
 На конференции FAST 2016 компания Google представила доклад со статистикой надёжности разнообразных SSD-накопителей при длительной работе в серверах. Собрана статистика по общей наработке в миллионы часов за шесть лет. Это первое масштабное и детальное исследование практической надёжности твёрдотельников.
На конференции FAST 2016 компания Google представила доклад со статистикой надёжности разнообразных SSD-накопителей при длительной работе в серверах. Собрана статистика по общей наработке в миллионы часов за шесть лет. Это первое масштабное и детальное исследование практической надёжности твёрдотельников.Доклад опубликован на страницах 67-80 сборника докладов конференции.
В серверах Google установлены десять моделей SSD-накопителей (правда, конкретные производители не называются) трёх типов: MLC, eMLC и SLC. Это накопители как корпоративного класса, так и бюджетные потребительские.
Опыт практического использования принёс несколько неожиданных результатов.
Неожиданным оказалось, что на надёжность накопителей влияет возраст, а не интенсивность использования.
Ещё один неожиданный результат: «профессиональные» накопители SLC не более надёжны, чем обычные MLC.

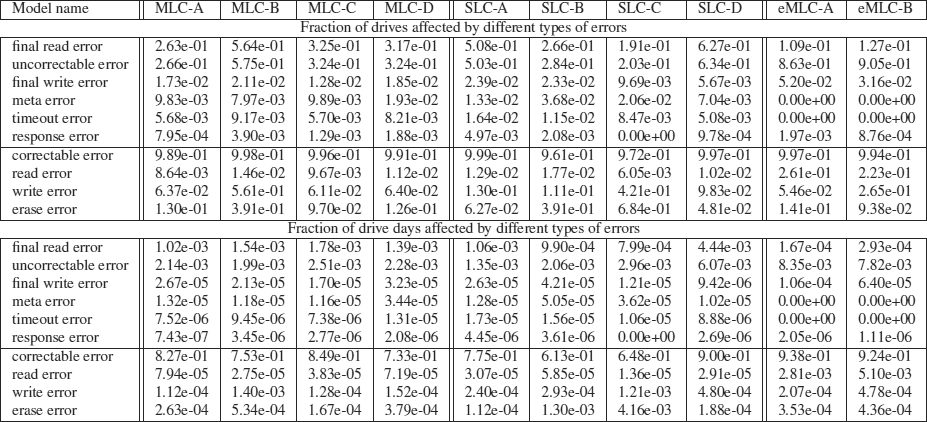
Выяснилось также, что в новых накопителях постоянно встречаются плохие блоки, это вполне обычное явление. При этом чем больше плохих блоков изначально, тем более вероятно появление сотен новых плохих блоков в будущем. Вероятно, это связано с аппаратными сбоями.
По статистике, у 30-80% SSD-накопителей появляется хотя бы один новый плохой блок в течение первых четырёх лет эксплуатации. Сбой микросхемы за тот же срок наблюдается у 2-7% накопителей.

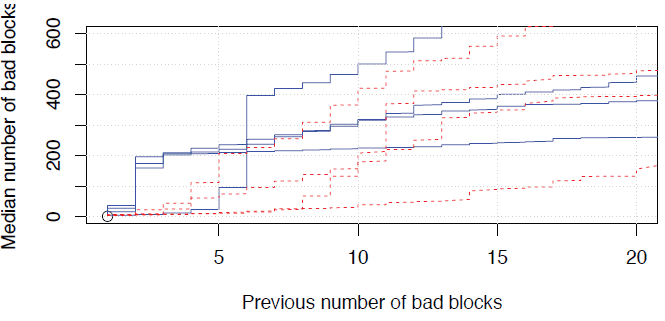
Ещё одно, на чём делают акцент исследователи Google: сбои SSD-накопителей случаются реже, чем сбои винчестеров, но они коварнее, потому что у SSD выше количество неисправимых ошибок (uncorrectable error). При этом, как упоминалось выше, показатель не зависит от количества циклов чтения и записи, так что значение UBER (Uncorrectable Bit Error Rate) в документации накопителя не имеет смысла.
Комментарии (75)

