
Этот пост будет полезен людям, кто хочет разобраться в локальных моделях, особенно использующим их, как инструмент в создании контента, арта и дизайна (контекст нейросетей - image и video). Так же поговорим о выборе видеокарты и параметрах влияющих на генеративные workflow.
VRAM requirements
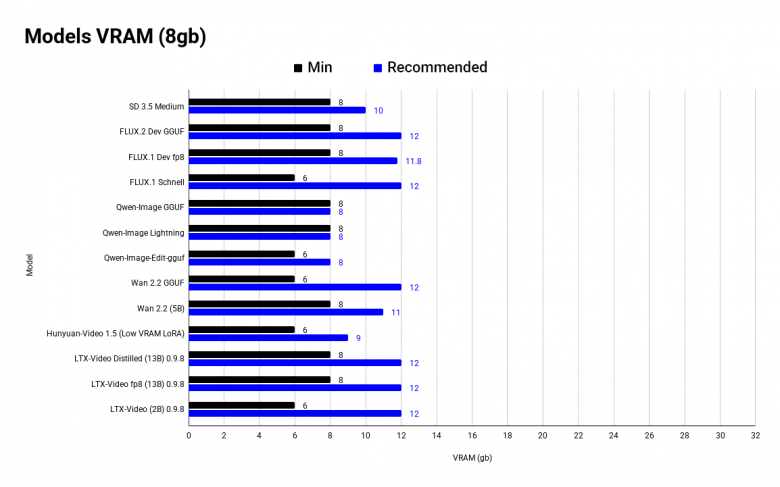
Для начала - график с оптимальными и минимальными значениями VRAM для image и video моделей.

Почему упор на обьем VRAM? При недостатке памяти вы либо не запустите модель, либо одна генерация будет длиться 1-2+ минуты (для image), что делает модель абсолютно не юзабельной. И да - с 8 gb можно запустить, например FLUX fp8, но это будет похоже на общение по почте - долго и муторно.
До минимальных значений модель либо выдаст ошибку, либо будет часто забирать global memory, что замедлит ее в разы. Оптимальное значение - это либо официальное требование VRAM, либо максимальное число по комьюнити тестам, выше которого обьем уже не даст приемущества в скорости.
Что влияет на размер нейросети?
Почти все веса модели - это матрицы и вектора (ну или weights and biases), которые еще называют "параметрами", вы могли видеть, что одна модель имеет размер 32B, у GPT-5 вообще 2 триллиона параметров и т.п. Они имеют precision или quantization level и отличаются по количеству байт.
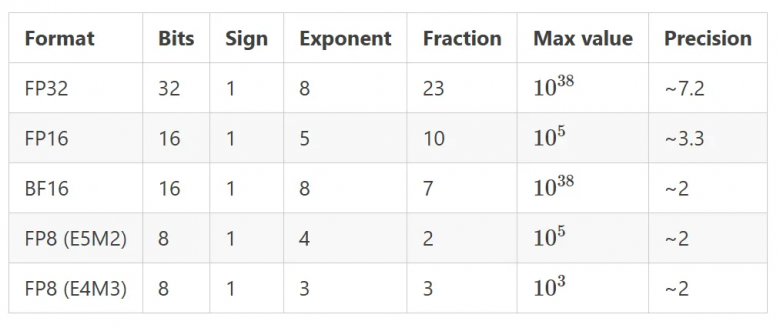
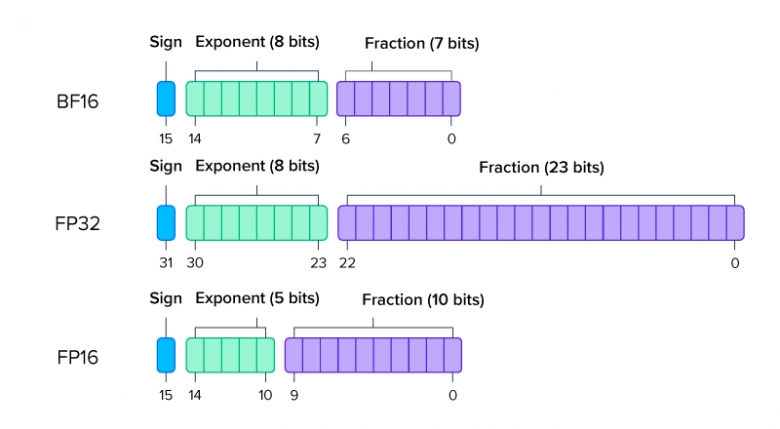
Самые популярные форматы:
FP16 - (16-bit floating point) 2 байта на параметр
BF16 - (16-bit floating point) 2 байта - разница в Exponent и Fraction битах
FP32 - (32-bit floating point) 4 байта
FP8 - здесь начинается квантизация - это самый популярный формат, требует 1 байт на параметр
GGUF - уже немного другой формат, но включим его сюда, квантизация начинается от Q2 до Q8, gguf - самый оптимизированный вариант
Соответственно, можно радикально сжать модель, если параметр будет весить не 4 байта, а один.


