

Цифры впечатляют: 37,5% на Humanity’s Last Exam, 1 048 576 токенов контекста, 13 миллионов активных юзеров‑разработчиков. За ними стоит Gemini 3 Pro — новая вершина в линейке ИИ‑моделей Google.
Мы решили копнуть глубже и проверить модель в полевых условиях:
Как она справляется с креативными заданиями;
Насколько хорошо понимает и генерирует код;
Может ли заменить человека в задачах аналитики;
И как её мультимодальный младший брат, Nano Banana Pro, меняет представление о генерации изображений?
Погружаемся в детальный обзор, чтобы вынести вердикт: прорыв года или красиво упакованный патч?

TL;DR;
Gemini 3 Pro — свежайший флагман Google (релиз: 18 ноября 2025-го), от которого у многих моделей, кажется, слегка подогнулась матрица. Он объединяет работу с текстом, кодом, изображениями, аудио и видео, выдавая рассуждения уровня профессора.
На вход модель ест всё: документы, кодовые базы, картинки, звук, видео — и аккуратно прожёвывает это в контексте 1 048 576 токенов.
В большинстве задач Gemini 3 Pro уверенно переигрывает ChatGPT 5.1 и даже GPT 5 Pro. ChatGPT держит позиции лишь там, где важна строгая математическая логика и другие знакомые подходы.
Google сообщает: уже 13 млн разработчиков заселили Gemini в свои IDE и скрипты.
Про изображения: наряду с Gemini 3 Pro вышла Nano Banana Pro — визуальный модуль, который справляется с композициями из 14 файлов, встраивает длинные надписи, рисует инфографику и редактирует фото.