ARMOR888
28.02.2016 21:55+4Эх, ещё бы то же самое, но с привязкой к конкретным моделям.
netto
29.02.2016 00:52+5Это научное исследование, а не рыночный обзор или sales guide.
alexkuzko
29.02.2016 02:24Что не мешало в отчете гугла по надежности винчестеров указать производителей. И это было очень полезно!
netto
29.02.2016 07:05+1Ни разу не видел в таких исследованиях указаний производителей. Это принцип… В «отчете гугла по надежности винчестеров» — тоже. Вы что-то с кем-то путаете.
alexkuzko
29.02.2016 08:31+4Точно. Хоть у гугла и был такой отчет, но без производителей. А с производителями это от Backblaze. Они не постеснялись — и молодцы. Нечего производителям мешать публиковать реальные сведения!

tazepam
29.02.2016 13:50*Ни разу не видел в таких исследованиях указаний производителей. Это принцип…*
По ссылке ниже подобное же исследование с названиями производителей и даже конкретных моделей.
https://habrahabr.ru/post/209894/netto
29.02.2016 18:48Это не научное исследование, это -так, sales guide. Тем, собственно, одно от другого и отличается. Очень жаль, что в последнее врем многие путают первое и второе.

Gendalph
01.03.2016 00:07Sales guide? Серьезно? Ребята используют сотни, а иногда и тысячи дисков одной модели. У них есть на чем строить статистику.
netto
01.03.2016 10:54Абсолютно серьезно. Науку интересует жесткий диск как таковой, и его поведение, а не «что вам купить из того, что есть на рынке». С точки зрения науки отчет, в котором «вендор А», «Вендор Б» и «Вендор Ц» совершенно нормален и правилен, это только вас интересует «а кто там за ними скрывается», ученому это не важно, да и не должно быть важно, по большому счету. Его не разница между вендорами интересует, выяснение этого может только помешать ответить на главные вопросы исследования.

