
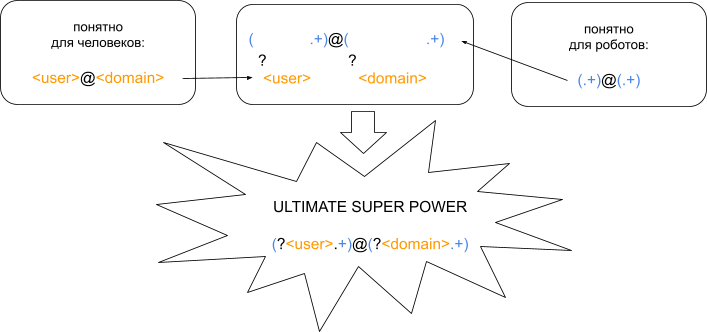
Разработчики делятся на три типа: тех, кто уже понимает регулярные выражения и порой решает сложные задачи одной строкой; тех, кто все еще боится их и всячески избегает; и тех, кто уже прочитал первую и вторую части этой серии статей и полон оптимизма разобраться с этими магическими письменами. Эта статья специально для третьих, чтобы обратно их напугать, ведь в этой части мы рассмотрим одну из самых сложных, но в буквальном смысле захватывающих тем.
Используйте навигацию, если не хотите читать текст целиком:
→ Старые знакомые
→ Захват-захват!
→ Ближе к реальности
→ Практическая польза
→ Три-в-одном
→ Парсим HTML
→ Иногда скобки — это просто скобки
→ Правила нумерации групп
→ Имена
→ Поиск простых чисел
→ Прочая магия
→ Заключение
Старые знакомые
Речь пойдет о круглых скобках. Казалось бы, что здесь страшного? Тем более, что мы уже рассматривали их еще в первой части.
Тогда говорилось, что круглые скобки позволяют ограничить область действия оператора ветвления «|». Например, следующее регулярное выражение определяет, не нарушает ли текст чьих-либо авторских прав:
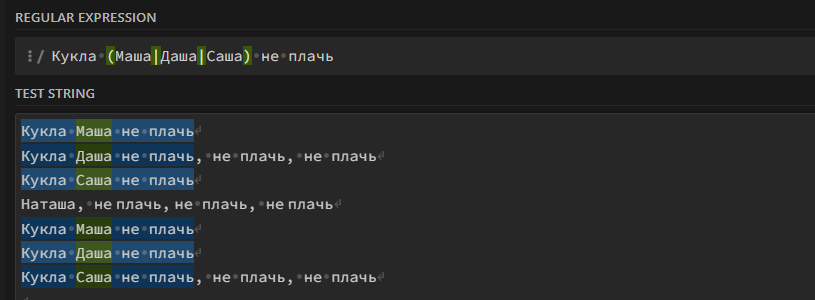
Кукла (Маша|Саша|Даша) не плачь
Однако у скобок есть и другое применение — сгруппировать текст, чтобы применить квантификаторы (звездочка, плюс, вопрос) не на один символ, а сразу на группу.
Например, продолжаем искать строчки песен:
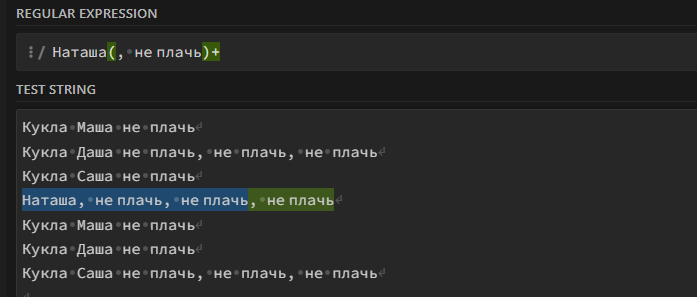
Наташа(, не плачь)+
Почему найденный текст где-то синий, а где-то зеленый? Скоро узнаем!

Захват-захват!
Итак, у круглых скобок есть два достаточно схожих применения. Можно даже сказать одно — сгруппировать символы. Однако, есть еще одно интересное свойство.