P. S. Если вы хотите протестировать Gemini 3 Pro и Nano Banana Pro сами уже сейчас, но сталкиваетесь с трудностями доступа, то самый простой способ — воспользоваться платформой BotHub. Там вы можете работать с оригинальным ChatGPT и другими передовыми нейросетями без VPN и с оплатой российскими картами.
По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями! Именно в BotHub я проводил тесты (вы найдёте их дальше в статье).
Содержание
➤ Что такое Gemini 3 Pro
➤ Технические характеристики
➤ Как Gemini 3 Pro ведёт себя в полях: бенчмарки
➤ Тесты и сравнения исследователей
➤ Nano Banana Pro — что важно знать
➤ Тесты!
Что такое Gemini 3 Pro
Gemini 3 Pro — это флагманская LLM от Google, новейшее поколение, которое объединило все возможности поколения 1, 2 и 2.5. Google называет её самым интеллектуальным и фактологически точным ИИ на сегодня.
DeepMind описывает модель как «заметно превосходящую» предшественника практически по всему, что можно измерить: рассуждения, кодинг, мультимодальность; даже умение аккуратно нести чушь, когда нужно, — улучшилось.
Google активно рекламирует Gemini 3 Pro как «новый шаг в эволюции разума»:
Она показывает «PhD‑уровень рассуждений» (Humanity’s Last Exam 37,5% без помощи инструментов, при 26% у ChatGPT 5 и 31,6% у GPT 5 Pro).
Устанавливает новый рекорд по тестам математики (MathArena Apex 23,4%).
На лидерборде LMArena у неё 1501 Elo.
GPQA Diamond — 91,9%.
В техническом отчёте Google пишут, что Gemini 3 Pro «стал самым продвинутым решателем в серии Gemini для сложных задач» и может «понять огромные объемы данных из разных источников».
В дополнение к базовой модели Google планирует выпустить режим Gemini 3 Deep Think для особо сложных задач (он уже превзошёл Pro на высокоуровневых IQ‑тестах).
Тарифы: входные токены стоят около 2 $ за 1M (контекст до 200к) и 4 $ за 1M токенов (если длинный контекст), выходные — 12/18 $ за 1M. Это дороже ChatGPT 5.1, но если вы собираетесь скормить модели три тома технической документации и попросить выжать из неё план миграции сервера, то оно наверняка окупится.
Технические характеристики
У Gemini 3 Pro контекстного окна — как у романиста, который решил писать эпопею в один том: до миллиона токенов на вход. Это значит, что модель спокойно проглатывает целую монорепу, пачку логов за сутки, пару PDF’ов толщиной с «Трое в лодке» и ещё останется место на десерт. А на выходе — 65 536 токенов. То есть если попросить её «пояснить, как работает всё», она вполне может попытаться.
Для сравнения, ChatGPT 5.1 в режиме рассуждений держит 196k, а через API — 400k.
Под капотом Gemini 3 Pro работает на архитектуре SMoE — разреженном микшере экспертов. Представьте себе не одного всезнающего гения, а толпу специалистов — один по математике, другой по коду, третий по видео. И модель сама решает, кого из них звать на сцену.
Gemini 3 Pro изначально тренировали так, словно она должна понимать всё: и инструкцию к видеомагнитофону, и комиксы, и диаграмму, и расписание электричек. Поэтому она нативно мультимодальна:
Можно загрузить фото рецептов, перевести их в кулинарные статьи или построить на основе серии видео обучающие карточки.
Разработка часто включает скриншоты интерфейсов, логи, PDF со схемами и даже короткие видеофрагменты — Gemini 3 Pro умеет учитывать всё это в одном запросе.
Вы можете дать модели целый файл PDF или длинный видеофайл (до 45 минут с аудио) — и модель постарается понять и ответить.
Объединить ReadMe + 10 файлов кода + CI‑логи в один контекст и попросить найти возможную причину падения билда — здесь это работает намного стабильнее, чем раньше.
Такой набор открывает двери к задачам, которые раньше выполняли только люди с терпением йога и стулом без мягкой подушки. А теперь можно просто разговаривать с моделью на человеческом языке — и она, если надо, сама найдёт нужный кусок данных, сопоставит, запустит мини‑анализ или предложит вариант решения. Иногда кажется, что она вот‑вот попросит кофе и скажет: «Ща, доделаю».
Работает всё это на фирменных TPU и стекe JAX/ML Pathways — то есть модель буквально выросла под жёлтым солнцем Google.
Знания у неё — по январь 2025 года, а остальное она подтягивает из свежих сетевых источников. Хорошо бы и нам так: обновился за ночь — и уже знаешь всё про курс валют и где оставил носки.
Как Gemini 3 Pro ведёт себя в полях: бенчмарки
Если верить обзорам, тестам и впечатлениям журналистов, Gemini 3 Pro ворвался в мир бенчмарков как новый отличник, который не просто выучил параграф, а ещё и переписал учебник «чтобы было правильнее».
")
Gemini 3 Pro и Gemini 3 Pro Image показали рекордные результаты на reasoning‑бенчмарках Humanity’s Last Exam — 37,5%/45,8% (без инструментов и с ними), ARC‑AGI-2 — 31,1%, MMMU‑Pro — 81,0%.
Модель решает математические задачи на принципиально новом уровне — новый рекорд 23,4% на MathArena Apex.
81% на MMMU‑Pro (понимание изображений) и 87.6% на Video‑MMMU (понимание видео) — тоже очередные рекорды для крупных моделей.
Модель превосходно справляется с фактическими вопросами: 72,1% на SimpleQA Verified.
По словам Google, Deep‑Think‑режим добивается на Humanity’s Last Exam показателя 41%.
И это не вспышка на солнце — в LMArena, где случайным пользователям показывают результаты разных моделей и спрашивают: «Ну что, какой ответ лучше?», — Gemini лидирует в пяти из шести категорий: текст, распознавание изображений, генерация, редактирование, веб‑поиск. Это тот редкий случай, когда народное голосование совпадает с таблицами: Gemini действительно перформит.
Результаты LMArena