Quantization
Если у вас недостаточно VRAM, или базовая модель огромна - ищите quantized версии (fp8, GGUF, lightning).
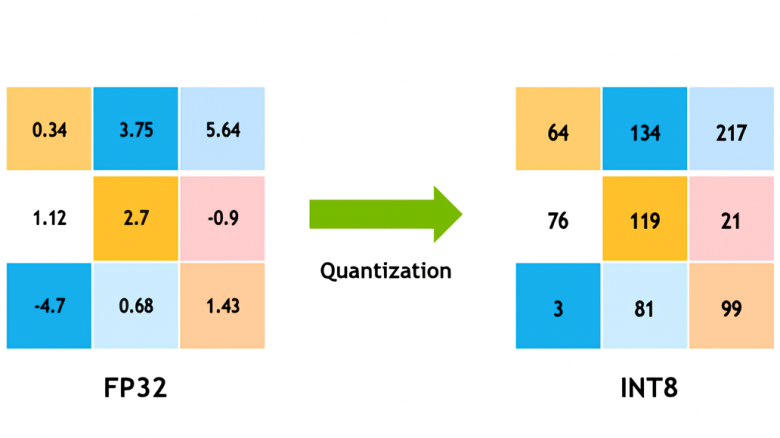
Quantization снижает битность параметра (FP32 --> FP16) и может поменять float на int (FP32 --> INT8), что сильнее оптимизирует нейросеть, снизит computational и memory costs. Говорят даже о снижении потребления энергии, но это в теории.
Да, за оптимизацию нужно платить качеством, но это не столь критично, когда стоит вопрос между использованием и не использованием нейросети.
(По правде, в личных тестах я почти не заметил отличий FLUX.1-Dev и fp8 версии, они становятся видны при снижении количества параметров (WAN 2.2 (14B) и (WAN 2.2 (5B)) или с изменением workflow (FLUX-Dev и FLUX.Schnell))
Зачем вам GPU?
Нейросети нагружают железо матричными операциями, сами матрицы большие, нейронов и слоев бывает много - значит нам важен обьем памяти и скорость вычислений.
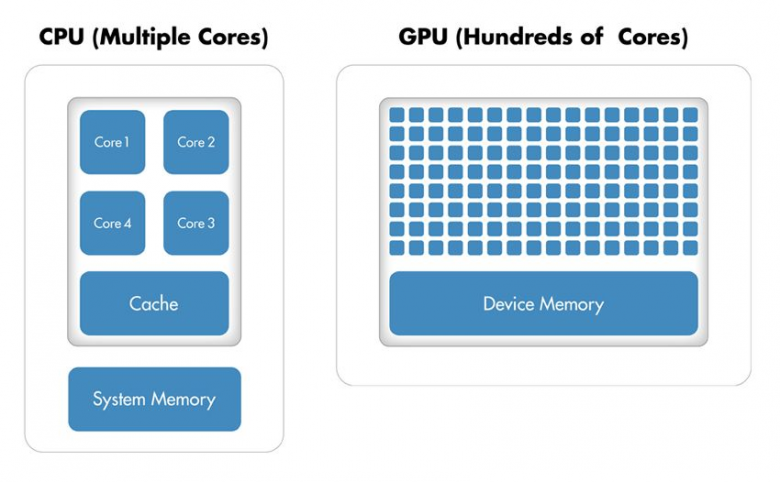