Рассмотрим такое выражение:
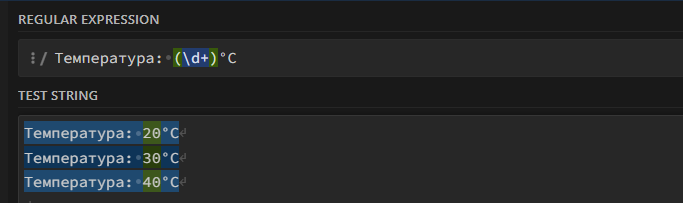
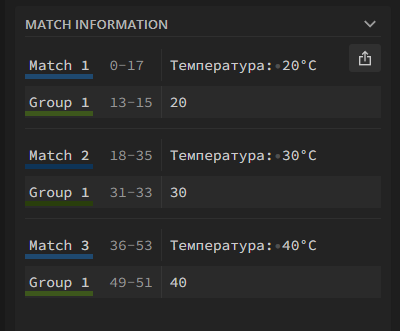
Температура: (\d+)°C
Выражение выглядит так, будто скобки здесь вовсе и не нужны: мы нигде не используем «|», а плюс находится внутри скобок. Ощущение, как будто они здесь просто для красоты.
На самом деле, главное предназначение круглых скобок — сформировать группу захвата, чтобы поймать и допросить подозрительные символы, не тронув при этом невинных граждан. В англоязычной литературе они так и называются — capturing groups.
В данном случае мы ищем строку, в которой указана температура, но извлекаем из нее не всю строку целиком, а только интересующее нас число.
В regex101 есть отдельное окошко, в котором можно посмотреть «захваченную» группу. Для каждой строки Group 1 содержит только интересующее нас число и ничего лишнего. Обратите внимание, что Group 1 подчеркнута зеленым — и тем же цветом выделяется в тексте.
Рассмотренное выше регулярное выражение работает только с градусами Цельсия, но игнорирует Фаренгейты. Досадное упущение, ведь именно в них измеряются произведения Брэдбери. Перепишем так:
Температура: (\d+)°(C|F)
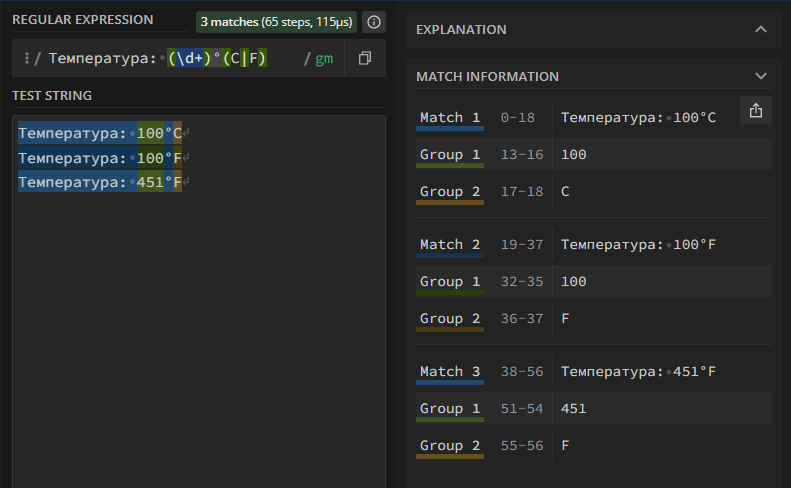
Теперь получилась не одна группа, а две: первая содержит число, вторая — шкалу измерения. То есть можно не просто находить строку по шаблону, но и нарезать найденный результат на отдельные кусочки и извлекать интересующую информацию. Именно за это и любят регулярки.
Ближе к реальности
Отдельное окошко в сервисе для отладки — это, безусловно, здорово, но как применять группы в реальной жизни? Это зависит от того, какой язык программирования вы используете. В предыдущих частях я избегал примеров кода, поскольку все языки все равно не покрыть, а оставлять кого-то обделенным не хотелось. Однако настало время, когда без кода уже не обойтись.
Приведу примеры только на JavaScript и Python, но в целом подход везде плюс-минус одинаковый.
Пример на JS:
const regex = /Температура: (\d+)°(C|F)/;
const line = 'Температура: 451°F';
const match = line.match(regex);
console.log(match[1]); // 451
console.log(match[2]); // F
Пример на Python:
import re
regex = r'Температура: (\d+)°(C|F)'
line = 'Температура: 451°F'
match = re.match(regex, line)
print(match.group(1)); # 451
print(match.group(2)); # F
Как вы заметили, группы нумеруются с единицы. Казалось бы, это нарушает главный закон кодекса программирования, согласно которому нумеровать нужно исключительно с нуля. На самом деле, все в порядке! У любого выражения есть нулевая группа — это все выражение в целом.