Но никакая сказка не обходится без ложки дёгтя. Google честно признаёт: да, модель иногда ошибается. И если уж ошибается — то с фантазией.
В тесте AA‑Omniscience (6000 вопросов) Gemini 3 Pro чаще всех выдаёт правильные ответы… но когда промахивается, то в 88% случаев предпочитает «сочинить», а не признать «не знаю». Это как студент, который на экзамене не помнит формулу, но начинает уверенно рассказывать историю про древних шумеров — лишь бы не молчать.
Для сравнения: Claude 4.5 Haiku в аналогичных ситуациях фантазирует только в 26% случаев, что делает его своеобразным «скромным ботом», который честно признаётся, когда не уверен.
Google напоминает: бенчмарки — вещь относительная. Лучше всего проверять модели самому, так сказать, методом «А ну‑ка, ответь вот на это». Но результаты всё же настолько яркие, что, по слухам, Сэму Альтману пришлось успокаивать сотрудников OpenAI, мол, держимся, ребята, времена сложатся непростые — но ещё не вечер.
(В этот момент Альтман стоит, сжимая кружку с надписью «We can still win», а сзади в окне — такой огромный логотип Gemini, который медленно подплывает всё ближе.)
Тесты и сравнения исследователей
Gemini 3 Pro вышел на ринг ровно в тот момент, когда конкуренты тоже подтянули перчатки и сделали разминку. Поэтому сравнения получились особенно показательные.
Авторский батл из 11 испытаний Tom’s Guide показал явное преимущество Gemini 3: 7 побед из 11. Особенно хорошо он проявил себя в анализе документов, стратегических задачах и креативных заданиях, где нужно не просто «написать», а «написать умно».
Например, в одном из экспериментов редакции Gemini 3 Pro блестяще решил творческую задачу со строгими ограничениями на количество 300 слов — он не просто следовал ограничениям, а творчески использовал их для усиления структуры текста, что сделало историю более оригинальной и впечатляющей.

«ChatGPT-5.1 успешно соблюдал ограничение на использование слов, начинающихся на буквы A–M, и представил связный рассказ с тремя сюжетными поворотами и клиффхэнгером, однако повествование ощущалось несколько натянутым, а поворот с „отражённой Амарой“ является распространённым научно‑фантастическим тропом. Gemini 3 мастерски использовал ограничение A–M, чтобы создать отчётливый, роботизированный повествовательный голос, и его три сюжетных поворота оказались более захватывающими и неожиданными, увеличивая масштаб истории от галлюцинации — до метакомментария о самом существовании».
ChatGPT 5.1 перещёлкивал Gemini лишь в рутинной математике (там, где важны привычные конвенции) и в одном тесте про бизнес‑этикет. То есть реальная ситуация — обе системы сильны, просто у них разные сильные зоны.
Одна из сильных сторон Gemini 3 — генерация кода. TechRadar показал пример «веб‑игры на пальцах», которую автор описал текстом, а Gemini 3 Pro мгновенно реализовал в рабочий прототип. Причём не просто «запилил что‑то», а реализовал нужное управление, дорисовал графику, улучшил механику — и, в общем, с каждой итерацией доводил игру до состояния «ну это уже хоть на itch.io выкладывай».
«В этом эксперименте Gemini 3 Pro „интуитивно угадал моё намерение“ и в итоге обошёл как ChatGPT 5.1, так и Claude 4.5 по скорости и качеству результата. В конечном итоге это едва ли можно было назвать соперничеством. Gemini 3 Pro оказался быстрее и умнее. Там, где я давал лишь минимальные ориентиры, он заполнял пробелы и воплощал мою идею игры в реальность. Казалось, Gemini 3 Pro почти интуитивно считывал мой замысел и в целом выдавал, с учётом ограничений, максимально возможный результат».

