
Мы давно ничего не писали в наш блог и возвращаемся с рассказом о нашем новом проекте: Relap.io (relevant pages).
Мы запустили рекомендательный B2B-сервис Relap.io полтора года назад. Он облегчает жизнь редакции и читателям СМИ. В будние дни Relap.io обслуживает 15 млн уников и выдаёт 30 миллиардов рекомендаций в месяц.
Сейчас Relap.io крупнейшая рекомендательная платформа в Европе и Азии.
Зачем нужен Relap.io
В зависимости от поведения пользователя мы подбираем статьи, которые будут ему интересны. Выглядит это как блок «Читать также» или «Вам будет интересно»:
Сейчас сервисом пользуются РИА Новости, AdMe, COUB, TJournal, Лайфхакер и другие медиа. Виджеты Relap.io установлены на более чем 1000 сайтов. 50 из них — миллионники (1 млн и более уникальных посетителей в сутки).
Relap.io начался с простенькой беты. Мы взяли рекомендательные алгоритмы Surfingbird и адаптировали их для сторонних площадок.
Из чего сделан Relap.io
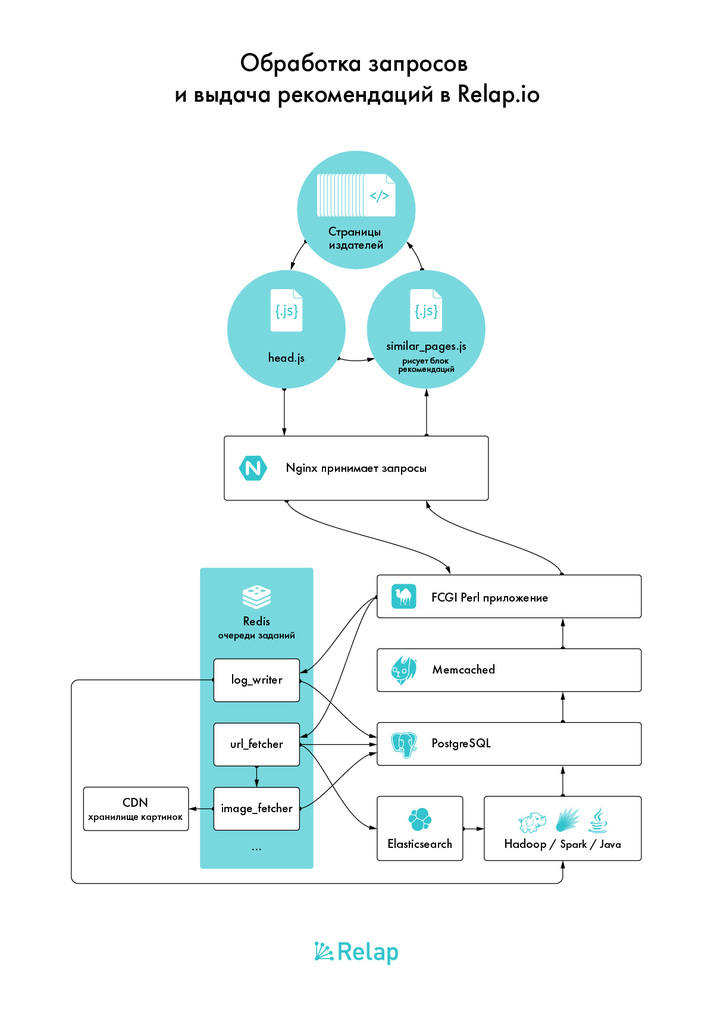
Каждую секунду на сервера Relap.io от пользователей поступает 15 000 http-запросов. Из них:
- 10К статика: изображения для виджетов, стили, статический js.
- 5К динамика: сбор сигналов, формирующих обучающее множество и формирование блоков рекомендаций.
Когда мы создавали архитектуру у нас было 2 требования:
- она должна выдерживать высокие нагрузки;
- масштабироваться.
Бэкенд — это два сервера с большим количеством памяти и объёмными SSD в RAID1. На них стоит PostgreSQL свежей версии, на одном сервере — мастер, на втором — слейв.
Рабочие лошадки — сервера поскромнее. Они принимают запросы из внешнего мира. На двух из них стоят Nginx-ы, которые балансируются друг с другом просто по DNS. Они раскидывают запросы. Их ловят перловые FCGI-воркеры.
FCGI-приложение построено таким образом, что отказ PostgreSQL не приводит к мгновенному отказу всего сервиса, у нас есть примерно 10 минут на устранение фатальных неисправностей. Даже если автоматическое переключение на реплику не спасло ситуацию.
Эти же сервера выполняют и другие роли — на них крутится бОльшая часть очередей, выполняющих в оффлайне всё, что можно делать в оффлайне; инстансы memcached и Redis, крон-скрипты.
Особняком стоят сервера, которые формируют рекомендациями. Для всех, кроме команды математиков, это более-менее чёрная коробка. Туда FCGI и очереди кидают данные, а они в ответ вставляют в PostgreSQL свежие рекомендации, посчитанные по разным алгоритмам, для каждой активной ссылки в базе. Ключевые слова — Hadoop, Spark, Elasticsearch как сторадж, толстый слой Java.
Коду остаётся только забирать готовое, накладывать некоторое фильтрование. Его мы стараемся делать минимальным и максимум фильтровать на этапе генерации и сортировки.
Всё что можно обвешано кешами. Кеш PostgreSQL в памяти, дисковый кеш, мемкешед или redis, где он удобнее, несколько видов кеширования прямо внутри процесса.