За вычисления отвечают ядра, у GPU их больше, чем у CPU, плюс отличия в архитектуре дают многократное приемущество в паралельных задачах. Тензорные ядра могут складывать и умножать матрицы за одну операцию. Все это важно для нейросетей, 3D, мат. анализа и любой big data.
При работе с нейросетями приходится делать много итераций: править промт, конфиг, делать тесты и чинить сломанные моменты. Чем короче каждая итерация - тем быстрее дорога к нужному результату.
Основа скорости - тензорные ядра. Они настолько быстрые, что основной проблемой становится скорость VRAM.
Memory bandwidth
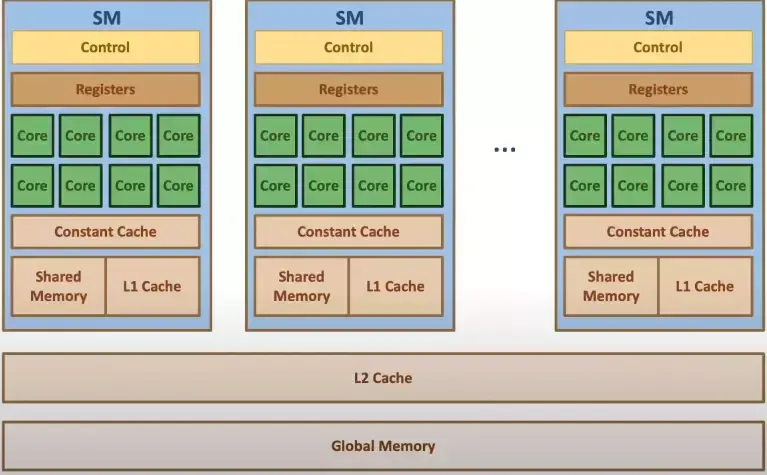
GPU имеет собственную память (VRAM), она разделяется по блокам:
-
Streaming Multiprocessors (SM):
Registers
Shared Memory
L1 Cache
L2 Cache
Global Memory
L1, Shared Memory, L2, Registers - отличаются по размеру и скорости, не будем останавливаться на них.
Global Memory - самая большая, но наиболее труднодоступная и медленная.
Напомню, что нам важны тензорные ядра, они складывают все наши матрицы и делают это настолько быстро, что могут спокойно простаивать 50% времени, потому что не успели получить новые операции из памяти - здесь возникает bottleneck.
Memory bandwidth (MB) - это скорость перемещения даты между GPU ядрами и блоками памяти. MB и количество тензоров должны быть в балансе. Если у GPU много тензоров, но низкая пропускная способность - толку от них мало. Далее я покажу хорошие примеры потребительских GPU, а сейчас наконец-то переходим к нейросетям!
Нейросети и VRAM
Напомню, что на графике минимальный (до него модель не будет работать) и оптимальный обьем VRAM. Я разбил данные на отрезки по 8, 12, 16, 24-32 gb - они наиболее популярны.