Авторы отметили, что Gemini будто сам дописывал промпты. Он брал «идею между строк», достраивал недостающие части и аккуратно делал игру всё лучше. К финалу там уже была не плоская сцена, а полноценная маленькая 3D‑арена, камера тряслась при столкновениях — ну красота же.
ChatGPT 5.1 и Claude Sonnet 4.5 в том же задании тоже справились добротно, но с меньшей гибкостью.
«Ежедневные» задачи: оба на равных
В бытовых запросах — вроде «подскажи подарок», «помоги с домашкой», «сделай маршрут», «разберись с умным домом» — разница между Gemini 3 и ChatGPT 5.1 становится почти косметической.
TechRadar проверил:
Gemini отвечает чётко, системно, по делу.
ChatGPT добавляет больше человечности, эмоций, небольших «историй внутри ответа».
Правда, иногда даже в повседневном общении у Gemini 3 отмечается склонность к «параноидальному» мышлению — редко, но модель может вести себя так, словно находится на экзамене.
Nano Banana Pro — что важно знать

Если текстовая версия Gemini 3 Pro — это такой академик в белом халате, который рассуждает, опираясь на стопку графиков, то Nano Banana Pro — её младший брат‑художник, который забрал у академика ноутбук, включил музыку и начал творить. Формально его ещё называют Gemini 3 Pro Image, но это уже тонкости номенклатуры.
Официальный анонс Nano Banana Pro показывает богатые возможности редактирования и монтажа. Он строится на тех же алгоритмах, что и текстовая модель, поэтому может использовать расширенное понимание мира.
Итак, что же умеет этот банановый гигант?
Текст на картинке. В эпоху, когда первые генераторы рисовали надписи так, будто их писали маркером в поезде на кочках, Nano Banana Pro выглядит как звезда каллиграфии. Он почти не ошибается в буквах, шрифтах, межбуквенных расстояниях. Хочешь афишу, хочешь инфографику, хочешь табличку «Осторожно, кот!» на хинди — пожалуйста. И да, локализацию текста он умеет тоже.




Это не магия и не зелье из подвала профессора — просто алгоритмы. Но выглядит именно как магия: до 14 исходников можно собрать в единую композицию. Причём модель сохраняет форму, выражение, структуру объектов так тщательно, что кажется, будто лично знакома с каждым персонажем. Например, 14 кукольных эскизов, собранных в единую сцену на диване. И хочешь — перекрась одежду, хочешь — поменяй прическу. Достаточно указать номер исходного файла или пару описательных слов в промпте. Сценографы, художники, дизайнеры — готовьте шампанское.

Gemini 3 Pro Image умеет управлять параметрами снимка как профессиональный фоторедактор:
— смещать фокус,
— менять ракурс,
— переставлять освещение — хоть симулируй съёмку на фонарик под одеялом,
— менять угол съемки,
— настраивать глубину резкости,
— добавить другие эффекты по описанию.
Всё это напоминает работу продвинутого 3D‑редактора, но делает ИИ сам, буквально по простой текстовой подсказке.