kaaquantum
02.03.2016 00:54+2У вас какие то совсем абстрактные ученые. Главное — непредвзятость и объективность методик и выводов, а не пуританское прикрываение ярлычков.
idiv
29.02.2016 19:46Что не мешало в отчете гугла по надежности винчестеров указать производителей.
Это требует разрешения производителя, причем независимо от автора исследования и в случае даже добровольной передачи на исследования. Скорее всего лицензионное соглашение.alexkuzko
29.02.2016 20:14+1Я знаю что многие очевидные вещи сейчас запрещены т.н. копирастами. Но это не должно считаться нормальным.
Поэтому пока еще не запретили обсуждать такое некорректное поведение, ущемляющее права человека, надо информировать население. Глядишь и созреет критическая масса (я про глобальное население, а не конкретной страны).
Запрет на публикацию тестов и т.п. это просто ужас. Производители и поставщики так хотят назад в век паровых машин, мануфактур и гильдий!idiv
29.02.2016 21:29Запрет на публикацию тестов и т.п. это просто ужас
Это у вас как вышло? Нельзя называть производителя, как правило, а результаты тестов с именами производителей А, Б и В можно. А так можно выложить практически информацию.
Кроме того, поставьте себя на место производителя. Кто-то купил партию дисков, а они оказались бракованными. Статью запускают, оказывается — брак единичной партии. А репутация потеряна… У Google ведь выборка тоже не самая строгая. Закупалось партиями, могло не повести с конкретной партией. А потом обиженная компания потребует компенсации стоимостью в утерянную прибыль (здесь она считается попроще, чем виртуальные расчеты в авторском праве), причем сразу. Потому никто не заинтересован в таком. Ответственность слишком большая.
kotomyava
01.03.2016 11:22+2Если производитель позволяет себе выдать бракованную партию, то его репутация и должна быть потеряна.
В принципе объективные и независимые тесты не выгодны производителям — им выгоден маркетинговый буллшит.
И ситуация, когда нет реальной возможности публиковать результаты таких тестов совершенно не нормальна — интересы потребителей должны бы быть в приоритете, иначе получается то, что мы имеем: мир одноразовых вещей.idiv
01.03.2016 21:59Если производитель позволяет себе выдать бракованную партию, то его репутация и должна быть потеряна.
А если не вина завода, а инженер из ОТК обиделся и решил "наказать" компанию и не сообщать о браке? Или было неправильное хранение или транспортировка, когда изготовитель вообще не при делах?
И ситуация, когда нет реальной возможности публиковать результаты таких тестов совершенно не нормальна
Она есть. Нужно убедить компанию в беспристрастном и взвешенном анализе.kotomyava
01.03.2016 22:18+1> А если не вина завода, а инженер из ОТК обиделся и решил «наказать» компанию и не сообщать о браке?
Вероятно, это и есть проблема компании? И такие ситуации точно также должны вредить её репутации?
> Она есть. Нужно убедить компанию в беспристрастном и взвешенном анализе.
Если бы… Убедить-то надо в том, что публикация выгодна компании. Компании не нужна никакая взвешенность и беспристрастность — наоборот, она сильно повредит, заведомо пойдя в разрез с результатами работы отдела маркетинга.
Компаний которые делают качественные вещи, как и тех, что описывают результаты своей работы объективно, пренебрежимо мало.
idiv
01.03.2016 22:37> А если не вина завода, а инженер из ОТК обиделся и решил «наказать» компанию и не сообщать о браке?
Вероятно, это и есть проблема компании? И такие ситуации точно также должны вредить её репутации?
В идеальном мире нет, на практике виноват будет не мистер Икс, а компания Игрек.
Компании не нужна никакая взвешенность и беспристрастность — наоборот, она сильно повредит, заведомо пойдя в разрез с результатами работы отдела маркетинга.
Компаний которые делают качественные вещи, как и тех, что описывают результаты своей работы объективно, пренебрежимо мало.
Зависит от репутации просящего. Тесты в RWTH проводили Ауди, Форд, Панасоник, Варта, Сименс (это те, про которые рассказывали у нас на факультете). Те же Форд с Панасоником одними своими объемами на "пренебрежимо мало" не тянет.kotomyava
02.03.2016 00:11+1> В идеальном мире нет, на практике виноват будет не мистер Икс, а компания Игрек.
И совершенно правильно. Если компания допускает возможность обхода/фальсификации проверки качества одним сотрудником, то процесс проверки не выдерживает критики, и это вина именно компании, и проблема построения её бизнес процессов. И, естественно, репутация такой компании должна падать.