В списке:
Image-models:
Stable Diffusion (SD)
FLUX
Qwen-Image & Qwen-Edit
Video-models:
Wan
Hunuyan-Video
LTX-Video
Желтым цветом отмечены "разблокированные" модели, доступные с увеличением VRAM.
8 gb
8 gb критически не достаточно для локальных моделей, я сам обновил свою 3070, чтобы плотнее заняться ими. На 8 gb не доступны:
Wan 2.2 (14B) - топовая видео модель с комьюнити и различными workflow
FLUX.1-Dev будет работать в fp8 версии, но - это самая низкая граница, генерации могут занимать несколько минут
по опыту - не доступен любой ControlNet workflow
Здесь находится минимальная граница, вы как бы можете запустить модель, но она будет работать не оптимально, будет залазить в global memory, все будет медленно и доооолго.
12 gb
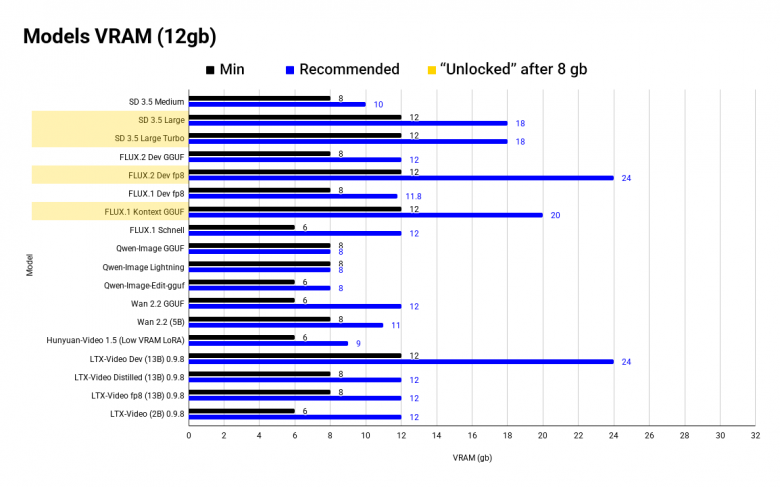
Свою RTX 3070 я обновил сразу на 5090, но перед этим пользовался различными VDS серверами и Colab'ом с Runpod'ом. Чаще пользовался A2 на 16 gb или той же 5090 на 32 gb. Не могу поделиться опытом работы на 12 gb.
Тут открываются:
FLUX.1 Kontext GGUF (но это нижняя граница)
FLUX.2 fp8
Stable Diffusion (SD) не буду даже упоминать - мое мнение вы можете прочесть в ТГ.
16 gb
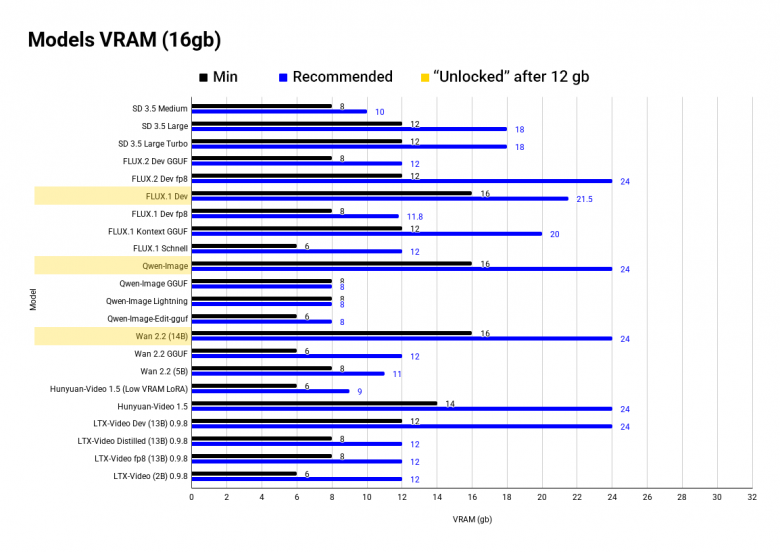
Самый оптимальный (на данный момент) обьем, здесь варятся локальные SOTA модели:
WAN 2.2 (14B)
FLUX.1-Dev и FLUX.2-Dev
Qwen-Image
Но на Qwen-Edit памяти уже не хватит, со временем требования вырастут и на актульные модели (чего стоит FLUX.1 и FLUX.2). Для самых жирных моделей потребуется отключить все программы, кроме ComfyUI, чтобы получить полную производительность.