Суперспособность: он ещё и знает, что рисует. Поскольку Nano Banana Pro подключён к знаниям Google‑поиска, он умеет проверять факты прямо во время генерации. Нужно построить карту давления воздуха на завтра? Нарисовать диаграмму электросхемы по ГОСТу? Смоделировать план завода? — Пожалуйста, заказывайте, пока горячо. По сути, это первый генератор изображений, который не просто «рисует красиво», но и подтверждает данные, на которых строит визуал.
Промпты и больше примеров здесь, здесь и здесь.
Тесты!
Пора перейти от теории к практике. На этот раз тест получился особенно забавным, потому что речь пойдёт о симуляции совместного редактирования.
Если вы хоть раз одновременно правили документ с кем‑то ещё, вы знаете это ощущение: курсоры скачут, текст живёт собственной жизнью, и вот уже коллега зачем‑то удалил ваш заголовок, хотя клялся, что только «чуть поправит пунктуацию». Когда эта фича впервые появилась, казалось невероятным, что кто‑то смог заставить такое работать без катушек Теслы и шаманских бубнов.
Я выбрал формат HTML + JS, чтобы всё можно было запустить в один клик и без тяжеловесных фреймворков.
Ниже — результаты.
(Удобнее открыть CodePen’ы в новой вкладке.)
А вот сам промпт, который я выдал моделям:
Сгенерируй одностраничный HTML — прототип совместного (кооперативного) Markdown‑редактора с имитацией редактирования в реальном времени.
1) В интерфейсе две панели: слева — редактор (contenteditable с подсветкой синтаксиса), справа — предпросмотр с рендером Markdown (используй CDN‑версию marked.js).
2) Реалтайм‑симуляция:
— Моделируй нескольких пользователей: их курсоры отображаются с разными цветами, движения курсора генерируются локально (simulated peers) через setInterval.
— Реализуй merge/conflict resolution simple OT‑like (операции вставки/удаления локально), или обёртку, которая помечает изменения другого пользователя (visual diff).
— Пользователи редактируют текст (исходный текст должен быть на русском, это может быть случайный текст) в случайных местах. Вдобавок сгенерируй 30 случайных предложений (на русском) — пользователи могут добавлять эти предложения целиком или брать из них отдельные слова для добавления. Также пользователи могут редактировать/заменять предложения/слова, воспользовавшись тем же примером случайного текста. Пусть правки выглядят осмысленными, то есть в рамках одной правки пусть происходит добавление/замена или слова, или набора слов, или целого предложения (а не случайного символа/символов). Новые фрагменты (слова/сочетания слов/предложения) пусть добавляются с учётом уже имеющихся слов, в частности на границах имеющихся слов (то есть не внутри имеющихся слов), с учётом знаков препинания и заглавных букв в начале предложений. Символы добавляются не мгновенно, а последовательно (как при вводе с клавиатуры); если при этом пользователи вводят текст одновременно в разных местах, нужно в реальном времени рассчитывать смещение текста с учётом только что введённых символов.
3) Сохранение: localStorage + экспорт/импорт.md.
4) UI‑эффекты: подсветка текущего редактора (glow), autosave‑индикатор (pulse), анимация появления новых сообщений/курсорных подсказок.
5) Добавьте выбор цветовой темы интерфейса через раскрывающийся список.
6) ВАЖНО! Текст в левой панели должен быть на русском! И вносимые виртуальными пользователями правки — тоже на русском!
Gemini 3 Pro
Claude Opus 4.5
Рассмотрим результаты!
(Кстати, вам тоже всегда казалось, что наименования типа Claude 3.7 Sonnet выглядят неестественно и нужно переставить местами две правые части? Наконец‑то в «четвёрке» это сделали: Claude Opus 4.5.)
Забегая вперёд, результат Gemini 3 Pro оказался более правильным:
В демке от Gemini я не обнаружил глюков — ввод правок происходит правильнее, даже когда «Анна» и «Борис» вводят текст одновременно.
В прототипе модели Opus 4.5 не учтены требования к коду, связанные с перерасчётом отступов (для 2-го, 3-го и так далее пользователя): из‑за этого, как только пользователи начинают печатать одновременно, слова текста превращаются в кракозябры. Начинается нечто, напоминающее криптографию времён Шифровального отдела республики.
Что ж, конкретно в этом задании у Gemini получилось лучше. Возможно, стоило проверить ещё и Claude Sonnet 4.5, так как она парадоксальным образом (будучи более бюджетной моделью) иногда справляется более изобретательски.
Почему такие задания вообще сложны?
Потому что симуляция совместного редактирования — это уже агентная задача. Она требует:
разбивки на этапы,
планирования,
пересчёта позиций,
создания реалистичного поведения,
и понимания логики более расширенной, чем простое «сгенерируй HTML».
Одним проходом такое обычно не решить: нужно уточнять детали, переписывать части кода, вносить корректировки. Именно поэтому опытные разработчики так любят работать с ИИ‑ассистентами циклично, шаг за шагом — в духе «давай поправим вот это, теперь вот то».
Кстати, как правильно использовать ИИ для разработки и не свихнуться, можно почитать вот здесь: https://habr.com/ru/companies/bothub/articles/881248/.