JS:
console.log(match[0]); // Температура: 451°F
Python:
print(match.group(0)); # Температура: 451°F
С некоторой вероятностью ваш любимый язык программирования остался неосвещенным, поэтому напишите в комментариях пример, как работать с группами в вашем любимом (и единственно лучшем) языке.
Практическая польза
Каким бы языком программирования вы ни пользовались, так или иначе приходится сталкиваться с сообщениями об ошибках: ошибках компиляции, ошибках времени выполнения, да и просто с предупреждениями или отладочной информацией. И иногда хочется автоматизировать обработку всего этого, то есть, грубо говоря, парсить логи.
Предположим, мы создаем дружелюбный ИИ, используя популярный генератор ошибок tsc, и получаем примерно такой вывод:
friendly_ai.ts:3:7 - error TS2451: Cannot redeclare block-scoped variable 'skynet'.
friendly_ai.ts:4:7 - error TS2451: Cannot redeclare block-scoped variable 'skynet'.
friendly_ai.ts:4:16 - error TS2348: Value of type 'typeof Skynet' is not callable. Did you mean to include 'new'?
friendly_ai.ts:5:8 - error TS2339: Property 'launchMissiles' does not exist on type 'Skynet'.
Заметно, что общий формат ошибок такой:
<файл>:<строка>:<столбец> — error TS<код ошибки>: <описание ошибки>
Поэтому можно распарсить следующим выражением:
(.+?):(\d+):(\d+) - error TS(\d+): (.*)
Выражение содержит пять пар скобок, соответственно, пять групп захвата.
- Первая ловит название файла (любые символы, пока не дойдем до двоеточия).
- Вторая — номер строки (цифры).
- Третья — номер символа (опять цифры).
- Затем пропускаем «- error TS» — эта последовательность служит чисто маркером.
- Далее получаем код ошибки (опять цифры, например 2451).
- И наконец последняя группа — текст ошибки (любые символы до конца строки).
Итого из одной строки мы «вырезаем» пять интересующих кусочков, которые расфасованы раздельно!
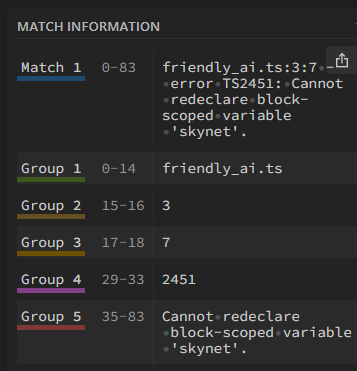
Вот так можно организовать извлечение информации из логов в коде.
Пример на JS:
const regex = /(.+?):(\d+):(\d+) - error TS(\d+): (.*)/;
const text = "ai.ts:5:8 - error TS2339: Property 'launchMissiles' does not exist on type 'Skynet'.";
const [ , filename, row, col, code, message] = regex.exec(text);
Обратите внимание на запятую перед списком переменных. Она нужна, чтобы пропустить нулевую группу — содержащую весь найденный фрагмент.
Пример на Python:
import re
regex = r'(.+?):(\d+):(\d+) - error TS(\d+): (.*)'
text = "ai.ts:5:8 - error TS2339: Property 'launchMissiles' does not exist on type 'Skynet'."
filename, row, col, code, message = re.match(regex, text).groups()
Обратите внимамание, что здесь пропускать нулевую группу не нужно. Метод groups() в отличие от метода group(), который мы использовали раньше, сам это сделает.
И в том, и в другом примере есть серьезная проблема — оптимизм. Код написан так, будто мы на 100% уверены, что требуемая строка найдется. И если в этом примере переживать не о чем, то в реальной жизни вполне может произойти так, что входная строка вообще не соответствует выражению, поиск не дает результата. Чтобы не поймать Null Pointer Exception, лучше сперва проверять, а действительно ли хоть что-то найдено.
Три-в-одном
Как все три применения взаимодействуют между собой? Что будет, если мы применим и ветвление, и квантификатор? Как оно будет работать в этом случае? Будет ли выбирать на каждом шаге или определится с выбором единожды и будет переизбирать до бесконечности?