24-32 gb
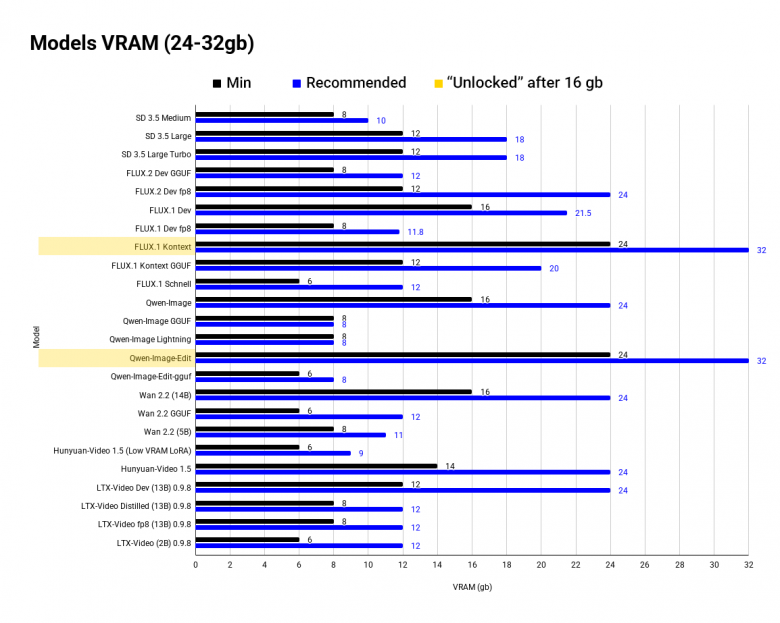
Территория Control-Net'ов, сложных workflow, файнтюнинга и 90-го семейства RTX.
Разблокирываются:
FLUX.1 Kontext
Qwen-Image-Edit
Control-Net и сложные workflow применяют технику MoE (Mixture of experts), когда задача распределяется между "экспертными" моделями, из-за этого количество LoRA и даты которую нужно подгружать - возрастает вместе с требованиями к обьему и скорости VRAM.
Для файн-тюнинга нужно прогонять датасет по множеству раз, от размера, количества эпох и отдельных параметров (например Learning Rate'а и длины токена) зависит качество, с бюджетными видеокартами трудно удержать все параметры на приемлемом уровне.
Видеокарты
По аналогии с моделями, для вашего удобства я собрал все популярные RTX карты в одной таблице и сделал анализ, но без цены, потому что не все GPU бывают в наличии, люди живут в разных местах, ситуация с дефицитом постоянно меняется. Решение по цене вы можете сделать самостоятельно, а сейчас посмотрим на 3 ключевых параметра:
обьем VRAM
Memory bandwidth (gb/s)
Количество Tensor Cores
Важный дисклеймер: RTX 5070 Super и RTX 5080 Super на момент Декабря 2025 еще не вышли, они запланированы на 2026 год.
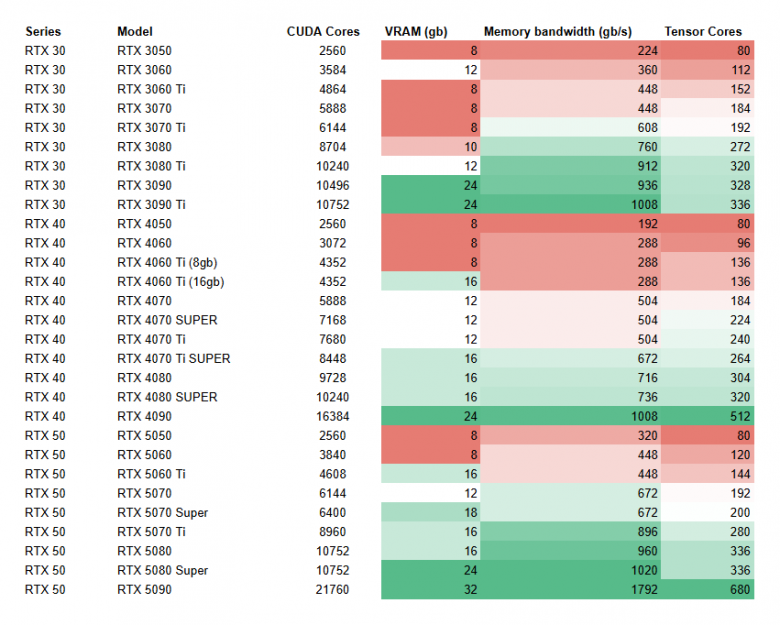
Данные отдельно по каждому параметру:
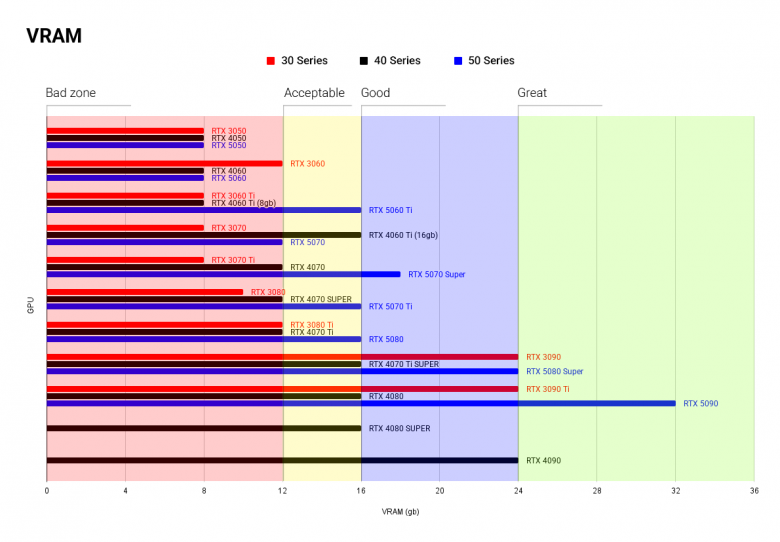
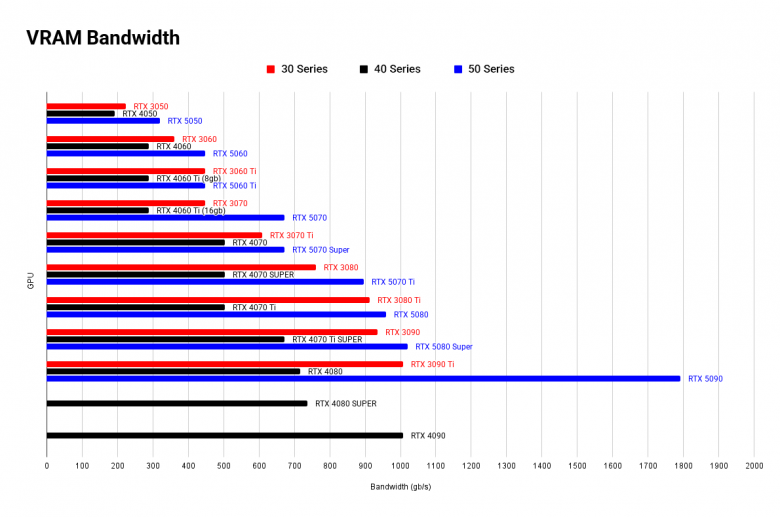
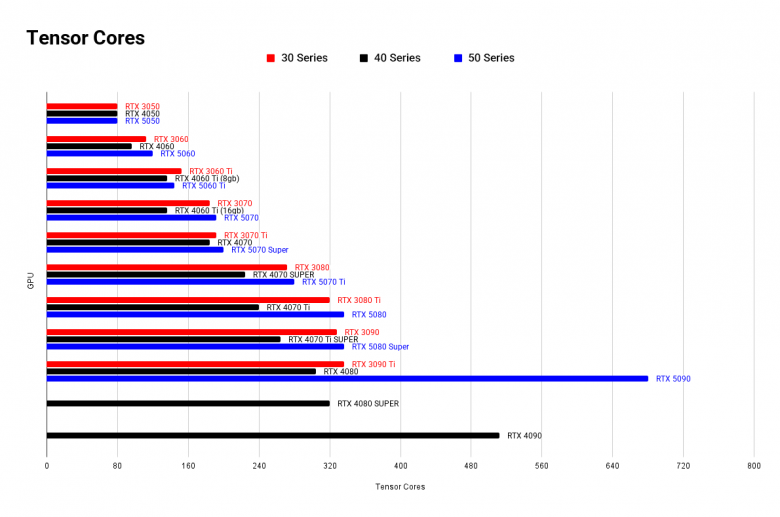
VRAM разделены по цвету:
красный - недостаточно
желтый - терпимо
синий - оптимально
зеленый - top-pick
фиолетовый - особенный случай
(Черным отмечен мой выбор GPU)
RTX tier 50