> Тесты в RWTH проводили Ауди, Форд, Панасоник, Варта, Сименс
Вы про заказные исследования на заданную тему с закономерными выводами? Какое отношение это имеет к рассматриваемой проблеме вообще?
Я-то речь вёл про независимые исследования без инициативы компании, и тем более прямого/косвенного финансирования.
Например такие, на которых пропалились те же VW, с подделкой данных экологичности дизелей. Хотя выявившим настолько серьёзные проблемы опубликоваться и защититься просто — слишком большой резонанс.
Кстати, VW финансировали исследования доказывающие экологичность дизелей, а не только покопались в ЭБУ, чтобы пройти тесты.
А вот если проблема не настолько серьёзна, отбиться от юристов крупной компании после публикации любых не угодных её данных может оказаться большой проблемой.
P.S. Ситуация в принципе не нормальна, когда надо какое-то разрешение спрашивать для подобных исследований и публикации их результатов.idiv
02.03.2016 19:34Если компания допускает возможность обхода/фальсификации проверки качества одним сотрудником, то процесс проверки не выдерживает критики, и это вина именно компании, и проблема построения её бизнес процессов
Вроде же нормальный подход, когда один человек несет ответственность, а не коллектив.
> Тесты в RWTH проводили Ауди, Форд, Панасоник, Варта, Сименс
Вы про заказные исследования на заданную тему с закономерными выводами? Какое отношение это имеет к рассматриваемой проблеме вообще?
Я-то речь вёл про независимые исследования без инициативы компании, и тем более прямого/косвенного финансирования.
Это были сравнительные независимые тесты. Эти компании разрешили озвучить результаты про себя независимо от их показателей.kotomyava
03.03.2016 00:37+2> А если не вина завода, а инженер из ОТК обиделся и решил «наказать» компанию и не сообщать о браке?
> Вроде же нормальный подход, когда один человек несет ответственность, а не коллектив.
При чём тут ответственность? Вы прочитайте, внимательно, что я писал выше — если один человек может пропустить бракованную партию, то виновата безусловно компания. Она неправильно организовала процесс. В итоге пострадает её репутация, и это вполне закономерно.
А кого там в компании за это накажут, и кто реально виноват в этой ситуации, потребителю этого брака совершенно не важно.
Важно, что сначала брак допустили, а потом ещё и отгрузили. Естественно, что доверие к такому поставщику и должно упасть, что вы в этом ведите не нормального, и не справедливого?
> Это были сравнительные независимые тесты. Эти компании разрешили озвучить результаты про себя независимо от их показателей.
Можно ссылки на исследования, и заодно, кто был инициатором, и кто финансировал эти исследования?idiv
03.03.2016 22:34> Вроде же нормальный подход, когда один человек несет ответственность, а не коллектив.
При чём тут ответственность? Вы прочитайте, внимательно, что я писал выше — если один человек может пропустить бракованную партию, то виновата безусловно компания.
Угу. Гораздо лучше, когда не только виноватого не найдешь, а еще и коллегиальное решение.
Такое впечатление, что вы с производством не сталкивались да и должность ваша никакой ответственности не заставляет на себя брать. Я описал ситуацию крайнюю, возможны еще ошибки.
Можно ссылки на исследования, и заодно, кто был инициатором, и кто финансировал эти исследования?
Вот один из примеров, первый запрос в Гугле (сложная работа, сделал для вас), финансирование от земли Северный Рейн-Вестфалия:
ссылкаkotomyava
04.03.2016 02:43> Угу. Гораздо лучше, когда не только виноватого не найдешь, а еще и коллегиальное решение.
Какое коллегиальное решение? Какие поиски виноватого? Есть методики проверки. Данные проверок фиксируются. Если какой-то работник может это легко обойти, что-то не так — это явная единая точка отказа.
Чтобы что-то гуглить, надо хотя бы приблизительно понимать, о какого рода исследованиях вы говорите, иначе можно угугуиться, а достаточной информации вы по этому случаю не предоставили.
С материалом по вашей ссылке я, к сожалению, ознакомиться не смог — немецкого я не знаю, а результаты автоматического перевода данного текста не читаемы, англоязычной версии тоже не видать.idiv
04.03.2016 20:26С материалом по вашей ссылке я, к сожалению, ознакомиться не смог — немецкого я не знаю, а результаты автоматического перевода данного текста не читаемы, англоязычной версии тоже не видать.
Английский вариант перевода вполне читаемый и понятный.