Например, такое выражение:
(красный |зелёный )+
Это исключительно много красного ИЛИ много зеленого, или же произвольная последовательность красного и зеленого? И что у нас в этом случае с группами? Будет ли единственная Group 1 или они клонируются и появится новая группа для каждого повтора?
Давайте попробуем!
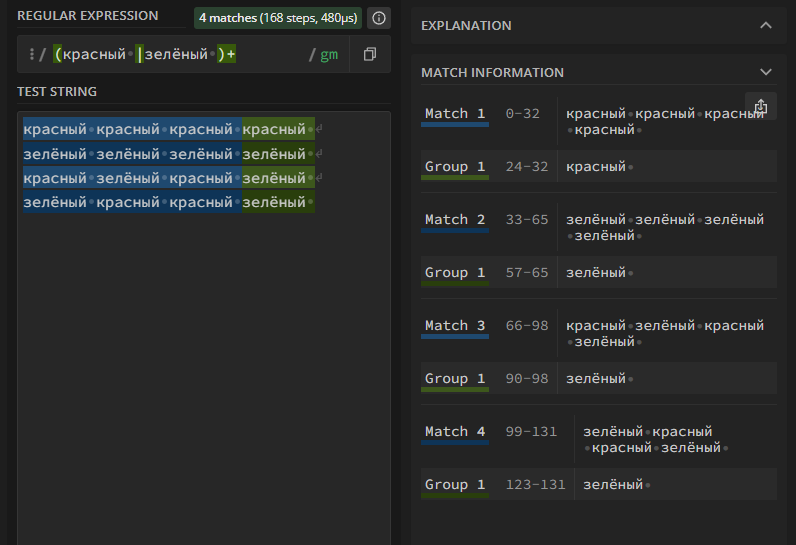
Как мы видим и на тесте, и на графе, на каждой итерации выбор происходит независимо. Что, в принципе, логично — мы это уже видели в предыдущей главе с квадратными скобками. Например, [0123456789]+ — это произвольное целое число, а не набор одинаковых цифр. Как сделать, чтобы слова повторялись (если нам вдруг это надо), мы скоро узнаем.
А что происходит с группой? Как мы видим, группа остается одна независимо от того, сколько раз она будет найдена в строке. Значение группы при каждом цикле перезаписывается, и в конце получается последнее найденное значение.
Парсим HTML
В первой части мы уже упоминали, что никогда, ни при каких условиях нельзя парсить HTML с помощью регулярных выражений. Это нужно, чтобы целостность Вселенной не пострадала. А давайте проверим Вселенную на прочность! Но осторожненько, не в полную силу.
Полноценный парсер HTML делать не будем, просто попробуем написать регулярное выражение, которое находит открывающий тег, закрывающий тег, и все, что находится между ними. То есть, нужно найти что-то вроде такого:
<тег>содержимое</тег>
А как сказать, что закрывающий тег должен быть точно таким же, как открывающий?
Если написать так, то ничего не получится, закрыться сможет чем угодно:
<(.*?)>(.*)<(\/.*?)>
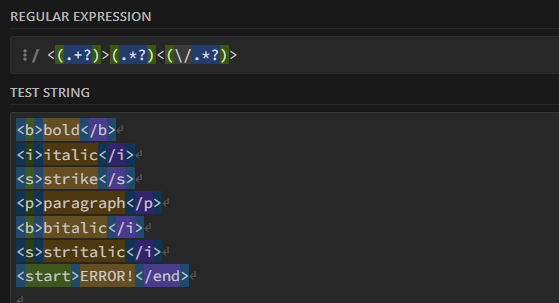
Нужно указать, что тег в конце должен повторять тег в начале. И это возможно как раз с помощью групп захвата! Дело в том, что захваченные символы можно использовать не только в каком-то внешнем скрипте, но и прямо внутри самого выражения!
Помните, в предыдущих частях мы говорили, что, чтобы наделить символ суперсилой, ему нужно вручить волшебную палочку? Вот такую: «\». Так вот, простые цифры 1, 2, 3 и так далее с волшебной палкой становятся не просто цифрами, а ссылками на группы! Например \1 означает «подставь сюда то, что нашлось в первой группе».
Вот так уже сработает:
<(.*?)>(.*?)<\/\1>
Первая группа — название тега, вторая группа — содержимое, а затем просто повторяем первую группу.