Я уже отмечал, что 8 gb недостаточно для локальных нейросетей, поэтому 50-ое семейство - не лучший выбор.
RTX tier 60
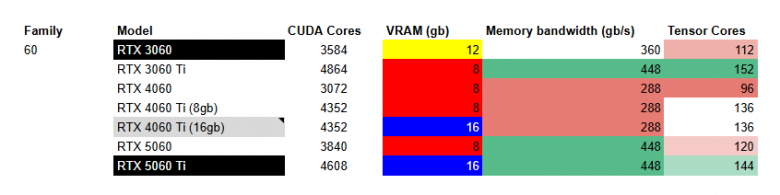
Если вам нужен дешевый и сердитый вариант - это RTX 3060 с 12 gb. Для 16 gb лучше выглядит 5060 Ti, потому что 4060 Ti имеет почти в 2 раза меньший Memory Bandwidth, что может создать ощутимый bottleneck.
RTX tier 70
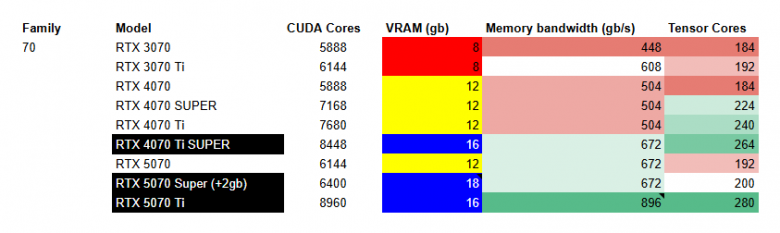
Смотрим на версии с 16gb VRAM, между 5070 Super и Ti появляется выбор:
Super - 2gb VRAM
Ti - 25% Memory Bandwidth
Мое мнение на стороне Super, 2 gb позволят комфортнее пользоваться ПК во время генерации, но вы можете выбрать скорость Ti версии.
(upd: На момент Декабря RTX 5070 Super еще не вышла, выбирайте между 4070 Ti Super и RTX 5070 Ti, разница в параметрах не такая большая - можно отталкиваться от цены)
RTX tier 80
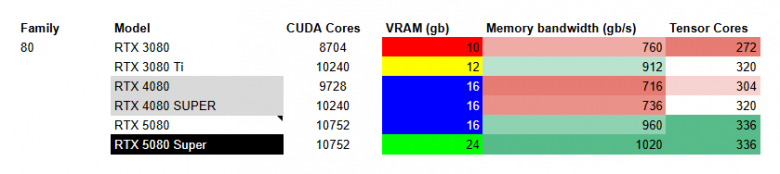
Для меня фаворит - 5080 Super из-за 24gb VRAM. Среди других я бы не стал выбирать обычную 5080, а посмотрел в сторону 4080, потому что у 50 серии нет особого прироста в тензорных ядрах, а цена заметно выше.
(upd: пока 5080 Super не вышла - я бы смотрел на RTX 4080)
RTX tier 90