ИИ — это новый яд энергии, придающей скорость разработке и бизнесу. Gemini 3 несёт новый заряд этой энергии: и он, и другие модели уже подключили моторы GPT‑авторазума. А мы — посвящённые в эти технологии — ощущаем себя мастерами в хитроумном ангаре прогресса: знаем коды, крутим гайки, знаем, куда поставить конденсатор, чтобы модель не взорвалась эмоцией.
В целом Gemini 3 Pro — это большой шаг. Gemini 3 Pro — яркий пример того, как быстро развивается ниша больших ИИ‑моделей. Он не просто чуть‑чуть лучше старого Gemini, это чуть ли не иной класс моделей.
В ближайшем будущем ждём Deep‑Think‑режим — особо «мозговитую» версию модели.
Комментарии (11)

empenoso
07.12.2025 18:22А чем от preview отличается?

dmitrifriend Автор
07.12.2025 18:22Это и есть Preview. С Gemini 2.5 Pro было схожим образом: «на всякий случай» обозначенная как Preview, её предварительная версия выкатывалась и обновлялась несколько раз в марте — июне 2024 года, а 17 июня вышла стабильная. Скорее всего, стабильная 3 Pro тоже выйдет через три месяца с момента релиза — в феврале 2025-го. Но все эти модели часто обозначаются без тега Preview, так как он обычно описывает что-то совсем нестабильное, но на самом деле модель работает уже достаточно предсказуемо.

Archangel_BasaroS
07.12.2025 18:22Подскажите лучший способ работы с Нано Банана в Antigravity IDE , пожалуйста .

Vigor1983
07.12.2025 18:22Может в каких-то бенчмарках результаты и действительно впечатляющи. Но с точки зрения реальной работы повседневного помощника он ужасен. Склонность к вечными галлюцинациями на ровном месте, потеря контекста, постоянные ошибки.
Чатгпт с переходим на 5ю версию тоже крепко обосрался - но гугл это просто сырая хрень.
Похоже что автор взял какие-то маркетинговые материалы и перевел.dmitrifriend Автор
07.12.2025 18:22Что именно у вас не получалось в работе с этими моделями?

mstrnkd
07.12.2025 18:22У меня например не получалось настроить Klipper на 3д принтере к1. С помощью Gemini 3. Он набросал мне код, я его вставил в printer.cfg иии ничего не сработало. Он все бился, пытался...мы и код удаляли из прошивки и добавляли , а chat gpt 5 1й командой все разрулил.
Еще приходилось заходить в сервисное меню офисной техники, и так получилось, что chat gpt вроде бы навел на правильную комбинацию цифр для входа в серв. меню, но потом потерялся. Gemini подхватил ситуацию и помог найти нужные правки.
Но никто из этих двух ИИ не смог дать инструкцию, как перевести язык с китайского на русский в принтере Pantum. А там все решалось нажатием "влево-влево-ok".
Кодерам может все эти модные иишки и стали большим подспорьем в работе, но тем, кто работает с настройкой техники....ну не знаю, полагаться на них нельзя. Всю критически важную и что самое важное, достоверную инфу в итоге находишь все равно сам.