quakin
28.02.2016 22:21+15По статистике, у 30-80% SSD-накопителей появляется хотя бы один новый плохой блок в течение первых четырёх лет эксплуатации
По сравнению со всем спектром значений (0-100%), указанные цифры — это вершина точности!
А если серьёзно и если я что-то не понимаю в процентах… как понимать эти цифры?
Logonoff
28.02.2016 22:30+10Понимать очень просто: не забывайте про бэкапы.

Wesha
29.02.2016 01:08+2> не забывайте про бэкапы.
… и про то, что бэкапы — не панацея, а всего лишь снижение вероятности потери, ибо в бэкапе ошибка может появиться точно так же, как и в основной копии…
Поэтому ZFS (https://ru.wikipedia.org/wiki/ZFS), построенная на предположении, что *все* носители ненадёжны, в режиме zraid — наше всё!
justaguest
29.02.2016 01:41Или ее конкурента btrfs (https://ru.wikipedia.org/wiki/Btrfs), там так же реализовано CoW (copy-on-write).
ClearAirTurbulence
29.02.2016 01:54btrfs, мягко выражаясь, недоделана, в отличие от.
justaguest
29.02.2016 02:03Да, я знаю про проблемы, я даже лично жаловался где-то в комментариях полгода назад. Я думаю, это зависит от «новизны» ядра, т.к. FS пока новая. К примеру, на данный момент у меня kernel-4.2.0-30, и проблем я больше давно не испытываю.
Статус можно посмотреть тут: https://btrfs.wiki.kernel.org/index.php/Main_Page#Stability_statusimmaculate
29.02.2016 09:47Около года назад у меня на btrfs появлялись неудаляемые каталоги, а btrfsck падал с Segmentation Fault.
Так что откатился на ext4, еще годик-два подожду.
reji
29.02.2016 15:06В отличии чего? От ZFS или от ZoL? Это очень важное замечание, ведь ZFS недоступна на линуксе.
P.S. Большинство проблем с btrfs было производными от контейнеров — когда создается тысячи снэпшотов. Сходу не могу придумать юзкейз для такого, если не использовать контейнеры.
P.P.S. Не умаляю багов btrfs, они есть. Но и в ZoL они присутствуют. И по опыту я доверяю первому больше, чем второму, так в продакшне ZoL — редчайшая редкость, а btrfs — нет.
ZoL будет доступен без бубна только с Ubuntu 16.04

Eureka
28.02.2016 22:52Я понял так: у 20% в течение первых 4 месяцев не обнаружено ни одного плохого блока, как минимум у 30% процентов был обнаружен минимум 1 плохой блок в тот же период.