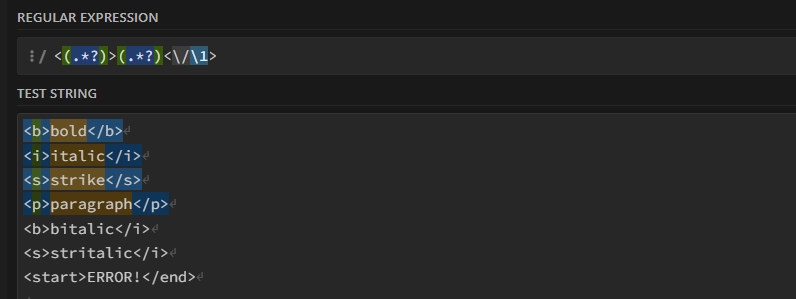
Вселенная пока устояла, но часы судного дня слегка дрогнули.
Иногда скобки — это просто скобки
Допустим, нужно найти в коде или в JSON что-нибудь, похожее на массивы целых чисел.
[ <число>, <число>, <число>, …, <число> ]
Таким образом нам нужно:
- Открывающая квадратная скобка \[
- Число \d+
- Запятая ,
- Число \d+
- Закрывающая квадратная скобка \]
Пункты 2 и 3 могут повторяться произвольное число раз (а могут и вообще отсутствовать), поэтому нужно объединить их в группу и поставить звездочку. Запишем:
\[(\d+,)*\d+\]
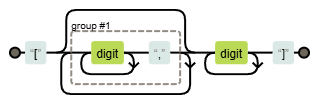
В результате у нас получилась захватывающая группа #1, хотя скобки нужны исключительно для того, чтобы применить звездочку на несколько символов. Захват не нужен.
Может показаться, что ну не нужен и нужен, пускай остается. Просто не будем им пользоваться. Однако, такие группы могут сбивать с толку, поскольку участвуют в нумерации, да еще и требуют дополнительные ресурсы, поскольку найденные фрагменты все равно нужно хранить.
Можно ли как-то сделать так, чтобы скобки перестали быть пакетиком три-в-одном и оставались просто скобками? Да! Можно отключить функцию захвата с помощью Элвиса. Элвис выглядит вот так:
?:
Просто ставим Элвиса сразу после открывающей скобки и он по каким-то загадочным причинам делает группу незаметной: «Проходите мимо, здесь ничего интересного, просто Элвис».
Такая группа называется незахватывающая. Это очень контринтуитивно, ведь понятно же, что с Элвисом любая группа была бы захватывающей. Ан-нет. Проверяем:
\[(?:\d+,)*\d+\]
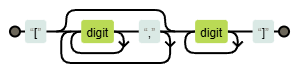
На графе группа и вовсе пропала.
В реальной жизни выражение работало бы гораздо лучше, если щедро насыпать пробелов \s* между всеми элементами, но тогда оно сильно теряет в иллюстративности, поэтому не стал этого делать.
Правила нумерации групп
Как мы уже видели, группы нумеруются слева направо. Все понятно. На этом главу можно закончить.
Однако, остановимся все-таки подробнее, поскольку иногда бывает путаница. Важно запомнить следующие правила:
- Нумерация групп зависит только от регулярного выражения. Входная строка никак не влияет на нумерацию. Не важно, сколько раз найдется группа в строке, хоть ни разу, хоть двадцать восемь раз — это все равно одна группа и ее номер зависит только от выражения.
- Группы нумеруются слева направо по открывающим скобкам. Группы могут быть вложенными сколько угодно глубоко. Чтобы не было путаницы, они нумеруются по открывающим скобкам.
- Незахватывающие группы в нумерации не участвуют.
Если после группы стоит «+» или «*», то она может повториться несколько раз. Повлияет ли это на нумерацию групп? Будет ли она повторена несколько раз с разными номерами? Нет. Как мы уже видели ранее в разделе «Три-в-одном», в этом случае захватывается только последний найденный фрагмент.
