, как всегда.
Зачем изобретать велосипед, когда есть PCG32?
Я не хотел совсем касаться темы конкретных генераторов ПСЧ, хотелось только обратить внимание на важность их выбора.
Что касается конкретного генератора.
Тут выбор богатый, и PCG32 — это всего лишь один из многих. Если бы в решении этой задачи (генерации ПСЧ) все было бы так просто, то было бы ровно одно решение.
Каждый выбирает, то что ему подходит лучше для решения конкретной задачи. Это мое мнение, возможно оно ошибочно, но пока такая концепция меня не подводила.
dimview
13.01.2016 21:52> Если бы в решении этой задачи (генерации ПСЧ) все было бы так просто,
Сейчас там действительно уже всё просто — если не известно, какой алгоритм использует стандартная библиотека, то надо на всякий случай взять готовую реализацию любого современного алгоритма (Mersenne Twister, PCG32) или блочного шифра (ChaCha20, Speck). Они все гарантированно проходят все тесты и отличаются только сложностью реализации и скоростью работы.
Преимущество PCG32 и Speck в том, что их реализация укладывается в несколько строчек, поэтому не нужно тянуть новую зависимость.
> то было бы ровно одно решение.
Не обязательно. Много решений существует по историческим причинам из из-за синдрома «изобретено не здесь». Языков человеческих вон тоже много существует, хотя они все одну и ту же функцию выполняют и примерно с одинаковым успехом.
RolexStrider
Вот в одном абзаце у вас есть два по отдельности истинных утверждения:
и… но из этого можно сделать ложный вывод, что «для вычислений по методу Монте-Карло чаще всего применяют стандартные датчики случайных чисел, период которых чаще всего не превосходит 2 в степени разрядности операционной системы, а то и еще меньше».
В действительности же применяются статистически-качественные ГПСЧ, чаще всего что-либо из семейства XorShift (период от 2^128-1 до 2^1024-1) либо Mersenne Twister — там уже от 2^19937 и более. А стандартные Math.rand(), которые в 85% случаев есть вариации на тему линейных конгруэнтных генераторов, да в каких-либо серьёзных симуляциях… Шутите? Вы бы еще RANDU вспомнили!
vasiatka
Спасибо, за комментарий. Полностью с вами согласен. Последние замечания в статье направлены больше на студенческую аудиторию. Например, я в студенческие годы (лет 13 назад) был удивлен результатом моделирования (при N>10^10).
Добавлю, что вариаций на тему генераторов случайных чисел очень много. Например, я часто использую для таких целей хорошо изученные криптографические алгоритмы (например, наши ГОСТы).
RolexStrider
Вспомнилось… В студенческие годы, и кстати примерно 13 лет назад напоролся на Modulo Bias (см.там соотв.параграф). Очень долго тупил: не мог понять, а что же я сделал не так с этим Math.rand() % m, ну типа всё очевидно же, получаем случайное число от 0...n, а нам надо 0...m, но ежели m < n, то поделим нацело, возьмем остаток, быстро, качественно, недорого,
херак-херак и в продакшн. Результат был, как бы немного предсказуем (см.статью по ссылке)… И неважно, взял бы я тогда стандартный сишный rand (он кстати и был), MT19937 или детектор космических лучей.Держу пари, что на этом «Modulo Bias» при симуляциях методом Монте-Карло гораздо больше народу споткнулось, чем на использовании негодных ГПСЧ.
dimview
Аналогичные грабли возникают, когда нужны случайные числа в плавающей точке, а ГПСЧ возвращает целые числа. Появляется желание просто поделить на RAND_MAX, но при этом есть неожиданные тёмные углы.