Bakanohito
29.02.2016 07:51Ну, или в среднем у 55% за четыре года появляется хотябы 1 бедблок, а 25% — полуширина доверительного интервала при выбранной значимости и количества проверенных устройств…
BigHotey
29.02.2016 08:39Здесь больше смысла в сравнении порядка цифр. Бедблоки появляются на порядок чаще, чем сбои микросхем.


Garbus
28.02.2016 22:42+3Интересно было бы глянуть статистику, отличается ли оно для TLC, или особых отличий от MLC нет?
Все же сейчас пытаются их продвинуть как самые недорогие, не хотелось бы падения срока службы даже без учета циклов записи.
denis_g
28.02.2016 23:16+2>> https://www.usenix.org/sites/default/files/fast16_full_proceedings.pdf
Да это же просто кладезь полезной информации! Спасибо.

icCE
28.02.2016 23:18+1что на надёжность накопителей влияет возраст, а не интенсивность использования.
Да ладно? По моему это очевидно.idiv
28.02.2016 23:26+1Да ладно? По моему это очевидно.
Имеется ввиду, что куча перезаписываний не настолько влияет на работоспособность по сравнению со свежим "из упаковки", как календарный износ. Что, в общем, неплохо, легче планировать замену.Patttern
29.02.2016 11:17Позволю себе не согласиться с тем, что куча перезаписываний не «настолько» влияет на работоспособность. Во-первых, хотелось бы уточнить какой процент интенсивности имелся ввиду в слове «настолько»? Во-вторых, с практической точки зрения, на наших серверах ни один SSD не прожил более полугода при интенсивных циклах чтение/запись.
reji
29.02.2016 15:10Так это же замечательно! Вам должны были обменять диск по гарантии. Планируйте замены и у вас всегда будет новый диск без затрат с вашей стороны ;)
Mad__Max
29.02.2016 20:23Не будет — т.к. в условиях гарантии прописан не только срок в годах/месяцах работы, но и максимально допустимые объемы записи — в виде кол-ва циклов или ТБ записанных данных.
reji
29.02.2016 21:41Странные у вас диски, однако.
root@NDA:~# vmstat -D | awk '/written sectors/ {print $1 * 512 / 1000 / 1000 / 1000}'
16955.4
root@NDA:~# uptime | awk '{print $3" "$4}'
186 days,
За полгода 17 ТБ, ни один диск не меняли.
Более долгую статистику лень поднимать.
P.S. Хотя это не честная статистика. Четыре диска, raid 10.Mad__Max
29.02.2016 22:05+1Какие диски странные? Почему у меня?
Я же не писал никаких конкретных объемов записи или конкретных моделей. Это вообще общая практика всех производителей SSD ограничивать объем записи и отказывать в гарантийной замене при превышении прописанных объемов/нагрузки по записи.
Что до конкретики, то 17 ТБ за полгода да еще не на одиночный диск, а целый массив — это совсем немного по меркам современных серверов и SSD. Для серверных вариантов дисков обычно нагрузка до 50-100 ГБ записи/сутки (на одиночный диск) покрывается гарантией. Потому и не меняли — до исчерпания ресурса скорее всего еще далеко.
У меня на скромном домашнем сервере/раб. станции только для личного использования (+ научные расчеты в на свободных процессорных ресурсах) на единственный диск 13 ТБ записи за последние 4 месяца. Правда объем смотрю не по мониторингу файловой системы ОС, а по данным контроллера самого диска (в SMART) — данные от ОС получаются заниженные, т.к. на SSD имеется такой эффект как Write amplification приводящий к тому, что по факту на флэш пишется существенно больше чем ОС отсылает для записи в контроллер диска. Из-за известного несоответствия логических блоков которыми идет запись на уровне ОС (сектор/кластер объемами 0.5-16 кб) и физической записью(стиранием) флэш памяти которая возможна только минимальными блоками по 256-1024 кб.reji
01.03.2016 18:21Глянул другой сервер. 636 гб/сутки(делим пополам, т.к. raid 10) при объеме диска в 279GiB (300GB) Но там аптайм всего 134 дня, поэтому не приводил как пример — меньше, чем указанные выше "выходят из строя за полгода".
И это по "существенно заниженным данным" (с)
Я веду к тому, что утверждение "ни один SSD не прожил более полугода" — голословно без пруфов.Mad__Max
01.03.2016 21:00Ну с этим вопросом к Patttern который про полгода и писал, а не я. Только какой пруф? Ну приведет он свою собственную статистику со своих серверов. Которую можно будет лишь принять (или не принимать) на веру/слово, т.к. какие там сервера и что они именно они у них в организации делают мы не знаем и проверить не можем.
А что действительно интенсивной записью SSD можно и всего за несколько месяцев убить я не сомневаюсь, проверялось неоднократно. Если задаться такой целью то и за неделю-другую убить можно(но это уже специально — типа зацикленного теста на линейную запись, в реальных задачах таких жестких вариантов не встречается). Для того производители SSD и страхуются прописывая объем записи в условиях гарантии в отличии от производителей HDD, которым этот параметр безразличен.
P.S.
Вот по 636 Гб/сутки по мониторингу ОС это уже довольно серьезные объемы записи для сервера. Диски из этого массива вполне рискуют не дожить до конца гарантии и получить отказ в бесплатной их замене по причине превышения допустимой нагрузки.reji
02.03.2016 19:09Упс, сорян, у вас ники и аватарки очень похожие, не заметил. (=
Если диск вылетит и я это замечу(а не кто-то другой из админов) — обязательно напишу здесь комментарий.
idiv
29.02.2016 19:44Позволю себе не согласиться с тем, что куча перезаписываний не «настолько» влияет на работоспособность.
Это статистика Google, не мои слова и не мои исследования. У вас есть сопоставимая по размерам база данных?Patttern
29.02.2016 21:14Если бы я занимался сбором статистики, я бы обязательно собрал подобные данные. Однако, в данном случае, меня больше интересует практическая сторона этого вопроса, которая, по моим меркам, никак не соответствует действительности.
Mad__Max
29.02.2016 20:27Там в табличке (последняя строчка в 1й) есть объем записи в эквиваленте среднего кол-ва циклов полной перезаписи. Ни в одном из обобщенных классов средний показатель даже до 1000 циклов не доходит — потому и "не влияет"
Хотя на самом деле влияет, но еще так слабо что статистической значимости не имеет и выводы из этого делать не позволяет.idiv
29.02.2016 21:33Хотя на самом деле влияет, но еще так слабо что статистической значимости не имеет и выводы из этого делать не позволяет.
Это статистика конкретной компании и конкретного способа использования. Была бы статистика для сравнения со сравнимы объемами — было бы интересно почитать.
Mad__Max
29.02.2016 20:22Она не влияет только потому что конкретно у гугла количество этих циклов до смешного (по меркам серверов) низкое — тут же в статье табличка с основными данными есть — среднее кол-во циклов перезаписи даже до 1000 ни в одном классе не дотягивает. Что существенно меньше самых слабых в этом смысле MLC (3000 циклов).
Естественно в таких условиях зависимость надежности от кол-ва циклов записи еще не прослеживается. Единственное непонятно — а нафига гугл вообще более дорогие SLC накопители массово закупал, если исходя из интенсировностей использования им вполне достаточно MLC?idiv
29.02.2016 21:34Единственное непонятно — а нафига гугл вообще более дорогие SLC накопители массово закупал, если исходя из интенсировностей использования им вполне достаточно MLC?
Тут могу предположить выгодные условия и право компании сообщать "а еще мы Гуглу наши продаем".netto
29.02.2016 23:37+1Скорее всего они их начали закупать еще тогда, когда SSD были только SLC на рынке, в самом их начале.