Почему все так?
PostgreSQL — самая полнофункциональная open-source база данных. Предсказуемая, стабильная, популярная. Nginx — куда лучше выдерживает масштабирование нагрузки, чем Apache.
MySQL или Apache более популярны, но нам кажется, что выбирать их для новых проектов можно только на shared-хостинге, где больше ничего нет. Или если вы очень хорошо умеете их готовить и масштабировать.
Выбирать shared-хостинг для нового проекта можно, только если вы заранее знаете, что рост ему не грозит. Тогда технологии стоит выбирать уже по принципу «а людей с какими знаниями я найду дешевле и быстрее всего» — это, скорее всего, люди со знанием PHP, MySQL и Apache. Замкнутый мир проектов на shared-хостингах.
Hadoop взяли потому, что особого опыта ни с одним из подобных решений у команды не было. А это некий стандарт в обработке больших данных. Здесь мы просто шли за всеми.
Ещё нам было нужно отдельное хранилище данных для Hadoop-а — PostgreSQL не подходил. Для этого мы выбрали, как ни странно, Elasticsearch, получив заодно полнотекстовый поиск и возможность строить алгоритмы, его использующие. Впрочем, это оказалось неправильным решением. Он может быстро все индексировать и находить, но не отдавать большие объёмы данных.
В следующей серии расскажем, как мы решали эту проблему.
Где хостится Relap.io
С ростом нагрузки перед нами вставала проблема выбора надёжного хостинг-провайдера. Сейчас мы хостимся на Servers.com. Они достаточно мощные, чтобы выдержать нагрузку 900 000 запросов в минуту. Это не пиковые нагрузки, а нормальное состояние в будние дни.
В прошлом году мы несколько раз меняли датацентр. Сначала был ДЦ Славянский. Там до сих пор хостится Surfingbird.ru.
Потом в марте 2015 переехали на Hetzner. Тогда мы выдавали 2К рекомендаций в секунду. При последнем переезде на Servers.com было 6К в секунду. Сейчас 15K.
Интеграция Relap.io на сайт:
Как виджет
Коробочное решение. Пользователь ставит наш код в head страницы, на которой должен быть виджет. Выбирает тип виджета и собирает дизайн во встроенном конструкторе. Формирование рекомендаций и фронтенд полностью происходит на нашей стороне. Так к Relap.io подключено большинство площадок. Например, Лайфхакер.
Через jsonp api
Площадка получает описание нашего api. Мы отдаём большой пакет рекомендаций, а площадка фильтрует их уже на своей стороне и подставляет в дизайн. Интеграция через JSONP API позволяет использовать кастомные элементы: историческое количество просмотров, лайков и любую другую информацию о ссылке. Таким способом к Relap.io подключены, например, AdMe или COUB.
В последующих статьях мы подробно расскажем о технологиях, алгоритмах машинного обучения и инфраструктуре сервиса. Задавайте вопросы в комментариях — обязательно ответим на них в следующих публикациях.
Комментарии (39)