rPman
07.12.2025 18:22если вы собираетесь скормить модели три тома технической документации и попросить выжать из неё план миграции сервера, то оно наверняка окупится.
я бы не надеялся на результат.
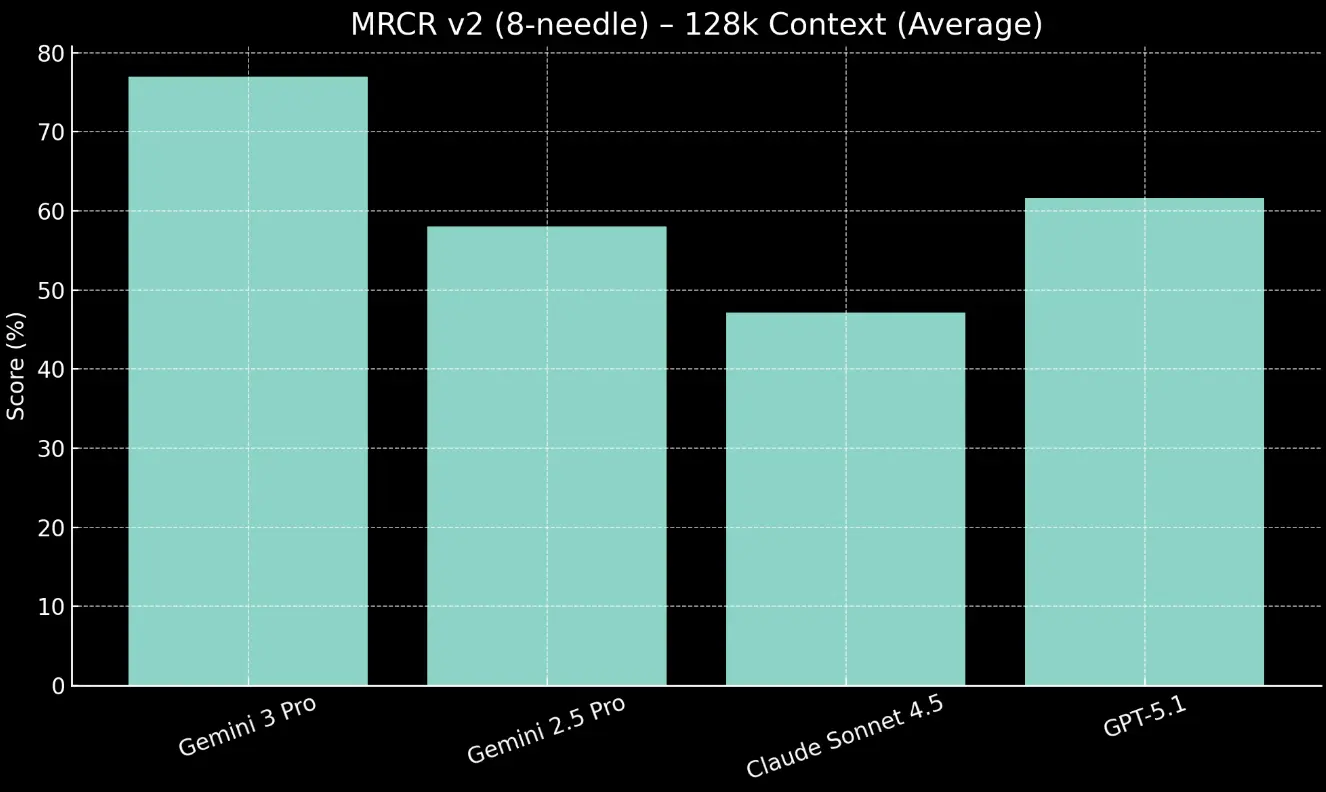
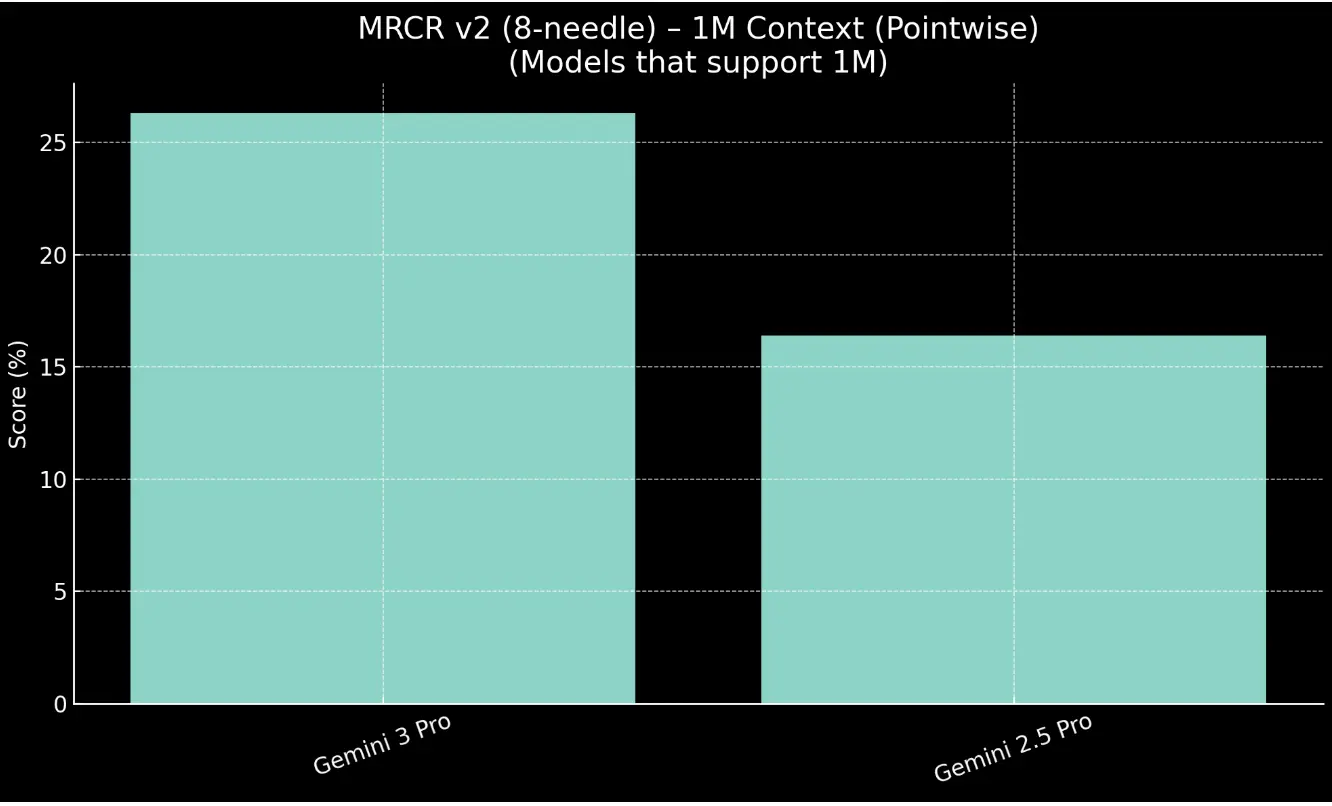
Хорошие показатели у модели на 128к контексте (~80% против 50%-60% у конкурентов), но вот бенчмарк на 1М контекст выдает порядка 25% на тест MRCR v2 (8 needle), это значит при прямом использовании 8-ми фактов из длинного контекста только в 1/4 задач оно решает верно, и это прямой запрос, в реальной задаче нужно косвенное использование всех данных в контексте, никакая линейная модель не выдаст в процессе анализа банальное количество фактов по условию фильтрации, а для работы требуется полноценная аналитика,.. условно проверить наличие ошибок в отчетности и указать что и где именно нужно чинить.
{kind=link}
{kind=link}

sickfar
07.12.2025 18:22Я вам новый «бенчмарк» принес. Прошу сгенерировать ascii карту Европы. И должен сказать, Gemini 3 - первая модель, у которой получается что-то похожее.
kujoro