MnogoBukv
28.02.2016 23:39+6С чего это вдруг становится очевидно? То все мозги промыли циклами записи, и вдруг время работы откуда-то появилось.
icCE
29.02.2016 07:50+2Для меня всегда был очевиден этот факт, как и то, что SSD плохо лежат без питания. Предлогам вам окунутся в мир мелкой электроники, это поможет смотреть на все вещи под другим углом.
MnogoBukv
01.03.2016 17:08Одно дело — потеря данных на полке с течением времени. Ячейка же не деградирует через 2 года, я надеюсь? Перезаписали, и в путь. А тут деградация. Необратимая. Мне кажется, это не одно и тоже.
Mad__Max
01.03.2016 21:11+1Да, совершенно разные процессы. В одном случае физическая деградация, в другом просто постепенное "утекание" заряда из управляющего электрода транзистора, который и сохраняет данные. И восстанавливается на исходном уровне после каждой перезаписи. Одно пропорционально кол-ву циклов перезаписи, 2е времени хранения без подачи питания.
Правда они коррелируют — чем выше физ. износ (количество уже произведенных циклов перезаписи), тем быстрее начинает "утекать" заряд.
Т.е. новый в плане "пробега" диск может довольно долго "лежать на полке" с данными в полной сохранности. А вот поношенный, приближающийся к концу ресурса по записи может уже через несколько месяцев без питания начинать терять записанные данные.
Поэтому взять старый(точнее изношенный) SSD и использовать его для бекапа — будет очень плохой идеей. Хотя такой вариант на 1й взгляд напрашивается — дескать при продолжении активной эксплуатации он скоро накроется ввиду исчерпания ресурса, а вот как офлайн-накопитель с очень редкой перезаписью еще послужит.



yogghy
28.02.2016 23:32+2Работаю в отрасли. Результаты весьма удивительны, надо признать: техпроцесс 50 нм, один и тот же вендор, а процент сбойных драйвов MLC-A и SLC-B отличаются в два с половиной раза не в пользу SLC. А еще в сравнении SLC-A и SLC-B — первый 34 нм, второй 50 нм — первый довольно неожиданно выигрывает.
Пожалуй, посмотрим на таблички повнимательнее на работе.
И это самое. Анатолий, вы бы убрали тэг UBER, ей-ей :)kotomyava
01.03.2016 22:33Ну у каждого производителя бывают более или менее удачные продукты… Тем более, что может быть разница в выходе качественных кристаллов на оборудовании с более грубым техпроцессом, к примеру — для 34нм оборудование явно современее и точнее, возможно, рассчитано и на более тонкие процессы. Или вообще разные фабрики с разной культурой производства, если делаются чипы не своими силами.
tixkost
29.02.2016 09:09Было бы намного интереснее узнать анализ физики отказа/деградации/усталости/ошибки при чтении SSD и сравнение актуальной статистики с моделями, которые использовались, чтобы предсказать надежность этих ссдшек.

lovecraft
29.02.2016 10:20Да, об этом тоже написано. Видимо, гадание на кофейной гуще надежнее )
Much academic work and also tests during the procurement
phase in industry rely on accelerated life tests to
derive projections for device reliability in the field. We
are interested in how well predictions from such tests reflect
field experience.
Analyzing results from tests performed during the procurement
phase at Google, following common methods
for test acceleration, we find that field RBER rates
are significantly higher than the projected rates. For example,
for model eMLC-A the median RBER for drives
in the field (which on average reached 600 PE cycles at
the end of data collection) is 1e-05, while under test the
RBER rates for this PE cycle range were almost an order
of magnitude lower and didn’t reach comparable rates
until more than 4,000 PE cycles. This indicates that it
might be very difficult to accurately predict RBER in the
field based on RBER estimates from lab tests.
lovecraft
29.02.2016 10:12+1Неожиданным оказалось, что на надёжность накопителей влияет возраст, а не интенсивность использования.
Это как сказать, вот коэффициент ранговой корреляции Спирмена из статьи.

Видно, что в первую очередь ошибки встречаются на тех дисках, на которых ошибки встречались ранее (корреляция 0,8 из 1), во вторую — на "старичках" и "затертых" (корреляция 0,4 из 1). Учитывая, что в энтерпрайзе количество PE является функцией от возраста диска, нет ничего удивительного в том, что PE и возраст влияют на надежность одинаково.

potan
29.02.2016 10:23Что значит "неисправимых"? На HDD может выйти из строя головка или механика и весь диск непригоден для работы. А появление нескольких bad block всего-лишь уменьшает доступную емкость, а для чтения может быть скомпенсировано избыточным кодированием.
lovecraft
29.02.2016 10:41+2Это у них терминология такая:
Uncorrectable error: A read operation encounters more
corrupted bits than the ECC can correct.
Final read error: A read operation experiences an error,
and even after retries the error persists.
Final write error: A write operation experiences an error
that persists even after retries.
alexkunin
То, что такие данные не зажимаются в столах менеджеров — офигенно.