Heckfi
19.02.2016 15:49+1Рекомендации формируются персонально для каждого пользователя или на страницу?

Skaurus
19.02.2016 18:27Помножьте количество страниц на количество пользователей. Так жить невозможно. Генерировать рекомендации в таких объёмах на лету — тоже.
Но для каждого пользователя есть минимальная кастомизация — учитываются уже просмотренные статьи, например. Планируем продолжать такую аккуратную кастомизацию, которую ненакладно делать прямо в процессе выдачи рекомендаций.

chizh_andrey
19.02.2016 15:58+1Чем Servers.com лучше Hetzner.de в вашем случае?
Skaurus
19.02.2016 18:23Как минимум у Hetzner узкий канал между стойками, да и в интернет не фонтан. Нам нужно больше гигабита и там и там :) Так что когда выросли из стойки — стали искать, куда переехать.

ShadowsMind
19.02.2016 17:08+2*Тут должна быть картинка про то как рисовать сову*
Начало было хорошее, а потом все скатилось непонятно куда. Не думаю, что людям на хабре надо объяснять почему shared-хостинг не подходит для подобных проектов. Да и без сравнения PostgreSQL/MySQL и Nginx/Apache тоже можно было обойтись.(тем более без упоминания реальных юзкейсов, в духе «нам надо было хранить json и PostgreSQL нам подошел лучше» (с) ).
Надеюсь в следующих статьях объем будет побольше и поинтереснее, т.к. куча вопросов по поводу Вашей архитектуры:
1. Почему Perl?
2. Почему Redis для очередей?
3. Про то как Spark используете.Skaurus
19.02.2016 18:09+1- Выбор Perl обусловлен тем, что у нас уже была сильная команда перловиков. На самом деле, конечно, можно использовать любой популярный для веб-разработки язык (даже PHP).
- В своё время для Surfingbird переписали Resque от твиттера на перл. Нам понравилось — работает хорошо, проблем нет. На новый проект взяли то же самое.
DoctorChaos
19.02.2016 21:54Допустить ремарку «даже php» очень непрофессионально с вашей стороны.
Хотя, перловикам простительно быть не в курсе, что актуальная версия php уже 7 а не 4.


ealekseev
19.02.2016 17:08Что нужно, чтобы подключиться к Вам через jsonp api ?
Skaurus
19.02.2016 18:12Для начала объяснить, зачем :) Стараемся обходиться виджетами. И оказаться сайтом с высокой посещаемостью.
ealekseev
19.02.2016 18:35Ну как минимум потому, что виджеты не совсем вписываются в дизайн :) Они конечно настраиваемые, но пока недостаточно.
Высокая для Вас — это от скольки в сутки?
vgray
19.02.2016 17:45Что нужно, чтобы подключиться к Вам через jsonp api ?
тоже интерисует этот вопрос, с кем связываться? чтобы получить стоимость этой услуги?
Вы можете давать рекомендации только по сайту в целом "Популярное сейчас..." или также можете давать рекомендации по каждой странице "Похожие статьи ...." ?