А если после группы стоит знак «?» или «*», то группа может вообще отсутствовать. Повлияет ли это на нумерацию групп, которые идут после? Нет, не повлияет. Если опциональная группа не найдена в строке, она будет содержать пустое значение, например
undefined в JS или None в Python. Нумерация групп не изменится.import re
regex = r'Закрывайте(, пожалуйста,)? (окно|дверь)'
print(re.match(regex, 'Закрывайте, пожалуйста, дверь').groups()) # (', пожалуйста,', 'дверь')
print(re.match(regex, 'Закрывайте, пожалуйста, окно').groups()) # (', пожалуйста,', 'окно')
print(re.match(regex, 'Закрывайте дверь').groups()) # (None, 'дверь')
print(re.match(regex, 'Закрывайте окно').groups()) # (None, 'окно')
Если используется ветвление, и в одной ветке есть группа, а в другой нет, означает ли это, что при разных входных строках нумерация групп будет разной? Нет, нумерация всегда одинаковая. Если в одной из веток группа отсутствует, и входная строка соответствует именно этой ветке, то группа просто останется пустой, как и в примере выше.
Вот иллюстрация нумерации групп.
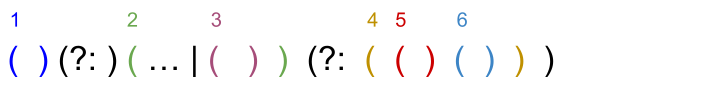
Если выражение большое и запутанное, то чтобы не запутаться в нумерации, можно дать группам имена.
Имена
Однажды кому-то пришла в голову мысль: а что если регулярные выражения ниспосланы на Земпю не только для того, чтобы нести страдания? А что если их можно сделать удобными и читабельными? А что если группам вместо порядковых номеров присваивать понятные человеку имена?
Например, раз email условно имеет формат <user>@<domain>, а в виде регулярного выражения, если не особо заморачиваться, записывается как
(.+)@(.+), то почему бы не совместить эти записи?Теперь к группам можно обращаться по имени.
Пример на JS:
const regex = /(?<user>.+)@(?<domain>.+)/;
const text = 'user@test.com';
const match = text.match(regex);
console.log(match.groups.user); // user
console.log(match.groups.domain); // test.com
Пример на Python:
import re
regex = r'(?P<user>.+)@(?P<domain>.+)'
text = 'user@test.com'
match = re.match(regex, text)
print(match.groupdict()['user']) // user
print(match.groupdict()['domain']) // test.com
Обратите внимание — на Python формат регулярки немного отличается: именованные группы начинаются с «?P».
Группа, которой задано имя, участвует в нумерации по обычным правилам. Таким образом, у нее есть и индекс, и имя, и можно обращаться обоими способами.
Фича кажется крутой и полезной, но, как это часто происходит, оказалась не такой уж и востребованной. Возможно, поэтому в движке RE2 (а, следовательно, в Google Docs/Sheets) она вообще не реализована.
Поиск простых чисел
В первой части упоминалось, что с помощью регулярных выражений можно даже искать простые числа. Звучит невероятно, но наших знаний уже достаточно, чтобы разобраться, как это работает.
Вот это магическое выражение выглядит, будто Пабло Пикассо открыл для себя ASCII-art:
^1?$|^(11+?)\1+$
Сперва немного развеем кликбейтный заголовок. Во-первых, это выражение не ищет простые числа, а проверяет число на простоту (точне на непростоту). Во-вторых, число должно быть записано в единичной, или унарной, системе счисления. Например, 7 записывается как 1111111.
Чтобы быть совсем точным: если строка из N единиц соответствует этому выражению, то N — не простое. Звучит уже не так заманчиво, как обещали на упаковке, но тоже интересно.
Давайте разберем, как оно работает. Простое число имеет только два множителя: 1 и само число. У составного же числа множителей больше, а значит его всегда можно разбить на два множителя, каждый из которых больше единицы. Исключениями являются 0 и 1: хоть их и нельзя разбить на множители больше единицы, но и простыми они тоже не считаются.
Теперь посмотрим на выражение, разбив его на отдельные компоненты.
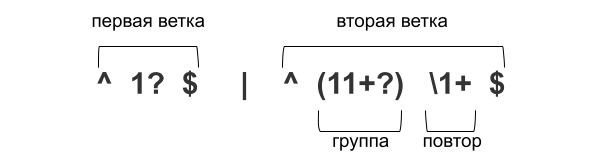
На графе выглядит еще нагляднее.