Топ-пик и мой пик - RTX 5090. Сила, мощь и явный отрыв среди вообще всех других видеокарт. Но вы можете взять и 40 серию, и 30.
3090 - особый случай, топ за свои деньги, Xeon среди видеокарт (шутка). Мощный и сердитый вариант, кто хочет отдачи от каждого вложенного рубля.
На этом все, мы рассмотрели нейросети и видеокарты. Кому было интересно и полезно - можете подписаться на мой ТГ-канал. Я пишу про нейросети (в основном локальные), тех арт и иногда про 3D. Спасибо за внимание!
Комментарии (24)

vp7
21.12.2025 16:30А что на счёт apple'овских M процессоров? Имеют право на жизнь?
M2 Pro с 32 Gb RAM сейчас можно купить за 120-140 т.р. - скорость ниже, но по объёму памяти ему нет конкурентов.

stas_dubich
21.12.2025 16:30Я тестировал M2 Pro но с 16 gb ram, на простых текстовых моделях
Если RTX 3090 выдает условно 60 токенов в секунду, то M2 Pro - по ощущениям 5-10
Да модель помещается, но скорость оставляет желать лучшего
Bardakan
21.12.2025 16:30нейросеть говорит что m2 pro - не альтернатива 3090. Нужно брать mac studio m4 max или m3/m4 ultra, причем с большим запасом озу - от 64гб

AbuMohammed
21.12.2025 16:30Мы запускали qwen для аннотации имэджевых данных на m2(а100 склеила ласты и ушла в страну вечной тренировки, а надо было здесь и сейчас) , вполне юзабельно было.
Bardakan
21.12.2025 16:30можно подробнее? Если я правильно понял, для вашей задачи как будто скорость не особо критична

iwram
21.12.2025 16:30И работает и есть проблемы. Не все модели будут корректно работать если купите самый дорогой mac studio. Оставлю это https://github.com/pytorch/pytorch/issues/141287 - некоторые модели и в том числе для дообучения - будут работать через процессор, что вызывает печаль. Не стал бы на данный момент инвестировать в яблоки, если цель запускать модели и остальные вещи связанные с ML

Shannon
21.12.2025 16:30А что на счёт apple'овских M процессоров? Имеют право на жизнь?
M2 Pro с 32 Gb RAM сейчас можно купить за 120-140 т.р. - скорость ниже, но по объёму памяти ему нет конкурентов.У M2 Pro скорость памяти 200 гб/с, это всего в 2 раза выше чем DDR5 память, и на старых маках нет тензорных matmul ядер, они появились только в m5. Есть, например, Ryzen AI Max+ 395 (Strix Halo), продаются на озонах, там скорость памяти 256 гб/с, бывают до 128гб, но стоят дешевле маков.
Сейчас в продаже появились AMD Pro R9700 32GB за 1300 баксов, люди уже тестируют LLM, flux2, и wan2.2, 128 тензорных ядра, поддержка fp4, LLM заводятся на AMD давно без проблем, и есть официальные сборки ComfyUI на AMD. Не так быстро и удобно как CUDA, но быстрее и удобнее чем старые маки.
Ещё плюс GPU - это возможность запускать огромные MoE модели за счёт ОЗУ. Например, для запуска GPT-OSS-120B нужно 64гб RAM и немного VRAM, примерно тоже самое с видеогенератором Wan2.2, ему, помимо VRAM, нужно много RAM для быстрой работы.