negodnik
20.02.2016 01:34Как построена монетизация? :)
Skaurus
20.02.2016 01:51Площадки, разместившие наш виджет, при желании могут согласиться размещать в виджете помимо рекомендаций рекламу. Доходы от рекламы делятся между нами и площадкой, по умолчанию — пополам.
Мы ну вообще бесплатны и зарабатываем, только помогая зарабатывать другим :)negodnik
20.02.2016 01:57Ещё вопрос назрел. У вас почти в чистом виде content based recommendation, за исключением учета прочитанных юзером. А как — в двух словах — вы тогда строите рекомендации? По ключевым словам плюс времени публикации, как-то так?
Skaurus
20.02.2016 14:10Алгоритмов много. Вплоть до того, что для каких-то сайтов могут быть модификации специально для них.
Вместе это работает примерно как на surfingbird — алгоритмы выстроены в цепочку, пытаемся взять из одного, не нашли достаточно — идём в следующий.
Основной — на самом деле item to item.negodnik
20.02.2016 15:46Как реализовано исключение прочтенного юзером из рекомендаций? Где вы храните прочтенные юзером ссылки и в какой момент это условие срабатывает? И как вообще работает отслеживание уника, если отключен прием third party cookies?
Skaurus
20.02.2016 15:57Пока что — в куках, и, соответственно, без них никак не работает.
negodnik
20.02.2016 16:12В виджете ни чего не выводится при этом? Или какой-то запасной вариант?
Skaurus
20.02.2016 16:14Выводится. item to item же основной алгоритм, я писал выше.
negodnik
20.02.2016 16:19Это понятно, но ведь в случае item-item все равно нужна матрица user/item? Ведь нужно понять, что еще читали юзеры, которые читали эту страницу. А в случае если кука на домен сервиса не будет отправляться, по юзерам просмотры не сгруппировать?
Skaurus
20.02.2016 16:33Кука не будет отправляться у меньшинства, так что корреляцию между item-ами посчитать всё равно получится.
Показать посчитанную корреляцию можно кому угодно, хоть у него кук вообще нет.
Я ответил на ваш вопрос?negodnik
20.02.2016 17:09+1Спасибо за ответы, я не подумал что большинство в данном случае спасает ситуацию.
negodnik
20.02.2016 15:56Поясню насчет отслеживания уника. Для создания матрицы item-user, где элемент это условно время, которое он провел на странице item, нужно идентифицировать уникального юзера, как вы это делаете с учетом third party cookies? По IP?
negodnik
20.02.2016 02:08+1Почитал на сайте «Мы собираем для каждого пользователя материалы на основе его поведения. На виджет Relap, кликают в 2 раза чаще, чем на блоки, собранные вручную.» Видимо, я не так понял коменты к этому посту :)
merk
20.02.2016 12:44Откровенно говоря, подозрительно выглядит позиция "Если хотите, то запускайте рекламу, а если не хотите рекламу — то пользуйтесь бесплатно". Это наводит на мысли, что вы можете использовать собранную информацию еще как-то в своих целях.
Честно слово, если бы вы предлагали схему с выбором между бесплатным использованием с рекламой или платным использованием без рекламы, то было бы больше доверия :)
В любом случае, у вас очень крутая идея!Skaurus
20.02.2016 14:42Собирать информацию нам так и так нужно, чтобы делать рекомендации. Поэтому чисто логически, непонятно, почему описанная вами схема добавила бы доверия.
Сейчас — у идеи попробовать нас нет минусов, а если наш виджет в итоге нравится, то ещё и заработать на нём тоже нет резона отказываться. Сплошная вигода.

drakmail
Здесь всё на самом деле стандартно, интересно как раз как и на основе чего формируются рекомендации и насколько они лучше обычной выдачи последних материалов, например
recompileme
А что больше интересует техническая сторона вопроса, как обсчитывать тысячи хитов в секунду и не загнуться или какая математика лежит в основе?
smileonl
Про математику :)
recompileme
Мы уже писали несколько статей ранее, пока можно ознакомиться с ними:
https://habrahabr.ru/company/surfingbird/blog/176461/
https://habrahabr.ru/company/surfingbird/blog/177889/
https://habrahabr.ru/company/surfingbird/blog/185622/
https://habrahabr.ru/company/surfingbird/blog/188812/
https://habrahabr.ru/company/surfingbird/blog/226677/
https://habrahabr.ru/company/surfingbird/blog/228249/
https://habrahabr.ru/company/surfingbird/blog/230103/