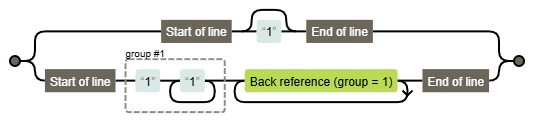
Итак, две ветки. Первая обрабатывает особые случаи — ноль и единицу.
Самое интересное во второй ветке. Сперва находим «голову», состоящую как минимум из двух единиц, и сохраняем в group #1. По сути, это строка из единиц, обозначающая некое число от 2 до N. Назовем это число X. Затем пытаемся разместить точно такие же группы, чтобы они целиком заполнили «хвост» без остатка. Это получится сделать, только если N нацело делится на X. В таком случае одна группа будет в «голове» и как минимум одна — «в хвосте». Значит, N можно разложить на два множителя больше единицы, следовательно, оно не простое.
Например, число 6 представим как 111111. Голова — [11], хвост — [11,11]. Следовательно, 6 = 2x3.
Как движок определяет размер группы? Перебором. Сперва пробуется минимально возможная группа 11. Если не получилось (хвост не сходится), пробуется группа 111. Если опять не получилось, пробуется 1111 и так далее. В конечном итоге или найдется подходящий размер, или закончатся единицы в строке.
Причем такой порядок от меньшего к большему — из-за ленивого плюса. Если бы плюс был жадным, перебор начинался бы с конца — сперва взять все единицы, что, разумеется приведет к фейлу, затем на одну меньше и так далее.
Вот такой крайне неэффективный, но вполне работающий метод определения (не)? простоты, который иногда применяют в code golf.
Прочая магия
Как мы увидели, у круглых скобок изначально несколько применений. А если после открывающей скобки стоит вопросительный знак, то поведение может еще как-то измениться:
- (?:) — незахватывающая группа,
- (?<>) — именованная группа.
Поэтому когда хотят добавить новую экспериментальную нестандартную фичу, обычно прикручивают ее к круглым скобкам. А со временем фичи становятся старыми, привычными и стандартными. Как правило, они уже выходят за пределы регулярных выражений (в математическом смысле) и добавляют функциональность, которая в традиционных регулярных выражениях будет или слишком многословной, или вовсе невозможной.
Примеры таких фич:
| (?=) |
Lookahead: только если впереди указанная строка |
| (?!) |
Negative lookahead: только если впереди точно не указанная подстрока |
| (?<=) |
Lookbehind: посмотреть назад |
| (?<!) |
Negative lookbehind |
| (?R) |
Рекурсия |
Заключение
Этот цикл статей задумывался как простое, ненапряжное и достаточно поверхностное введение в регулярные выражения для тех, кто вообще ни разу их не пробовал. Безусловно, тема эта большая, многогранная и с множеством нюансов. Если пытаться рассмотреть их все, потеряется та легкость и ненавязчивость, которая изначально планировалась.
На этой части планировалось остановиться. Но если вам кажется, что осталось чувство незавершенности, и вы жаждете продолжения — напишите, что еще хотелось бы рассмотреть.
А вообще для более глубокого и досконального изучения регулярных выражений я рекомендую ресурс regular-expressions.info — возможно, он наиболее исчерпывающе разбирает тему регулярок.
Комментарии (7)


morr
30.06.2025 09:06Тем, кто хочет навсегда для себя закрыть вопрос регулярных выражений, нужно прочитать эту книгу https://www.ozon.ru/product/regulyarnye-vyrazheniya-3-e-izdanie-fridl-dzheffri-1393134797
Там простым и понятным языком описано, что означают все эти закорючки, и как они работают.

sleirsgoevy
30.06.2025 09:06А ещё с помощью регулярок можно решать 3-SAT. Пример:
^[0-1]{4}(?<=100.|010.|001.)(?<=.000|.111)$


JBFW
30.06.2025 09:06А на умершем уже Perl со сложным синтаксисом это всё пишется примерно так:
if ( $str =~ /(.+?):(\d+):(\d+) - error TS(\d+): (.*)/ ) { print "$1, $2, $3, $4, $5\n"; }И проверили, что строка подпадает под регулярку, и подстроки из нее сразу выкусили. Сложный синтаксис...
domix32
Забавно как "простые слова" длятся уже третью статью.
DandyDan Автор
Ну так "простыми словами", а не "в двух словах" ;)