m0xf
21.12.2025 16:30Ещё есть вариант - переделанная RTX 4090 на 48Gb. По цене примерно как RTX 5090.

wiki7979
21.12.2025 16:30Подскажите профану. Если есть обычный мини пк alder n100, с 8 ГБ ОЗУ - можно ли как-то подключить видеокарту?

melodictsk
21.12.2025 16:30Да, можно. В разъём М2 для ссд. Это не имеет никакого смысла. Потому, что у Н100 очень медленная озу. Я делал эксперимент на минипк с амд 6800hs 16гб лпддр5 + внешняя видеокарта 3070м 8гб подключён на через м2 4х псие4.0. Вполне шустро и сносно работает благодаря быстрому процессору и очень быстрой озу (по тесту под 100 гб/с).

rrrrex
21.12.2025 16:30Какие ещё RTX 5070/5080 super? Как можно советовать то, что ещё не вышло.

Starkfrost
21.12.2025 16:30Тоже споткнулся на фразе "Для меня фаворит - 5080 Super из-за 24gb VRAM". Всё-таки нейросеть писала.

Andreev_TechArt Автор
21.12.2025 16:30забыл упомянуть, да. Чуть позже будет время внесу комент в статью


Astus
21.12.2025 16:30Z-image не хватает, потрясающе быстрый и качественный вариант домашней локальной генерации, на моей старушке 2080 просто летает, лучшее соотношение скорости-качества на данный момент. С нетерпением жду edit-версию.
Andreev_TechArt Автор
21.12.2025 16:30Z-image да, пока писал статью и занимался video нейронками - упустил ее из вида. Они выходят слишком быстро

theult
21.12.2025 16:30Судя по ценникам в магазинах, нейросетям нужна абсолютно вся ram, vram, tlc и 3dnand :)



Moog_Prodigy
21.12.2025 16:30Ну, для генерации картинок врам и гпу, имхо даже поважнее будет, чем для применений типа LLM. Поясню: когда мы пишем промпт для картинки, нам нужна обратная связь (в большинстве случаев) - что то мы упустили в промпте, может местами переставить, веса подправить, а может и моделька неподходящая. Но пока картинка вся не сгенерится - мы этого не поймем. Без ГПУ на проце это может занять минут 15-30 ожидания, за которые можно уже подзабыть - а что мы хотели то? Или наоборот, за это время накрутили совсем новый промпт, который кажется нам верхом промптинга....через следующую генерацию понимаем что это не так. Наше счастье, что генераторы картинок (точнее их модельки) не такие огромные, как LLM, поэтому можно и на не новых видеокартах работать.
LLM даже на проце без всяких ГПУ начинают выдавать токены сразу. Нууу..."почти" сразу. Тем не менее они их начинают понемножку выдавать, и буквально с самого начала становится понятно, хрень она пишет или нет. Например "Я не могу" в начале ответа может вполне быть стоп-словом, если моделька отвечает по API, и прервать дальнейшую генерацию можно в самом начале. Или какое нибудь "Извините, я...".
Или вообще говоришь ей писать на питоне а она начинает выдавать псевдокод в виде смеси Питона и Си. Потому что она насмотрелась этого псевдокода в статьях.
Вот видеогенераторы - там все настолько медленно и жруче, что даже и не поймешь. Но подозреваю что с ними все как с рисовалками картинок. Это же по сути те же рисовалки, только у них унутре уже встроены контролнеты и прочее барахло, которое призвано по сути нарисовать и чуть изменять картинку, и так тысячи раз.

dadada1255
21.12.2025 16:30rtx 5070 18gb и rtx 5080 Super 24gb - этих карт нет на данный момент- декабрь 2025.
Текст писала нейросеть, без проверки редактором..

shurx
21.12.2025 16:30Я использую Triton и sageattention для ускорения генерации на 4090. Но с каждым разом новые модели становятся более требовательными.
jarkevithwlad
если нужна генерация изображений то есть nunchaku github который позволяет некоторые модели запускать при 3gb vram, вот недавно выпустили поддержку z-image, а старый flux-dev давно ими квантован, потерь качества почти нет, при этом и скорость значительно выше
Скрытый текст